 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
ASR Error Detection via Audio-Transcript entailment
Jul 22, 2022


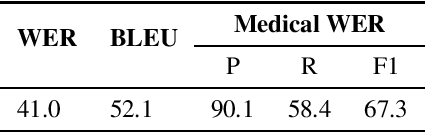
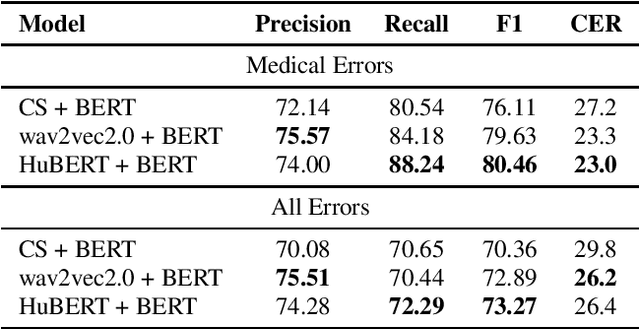
Despite improved performances of the latest Automatic Speech Recognition (ASR) systems, transcription errors are still unavoidable. These errors can have a considerable impact in critical domains such as healthcare, when used to help with clinical documentation. Therefore, detecting ASR errors is a critical first step in preventing further error propagation to downstream applications. To this end, we propose a novel end-to-end approach for ASR error detection using audio-transcript entailment. To the best of our knowledge, we are the first to frame this problem as an end-to-end entailment task between the audio segment and its corresponding transcript segment. Our intuition is that there should be a bidirectional entailment between audio and transcript when there is no recognition error and vice versa. The proposed model utilizes an acoustic encoder and a linguistic encoder to model the speech and transcript respectively. The encoded representations of both modalities are fused to predict the entailment. Since doctor-patient conversations are used in our experiments, a particular emphasis is placed on medical terms. Our proposed model achieves classification error rates (CER) of 26.2% on all transcription errors and 23% on medical errors specifically, leading to improvements upon a strong baseline by 12% and 15.4%, respectively.
