 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Accented Speech Recognition With Accent-specific Codebooks
Oct 25, 2023
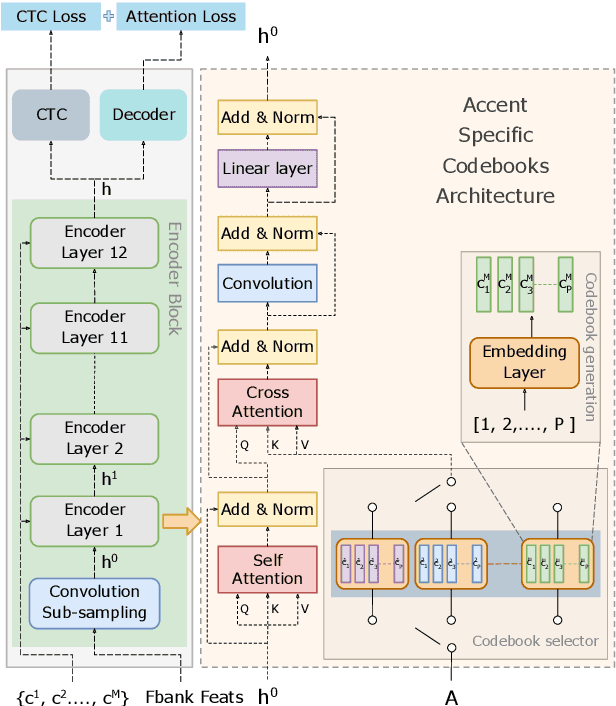
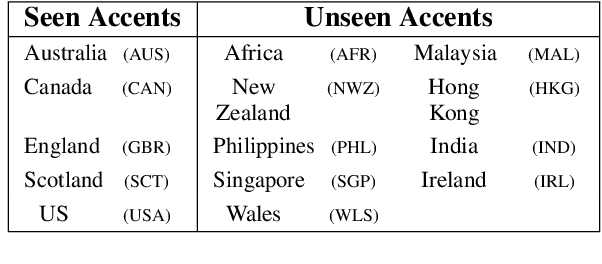
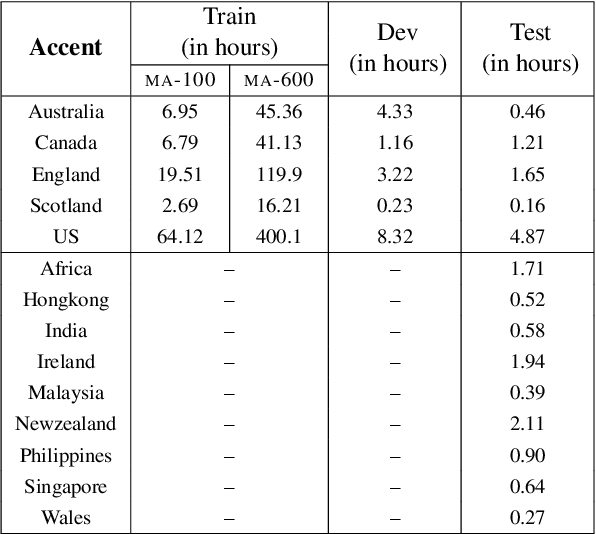
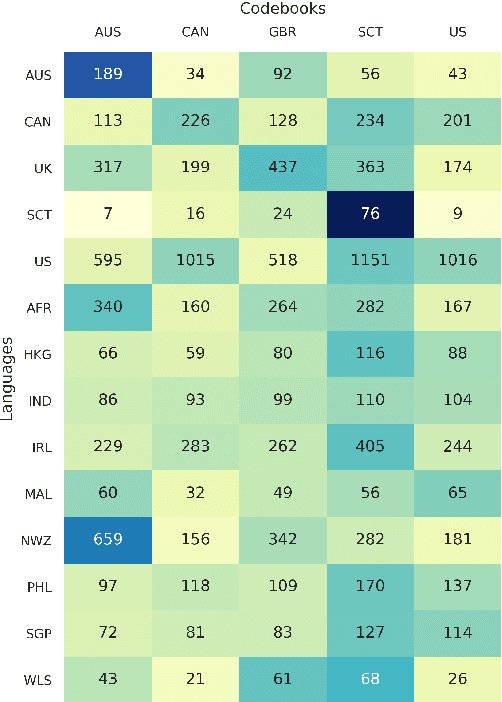
Speech accents pose a significant challenge to state-of-the-art automatic speech recognition (ASR) systems. Degradation in performance across underrepresented accents is a severe deterrent to the inclusive adoption of ASR. In this work, we propose a novel accent adaptation approach for end-to-end ASR systems using cross-attention with a trainable set of codebooks. These learnable codebooks capture accent-specific information and are integrated within the ASR encoder layers. The model is trained on accented English speech, while the test data also contained accents which were not seen during training. On the Mozilla Common Voice multi-accented dataset, we show that our proposed approach yields significant performance gains not only on the seen English accents (up to $37\%$ relative improvement in word error rate) but also on the unseen accents (up to $5\%$ relative improvement in WER). Further, we illustrate benefits for a zero-shot transfer setup on the L2Artic dataset. We also compare the performance with other approaches based on accent adversarial training.
