 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Fixed-MAML for Few Shot Classification in Multilingual Speech Emotion Recognition
Jan 05, 2021
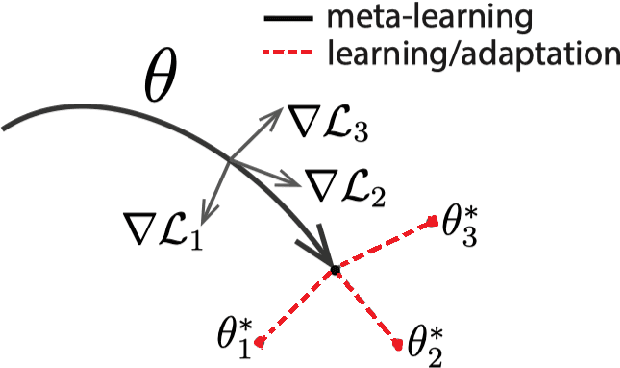
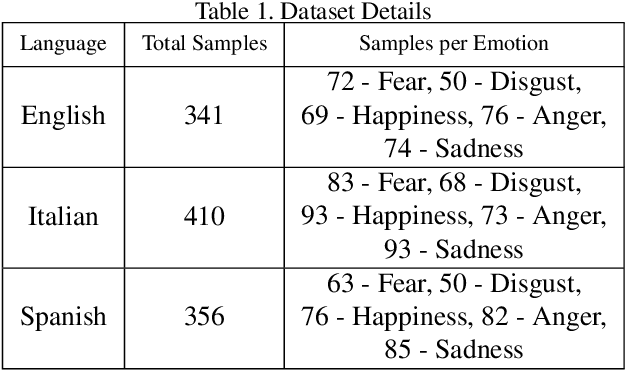
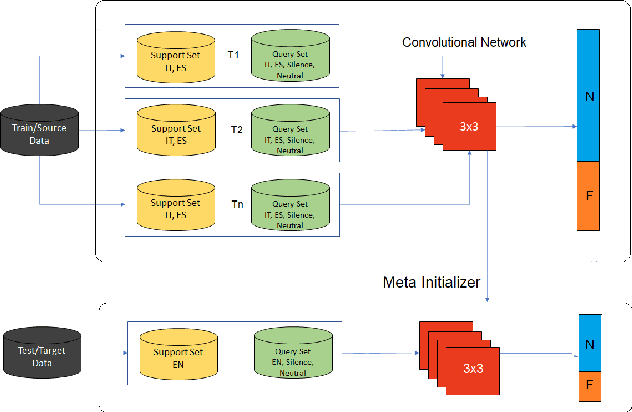

In this paper, we analyze the feasibility of applying few-shot learning to speech emotion recognition task (SER). The current speech emotion recognition models work exceptionally well but fail when then input is multilingual. Moreover, when training such models, the models' performance is suitable only when the training corpus is vast. This availability of a big training corpus is a significant problem when choosing a language that is not much popular or obscure. We attempt to solve this challenge of multilingualism and lack of available data by turning this problem into a few-shot learning problem. We suggest relaxing the assumption that all N classes in an N-way K-shot problem be new and define an N+F way problem where N and F are the number of emotion classes and predefined fixed classes, respectively. We propose this modification to the Model-Agnostic MetaLearning (MAML) algorithm to solve the problem and call this new model F-MAML. This modification performs better than the original MAML and outperforms on EmoFilm dataset.
Does Speech enhancement of publicly available data help build robust Speech Recognition Systems?
Oct 29, 2019
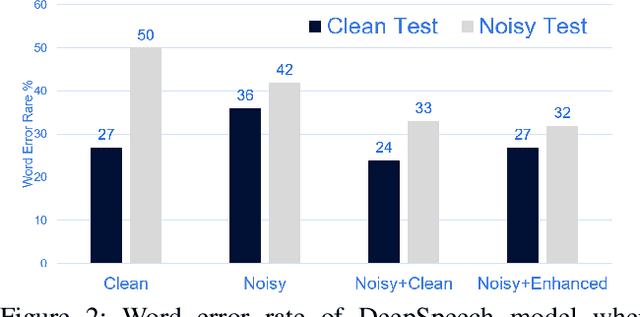
Automatic speech recognition (ASR) systems play a key role in many commercial products including voice assistants. Typically, they require large amounts of clean speech data for training which gives an undue advantage to large organizations which have tons of private data. In this paper, we have first curated a fairly big dataset using publicly available data sources. Thereafter, we tried to investigate if we can use publicly available noisy data to train robust ASR systems. We have used speech enhancement to clean the noisy data first and then used it together with its cleaned version to train ASR systems. We have found that using speech enhancement gives 9.5\% better word error rate than training on just noisy data and 9\% better than training on just clean data. It's performance is also comparable to the ideal case scenario when trained on noisy and its clean version.
