 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Directional ASR: A New Paradigm for E2E Multi-Speaker Speech Recognition with Source Localization
Oct 30, 2020
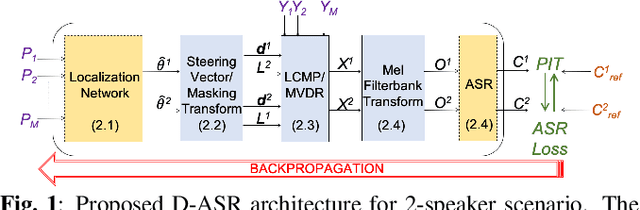
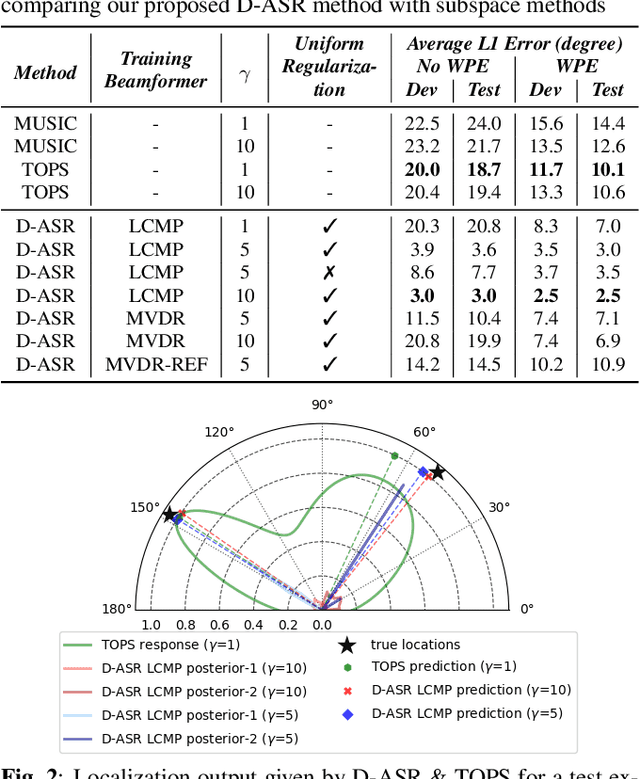
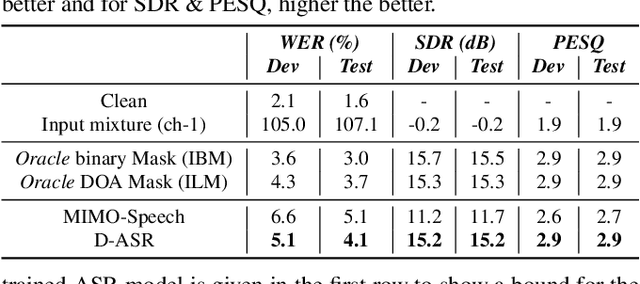

This paper proposes a new paradigm for handling far-field multi-speaker data in an end-to-end neural network manner, called directional automatic speech recognition (D-ASR), which explicitly models source speaker locations. In D-ASR, the azimuth angle of the sources with respect to the microphone array is defined as a latent variable. This angle controls the quality of separation, which in turn determines the ASR performance. All three functionalities of D-ASR: localization, separation, and recognition are connected as a single differentiable neural network and trained solely based on ASR error minimization objectives. The advantages of D-ASR over existing methods are threefold: (1) it provides explicit speaker locations, (2) it improves the explainability factor, and (3) it achieves better ASR performance as the process is more streamlined. In addition, D-ASR does not require explicit direction of arrival (DOA) supervision like existing data-driven localization models, which makes it more appropriate for realistic data. For the case of two source mixtures, D-ASR achieves an average DOA prediction error of less than three degrees. It also outperforms a strong far-field multi-speaker end-to-end system in both separation quality and ASR performance.
