 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Two-Pass Low Latency End-to-End Spoken Language Understanding
Jul 14, 2022
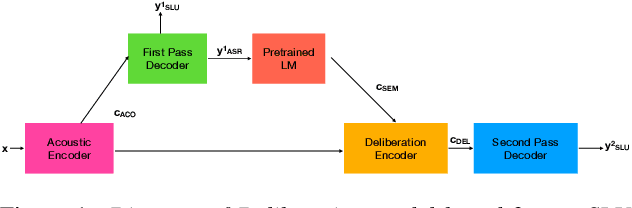
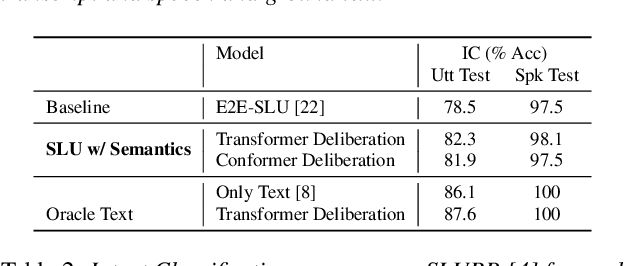

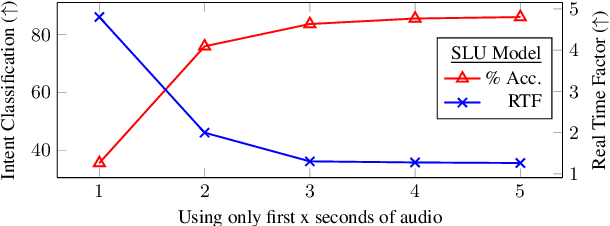
End-to-end (E2E) models are becoming increasingly popular for spoken language understanding (SLU) systems and are beginning to achieve competitive performance to pipeline-based approaches. However, recent work has shown that these models struggle to generalize to new phrasings for the same intent indicating that models cannot understand the semantic content of the given utterance. In this work, we incorporated language models pre-trained on unlabeled text data inside E2E-SLU frameworks to build strong semantic representations. Incorporating both semantic and acoustic information can increase the inference time, leading to high latency when deployed for applications like voice assistants. We developed a 2-pass SLU system that makes low latency prediction using acoustic information from the few seconds of the audio in the first pass and makes higher quality prediction in the second pass by combining semantic and acoustic representations. We take inspiration from prior work on 2-pass end-to-end speech recognition systems that attends on both audio and first-pass hypothesis using a deliberation network. The proposed 2-pass SLU system outperforms the acoustic-based SLU model on the Fluent Speech Commands Challenge Set and SLURP dataset and reduces latency, thus improving user experience. Our code and models are publicly available as part of the ESPnet-SLU toolkit.
Low-Dimensional Bottleneck Features for On-Device Continuous Speech Recognition
Oct 31, 2018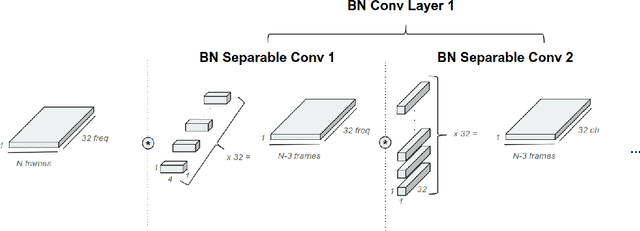

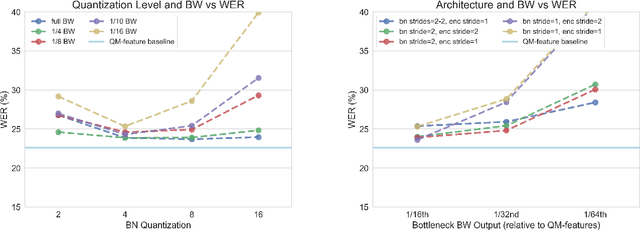
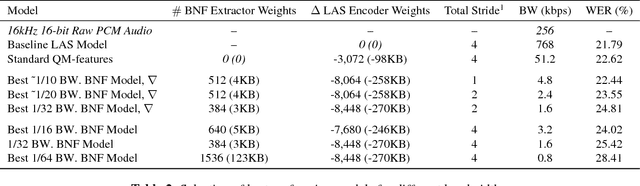
Low power digital signal processors (DSPs) typically have a very limited amount of memory in which to cache data. In this paper we develop efficient bottleneck feature (BNF) extractors that can be run on a DSP, and retrain a baseline large-vocabulary continuous speech recognition (LVCSR) system to use these BNFs with only a minimal loss of accuracy. The small BNFs allow the DSP chip to cache more audio features while the main application processor is suspended, thereby reducing the overall battery usage. Our presented system is able to reduce the footprint of standard, fixed point DSP spectral features by a factor of 10 without any loss in word error rate (WER) and by a factor of 64 with only a 5.8% relative increase in WER.