Improving sequence-to-sequence speech recognition training with on-the-fly data augmentation
Oct 29, 2019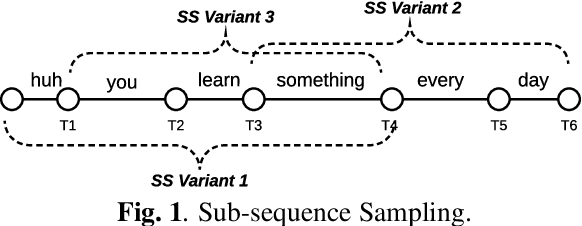
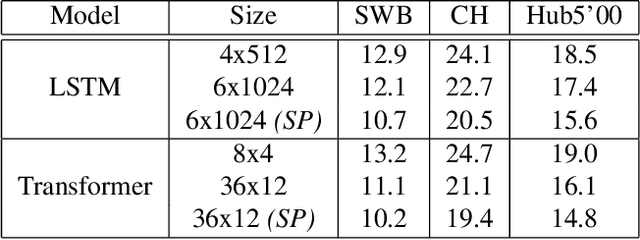
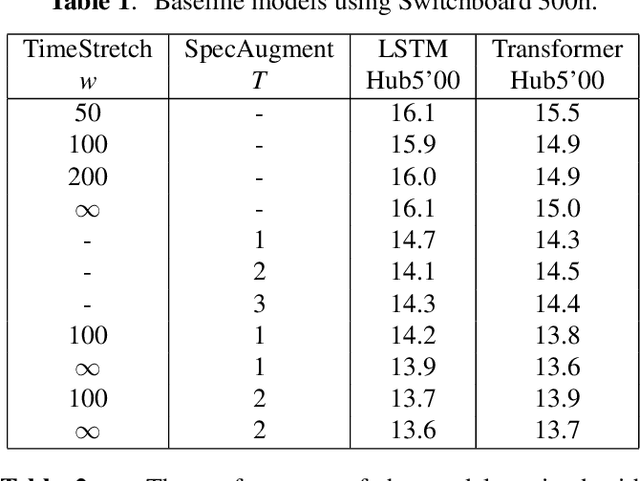
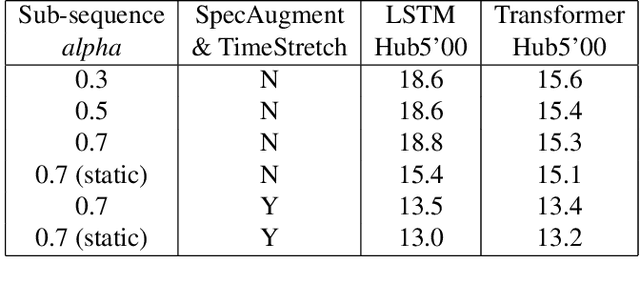
Sequence-to-Sequence (S2S) models recently started to show state-of-the-art performance for automatic speech recognition (ASR). With these large and deep models overfitting remains the largest problem, outweighing performance improvements that can be obtained from better architectures. One solution to the overfitting problem is increasing the amount of available training data and the variety exhibited by the training data with the help of data augmentation. In this paper we examine the influence of three data augmentation methods on the performance of two S2S model architectures. One of the data augmentation method comes from literature, while two other methods are our own development - a time perturbation in the frequency domain and sub-sequence sampling. Our experiments on Switchboard and Fisher data show state-of-the-art performance for S2S models that are trained solely on the speech training data and do not use additional text data.