Transformer-based Automatic Speech Recognition of Formal and Colloquial Czech in MALACH Project
Jun 15, 2022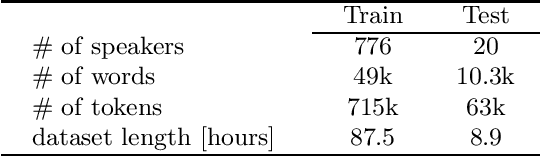


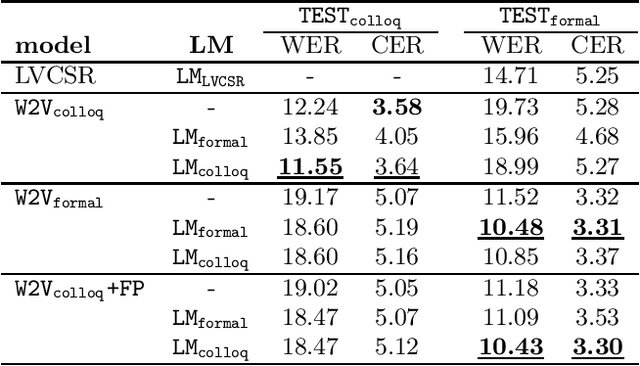
Czech is a very specific language due to its large differences between the formal and the colloquial form of speech. While the formal (written) form is used mainly in official documents, literature, and public speeches, the colloquial (spoken) form is used widely among people in casual speeches. This gap introduces serious problems for ASR systems, especially when training or evaluating ASR models on datasets containing a lot of colloquial speech, such as the MALACH project. In this paper, we are addressing this problem in the light of a new paradigm in end-to-end ASR systems -- recently introduced self-supervised audio Transformers. Specifically, we are investigating the influence of colloquial speech on the performance of Wav2Vec 2.0 models and their ability to transcribe colloquial speech directly into formal transcripts. We are presenting results with both formal and colloquial forms in the training transcripts, language models, and evaluation transcripts.
Contextual Speech Recognition with Difficult Negative Training Examples
Oct 29, 2018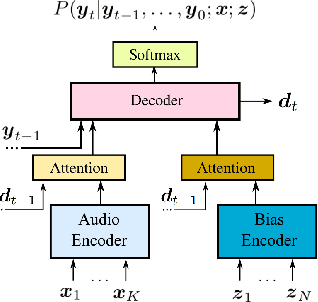
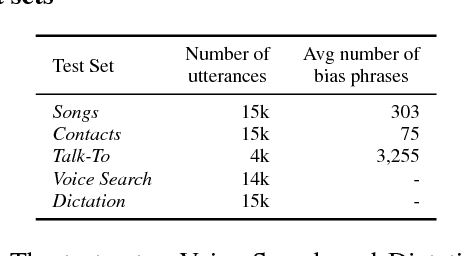
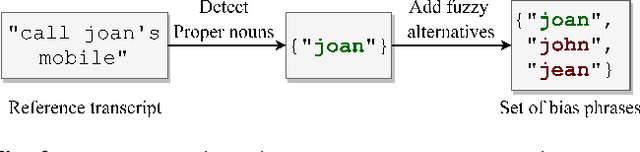
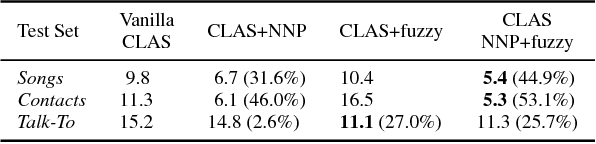
Improving the representation of contextual information is key to unlocking the potential of end-to-end (E2E) automatic speech recognition (ASR). In this work, we present a novel and simple approach for training an ASR context mechanism with difficult negative examples. The main idea is to focus on proper nouns (e.g., unique entities such as names of people and places) in the reference transcript, and use phonetically similar phrases as negative examples, encouraging the neural model to learn more discriminative representations. We apply our approach to an end-to-end contextual ASR model that jointly learns to transcribe and select the correct context items, and show that our proposed method gives up to $53.1\%$ relative improvement in word error rate (WER) across several benchmarks.
