 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Multistream neural architectures for cued-speech recognition using a pre-trained visual feature extractor and constrained CTC decoding
Apr 11, 2022
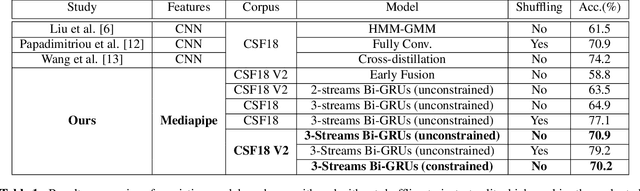
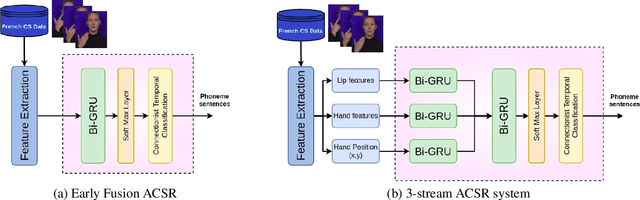
This paper proposes a simple and effective approach for automatic recognition of Cued Speech (CS), a visual communication tool that helps people with hearing impairment to understand spoken language with the help of hand gestures that can uniquely identify the uttered phonemes in complement to lipreading. The proposed approach is based on a pre-trained hand and lips tracker used for visual feature extraction and a phonetic decoder based on a multistream recurrent neural network trained with connectionist temporal classification loss and combined with a pronunciation lexicon. The proposed system is evaluated on an updated version of the French CS dataset CSF18 for which the phonetic transcription has been manually checked and corrected. With a decoding accuracy at the phonetic level of 70.88%, the proposed system outperforms our previous CNN-HMM decoder and competes with more complex baselines.
Adversarial Attacks on ASR Systems: An Overview
Aug 03, 2022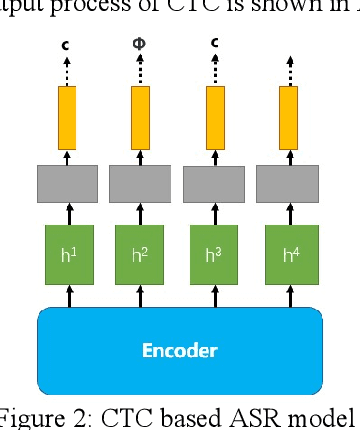
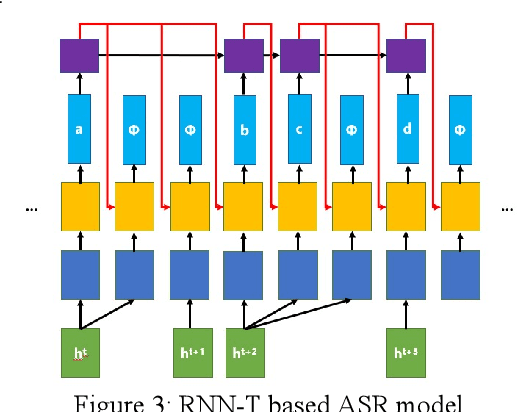
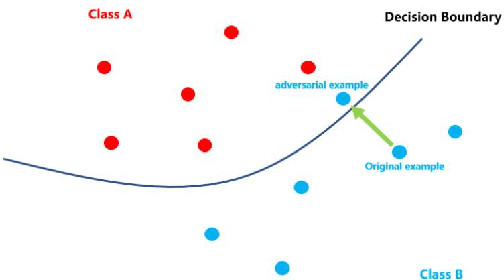
With the development of hardware and algorithms, ASR(Automatic Speech Recognition) systems evolve a lot. As The models get simpler, the difficulty of development and deployment become easier, ASR systems are getting closer to our life. On the one hand, we often use APPs or APIs of ASR to generate subtitles and record meetings. On the other hand, smart speaker and self-driving car rely on ASR systems to control AIoT devices. In past few years, there are a lot of works on adversarial examples attacks against ASR systems. By adding a small perturbation to the waveforms, the recognition results make a big difference. In this paper, we describe the development of ASR system, different assumptions of attacks, and how to evaluate these attacks. Next, we introduce the current works on adversarial examples attacks from two attack assumptions: white-box attack and black-box attack. Different from other surveys, we pay more attention to which layer they perturb waveforms in ASR system, the relationship between these attacks, and their implementation methods. We focus on the effect of their works.