Biologically inspired speech emotion recognition
Nov 15, 2021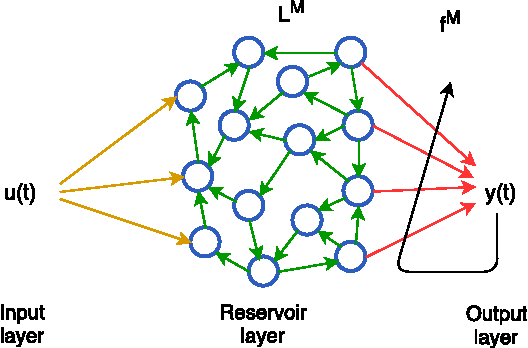
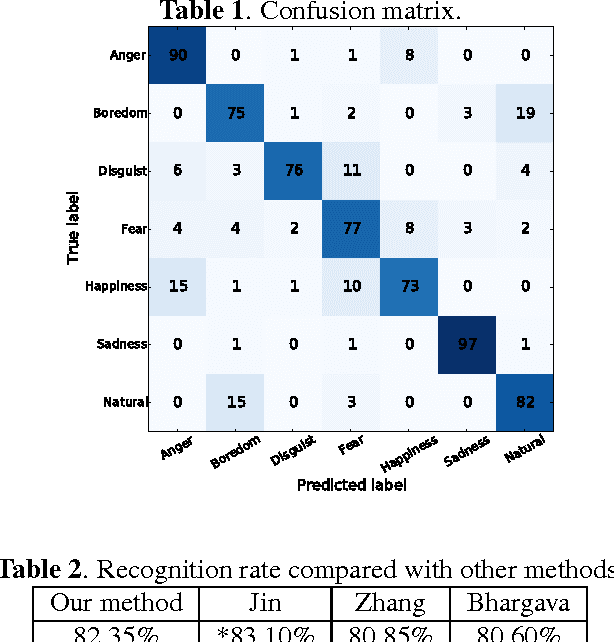
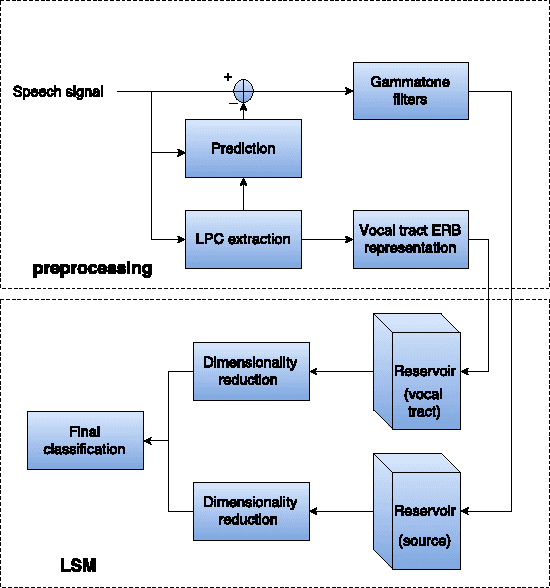
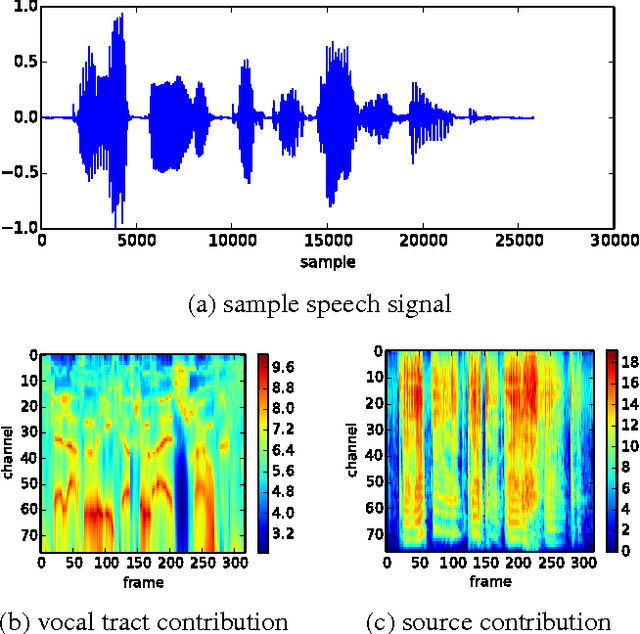
Conventional feature-based classification methods do not apply well to automatic recognition of speech emotions, mostly because the precise set of spectral and prosodic features that is required to identify the emotional state of a speaker has not been determined yet. This paper presents a method that operates directly on the speech signal, thus avoiding the problematic step of feature extraction. Furthermore, this method combines the strengths of the classical source-filter model of human speech production with those of the recently introduced liquid state machine (LSM), a biologically-inspired spiking neural network (SNN). The source and vocal tract components of the speech signal are first separated and converted into perceptually relevant spectral representations. These representations are then processed separately by two reservoirs of neurons. The output of each reservoir is reduced in dimensionality and fed to a final classifier. This method is shown to provide very good classification performance on the Berlin Database of Emotional Speech (Emo-DB). This seems a very promising framework for solving efficiently many other problems in speech processing.