GPU-Accelerated WFST Beam Search Decoder for CTC-based Speech Recognition
Nov 08, 2023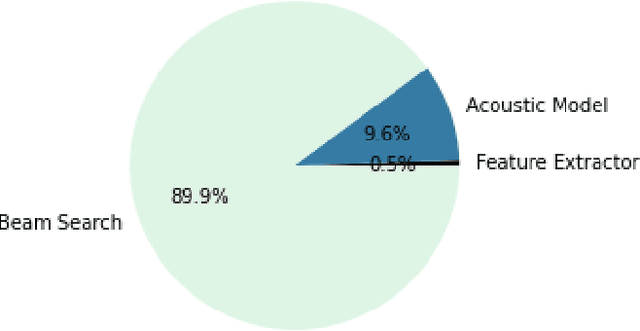
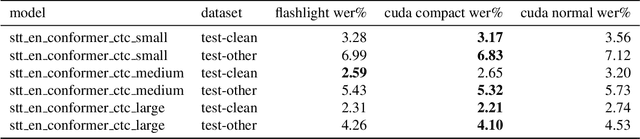
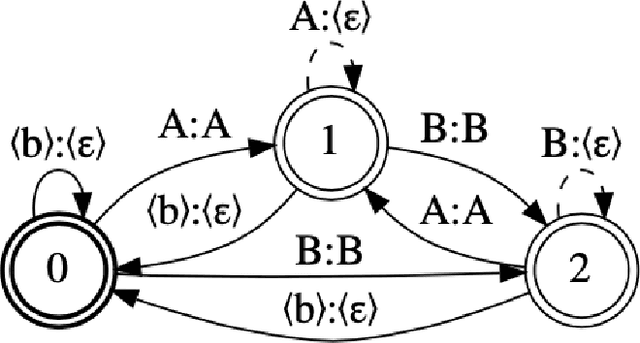

While Connectionist Temporal Classification (CTC) models deliver state-of-the-art accuracy in automated speech recognition (ASR) pipelines, their performance has been limited by CPU-based beam search decoding. We introduce a GPU-accelerated Weighted Finite State Transducer (WFST) beam search decoder compatible with current CTC models. It increases pipeline throughput and decreases latency, supports streaming inference, and also supports advanced features like utterance-specific word boosting via on-the-fly composition. We provide pre-built DLPack-based python bindings for ease of use with Python-based machine learning frameworks at https://github.com/nvidia-riva/riva-asrlib-decoder. We evaluated our decoder for offline and online scenarios, demonstrating that it is the fastest beam search decoder for CTC models. In the offline scenario it achieves up to 7 times more throughput than the current state-of-the-art CPU decoder and in the online streaming scenario, it achieves nearly 8 times lower latency, with same or better word error rate.
