 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Isolated and Ensemble Audio Preprocessing Methods for Detecting Adversarial Examples against Automatic Speech Recognition
Sep 11, 2018
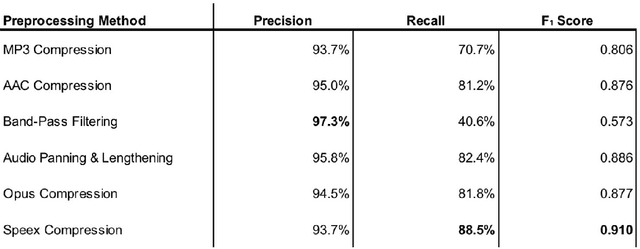
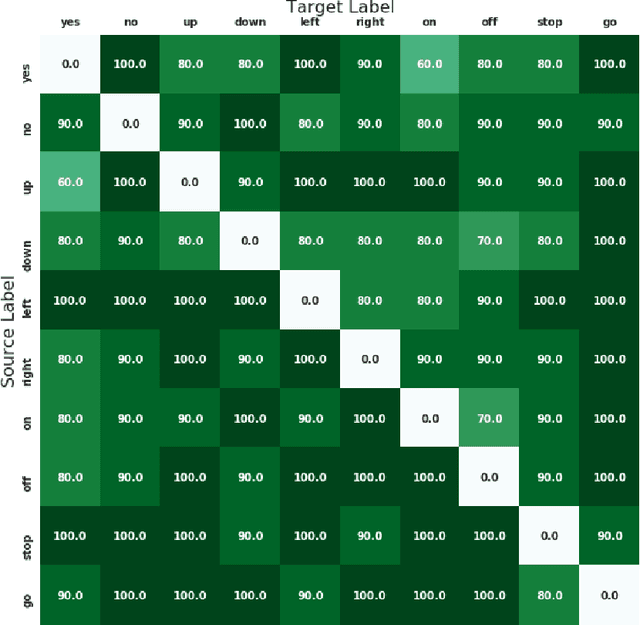
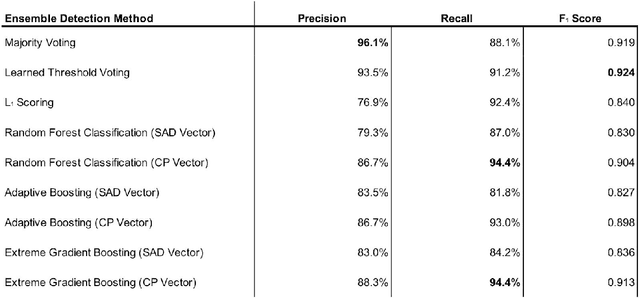

An adversarial attack is an exploitative process in which minute alterations are made to natural inputs, causing the inputs to be misclassified by neural models. In the field of speech recognition, this has become an issue of increasing significance. Although adversarial attacks were originally introduced in computer vision, they have since infiltrated the realm of speech recognition. In 2017, a genetic attack was shown to be quite potent against the Speech Commands Model. Limited-vocabulary speech classifiers, such as the Speech Commands Model, are used in a variety of applications, particularly in telephony; as such, adversarial examples produced by this attack pose as a major security threat. This paper explores various methods of detecting these adversarial examples with combinations of audio preprocessing. One particular combined defense incorporating compressions, speech coding, filtering, and audio panning was shown to be quite effective against the attack on the Speech Commands Model, detecting audio adversarial examples with 93.5% precision and 91.2% recall.