A$^3$T: Alignment-Aware Acoustic and Text Pretraining for Speech Synthesis and Editing
Mar 18, 2022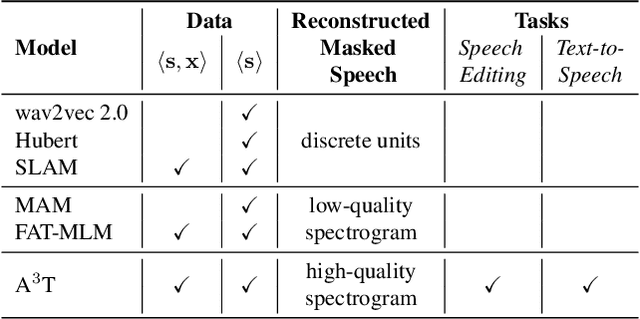
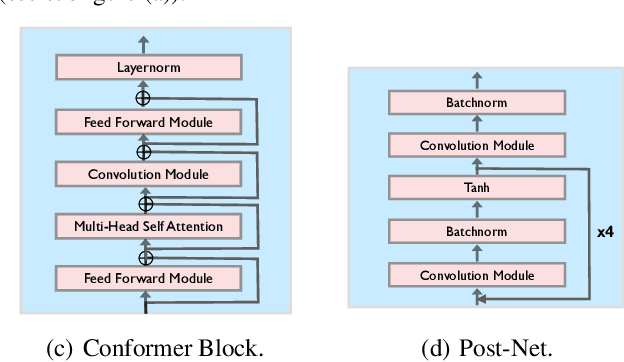

Recently, speech representation learning has improved many speech-related tasks such as speech recognition, speech classification, and speech-to-text translation. However, all the above tasks are in the direction of speech understanding, but for the inverse direction, speech synthesis, the potential of representation learning is yet to be realized, due to the challenging nature of generating high-quality speech. To address this problem, we propose our framework, Alignment-Aware Acoustic-Text Pretraining (A$^3$T), which reconstructs masked acoustic signals with text input and acoustic-text alignment during training. In this way, the pretrained model can generate high quality of reconstructed spectrogram, which can be applied to the speech editing and unseen speaker TTS directly. Experiments show A$^3$T outperforms SOTA models on speech editing, and improves multi-speaker speech synthesis without the external speaker verification model.
Analysis of French Phonetic Idiosyncrasies for Accent Recognition
Oct 18, 2021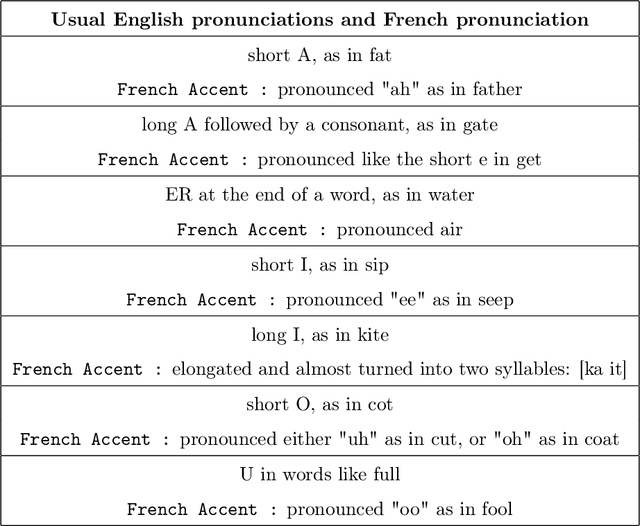
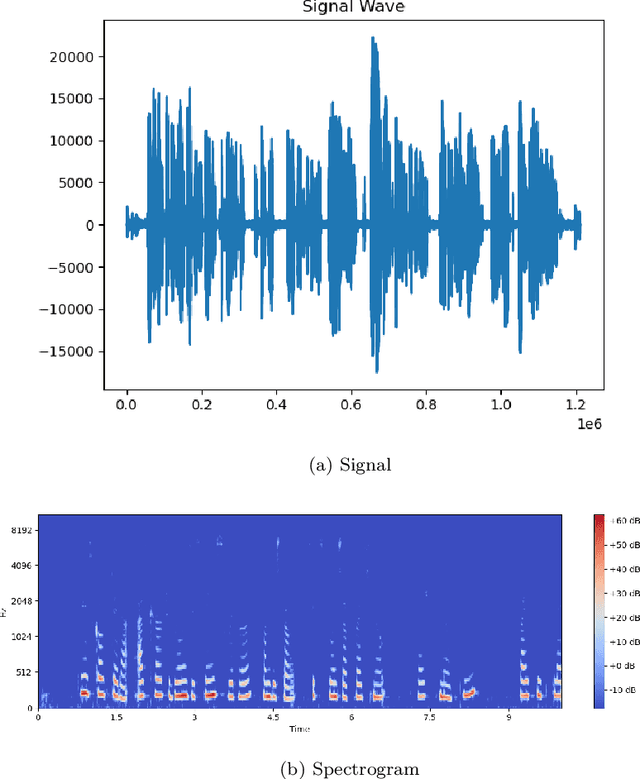
Speech recognition systems have made tremendous progress since the last few decades. They have developed significantly in identifying the speech of the speaker. However, there is a scope of improvement in speech recognition systems in identifying the nuances and accents of a speaker. It is known that any specific natural language may possess at least one accent. Despite