 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
RTMobile: Beyond Real-Time Mobile Acceleration of RNNs for Speech Recognition
Feb 19, 2020
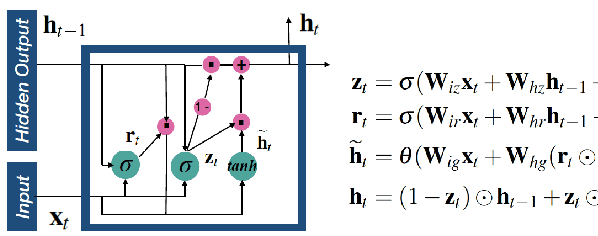
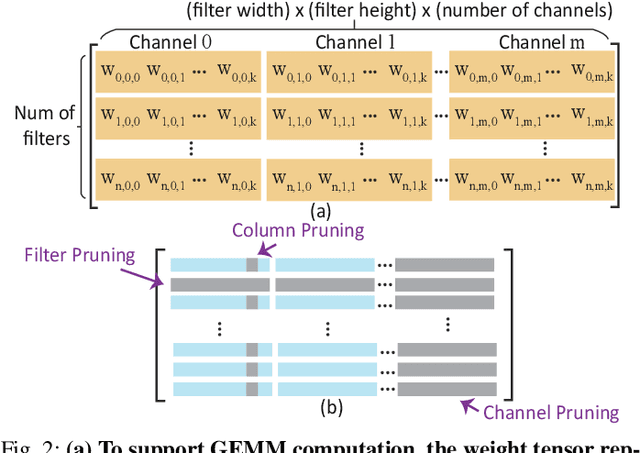
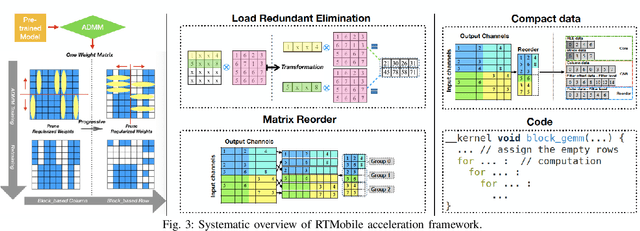
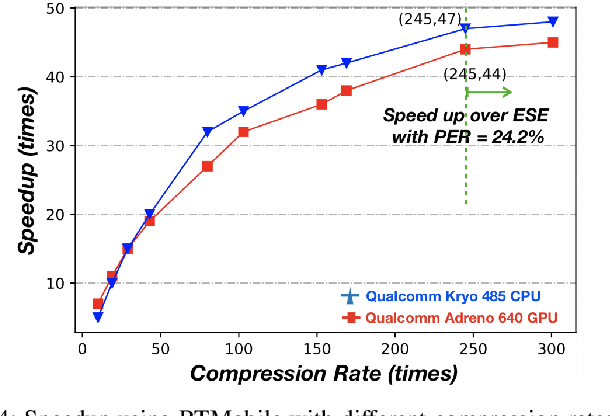
Recurrent neural networks (RNNs) based automatic speech recognition has nowadays become prevalent on mobile devices such as smart phones. However, previous RNN compression techniques either suffer from hardware performance overhead due to irregularity or significant accuracy loss due to the preserved regularity for hardware friendliness. In this work, we propose RTMobile that leverages both a novel block-based pruning approach and compiler optimizations to accelerate RNN inference on mobile devices. Our proposed RTMobile is the first work that can achieve real-time RNN inference on mobile platforms. Experimental results demonstrate that RTMobile can significantly outperform existing RNN hardware acceleration methods in terms of inference accuracy and time. Compared with prior work on FPGA, RTMobile using Adreno 640 embedded GPU on GRU can improve the energy-efficiency by about 40$\times$ while maintaining the same inference time.
