 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Two-stage dimensional emotion recognition by fusing predictions of acoustic and text networks using SVM
Oct 26, 2022
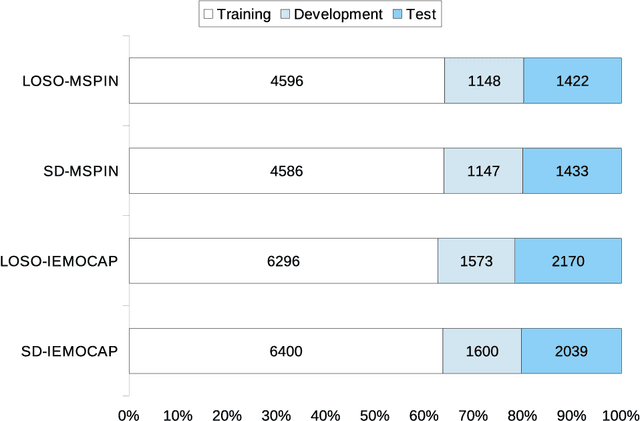

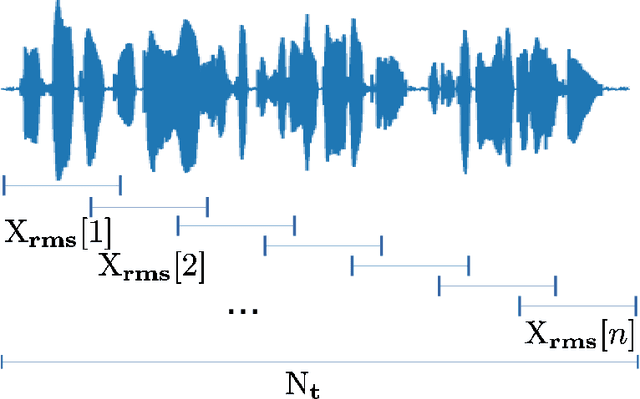
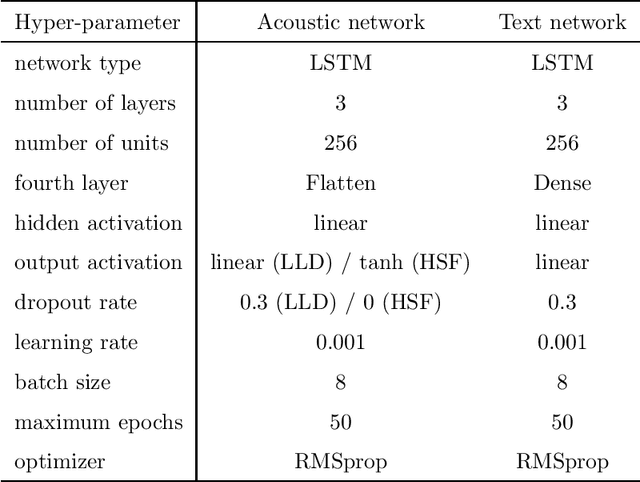
Automatic speech emotion recognition (SER) by a computer is a critical component for more natural human-machine interaction. As in human-human interaction, the capability to perceive emotion correctly is essential to take further steps in a particular situation. One issue in SER is whether it is necessary to combine acoustic features with other data such as facial expressions, text, and motion capture. This research proposes to combine acoustic and text information by applying a late-fusion approach consisting of two steps. First, acoustic and text features are trained separately in deep learning systems. Second, the prediction results from the deep learning systems are fed into a support vector machine (SVM) to predict the final regression score. Furthermore, the task in this research is dimensional emotion modeling because it can enable a deeper analysis of affective states. Experimental results show that this two-stage, late-fusion approach, obtains higher performance than that of any one-stage processing, with a linear correlation from one-stage to two-stage processing. This late-fusion approach improves previous early fusion results measured in concordance correlation coefficients score.
