 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Transfer Learning for Robust Low-Resource Children's Speech ASR with Transformers and Source-Filter Warping
Jun 19, 2022
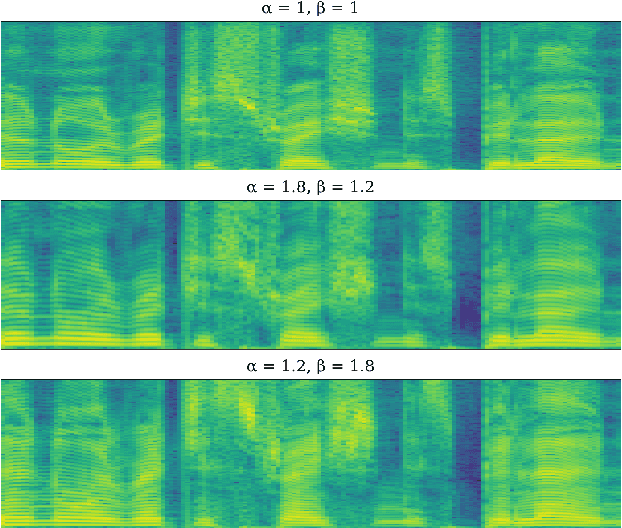
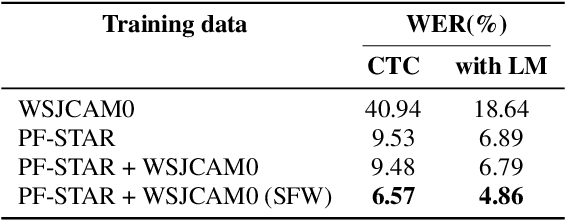
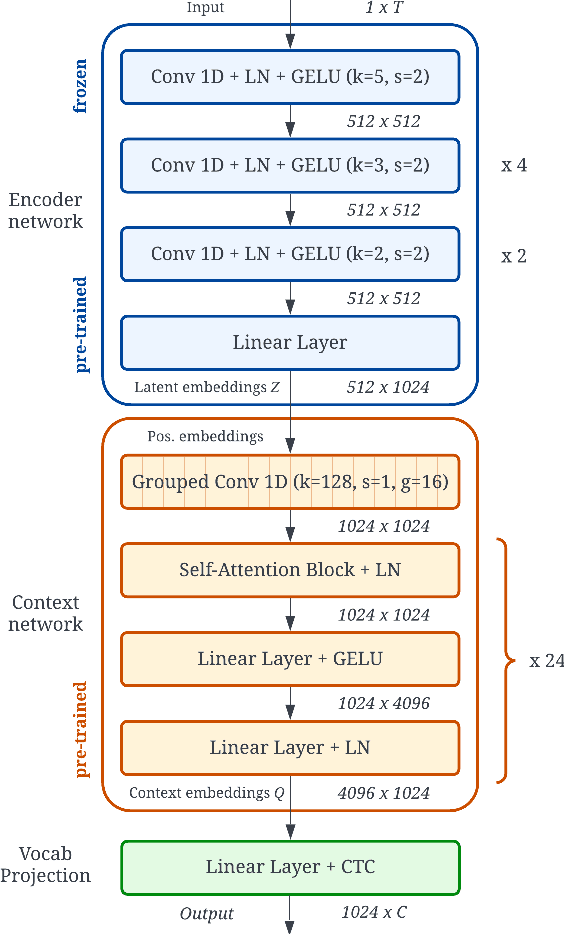
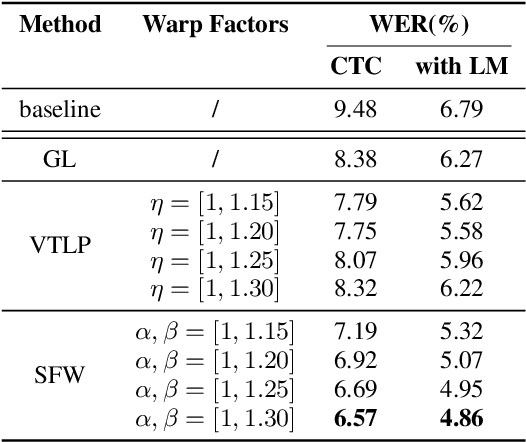
Automatic Speech Recognition (ASR) systems are known to exhibit difficulties when transcribing children's speech. This can mainly be attributed to the absence of large children's speech corpora to train robust ASR models and the resulting domain mismatch when decoding children's speech with systems trained on adult data. In this paper, we propose multiple enhancements to alleviate these issues. First, we propose a data augmentation technique based on the source-filter model of speech to close the domain gap between adult and children's speech. This enables us to leverage the data availability of adult speech corpora by making these samples perceptually similar to children's speech. Second, using this augmentation strategy, we apply transfer learning on a Transformer model pre-trained on adult data. This model follows the recently introduced XLS-R architecture, a wav2vec 2.0 model pre-trained on several cross-lingual adult speech corpora to learn general and robust acoustic frame-level representations. Adopting this model for the ASR task using adult data augmented with the proposed source-filter warping strategy and a limited amount of in-domain children's speech significantly outperforms previous state-of-the-art results on the PF-STAR British English Children's Speech corpus with a 4.86% WER on the official test set.
