 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Incremental Learning for End-to-End Automatic Speech Recognition
May 11, 2020
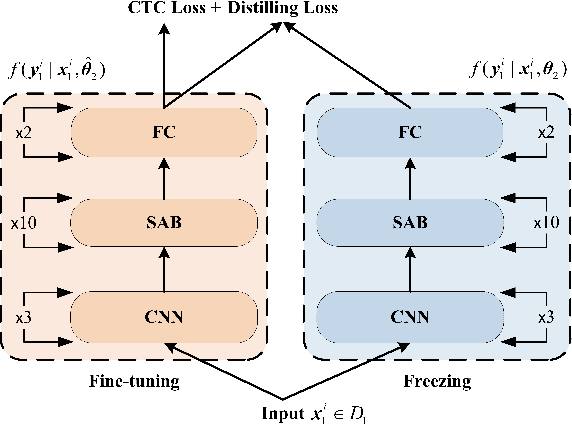
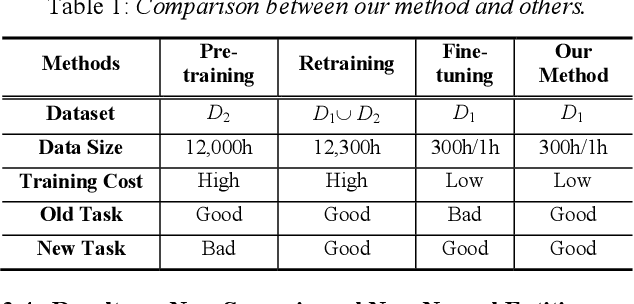
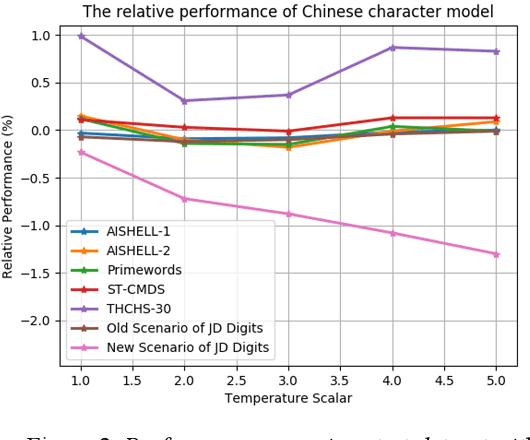
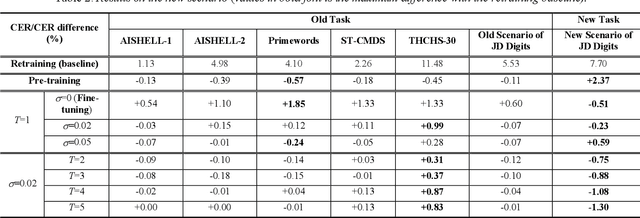
We propose an incremental learning for end-to-end Automatic Speech Recognition (ASR) to extend the model's capacity on a new task while retaining the performance on existing ones. The proposed method is effective without accessing to the old dataset to address the issues of high training cost and old dataset unavailability. To achieve this, knowledge distillation is applied as a guidance to retain the recognition ability from the previous model, which is then combined with the new ASR task for model optimization. With an ASR model pre-trained on 12,000h Mandarin speech, we test our proposed method on 300h new scenario task and 1h new named entities task. Experiments show that our method yields 3.25% and 0.88% absolute Character Error Rate (CER) reduction on the new scenario, when compared with the pre-trained model and the full-data retraining baseline, respectively. It even yields a surprising 0.37% absolute CER reduction on the new scenario than the fine-tuning. For the new named entities task, our method significantly improves the accuracy compared with the pre-trained model, i.e. 16.95% absolute CER reduction. For both of the new task adaptions, the new models still maintain a same accuracy with the baseline on the old tasks.