Comparison and Analysis of New Curriculum Criteria for End-to-End ASR
Aug 10, 2022
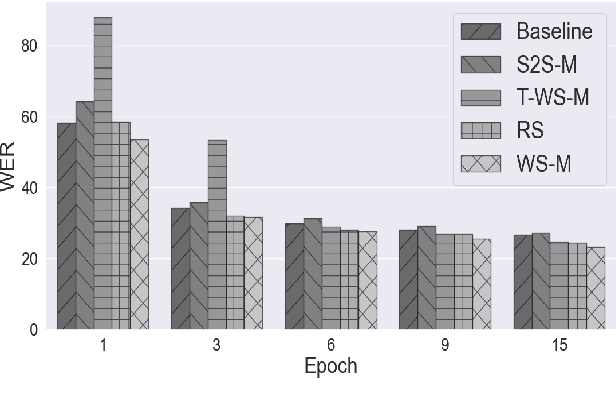
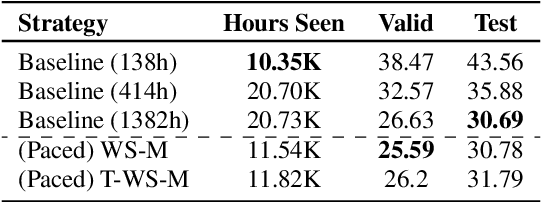
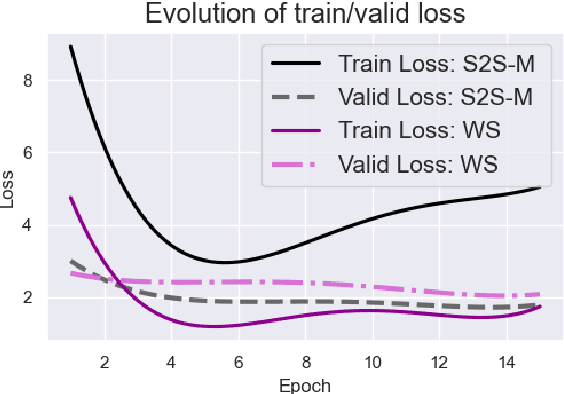
It is common knowledge that the quantity and quality of the training data play a significant role in the creation of a good machine learning model. In this paper, we take it one step further and demonstrate that the way the training examples are arranged is also of crucial importance. Curriculum Learning is built on the observation that organized and structured assimilation of knowledge has the ability to enable faster training and better comprehension. When humans learn to speak, they first try to utter basic phones and then gradually move towards more complex structures such as words and sentences. This methodology is known as Curriculum Learning, and we employ it in the context of Automatic Speech Recognition. We hypothesize that end-to-end models can achieve better performance when provided with an organized training set consisting of examples that exhibit an increasing level of difficulty (i.e. a curriculum). To impose structure on the training set and to define the notion of an easy example, we explored multiple scoring functions that either use feedback from an external neural network or incorporate feedback from the model itself. Empirical results show that with different curriculums we can balance the training times and the network's performance.