Advances and Challenges in Deep Lip Reading
Oct 15, 2021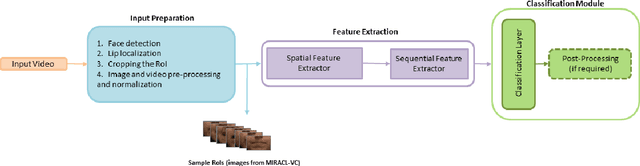

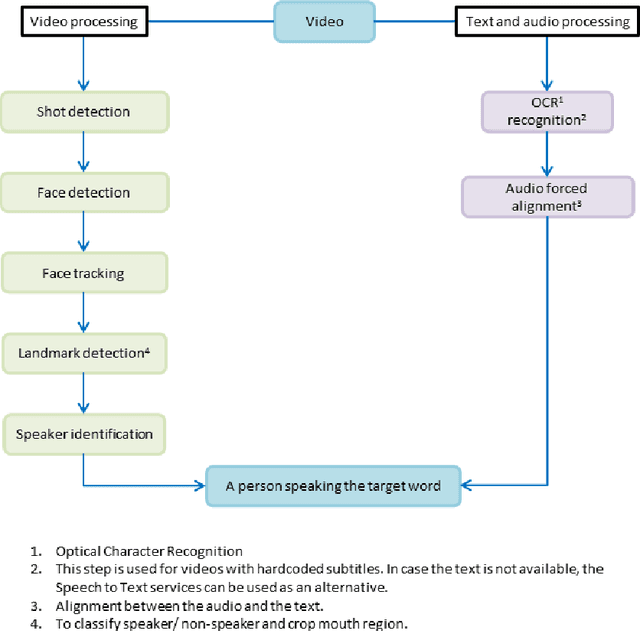
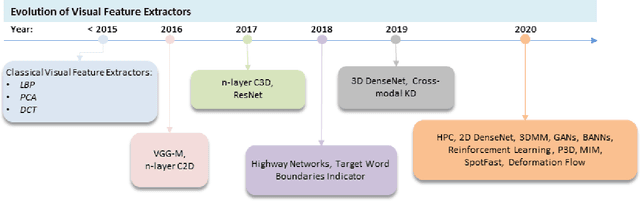
Driven by deep learning techniques and large-scale datasets, recent years have witnessed a paradigm shift in automatic lip reading. While the main thrust of Visual Speech Recognition (VSR) was improving accuracy of Audio Speech Recognition systems, other potential applications, such as biometric identification, and the promised gains of VSR systems, have motivated extensive efforts on developing the lip reading technology. This paper provides a comprehensive survey of the state-of-the-art deep learning based VSR research with a focus on data challenges, task-specific complications, and the corresponding solutions. Advancements in these directions will expedite the transformation of silent speech interface from theory to practice. We also discuss the main modules of a VSR pipeline and the influential datasets. Finally, we introduce some typical VSR application concerns and impediments to real-world scenarios as well as future research directions.
