 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Position Prediction as an Effective Pretraining Strategy
Jul 15, 2022
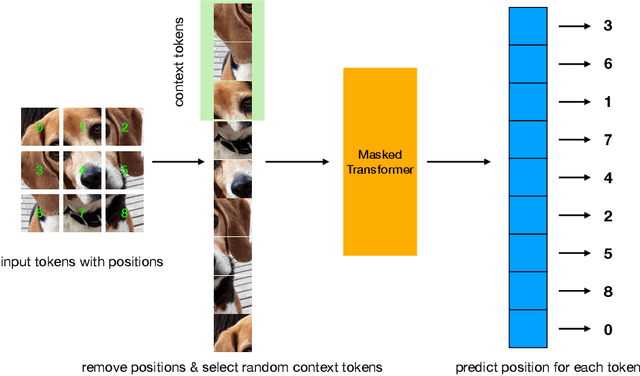


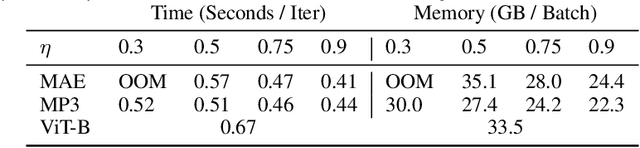
Transformers have gained increasing popularity in a wide range of applications, including Natural Language Processing (NLP), Computer Vision and Speech Recognition, because of their powerful representational capacity. However, harnessing this representational capacity effectively requires a large amount of data, strong regularization, or both, to mitigate overfitting. Recently, the power of the Transformer has been unlocked by self-supervised pretraining strategies based on masked autoencoders which rely on reconstructing masked inputs, directly, or contrastively from unmasked content. This pretraining strategy which has been used in BERT models in NLP, Wav2Vec models in Speech and, recently, in MAE models in Vision, forces the model to learn about relationships between the content in different parts of the input using autoencoding related objectives. In this paper, we propose a novel, but surprisingly simple alternative to content reconstruction~-- that of predicting locations from content, without providing positional information for it. Doing so requires the Transformer to understand the positional relationships between different parts of the input, from their content alone. This amounts to an efficient implementation where the pretext task is a classification problem among all possible positions for each input token. We experiment on both Vision and Speech benchmarks, where our approach brings improvements over strong supervised training baselines and is comparable to modern unsupervised/self-supervised pretraining methods. Our method also enables Transformers trained without position embeddings to outperform ones trained with full position information.
An online sequence-to-sequence model for noisy speech recognition
Jun 16, 2017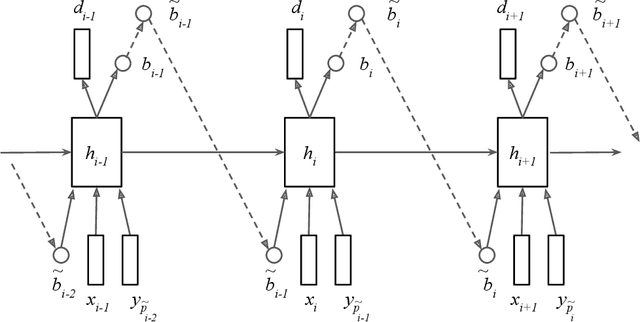
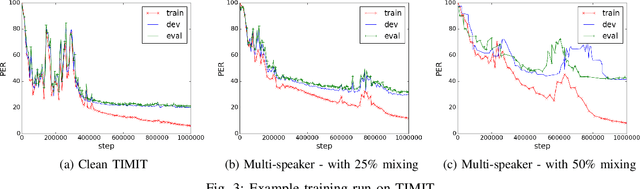
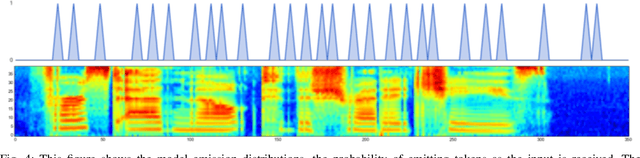
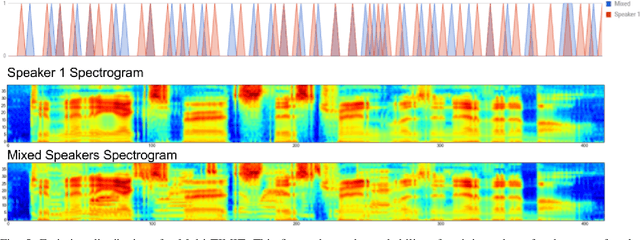