Rank-1 Constrained Multichannel Wiener Filter for Speech Recognition in Noisy Environments
Nov 15, 2017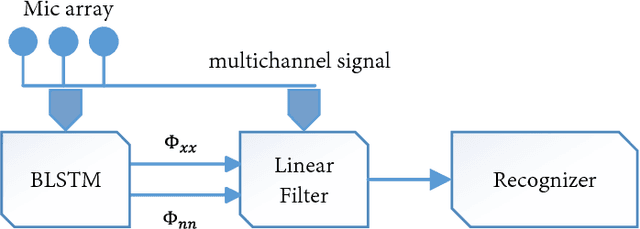

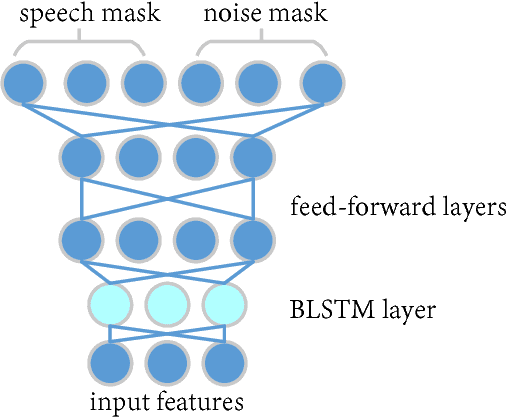
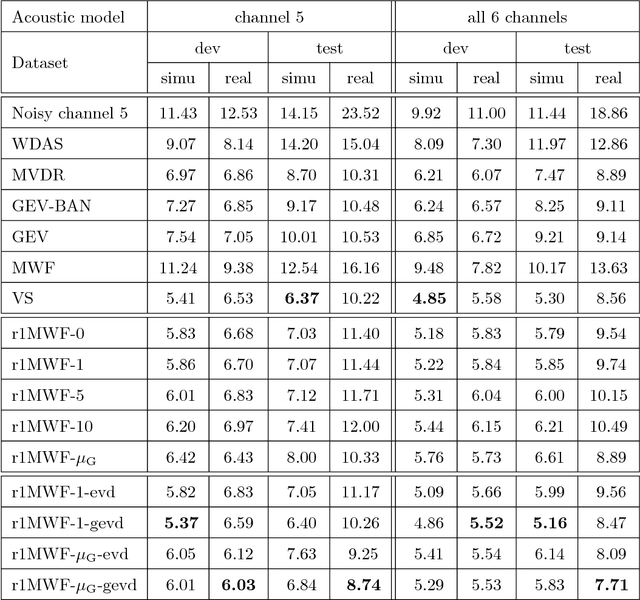
Multichannel linear filters, such as the Multichannel Wiener Filter (MWF) and the Generalized Eigenvalue (GEV) beamformer are popular signal processing techniques which can improve speech recognition performance. In this paper, we present an experimental study on these linear filters in a specific speech recognition task, namely the CHiME-4 challenge, which features real recordings in multiple noisy environments. Specifically, the rank-1 MWF is employed for noise reduction and a new constant residual noise power constraint is derived which enhances the recognition performance. To fulfill the underlying rank-1 assumption, the speech covariance matrix is reconstructed based on eigenvectors or generalized eigenvectors. Then the rank-1 constrained MWF is evaluated with alternative multichannel linear filters under the same framework, which involves a Bidirectional Long Short-Term Memory (BLSTM) network for mask estimation. The proposed filter outperforms alternative ones, leading to a 40% relative Word Error Rate (WER) reduction compared with the baseline Weighted Delay and Sum (WDAS) beamformer on the real test set, and a 15% relative WER reduction compared with the GEV-BAN method. The results also suggest that the speech recognition accuracy correlates more with the Mel-frequency cepstral coefficients (MFCC) feature variance than with the noise reduction or the speech distortion level.