* Published in Speech Communications
Dual Language Models for Code Switched Speech Recognition
Aug 03, 2018
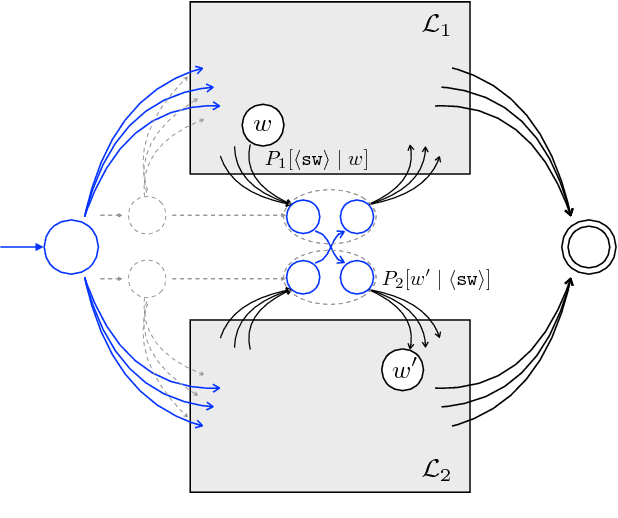
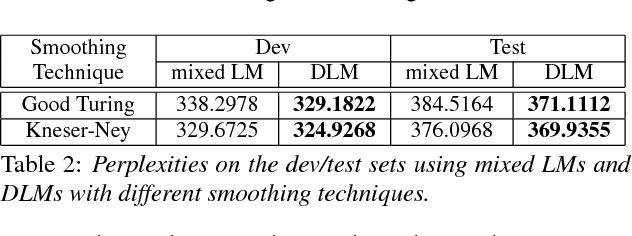
In this work, we present a simple and elegant approach to language modeling for bilingual code-switched text. Since code-switching is a blend of two or more different languages, a standard bilingual language model can be improved upon by using structures of the monolingual language models. We propose a novel technique called dual language models, which involves building two complementary monolingual language models and combining them using a probabilistic model for switching between the two. We evaluate the efficacy of our approach using a conversational Mandarin-English speech corpus. We prove the robustness of our model by showing significant improvements in perplexity measures over the standard bilingual language model without the use of any external information. Similar consistent improvements are also reflected in automatic speech recognition error rates.
Distributed Deep Learning Strategies For Automatic Speech Recognition
Apr 10, 2019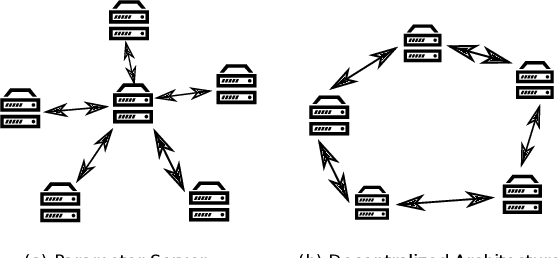
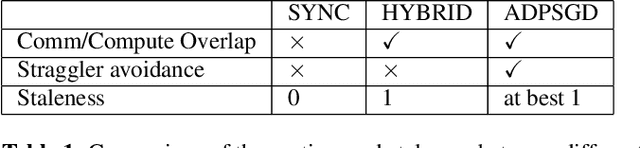
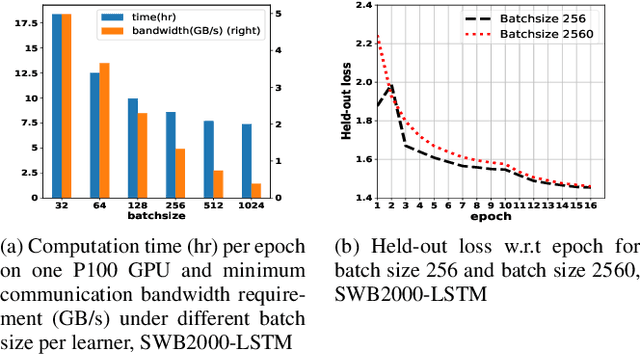
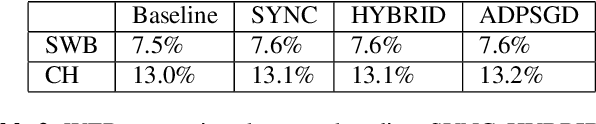
In this paper, we propose and investigate a variety of distributed deep learning strategies for automatic speech recognition (ASR) and evaluate them with a state-of-the-art Long short-term memory (LSTM) acoustic model on the 2000-hour Switchboard (SWB2000), which is one of the most widely used datasets for ASR performance benchmark. We first investigate what are the proper hyper-parameters (e.g., learning rate) to enable the training with sufficiently large batch size without impairing the model accuracy. We then implement various distributed strategies, including Synchronous (SYNC), Asynchronous Decentralized Parallel SGD (ADPSGD) and the hybrid of the two HYBRID, to study their runtime/accuracy trade-off. We show that we can train the LSTM model using ADPSGD in 14 hours with 16 NVIDIA P100 GPUs to reach a 7.6% WER on the Hub5- 2000 Switchboard (SWB) test set and a 13.1% WER on the CallHome (CH) test set. Furthermore, we can train the model using HYBRID in 11.5 hours with 32 NVIDIA V100 GPUs without loss in accuracy.