Generative models have long been the dominant approach for speech recognition. The success of these models however relies on the use of sophisticated recipes and complicated machinery that is not easily accessible to non-practitioners. Recent innovations in Deep Learning have given rise to an alternative - discriminative models called Sequence-to-Sequence models, that can almost match the accuracy of state of the art generative models. While these models are easy to train as they can be trained end-to-end in a single step, they have a practical limitation that they can only be used for offline recognition. This is because the models require that the entirety of the input sequence be available at the beginning of inference, an assumption that is not valid for instantaneous speech recognition. To address this problem, online sequence-to-sequence models were recently introduced. These models are able to start producing outputs as data arrives, and the model feels confident enough to output partial transcripts. These models, like sequence-to-sequence are causal - the output produced by the model until any time, $t$, affects the features that are computed subsequently. This makes the model inherently more powerful than generative models that are unable to change features that are computed from the data. This paper highlights two main contributions - an improvement to online sequence-to-sequence model training, and its application to noisy settings with mixed speech from two speakers.
Contrastive Unsupervised Learning for Speech Emotion Recognition
Feb 12, 2021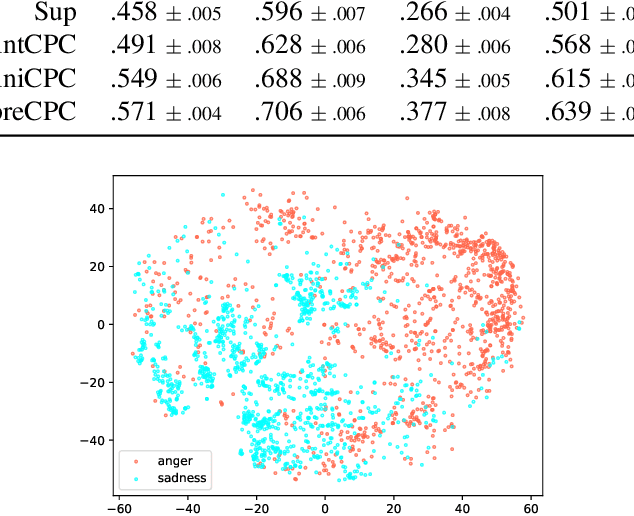

Speech emotion recognition (SER) is a key technology to enable more natural human-machine communication. However, SER has long suffered from a lack of public large-scale labeled datasets. To circumvent this problem, we investigate how unsupervised representation learning on unlabeled datasets can benefit SER. We show that the contrastive predictive coding (CPC) method can learn salient representations from unlabeled datasets, which improves emotion recognition performance. In our experiments, this method achieved state-of-the-art concordance correlation coefficient (CCC) performance for all emotion primitives (activation, valence, and dominance) on IEMOCAP. Additionally, on the MSP- Podcast dataset, our method obtained considerable performance improvements compared to baselines.
