 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Efficient Active Learning for Automatic Speech Recognition via Augmented Consistency Regularization
Jun 19, 2020
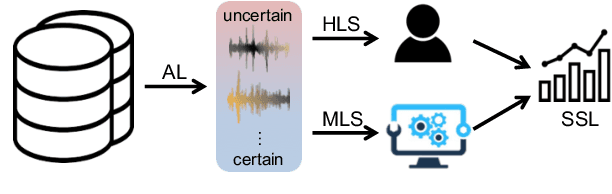
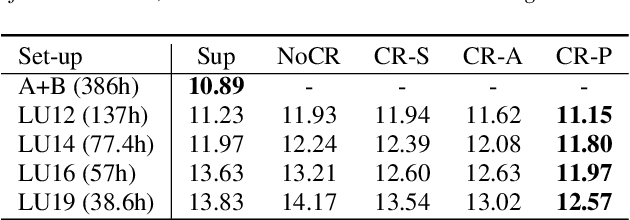
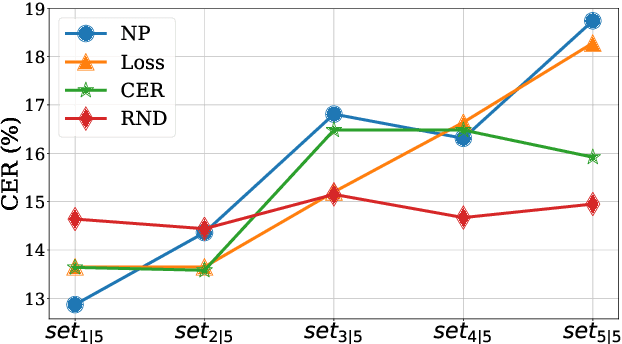
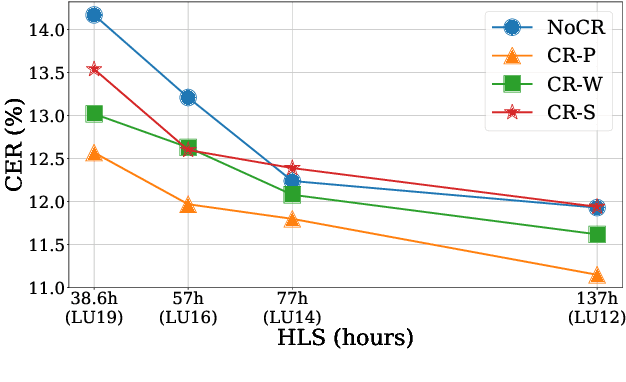
The cost of labeling transcriptions for large speech corpora becomes a bottleneck to maximally enjoy the potential capacity of deep neural network-based automatic speech recognition (ASR) models. Therefore, in this paper, we present a new training scheme that minimizes the labeling cost by adopting the concepts of semi-supervised learning (SSL) and active learning (AL) approaches and making a synergy from them. While AL studies only focus on selecting minimized the number of samples to be labeled with a criterion and taking advantage of such samples, we show that the training efficiency can be further improved by utilizing the unlabeled samples by sophisticatedly designing unsupervised loss that complements the unwanted behavior of supervised loss effectively. Our unsupervised loss is built on Consistency-Regularization (CR) approach, and we propose appropriate augmentation techniques to adopt CR in ASR field successfully. From the qualitative and quantitative experiments on the real-world dataset from deployed end-user voice assistant services, we show that the proposed methods can handle a large number of unlabeled speech data to achieve competitive model performance, with a sustainable amount of human labeling cost.
