 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Improving End-to-end Speech Recognition with Pronunciation-assisted Sub-word Modeling
Nov 10, 2018
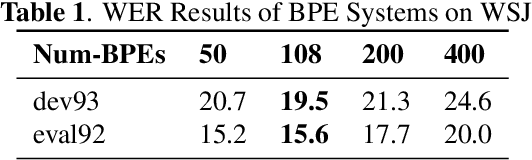
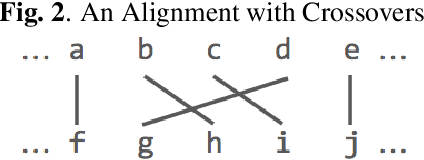

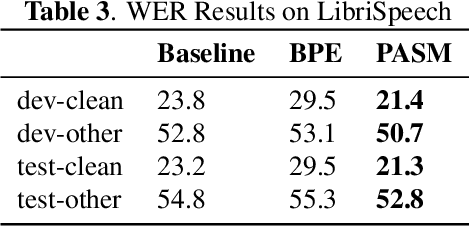
In recent years, end-to-end models have become popular for application in automatic speech recognition. Compared to hybrid approaches, which perform the phone-sequence to word conversion based on a lexicon, an end-to-end system models text directly, usually as a sequence of characters or sub-word features. We propose a sub-word modeling method that leverages the pronunciation information of a word. Experiments show that the proposed method can greatly improve upon the character-based baseline, and also outperform commonly used byte-pair encoding methods.
Reinforcement Learning of Speech Recognition System Based on Policy Gradient and Hypothesis Selection
Nov 10, 2017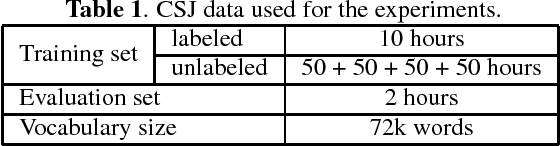
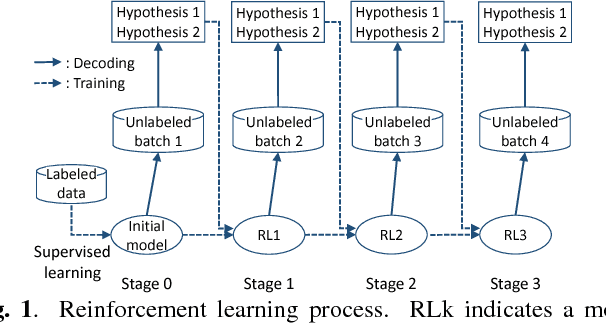
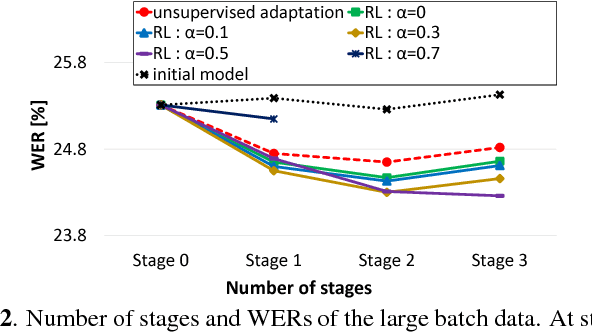
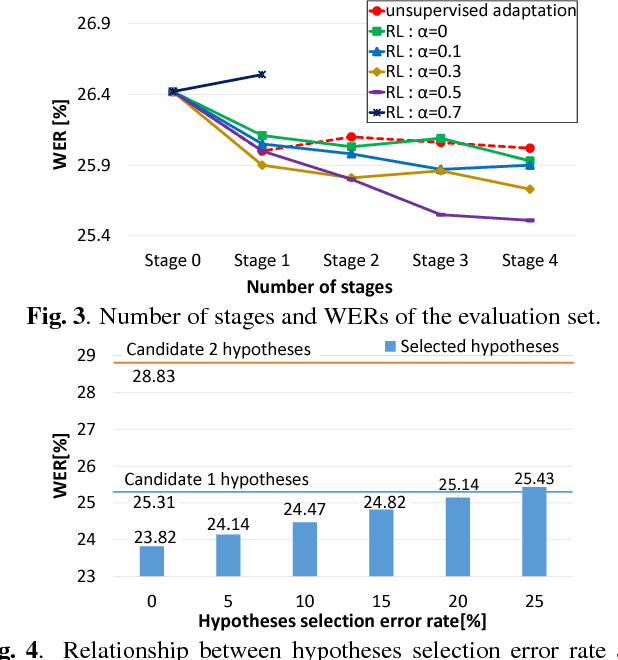
Speech recognition systems have achieved high recognition performance for several tasks. However, the performance of such systems is dependent on the tremendously costly development work of preparing vast amounts of task-matched transcribed speech data for supervised training. The key problem here is the cost of transcribing speech data. The cost is repeatedly required to support new languages and new tasks. Assuming broad network services for transcribing speech data for many users, a system would become more self-sufficient and more useful if it possessed the ability to learn from very light feedback from the users without annoying them. In this paper, we propose a general reinforcement learning framework for speech recognition systems based on the policy gradient method. As a particular instance of the framework, we also propose a hypothesis selection-based reinforcement learning method. The proposed framework provides a new view for several existing training and adaptation methods. The experimental results show that the proposed method improves the recognition performance compared to unsupervised adaptation.