Multiple-hypothesis RNN-T Loss for Unsupervised Fine-tuning and Self-training of Neural Transducer
Jul 29, 2022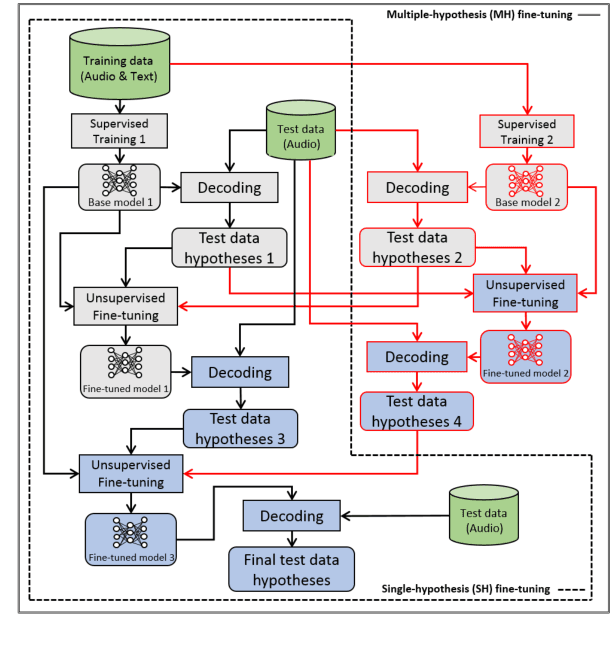
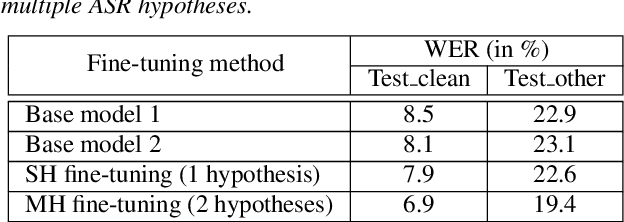
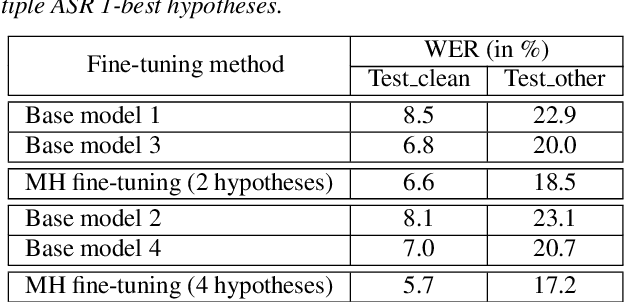
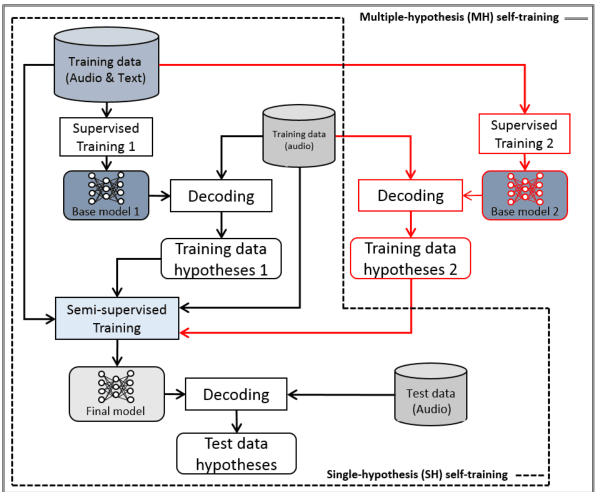
This paper proposes a new approach to perform unsupervised fine-tuning and self-training using unlabeled speech data for recurrent neural network (RNN)-Transducer (RNN-T) end-to-end (E2E) automatic speech recognition (ASR) systems. Conventional systems perform fine-tuning/self-training using ASR hypothesis as the targets when using unlabeled audio data and are susceptible to the ASR performance of the base model. Here in order to alleviate the influence of ASR errors while using unlabeled data, we propose a multiple-hypothesis RNN-T loss that incorporates multiple ASR 1-best hypotheses into the loss function. For the fine-tuning task, ASR experiments on Librispeech show that the multiple-hypothesis approach achieves a relative reduction of 14.2% word error rate (WER) when compared to the single-hypothesis approach, on the test_other set. For the self-training task, ASR models are trained using supervised data from Wall Street Journal (WSJ), Aurora-4 along with CHiME-4 real noisy data as unlabeled data. The multiple-hypothesis approach yields a relative reduction of 3.3% WER on the CHiME-4's single-channel real noisy evaluation set when compared with the single-hypothesis approach.