Internal Language Model Estimation for Domain-Adaptive End-to-End Speech Recognition
Nov 03, 2020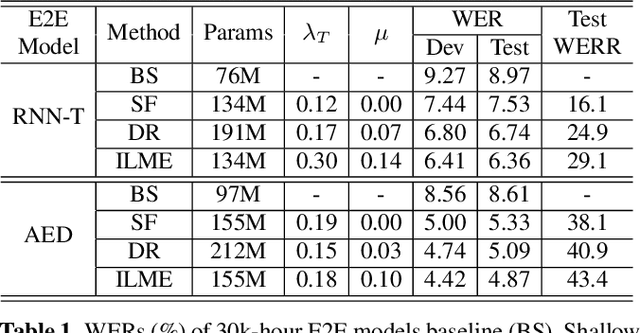
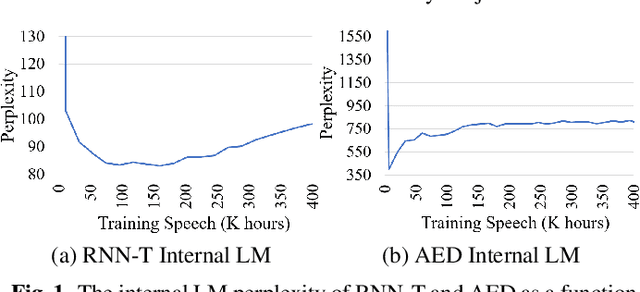
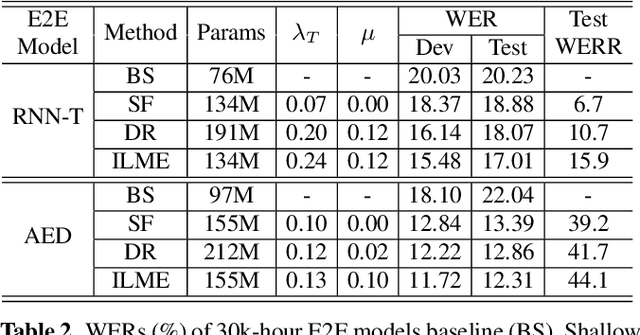
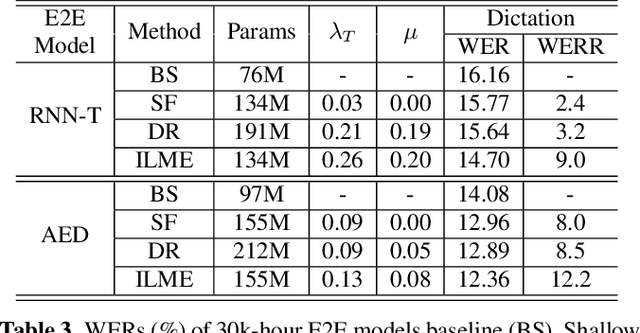
The external language models (LM) integration remains a challenging task for end-to-end (E2E) automatic speech recognition (ASR) which has no clear division between acoustic and language models. In this work, we propose an internal LM estimation (ILME) method to facilitate a more effective integration of the external LM with all pre-existing E2E models with no additional model training, including the most popular recurrent neural network transducer (RNN-T) and attention-based encoder-decoder (AED) models. Trained with audio-transcript pairs, an E2E model implicitly learns an internal LM that characterizes the training data in the source domain. With ILME, the internal LM scores of an E2E model are estimated and subtracted from the log-linear interpolation between the scores of the E2E model and the external LM. The internal LM scores are approximated as the output of an E2E model when eliminating its acoustic components. ILME can alleviate the domain mismatch between training and testing, or improve the multi-domain E2E ASR. Experimented with 30K-hour trained RNN-T and AED models, ILME achieves up to 15.5% and 6.8% relative word error rate reductions from Shallow Fusion on out-of-domain LibriSpeech and in-domain Microsoft production test sets, respectively.