Efficient Segmental Cascades for Speech Recognition
Aug 02, 2016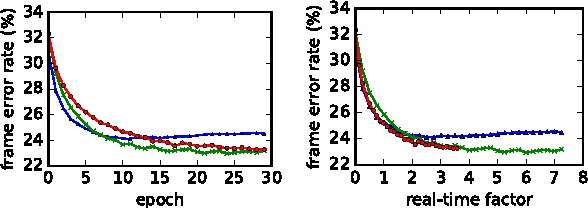

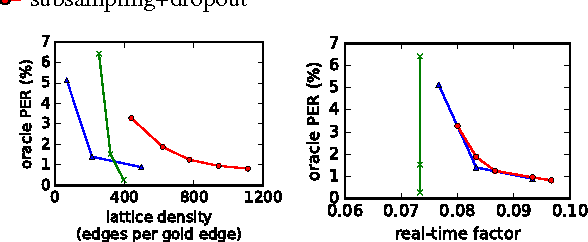

Discriminative segmental models offer a way to incorporate flexible feature functions into speech recognition. However, their appeal has been limited by their computational requirements, due to the large number of possible segments to consider. Multi-pass cascades of segmental models introduce features of increasing complexity in different passes, where in each pass a segmental model rescores lattices produced by a previous (simpler) segmental model. In this paper, we explore several ways of making segmental cascades efficient and practical: reducing the feature set in the first pass, frame subsampling, and various pruning approaches. In experiments on phonetic recognition, we find that with a combination of such techniques, it is possible to maintain competitive performance while greatly reducing decoding, pruning, and training time.
SoundSpaces 2.0: A Simulation Platform for Visual-Acoustic Learning
Jun 16, 2022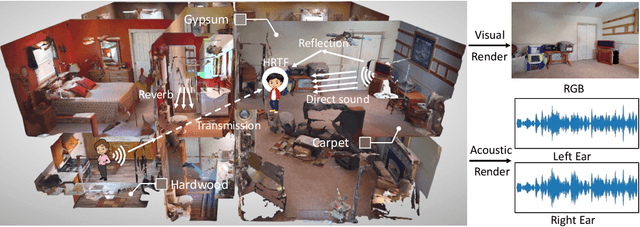
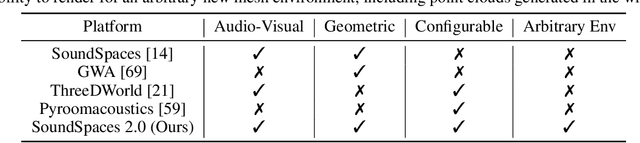

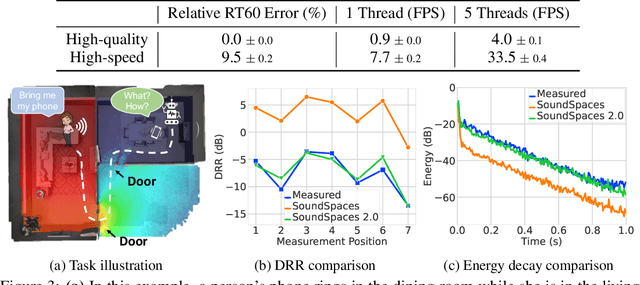
We introduce SoundSpaces 2.0, a platform for on-the-fly geometry-based audio rendering for 3D environments. Given a 3D mesh of a real-world environment, SoundSpaces can generate highly realistic acoustics for arbitrary sounds captured from arbitrary microphone locations. Together with existing 3D visual assets, it supports an array of audio-visual research tasks, such as audio-visual navigation, mapping, source localization and separation, and acoustic matching. Compared to existing resources, SoundSpaces 2.0 has the advantages of allowing continuous spatial sampling, generalization to novel environments, and configurable microphone and material properties. To our best knowledge, this is the first geometry-based acoustic simulation that offers high fidelity and realism while also being fast enough to use for embodied learning. We showcase the simulator's properties and benchmark its performance against real-world audio measurements. In addition, through two downstream tasks covering embodied navigation and far-field automatic speech recognition, highlighting sim2real performance for the latter. SoundSpaces 2.0 is publicly available to facilitate wider research for perceptual systems that can both see and hear.