Generating Synthetic Audio Data for Attention-Based Speech Recognition Systems
Dec 19, 2019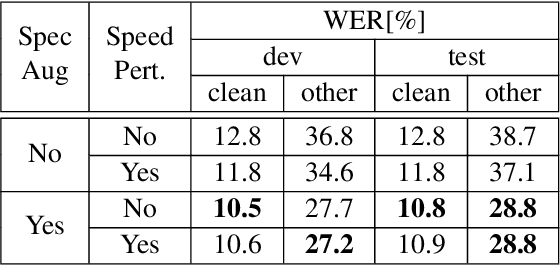
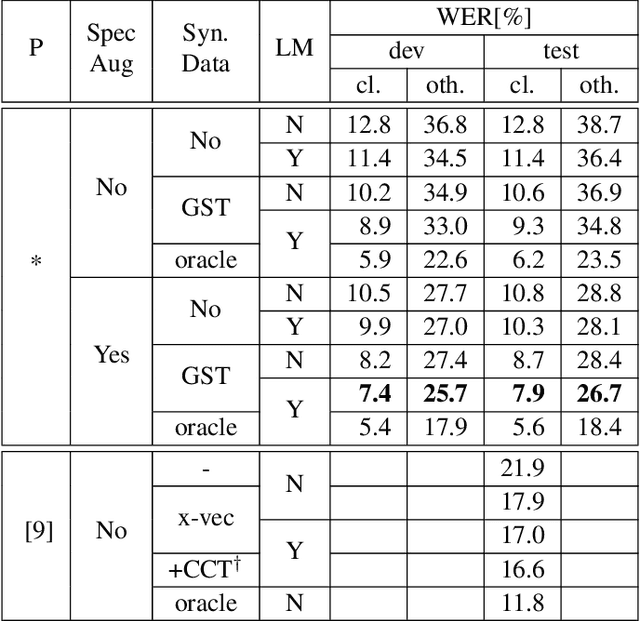
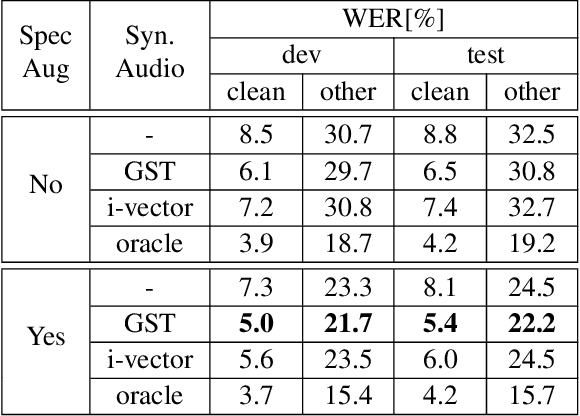
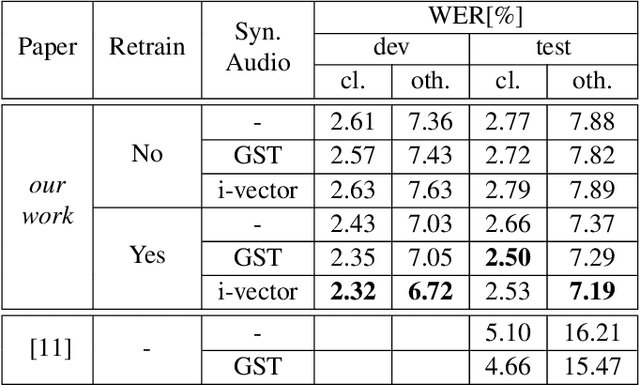
Recent advances in text-to-speech (TTS) led to the development of flexible multi-speaker end-to-end TTS systems. We extend state-of-the-art attention-based automatic speech recognition (ASR) systems with synthetic audio generated by a TTS system trained only on the ASR corpora itself. ASR and TTS systems are built separately to show that text-only data can be used to enhance existing end-to-end ASR systems without the necessity of parameter or architecture changes. We compare our method with language model integration of the same text data and with simple data augmentation methods like SpecAugment and show that performance improvements are mostly independent. We achieve improvements of up to 33% relative in word-error-rate (WER) over a strong baseline with data-augmentation in a low-resource environment (LibriSpeech-100h), closing the gap to a comparable oracle experiment by more than 50\%. We also show improvements of up to 5% relative WER over our most recent ASR baseline on LibriSpeech-960h.