Scaling ASR Improves Zero and Few Shot Learning
Nov 29, 2021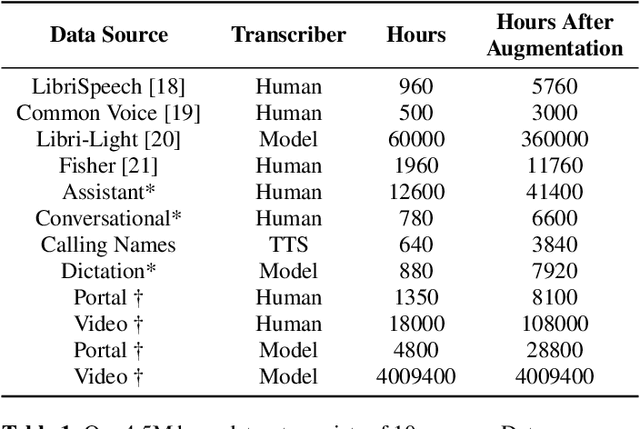
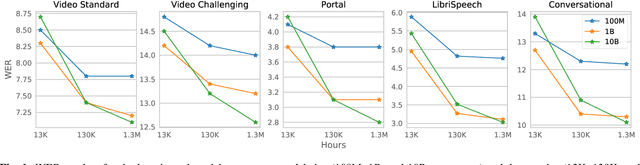
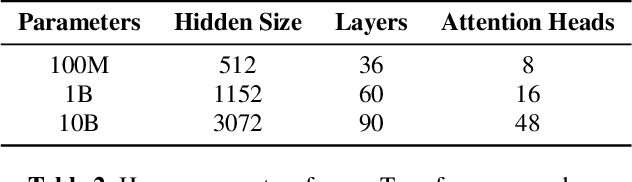
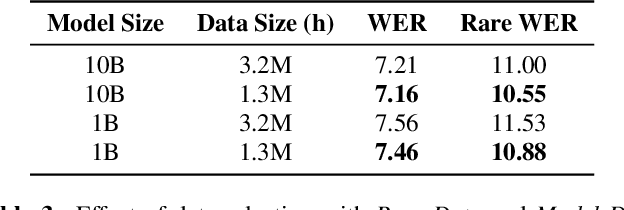
With 4.5 million hours of English speech from 10 different sources across 120 countries and models of up to 10 billion parameters, we explore the frontiers of scale for automatic speech recognition. We propose data selection techniques to efficiently scale training data to find the most valuable samples in massive datasets. To efficiently scale model sizes, we leverage various optimizations such as sparse transducer loss and model sharding. By training 1-10B parameter universal English ASR models, we push the limits of speech recognition performance across many domains. Furthermore, our models learn powerful speech representations with zero and few-shot capabilities on novel domains and styles of speech, exceeding previous results across multiple in-house and public benchmarks. For speakers with disorders due to brain damage, our best zero-shot and few-shot models achieve 22% and 60% relative improvement on the AphasiaBank test set, respectively, while realizing the best performance on public social media videos. Furthermore, the same universal model reaches equivalent performance with 500x less in-domain data on the SPGISpeech financial-domain dataset.
Unsupervised Cross-Lingual Speech Emotion Recognition Using Pseudo Multilabel
Aug 19, 2021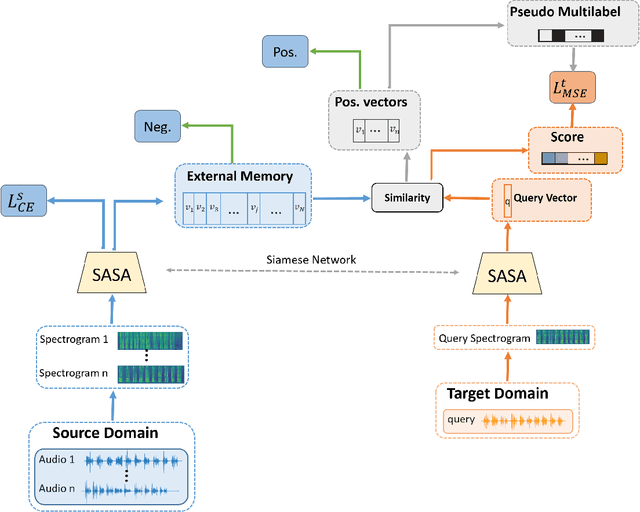
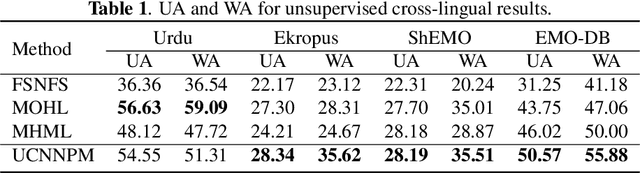