Multi-Level Knowledge Distillation for Speech Emotion Recognition in Noisy Conditions
Dec 21, 2023Speech emotion recognition (SER) performance deteriorates significantly in the presence of noise, making it challenging to achieve competitive performance in noisy conditions. To this end, we propose a multi-level knowledge distillation (MLKD) method, which aims to transfer the knowledge from a teacher model trained on clean speech to a simpler student model trained on noisy speech. Specifically, we use clean speech features extracted by the wav2vec-2.0 as the learning goal and train the distil wav2vec-2.0 to approximate the feature extraction ability of the original wav2vec-2.0 under noisy conditions. Furthermore, we leverage the multi-level knowledge of the original wav2vec-2.0 to supervise the single-level output of the distil wav2vec-2.0. We evaluate the effectiveness of our proposed method by conducting extensive experiments using five types of noise-contaminated speech on the IEMOCAP dataset, which show promising results compared to state-of-the-art models.
Exploratory Evaluation of Speech Content Masking
Jan 08, 2024Most recent speech privacy efforts have focused on anonymizing acoustic speaker attributes but there has not been as much research into protecting information from speech content. We introduce a toy problem that explores an emerging type of privacy called "content masking" which conceals selected words and phrases in speech. In our efforts to define this problem space, we evaluate an introductory baseline masking technique based on modifying sequences of discrete phone representations (phone codes) produced from a pre-trained vector-quantized variational autoencoder (VQ-VAE) and re-synthesized using WaveRNN. We investigate three different masking locations and three types of masking strategies: noise substitution, word deletion, and phone sequence reversal. Our work attempts to characterize how masking affects two downstream tasks: automatic speech recognition (ASR) and automatic speaker verification (ASV). We observe how the different masks types and locations impact these downstream tasks and discuss how these issues may influence privacy goals.
Machine Perceptual Quality: Evaluating the Impact of Severe Lossy Compression on Audio and Image Models
Jan 15, 2024In the field of neural data compression, the prevailing focus has been on optimizing algorithms for either classical distortion metrics, such as PSNR or SSIM, or human perceptual quality. With increasing amounts of data consumed by machines rather than humans, a new paradigm of machine-oriented compression$\unicode{x2013}$which prioritizes the retention of features salient for machine perception over traditional human-centric criteria$\unicode{x2013}$has emerged, creating several new challenges to the development, evaluation, and deployment of systems utilizing lossy compression. In particular, it is unclear how different approaches to lossy compression will affect the performance of downstream machine perception tasks. To address this under-explored area, we evaluate various perception models$\unicode{x2013}$including image classification, image segmentation, speech recognition, and music source separation$\unicode{x2013}$under severe lossy compression. We utilize several popular codecs spanning conventional, neural, and generative compression architectures. Our results indicate three key findings: (1) using generative compression, it is feasible to leverage highly compressed data while incurring a negligible impact on machine perceptual quality; (2) machine perceptual quality correlates strongly with deep similarity metrics, indicating a crucial role of these metrics in the development of machine-oriented codecs; and (3) using lossy compressed datasets, (e.g. ImageNet) for pre-training can lead to counter-intuitive scenarios where lossy compression increases machine perceptual quality rather than degrading it. To encourage engagement on this growing area of research, our code and experiments are available at: https://github.com/danjacobellis/MPQ.
Named Entity Recognition for Address Extraction in Speech-to-Text Transcriptions Using Synthetic Data
Feb 08, 2024This paper introduces an approach for building a Named Entity Recognition (NER) model built upon a Bidirectional Encoder Representations from Transformers (BERT) architecture, specifically utilizing the SlovakBERT model. This NER model extracts address parts from data acquired from speech-to-text transcriptions. Due to scarcity of real data, a synthetic dataset using GPT API was generated. The importance of mimicking spoken language variability in this artificial data is emphasized. The performance of our NER model, trained solely on synthetic data, is evaluated using small real test dataset.