STSC-SNN: Spatio-Temporal Synaptic Connection with Temporal Convolution and Attention for Spiking Neural Networks
Oct 11, 2022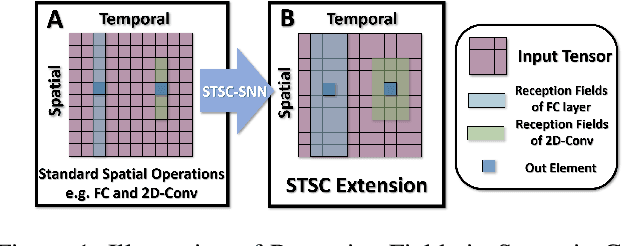
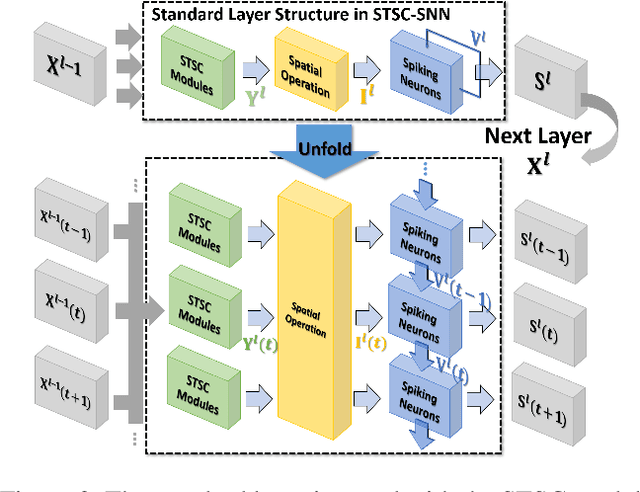
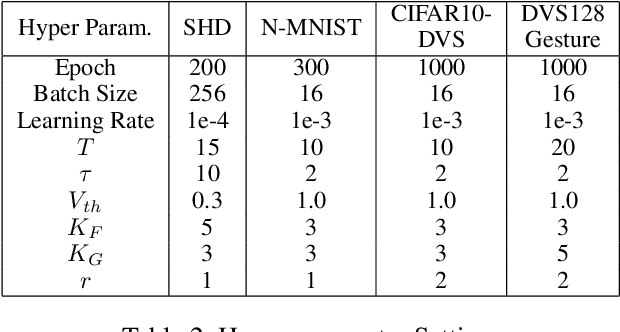
Spiking Neural Networks (SNNs), as one of the algorithmic models in neuromorphic computing, have gained a great deal of research attention owing to temporal information processing capability, low power consumption, and high biological plausibility. The potential to efficiently extract spatio-temporal features makes it suitable for processing the event streams. However, existing synaptic structures in SNNs are almost full-connections or spatial 2D convolution, neither of which can extract temporal dependencies adequately. In this work, we take inspiration from biological synapses and propose a spatio-temporal synaptic connection SNN (STSC-SNN) model, to enhance the spatio-temporal receptive fields of synaptic connections, thereby establishing temporal dependencies across layers. Concretely, we incorporate temporal convolution and attention mechanisms to implement synaptic filtering and gating functions. We show that endowing synaptic models with temporal dependencies can improve the performance of SNNs on classification tasks. In addition, we investigate the impact of performance vias varied spatial-temporal receptive fields and reevaluate the temporal modules in SNNs. Our approach is tested on neuromorphic datasets, including DVS128 Gesture (gesture recognition), N-MNIST, CIFAR10-DVS (image classification), and SHD (speech digit recognition). The results show that the proposed model outperforms the state-of-the-art accuracy on nearly all datasets.