Improving noise robust automatic speech recognition with single-channel time-domain enhancement network
Mar 09, 2020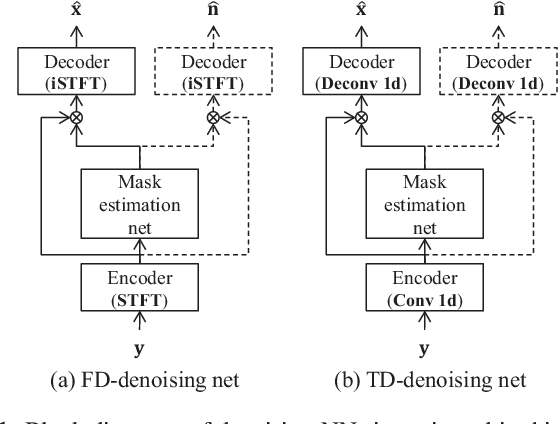
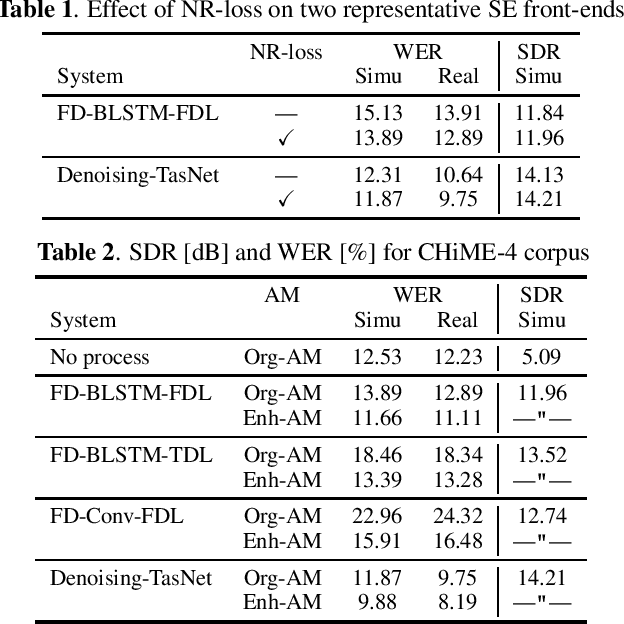
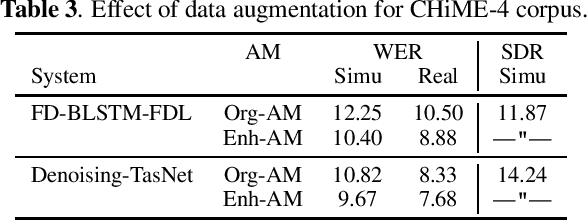

With the advent of deep learning, research on noise-robust automatic speech recognition (ASR) has progressed rapidly. However, ASR performance in noisy conditions of single-channel systems remains unsatisfactory. Indeed, most single-channel speech enhancement (SE) methods (denoising) have brought only limited performance gains over state-of-the-art ASR back-end trained on multi-condition training data. Recently, there has been much research on neural network-based SE methods working in the time-domain showing levels of performance never attained before. However, it has not been established whether the high enhancement performance achieved by such time-domain approaches could be translated into ASR. In this paper, we show that a single-channel time-domain denoising approach can significantly improve ASR performance, providing more than 30 % relative word error reduction over a strong ASR back-end on the real evaluation data of the single-channel track of the CHiME-4 dataset. These positive results demonstrate that single-channel noise reduction can still improve ASR performance, which should open the door to more research in that direction.