Manifold-Kernels Comparison in MKPLS for Visual Speech Recognition
Jan 22, 2016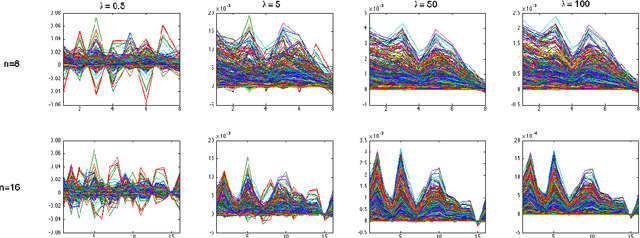
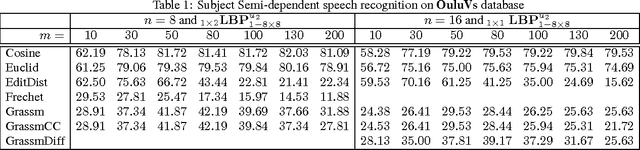
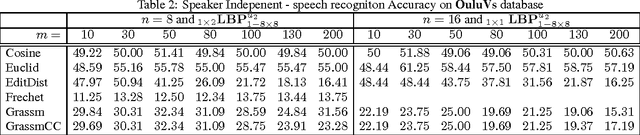
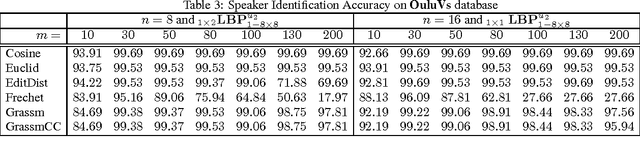
Speech recognition is a challenging problem. Due to the acoustic limitations, using visual information is essential for improving the recognition accuracy in real-life unconstraint situations. One common approach is to model the visual recognition as nonlinear optimization problem. Measuring the distances between visual units is essential for solving this problem. Embedding the visual units on a manifold and using manifold kernels is one way to measure these distances. This work is intended to evaluate the performance of several manifold kernels for solving the problem of visual speech recognition. We show the theory behind each kernel. We apply manifold kernel partial least squares framework to OuluVs and AvLetters databases, and show empirical comparison between all kernels. This framework provides convenient way to explore different kernels.
Punctuation Restoration in Spanish Customer Support Transcripts using Transfer Learning
May 27, 2022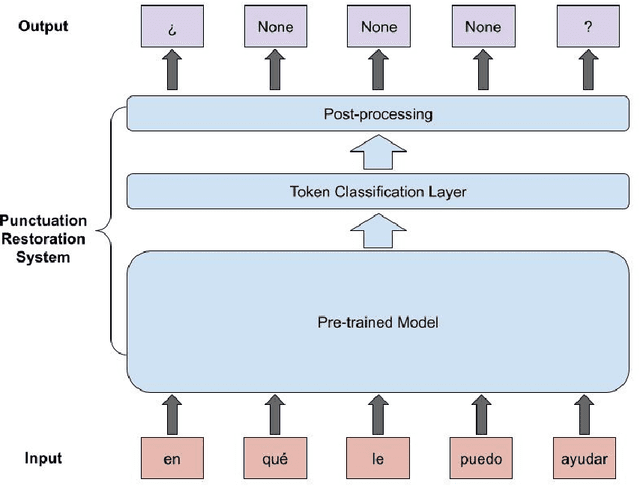
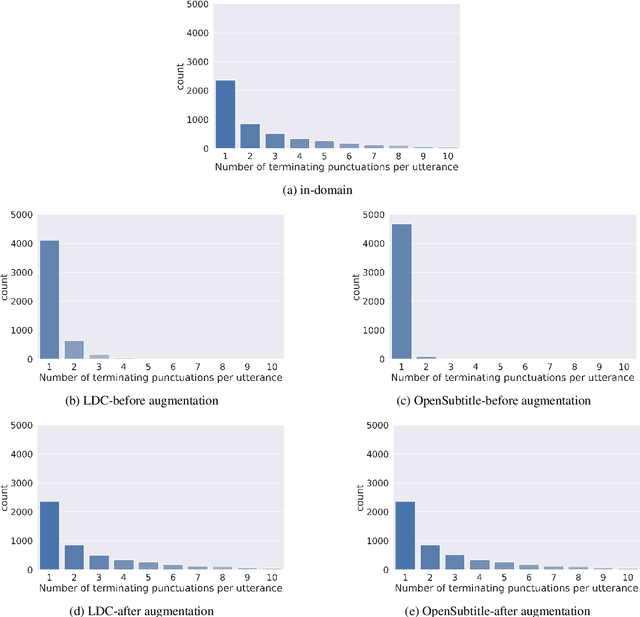

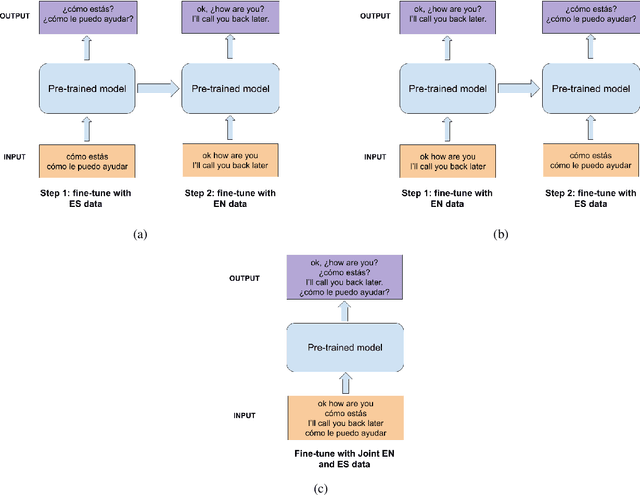
Automatic Speech Recognition (ASR) systems typically produce unpunctuated transcripts that have poor readability. In addition, building a punctuation restoration system is challenging for low-resource languages, especially for domain-specific applications. In this paper, we propose a Spanish punctuation restoration system designed for a real-time customer