Resolution limits on visual speech recognition
Oct 03, 2017

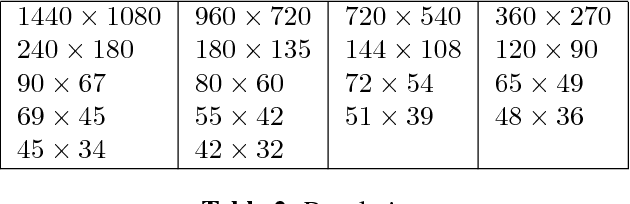
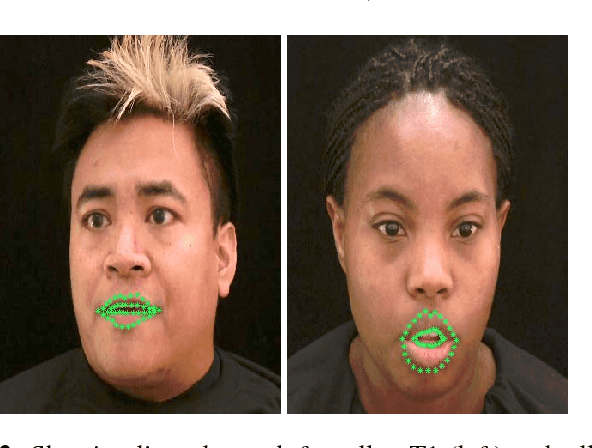
Visual-only speech recognition is dependent upon a number of factors that can be difficult to control, such as: lighting; identity; motion; emotion and expression. But some factors, such as video resolution are controllable, so it is surprising that there is not yet a systematic study of the effect of resolution on lip-reading. Here we use a new data set, the Rosetta Raven data, to train and test recognizers so we can measure the affect of video resolution on recognition accuracy. We conclude that, contrary to common practice, resolution need not be that great for automatic lip-reading. However it is highly unlikely that automatic lip-reading can work reliably when the distance between the bottom of the lower lip and the top of the upper lip is less than four pixels at rest.
Recurrent Deep Stacking Networks for Speech Recognition
Dec 14, 2016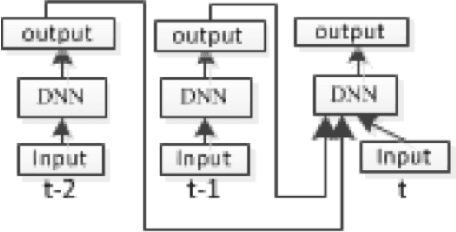
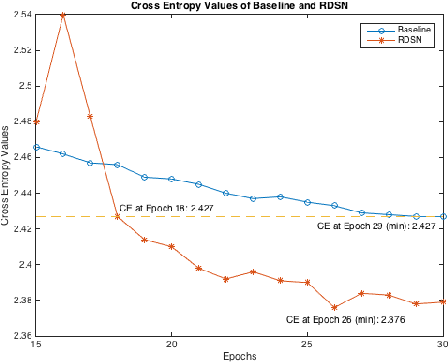
This paper presented our work on applying Recurrent Deep Stacking Networks (RDSNs) to Robust Automatic Speech Recognition (ASR) tasks. In the paper, we also proposed a more efficient yet comparable substitute to RDSN, Bi- Pass Stacking Network (BPSN). The main idea of these two models is to add phoneme-level information into acoustic models, transforming an acoustic model to the combination of an acoustic model and a phoneme-level N-gram model. Experiments showed that RDSN and BPsn can substantially improve the performances over conventional DNNs.
End-to-End Multimodal Speech Recognition
Apr 25, 2018
Transcription or sub-titling of open-domain videos is still a challenging domain for Automatic Speech Recognition (ASR) due to the data's challenging acoustics, variable signal processing and the essentially unrestricted domain of the data. In previous work, we have shown that the visual channel -- specifically object and scene features -- can help to adapt the acoustic model (AM) and language model (LM) of a recognizer, and we are now expanding this work to end-to-end approaches. In the case of a Connectionist Temporal Classification (CTC)-based approach, we retain the separation of AM and LM, while for a sequence-to-sequence (S2S) approach, both information sources are adapted together, in a single model. This paper also analyzes the behavior of CTC and S2S models on noisy video data (How-To corpus), and compares it to results on the clean Wall Street Journal (WSJ) corpus, providing insight into the robustness of both approaches.