Auxiliary Interference Speaker Loss for Target-Speaker Speech Recognition
Jun 26, 2019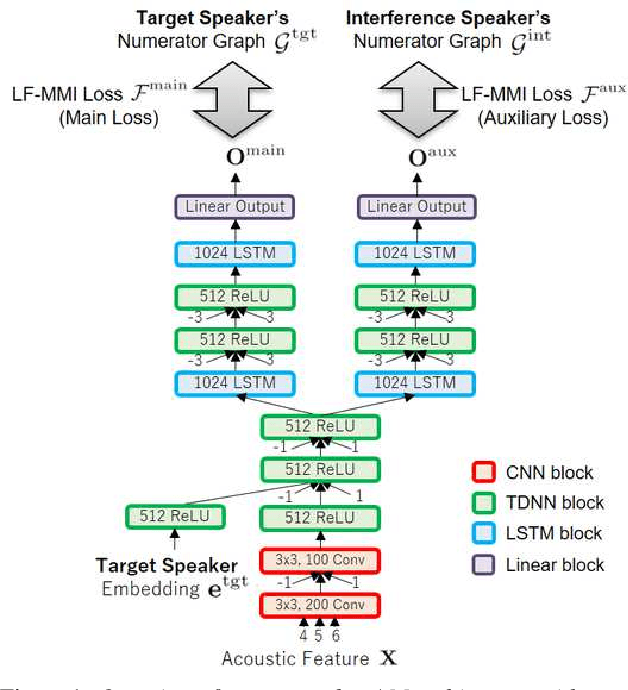

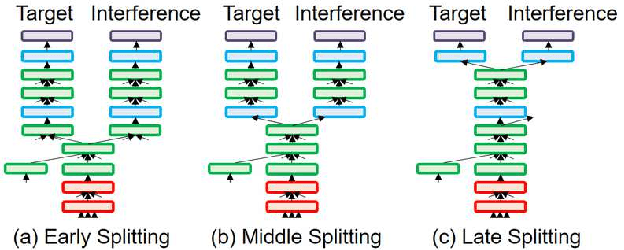
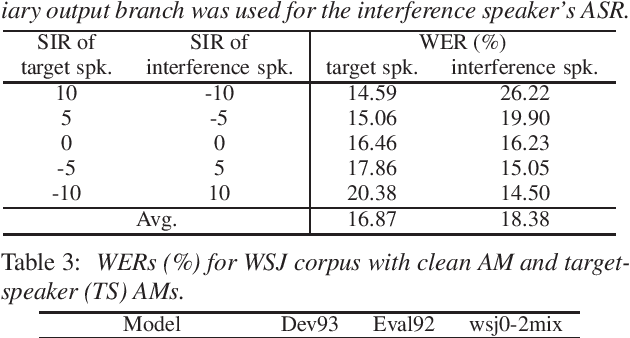
In this paper, we propose a novel auxiliary loss function for target-speaker automatic speech recognition (ASR). Our method automatically extracts and transcribes target speaker's utterances from a monaural mixture of multiple speakers speech given a short sample of the target speaker. The proposed auxiliary loss function attempts to additionally maximize interference speaker ASR accuracy during training. This will regularize the network to achieve a better representation for speaker separation, thus achieving better accuracy on the target-speaker ASR. We evaluated our proposed method using two-speaker-mixed speech in various signal-to-interference-ratio conditions. We first built a strong target-speaker ASR baseline based on the state-of-the-art lattice-free maximum mutual information. This baseline achieved a word error rate (WER) of 18.06% on the test set while a normal ASR trained with clean data produced a completely corrupted result (WER of 84.71%). Then, our proposed loss further reduced the WER by 6.6% relative to this strong baseline, achieving a WER of 16.87%. In addition to the accuracy improvement, we also showed that the auxiliary output branch for the proposed loss can even be used for a secondary ASR for interference speakers' speech.