Investigating the Lombard Effect Influence on End-to-End Audio-Visual Speech Recognition
Jul 09, 2019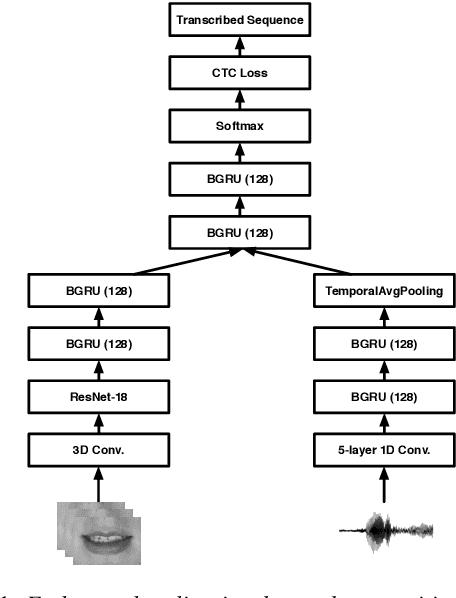

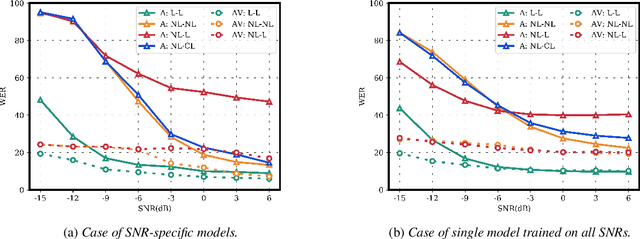
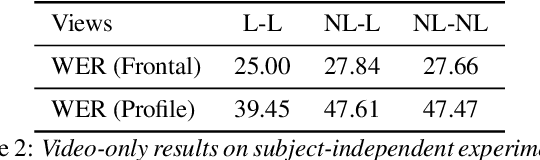
Several audio-visual speech recognition models have been recently proposed which aim to improve the robustness over audio-only models in the presence of noise. However, almost all of them ignore the impact of the Lombard effect, i.e., the change in speaking style in noisy environments which aims to make speech more intelligible and affects both the acoustic characteristics of speech and the lip movements. In this paper, we investigate the impact of the Lombard effect in audio-visual speech recognition. To the best of our knowledge, this is the first work which does so using end-to-end deep architectures and presents results on unseen speakers. Our results show that properly modelling Lombard speech is always beneficial. Even if a relatively small amount of Lombard speech is added to the training set then the performance in a real scenario, where noisy Lombard speech is present, can be significantly improved. We also show that the standard approach followed in the literature, where a model is trained and tested on noisy plain speech, provides a correct estimate of the video-only performance and slightly underestimates the audio-visual performance. In case of audio-only approaches, performance is overestimated for SNRs higher than -3dB and underestimated for lower SNRs.
Adversarial synthesis based data-augmentation for code-switched spoken language identification
May 30, 2022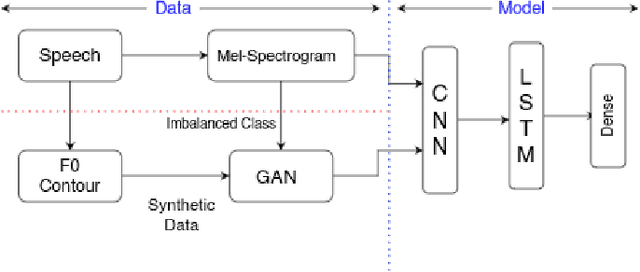
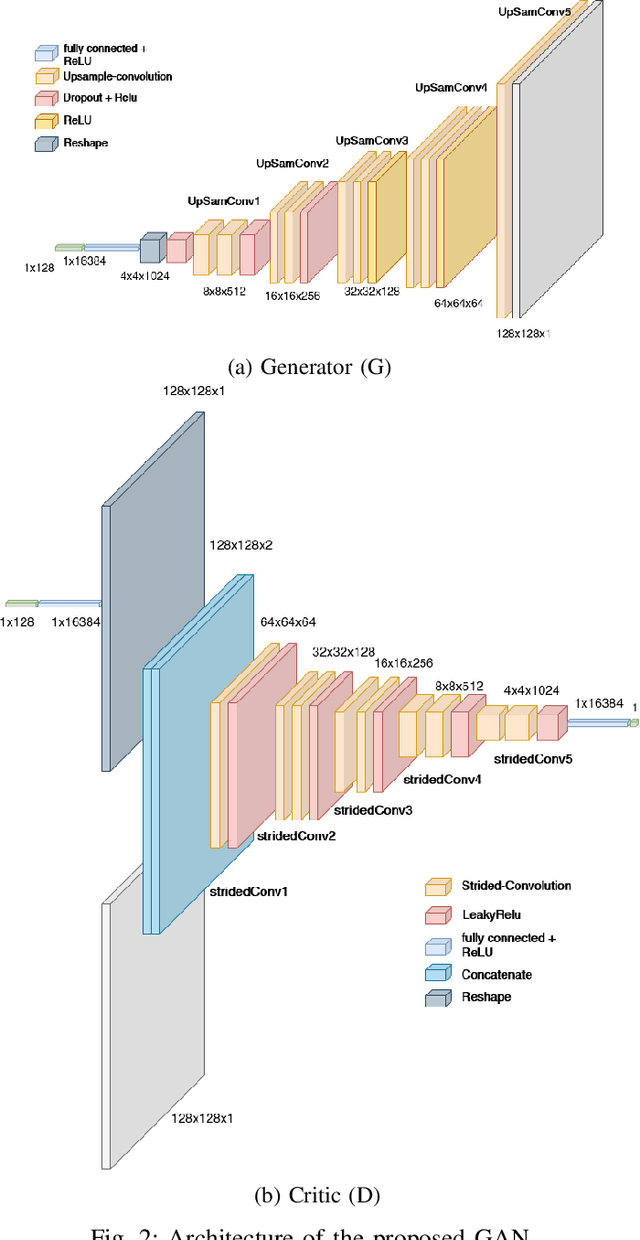
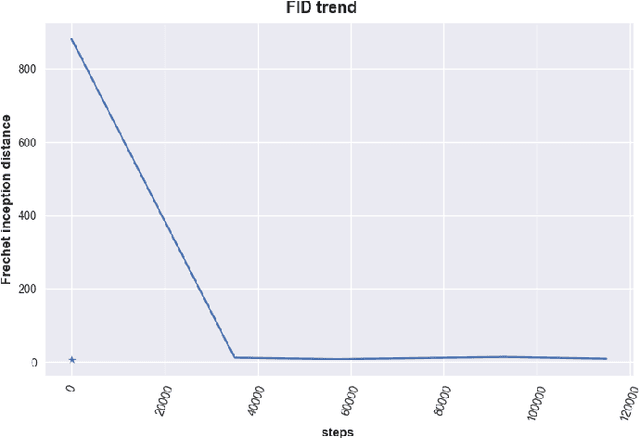