* 8 pages, 2 figures, SLT 2021
FSER: Deep Convolutional Neural Networks for Speech Emotion Recognition
Sep 15, 2021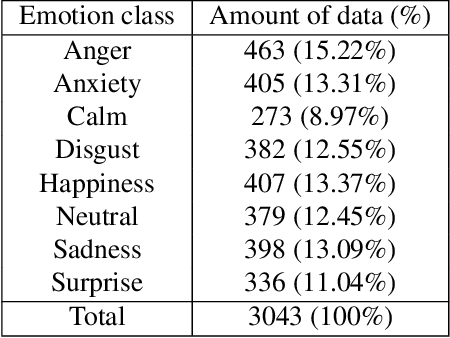
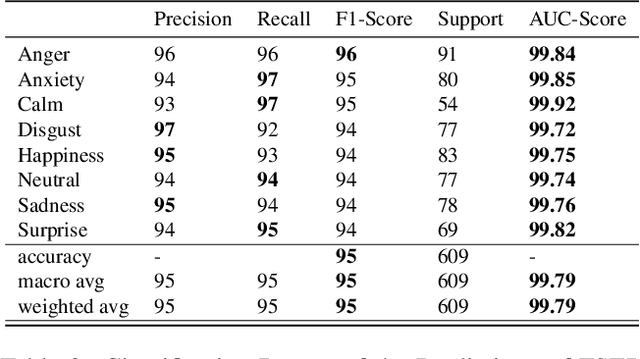
Using mel-spectrograms over conventional MFCCs features, we assess the abilities of convolutional neural networks to accurately recognize and classify emotions from speech data. We introduce FSER, a speech emotion recognition model trained on four valid speech databases, achieving a high-classification accuracy of 95,05\%, over 8 different emotion classes: anger, anxiety, calm, disgust, happiness, neutral, sadness, surprise. On each benchmark dataset, FSER outperforms the best models introduced so far, achieving a state-of-the-art performance. We show that FSER stays reliable, independently of the language, sex identity, and any other external factor. Additionally, we describe how FSER could potentially be used to improve mental and emotional health care and how our analysis and findings serve as guidelines and benchmarks for further works in the same direction.
Compute Cost Amortized Transformer for Streaming ASR
Jul 05, 2022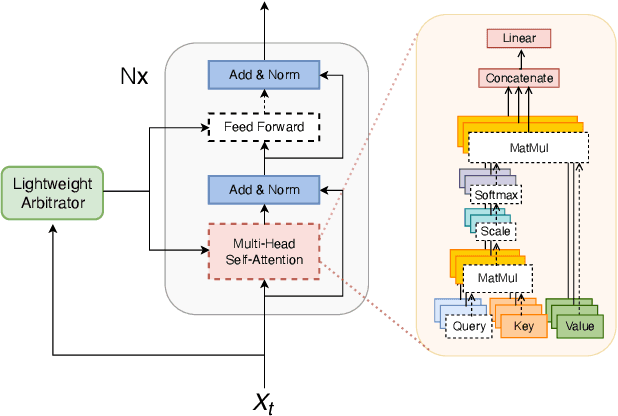
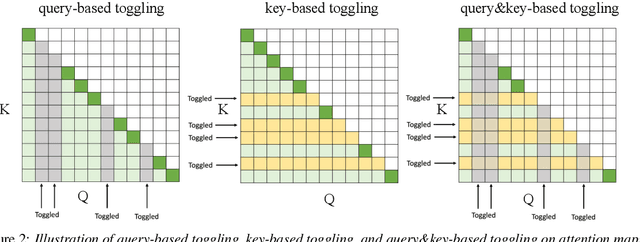
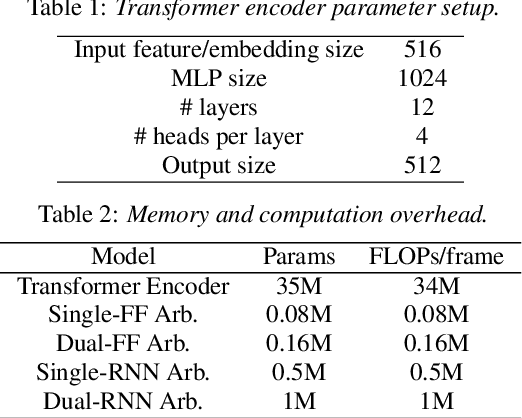
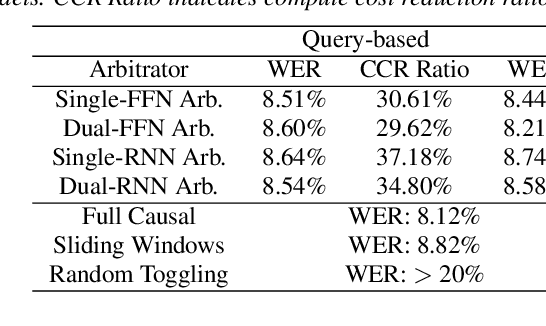