Fast and Accurate Recurrent Neural Network Acoustic Models for Speech Recognition
Jul 24, 2015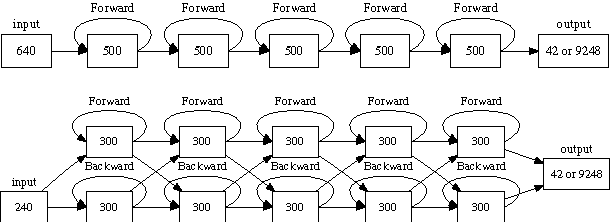
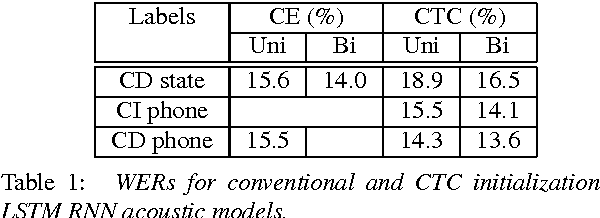
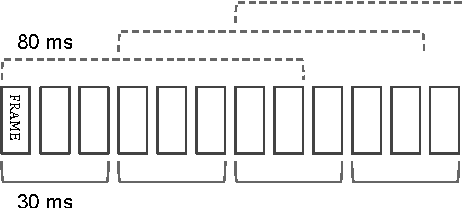
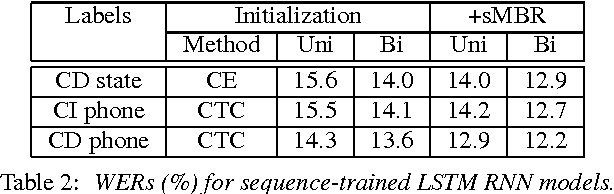
We have recently shown that deep Long Short-Term Memory (LSTM) recurrent neural networks (RNNs) outperform feed forward deep neural networks (DNNs) as acoustic models for speech recognition. More recently, we have shown that the performance of sequence trained context dependent (CD) hidden Markov model (HMM) acoustic models using such LSTM RNNs can be equaled by sequence trained phone models initialized with connectionist temporal classification (CTC). In this paper, we present techniques that further improve performance of LSTM RNN acoustic models for large vocabulary speech recognition. We show that frame stacking and reduced frame rate lead to more accurate models and faster decoding. CD phone modeling leads to further improvements. We also present initial results for LSTM RNN models outputting words directly.
Analyzing Utility of Visual Context in Multimodal Speech Recognition Under Noisy Conditions
Jun 30, 2019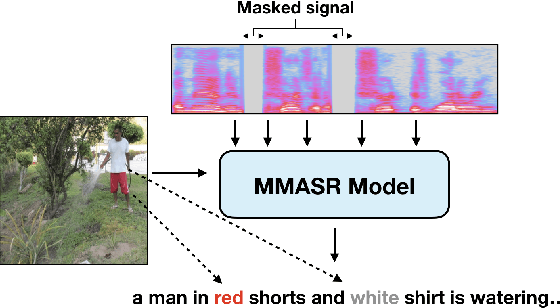

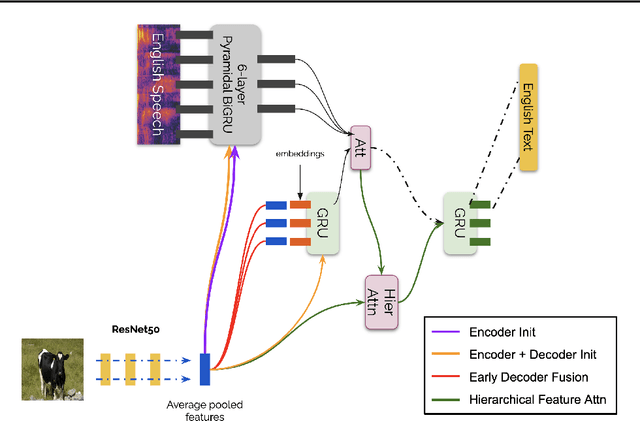
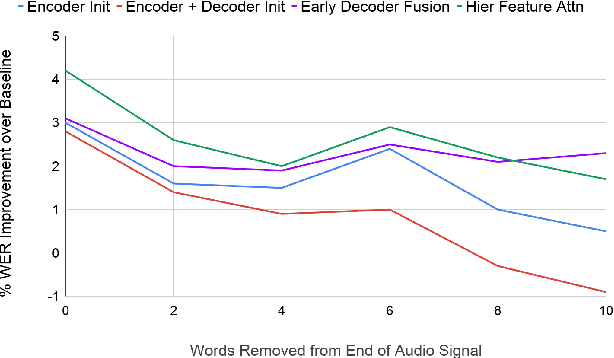
Multimodal learning allows us to leverage information from multiple sources (visual, acoustic and text), similar to our experience of the real world. However, it is currently unclear to what extent auxiliary modalities improve performance over unimodal models, and under what circumstances the auxiliary modalities are useful. We examine the utility of the auxiliary visual context in Multimodal Automatic Speech Recognition in adversarial settings, where we deprive the models from partial audio signal during inference time. Our experiments show that while MMASR models show significant gains over traditional speech-to-text architectures (upto 4.2% WER improvements), they do not incorporate visual information when the audio signal has been corrupted. This shows that current methods of integrating the visual modality do not improve model robustness to noise, and we need better visually grounded adaptation techniques.
