 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Character-Aware Attention-Based End-to-End Speech Recognition
Jan 06, 2020

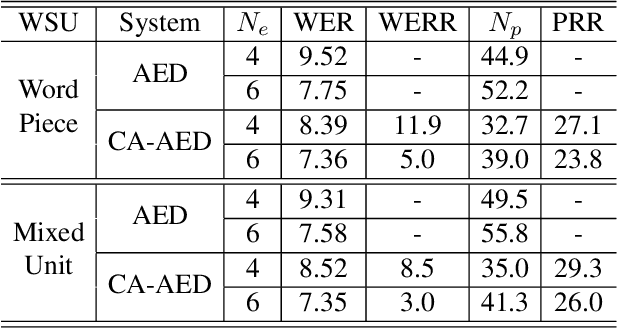
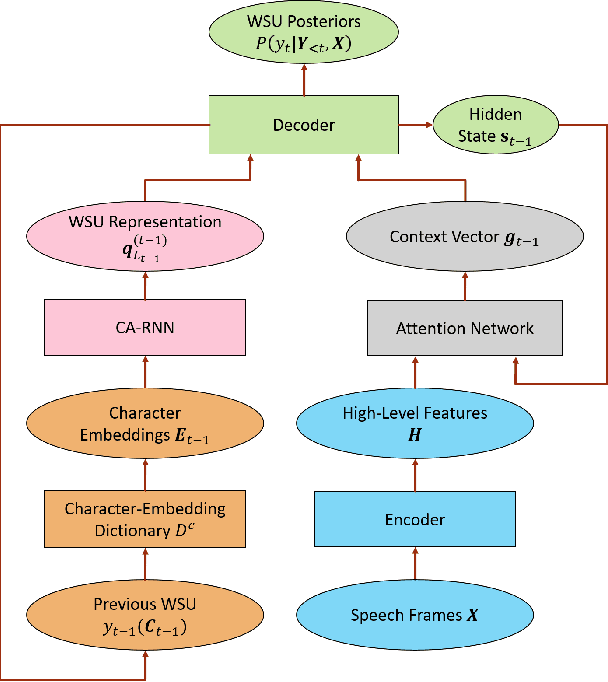
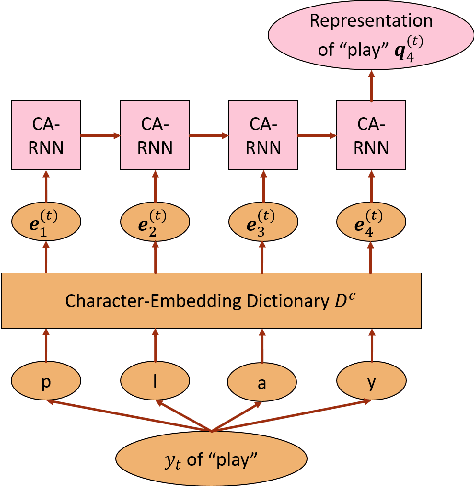
Predicting words and subword units (WSUs) as the output has shown to be effective for the attention-based encoder-decoder (AED) model in end-to-end speech recognition. However, as one input to the decoder recurrent neural network (RNN), each WSU embedding is learned independently through context and acoustic information in a purely data-driven fashion. Little effort has been made to explicitly model the morphological relationships among WSUs. In this work, we propose a novel character-aware (CA) AED model in which each WSU embedding is computed by summarizing the embeddings of its constituent characters using a CA-RNN. This WSU-independent CA-RNN is jointly trained with the encoder, the decoder and the attention network of a conventional AED to predict WSUs. With CA-AED, the embeddings of morphologically similar WSUs are naturally and directly correlated through the CA-RNN in addition to the semantic and acoustic relations modeled by a traditional AED. Moreover, CA-AED significantly reduces the model parameters in a traditional AED by replacing the large pool of WSU embeddings with a much smaller set of character embeddings. On a 3400 hours Microsoft Cortana dataset, CA-AED achieves up to 11.9% relative WER improvement over a strong AED baseline with 27.1% fewer model parameters.