Serialized Output Training for End-to-End Overlapped Speech Recognition
Mar 28, 2020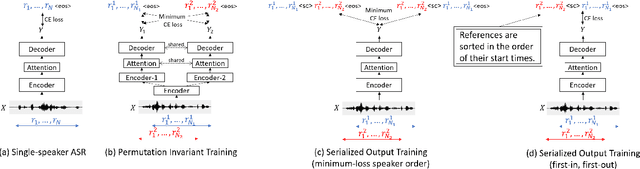
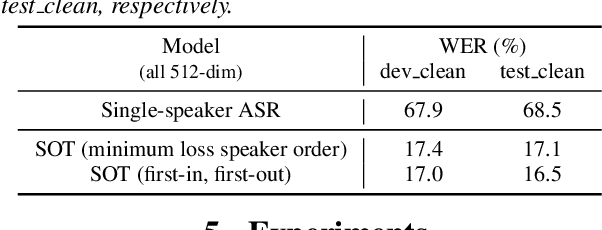
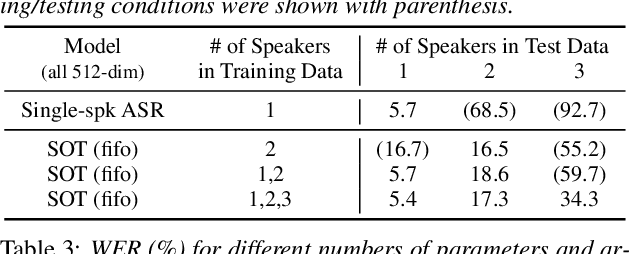
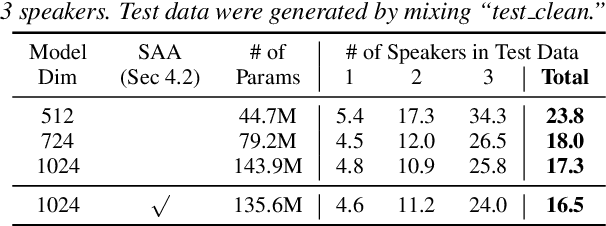
This paper proposes serialized output training (SOT), a novel framework for multi-speaker overlapped speech recognition based on an attention-based encoder-decoder approach. Instead of having multiple output layers as with the permutation invariant training (PIT), SOT uses a model with only one output layer that generates the transcriptions of multiple speakers one after another. The attention and decoder modules take care of producing multiple transcriptions from overlapped speech. SOT has two advantages over PIT: (1) no limitation in the maximum number of speakers, and (2) an ability to model the dependencies among outputs for different speakers. We also propose a simple trick to reduce the complexity of processing each training sample from $O(S!)$ to $O(1)$, where $S$ is the number of the speakers in the training sample, by using the start times of the constituent source utterances. Experimental results on LibriSpeech corpus show that the SOT models can transcribe overlapped speech with variable numbers of speakers significantly better than PIT-based models. We also show that the SOT models can accurately count the number of speakers in the input audio.
Knowledge distillation from language model to acoustic model: a hierarchical multi-task learning approach
Oct 20, 2021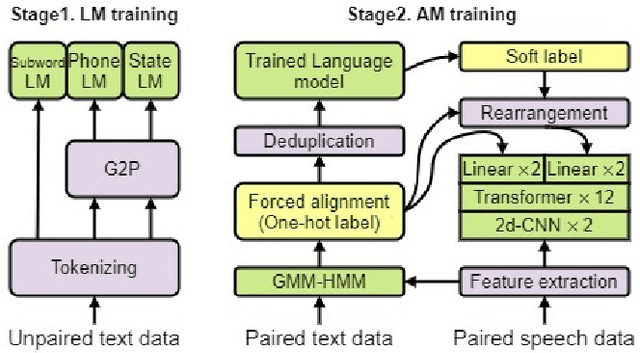
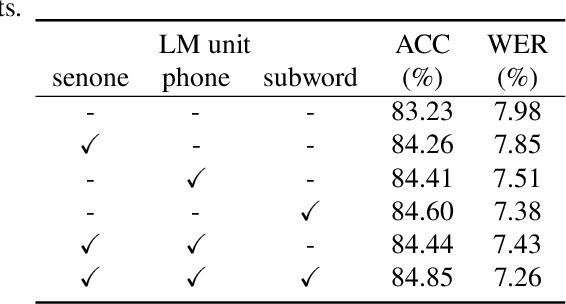
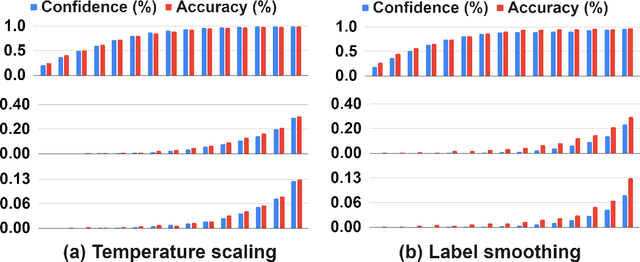

The remarkable performance of the pre-trained language model (LM) using self-supervised learning has led to a major paradigm shift in the study of natural language processing. In line with these changes, leveraging the performance of speech recognition systems with massive deep learning-based LMs is a major topic of speech recognition research. Among the various methods of applying LMs to speech recognition systems, in this paper, we focus on a cross-modal knowledge distillation method that transfers knowledge between two types of deep neural networks with different modalities. We propose an acoustic model structure with multiple auxiliary output layers for cross-modal distillation and demonstrate that the proposed method effectively compensates for the shortcomings of the existing label-interpolation-based distillation method. In addition, we extend the proposed method to a hierarchical distillation method using LMs trained in different units (senones, monophones, and subwords) and reveal the effectiveness of the hierarchical distillation method through an ablation study.