ContextNet: Improving Convolutional Neural Networks for Automatic Speech Recognition with Global Context
May 09, 2020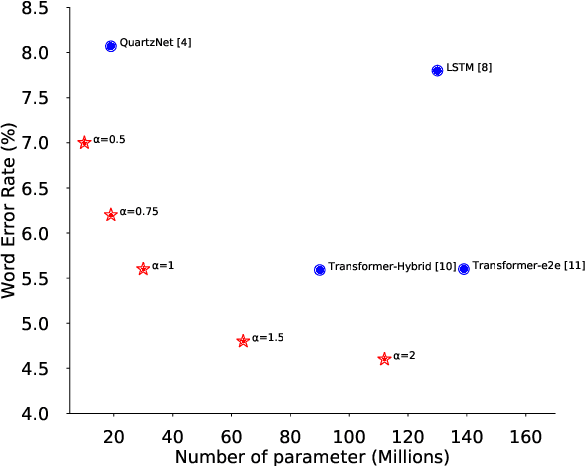
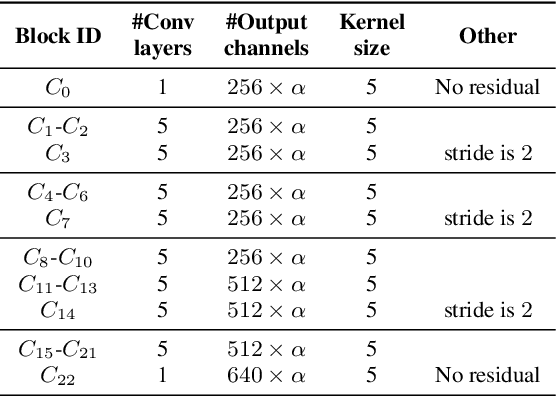
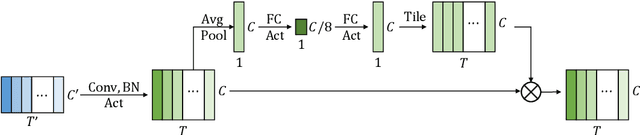
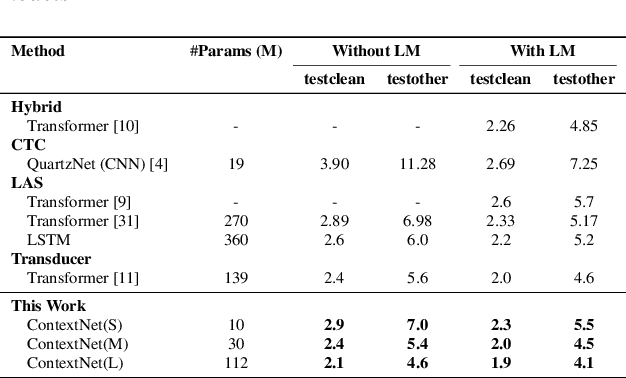
Convolutional neural networks (CNN) have shown promising results for end-to-end speech recognition, albeit still behind other state-of-the-art methods in performance. In this paper, we study how to bridge this gap and go beyond with a novel CNN-RNN-transducer architecture, which we call ContextNet. ContextNet features a fully convolutional encoder that incorporates global context information into convolution layers by adding squeeze-and-excitation modules. In addition, we propose a simple scaling method that scales the widths of ContextNet that achieves good trade-off between computation and accuracy. We demonstrate that on the widely used LibriSpeech benchmark, ContextNet achieves a word error rate (WER) of 2.1%/4.6% without external language model (LM), 1.9%/4.1% with LM and 2.9%/7.0% with only 10M parameters on the clean/noisy LibriSpeech test sets. This compares to the previous best published system of 2.0%/4.6% with LM and 3.9%/11.3% with 20M parameters. The superiority of the proposed ContextNet model is also verified on a much larger internal dataset.