* 7 pages, 3 figures, ASRU 2019
Paraformer: Fast and Accurate Parallel Transformer for Non-autoregressive End-to-End Speech Recognition
Jun 20, 2022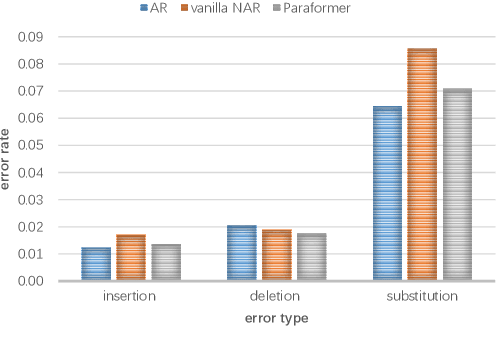
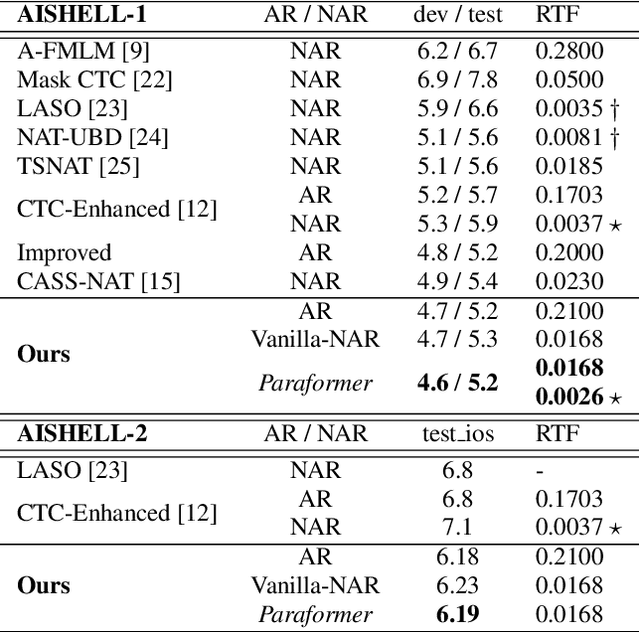
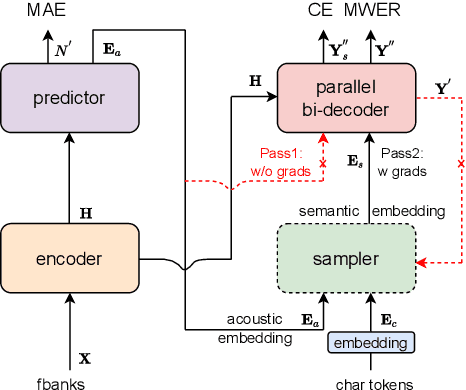
Transformers have recently dominated the ASR field. Although able to yield good performance, they involve an autoregressive (AR) decoder to generate tokens one by one, which is computationally inefficient. To speed up inference, non-autoregressive (NAR) methods, e.g. single-step NAR, were designed, to enable parallel generation. However, due to an independence assumption within the output tokens, performance of single-step NAR is inferior to that of AR models, especially with a large-scale corpus. There are two challenges to improving single-step NAR: Firstly to accurately predict the number of output tokens and extract hidden variables; secondly, to enhance modeling of interdependence between output tokens. To tackle both challenges, we propose a fast and accurate parallel transformer, termed Paraformer. This utilizes a continuous integrate-and-fire based predictor to predict the number of tokens and generate hidden variables. A glancing language model (GLM) sampler then generates semantic embeddings to enhance the NAR decoder's ability to model context interdependence. Finally, we design a strategy to generate negative samples for minimum word error rate training to further improve performance. Experiments using the public AISHELL-1, AISHELL-2 benchmark, and an industrial-level 20,000 hour task demonstrate that the proposed Paraformer can attain comparable performance to the state-of-the-art AR transformer, with more than 10x speedup.