support transcription service. To address the data sparsity of Spanish transcripts in the customer support domain, we introduce two transfer-learning-based strategies: 1) domain adaptation using out-of-domain Spanish text data; 2) cross-lingual transfer learning leveraging in-domain English transcript data. Our experiment results show that these strategies improve the accuracy of the Spanish punctuation restoration system.
English Conversational Telephone Speech Recognition by Humans and Machines
Mar 06, 2017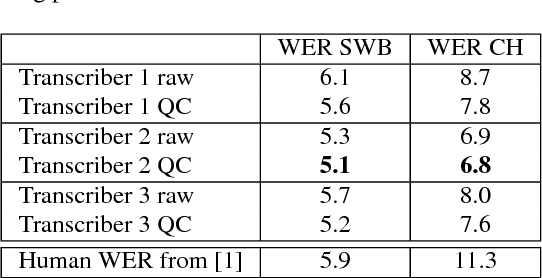
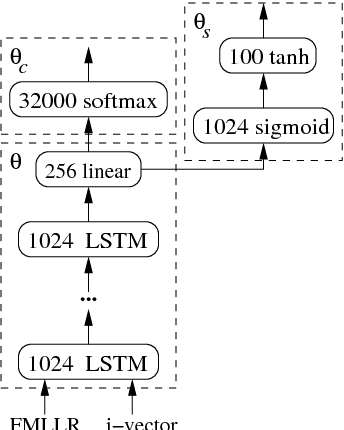
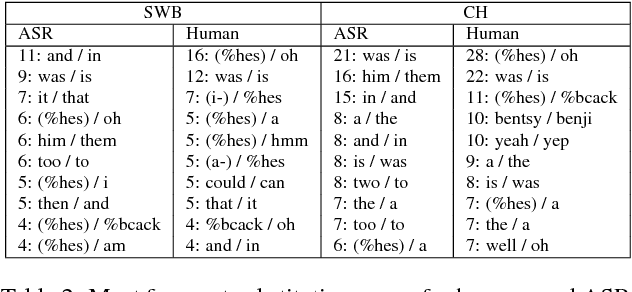
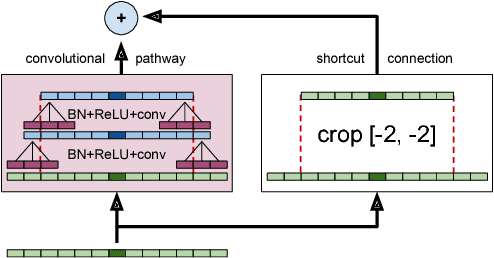
One of the most difficult speech recognition tasks is accurate recognition of human to human communication. Advances in deep learning over the last few years have produced major speech recognition improvements on the representative Switchboard conversational corpus. Word error rates that just a few years ago were 14% have dropped to 8.0%, then 6.6% and most recently 5.8%, and are now believed to be within striking range of human performance. This then raises two issues - what IS human performance, and how far down can we still drive speech recognition error rates? A recent paper by Microsoft suggests that we have already achieved human performance. In trying to verify this statement, we performed an independent set of human performance measurements on two conversational tasks and found that human performance may be considerably better than what was earlier reported, giving the community a significantly harder goal to achieve. We also report on our own efforts in this area, presenting a set