Analyzing Hidden Representations in End-to-End Automatic Speech Recognition Systems
Sep 13, 2017
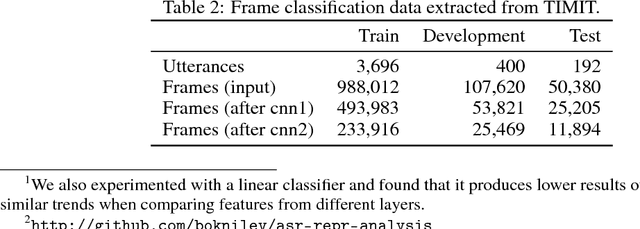
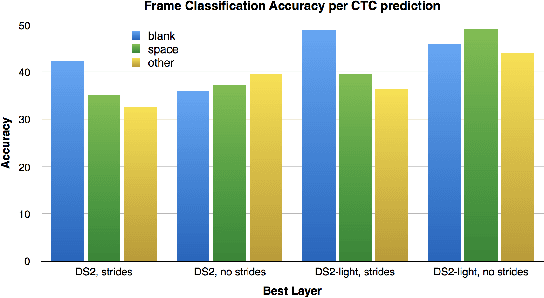
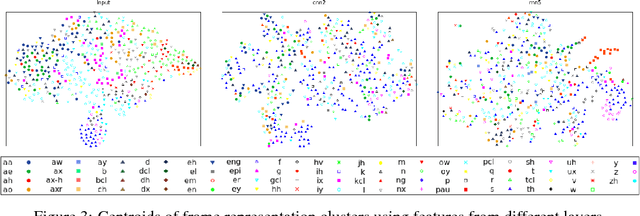
Neural models have become ubiquitous in automatic speech recognition systems. While neural networks are typically used as acoustic models in more complex systems, recent studies have explored end-to-end speech recognition systems based on neural networks, which can be trained to directly predict text from input acoustic features. Although such systems are conceptually elegant and simpler than traditional systems, it is less obvious how to interpret the trained models. In this work, we analyze the speech representations learned by a deep end-to-end model that is based on convolutional and recurrent layers, and trained with a connectionist temporal classification (CTC) loss. We use a pre-trained model to generate frame-level features which are given to a classifier that is trained on frame classification into phones. We evaluate representations from different layers of the deep model and compare their quality for predicting phone labels. Our experiments shed light on important aspects of the end-to-end model such as layer depth, model complexity, and other design choices.
Generative Adversarial Training Data Adaptation for Very Low-resource Automatic Speech Recognition
May 19, 2020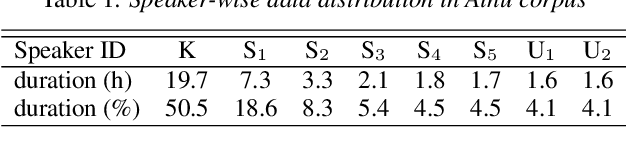
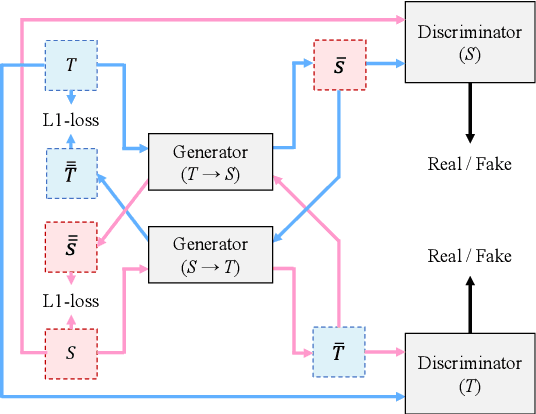
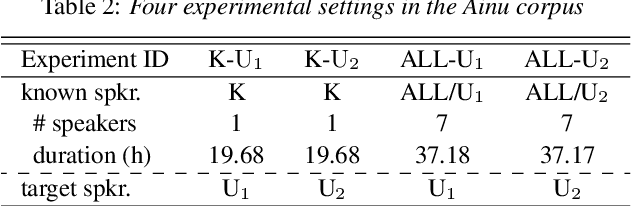
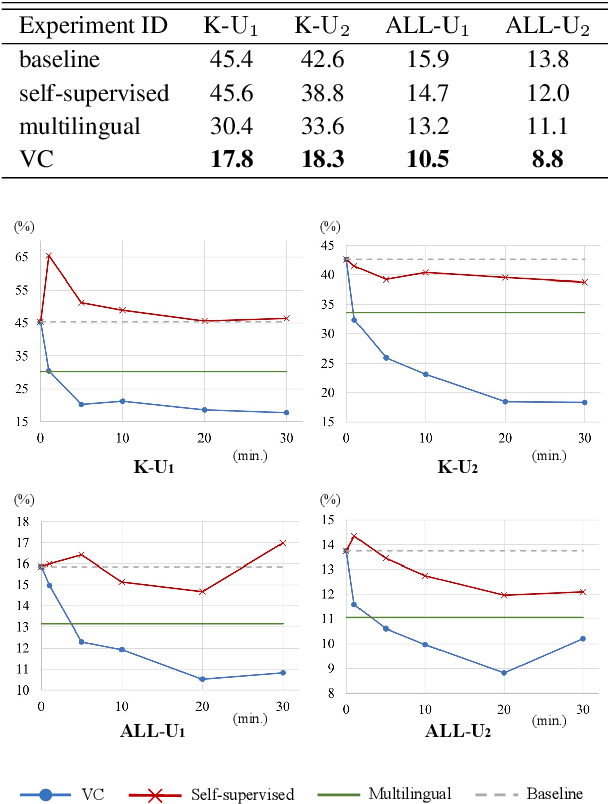
