 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
MobiVSR: A Visual Speech Recognition Solution for Mobile Devices
Jun 05, 2019

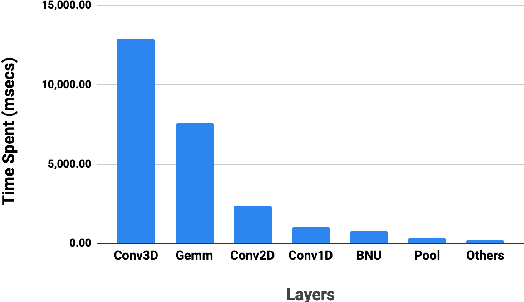
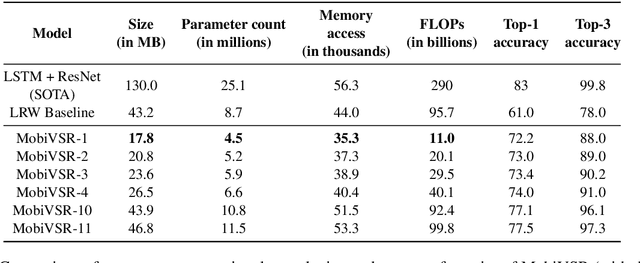
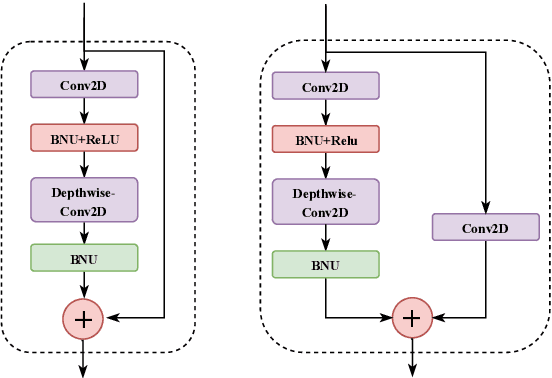
Visual speech recognition (VSR) is the task of recognizing spoken language from video input only, without any audio. VSR has many applications as an assistive technology, especially if it could be deployed in mobile devices and embedded systems. The need of intensive computational resources and large memory footprint are two of the major obstacles in developing neural network models for VSR in a resource constrained environment. We propose a novel end-to-end deep neural network architecture for word level VSR called MobiVSR with a design parameter that aids in balancing the model's accuracy and parameter count. We use depthwise-separable 3D convolution for the first time in the domain of VSR and show how it makes our model efficient. MobiVSR achieves an accuracy of 73\% on a challenging Lip Reading in the Wild dataset with 6 times fewer parameters and 20 times lesser memory footprint than the current state of the art. MobiVSR can also be compressed to 6 MB by applying post training quantization.
Thutmose Tagger: Single-pass neural model for Inverse Text Normalization
Jul 29, 2022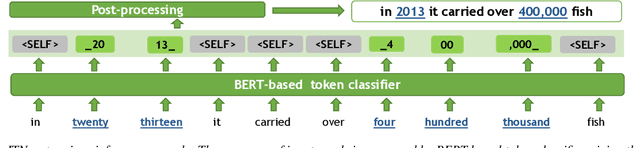
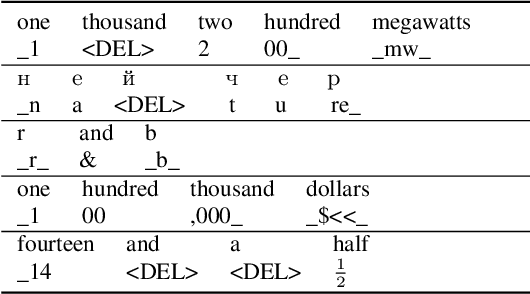

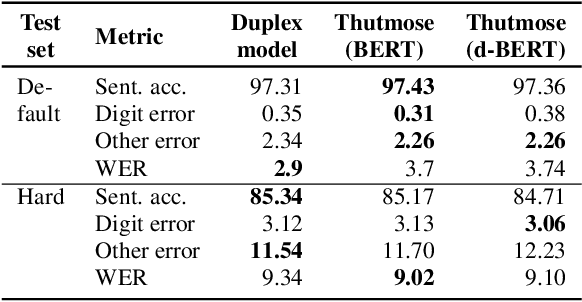
Inverse text normalization (ITN) is an essential post-processing step in automatic speech recognition (ASR). It converts numbers, dates, abbreviations, and other semiotic classes from the spoken form generated by ASR to their written forms. One can consider ITN as a Machine Translation task and use neural sequence-to-sequence models to solve it. Unfortunately, such neural models are prone to hallucinations that could lead to unacceptable errors. To mitigate this issue, we propose a single-pass token classifier model that regards ITN as a tagging task. The model assigns a replacement fragment to every input token or marks it for deletion or copying without changes. We present a dataset preparation method based on the granular alignment of ITN examples. The proposed model is less prone to hallucination errors. The model is trained on the Google Text Normalization dataset and achieves state-of-the-art sentence accuracy on both English and Russian test sets. One-to-one correspondence between tags and input words improves the interpretability of the model's predictions, simplifies debugging, and allows for post-processing corrections. The model is simpler than sequence-to-sequence models and easier to optimize in production settings. The model and the code to prepare the dataset is published as part of NeMo project.