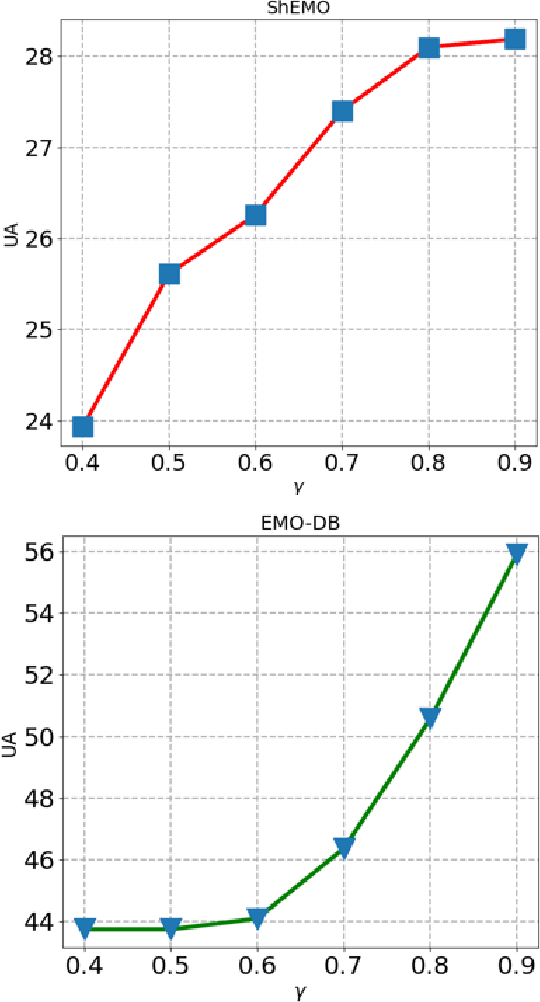
Speech Emotion Recognition (SER) in a single language has achieved remarkable results through deep learning approaches in the last decade. However, cross-lingual SER remains a challenge in real-world applications due to a great difference between the source and target domain distributions. To address this issue, we propose an Unsupervised Cross-Lingual Neural Network with Pseudo Multilabel (UCNNPM) that is trained to learn the emotion similarities between source domain features inside an external memory adjusted to identify emotion in cross-lingual databases. UCNNPM introduces a novel approach that leverages external memory to store source domain features and generates pseudo multilabel for each target domain data by computing the similarities between the external memory and the target domain features. We evaluate our approach on multiple different languages of speech emotion databases. Experimental results show our proposed approach significantly improves the weighted accuracy (WA) across multiple low-resource languages on Urdu, Skropus, ShEMO, and EMO-DB corpus.
Complex Frequency Domain Linear Prediction: A Tool to Compute Modulation Spectrum of Speech
Mar 31, 2022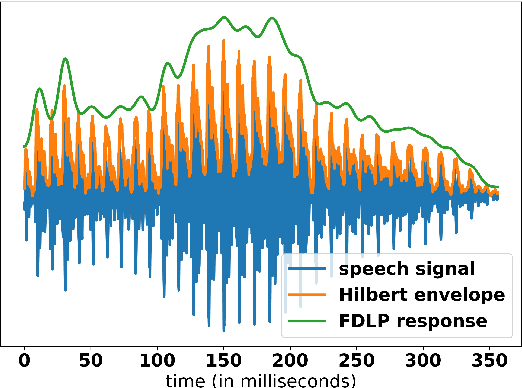

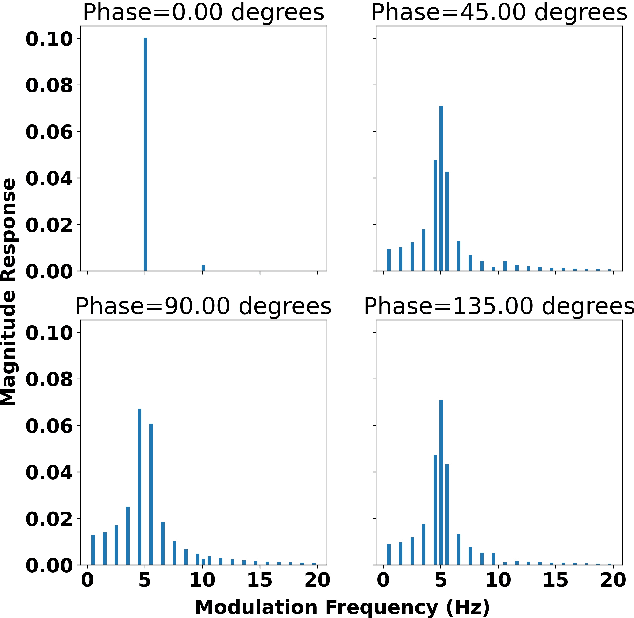
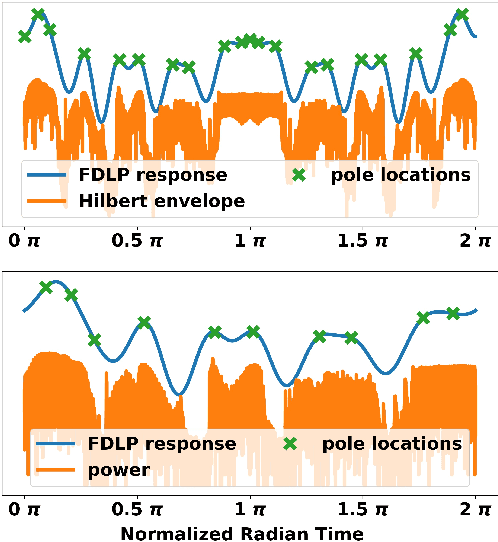