It is important to transcribe and archive speech data of endangered languages for preserving heritages of verbal culture and automatic speech recognition (ASR) is a powerful tool to facilitate this process. However, since endangered languages do not generally have large corpora with many speakers, the performance of ASR models trained on them are considerably poor in general. Nevertheless, we are often left with a lot of recordings of spontaneous speech data that have to be transcribed. In this work, for mitigating this speaker sparsity problem, we propose to convert the whole training speech data and make it sound like the test speaker in order to develop a highly accurate ASR system for this speaker. For this purpose, we utilize a CycleGAN-based non-parallel voice conversion technology to forge a labeled training data that is close to the test speaker's speech. We evaluated this speaker adaptation approach on two low-resource corpora, namely, Ainu and Mboshi. We obtained 35-60% relative improvement in phone error rate on the Ainu corpus, and 40% relative improvement was attained on the Mboshi corpus. This approach outperformed two conventional methods namely unsupervised adaptation and multilingual training with these two corpora.
PriMock57: A Dataset Of Primary Care Mock Consultations
Apr 01, 2022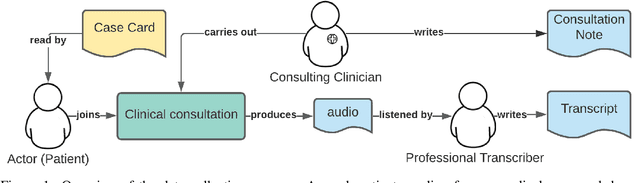
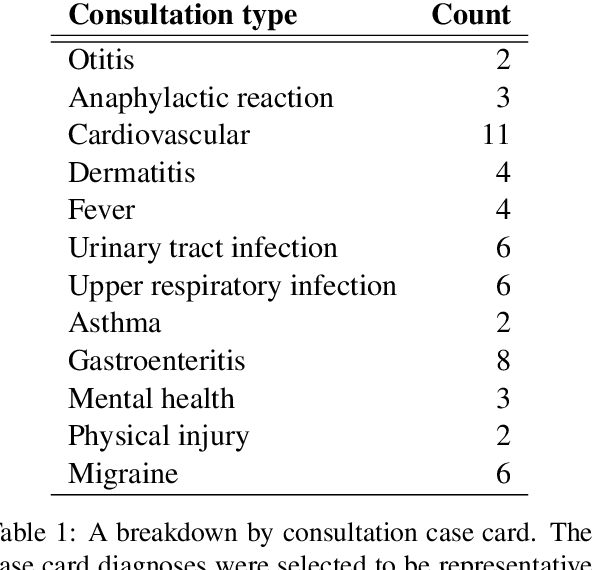

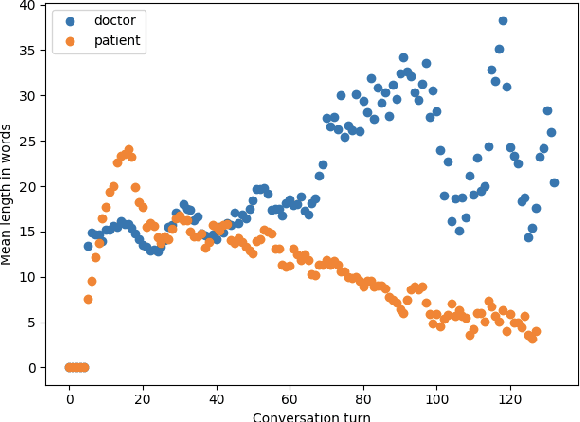
Recent advances in Automatic Speech Recognition (ASR) have made it possible to reliably produce automatic transcripts of clinician-patient conversations. However, access to clinical datasets is heavily restricted due to patient privacy, thus slowing down normal research practices. We detail the development of a public access, high quality dataset comprising of57 mocked primary care consultations, including audio recordings, their manual utterance-level transcriptions, and the associated consultation notes. Our work illustrates how the dataset can be used as a benchmark for conversational medical ASR as well as consultation note generation from transcripts.