MM-ALT: A Multimodal Automatic Lyric Transcription System
Jul 13, 2022
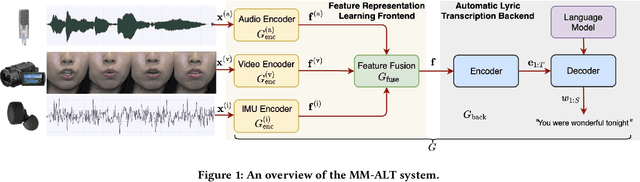
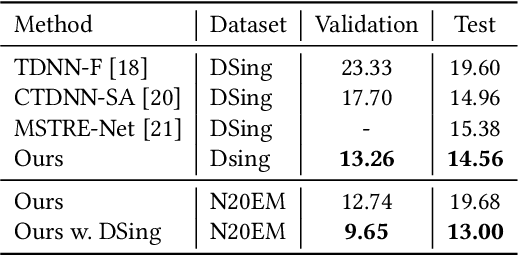
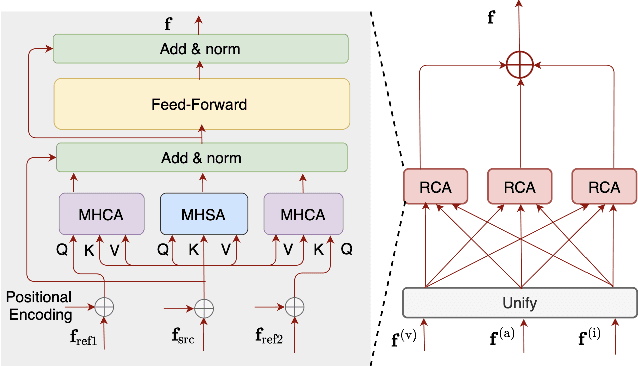
Automatic lyric transcription (ALT) is a nascent field of study attracting increasing interest from both the speech and music information retrieval communities, given its significant application potential. However, ALT with audio data alone is a notoriously difficult task due to instrumental accompaniment and musical constraints resulting in degradation of both the phonetic cues and the intelligibility of sung lyrics. To tackle this challenge, we propose the MultiModal Automatic Lyric Transcription system (MM-ALT), together with a new dataset, N20EM, which consists of audio recordings, videos of lip movements, and inertial measurement unit (IMU) data of an earbud worn by the performing singer. We first adapt the wav2vec 2.0 framework from automatic speech recognition (ASR) to the ALT task. We then propose a video-based ALT method and an IMU-based voice activity detection (VAD) method. In addition, we put forward the Residual Cross Attention (RCA) mechanism to fuse data from the three modalities (i.e., audio, video, and IMU). Experiments show the effectiveness of our proposed MM-ALT system, especially in terms of noise robustness.
Multilingual Alzheimer's Dementia Recognition through Spontaneous Speech: a Signal Processing Grand Challenge
Jan 13, 2023This Signal Processing Grand Challenge (SPGC) targets a difficult automatic prediction problem of societal and medical relevance, namely, the detection of Alzheimer's Dementia (AD). Participants were invited to employ signal processing and machine learning methods to create predictive models based on spontaneous speech data. The Challenge has been designed to assess the extent to which predictive models built based on speech in one language (English) generalise to another language (Greek). To the best of our knowledge no work has investigated acoustic features of the speech signal in multilingual AD detection. Our baseline system used conventional machine learning algorithms with Active Data Representation of acoustic features, achieving accuracy of 73.91% on AD detection, and 4.95 root mean squared error on cognitive score prediction.