Conventional Frequency Domain Linear Prediction (FDLP) technique models the squared Hilbert envelope of speech with varied degrees of approximation which can be sampled at the required frame rate and used as features for Automatic Speech Recognition (ASR). Although previously the complex cepstrum of the conventional FDLP model has been used as compact frame-wise speech features, it has lacked interpretability in the context of the Hilbert envelope. In this paper, we propose a modification of the conventional FDLP model that allows easy interpretability of the complex cepstrum as temporal modulations in an all-pole model approximation of the power of the speech signal. Additionally, our "complex" FDLP yields significant speed-ups in comparison to conventional FDLP for the same degree of approximation.
Context-based out-of-vocabulary word recovery for ASR systems in Indian languages
Jun 09, 2022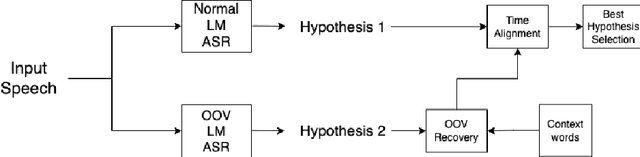
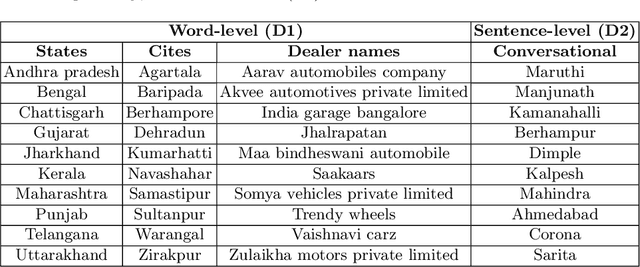
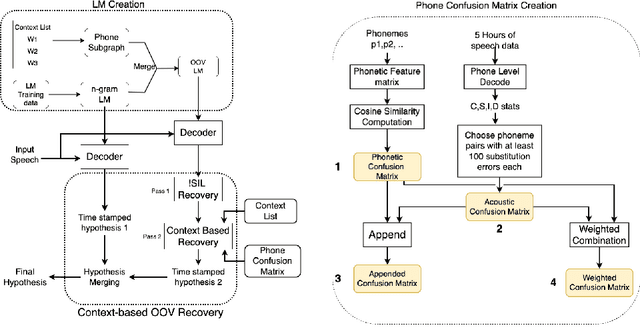
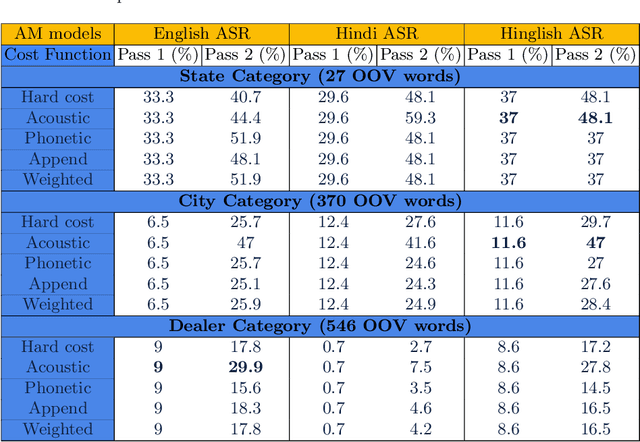
Detecting and recovering out-of-vocabulary (OOV) words is always challenging for Automatic Speech Recognition (ASR) systems. Many existing methods focus on modeling OOV words by modifying acoustic and language models and integrating context words cleverly into models. To train such complex models, we need a large amount of data with context words, additional training time, and increased model size. However, after getting the ASR transcription to recover context-based OOV words, the post-processing method has not been explored much. In this work, we propose a post-processing technique to improve the performance of context-based OOV recovery. We created an acoustically