Parallel Composition of Weighted Finite-State Transducers
Oct 06, 2021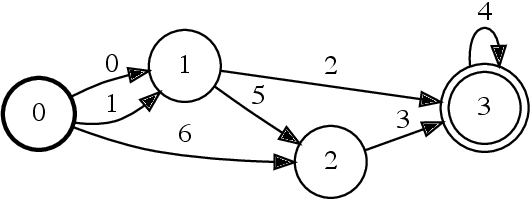
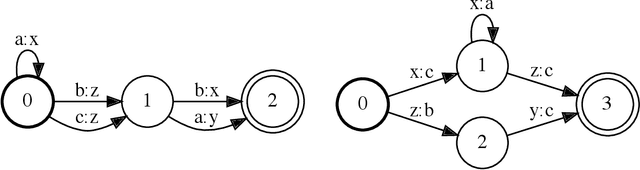
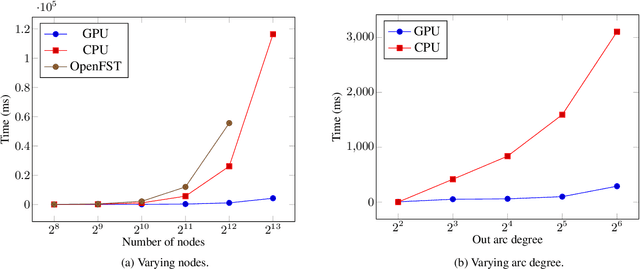
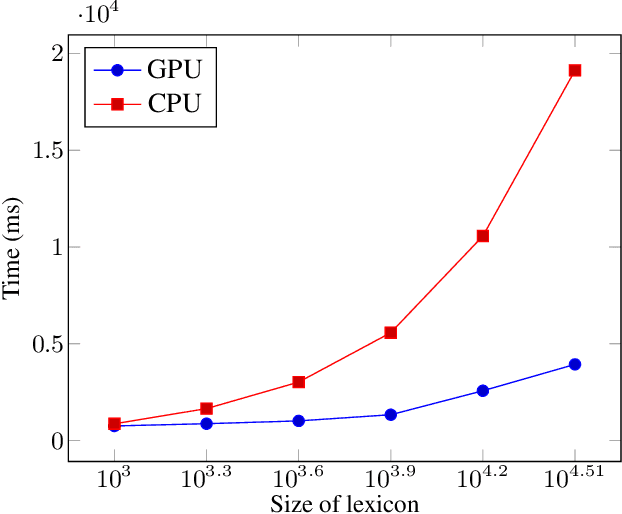
Finite-state transducers (FSTs) are frequently used in speech recognition. Transducer composition is an essential operation for combining different sources of information at different granularities. However, composition is also one of the more computationally expensive operations. Due to the heterogeneous structure of FSTs, parallel algorithms for composition are suboptimal in efficiency, generality, or both. We propose an algorithm for parallel composition and implement it on graphics processing units. We benchmark our parallel algorithm on the composition of random graphs and the composition of graphs commonly used in speech recognition. The parallel composition scales better with the size of the input graphs and for large graphs can be as much as 10 to 30 times faster than a sequential CPU algorithm.
Dawn of the transformer era in speech emotion recognition: closing the valence gap
Mar 16, 2022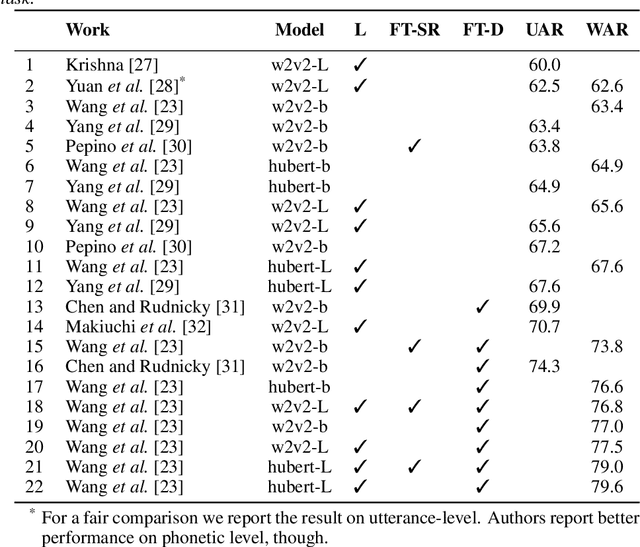
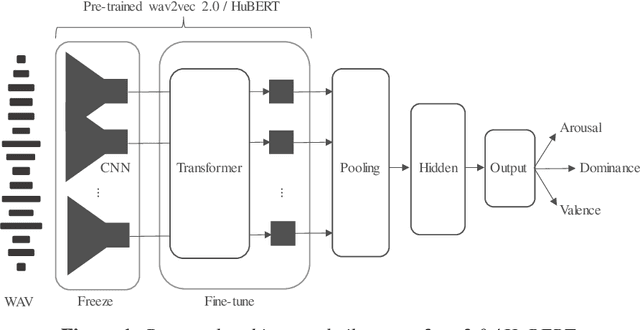
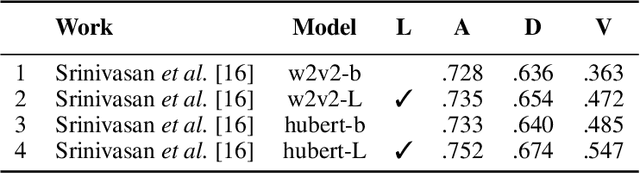
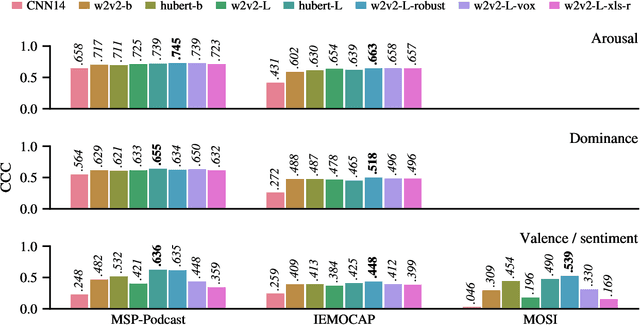
Recent advances in transformer-based architectures which are pre-trained in self-supervised manner have shown great promise in several machine learning tasks. In the audio domain, such architectures have also been successfully utilised in the field of speech emotion recognition (SER). However, existing works have not evaluated the influence of model size and pre-training data on downstream performance, and have shown limited attention to generalisation, robustness, fairness, and efficiency. The present contribution conducts a thorough analysis of these aspects on several pre-trained variants of wav2vec 2.0 and HuBERT that we fine-tuned on the dimensions arousal, dominance, and valence of MSP-Podcast, while additionally using IEMOCAP and MOSI to test cross-corpus generalisation. To the best of our knowledge, we obtain the top performance for valence prediction without use of explicit linguistic information, with a concordance correlation coefficient (CCC) of .638 on MSP-Podcast. Furthermore, our