Open Source Automatic Speech Recognition for German
Jul 26, 2018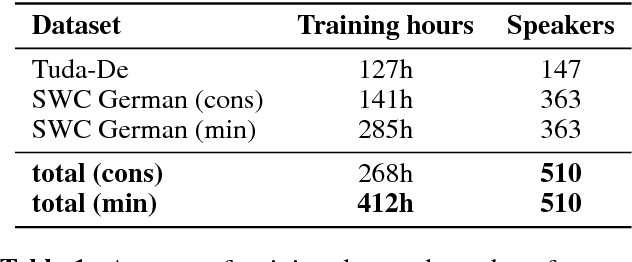
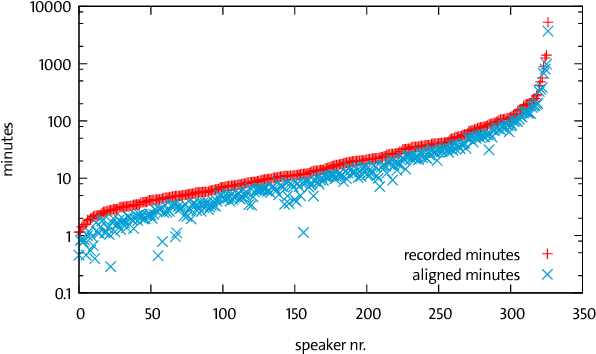
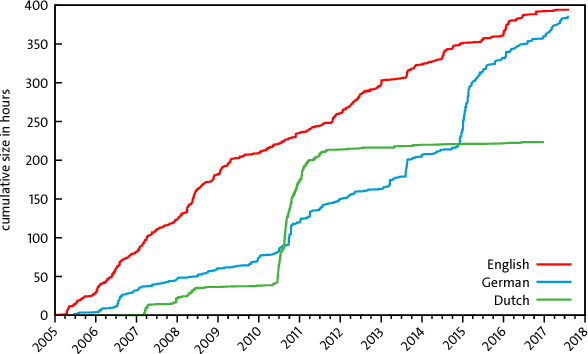
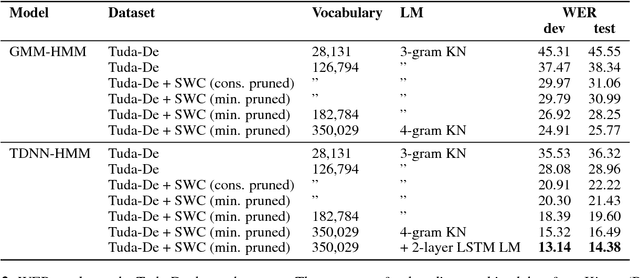
High quality Automatic Speech Recognition (ASR) is a prerequisite for speech-based applications and research. While state-of-the-art ASR software is freely available, the language dependent acoustic models are lacking for languages other than English, due to the limited amount of freely available training data. We train acoustic models for German with Kaldi on two datasets, which are both distributed under a Creative Commons license. The resulting model is freely redistributable, lowering the cost of entry for German ASR. The models are trained on a total of 412 hours of German read speech data and we achieve a relative word error reduction of 26% by adding data from the Spoken Wikipedia Corpus to the previously best freely available German acoustic model recipe and dataset. Our best model achieves a word error rate of 14.38 on the Tuda-De test set. Due to the large amount of speakers and the diversity of topics included in the training data, our model is robust against speaker variation and topic shift.
Mitigating the Impact of Speech Recognition Errors on Chatbot using Sequence-to-Sequence Model
Dec 02, 2017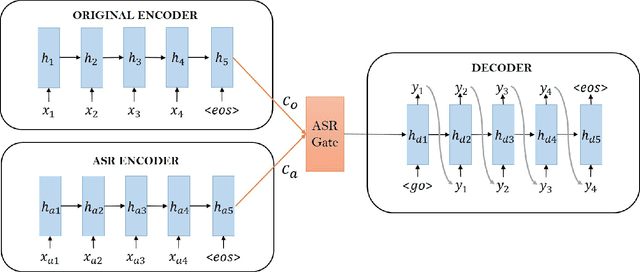

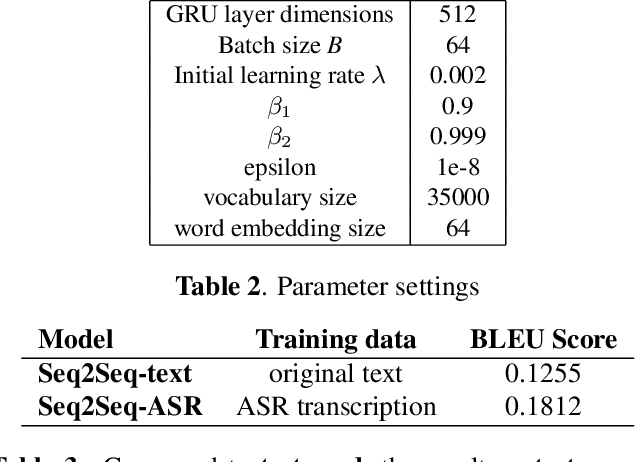
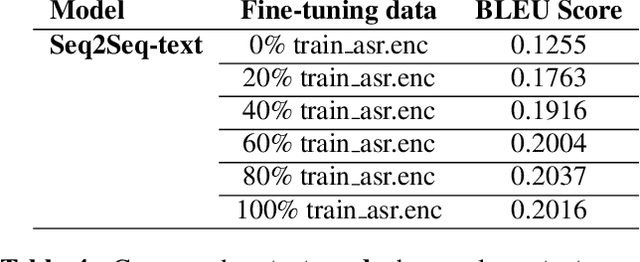
We apply sequence-to-sequence model to mitigate the impact of speech recognition errors on open domain end-to-end dialog generation. We cast the task as a domain adaptation problem where ASR transcriptions and original text are in two different domains. In this paper, our proposed model includes two individual encoders for each domain data and make their hidden states similar to ensure the decoder predict the same dialog text. The method shows that the sequence-to-sequence model can learn the ASR transcriptions and original text pair having the same meaning and eliminate the speech recognition errors. Experimental results on Cornell movie dialog dataset demonstrate that the domain adaption system help the spoken dialog system generate more similar responses with the original text answers.