A language score based output selection method for multilingual speech recognition
May 02, 2020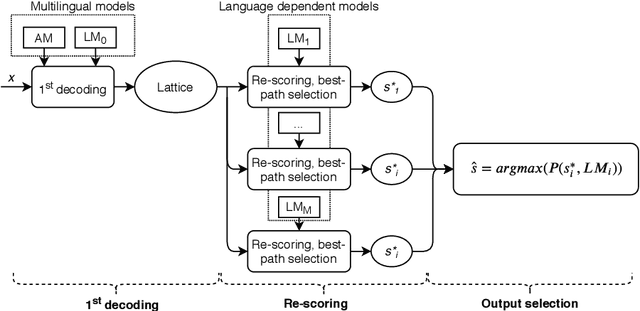
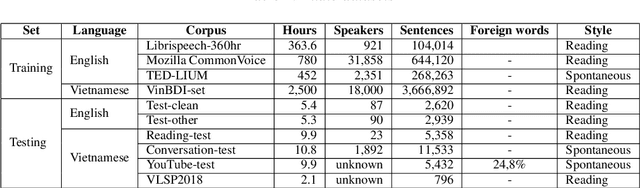
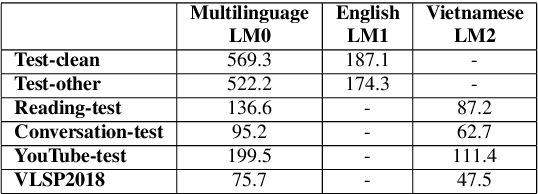
The quality of a multilingual speech recognition system can be improved by adaptation methods if the input language is specified. For systems that can accept multilingual inputs, the popular approach is to apply a language identifier to the input then switch or configure decoders in the next step, or use one more subsequence model to select the output from a set of candidates. Motivated by the goal of reducing the latency for real-time applications, in this paper, a language model rescoring method is firstly applied to produce all possible candidates for target languages, then a simple score is proposed to automatically select the output without any identifier model or language specification of the input language. The main point is that this score can be simply and automatically estimated on-the-fly so that the whole decoding pipeline is more simple and compact. Experimental results showed that this method can achieve the same quality as when the input language is specified. In addition, we present to design an English and Vietnamese End-to-End model to deal with not only the problem of cross-lingual speakers but also as a solution to improve the accuracy of borrowed words of English in Vietnamese.