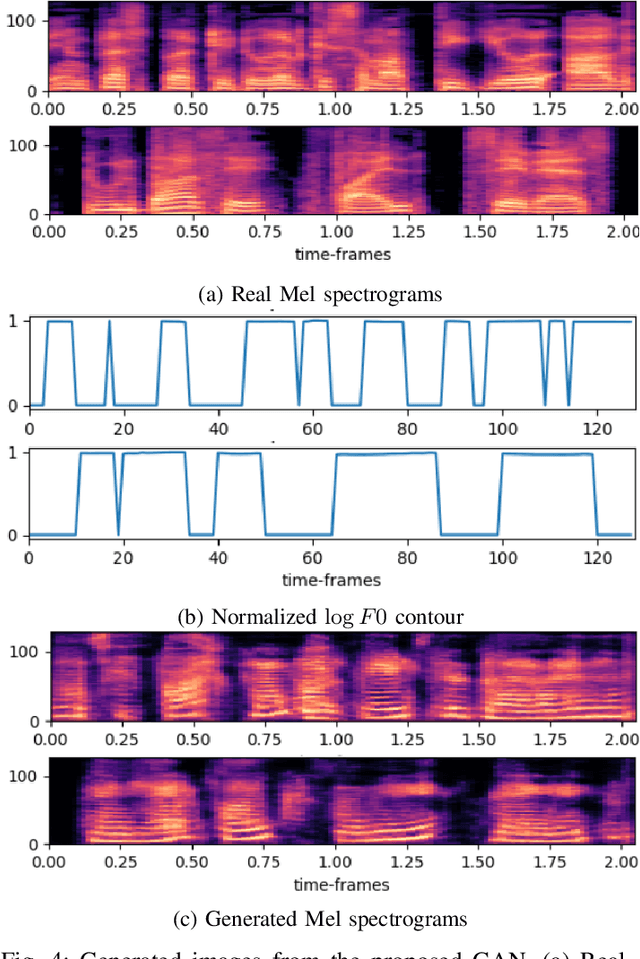
Spoken Language Identification (LID) is an important sub-task of Automatic Speech Recognition(ASR) that is used to classify the language(s) in an audio segment. Automatic LID plays an useful role in multilingual countries. In various countries, identifying a language becomes hard, due to the multilingual scenario where two or more than two languages are mixed together during conversation. Such phenomenon of speech is called as code-mixing or code-switching. This nature is followed not only in India but also in many Asian countries. Such code-mixed data is hard to find, which further reduces the capabilities of the spoken LID. Due to the lack of avalibility of this code-mixed data, it becomes a minority class in LID task. Hence, this work primarily addresses this problem using data augmentation as a solution on the minority code-switched class. This study focuses on Indic language code-mixed with English. Spoken LID is performed on Hindi, code-mixed with English. This research proposes Generative Adversarial Network (GAN) based data augmentation technique performed using Mel spectrograms for audio data. GANs have already been proven to be accurate in representing the real data distribution in the image domain. Proposed research exploits these capabilities of GANs in speech domains such as speech classification, automatic speech recognition,etc. GANs are trained to generate Mel spectrograms of the minority code-mixed class which are then used to augment data for the classifier. Utilizing GANs give an overall improvement on Unweighted Average Recall by an amount of 3.5\% as compared to a Convolutional Recurrent Neural Network (CRNN) classifier used as the baseline reference.