Semantic Mask for Transformer based End-to-End Speech Recognition
Dec 06, 2019
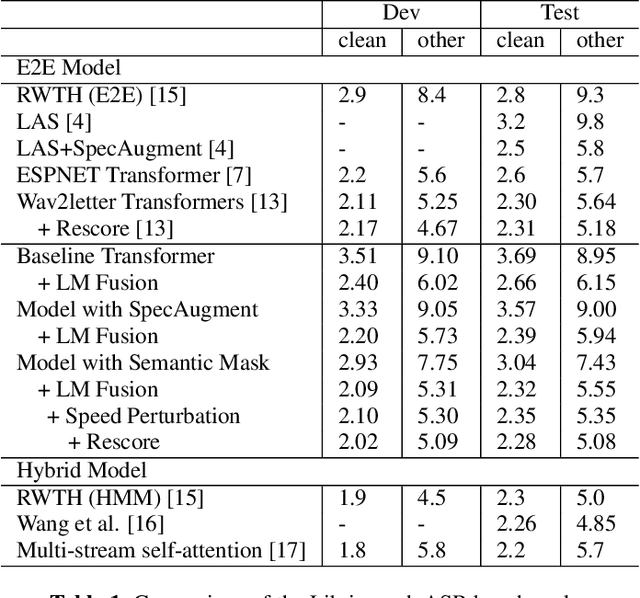
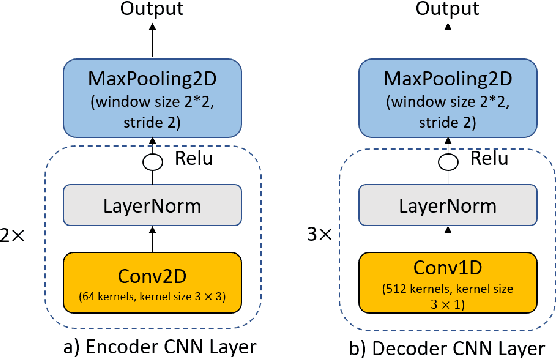
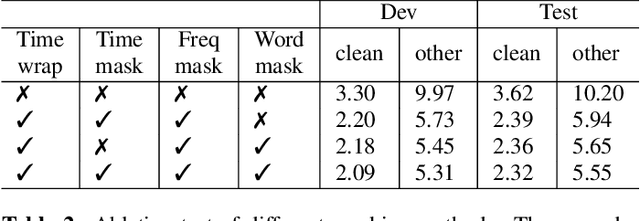
Attention-based encoder-decoder model has achieved impressive results for both automatic speech recognition (ASR) and text-to-speech (TTS) tasks. This approach takes advantage of the memorization capacity of neural networks to learn the mapping from the input sequence to the output sequence from scratch, without the assumption of prior knowledge such as the alignments. However, this model is prone to overfitting, especially when the amount of training data is limited. Inspired by SpecAugment and BERT, in this paper, we propose a semantic mask based regularization for training such kind of end-to-end (E2E) model. The idea is to mask the input features corresponding to a particular output token, e.g., a word or a word-piece, in order to encourage the model to fill the token based on the contextual information. While this approach is applicable to the encoder-decoder framework with any type of neural network architecture, we study the transformer-based model for ASR in this work. We perform experiments on Librispeech 960h and TedLium2 data sets, and achieve the state-of-the-art performance on the test set in the scope of E2E models.