A Novel Exploitative and Explorative GWO-SVM Algorithm for Smart Emotion Recognition
Jan 05, 2023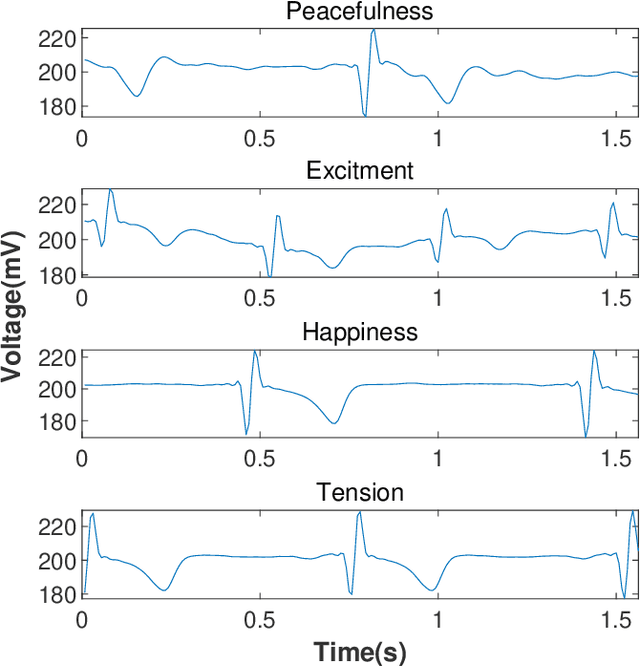
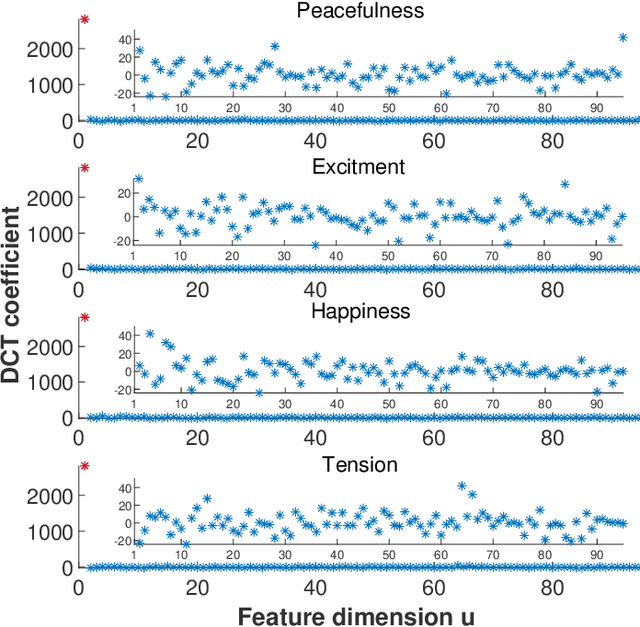
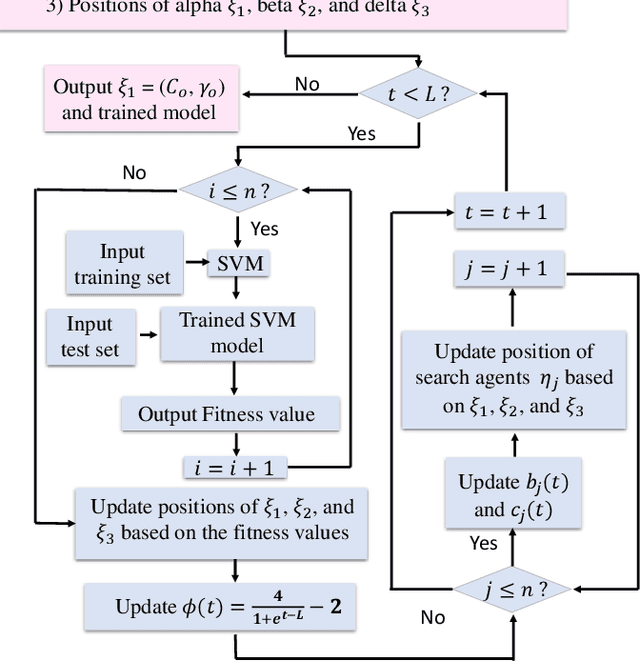
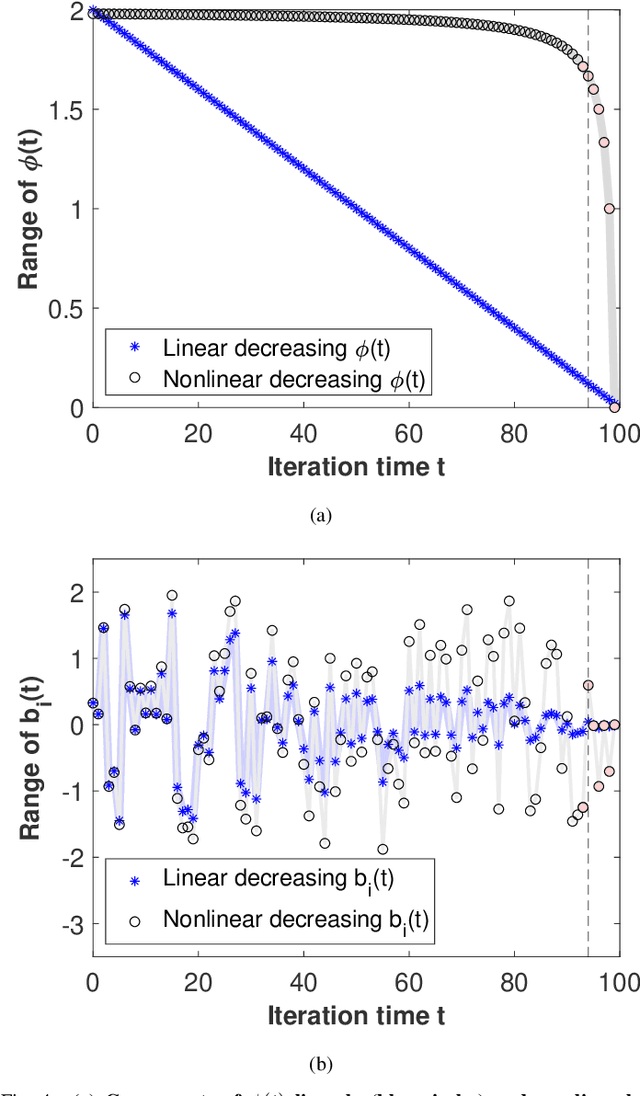
Emotion recognition or detection is broadly utilized in patient-doctor interactions for diseases such as schizophrenia and autism and the most typical techniques are speech detection and facial recognition. However, features extracted from these behavior-based emotion recognitions are not reliable since humans can disguise their emotions. Recording voices or tracking facial expressions for a long term is also not efficient. Therefore, our aim is to find a reliable and efficient emotion recognition scheme, which can be used for non-behavior-based emotion recognition in real-time. This can be solved by implementing a single-channel electrocardiogram (ECG) based emotion recognition scheme in a lightweight embedded system. However, existing schemes have relatively low accuracy. Therefore, we propose a reliable and efficient emotion recognition scheme - exploitative and explorative grey wolf optimizer based SVM (X - GWO - SVM) for ECG-based emotion recognition. Two datasets, one raw self-collected iRealcare dataset, and the widely-used benchmark WESAD dataset are used in the X - GWO - SVM algorithm for emotion recognition. This work demonstrates that the X - GWO - SVM algorithm can be used for emotion recognition and the algorithm exhibits