of acoustic and language modeling techniques that lowered the word error rate of our own English conversational telephone LVCSR system to the level of 5.5%/10.3% on the Switchboard/CallHome subsets of the Hub5 2000 evaluation, which - at least at the writing of this paper - is a new performance milestone (albeit not at what we measure to be human performance!). On the acoustic side, we use a score fusion of three models: one LSTM with multiple feature inputs, a second LSTM trained with speaker-adversarial multi-task learning and a third residual net (ResNet) with 25 convolutional layers and time-dilated convolutions. On the language modeling side, we use word and character LSTMs and convolutional WaveNet-style language models.
Articulatory information and Multiview Features for Large Vocabulary Continuous Speech Recognition
Feb 16, 2018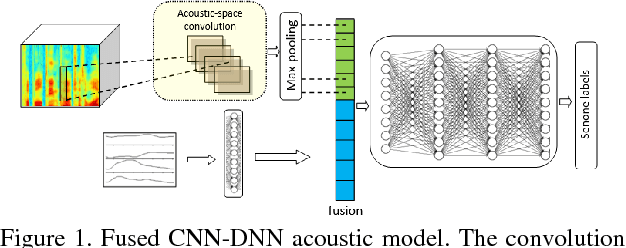
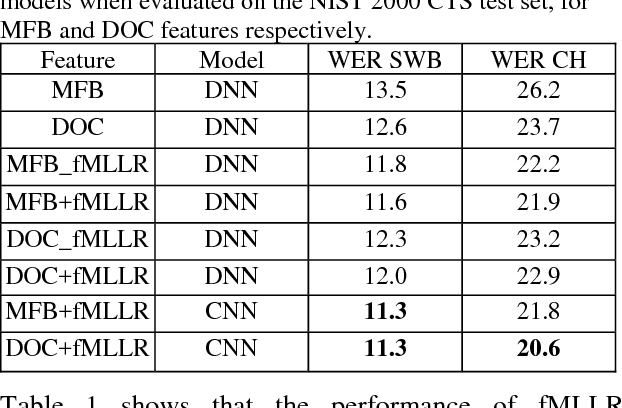
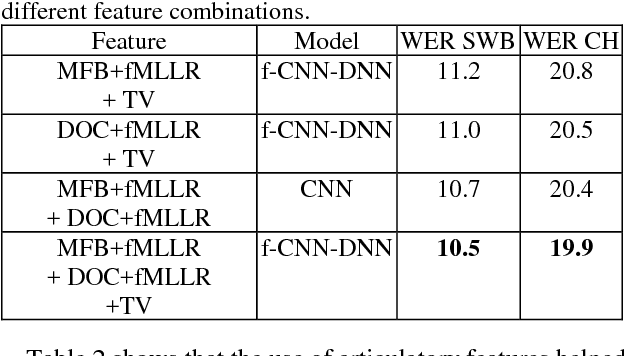
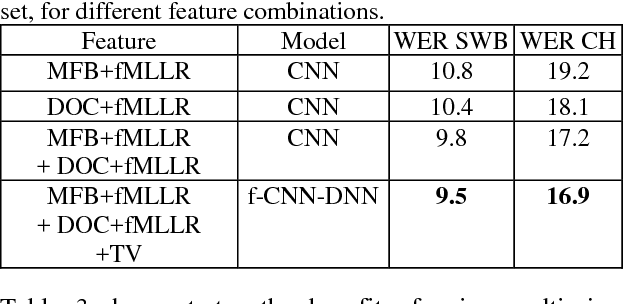
This paper explores the use of multi-view features and their discriminative transforms in a convolutional deep neural network (CNN) architecture for a continuous large vocabulary speech recognition task. Mel-filterbank energies and perceptually motivated forced damped oscillator coefficient (DOC) features are used after feature-space maximum-likelihood linear regression (fMLLR) transforms, which are combined and fed as a multi-view feature to a single CNN acoustic model. Use of multi-view feature representation demonstrated significant reduction in word error rates (WERs) compared to the use of individual features by themselves. In addition, when articulatory