The Marchex 2018 English Conversational Telephone Speech Recognition System
Nov 05, 2018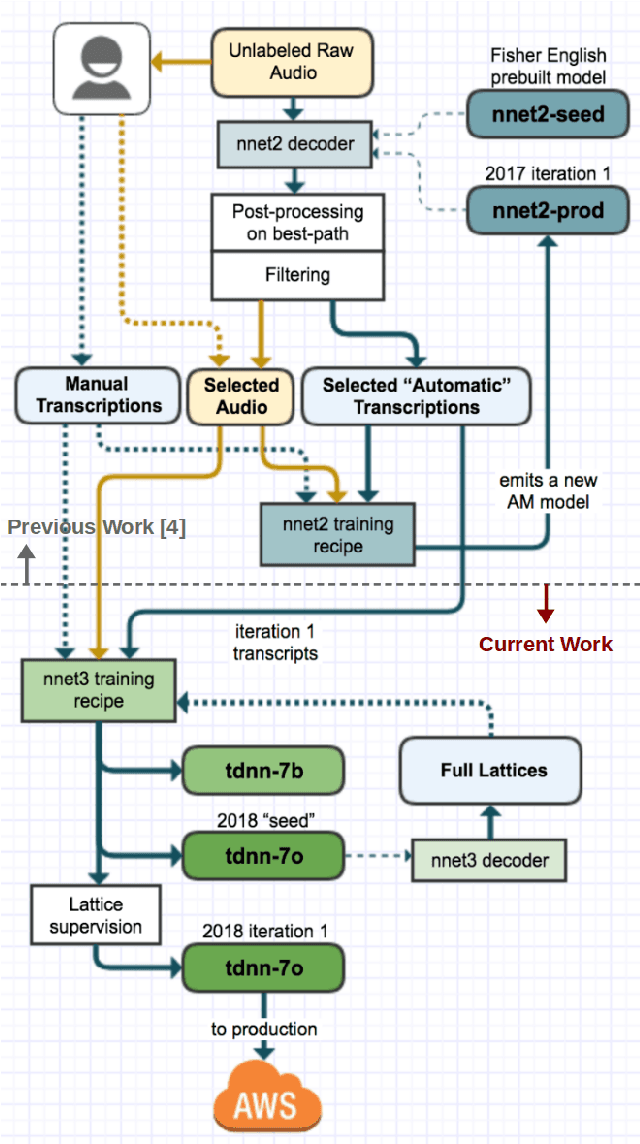
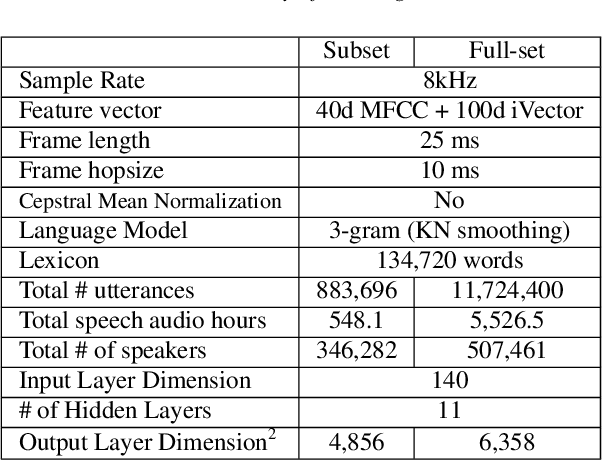
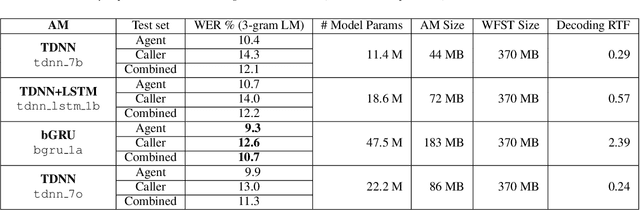

In this paper, we describe recent improvements to the production Marchex speech recognition system for our spontaneous customer-to-business telephone conversations. We outline our semi-supervised lattice-free maximum mutual information (LF-MMI) training process which can supervise over full lattices from unlabeled audio. We also elaborate on production-scale text selection techniques for constructing very large conversational language models (LMs). On Marchex English (ME), a modern evaluation set of conversational North American English, for acoustic modeling we report a 3.3% ({agent, caller}:{3.2%, 3.6%}) reduction in absolute word error rate (WER). For language modeling, we observe a separate {1.3%, 1.2%} point reduction on {agent, caller} utterances respectively over the performance of the 2017 production system.