A Comparison of Label-Synchronous and Frame-Synchronous End-to-End Models for Speech Recognition
May 25, 2020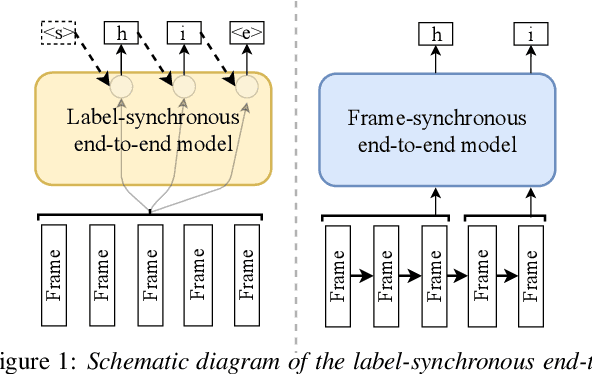

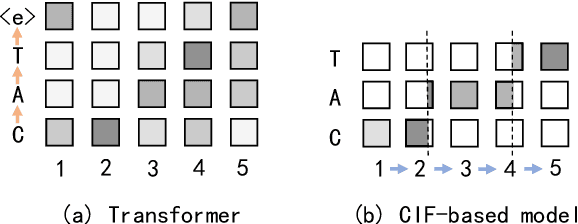
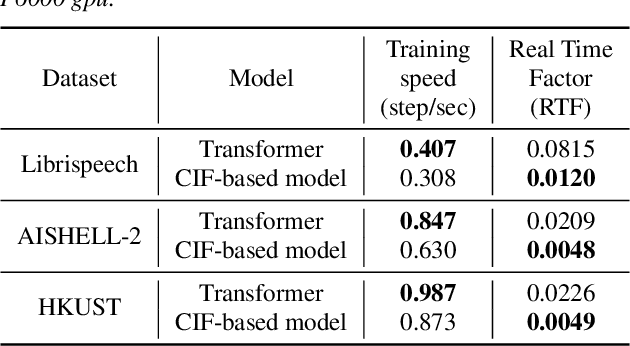
End-to-end models are gaining wider attention in the field of automatic speech recognition (ASR). One of their advantages is the simplicity of building that directly recognizes the speech frame sequence into the text label sequence by neural networks. According to the driving end in the recognition process, end-to-end ASR models could be categorized into two types: label-synchronous and frame-synchronous, each of which has unique model behaviour and characteristic. In this work, we make a detailed comparison on a representative label-synchronous model (transformer) and a soft frame-synchronous model (continuous integrate-and-fire (CIF) based model). The results on three public dataset and a large-scale dataset with 12000 hours of training data show that the two types of models have respective advantages that are consistent with their synchronous mode.