Neural Speech Recognizer: Acoustic-to-Word LSTM Model for Large Vocabulary Speech Recognition
Oct 31, 2016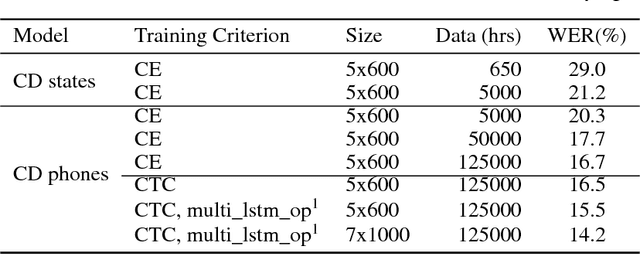
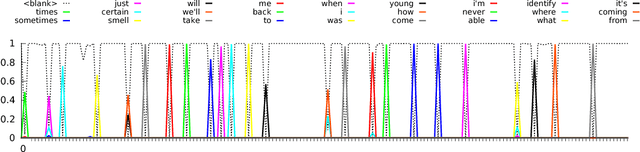
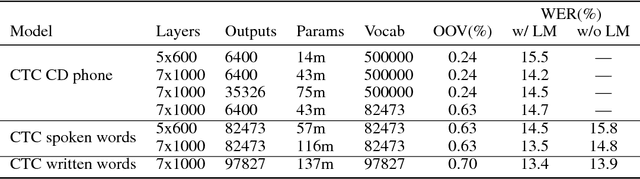

We present results that show it is possible to build a competitive, greatly simplified, large vocabulary continuous speech recognition system with whole words as acoustic units. We model the output vocabulary of about 100,000 words directly using deep bi-directional LSTM RNNs with CTC loss. The model is trained on 125,000 hours of semi-supervised acoustic training data, which enables us to alleviate the data sparsity problem for word models. We show that the CTC word models work very well as an end-to-end all-neural speech recognition model without the use of traditional context-dependent sub-word phone units that require a pronunciation lexicon, and without any language model removing the need to decode. We demonstrate that the CTC word models perform better than a strong, more complex, state-of-the-art baseline with sub-word units.
Bimodal Speech Emotion Recognition Using Pre-Trained Language Models
Nov 29, 2019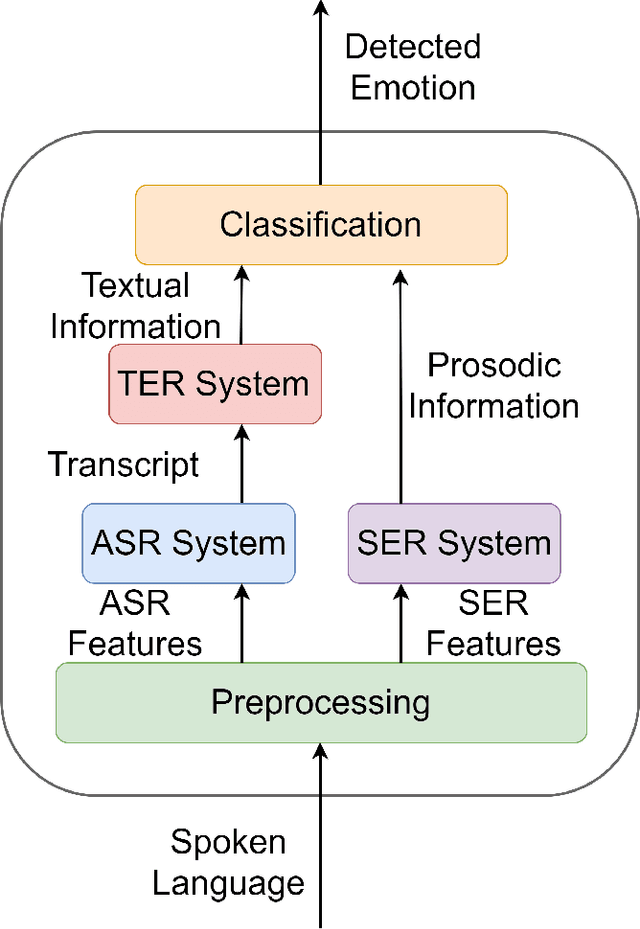
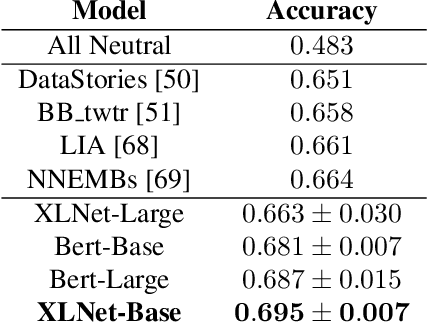

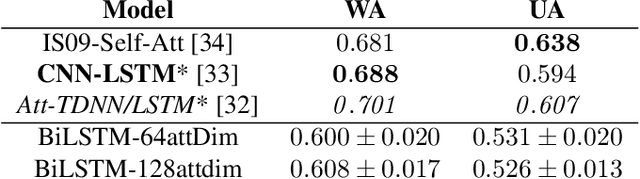
Speech emotion recognition is a challenging task and an important step towards more natural human-machine interaction. We show that pre-trained language models can be fine-tuned for text emotion recognition, achieving an accuracy of 69.5% on Task 4A of SemEval 2017, improving upon the previous state of the art by over 3% absolute. We combine these language models with speech emotion recognition, achieving results of 73.5% accuracy when using provided transcriptions and speech data on a subset of four classes of the IEMOCAP dataset. The use of noise-induced transcriptions and speech data results in an accuracy of 71.4%. For our experiments, we created IEmoNet, a modular and adaptable bimodal framework for speech emotion recognition based on pre-trained language models. Lastly, we discuss the idea of using an emotional classifier as a reward for reinforcement learning as a step towards more successful and convenient human-machine interaction.