superior performance in reliability compared to the use of other supervised machine learning methods in earlier works. It can be implemented in a lightweight embedded system, which is much more efficient than existing solutions based on deep neural networks.
Speech Emotion Recognition Based on Multi-feature and Multi-lingual Fusion
Jan 16, 2020
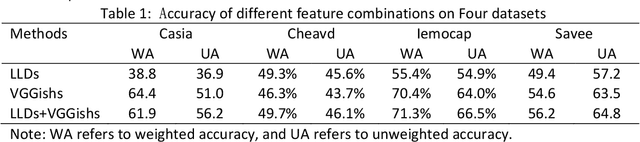
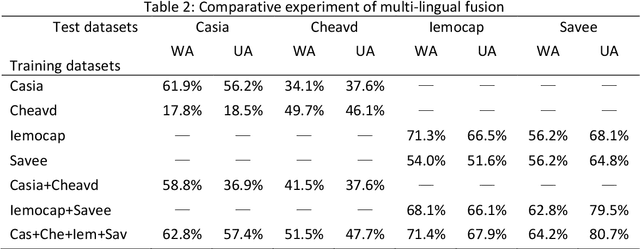
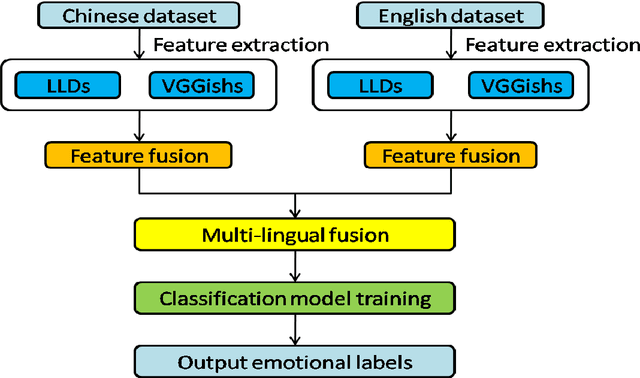
A speech emotion recognition algorithm based on multi-feature and Multi-lingual fusion is proposed in order to resolve low recognition accuracy caused by lack of large speech dataset and low robustness of acoustic features in the recognition of speech emotion. First, handcrafted and deep automatic features are extracted from existing data in Chinese and English speech emotions. Then, the various features are fused respectively. Finally, the fused features of different languages are fused again and trained in a classification model. Distinguishing the fused features with the unfused ones, the results manifest that the fused features significantly enhance the accuracy of speech emotion recognition algorithm. The proposed solution is evaluated on the two Chinese corpus and two English corpus, and is shown to provide more accurate predictions compared to original solution. As a result of this study, the multi-feature and Multi-lingual fusion algorithm can significantly improve the speech emotion recognition accuracy when the dataset is small.