We present a streaming, Transformer-based end-to-end automatic speech recognition (ASR) architecture which achieves efficient neural inference through compute cost amortization. Our architecture creates sparse computation pathways dynamically at inference time, resulting in selective use of compute resources throughout decoding, enabling significant reductions in compute with minimal impact on accuracy. The fully differentiable architecture is trained end-to-end with an accompanying lightweight arbitrator mechanism operating at the frame-level to make dynamic decisions on each input while a tunable loss function is used to regularize the overall level of compute against predictive performance. We report empirical results from experiments using the compute amortized Transformer-Transducer (T-T) model conducted on LibriSpeech data. Our best model can achieve a 60% compute cost reduction with only a 3% relative word error rate (WER) increase.
An Overview of Hindi Speech Recognition
May 09, 2013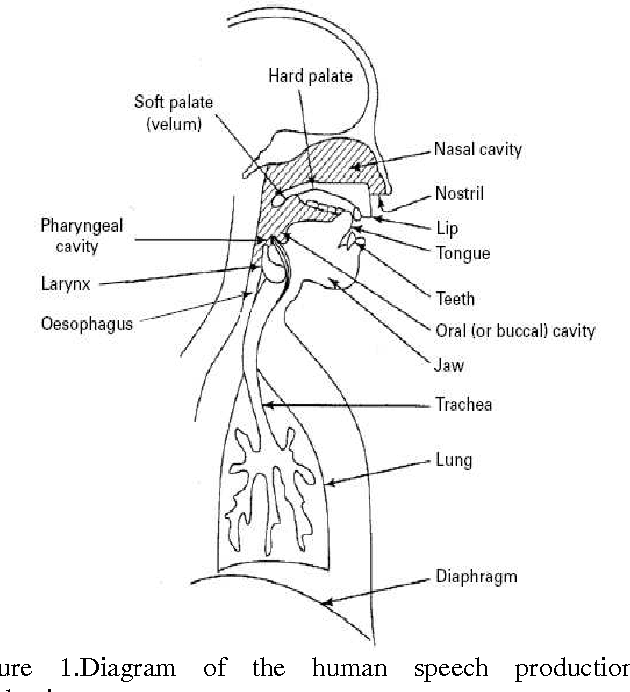

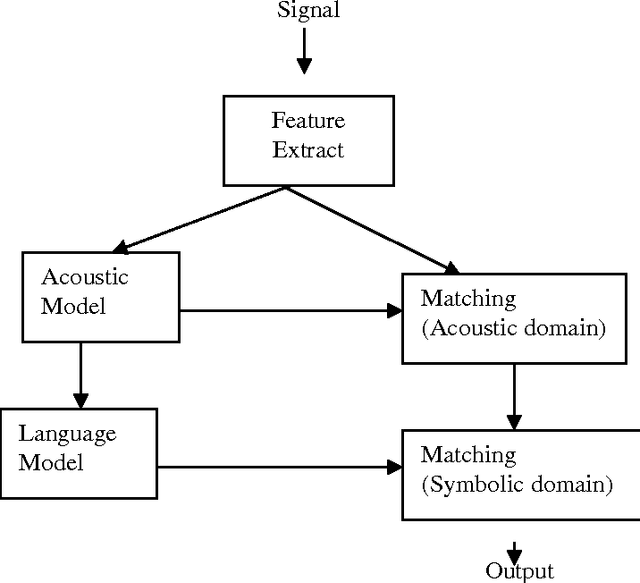
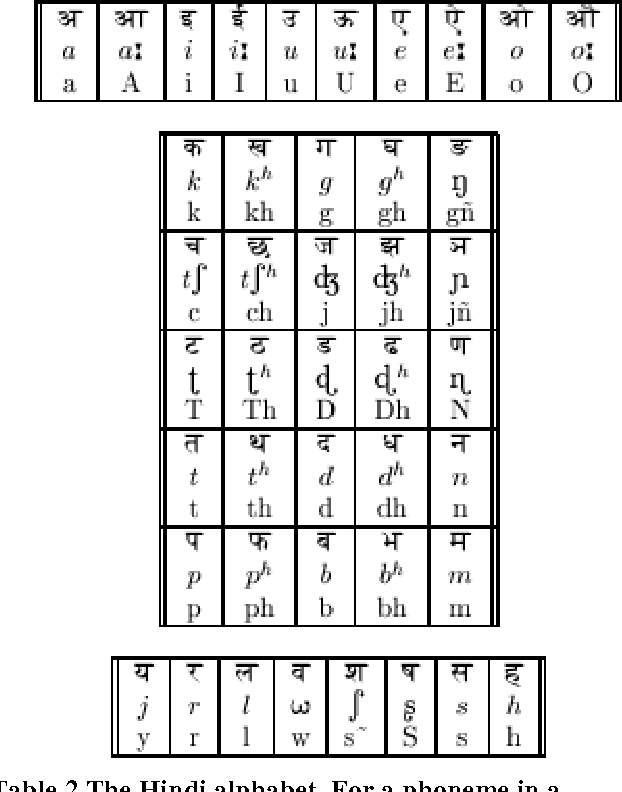
In this age of information technology, information access in a convenient manner has gained importance. Since speech is a primary mode of communication among human beings, it is natural for people to expect to be able to carry out spoken dialogue with computer. Speech recognition system permits ordinary people to speak to the computer to retrieve information. It is desirable to have a human computer dialogue in local language. Hindi being the most widely spoken Language in India is the natural primary human language