 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Joint Modeling of Code-Switched and Monolingual ASR via Conditional Factorization
Nov 29, 2021
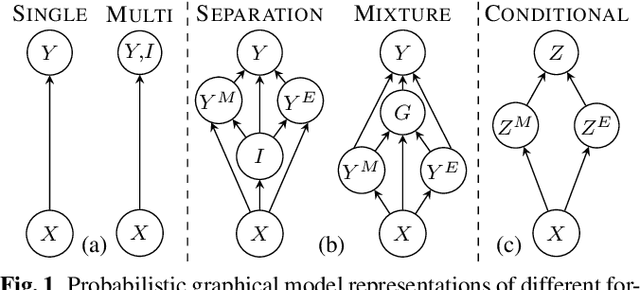
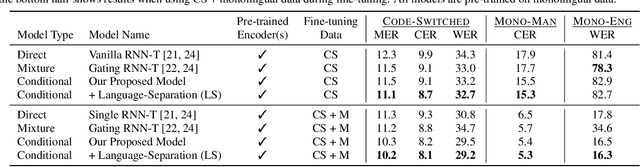
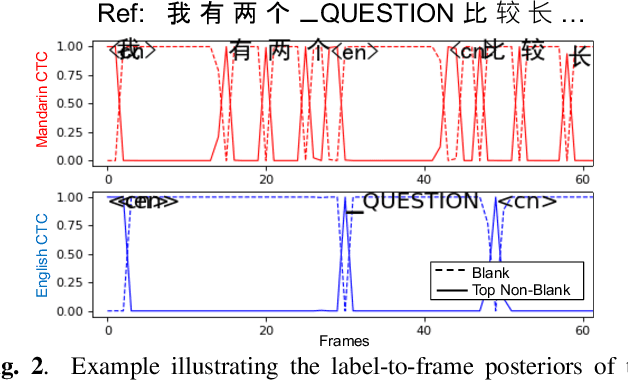
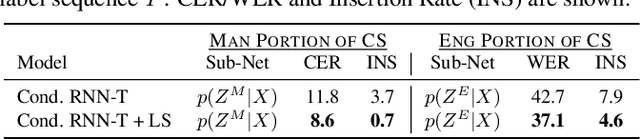
Conversational bilingual speech encompasses three types of utterances: two purely monolingual types and one intra-sententially code-switched type. In this work, we propose a general framework to jointly model the likelihoods of the monolingual and code-switch sub-tasks that comprise bilingual speech recognition. By defining the monolingual sub-tasks with label-to-frame synchronization, our joint modeling framework can be conditionally factorized such that the final bilingual output, which may or may not be code-switched, is obtained given only monolingual information. We show that this conditionally factorized joint framework can be modeled by an end-to-end differentiable neural network. We demonstrate the efficacy of our proposed model on bilingual Mandarin-English speech recognition across both monolingual and code-switched corpora.