Improving Streaming End-to-End ASR on Transformer-based Causal Models with Encoder States Revision Strategies
Jul 06, 2022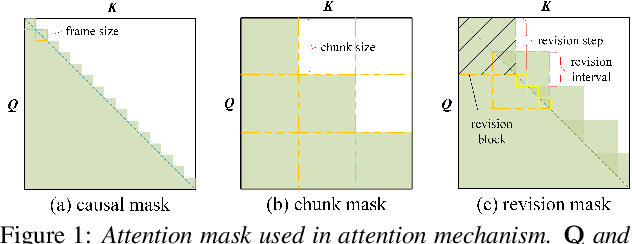
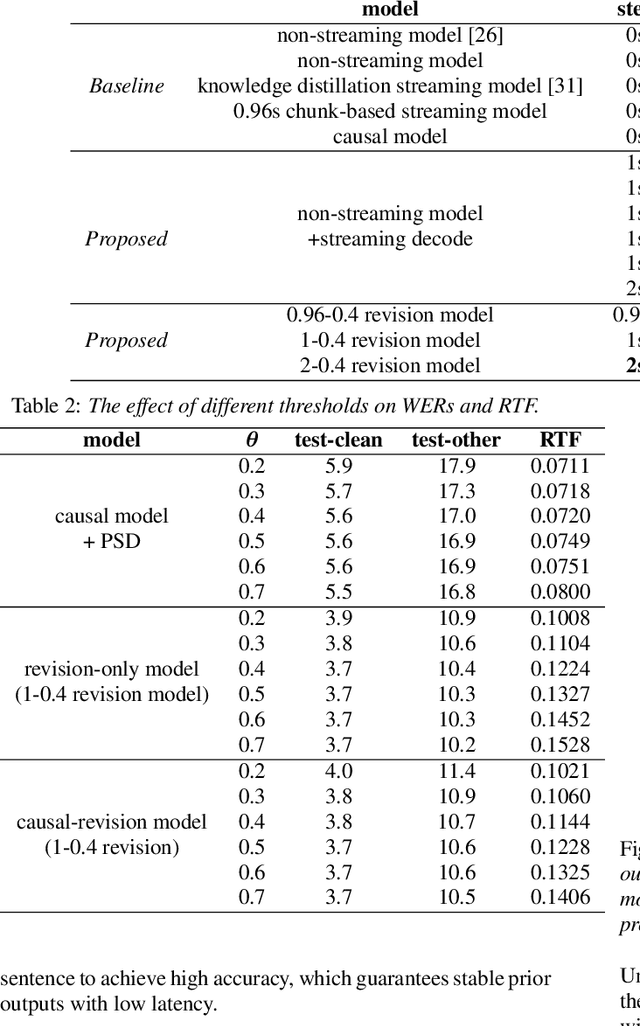
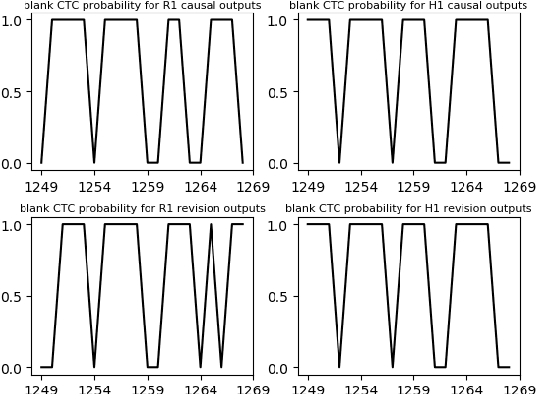
There is often a trade-off between performance and latency in streaming automatic speech recognition (ASR). Traditional methods such as look-ahead and chunk-based methods, usually require information from future frames to advance recognition accuracy, which incurs inevitable latency even if the computation is fast enough. A causal model that computes without any future frames can avoid this latency, but its performance is significantly worse than traditional methods. In this paper, we propose corresponding revision strategies to improve the causal model. Firstly, we introduce a real-time encoder states revision strategy to modify previous states. Encoder forward computation starts once the data is received and revises the previous encoder states after several frames, which is no need to wait for any right context. Furthermore, a CTC spike position alignment decoding algorithm is designed to reduce time costs brought by the revision strategy. Experiments are all conducted on Librispeech datasets. Fine-tuning on the CTC-based wav2vec2.0 model, our best method can achieve 3.7/9.2 WERs on test-clean/other sets, which is also competitive with the chunk-based methods and the knowledge distillation methods.