Decentralizing Feature Extraction with Quantum Convolutional Neural Network for Automatic Speech Recognition
Oct 26, 2020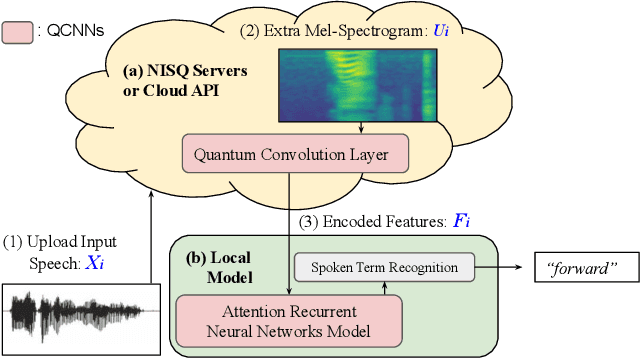

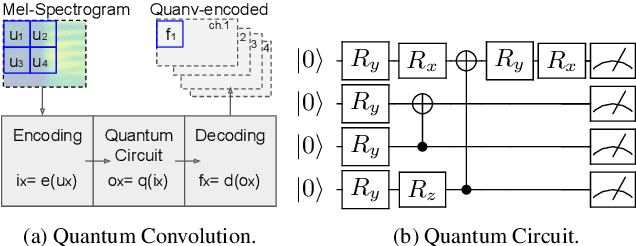
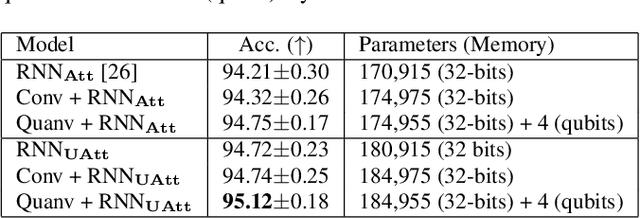
We propose a novel decentralized feature extraction approach in federated learning to address privacy-preservation issues for speech recognition. It is built upon a quantum convolutional neural network (QCNN) composed of a quantum circuit encoder for feature extraction, and a recurrent neural network (RNN) based end-to-end acoustic model (AM). To enhance model parameter protection in a decentralized architecture, an input speech is first up-streamed to a quantum computing server to extract Mel-spectrogram, and the corresponding convolutional features are encoded using a quantum circuit algorithm with random parameters. The encoded features are then down-streamed to the local RNN model for the final recognition. The proposed decentralized framework takes advantage of the quantum learning progress to secure models and to avoid privacy leakage attacks. Testing on the Google Speech Commands Dataset, the proposed QCNN encoder attains a competitive accuracy of 95.12\% in a decentralized model, which is better than the previous architectures using centralized RNN models with convolutional features. We also conduct an in-depth study of different quantum circuit encoder architectures to provide insights into designing QCNN-based feature extractors. Finally, neural saliency analyses demonstrate a high correlation between the proposed QCNN features, class activation maps, and the input Mel-spectrogram.