Kernel Approximation Methods for Speech Recognition
Jan 13, 2017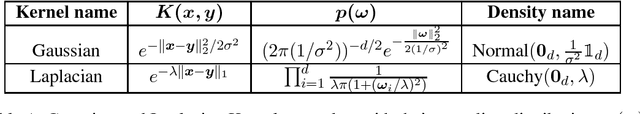
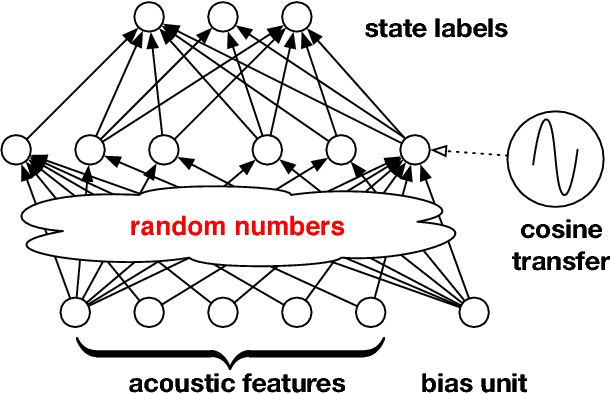
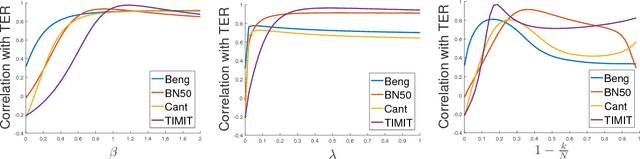

We study large-scale kernel methods for acoustic modeling in speech recognition and compare their performance to deep neural networks (DNNs). We perform experiments on four speech recognition datasets, including the TIMIT and Broadcast News benchmark tasks, and compare these two types of models on frame-level performance metrics (accuracy, cross-entropy), as well as on recognition metrics (word/character error rate). In order to scale kernel methods to these large datasets, we use the random Fourier feature method of Rahimi and Recht (2007). We propose two novel techniques for improving the performance of kernel acoustic models. First, in order to reduce the number of random features required by kernel models, we propose a simple but effective method for feature selection. The method is able to explore a large number of non-linear features while maintaining a compact model more efficiently than existing approaches. Second, we present a number of frame-level metrics which correlate very strongly with recognition performance when computed on the heldout set; we take advantage of these correlations by monitoring these metrics during training in order to decide when to stop learning. This technique can noticeably improve the recognition performance of both DNN and kernel models, while narrowing the gap between them. Additionally, we show that the linear bottleneck method of Sainath et al. (2013) improves the performance of our kernel models significantly, in addition to speeding up training and making the models more compact. Together, these three methods dramatically improve the performance of kernel acoustic models, making their performance comparable to DNNs on the tasks we explored.
CTL-MTNet: A Novel CapsNet and Transfer Learning-Based Mixed Task Net for the Single-Corpus and Cross-Corpus Speech Emotion Recognition
Jul 18, 2022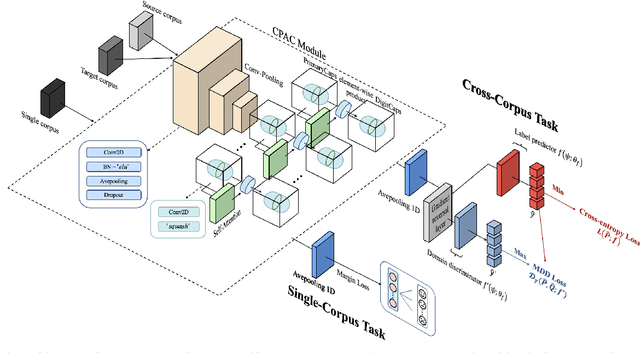
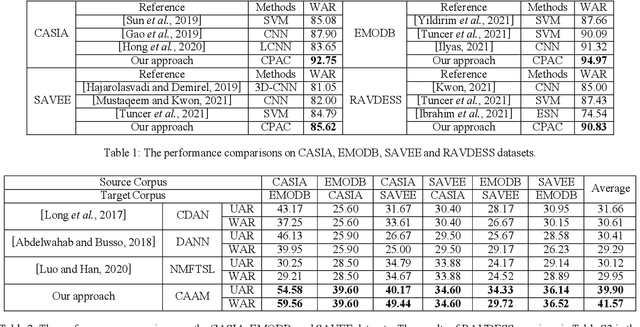
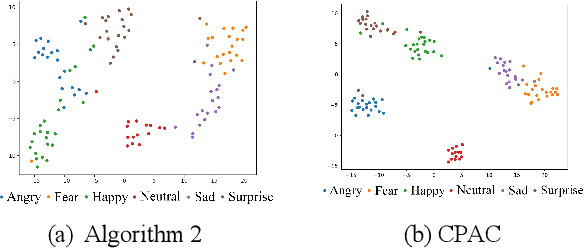

Speech Emotion Recognition (SER) has become a growing focus of research in human-computer interaction. An essential challenge in SER is to extract common attributes from different speakers or languages, especially when a specific source corpus has to be trained to recognize the unknown data coming from another speech corpus. To address this challenge, a Capsule Network (CapsNet) and Transfer Learning based Mixed Task Net (CTLMTNet) are proposed to deal with both the singlecorpus and cross-corpus SER