Streaming End-to-end Speech Recognition For Mobile Devices
Nov 15, 2018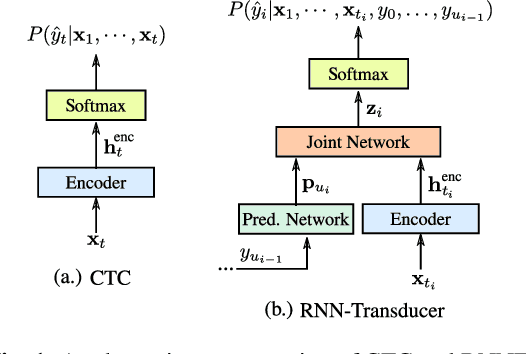
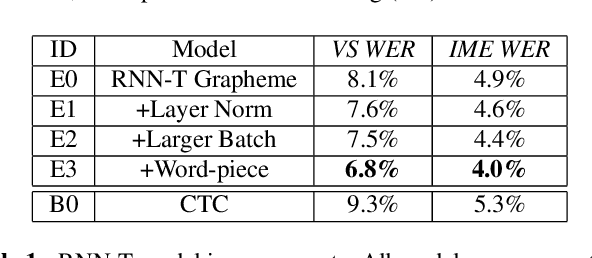
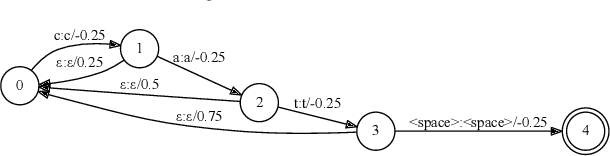
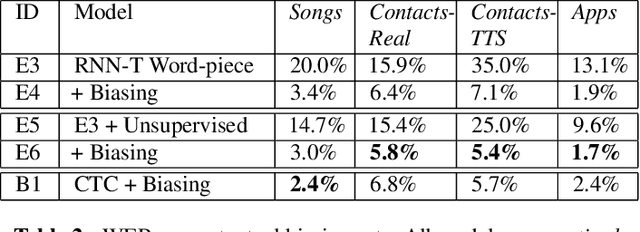
End-to-end (E2E) models, which directly predict output character sequences given input speech, are good candidates for on-device speech recognition. E2E models, however, present numerous challenges: In order to be truly useful, such models must decode speech utterances in a streaming fashion, in real time; they must be robust to the long tail of use cases; they must be able to leverage user-specific context (e.g., contact lists); and above all, they must be extremely accurate. In this work, we describe our efforts at building an E2E speech recognizer using a recurrent neural network transducer. In experimental evaluations, we find that the proposed approach can outperform a conventional CTC-based model in terms of both latency and accuracy in a number of evaluation categories.
CTA-RNN: Channel and Temporal-wise Attention RNN Leveraging Pre-trained ASR Embeddings for Speech Emotion Recognition
Mar 31, 2022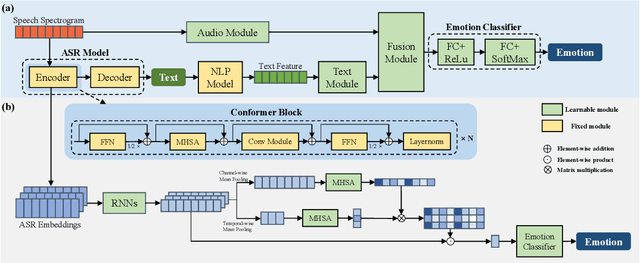

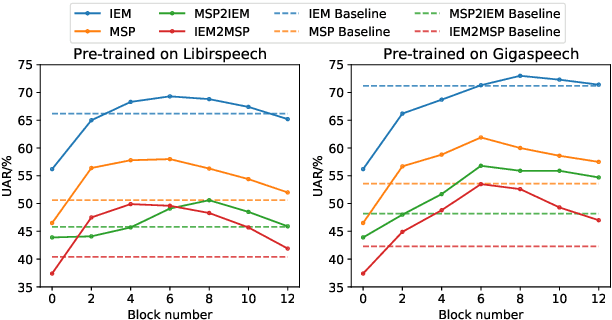
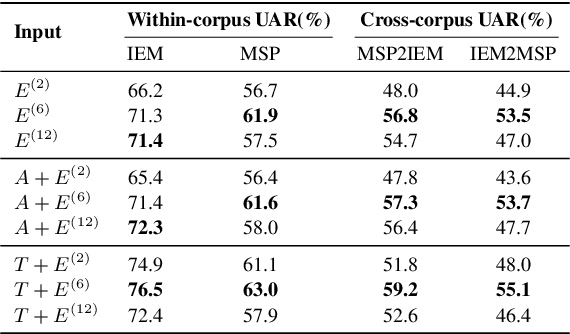
Previous research has looked into ways to improve speech emotion recognition (SER) by utilizing both acoustic and linguistic cues of speech. However, the potential association between state-of-the-art ASR models and the SER task has yet to be investigated. In this paper, we propose a novel channel and temporal-wise attention RNN (CTA-RNN) architecture based on the intermediate representations of pre-trained ASR models. Specifically, the embeddings of a large-scale pre-trained end-to-end ASR encoder contain both acoustic and linguistic information, as well as the ability to generalize to different speakers, making them well suited for downstream SER task. To further exploit the embeddings from different layers of the ASR encoder, we propose a novel CTA-RNN architecture to capture the emotional salient parts of embeddings in both the channel and temporal directions. We evaluate our approach on two popular benchmark datasets, IEMOCAP and MSP-IMPROV, using both within-corpus and cross-corpus settings. Experimental results show that our proposed method can achieve excellent performance in terms of accuracy and robustness.