Should we hard-code the recurrence concept or learn it instead ? Exploring the Transformer architecture for Audio-Visual Speech Recognition
May 19, 2020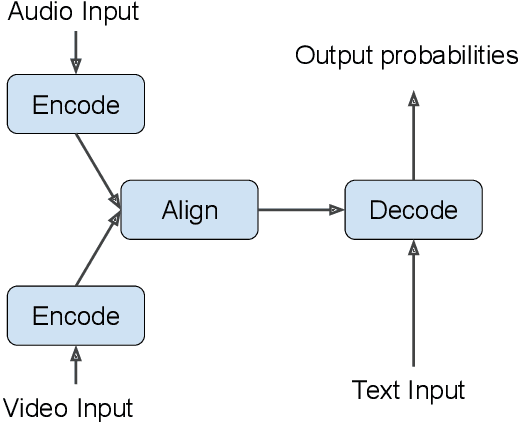
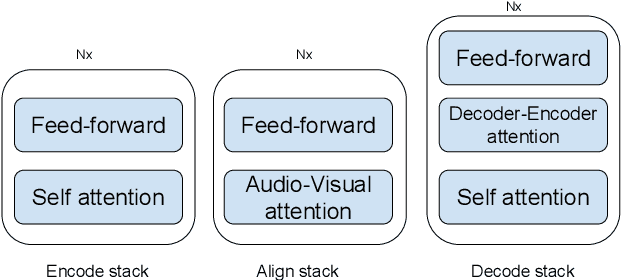
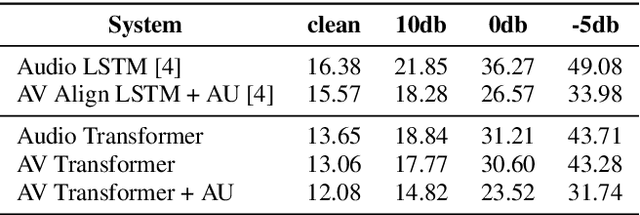
The audio-visual speech fusion strategy AV Align has shown significant performance improvements in audio-visual speech recognition (AVSR) on the challenging LRS2 dataset. Performance improvements range between 7% and 30% depending on the noise level when leveraging the visual modality of speech in addition to the auditory one. This work presents a variant of AV Align where the recurrent Long Short-term Memory (LSTM) computation block is replaced by the more recently proposed Transformer block. We compare the two methods, discussing in greater detail their strengths and weaknesses. We find that Transformers also learn cross-modal monotonic alignments, but suffer from the same visual convergence problems as the LSTM model, calling for a deeper investigation into the dominant modality problem in machine learning.