tasks simultaneously in this paper. For the single-corpus task, the combination of Convolution-Pooling and Attention CapsNet module CPAC) is designed by embedding the self-attention mechanism to the CapsNet, guiding the module to focus on the important features that can be fed into different capsules. The extracted high-level features by CPAC provide sufficient discriminative ability. Furthermore, to handle the cross-corpus task, CTL-MTNet employs a Corpus Adaptation Adversarial Module (CAAM) by combining CPAC with Margin Disparity Discrepancy (MDD), which can learn the domain-invariant emotion representations through extracting the strong emotion commonness. Experiments including ablation studies and visualizations on both singleand cross-corpus tasks using four well-known SER datasets in different languages are conducted for performance evaluation and comparison. The results indicate that in both tasks the CTL-MTNet showed better performance in all cases compared to a number of state-of-the-art methods. The source code and the supplementary materials are available at: https://github.com/MLDMXM2017/CTLMTNet
Multi-task self-supervised learning for Robust Speech Recognition
Jan 25, 2020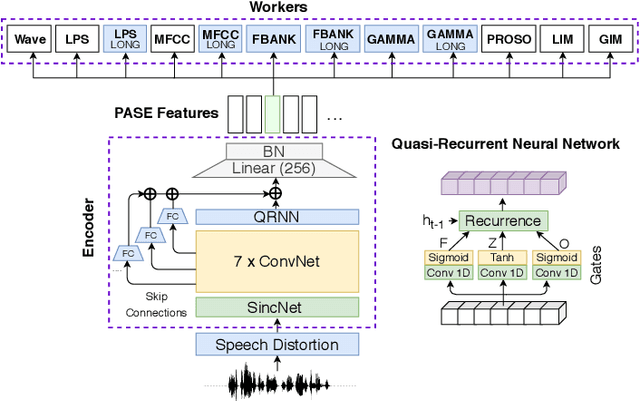
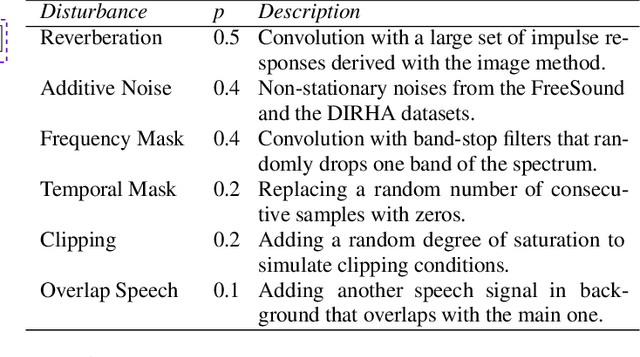
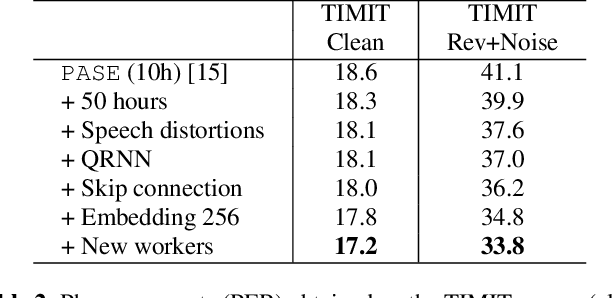
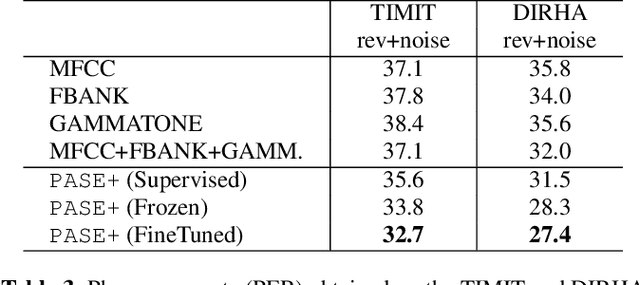
Despite the growing interest in unsupervised learning, extracting meaningful knowledge from unlabelled audio remains an open challenge. To take a step in this direction, we recently proposed a problem-agnostic speech encoder (PASE), that combines a convolutional encoder followed by multiple neural networks, called workers, tasked to solve self-supervised problems (i.e., ones that do not require manual annotations as ground truth). PASE was shown to capture relevant speech information, including speaker voice-print and phonemes. This paper proposes PASE+, an improved version of PASE for robust speech recognition in noisy and reverberant environments. To this end, we employ an online speech distortion module, that contaminates the input signals with a variety of random disturbances. We then propose a revised encoder that better learns short- and long-term speech dynamics with an efficient combination of recurrent and convolutional networks. Finally, we refine the set of workers used in self-supervision to encourage better cooperation. Results on TIMIT, DIRHA and CHiME-5 show that PASE+ significantly outperforms both the previous version of PASE as well as common acoustic features. Interestingly, PASE+ learns transferable representations suitable for highly mismatched acoustic conditions.