The PyTorch-Kaldi Speech Recognition Toolkit
Nov 19, 2018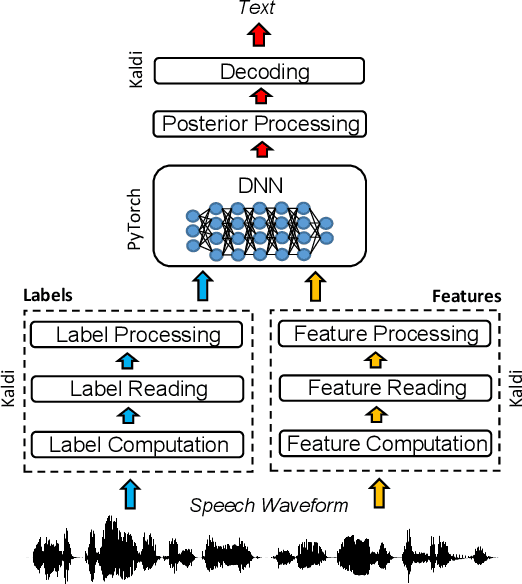
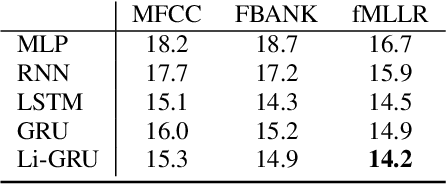

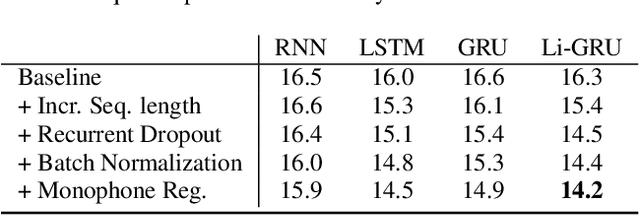
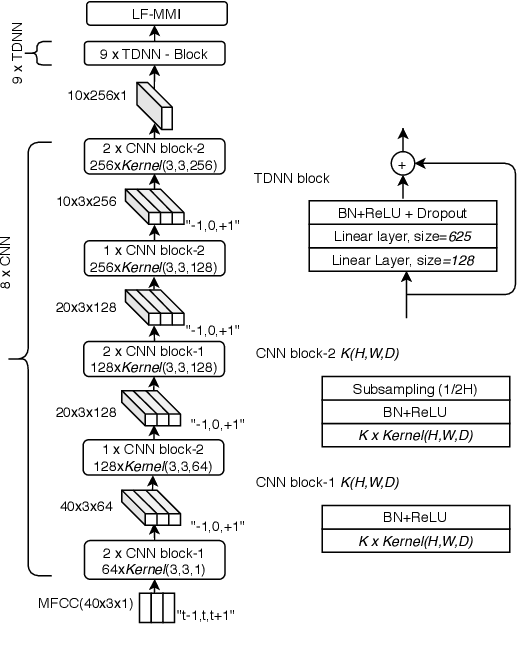
The availability of open-source software is playing a remarkable role in the popularization of speech recognition and deep learning. Kaldi, for instance, is nowadays an established framework used to develop state-of-the-art speech recognizers. PyTorch is used to build neural networks with the Python language and has recently spawn tremendous interest within the machine learning community thanks to its simplicity and flexibility. The PyTorch-Kaldi project aims to bridge the gap between these popular toolkits, trying to inherit the efficiency of Kaldi and the flexibility of PyTorch. PyTorch-Kaldi is not only a simple interface between these software, but it embeds several useful features for developing modern speech recognizers. For instance, the code is specifically designed to naturally plug-in user-defined acoustic models. As an alternative, users can exploit several pre-implemented neural networks that can be customized using intuitive configuration files. PyTorch-Kaldi supports multiple feature and label streams as well as combinations of neural networks, enabling the use of complex neural architectures. The toolkit is publicly-released along with a rich documentation and is designed to properly work locally or on HPC clusters. Experiments, that are conducted on several datasets and tasks, show that PyTorch-Kaldi can effectively be used to develop modern state-of-the-art speech recognizers.