AutoDiCE: Fully Automated Distributed CNN Inference at the Edge
Jul 20, 2022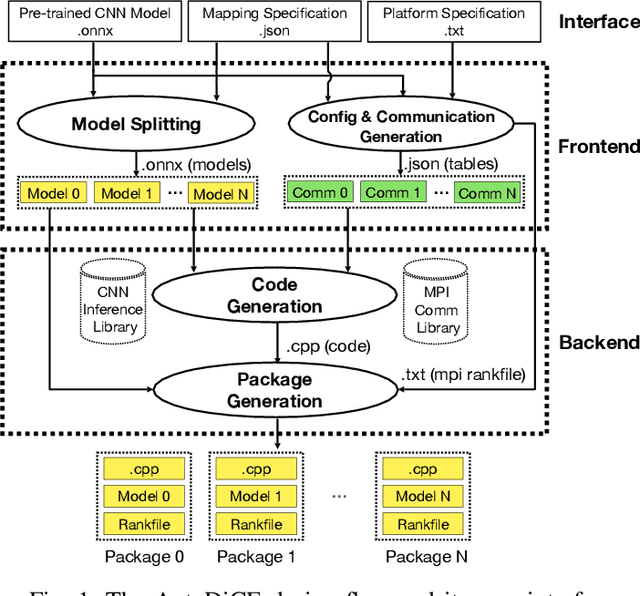
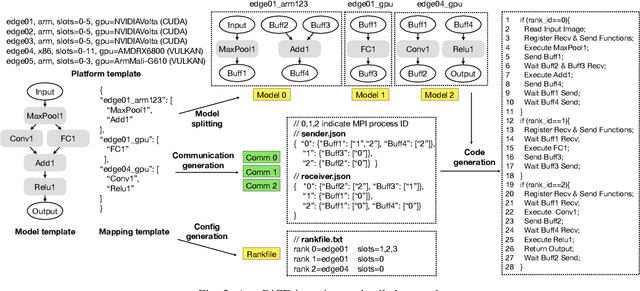
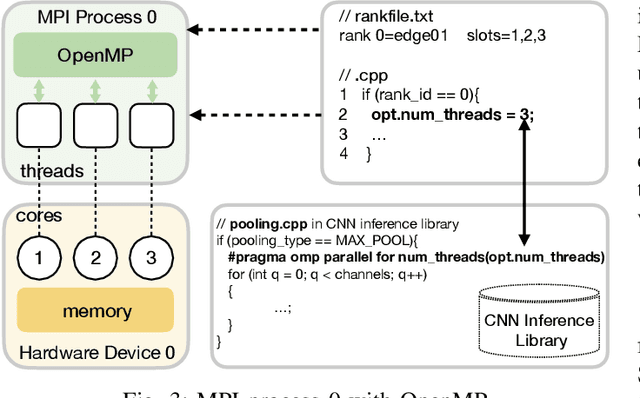
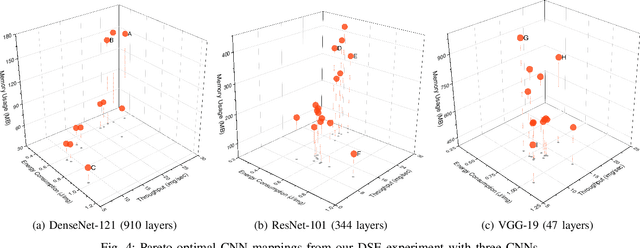
Deep Learning approaches based on Convolutional Neural Networks (CNNs) are extensively utilized and very successful in a wide range of application areas, including image classification and speech recognition. For the execution of trained CNNs, i.e. model inference, we nowadays witness a shift from the Cloud to the Edge. Unfortunately, deploying and inferring large, compute and memory intensive CNNs on edge devices is challenging because these devices typically have limited power budgets and compute/memory resources. One approach to address this challenge is to leverage all available resources across multiple edge devices to deploy and execute a large CNN by properly partitioning the CNN and running each CNN partition on a separate edge device. Although such distribution, deployment, and execution of large CNNs on multiple edge devices is a desirable and beneficial approach, there currently does not exist a design and programming framework that takes a trained CNN model, together with a CNN partitioning specification, and fully automates the CNN model splitting and deployment on multiple edge devices to facilitate distributed CNN inference at the Edge. Therefore, in this paper, we propose a novel framework, called AutoDiCE, for automated splitting of a CNN model into a set of sub-models and automated code generation for distributed and collaborative execution of these sub-models on multiple, possibly heterogeneous, edge devices, while supporting the exploitation of parallelism among and within the edge devices. Our experimental results show that AutoDiCE can deliver distributed CNN inference with reduced energy consumption and memory usage per edge device, and improved overall system throughput at the same time.