Multi-task Recurrent Model for True Multilingual Speech Recognition
Sep 27, 2016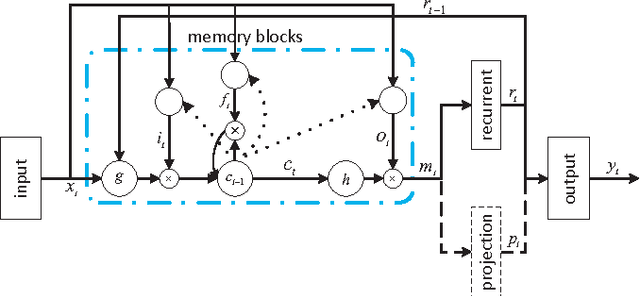
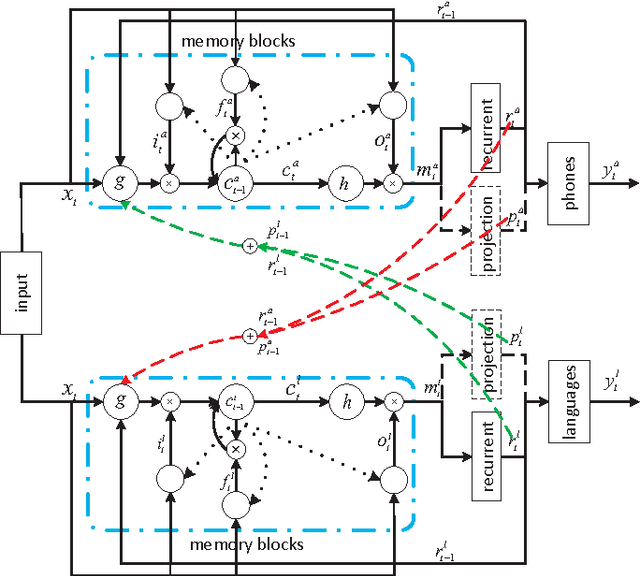
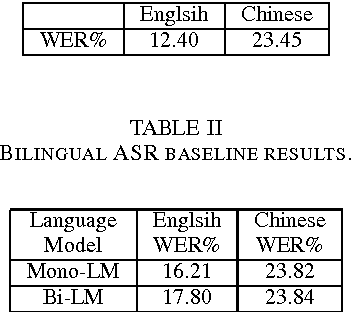
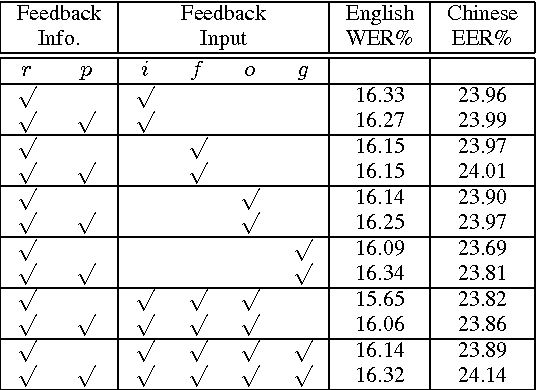
Research on multilingual speech recognition remains attractive yet challenging. Recent studies focus on learning shared structures under the multi-task paradigm, in particular a feature sharing structure. This approach has been found effective to improve performance on each individual language. However, this approach is only useful when the deployed system supports just one language. In a true multilingual scenario where multiple languages are allowed, performance will be significantly reduced due to the competition among languages in the decoding space. This paper presents a multi-task recurrent model that involves a multilingual speech recognition (ASR) component and a language recognition (LR) component, and the ASR component is informed of the language information by the LR component, leading to a language-aware recognition. We tested the approach on an English-Chinese bilingual recognition task. The results show that the proposed multi-task recurrent model can improve performance of multilingual recognition systems.