Pronunciation Dictionary-Free Multilingual Speech Synthesis by Combining Unsupervised and Supervised Phonetic Representations
Jun 02, 2022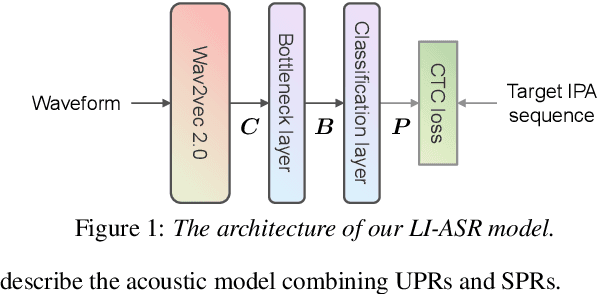
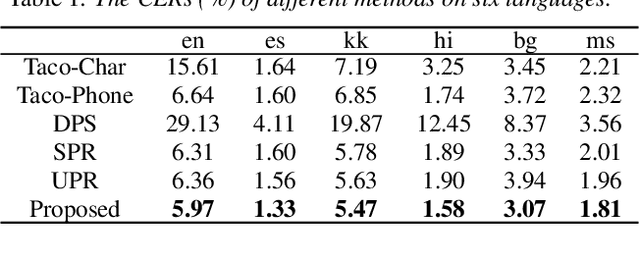
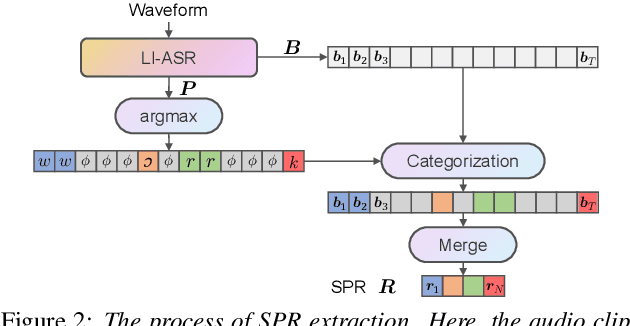

This paper proposes a multilingual speech synthesis method which combines unsupervised phonetic representations (UPR) and supervised phonetic representations (SPR) to avoid reliance on the pronunciation dictionaries of target languages. In this method, a pretrained wav2vec 2.0 model is adopted to extract UPRs and a language-independent automatic speech recognition (LI-ASR) model is built with a connectionist temporal classification (CTC) loss to extract segment-level SPRs from the audio data of target languages. Then, an acoustic model is designed, which first predicts UPRs and SPRs from texts separately and then combines the predicted UPRs and SPRs to generate mel-spectrograms. The results of our experiments on six languages show that the proposed method outperformed the methods that directly predicted mel-spectrograms from character or phoneme sequences and the ablated models that utilized only UPRs or SPRs.
FAAG: Fast Adversarial Audio Generation through Interactive Attack Optimisation
Feb 11, 2022
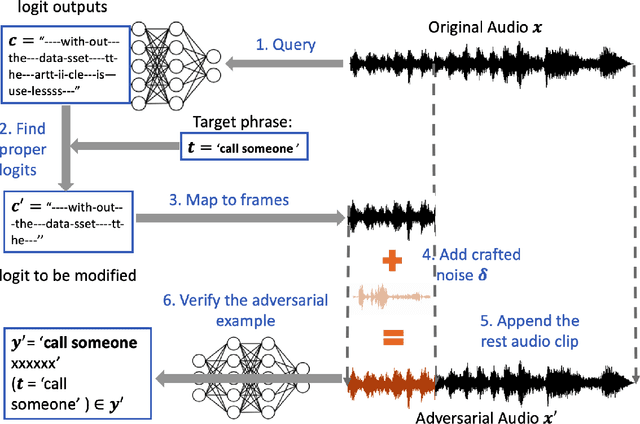
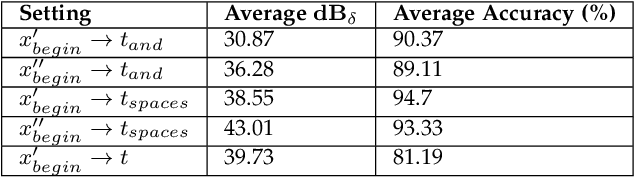
Automatic Speech Recognition services (ASRs) inherit deep neural networks' vulnerabilities like crafted adversarial examples. Existing methods often suffer from low efficiency because the target phases are added to the entire audio sample, resulting in high demand for computational resources. This paper proposes a novel scheme named FAAG as an iterative optimization-based method to generate targeted adversarial examples quickly. By injecting the noise over the beginning part of the audio, FAAG generates adversarial audio in high quality with a high success rate timely. Specifically, we use audio's logits output to map each character in the transcription to an approximate position of the audio's frame. Thus, an adversarial example can be generated by FAAG in approximately two minutes using CPUs only and around ten seconds with one GPU while maintaining an average success rate over 85%. Specifically, the FAAG method can speed up around 60% compared with the baseline method during the adversarial example generation process. Furthermore, we found that appending benign audio to any suspicious examples can effectively defend against the targeted adversarial attack. We hope that this work paves the way for inventing new adversarial attacks against speech recognition with computational constraints.