A Deep Dive into Deep Cluster
Jul 24, 2022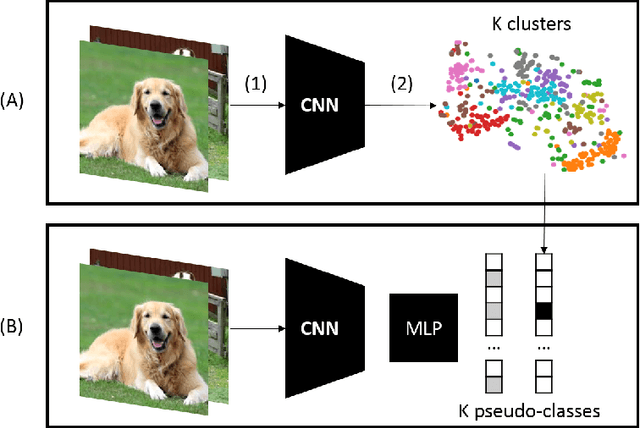

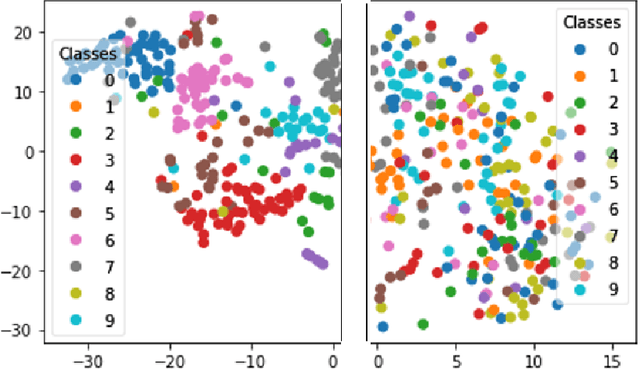
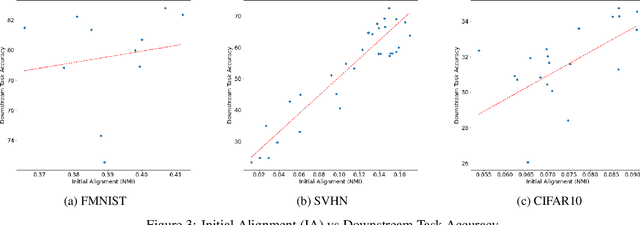
Deep Learning has demonstrated a significant improvement against traditional machine learning approaches in different domains such as image and speech recognition. Their success on benchmark datasets is transferred to the real-world through pretrained models by practitioners. Pretraining visual models using supervised learning requires a significant amount of expensive data annotation. To tackle this limitation, DeepCluster - a simple and scalable unsupervised pretraining of visual representations - has been proposed. However, the underlying work of the model is not yet well understood. In this paper, we analyze DeepCluster internals and exhaustively evaluate the impact of various hyperparameters over a wide range of values on three different datasets. Accordingly, we propose an explanation of why the algorithm works in practice. We also show that DeepCluster convergence and performance highly depend on the interplay between the quality of the randomly initialized filters of the convolutional layer and the selected number of clusters. Furthermore, we demonstrate that continuous clustering is not critical for DeepCluster convergence. Therefore, early stopping of the clustering phase will reduce the training time and allow the algorithm to scale to large datasets. Finally, we derive plausible hyperparameter selection criteria in a semi-supervised setting.