boosted language model with a sub-graph made at phone level with an OOV words list. We proposed two methods to determine a suitable cost function to retrieve the OOV words based on the context. The cost function is defined based on phonetic and acoustic knowledge for matching and recovering the correct context words in the decode. The effectiveness of the proposed cost function is evaluated at both word-level and sentence-level. The evaluation results show that this approach can recover an average of 50% context-based OOV words across multiple categories.
Memory-Efficient Training of RNN-Transducer with Sampled Softmax
Mar 31, 2022
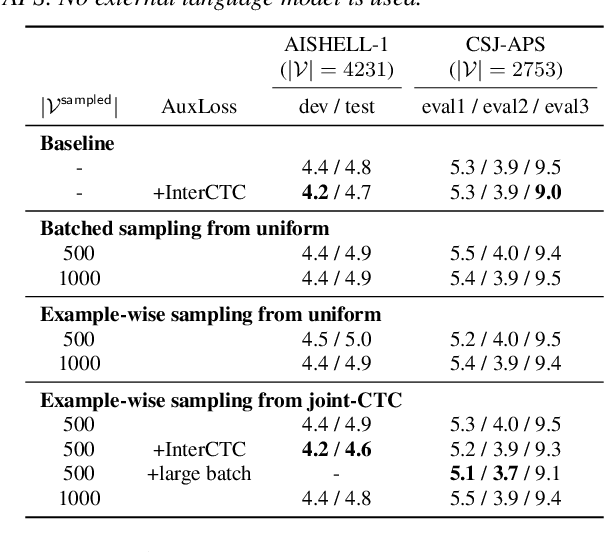
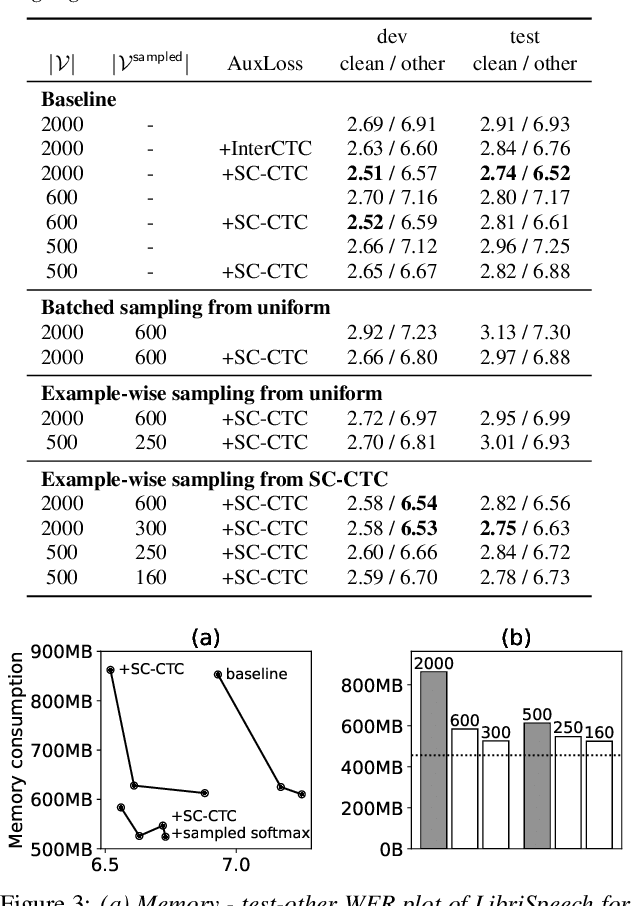
RNN-Transducer has been one of promising architectures for end-to-end automatic speech recognition. Although RNN-Transducer has many advantages including its strong accuracy and streaming-friendly property, its high memory consumption during training has been a critical problem for development. In this work, we propose to apply sampled softmax to RNN-Transducer, which requires only a small subset of vocabulary during training thus saves its memory consumption. We further extend sampled softmax to optimize memory consumption for a minibatch, and employ distributions of auxiliary CTC losses for sampling vocabulary to improve model accuracy. We present experimental results on LibriSpeech, AISHELL-1, and CSJ-APS, where sampled softmax greatly reduces memory consumption and still maintains the accuracy of the baseline model.