Personalized Speech Enhancement: New Models and Comprehensive Evaluation
Oct 18, 2021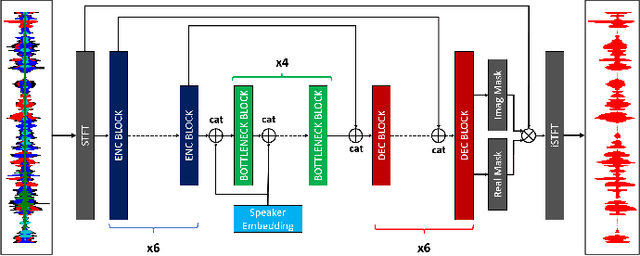


Personalized speech enhancement (PSE) models utilize additional cues, such as speaker embeddings like d-vectors, to remove background noise and interfering speech in real-time and thus improve the speech quality of online video conferencing systems for various acoustic scenarios. In this work, we propose two neural networks for PSE that achieve superior performance to the previously proposed VoiceFilter. In addition, we create test sets that capture a variety of scenarios that users can encounter during video conferencing. Furthermore, we propose a new metric to measure the target speaker over-suppression (TSOS) problem, which was not sufficiently investigated before despite its critical importance in deployment. Besides, we propose multi-task training with a speech recognition back-end. Our results show that the proposed models can yield better speech recognition accuracy, speech intelligibility, and perceptual quality than the baseline models, and the multi-task training can alleviate the TSOS issue in addition to improving the speech recognition accuracy.
Bloom Library: Multimodal Datasets in 300+ Languages for a Variety of Downstream Tasks
Oct 26, 2022