VoxSRC 2022: The Fourth VoxCeleb Speaker Recognition Challenge
Feb 20, 2023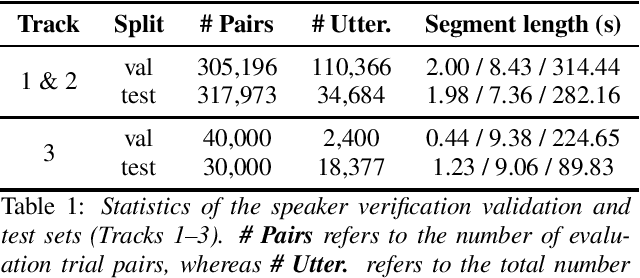
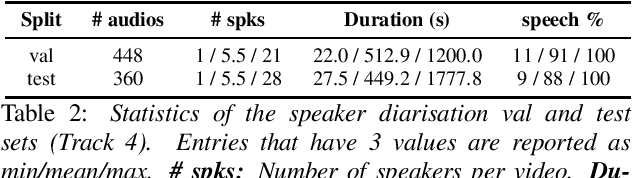
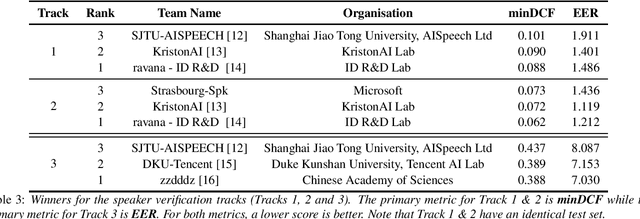

This paper summarises the findings from the VoxCeleb Speaker Recognition Challenge 2022 (VoxSRC-22), which was held in conjunction with INTERSPEECH 2022. The goal of this challenge was to evaluate how well state-of-the-art speaker recognition systems can diarise and recognise speakers from speech obtained "in the wild". The challenge consisted of: (i) the provision of publicly available speaker recognition and diarisation data from YouTube videos together with ground truth annotation and standardised evaluation software; and (ii) a public challenge and hybrid workshop held at INTERSPEECH 2022. We describe the four tracks of our challenge along with the baselines, methods, and results. We conclude with a discussion on the new domain-transfer focus of VoxSRC-22, and on the progression of the challenge from the previous three editions.