A study on cross-corpus speech emotion recognition and data augmentation
Jan 10, 2022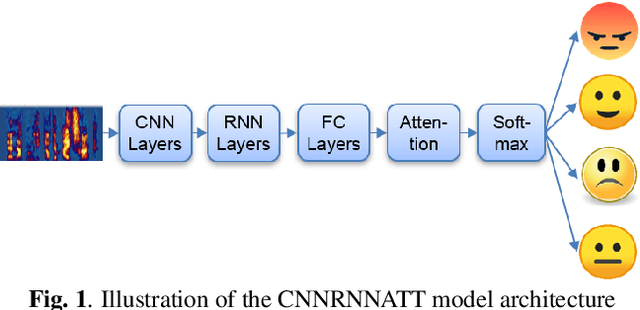
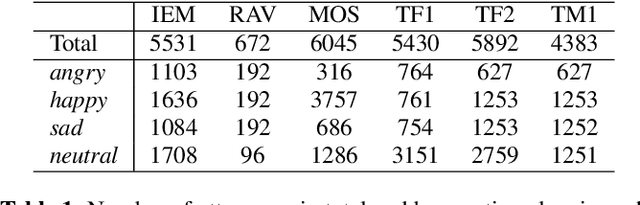

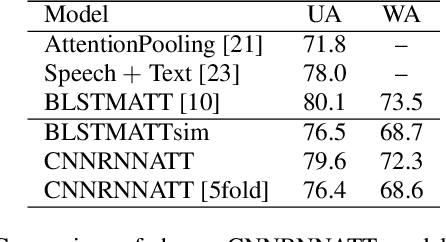
Models that can handle a wide range of speakers and acoustic conditions are essential in speech emotion recognition (SER). Often, these models tend to show mixed results when presented with speakers or acoustic conditions that were not visible during training. This paper investigates the impact of cross-corpus data complementation and data augmentation on the performance of SER models in matched (test-set from same corpus) and mismatched (test-set from different corpus) conditions. Investigations using six emotional speech corpora that include single and multiple speakers as well as variations in emotion style (acted, elicited, natural) and recording conditions are presented. Observations show that, as expected, models trained on single corpora perform best in matched conditions while performance decreases between 10-40% in mismatched conditions, depending on corpus specific features. Models trained on mixed corpora can be more stable in mismatched contexts, and the performance reductions range from 1 to 8% when compared with single corpus models in matched conditions. Data augmentation yields additional gains up to 4% and seem to benefit mismatched conditions more than matched ones.
Speaker Attentive Speech Emotion Recognition
Apr 15, 2021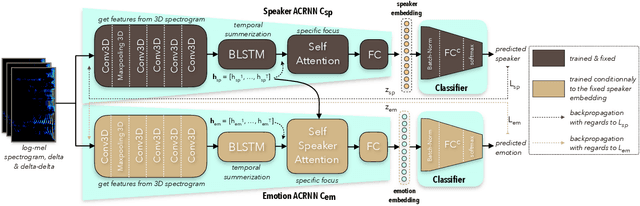
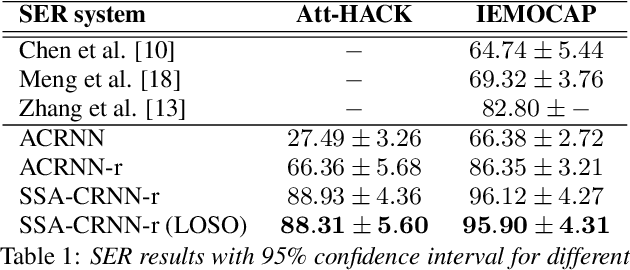
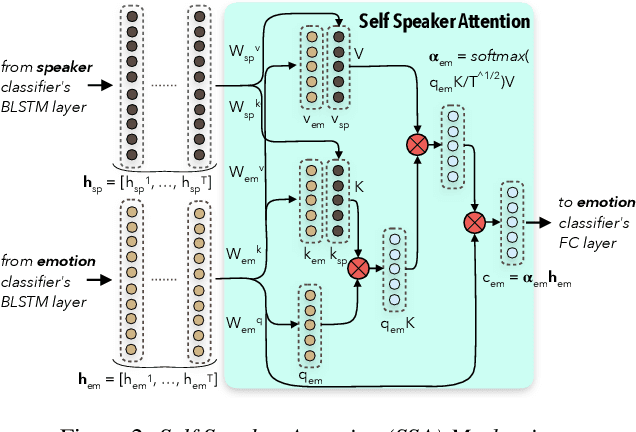
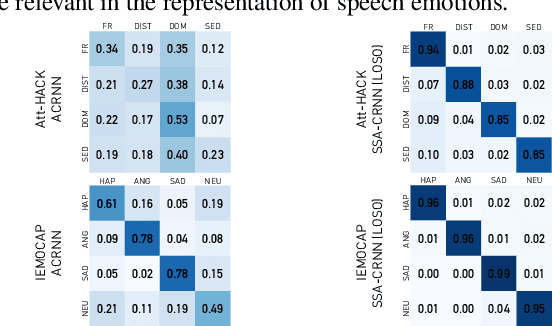
Speech Emotion Recognition (SER) task has known significant improvements over the last years with the advent of Deep Neural Networks (DNNs). However, even the most successful methods are still rather failing when adaptation to specific speakers and scenarios is needed, inevitably leading to poorer performances when compared to humans. In this paper, we present novel work based on the idea of teaching the emotion recognition network about speaker identity. Our system is a combination of two ACRNN classifiers respectively dedicated to speaker and emotion recognition. The first informs the latter through a Self Speaker Attention (SSA) mechanism that is shown to considerably help to focus on emotional information of the speech signal. Experiments on social attitudes database Att-HACK and IEMOCAP corpus demonstrate the effectiveness of the proposed method and achieve the state-of-the-art performance in terms of unweighted average recall.