You Do Not Need More Data: Improving End-To-End Speech Recognition by Text-To-Speech Data Augmentation
May 14, 2020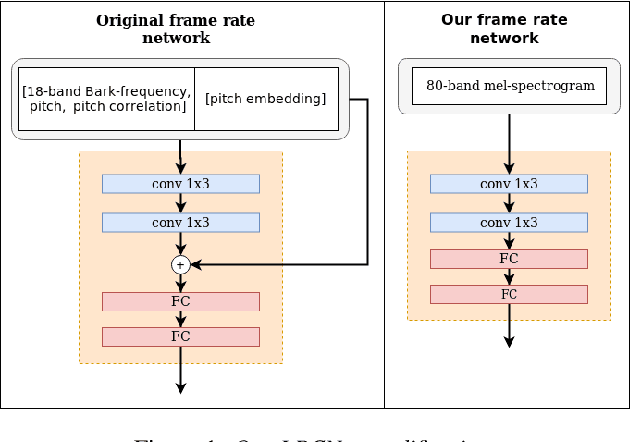
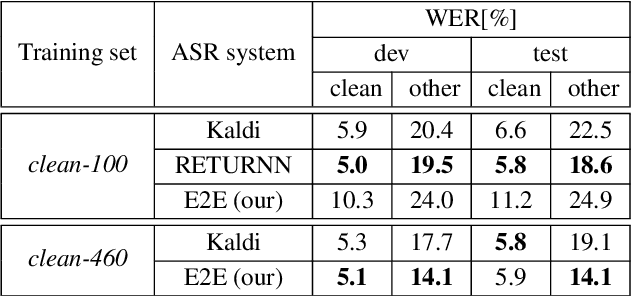
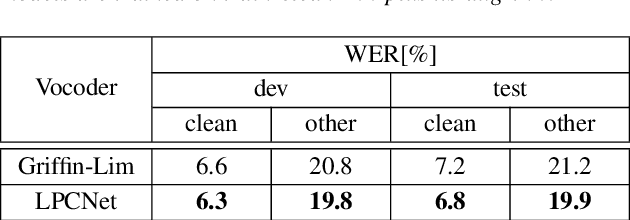
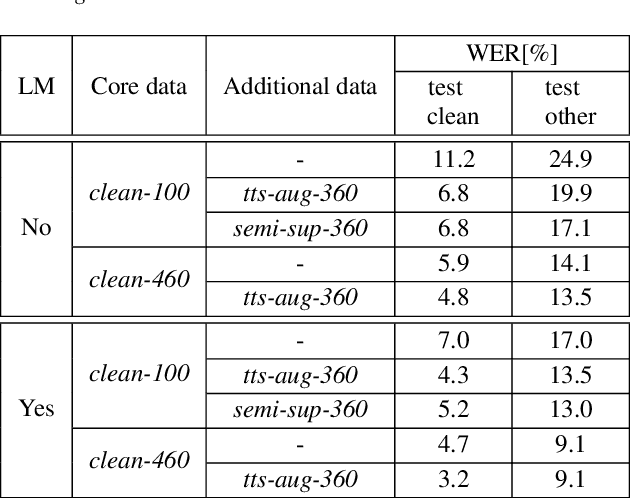
Data augmentation is one of the most effective ways to make end-to-end automatic speech recognition (ASR) perform close to the conventional hybrid approach, especially when dealing with low-resource tasks. Using recent advances in speech synthesis (text-to-speech, or TTS), we build our TTS system on an ASR training database and then extend the data with synthesized speech to train a recognition model. We argue that, when the training data amount is low, this approach can allow an end-to-end model to reach hybrid systems' quality. For an artificial low-resource setup, we compare the proposed augmentation with the semi-supervised learning technique. We also investigate the influence of vocoder usage on final ASR performance by comparing Griffin-Lim algorithm with our modified LPCNet. An external language model allows our approach to reach the quality of a comparable supervised setup and outperform a semi-supervised setup (both on test-clean). We establish a state-of-the-art result for end-to-end ASR trained on LibriSpeech train-clean-100 set with WER 4.3% on test-clean and 13.5% on test-other.