Part-of-Speech Tagger for Bodo Language using Deep Learning approach
Jan 06, 2024Language Processing systems such as Part-of-speech tagging, Named entity recognition, Machine translation, Speech recognition, and Language modeling (LM) are well-studied in high-resource languages. Nevertheless, research on these systems for several low-resource languages, including Bodo, Mizo, Nagamese, and others, is either yet to commence or is in its nascent stages. Language model plays a vital role in the downstream tasks of modern NLP. Extensive studies are carried out on LMs for high-resource languages. Nevertheless, languages such as Bodo, Rabha, and Mising continue to lack coverage. In this study, we first present BodoBERT, a language model for the Bodo language. To the best of our knowledge, this work is the first such effort to develop a language model for Bodo. Secondly, we present an ensemble DL-based POS tagging model for Bodo. The POS tagging model is based on combinations of BiLSTM with CRF and stacked embedding of BodoBERT with BytePairEmbeddings. We cover several language models in the experiment to see how well they work in POS tagging tasks. The best-performing model achieves an F1 score of 0.8041. A comparative experiment was also conducted on Assamese POS taggers, considering that the language is spoken in the same region as Bodo.
Intelligibility prediction with a pretrained noise-robust automatic speech recognition model
Oct 20, 2023This paper describes two intelligibility prediction systems derived from a pretrained noise-robust automatic speech recognition (ASR) model for the second Clarity Prediction Challenge (CPC2). One system is intrusive and leverages the hidden representations of the ASR model. The other system is non-intrusive and makes predictions with derived ASR uncertainty. The ASR model is only pretrained with a simulated noisy speech corpus and does not take advantage of the CPC2 data. For that reason, the intelligibility prediction systems are robust to unseen scenarios given the accurate prediction performance on the CPC2 evaluation.
Ms-senet: Enhancing Speech Emotion Recognition Through Multi-scale Feature Fusion With Squeeze-and-excitation Blocks
Dec 25, 2023Speech Emotion Recognition (SER) has become a growing focus of research in human-computer interaction. Spatiotemporal features play a crucial role in SER, yet current research lacks comprehensive spatiotemporal feature learning. This paper focuses on addressing this gap by proposing a novel approach. In this paper, we employ Convolutional Neural Network (CNN) with varying kernel sizes for spatial and temporal feature extraction. Additionally, we introduce Squeeze-and-Excitation (SE) modules to capture and fuse multi-scale features, facilitating effective information fusion for improved emotion recognition and a deeper understanding of the temporal evolution of speech emotion. Moreover, we employ skip connections and Spatial Dropout (SD) layers to prevent overfitting and increase the model's depth. Our method outperforms the previous state-of-the-art method, achieving an average UAR and WAR improvement of 1.62% and 1.32%, respectively, across six benchmark SER datasets. Further experiments demonstrated that our method can fully extract spatiotemporal features in low-resource conditions.
Self-Supervised Adaptive AV Fusion Module for Pre-Trained ASR Models
Dec 21, 2023Automatic speech recognition (ASR) has reached a level of accuracy in recent years, that even outperforms humans in transcribing speech to text. Nevertheless, all current ASR approaches show a certain weakness against ambient noise. To reduce this weakness, audio-visual speech recognition (AVSR) approaches additionally consider visual information from lip movements for transcription. This additional modality increases the computational cost for training models from scratch. We propose an approach, that builds on a pre-trained ASR model and extends it with an adaptive upstream module, that fuses audio and visual information. Since we do not need to train the transformer structure from scratch, our approach requires a fraction of the computational resources compared to traditional AVSR models. Compared to current SOTA systems like AV-HuBERT, our approach achieves an average improvement of 8.3% in word error rate across different model sizes, noise categories and broad SNR range. The approach allows up to 21% smaller models and requires only a fraction of the computational resources for training and inference compared to common AVSR approaches.