the identical word phonemic composition, if it is pronounced in different accents, we will have sound waves, which are different from each other. Differences in pronunciation, in accent and intonation of speech in general, create one of the most common problems of speech recognition. If there are a lot of accents in language we should create the acoustic model for each separately. We carry out a systematic analysis of the problem in the accurate classification of accents. We use traditional machine learning techniques and convolutional neural networks, and show that the classical techniques are not sufficiently efficient to solve this problem. Using spectrograms of speech signals, we propose a multi-class classification framework for accent recognition. In this paper, we focus our attention on the French accent. We also identify its limitation by understanding the impact of French idiosyncrasies on its spectrograms.
indic-punct: An automatic punctuation restoration and inverse text normalization framework for Indic languages
Mar 31, 2022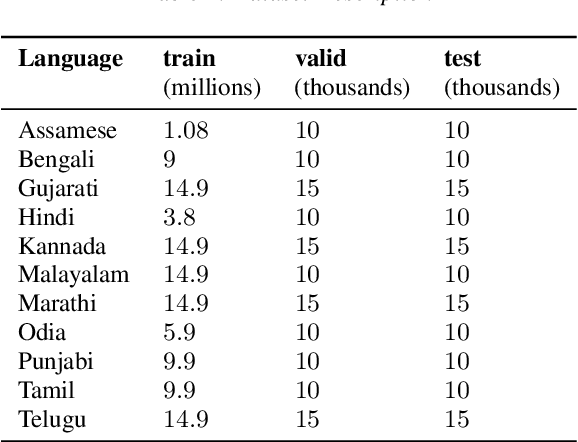
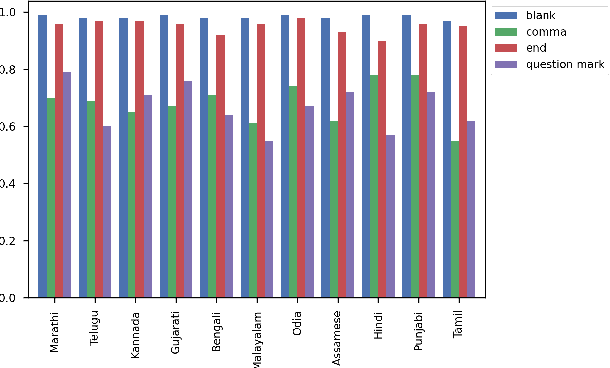
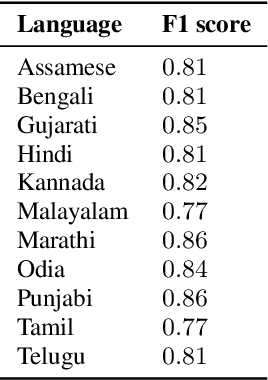
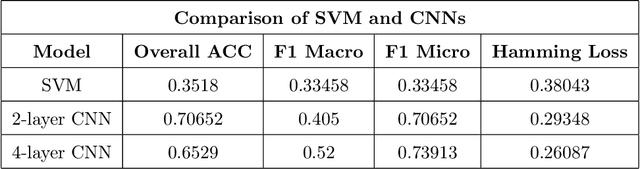
Automatic Speech Recognition (ASR) generates text which is most of the times devoid of any punctuation. Absence of punctuation is text can affect readability. Also, down stream NLP tasks such as sentiment analysis, machine translation, greatly benefit by having punctuation and sentence boundary information. We present an approach for automatic punctuation of text using a pretrained IndicBERT model. Inverse text normalization is done by hand