candidate for human machine interaction. There are five pairs of vowels in Hindi languages; one member is longer than the other one. This paper describes an overview of speech recognition system that includes how speech is produced and the properties and characteristics of Hindi Phoneme.
Transformer-Transducer: End-to-End Speech Recognition with Self-Attention
Oct 28, 2019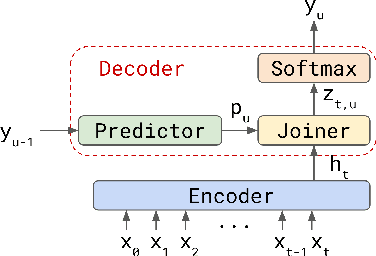
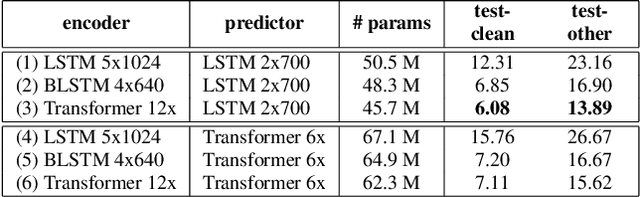
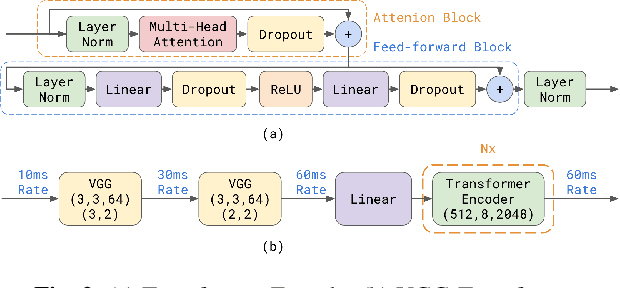
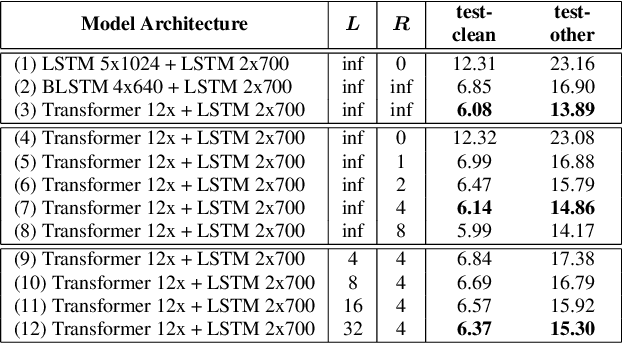
We explore options to use Transformer networks in neural transducer for end-to-end speech recognition. Transformer networks use self-attention for sequence modeling and comes with advantages in parallel computation and capturing contexts. We propose 1) using VGGNet with causal convolution to incorporate positional information and reduce frame rate for efficient inference 2) using truncated self-attention to enable streaming for Transformer and reduce computational complexity. All experiments are conducted on the public LibriSpeech corpus. The proposed Transformer-Transducer outperforms neural transducer with LSTM/BLSTM networks and achieved word error rates of 6.37 % on the test-clean set and 15.30 % on the test-other set, while remaining streamable, compact with 45.7M parameters for the entire system, and computationally efficient with complexity of O(T), where T is input sequence length.