Low-resource Accent Classification in Geographically-proximate Settings: A Forensic and Sociophonetics Perspective
Jun 29, 2022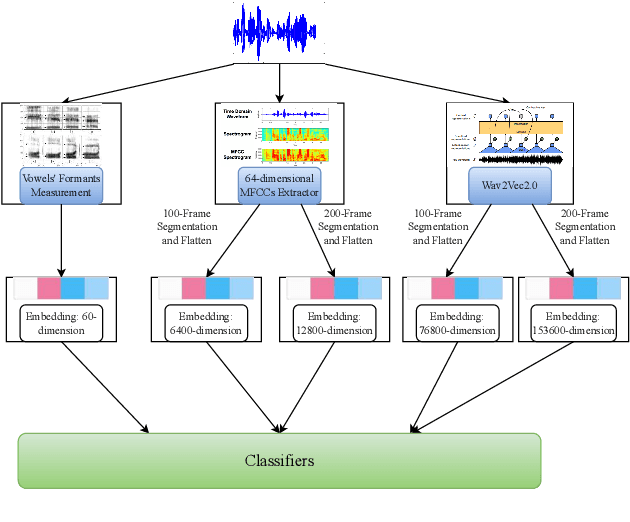
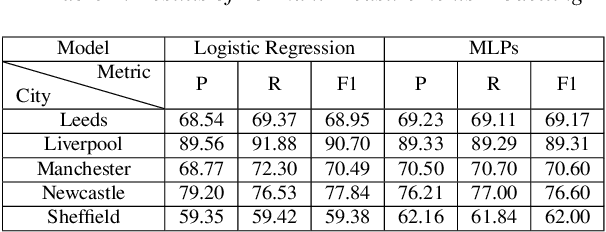

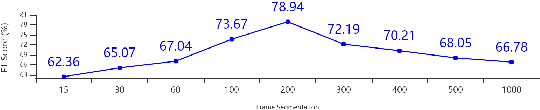
Accented speech recognition and accent classification are relatively under-explored research areas in speech technology. Recently, deep learning-based methods and Transformer-based pretrained models have achieved superb performances in both areas. However, most accent classification tasks focused on classifying different kinds of English accents and little attention was paid to geographically-proximate accent classification, especially under a low-resource setting where forensic speech science tasks usually encounter. In this paper, we explored three main accent modelling methods combined with two different classifiers based on 105 speaker recordings retrieved from five urban varieties in Northern England. Although speech representations generated from pretrained models generally have better performances in downstream classification, traditional methods like Mel Frequency Cepstral Coefficients (MFCCs) and formant measurements are equipped with specific strengths. These results suggest that in forensic phonetics scenario where data are relatively scarce, a simple modelling method and classifier could be competitive with state-of-the-art pretrained speech models as feature extractors, which could enhance a sooner estimation for the accent information in practices. Besides, our findings also cross-validated a new methodology in quantifying sociophonetic changes.