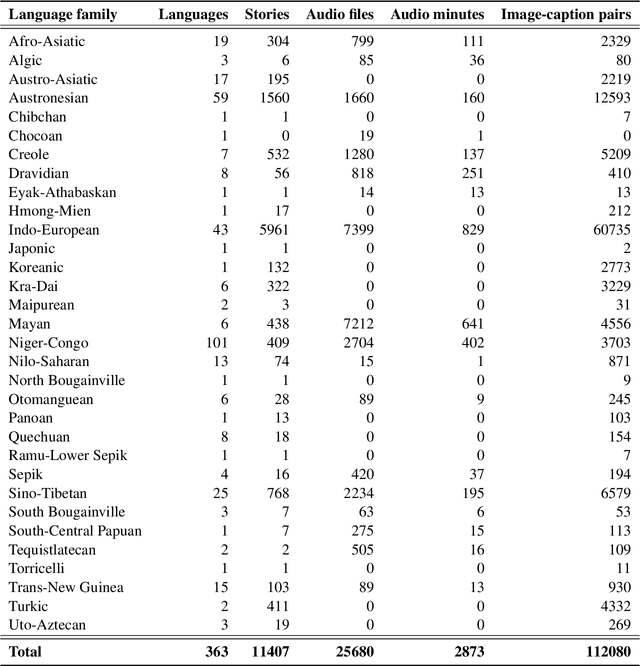
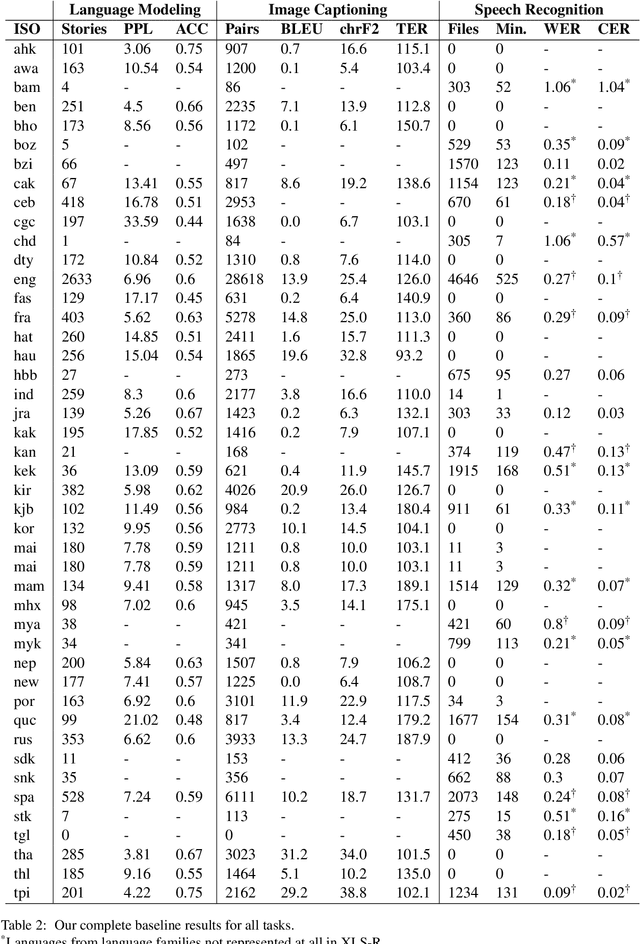
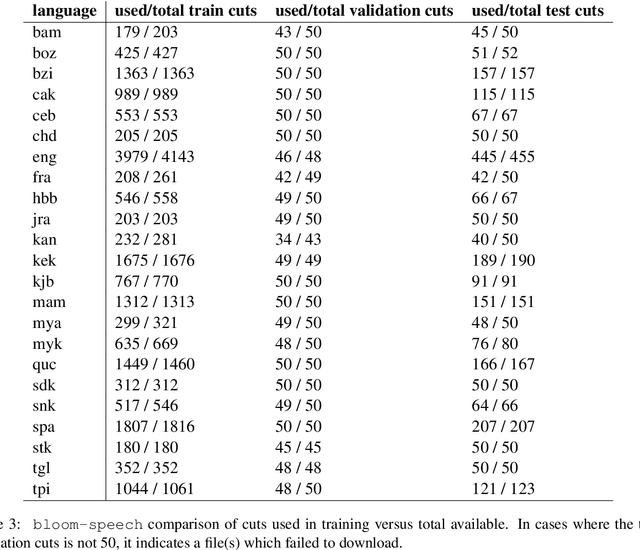
We present Bloom Library, a linguistically diverse set of multimodal and multilingual datasets for language modeling, image captioning, visual storytelling, and speech synthesis/recognition. These datasets represent either the most, or among the most, multilingual datasets for each of the included downstream tasks. In total, the initial release of the Bloom Library datasets covers 363 languages across 32 language families. We train downstream task models for various languages represented in the data, showing the viability of the data for future work in low-resource, multimodal NLP and establishing the first known baselines for these downstream tasks in certain languages (e.g., Bisu [bzi], with an estimated population of 700 users). Some of these first-of-their-kind baselines are comparable to state-of-the-art performance for higher-resourced languages. The Bloom Library datasets are released under Creative Commons licenses on the Hugging Face datasets hub to catalyze more linguistically diverse research in the included downstream tasks.
* 14 pages, 1 figure, 3 tables, accepted to and presented at EMNLP 2022
When Is TTS Augmentation Through a Pivot Language Useful?