Investigating the Lombard Effect Influence on End-to-End Audio-Visual Speech Recognition
Jul 09, 2019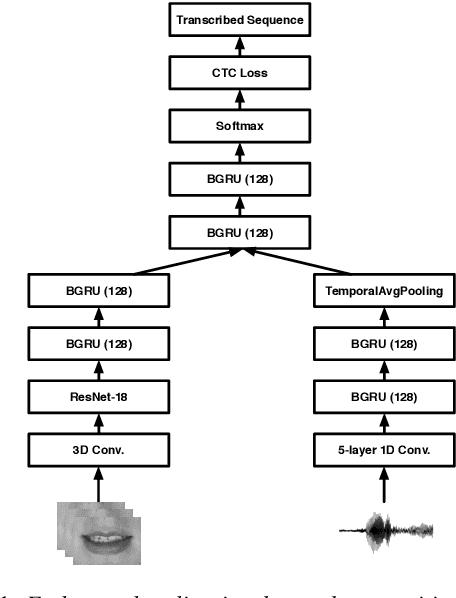

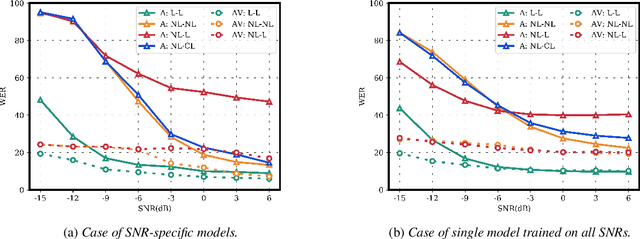
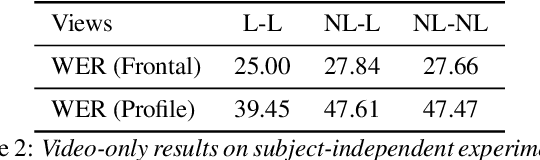
Several audio-visual speech recognition models have been recently proposed which aim to improve the robustness over audio-only models in the presence of noise. However, almost all of them ignore the impact of the Lombard effect, i.e., the change in speaking style in noisy environments which aims to make speech more intelligible and affects both the acoustic characteristics of speech and the lip movements. In this paper, we investigate the impact of the Lombard effect in audio-visual speech recognition. To the best of our knowledge, this is the first work which does so using end-to-end deep architectures and presents results on unseen speakers. Our results show that properly modelling Lombard speech is always beneficial. Even if a relatively small amount of Lombard speech is added to the training set then the performance in a real scenario, where noisy Lombard speech is present, can be significantly improved. We also show that the standard approach followed in the literature, where a model is trained and tested on noisy plain speech, provides a correct estimate of the video-only performance and slightly underestimates the audio-visual performance. In case of audio-only approaches, performance is overestimated for SNRs higher than -3dB and underestimated for lower SNRs.