MobiVSR: A Visual Speech Recognition Solution for Mobile Devices
Jun 05, 2019
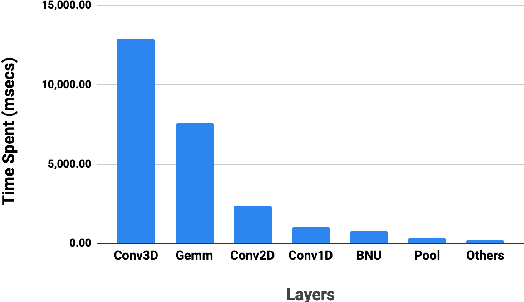
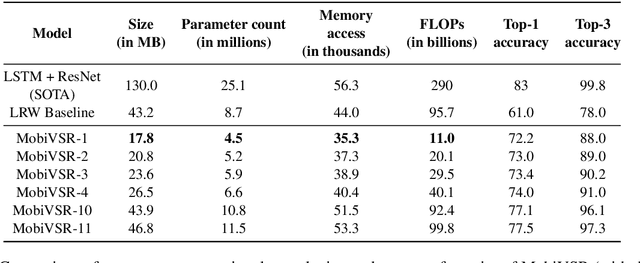
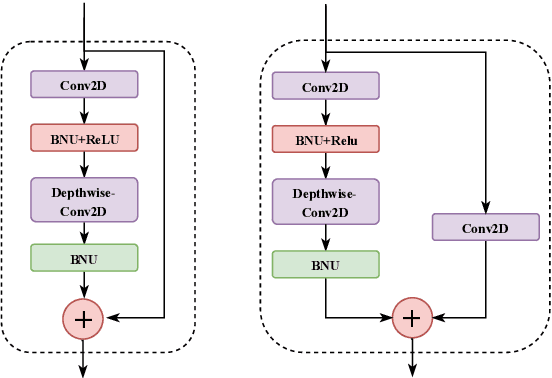
Visual speech recognition (VSR) is the task of recognizing spoken language from video input only, without any audio. VSR has many applications as an assistive technology, especially if it could be deployed in mobile devices and embedded systems. The need of intensive computational resources and large memory footprint are two of the major obstacles in developing neural network models for VSR in a resource constrained environment. We propose a novel end-to-end deep neural network architecture for word level VSR called MobiVSR with a design parameter that aids in balancing the model's accuracy and parameter count. We use depthwise-separable 3D convolution for the first time in the domain of VSR and show how it makes our model efficient. MobiVSR achieves an accuracy of 73\% on a challenging Lip Reading in the Wild dataset with 6 times fewer parameters and 20 times lesser memory footprint than the current state of the art. MobiVSR can also be compressed to 6 MB by applying post training quantization.