Improving the Training Recipe for a Robust Conformer-based Hybrid Model
Jun 26, 2022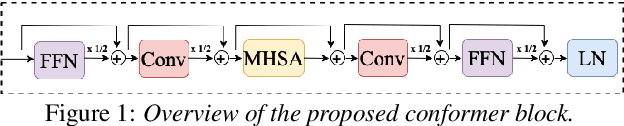
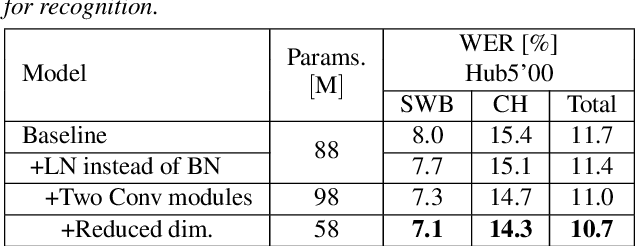
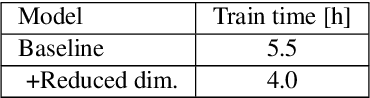
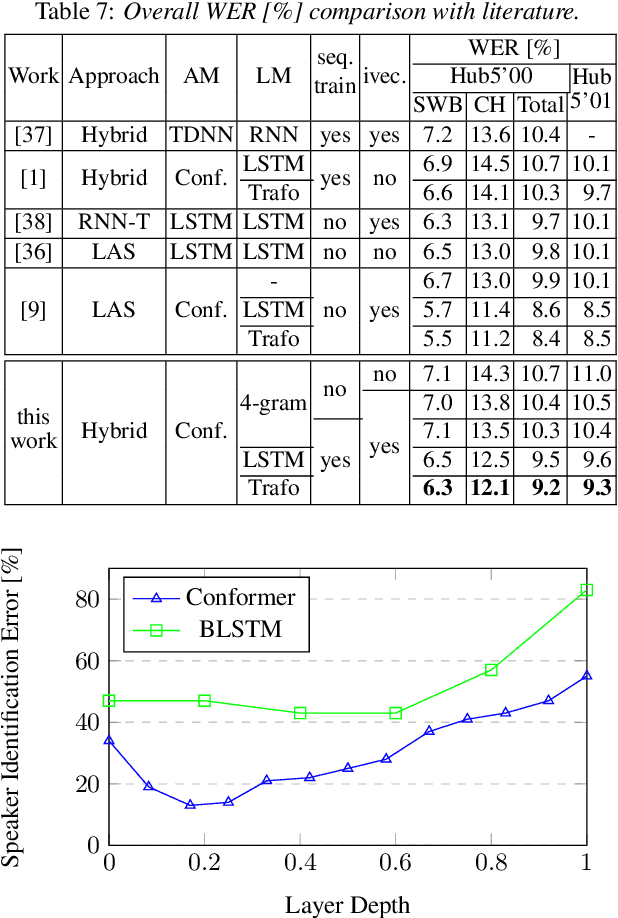
Speaker adaptation is important to build robust automatic speech recognition (ASR) systems. In this work, we investigate various methods for speaker adaptive training (SAT) based on feature-space approaches for a conformer-based acoustic model (AM) on the Switchboard 300h dataset. We propose a method, called Weighted-Simple-Add, which adds weighted speaker information vectors to the input of the multi-head self-attention module of the conformer AM. Using this method for SAT, we achieve 3.5% and 4.5% relative improvement in terms of WER on the CallHome part of Hub5'00 and Hub5'01 respectively. Moreover, we build on top of our previous work where we proposed a novel and competitive training recipe for a conformer-based hybrid AM. We extend and improve this recipe where we achieve 11% relative improvement in terms of word-error-rate (WER) on Switchboard 300h Hub5'00 dataset. We also make this recipe efficient by reducing the total number of parameters by 34% relative.