Jul 20, 2022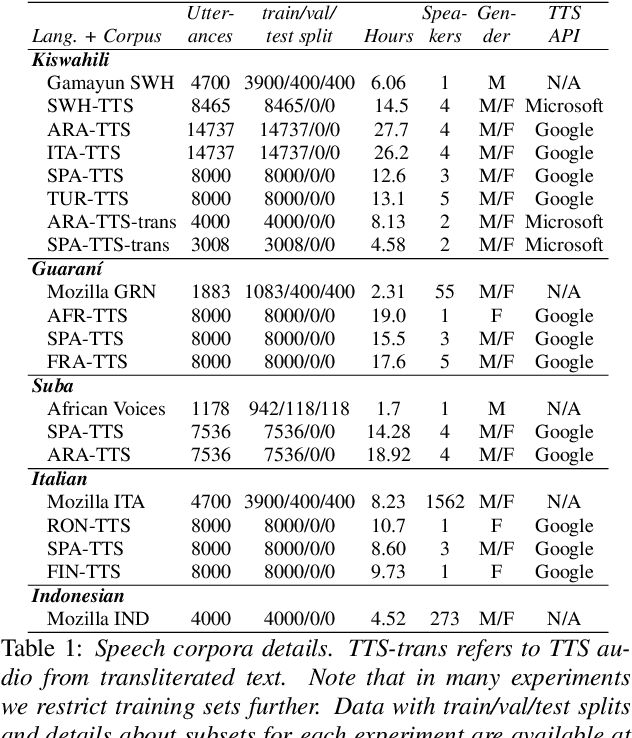
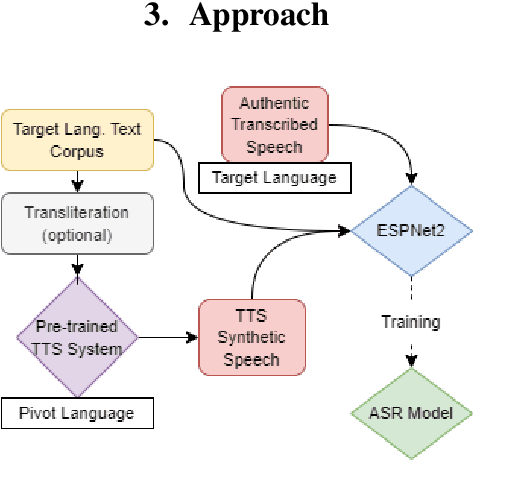
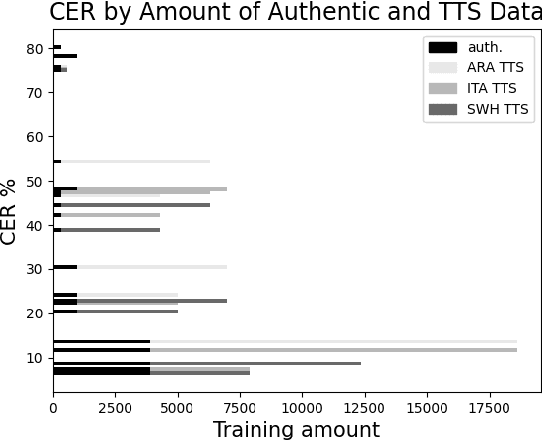
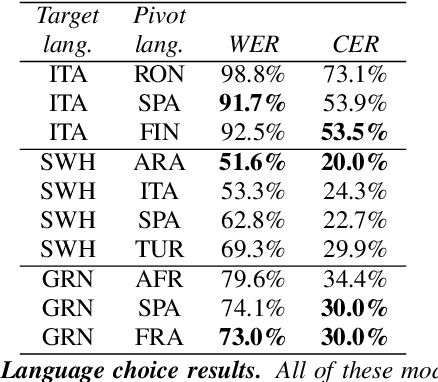
Developing Automatic Speech Recognition (ASR) for low-resource languages is a challenge due to the small amount of transcribed audio data. For many such languages, audio and text are available separately, but not audio with transcriptions. Using text, speech can be synthetically produced via text-to-speech (TTS) systems. However, many low-resource languages do not have quality TTS systems either. We propose an alternative: produce synthetic audio by running text from the target language through a trained TTS system for a higher-resource pivot language. We investigate when and how this technique is most effective in low-resource settings. In our experiments, using several thousand synthetic TTS text-speech pairs and duplicating authentic data to balance yields optimal results. Our findings suggest that searching over a set of candidate pivot languages can lead to marginal improvements and that, surprisingly, ASR performance can by harmed by increases in measured TTS quality. Application of these findings improves ASR by 64.5\% and 45.0\% character error reduction rate (CERR) respectively for two low-resource languages: Guaran\'i and Suba.