Small energy masking for improved neural network training for end-to-end speech recognition
Feb 15, 2020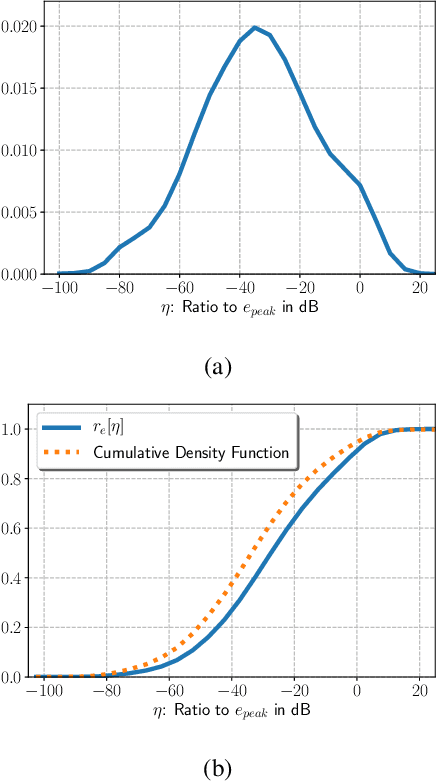
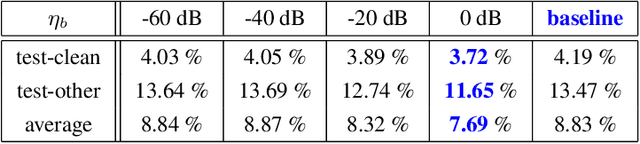
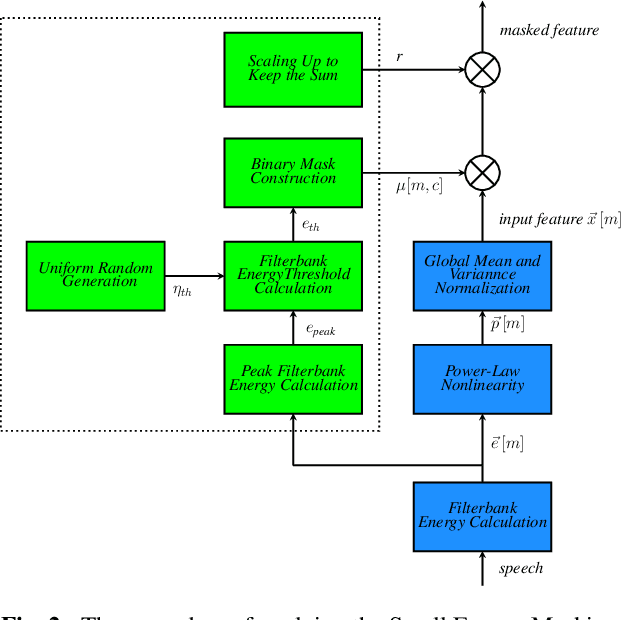
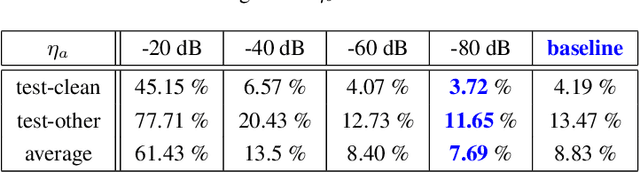
In this paper, we present a Small Energy Masking (SEM) algorithm, which masks inputs having values below a certain threshold. More specifically, a time-frequency bin is masked if the filterbank energy in this bin is less than a certain energy threshold. A uniform distribution is employed to randomly generate the ratio of this energy threshold to the peak filterbank energy of each utterance in decibels. The unmasked feature elements are scaled so that the total sum of the feature values remain the same through this masking procedure. This very simple algorithm shows relatively 11.2 % and 13.5 % Word Error Rate (WER) improvements on the standard LibriSpeech test-clean and test-other sets over the baseline end-to-end speech recognition system. Additionally, compared to the input dropout algorithm, SEM algorithm shows relatively 7.7 % and 11.6 % improvements on the same LibriSpeech test-clean and test-other sets. With a modified shallow-fusion technique with a Transformer LM, we obtained a 2.62 % WER on the LibriSpeech test-clean set and a 7.87 % WER on the LibriSpeech test-other set.
Leveraging Acoustic Contextual Representation by Audio-textual Cross-modal Learning for Conversational ASR
Jul 03, 2022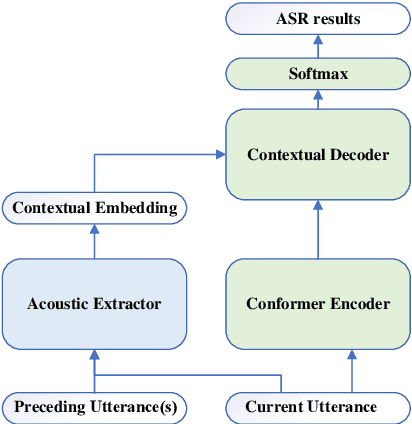
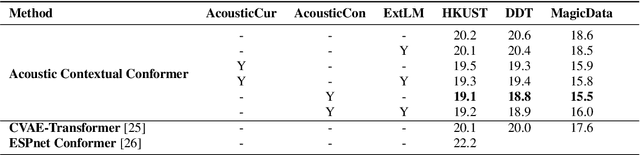