Unsupervised Cross-Lingual Speech Emotion Recognition Using Pseudo Multilabel
Aug 19, 2021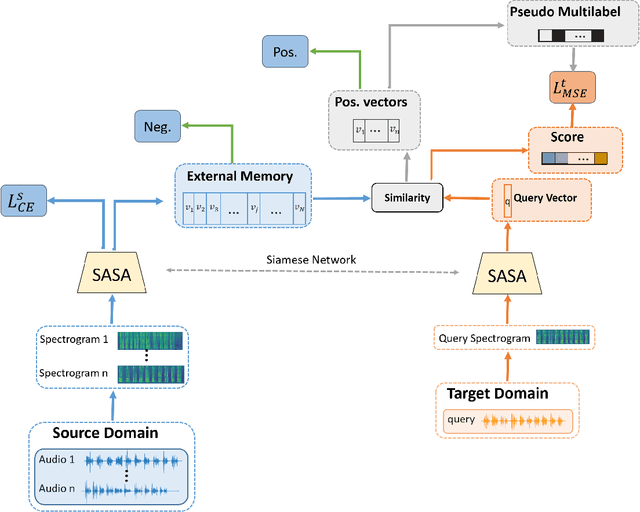
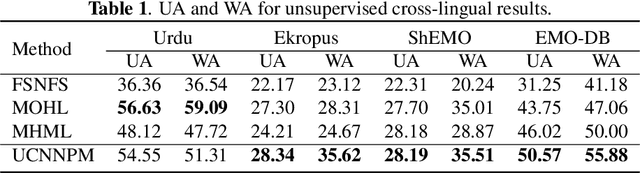

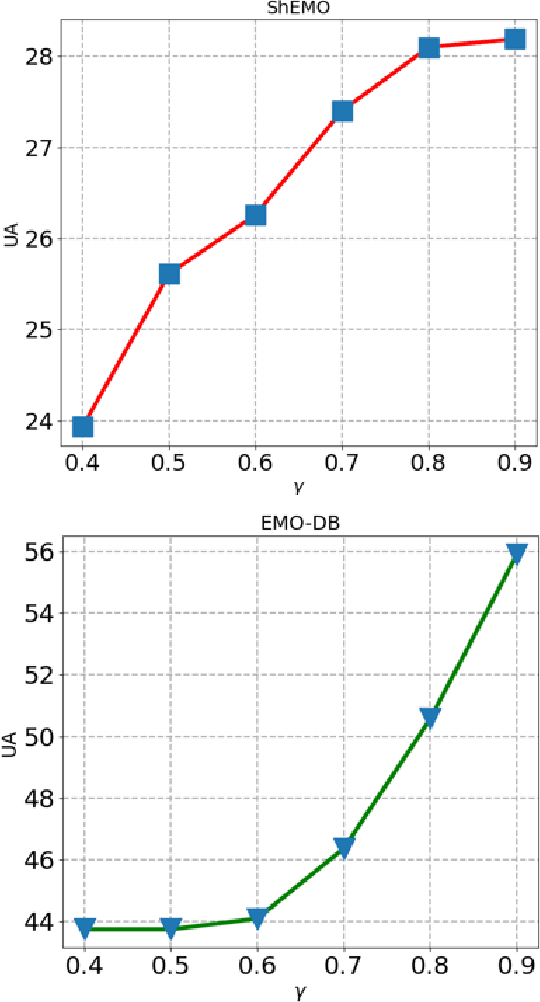
Speech Emotion Recognition (SER) in a single language has achieved remarkable results through deep learning approaches in the last decade. However, cross-lingual SER remains a challenge in real-world applications due to a great difference between the source and target domain distributions. To address this issue, we propose an Unsupervised Cross-Lingual Neural Network with Pseudo Multilabel (UCNNPM) that is trained to learn the emotion similarities between source domain features inside an external memory adjusted to identify emotion in cross-lingual databases. UCNNPM introduces a novel approach that leverages external memory to store source domain features and generates pseudo multilabel for each target domain data by computing the similarities between the external memory and the target domain features. We evaluate our approach on multiple different languages of speech emotion databases. Experimental results show our proposed approach significantly improves the weighted accuracy (WA) across multiple low-resource languages on Urdu, Skropus, ShEMO, and EMO-DB corpus.