Big-Little Net: An Efficient Multi-Scale Feature Representation for Visual and Speech Recognition
Jul 10, 2018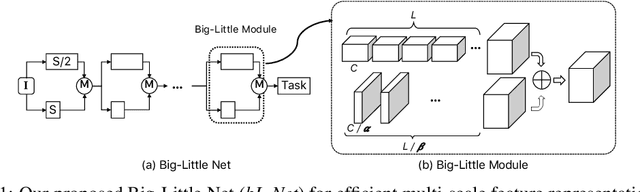
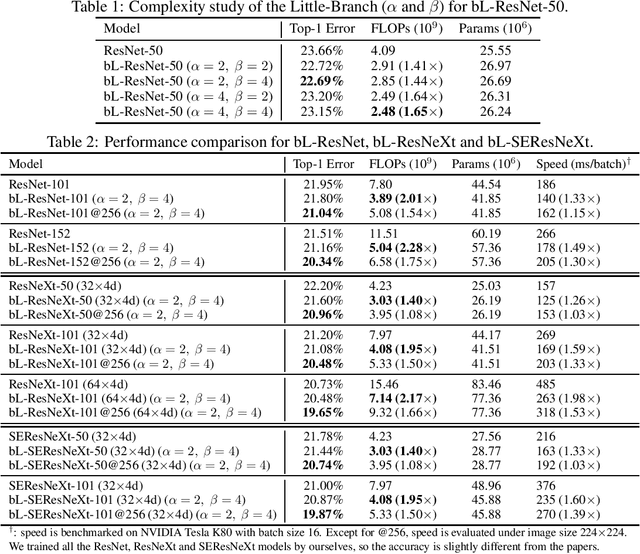
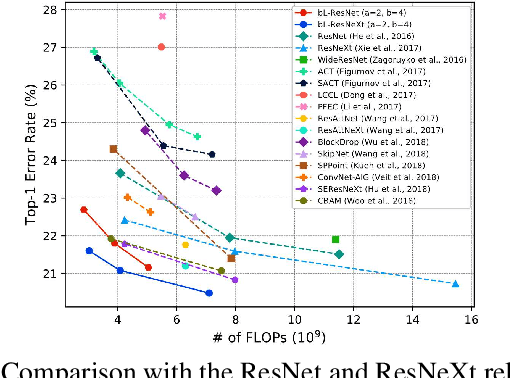
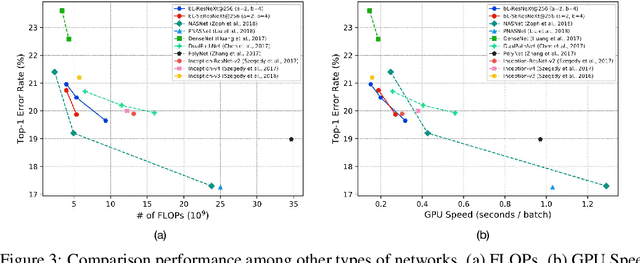
In this paper, we propose a novel Convolutional Neural Network (CNN) architecture for learning multi-scale feature representations with good tradeoffs between speed and accuracy. This is achieved by using a multi-branch network, which has different computational complexity at different branches. Through frequent merging of features from branches at distinct scales, our model obtains multi-scale features while using less computation. The proposed approach demonstrates improvement of model efficiency and performance on both object recognition and speech recognition tasks,using popular architectures including ResNet and ResNeXt. For object recognition, our approach reduces computation by 33% on object recognition while improving accuracy with 0.9%. Furthermore, our model surpasses state-of-the-art CNN acceleration approaches by a large margin in accuracy and FLOPs reduction. On the task of speech recognition, our proposed multi-scale CNNs save 30% FLOPs with slightly better word error rates, showing good generalization across domains.