Distilling a Pretrained Language Model to a Multilingual ASR Model
Jun 25, 2022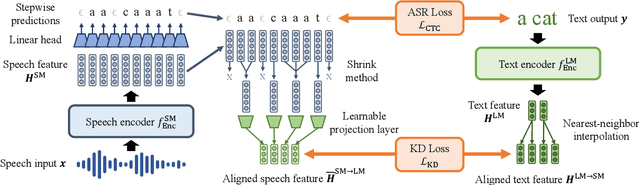
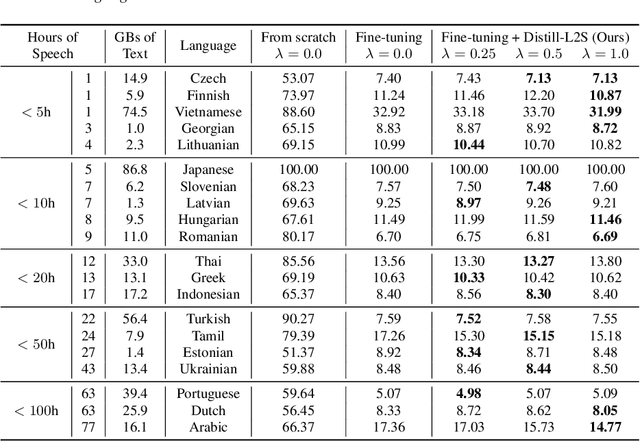
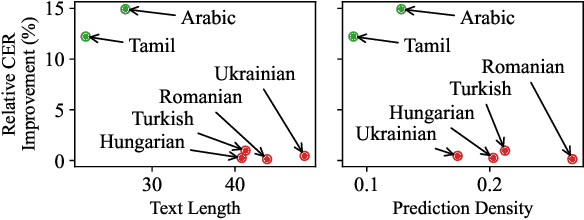
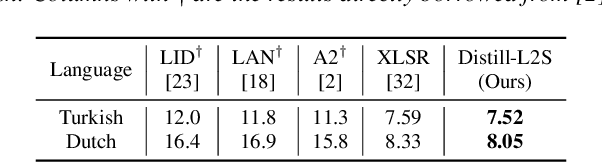
Multilingual speech data often suffer from long-tailed language distribution, resulting in performance degradation. However, multilingual text data is much easier to obtain, yielding a more useful general language model. Hence, we are motivated to distill the rich knowledge embedded inside a well-trained teacher text model to the student speech model. We propose a novel method called the Distilling a Language model to a Speech model (Distill-L2S), which aligns the latent representations of two different modalities. The subtle differences are handled by the shrinking mechanism, nearest-neighbor interpolation, and a learnable linear projection layer. We demonstrate the effectiveness of our distillation method by applying it to the multilingual automatic speech recognition (ASR) task. We distill the transformer-based cross-lingual language model (InfoXLM) while fine-tuning the large-scale multilingual ASR model (XLSR-wav2vec 2.0) for each language. We show the superiority of our method on 20 low-resource languages of the CommonVoice dataset with less than 100 hours of speech data.
Detecting Adversarial Examples in Batches -- a geometrical approach
Jun 17, 2022

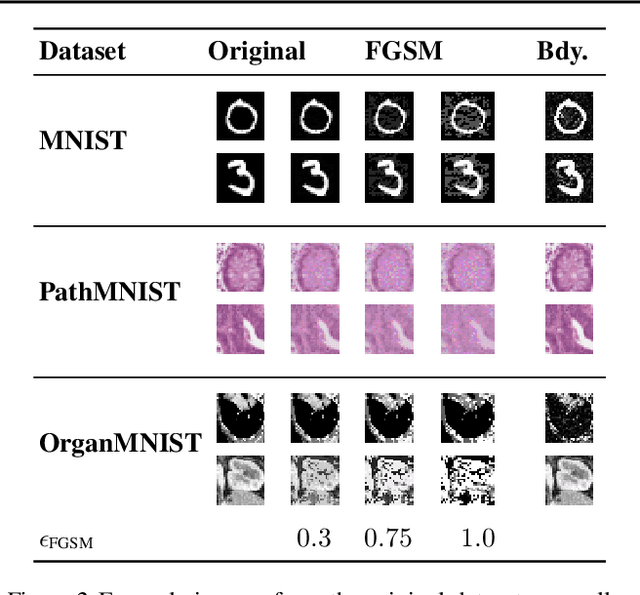

Many deep learning methods have successfully solved complex tasks in computer vision and speech recognition applications. Nonetheless, the robustness of these models has been found to be vulnerable to perturbed inputs or adversarial examples, which are imperceptible to the human eye, but lead the model to erroneous output decisions. In this study, we adapt and introduce two geometric metrics, density and coverage, and evaluate their use in detecting adversarial samples in batches of unseen data. We empirically study these metrics using MNIST and two real-world biomedical datasets from MedMNIST, subjected to two different adversarial attacks. Our experiments show promising results for both metrics to detect adversarial examples. We believe that his work can lay the ground for further study on these metrics' use in deployed machine learning systems to monitor for possible attacks by adversarial examples or related pathologies such as dataset shift.