End-to-End Automatic Speech Recognition Integrated With CTC-Based Voice Activity Detection
Feb 14, 2020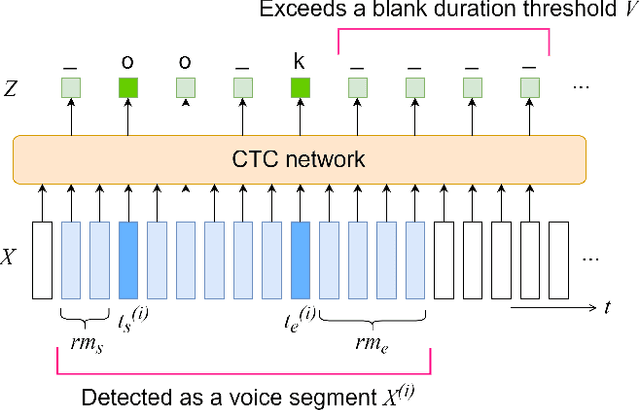
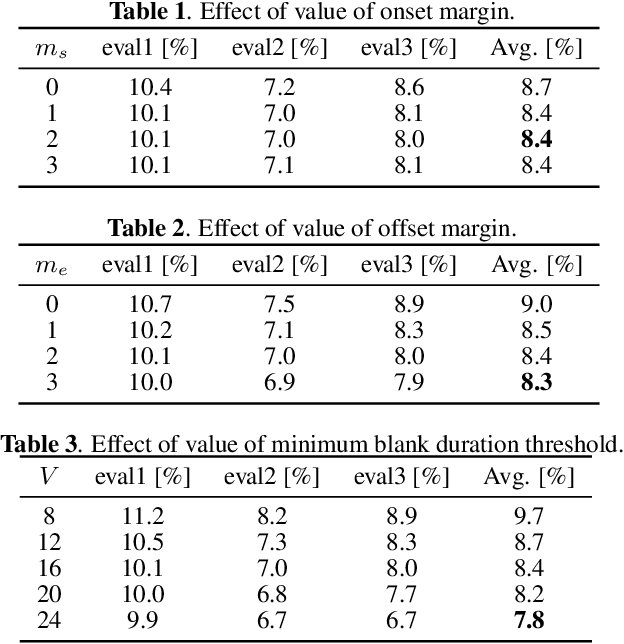
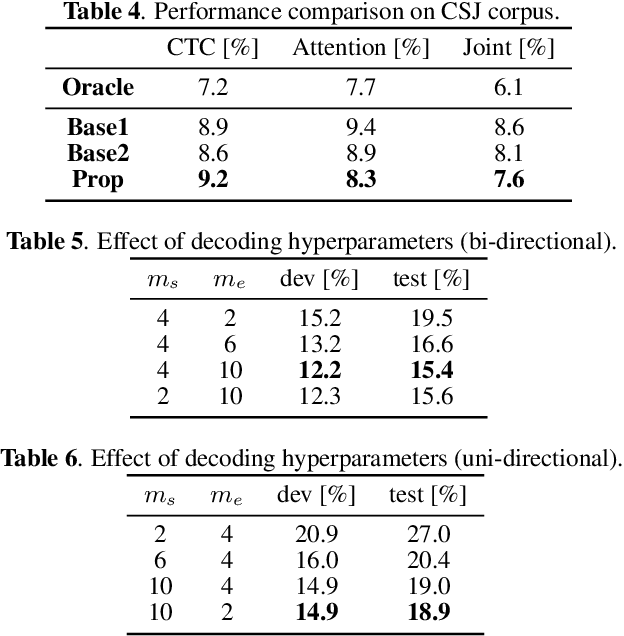

This paper integrates a voice activity detection (VAD) function with end-to-end automatic speech recognition toward an online speech interface and transcribing very long audio recordings. We focus on connectionist temporal classification (CTC) and its extension of CTC/attention architectures. As opposed to an attention-based architecture, input-synchronous label prediction can be performed based on a greedy search with the CTC (pre-)softmax output. This prediction includes consecutive long blank labels, which can be regarded as a non-speech region. We use the labels as a cue for detecting speech segments with simple thresholding. The threshold value is directly related to the length of a non-speech region, which is more intuitive and easier to control than conventional VAD hyperparameters. Experimental results on unsegmented data show that the proposed method outperformed the baseline methods using the conventional energy-based and neural-network-based VAD methods and achieved an RTF less than 0.2. The proposed method is publicly available.