Efficient Neural Architecture Search for End-to-end Speech Recognition via Straight-Through Gradients
Nov 11, 2020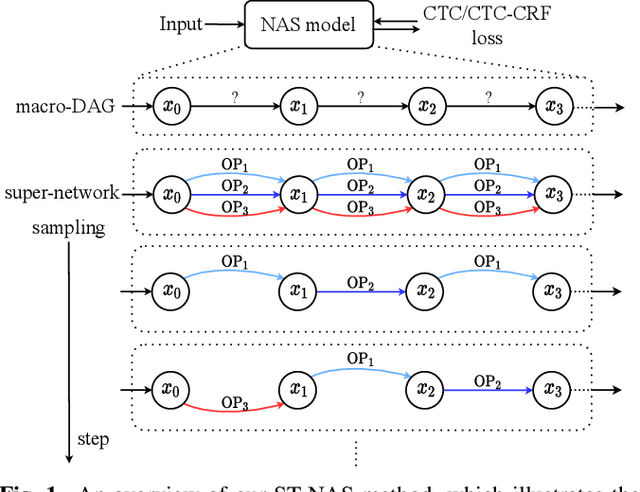
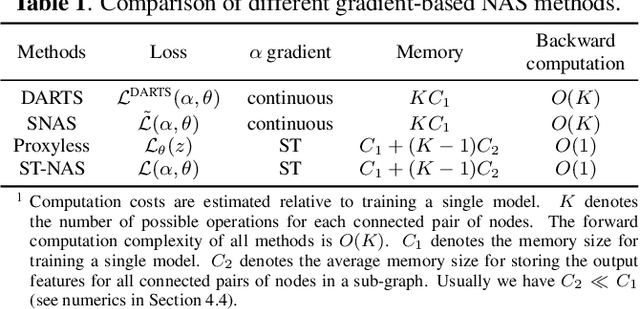
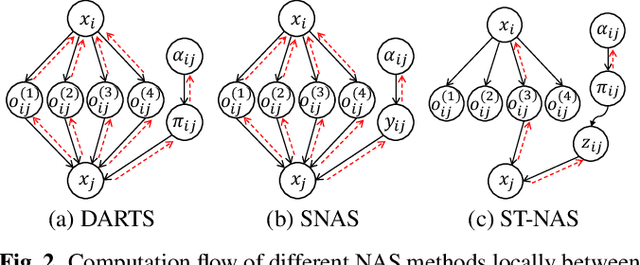
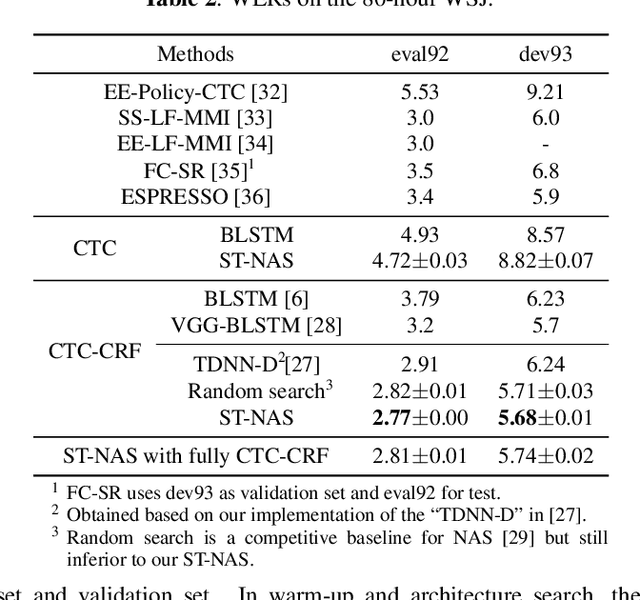
Neural Architecture Search (NAS), the process of automating architecture engineering, is an appealing next step to advancing end-to-end Automatic Speech Recognition (ASR), replacing expert-designed networks with learned, task-specific architectures. In contrast to early computational-demanding NAS methods, recent gradient-based NAS methods, e.g., DARTS (Differentiable ARchiTecture Search), SNAS (Stochastic NAS) and ProxylessNAS, significantly improve the NAS efficiency. In this paper, we make two contributions. First, we rigorously develop an efficient NAS method via Straight-Through (ST) gradients, called ST-NAS. Basically, ST-NAS uses the loss from SNAS but uses ST to back-propagate gradients through discrete variables to optimize the loss, which is not revealed in ProxylessNAS. Using ST gradients to support sub-graph sampling is a core element to achieve efficient NAS beyond DARTS and SNAS. Second, we successfully apply ST-NAS to end-to-end ASR. Experiments over the widely benchmarked 80-hour WSJ and 300-hour Switchboard datasets show that the ST-NAS induced architectures significantly outperform the human-designed architecture across the two datasets. Strengths of ST-NAS such as architecture transferability and low computation cost in memory and time are also reported.