writing weighted finite state transducer (WFST) grammars. We have developed this tool for 11 Indic languages namely Hindi, Tamil, Telugu, Kannada, Gujarati, Marathi, Odia, Bengali, Assamese, Malayalam and Punjabi. All code and data is publicly. available
Reinforcement Learning of Speech Recognition System Based on Policy Gradient and Hypothesis Selection
Nov 10, 2017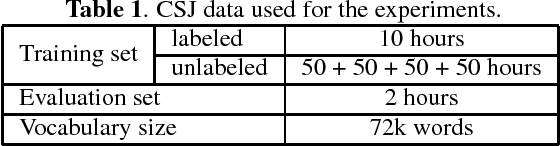
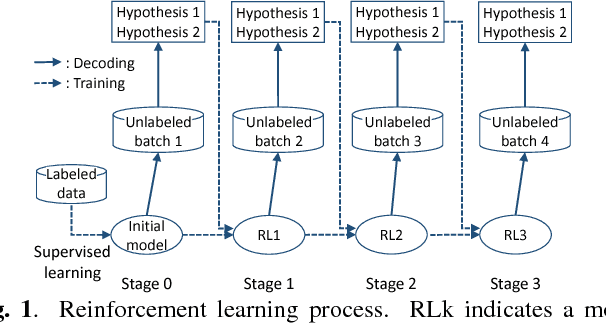
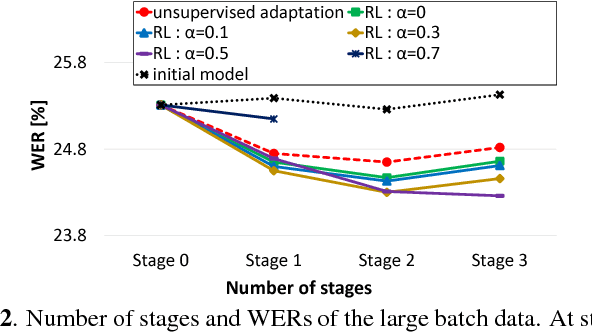
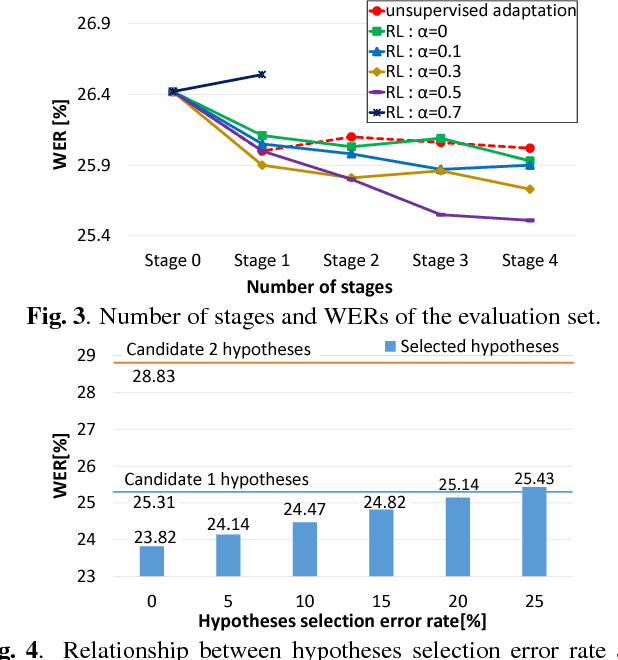
Speech recognition systems have achieved high recognition performance for several tasks. However, the performance of such systems is dependent on the tremendously costly development work of preparing vast amounts of task-matched transcribed speech data for supervised training. The key problem here is the cost of transcribing speech data. The cost is repeatedly required to support new languages and new tasks. Assuming broad network services for transcribing speech data for many users, a system would become more self-sufficient and more useful if it possessed the ability to learn from very light feedback from the users without annoying them. In this paper, we propose a general reinforcement learning framework for speech recognition systems based on the policy gradient method. As a particular instance of the framework, we also propose a hypothesis selection-based reinforcement learning method. The proposed framework provides a new view for several existing training and adaptation methods. The experimental results show that the proposed method improves the recognition performance compared to unsupervised adaptation.