HAPI: A Large-scale Longitudinal Dataset of Commercial ML API Predictions
Sep 18, 2022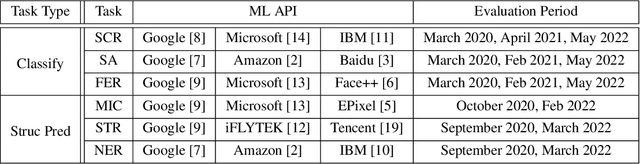
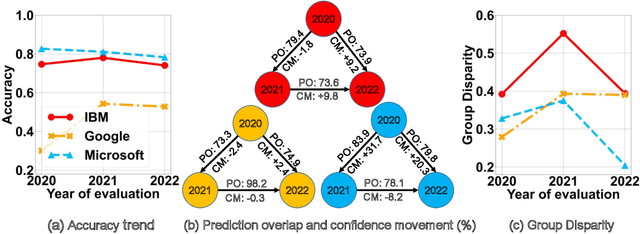
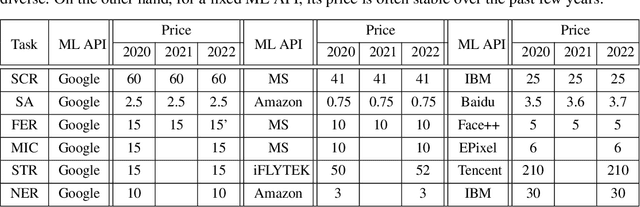
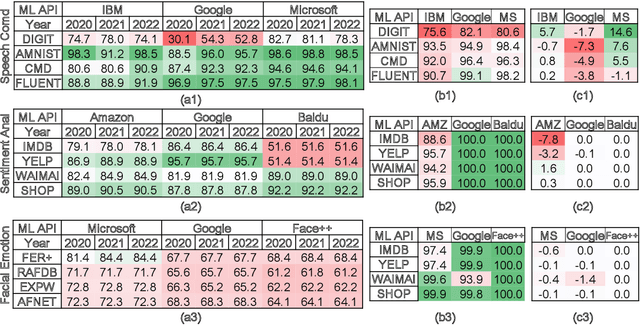
Commercial ML APIs offered by providers such as Google, Amazon and Microsoft have dramatically simplified ML adoption in many applications. Numerous companies and academics pay to use ML APIs for tasks such as object detection, OCR and sentiment analysis. Different ML APIs tackling the same task can have very heterogeneous performance. Moreover, the ML models underlying the APIs also evolve over time. As ML APIs rapidly become a valuable marketplace and a widespread way to consume machine learning, it is critical to systematically study and compare different APIs with each other and to characterize how APIs change over time. However, this topic is currently underexplored due to the lack of data. In this paper, we present HAPI (History of APIs), a longitudinal dataset of 1,761,417 instances of commercial ML API applications (involving APIs from Amazon, Google, IBM, Microsoft and other providers) across diverse tasks including image tagging, speech recognition and text mining from 2020 to 2022. Each instance consists of a query input for an API (e.g., an image or text) along with the API's output prediction/annotation and confidence scores. HAPI is the first large-scale dataset of ML API usages and is a unique resource for studying ML-as-a-service (MLaaS). As examples of the types of analyses that HAPI enables, we show that ML APIs' performance change substantially over time--several APIs' accuracies dropped on specific benchmark datasets. Even when the API's aggregate performance stays steady, its error modes can shift across different subtypes of data between 2020 and 2022. Such changes can substantially impact the entire analytics pipelines that use some ML API as a component. We further use HAPI to study commercial APIs' performance disparities across demographic subgroups over time. HAPI can stimulate more research in the growing field of MLaaS.