information was used as an additional input to a fused deep neural network (DNN) and CNN acoustic model, it was found to demonstrate further reduction in WER for the Switchboard subset and the CallHome subset (containing partly non-native accented speech) of the NIST 2000 conversational telephone speech test set, reducing the error rate by 12% relative to the baseline in both cases. This work shows that multi-view features in association with articulatory information can improve speech recognition robustness to spontaneous and non-native speech.
Correction of Automatic Speech Recognition with Transformer Sequence-to-sequence Model
Oct 23, 2019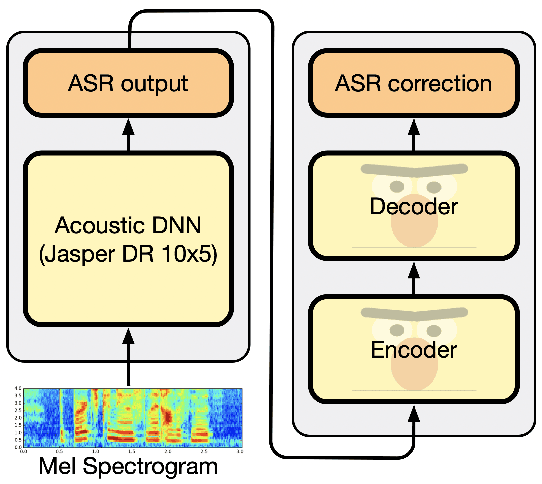
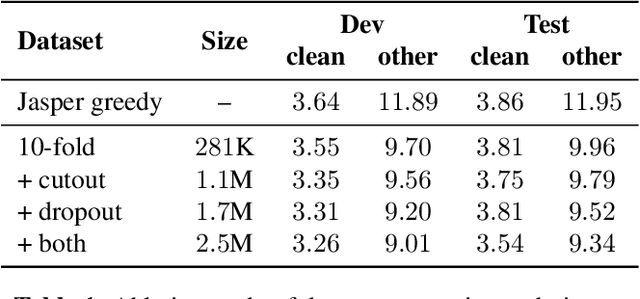
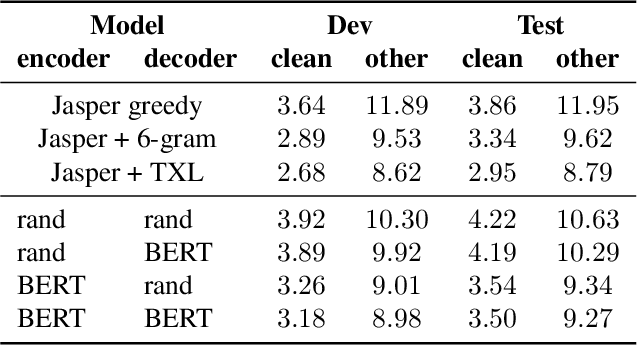
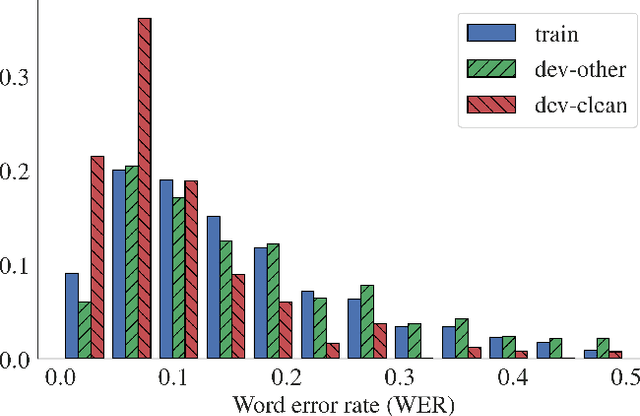
In this work, we introduce a simple yet efficient post-processing model for automatic speech recognition (ASR). Our model has Transformer-based encoder-decoder architecture which "translates" ASR model output into grammatically and semantically correct text. We investigate different strategies for regularizing and optimizing the model and show that extensive data augmentation and the initialization with pre-trained weights are required to achieve good performance. On the LibriSpeech benchmark, our method demonstrates significant improvement in word error rate over the baseline acoustic model with greedy decoding, especially on much noisier dev-other and test-other portions of the evaluation dataset. Our model also outperforms baseline with 6-gram language model re-scoring and approaches the performance of re-scoring with Transformer-XL neural language model.