An Overview of Hindi Speech Recognition
May 09, 2013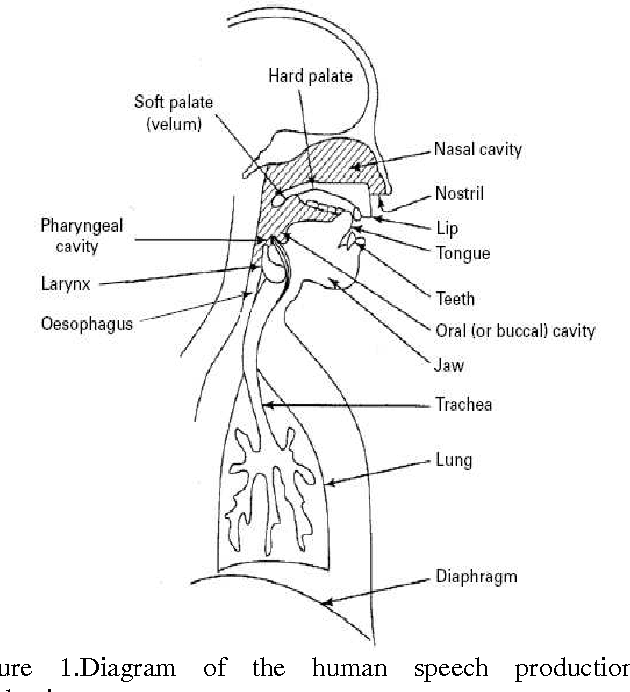

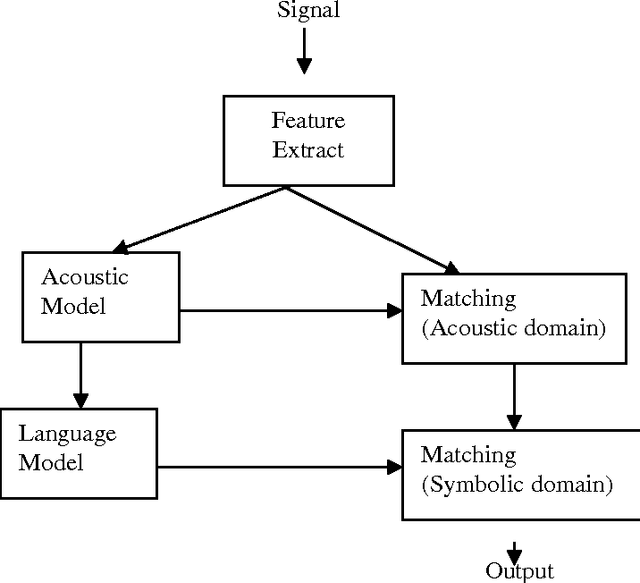
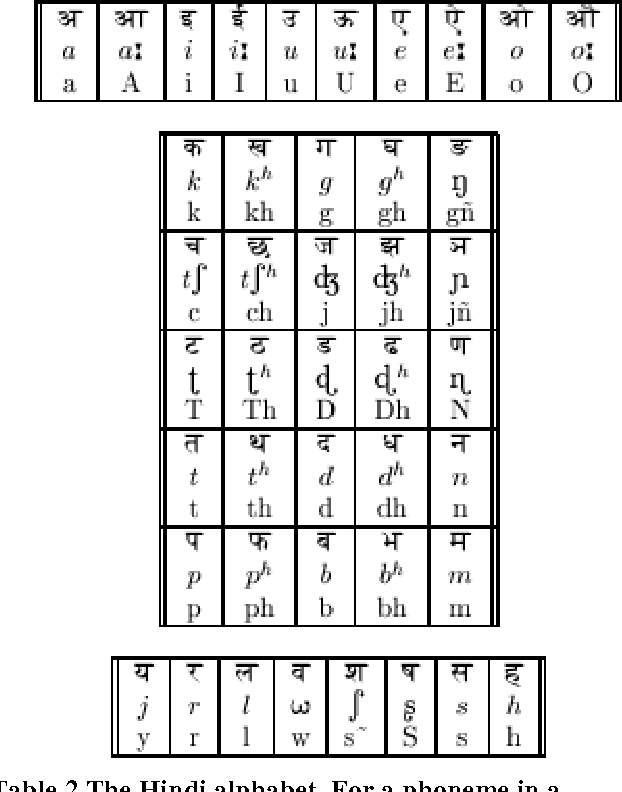
In this age of information technology, information access in a convenient manner has gained importance. Since speech is a primary mode of communication among human beings, it is natural for people to expect to be able to carry out spoken dialogue with computer. Speech recognition system permits ordinary people to speak to the computer to retrieve information. It is desirable to have a human computer dialogue in local language. Hindi being the most widely spoken Language in India is the natural primary human language candidate for human machine interaction. There are five pairs of vowels in Hindi languages; one member is longer than the other one. This paper describes an overview of speech recognition system that includes how speech is produced and the properties and characteristics of Hindi Phoneme.