Speaker consistency loss and step-wise optimization for semi-supervised joint training of TTS and ASR using unpaired text data
Jul 11, 2022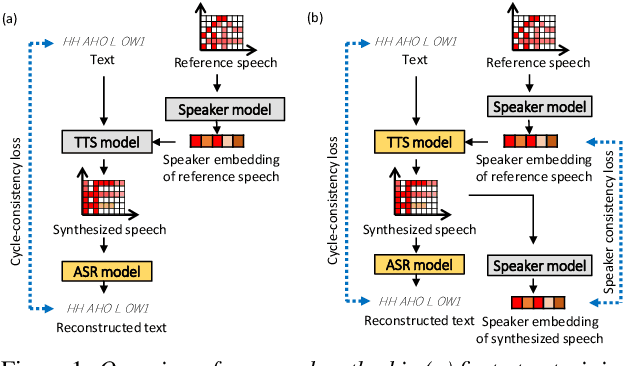
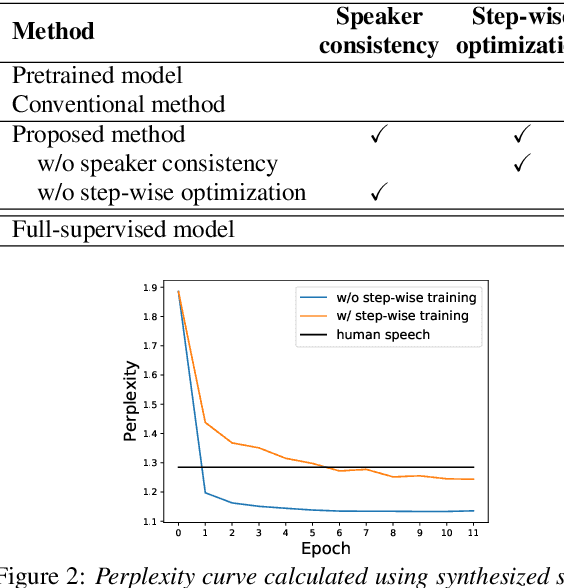
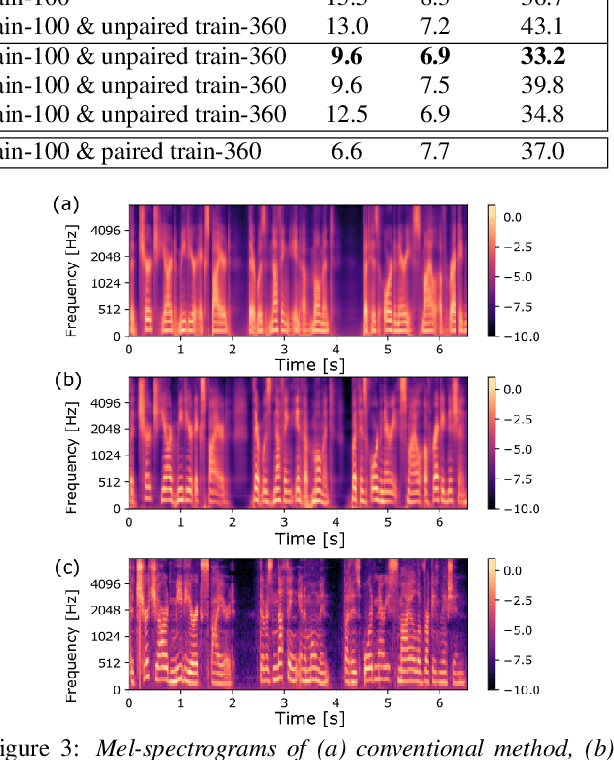
In this paper, we investigate the semi-supervised joint training of text to speech (TTS) and automatic speech recognition (ASR), where a small amount of paired data and a large amount of unpaired text data are available. Conventional studies form a cycle called the TTS-ASR pipeline, where the multispeaker TTS model synthesizes speech from text with a reference speech and the ASR model reconstructs the text from the synthesized speech, after which both models are trained with a cycle-consistency loss. However, the synthesized speech does not reflect the speaker characteristics of the reference speech and the synthesized speech becomes overly easy for the ASR model to recognize after training. This not only decreases the TTS model quality but also limits the ASR model improvement. To solve this problem, we propose improving the cycleconsistency-based training with a speaker consistency loss and step-wise optimization. The speaker consistency loss brings the speaker characteristics of the synthesized speech closer to that of the reference speech. In the step-wise optimization, we first freeze the parameter of the TTS model before both models are trained to avoid over-adaptation of the TTS model to the ASR model. Experimental results demonstrate the efficacy of the proposed method.