UserLibri: A Dataset for ASR Personalization Using Only Text
Jul 02, 2022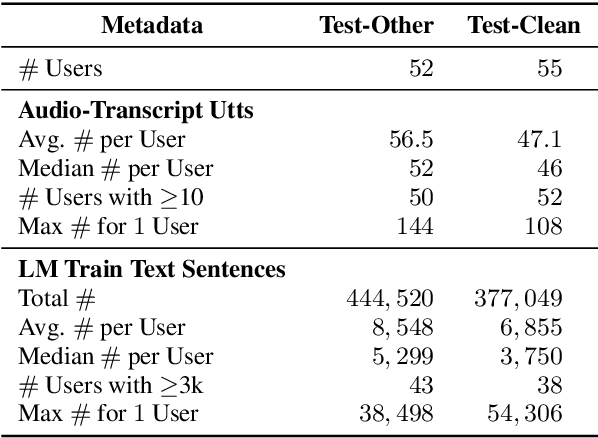
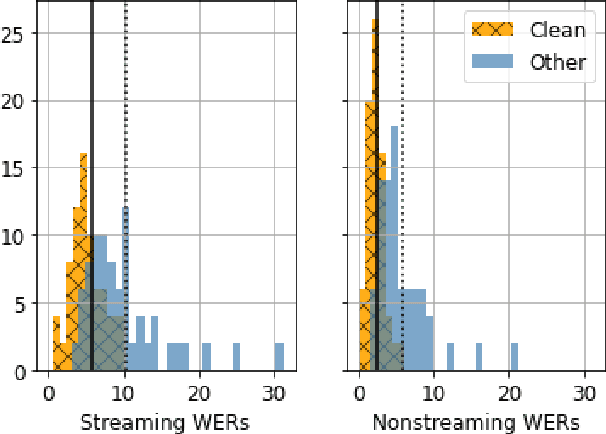
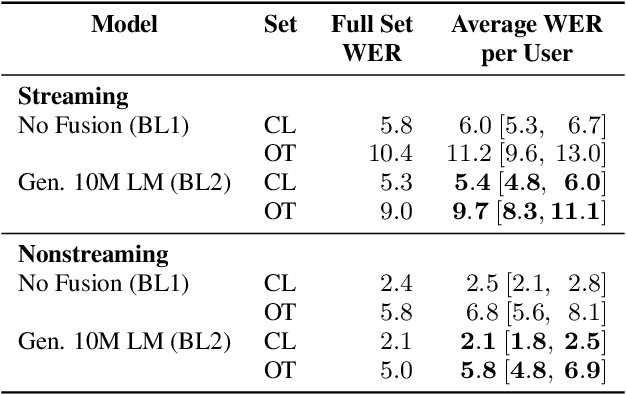
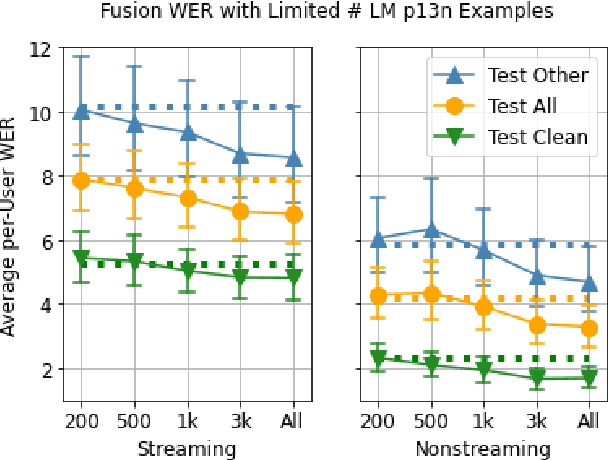
Personalization of speech models on mobile devices (on-device personalization) is an active area of research, but more often than not, mobile devices have more text-only data than paired audio-text data. We explore training a personalized language model on text-only data, used during inference to improve speech recognition performance for that user. We experiment on a user-clustered LibriSpeech corpus, supplemented with personalized text-only data for each user from Project Gutenberg. We release this User-Specific LibriSpeech (UserLibri) dataset to aid future personalization research. LibriSpeech audio-transcript pairs are grouped into 55 users from the test-clean dataset and 52 users from test-other. We are able to lower the average word error rate per user across both sets in streaming and nonstreaming models, including an improvement of 2.5 for the harder set of test-other users when streaming.
Fast and Robust Unsupervised Contextual Biasing for Speech Recognition
May 04, 2020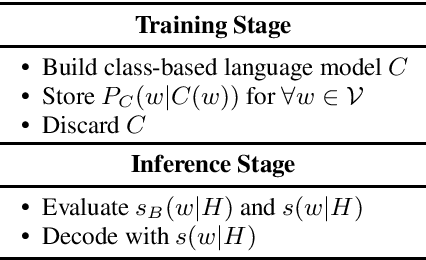
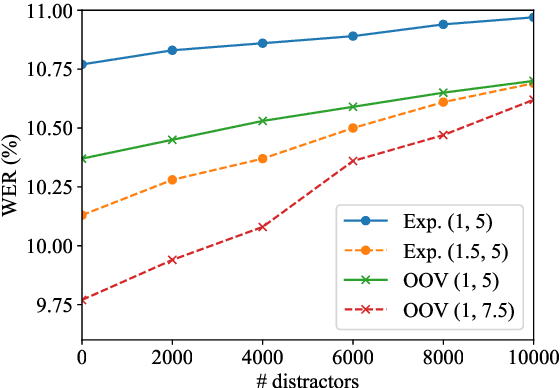
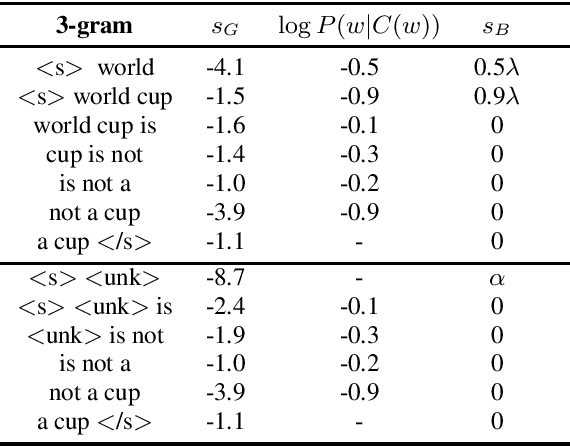
Automatic speech recognition (ASR) system is becoming a ubiquitous technology. Although its accuracy is closing the gap with that of human level under certain settings, one area that can further improve is to incorporate user-specific information or context to bias its prediction. A common framework is to dynamically construct a small language model from the provided contextual mini corpus and interpolate its score with the main language model during the decoding process. Here we propose an alternative approach that does not entail explicit contextual language model. Instead, we derive the bias score for every word in the system vocabulary from the training corpus. The method is unique in that 1) it does not require meta-data or class-label annotation for the context or the training corpus. 2) The bias score is proportional to the word's log-probability, thus not only would it bias the provided context, but also robust against irrelevant context (e.g. user mis-specified or in case where it is hard to quantify a tight scope). 3) The bias score for the entire vocabulary is pre-determined during the training stage, thereby eliminating computationally expensive language model construction during inference. We show significant improvement in recognition accuracy when the relevant context is available. Additionally, we also demonstrate that the proposed method exhibits high tolerance to false-triggering errors in the presence of irrelevant context.