Decoupled Federated Learning for ASR with Non-IID Data
Jun 18, 2022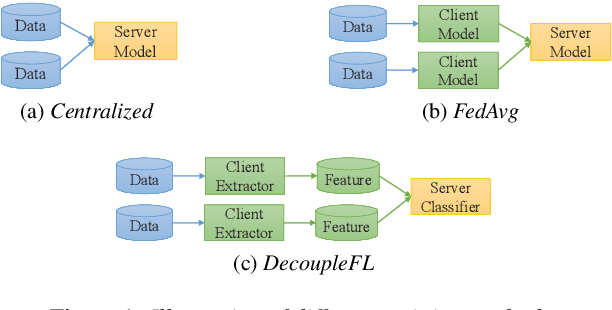
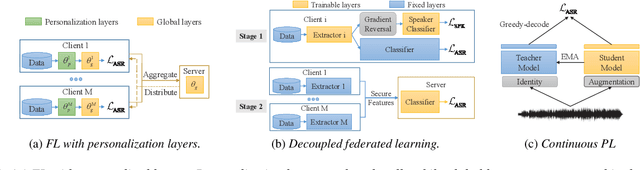
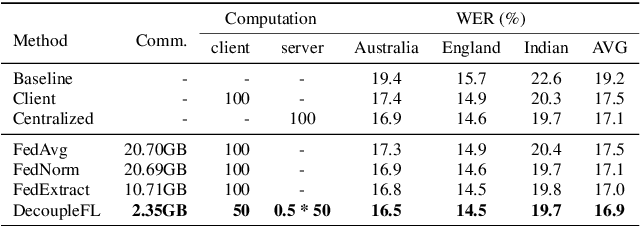
Automatic speech recognition (ASR) with federated learning (FL) makes it possible to leverage data from multiple clients without compromising privacy. The quality of FL-based ASR could be measured by recognition performance, communication and computation costs. When data among different clients are not independently and identically distributed (non-IID), the performance could degrade significantly. In this work, we tackle the non-IID issue in FL-based ASR with personalized FL, which learns personalized models for each client. Concretely, we propose two types of personalized FL approaches for ASR. Firstly, we adapt the personalization layer based FL for ASR, which keeps some layers locally to learn personalization models. Secondly, to reduce the communication and computation costs, we propose decoupled federated learning (DecoupleFL). On one hand, DecoupleFL moves the computation burden to the server, thus decreasing the computation on clients. On the other hand, DecoupleFL communicates secure high-level features instead of model parameters, thus reducing communication cost when models are large. Experiments demonstrate two proposed personalized FL-based ASR approaches could reduce WER by 2.3% - 3.4% compared with FedAvg. Among them, DecoupleFL has only 11.4% communication and 75% computation cost compared with FedAvg, which is also significantly less than the personalization layer based FL.
Deep Neural Mel-Subband Beamformer for In-car Speech Separation
Nov 22, 2022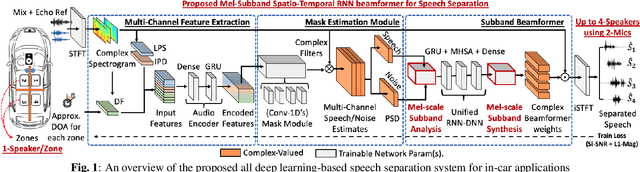
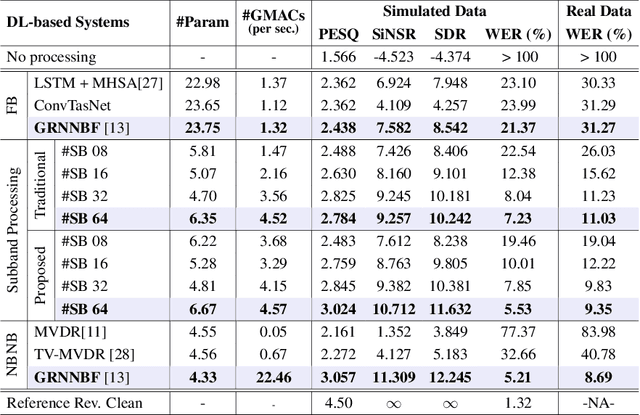
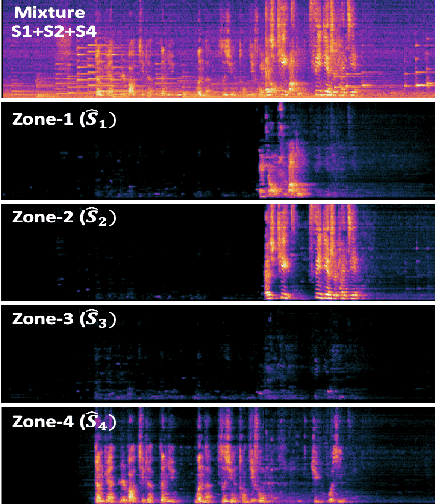
While current deep learning (DL)-based beamforming techniques have been proved effective in speech separation, they are often designed to process narrow-band (NB) frequencies independently which results in higher computational costs and inference times, making them unsuitable for real-world use. In this paper, we propose DL-based mel-subband spatio-temporal beamformer to perform speech separation in a car environment with reduced computation cost and inference time. As opposed to conventional subband (SB) approaches, our framework uses a mel-scale based subband selection strategy which ensures a fine-grained processing for lower frequencies where most speech formant structure is present, and coarse-grained processing for higher frequencies. In a recursive way, robust frame-level beamforming weights are determined for each speaker location/zone in a car from the estimated subband speech and noise covariance matrices. Furthermore, proposed framework also estimates and suppresses any echoes from the loudspeaker(s) by using the echo reference signals. We compare the performance of our proposed framework to several NB, SB, and full-band (FB) processing techniques in terms of speech quality and recognition metrics. Based on experimental evaluations on simulated and real-world recordings, we find that our proposed framework achieves better separation performance over all SB and FB approaches and achieves performance closer to NB processing techniques while requiring lower computing cost.