XTREME-S: Evaluating Cross-lingual Speech Representations
Apr 13, 2022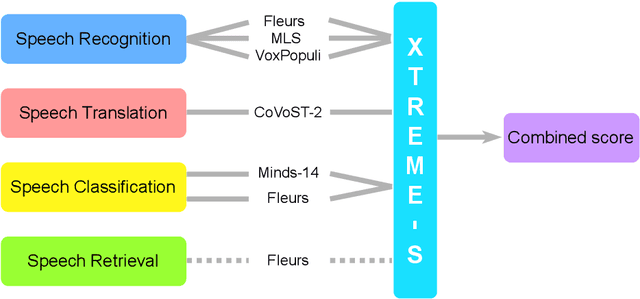
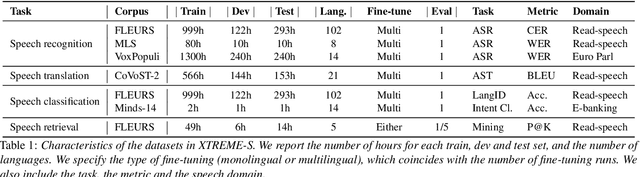
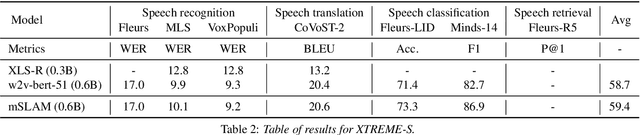
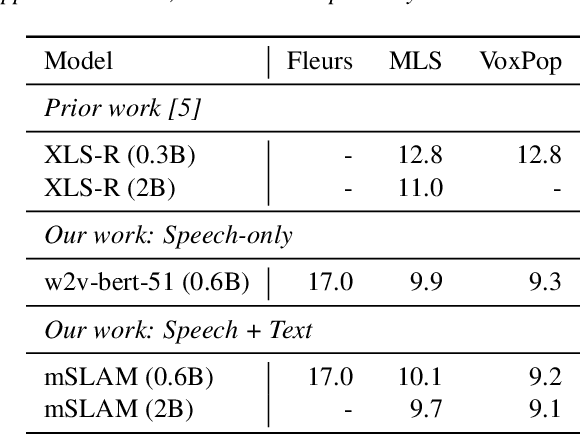
We introduce XTREME-S, a new benchmark to evaluate universal cross-lingual speech representations in many languages. XTREME-S covers four task families: speech recognition, classification, speech-to-text translation and retrieval. Covering 102 languages from 10+ language families, 3 different domains and 4 task families, XTREME-S aims to simplify multilingual speech representation evaluation, as well as catalyze research in "universal" speech representation learning. This paper describes the new benchmark and establishes the first speech-only and speech-text baselines using XLS-R and mSLAM on all downstream tasks. We motivate the design choices and detail how to use the benchmark. Datasets and fine-tuning scripts are made easily accessible at https://hf.co/datasets/google/xtreme_s.
Simultaneous Speech Recognition and Speaker Diarization for Monaural Dialogue Recordings with Target-Speaker Acoustic Models
Sep 17, 2019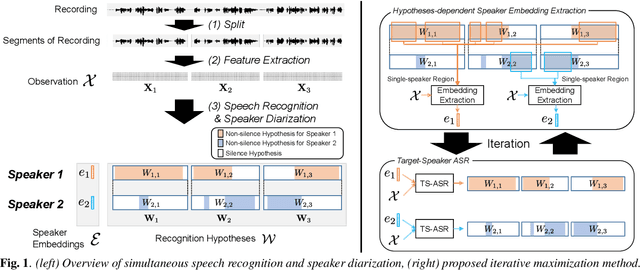
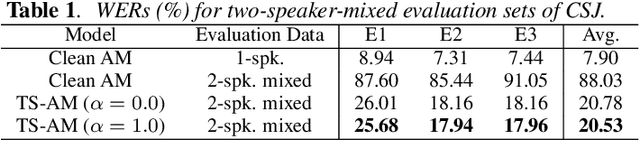
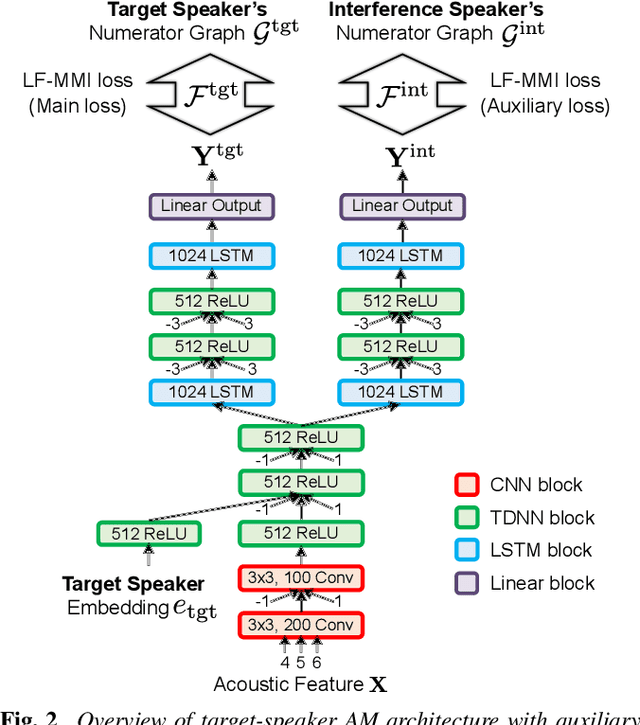
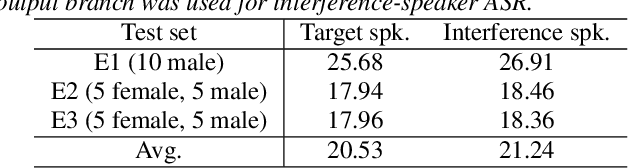
This paper investigates the use of target-speaker automatic speech recognition (TS-ASR) for simultaneous speech recognition and speaker diarization of single-channel dialogue recordings. TS-ASR is a technique to automatically extract and recognize only the speech of a target speaker given a short sample utterance of that speaker. One obvious drawback of TS-ASR is that it cannot be used when the speakers in the recordings are unknown because it requires a sample of the target speakers in advance of decoding. To remove this limitation, we propose an iterative method, in which (i) the estimation of speaker embeddings and (ii) TS-ASR based on the estimated speaker embeddings are alternately executed. We evaluated the