Performance Monitoring for End-to-End Speech Recognition
Apr 09, 2019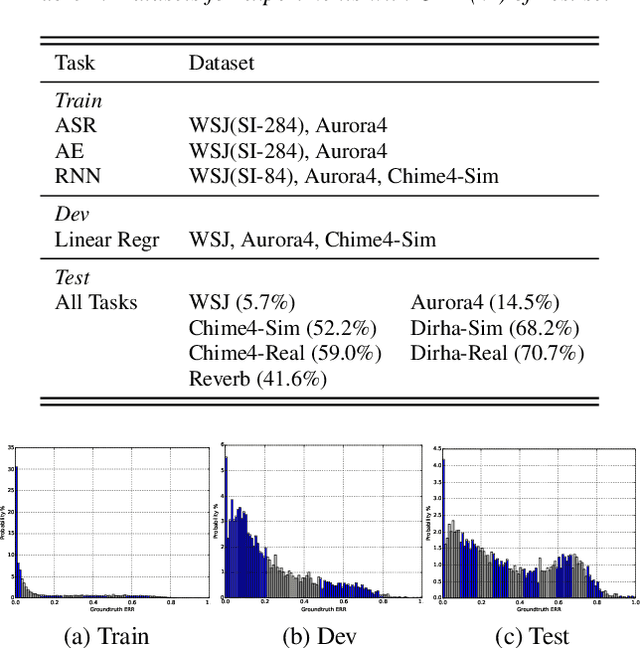
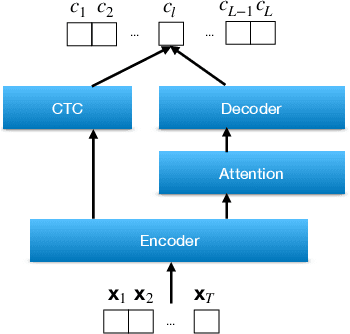
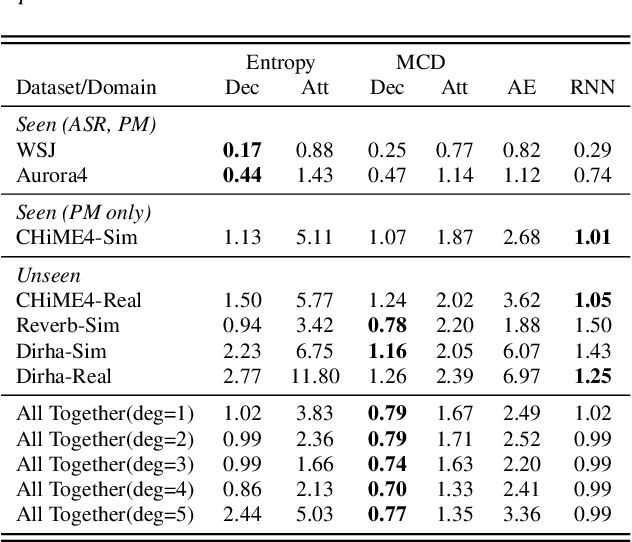
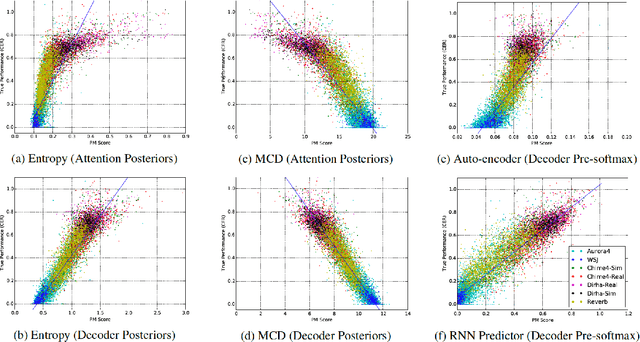
Measuring performance of an automatic speech recognition (ASR) system without ground-truth could be beneficial in many scenarios, especially with data from unseen domains, where performance can be highly inconsistent. In conventional ASR systems, several performance monitoring (PM) techniques have been well-developed to monitor performance by looking at tri-phone posteriors or pre-softmax activations from neural network acoustic modeling. However, strategies for monitoring more recently developed end-to-end ASR systems have not yet been explored, and so that is the focus of this paper. We adapt previous PM measures (Entropy, M-measure and Auto-encoder) and apply our proposed RNN predictor in the end-to-end setting. These measures utilize the decoder output layer and attention probability vectors, and their predictive power is measured with simple linear models. Our findings suggest that decoder-level features are more feasible and informative than attention-level probabilities for PM measures, and that M-measure on the decoder posteriors achieves the best overall predictive performance with an average prediction error 8.8%. Entropy measures and RNN-based prediction also show competitive predictability, especially for unseen conditions.
A Study of Enhancement, Augmentation, and Autoencoder Methods for Domain Adaptation in Distant Speech Recognition
Jun 13, 2018

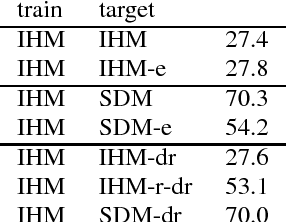
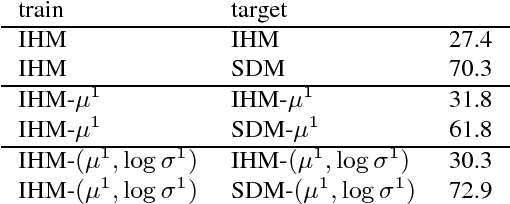