Improving End-to-end Speech Recognition with Pronunciation-assisted Sub-word Modeling
Nov 10, 2018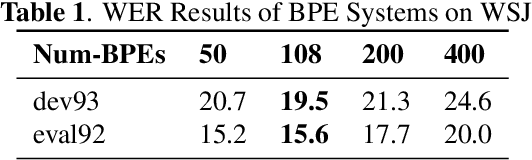
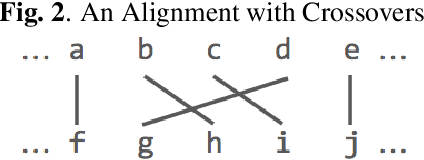

In recent years, end-to-end models have become popular for application in automatic speech recognition. Compared to hybrid approaches, which perform the phone-sequence to word conversion based on a lexicon, an end-to-end system models text directly, usually as a sequence of characters or sub-word features. We propose a sub-word modeling method that leverages the pronunciation information of a word. Experiments show that the proposed method can greatly improve upon the character-based baseline, and also outperform commonly used byte-pair encoding methods.
Sequence-to-sequence Automatic Speech Recognition with Word Embedding Regularization and Fused Decoding
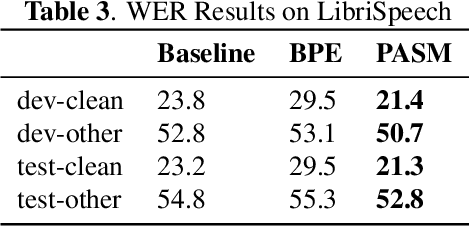
Oct 28, 2019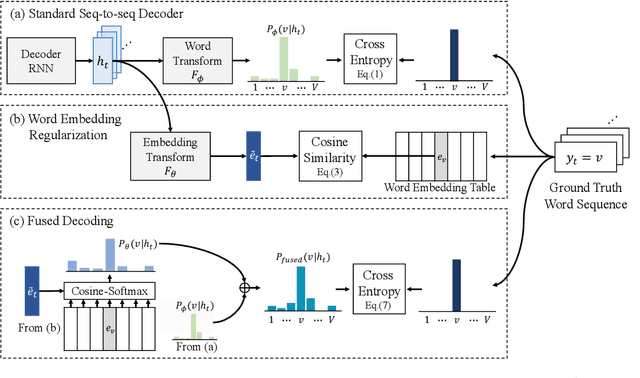
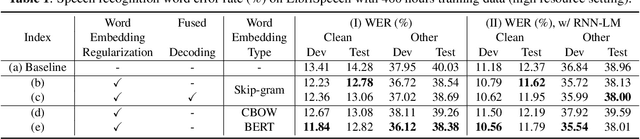
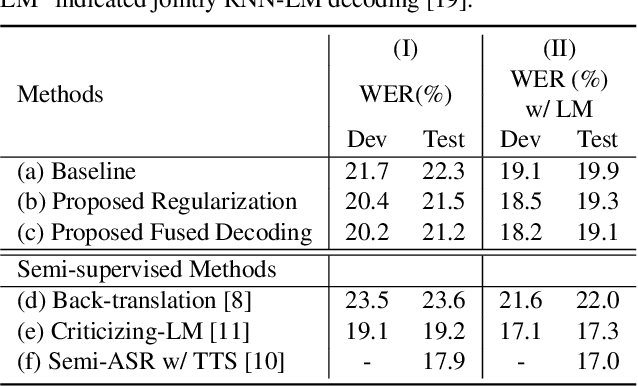
In this paper, we investigate the benefit that off-the-shelf word embedding can bring to the sequence-to-sequence (seq-to-seq) automatic speech recognition (ASR). We first introduced the word embedding regularization by maximizing the cosine similarity between a transformed decoder feature and the target word embedding. Based on the regularized decoder, we further proposed the fused decoding mechanism. This allows the decoder to consider the semantic consistency during decoding by absorbing the information carried by the transformed decoder feature, which is learned to be close to the target word embedding. Initial results on LibriSpeech demonstrated that pre-trained word embedding can significantly lower ASR recognition error with a negligible cost, and the choice of word embedding algorithms among Skip-gram, CBOW and BERT is important.