proposed method by using very challenging dialogue recordings in which the speaker overlap ratio was over 20%. We confirmed that the proposed method significantly reduced both the word error rate (WER) and diarization error rate (DER). Our proposed method combined with i-vector speaker embeddings ultimately achieved a WER that differed by only 2.1 % from that of TS-ASR given oracle speaker embeddings. Furthermore, our method can solve speaker diarization simultaneously as a by-product and achieved better DER than that of the conventional clustering-based speaker diarization method based on i-vector.
cross-modal fusion techniques for utterance-level emotion recognition from text and speech
Feb 05, 2023
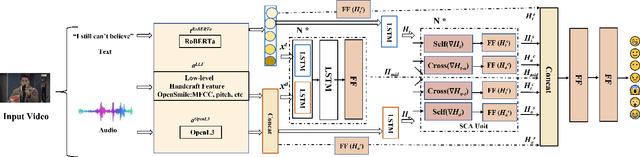
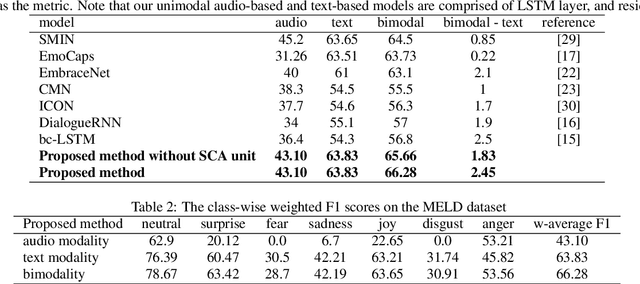

Multimodal emotion recognition (MER) is a fundamental complex research problem due to the uncertainty of human emotional expression and the heterogeneity gap between different modalities. Audio and text modalities are particularly important for a human participant in understanding emotions. Although many successful attempts have been designed multimodal representations for MER, there still exist multiple challenges to be addressed: 1) bridging the heterogeneity gap between multimodal features and model inter- and intra-modal interactions of multiple modalities; 2) effectively and efficiently modelling the contextual dynamics in the conversation sequence. In this paper, we propose Cross-Modal RoBERTa (CM-RoBERTa) model for emotion detection from spoken audio and corresponding transcripts. As the core unit of the CM-RoBERTa, parallel self- and cross- attention is designed to dynamically capture inter- and intra-modal interactions of audio and text. Specially, the mid-level fusion and residual module are employed to model long-term contextual dependencies and learn modality-specific patterns. We evaluate the approach on the MELD dataset and the experimental results show the proposed approach achieves the state-of-art performance on the dataset.