Adversarial Attacks on ASR Systems: An Overview
Aug 03, 2022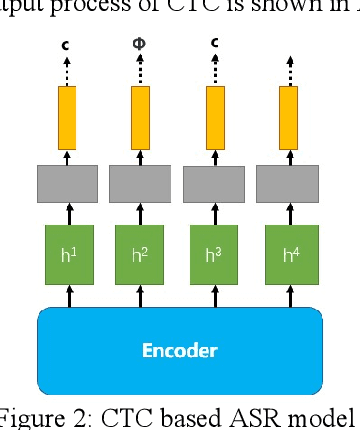
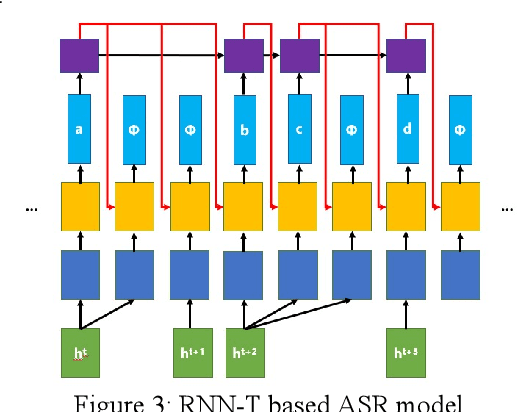
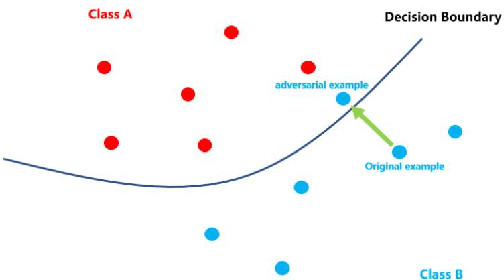
With the development of hardware and algorithms, ASR(Automatic Speech Recognition) systems evolve a lot. As The models get simpler, the difficulty of development and deployment become easier, ASR systems are getting closer to our life. On the one hand, we often use APPs or APIs of ASR to generate subtitles and record meetings. On the other hand, smart speaker and self-driving car rely on ASR systems to control AIoT devices. In past few years, there are a lot of works on adversarial examples attacks against ASR systems. By adding a small perturbation to the waveforms, the recognition results make a big difference. In this paper, we describe the development of ASR system, different assumptions of attacks, and how to evaluate these attacks. Next, we introduce the current works on adversarial examples attacks from two attack assumptions: white-box attack and black-box attack. Different from other surveys, we pay more attention to which layer they perturb waveforms in ASR system, the relationship between these attacks, and their implementation methods. We focus on the effect of their works.
Adversarial Joint Training with Self-Attention Mechanism for Robust End-to-End Speech Recognition
Apr 03, 2021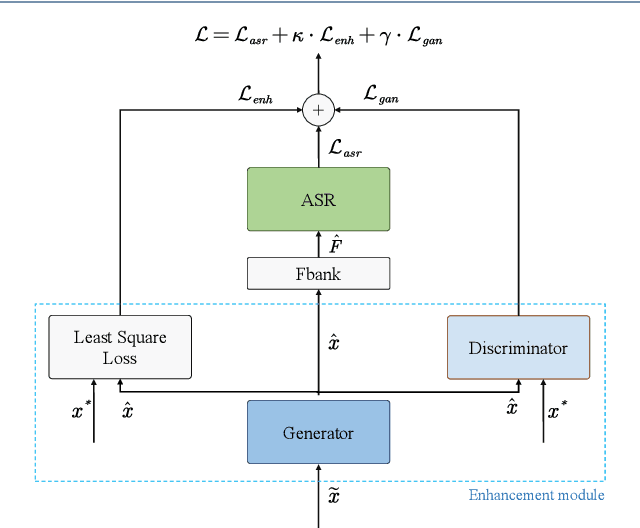

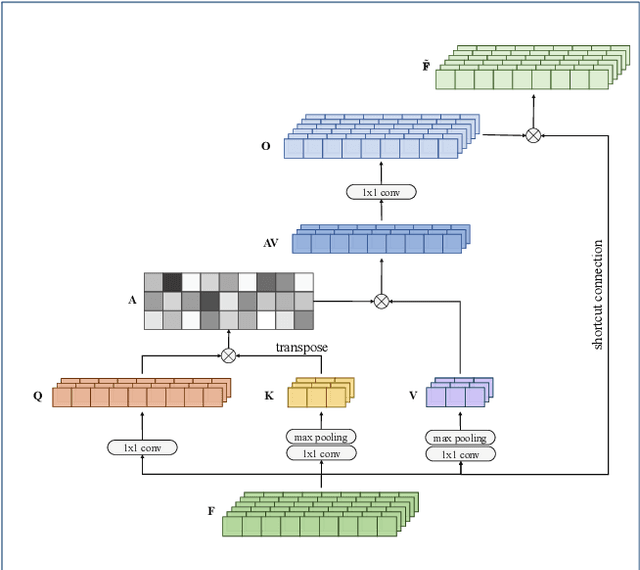
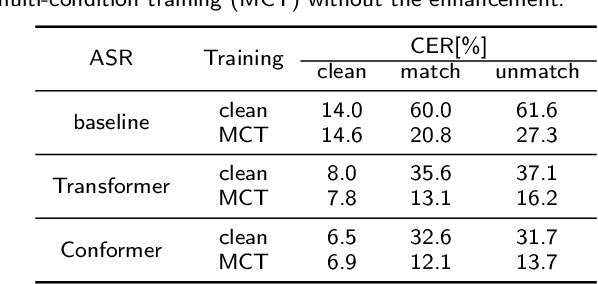
Lately, the self-attention mechanism has marked a new milestone in the field of automatic speech recognition (ASR). Nevertheless, its performance is susceptible to environmental intrusions as the system predicts the next output symbol depending on the full input sequence and the previous predictions. Inspired by the extensive applications of the generative adversarial networks (GANs) in speech enhancement and ASR tasks, we propose an adversarial joint training framework with the self-attention mechanism to boost the noise robustness of the ASR system. Generally, it consists of a self-attention speech