Towards Privacy-Preserving Speech Representation for Client-Side Data Sharing
Mar 26, 2022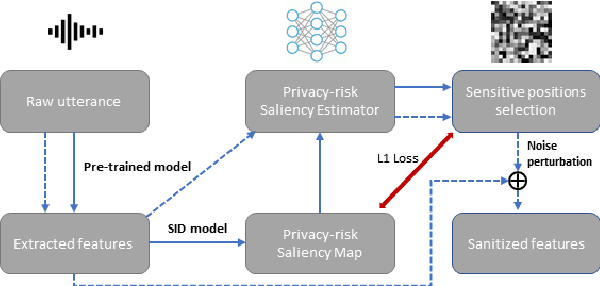
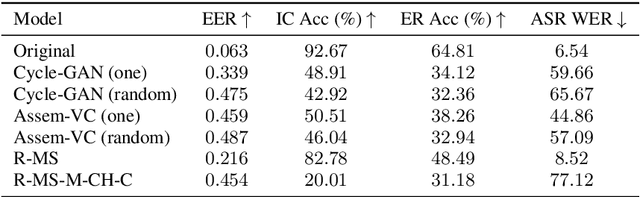
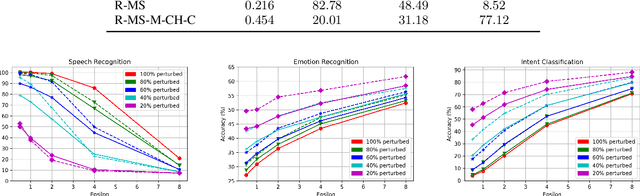
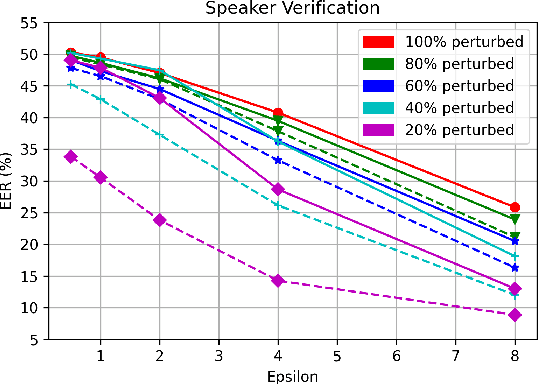
Privacy and security are major concerns when sharing and collecting speech data for cloud services such as automatic speech recognition (ASR) and speech emotion recognition (SER). Existing solutions for client-side privacy mainly focus on voice conversion or voice modification to convert a raw utterance into another one with similar content but different, or no, identity-related information. However, an alternative approach to share speech data under the form of privacy-preserving representations has been largely under-explored. To fill this gap, we propose a speech anonymization framework that provides formal privacy guarantees via noise perturbation to a selected subset of the high-utility representations extracted using a pre-trained speech encoder. The subset is chosen with a Transformer-based privacy-risk saliency estimator. We validate our framework on four tasks, namely, Automatic Speaker Verification (ASV), ASR, SER and Intent Classification (IC) for privacy and utility assessment. Experimental results show that our approach is able to achieve a competitive, or even better, utility compared to the baselines that use voice conversion and voice modification, providing the same level of privacy. Moreover, the easily-controlled amount of perturbation allows our framework to have a flexible range of privacy-utility trade-offs without re-training any components.