Speech recognizers trained on close-talking speech do not generalize to distant speech and the word error rate degradation can be as large as 40% absolute. Most studies focus on tackling distant speech recognition as a separate problem, leaving little effort to adapting close-talking speech recognizers to distant speech. In this work, we review several approaches from a domain adaptation perspective. These approaches, including speech enhancement, multi-condition training, data augmentation, and autoencoders, all involve a transformation of the data between domains. We conduct experiments on the AMI data set, where these approaches can be realized under the same controlled setting. These approaches lead to different amounts of improvement under their respective assumptions. The purpose of this paper is to quantify and characterize the performance gap between the two domains, setting up the basis for studying adaptation of speech recognizers from close-talking speech to distant speech. Our results also have implications for improving distant speech recognition.
Exploiting Hidden Representations from a DNN-based Speech Recogniser for Speech Intelligibility Prediction in Hearing-impaired Listeners
Apr 08, 2022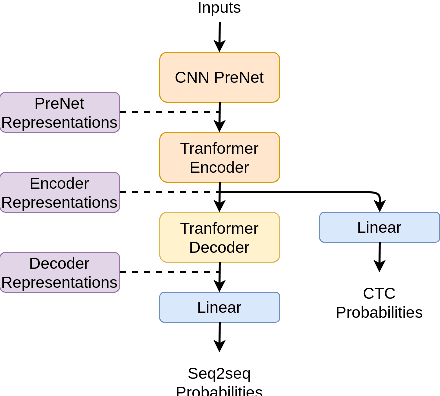
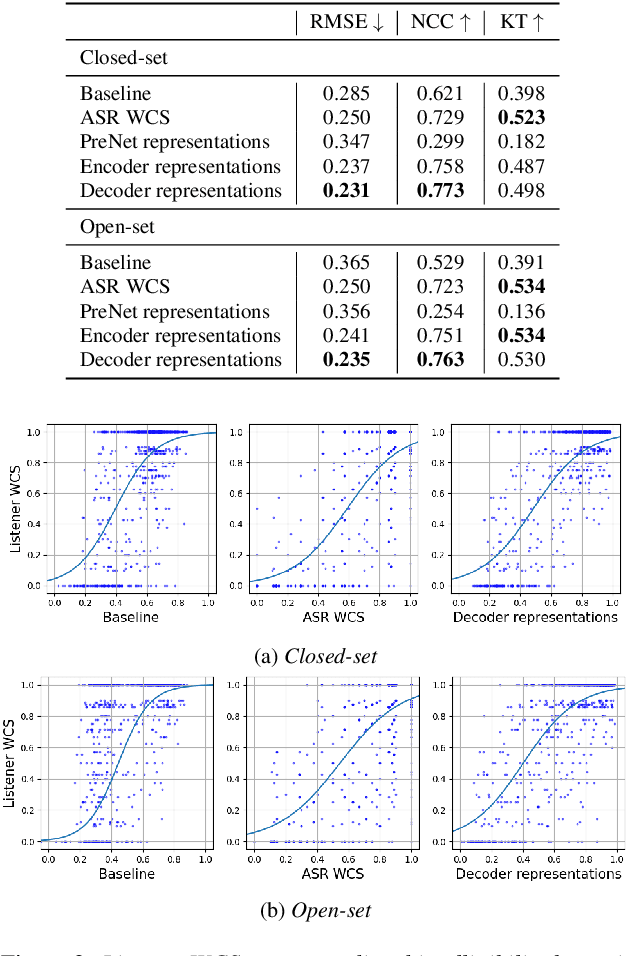
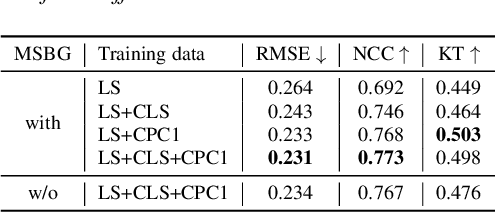
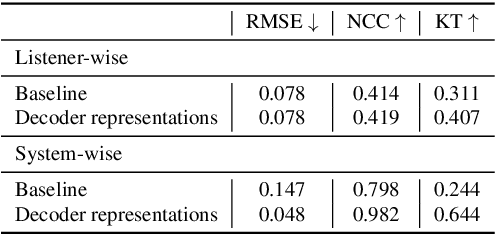
An accurate objective speech intelligibility prediction algorithms is of great interest for many applications such as speech enhancement for hearing aids. Most algorithms measures the signal-to-noise ratios or correlations between the acoustic features of clean reference signals and degraded signals. However, these hand-picked acoustic features are usually not explicitly correlated with recognition. Meanwhile, deep neural network (DNN) based automatic