Lightweight and Efficient End-to-End Speech Recognition Using Low-Rank Transformer
Oct 30, 2019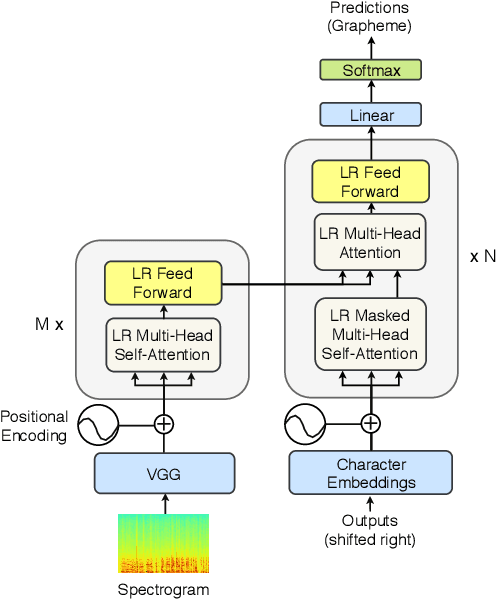
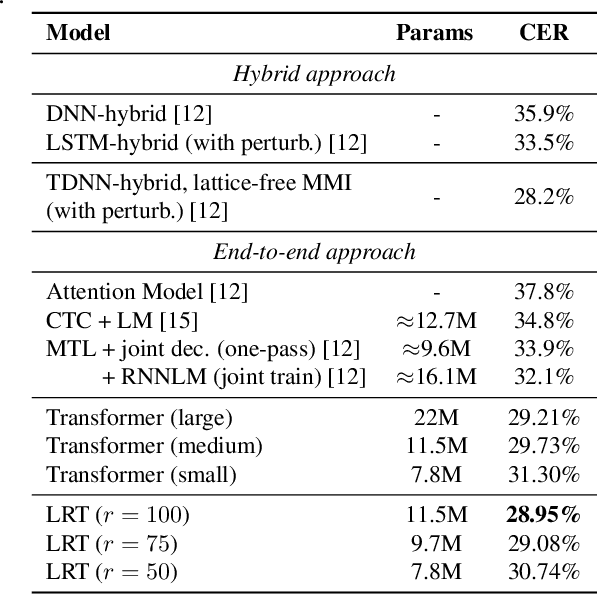
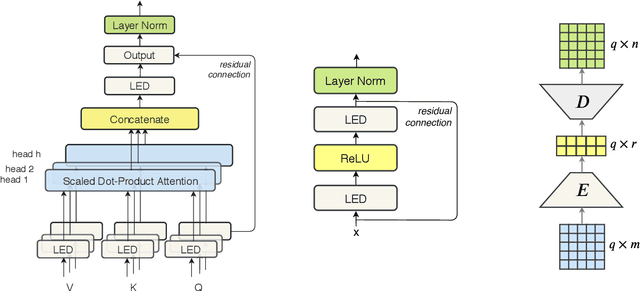
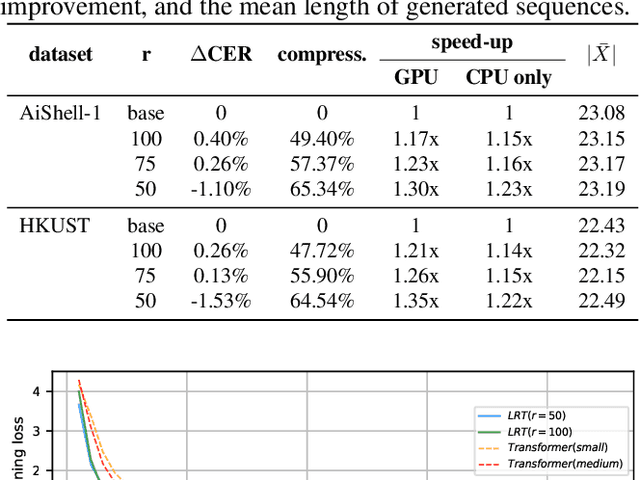
High performing deep neural networks come at the cost of computational complexity that limits its practicality for deployment on portable devices. We propose Low-Rank Transformer (LRT), a memory-efficient and fast neural architecture that significantly reduces the parameters and boosts the speed in training and inference for end-to-end speech recognition. Our approach reduces the number of parameters of the network by more than 50% parameters and speed-up the inference time by around 1.26x compared to the baseline transformer model. The experiments show that LRT models generalize better and yield lower error rates on both validation and test sets compared to the uncompressed transformer model. LRT models outperform existing works on several datasets in an end-to-end setting without using any external language model and acoustic data.