Linguistic and Gender Variation in Speech Emotion Recognition using Spectral Features
Dec 17, 2021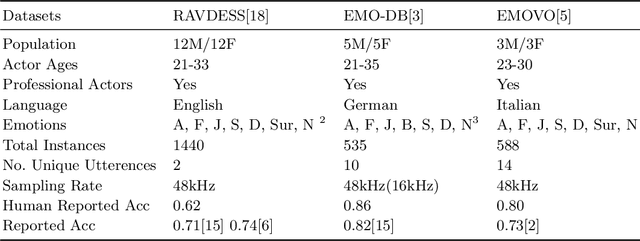
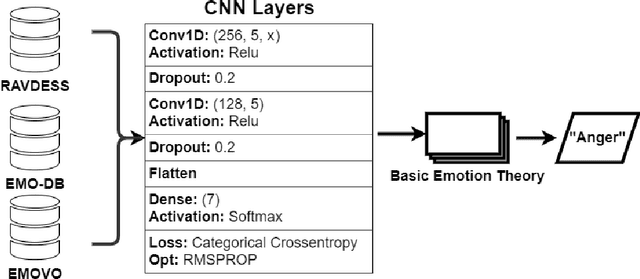
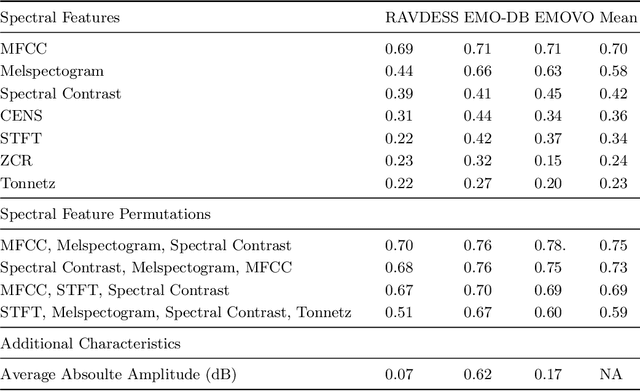
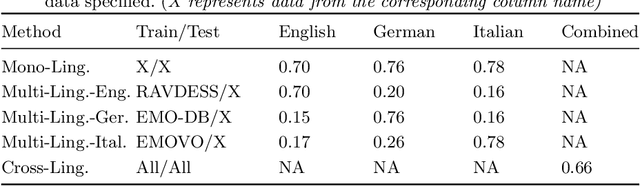
This work explores the effect of gender and linguistic-based vocal variations on the accuracy of emotive expression classification. Emotive expressions are considered from the perspective of spectral features in speech (Mel-frequency Cepstral Coefficient, Melspectrogram, Spectral Contrast). Emotions are considered from the perspective of Basic Emotion Theory. A convolutional neural network is utilised to classify emotive expressions in emotive audio datasets in English, German, and Italian. Vocal variations for spectral features assessed by (i) a comparative analysis identifying suitable spectral features, (ii) the classification performance for mono, multi and cross-lingual emotive data and (iii) an empirical evaluation of a machine learning model to assess the effects of gender and linguistic variation on classification accuracy. The results showed that spectral features provide a potential avenue for increasing emotive expression classification. Additionally, the accuracy of emotive expression classification was high within mono and cross-lingual emotive data, but poor in multi-lingual data. Similarly, there were differences in classification accuracy between gender populations. These results demonstrate the importance of accounting for population differences to enable accurate speech emotion recognition.