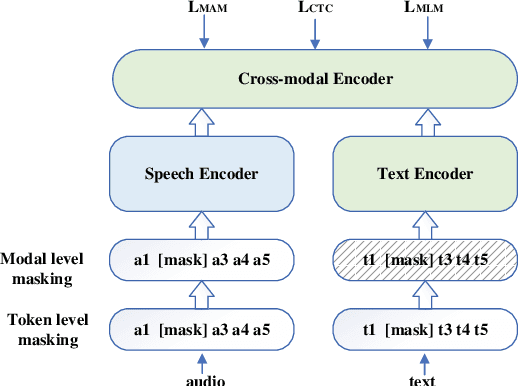

Leveraging context information is an intuitive idea to improve performance on conversational automatic speech recognition(ASR). Previous works usually adopt recognized hypotheses of historical utterances as preceding context, which may bias the current recognized hypothesis due to the inevitable historicalrecognition errors. To avoid this problem, we propose an audio-textual cross-modal representation extractor to learn contextual representations directly from preceding speech. Specifically, it consists of two modal-related encoders, extracting high-level latent features from speech and the corresponding text, and a cross-modal encoder, which aims to learn the correlation between speech and text. We randomly mask some input tokens and input sequences of each modality. Then a token-missing or modal-missing prediction with a modal-level CTC loss on the cross-modal encoder is performed. Thus, the model captures not only the bi-directional context dependencies in a specific modality but also relationships between different modalities. Then, during the training of the conversational ASR system, the extractor will be frozen to extract the textual representation of preceding speech, while such representation is used as context fed to the ASR decoder through attention mechanism. The effectiveness of the proposed approach is validated on several Mandarin conversation corpora and the highest character error rate (CER) reduction up to 16% is achieved on the MagicData dataset.