End-to-end contextual asr based on posterior distribution adaptation for hybrid ctc/attention system
Feb 18, 2022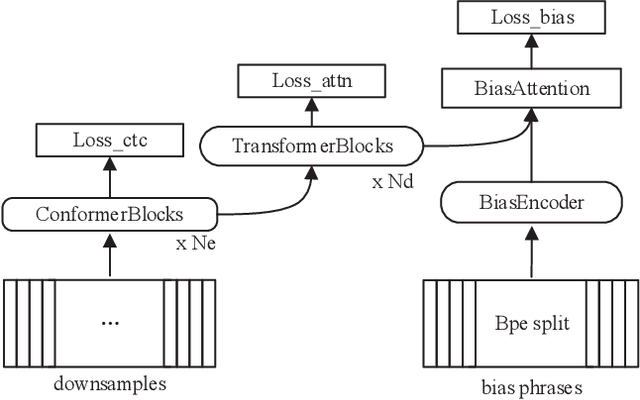
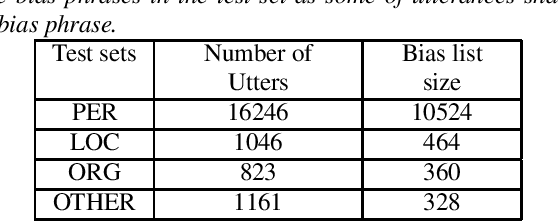
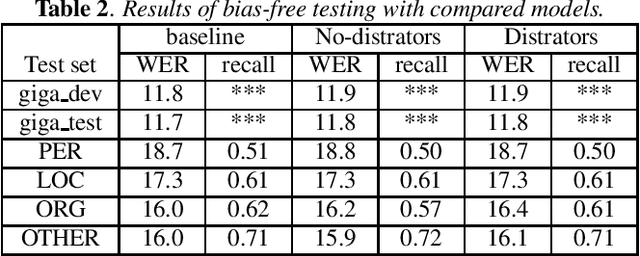
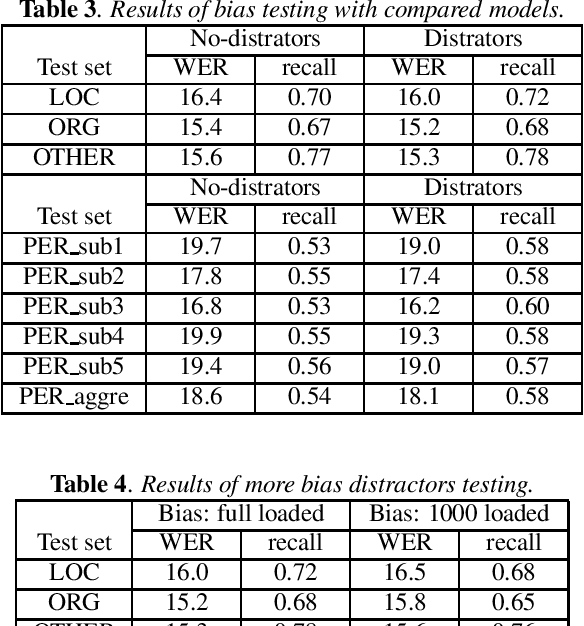
End-to-end (E2E) speech recognition architectures assemble all components of traditional speech recognition system into a single model. Although it simplifies ASR system, it introduces contextual ASR drawback: the E2E model has worse performance on utterances containing infrequent proper nouns. In this work, we propose to add a contextual bias attention (CBA) module to attention based encoder decoder (AED) model to improve its ability of recognizing the contextual phrases. Specifically, CBA utilizes the context vector of source attention in decoder to attend to a specific bias embedding. Jointly learned with the basic AED parameters, CBA can tell the model when and where to bias its output probability distribution. At inference stage, a list of bias phrases is preloaded and we adapt the posterior distributions of both CTC and attention decoder according to the attended bias phrase of CBA. We evaluate the proposed method on GigaSpeech and achieve a consistent relative