enhancement GAN and a self-attention end-to-end ASR model. There are two highlights which are worth noting in this proposed framework. One is that it benefits from the advancement of both self-attention mechanism and GANs; while the other is that the discriminator of GAN plays the role of the global discriminant network in the stage of the adversarial joint training, which guides the enhancement front-end to capture more compatible structures for the subsequent ASR module and thereby offsets the limitation of the separate training and handcrafted loss functions. With the adversarial joint optimization, the proposed framework is expected to learn more robust representations suitable for the ASR task. We execute systematic experiments on the corpus AISHELL-1, and the experimental results show that on the artificial noisy test set, the proposed framework achieves the relative improvements of 66% compared to the ASR model trained by clean data solely, 35.1% compared to the speech enhancement & ASR scheme without joint training, and 5.3% compared to multi-condition training.
VoxSRC 2022: The Fourth VoxCeleb Speaker Recognition Challenge
Feb 20, 2023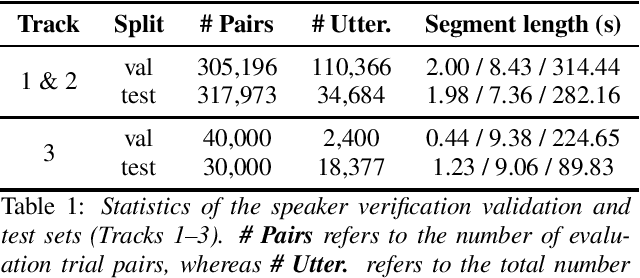
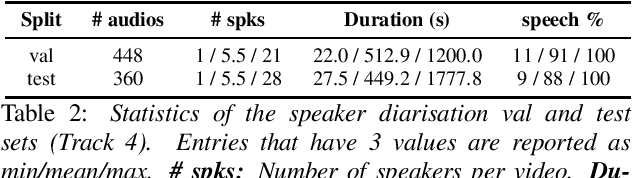
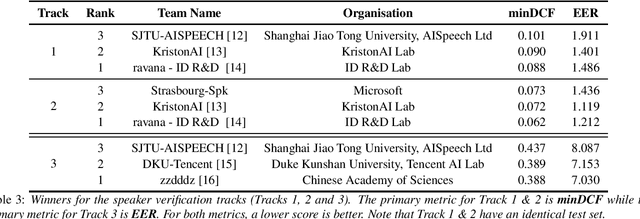

This paper summarises the findings from the VoxCeleb Speaker Recognition Challenge 2022 (VoxSRC-22), which was held in conjunction with INTERSPEECH 2022. The goal of this challenge was to evaluate how well state-of-the-art speaker recognition systems can diarise and recognise speakers from speech obtained "in the wild". The challenge consisted of: (i) the provision of publicly available speaker recognition and diarisation data from YouTube videos together with ground truth annotation and standardised evaluation software; and (ii) a public challenge and hybrid workshop held at INTERSPEECH 2022. We describe the four tracks of our challenge along with the baselines, methods, and results. We conclude with a discussion on the new domain-transfer focus of VoxSRC-22, and on the progression of the challenge from the previous three editions.