Improving speech recognition models with small samples for air traffic control systems
Feb 16, 2021
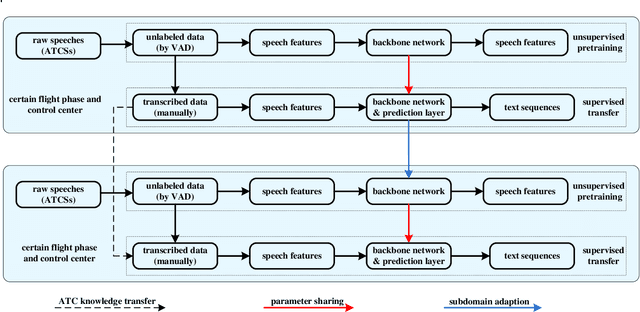
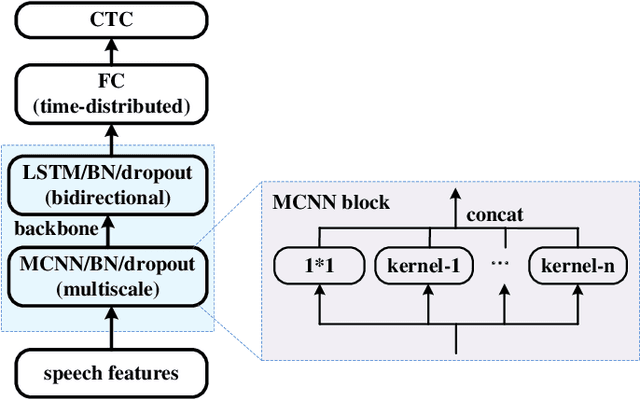
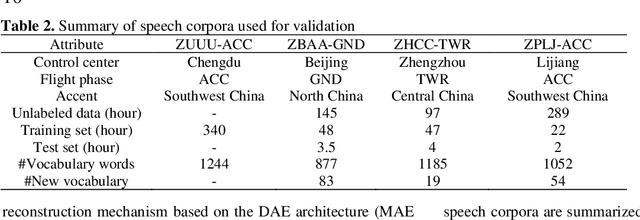
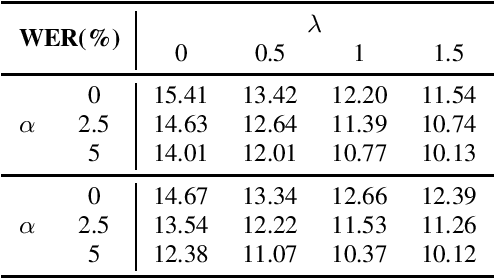
In the domain of air traffic control (ATC) systems, efforts to train a practical automatic speech recognition (ASR) model always faces the problem of small training samples since the collection and annotation of speech samples are expert- and domain-dependent task. In this work, a novel training approach based on pretraining and transfer learning is proposed to address this issue, and an improved end-to-end deep learning model is developed to address the specific challenges of ASR in the ATC domain. An unsupervised pretraining strategy is first proposed to learn speech representations from unlabeled samples for a certain dataset. Specifically, a masking strategy is applied to improve the diversity of the sample without losing their general patterns. Subsequently, transfer learning is applied to fine-tune a pretrained or other optimized baseline models to finally achieves the supervised ASR task. By virtue of the common terminology used in the ATC domain, the transfer learning task can be regarded as a sub-domain adaption task, in which the transferred model is optimized using a joint corpus consisting of baseline samples and new transcribed samples from the target dataset. This joint corpus construction strategy enriches the size and diversity of the training samples, which is important for addressing the issue of the small transcribed corpus. In addition, speed perturbation is applied to augment the new transcribed samples to further improve the quality of the speech corpus. Three real ATC datasets are used to validate the proposed ASR model and training strategies. The experimental results demonstrate that the ASR performance is significantly improved on all three datasets, with an absolute character error rate only one-third of that achieved through the supervised training. The applicability of the proposed strategies to other ASR approaches is also validated.