investigations reveal that transformer-based architectures are more robust to small perturbations compared to a CNN-based baseline and fair with respect to biological sex groups, but not towards individual speakers. Finally, we are the first to show that their extraordinary success on valence is based on implicit linguistic information learnt during fine-tuning of the transformer layers, which explains why they perform on-par with recent multimodal approaches that explicitly utilise textual information. Our findings collectively paint the following picture: transformer-based architectures constitute the new state-of-the-art in SER, but further advances are needed to mitigate remaining robustness and individual speaker issues. To make our findings reproducible, we release the best performing model to the community.
Visual Speech Recognition Using PCA Networks and LSTMs in a Tandem GMM-HMM System
Oct 19, 2017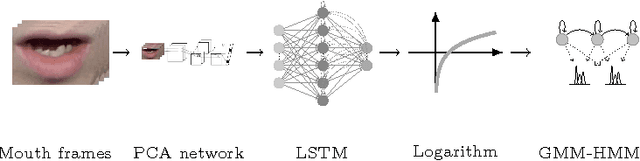
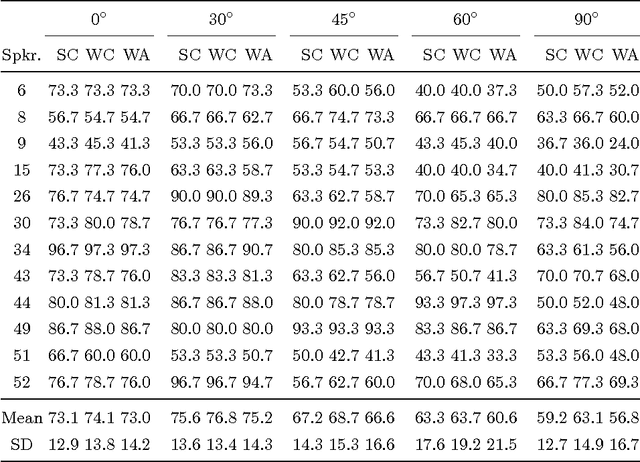
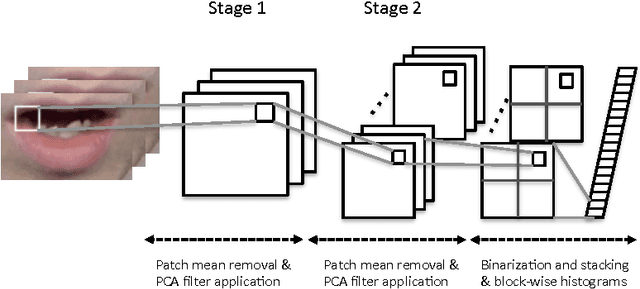
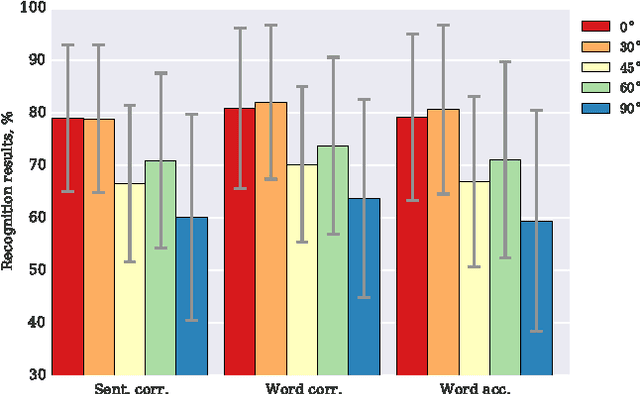
Automatic visual speech recognition is an interesting problem in pattern recognition especially when audio data is noisy or not readily available. It is also a very challenging task mainly because of the lower amount of information in the visual articulations compared to the audible utterance. In this work, principle component analysis is applied to the image patches - extracted from the video data - to learn the weights of a two-stage convolutional network. Block histograms are then extracted as the unsupervised learning features. These features are employed to learn a recurrent neural network with a set of long short-term memory cells to obtain spatiotemporal features. Finally, the obtained features are used in a tandem GMM-HMM system for speech recognition. Our results show that the proposed method has outperformed the baseline techniques applied to the OuluVS2 audiovisual database for phrase recognition with the frontal view cross-validation and testing sentence correctness reaching 79% and 73%, respectively, as compared to the baseline of 74% on cross-validation.
Imperceptible, Robust, and Targeted Adversarial Examples for Automatic Speech Recognition
Mar 22, 2019