speech recogniser (ASR) is approaching human performance in some speech recognition tasks. This work leverages the hidden representations from DNN-based ASR as features for speech intelligibility prediction in hearing-impaired listeners. The experiments based on a hearing aid intelligibility database show that the proposed method could make better prediction than a widely used short-time objective intelligibility (STOI) based binaural measure.
Character-Level Incremental Speech Recognition with Recurrent Neural Networks
Jan 28, 2016
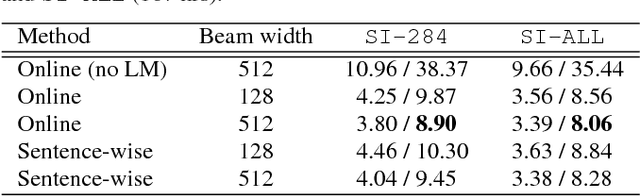
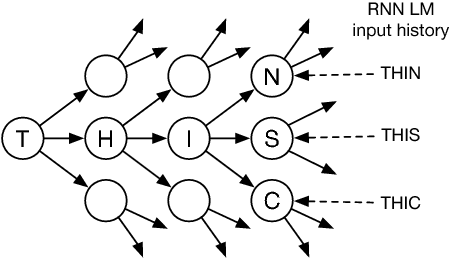

In real-time speech recognition applications, the latency is an important issue. We have developed a character-level incremental speech recognition (ISR) system that responds quickly even during the speech, where the hypotheses are gradually improved while the speaking proceeds. The algorithm employs a speech-to-character unidirectional recurrent neural network (RNN), which is end-to-end trained with connectionist temporal classification (CTC), and an RNN-based character-level language model (LM). The output values of the CTC-trained RNN are character-level probabilities, which are processed by beam search decoding. The RNN LM augments the decoding by providing long-term dependency information. We propose tree-based online beam search with additional depth-pruning, which enables the system to process infinitely long input speech with low latency. This system not only responds quickly on speech but also can dictate out-of-vocabulary (OOV) words according to pronunciation. The proposed model achieves the word error rate (WER) of 8.90% on the Wall Street Journal (WSJ) Nov'92 20K evaluation set when trained on the WSJ SI-284 training set.