improvement on recall rate of bias phrases ranging from 15% to 28% compared to the baseline model. Meanwhile, our method shows a strong anti-bias ability as the performance on general tests only degrades 1.7% even 2,000 bias phrases are present.
Streaming End-to-end Speech Recognition For Mobile Devices
Nov 15, 2018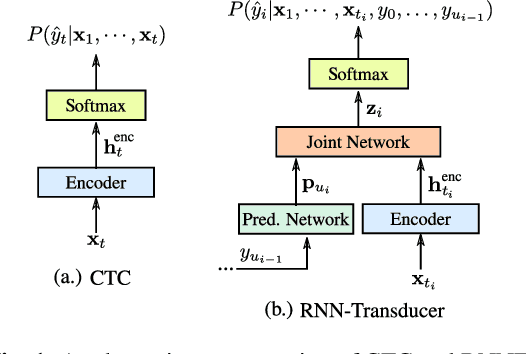
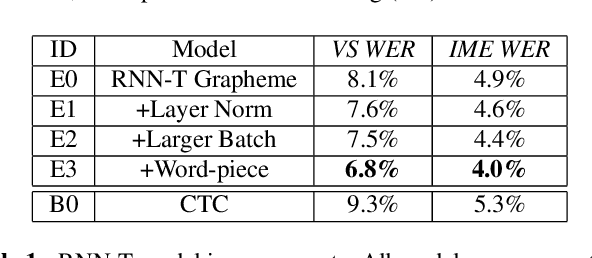
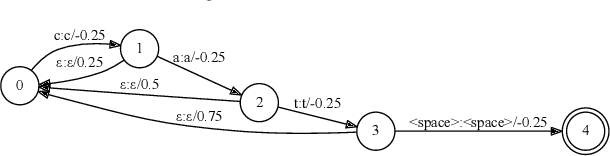
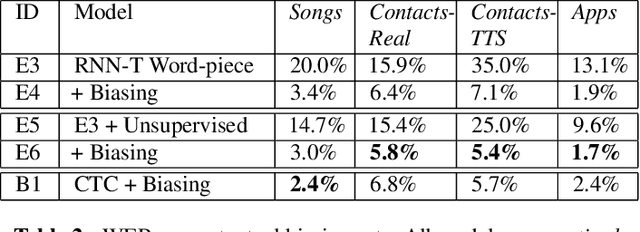
End-to-end (E2E) models, which directly predict output character sequences given input speech, are good candidates for on-device speech recognition. E2E models, however, present numerous challenges: In order to be truly useful, such models must decode speech utterances in a streaming fashion, in real time; they must be robust to the long tail of use cases; they must be able to leverage user-specific context (e.g., contact lists); and above all, they must be extremely accurate. In this work, we describe our efforts at building an E2E speech recognizer using a recurrent neural network transducer. In experimental evaluations, we find that the proposed approach can outperform a conventional CTC-based model in terms of both latency and accuracy in a number of evaluation categories.