Adversarial examples are inputs to machine learning models designed by an adversary to cause an incorrect output. So far, adversarial examples have been studied most extensively in the image domain. In this domain, adversarial examples can be constructed by imperceptibly modifying images to cause misclassification, and are practical in the physical world. In contrast, current targeted adversarial examples applied to speech recognition systems have neither of these properties: humans can easily identify the adversarial perturbations, and they are not effective when played over-the-air. This paper makes advances on both of these fronts. First, we develop effectively imperceptible audio adversarial examples (verified through a human study) by leveraging the psychoacoustic principle of auditory masking, while retaining 100% targeted success rate on arbitrary full-sentence targets. Next, we make progress towards physical-world over-the-air audio adversarial examples by constructing perturbations which remain effective even after applying realistic simulated environmental distortions.
SpeechMoE2: Mixture-of-Experts Model with Improved Routing
Nov 23, 2021
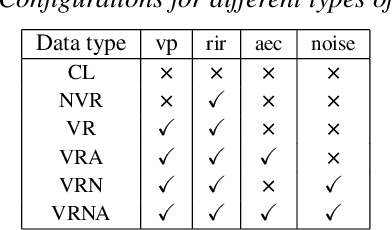
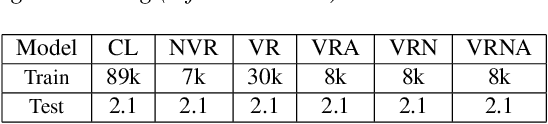
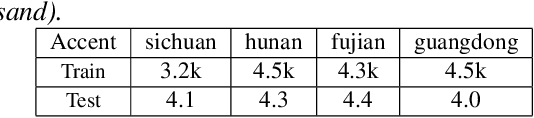
Mixture-of-experts based acoustic models with dynamic routing mechanisms have proved promising results for speech recognition. The design principle of router architecture is important for the large model capacity and high computational efficiency. Our previous work SpeechMoE only uses local grapheme embedding to help routers to make route decisions. To further improve speech recognition performance against varying domains and accents, we propose a new router architecture which integrates additional global domain and accent embedding into router input to promote adaptability. Experimental results show that the proposed SpeechMoE2 can achieve lower character error rate (CER) with comparable parameters than SpeechMoE on both multi-domain and multi-accent task. Primarily, the proposed method provides up to 1.6% - 4.8% relative CER improvement for the multidomain task and 1.9% - 17.7% relative CER improvement for the multi-accent task respectively. Besides, increasing the number of experts also achieves consistent performance improvement and keeps the computational cost constant.