Clinical Dialogue Transcription Error Correction using Seq2Seq Models
May 26, 2022
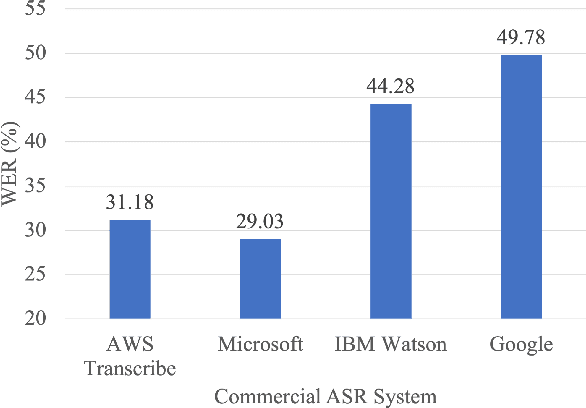
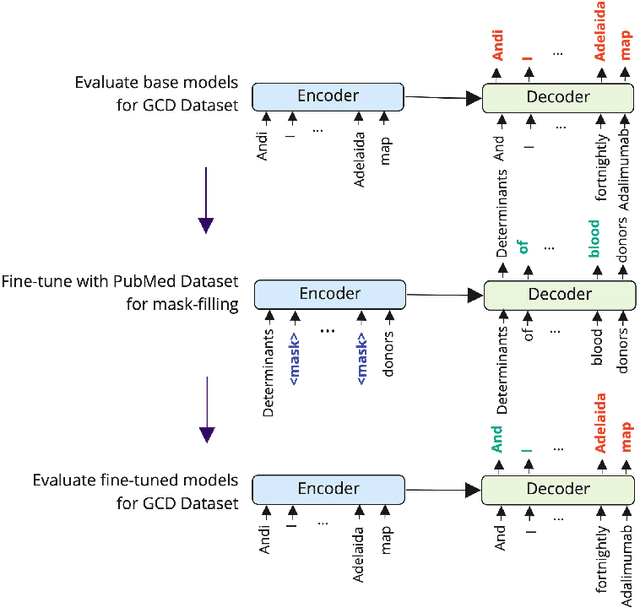

Good communication is critical to good healthcare. Clinical dialogue is a conversation between health practitioners and their patients, with the explicit goal of obtaining and sharing medical information. This information contributes to medical decision-making regarding the patient and plays a crucial role in their healthcare journey. The reliance on note taking and manual scribing processes are extremely inefficient and leads to manual transcription errors when digitizing notes. Automatic Speech Recognition (ASR) plays a significant role in speech-to-text applications, and can be directly used as a text generator in conversational applications. However, recording clinical dialogue presents a number of general and domain-specific challenges. In this paper, we present a seq2seq learning approach for ASR transcription error correction of clinical dialogues. We introduce a new Gastrointestinal Clinical Dialogue (GCD) Dataset which was gathered by healthcare professionals from a NHS Inflammatory Bowel Disease clinic and use this in a comparative study with four commercial ASR systems. Using self-supervision strategies, we fine-tune a seq2seq model on a mask-filling task using a domain-specific PubMed dataset which we have shared publicly for future research. The BART model fine-tuned for mask-filling was able to correct transcription errors and achieve lower word error rates for three out of four commercial ASR outputs.