Low-Latency Sequence-to-Sequence Speech Recognition and Translation by Partial Hypothesis Selection
May 22, 2020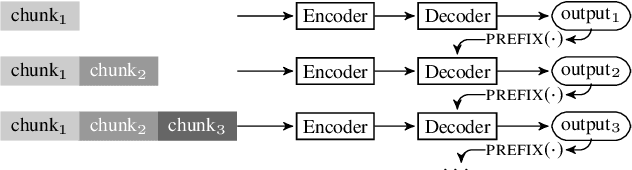
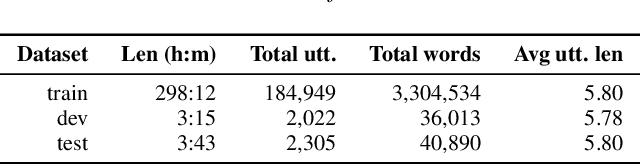
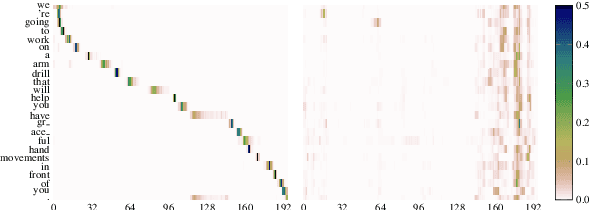
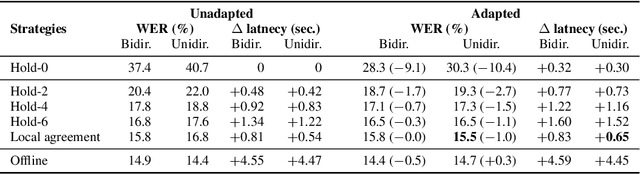
Encoder-decoder models provide a generic architecture for sequence-to-sequence tasks such as speech recognition and translation. While offline systems are often evaluated on quality metrics like word error rates (WER) and BLEU, latency is also a crucial factor in many practical use-cases. We propose three latency reduction techniques for chunk-based incremental inference and evaluate their efficiency in terms of accuracy-latency trade-off. On the 300-hour How2 dataset, we reduce latency by 83% to 0.8 second by sacrificing 1% WER (6% rel.) compared to offline transcription. Although our experiments use the Transformer, the hypothesis selection strategies are applicable to other encoder-decoder models. To avoid expensive re-computation, we use a unidirectionally-attending encoder. After an adaptation procedure to partial sequences, the unidirectional model performs on-par with the original model. We further show that our approach is also applicable to low-latency speech translation. On How2 English-Portuguese speech translation, we reduce latency to 0.7 second (-84% rel.) while incurring a loss of 2.4 BLEU points (5% rel.) compared to the offline system.
MobiVSR: A Visual Speech Recognition Solution for Mobile Devices
May 10, 2019
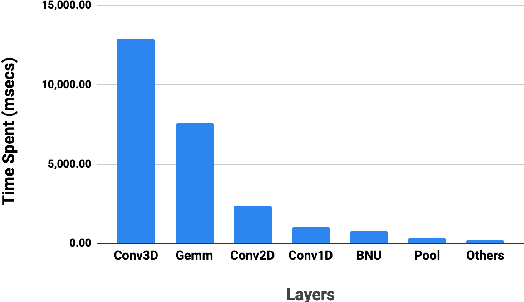
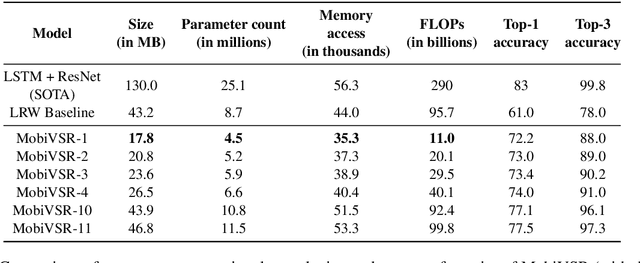
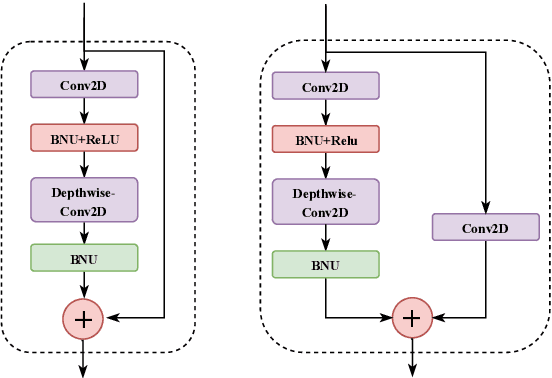
Visual speech recognition (VSR) is the task of recognizing spoken language from video input only, without any audio. VSR has many applications as an assistive technology, especially if it could be deployed in mobile devices and embedded systems. The need of intensive computational resources and large memory footprint are two of the major obstacles in developing neural network models for VSR in a resource constrained environment. We propose a novel end-to-end deep neural network architecture for word level VSR called MobiVSR with a design parameter that aids in balancing the model's accuracy and parameter count. We use depthwise-separable 3D convolution for the first time in the domain of VSR and show how it makes our model efficient. MobiVSR achieves an accuracy of 73\% on a challenging Lip Reading in the Wild dataset with 6 times fewer parameters and 20 times lesser memory footprint than the current state of the art. MobiVSR can also be compressed to 6 MB by applying post training quantization.