Privacy against Real-Time Speech Emotion Detection via Acoustic Adversarial Evasion of Machine Learning
Nov 17, 2022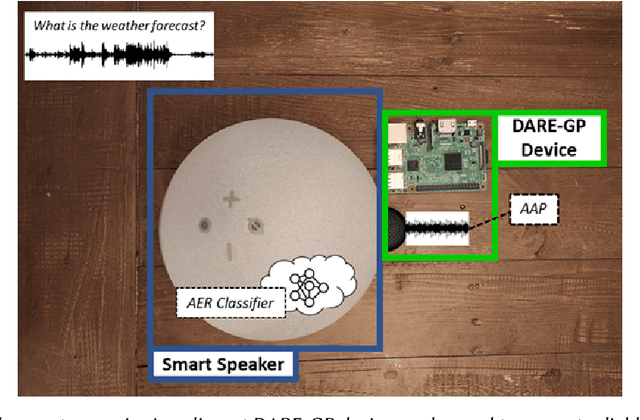
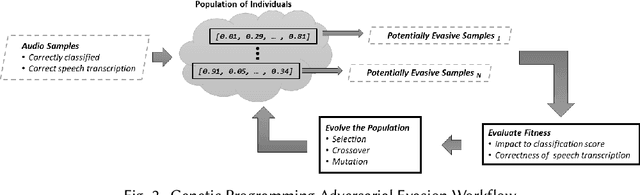

Emotional Surveillance is an emerging area with wide-reaching privacy concerns. These concerns are exacerbated by ubiquitous IoT devices with multiple sensors that can support these surveillance use cases. The work presented here considers one such use case: the use of a speech emotion recognition (SER) classifier tied to a smart speaker. This work demonstrates the ability to evade black-box SER classifiers tied to a smart speaker without compromising the utility of the smart speaker. This privacy concern is considered through the lens of adversarial evasion of machine learning. Our solution, Defeating Acoustic Recognition of Emotion via Genetic Programming (DARE-GP), uses genetic programming to generate non-invasive additive audio perturbations (AAPs). By constraining the evolution of these AAPs, transcription accuracy can be protected while simultaneously degrading SER classifier performance. The additive nature of these AAPs, along with an approach that generates these AAPs for a fixed set of users in an utterance and user location-independent manner, supports real-time, real-world evasion of SER classifiers. DARE-GP's use of spectral features, which underlay the emotional content of speech, allows the transferability of AAPs to previously unseen black-box SER classifiers. Further, DARE-GP outperforms state-of-the-art SER evasion techniques and is robust against defenses employed by a knowledgeable adversary. The evaluations in this work culminate with acoustic evaluations against two off-the-shelf commercial smart speakers, where a single AAP could evade a black box classifier over 70% of the time. The final evaluation deployed AAP playback on a small-form-factor system (raspberry pi) integrated with a wake-word system to evaluate the efficacy of a real-world, real-time deployment where DARE-GP is automatically invoked with the smart speaker's wake word.
Automatic Spoken Language Identification using a Time-Delay Neural Network
May 19, 2022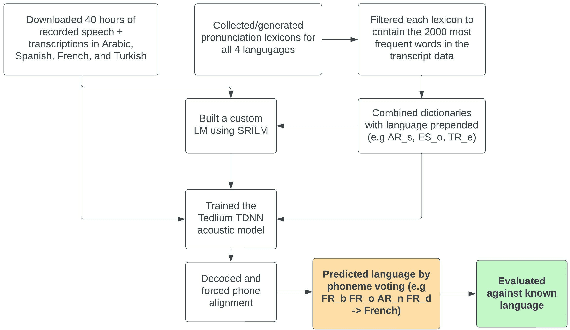



Closed-set spoken language identification is the task of recognizing the language being spoken in a recorded audio clip from a set of known languages. In this study, a language identification system was built and trained to distinguish between Arabic, Spanish, French, and Turkish based on nothing more than recorded speech. A pre-existing multilingual dataset was used to train a series of acoustic models based on the Tedlium TDNN model to perform automatic speech recognition. The system was provided with a custom multilingual language model and a specialized pronunciation lexicon with language names prepended to phones. The trained model was used to generate phone alignments to test data from all four languages, and languages were predicted based on a voting scheme choosing the most common language prepend in an utterance. Accuracy was measured by comparing predicted languages to known languages, and was determined to be very high in identifying Spanish and Arabic, and somewhat lower in identifying Turkish and French.