Large-Scale Mixed-Bandwidth Deep Neural Network Acoustic Modeling for Automatic Speech Recognition
Jul 10, 2019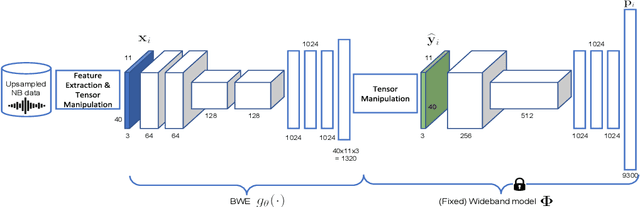

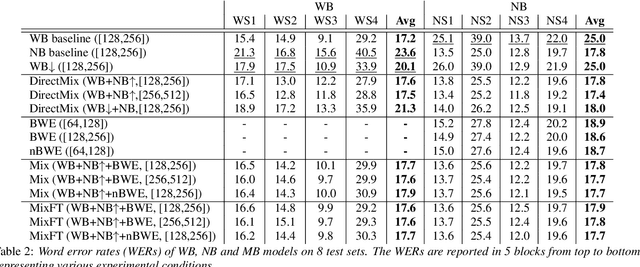
In automatic speech recognition (ASR), wideband (WB) and narrowband (NB) speech signals with different sampling rates typically use separate acoustic models. Therefore mixed-bandwidth (MB) acoustic modeling has important practical values for ASR system deployment. In this paper, we extensively investigate large-scale MB deep neural network acoustic modeling for ASR using 1,150 hours of WB data and 2,300 hours of NB data. We study various MB strategies including downsampling, upsampling and bandwidth extension for MB acoustic modeling and evaluate their performance on 8 diverse WB and NB test sets from various application domains. To deal with the large amounts of training data, distributed training is carried out on multiple GPUs using synchronous data parallelism.
Meta Auxiliary Learning for Low-resource Spoken Language Understanding
Jun 26, 2022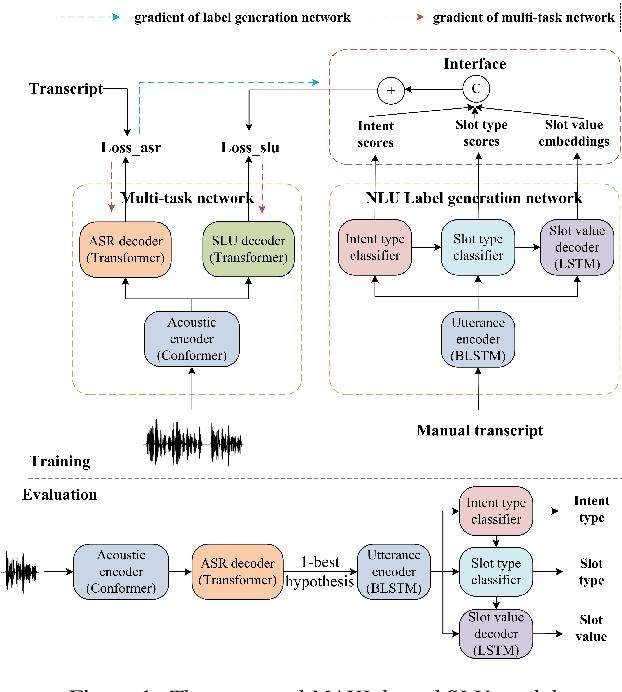

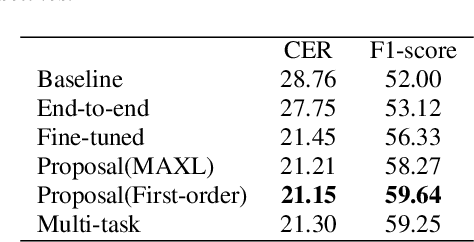

Spoken language understanding (SLU) treats automatic speech recognition (ASR) and natural language understanding (NLU) as a unified task and usually suffers from data scarcity. We exploit an ASR and NLU joint training method based on meta auxiliary learning to improve the performance of low-resource SLU task by only taking advantage of abundant manual transcriptions of speech data. One obvious advantage of such method is that it provides a flexible framework to implement a low-resource SLU training task without requiring access to any further semantic annotations. In particular, a NLU model is taken as label generation network to predict intent and slot tags from texts; a multi-task network trains ASR task and SLU task synchronously from speech; and the predictions of label generation network are delivered to the multi-task network as semantic targets. The efficiency of the proposed algorithm is demonstrated with experiments on the public CATSLU dataset, which produces more suitable ASR hypotheses for the downstream NLU task.