Multi-task Recurrent Model for True Multilingual Speech Recognition
Sep 27, 2016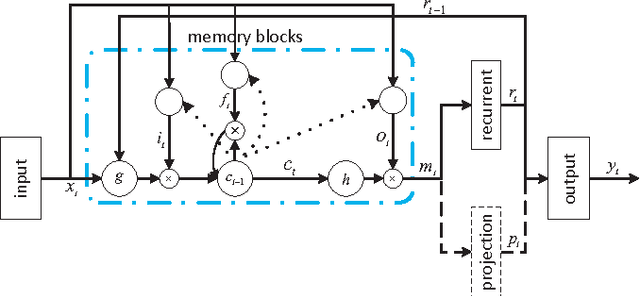
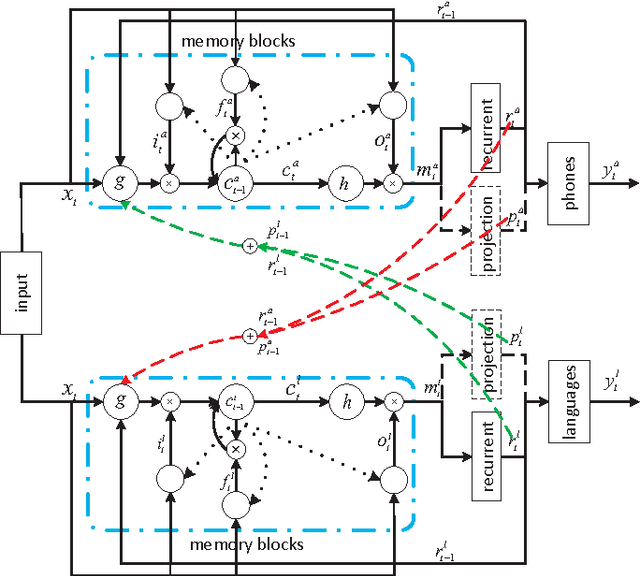
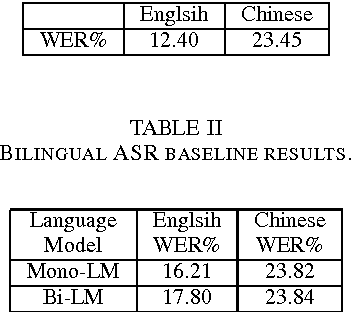
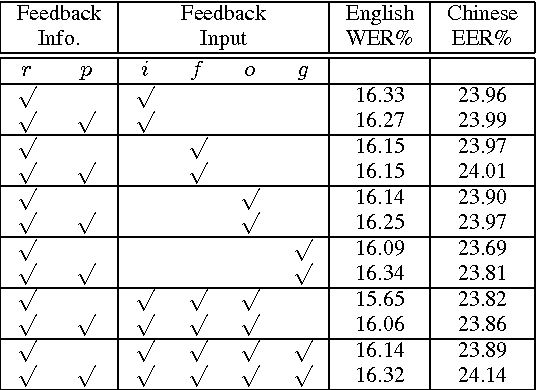
Research on multilingual speech recognition remains attractive yet challenging. Recent studies focus on learning shared structures under the multi-task paradigm, in particular a feature sharing structure. This approach has been found effective to improve performance on each individual language. However, this approach is only useful when the deployed system supports just one language. In a true multilingual scenario where multiple languages are allowed, performance will be significantly reduced due to the competition among languages in the decoding space. This paper presents a multi-task recurrent model that involves a multilingual speech recognition (ASR) component and a language recognition (LR) component, and the ASR component is informed of the language information by the LR component, leading to a language-aware recognition. We tested the approach on an English-Chinese bilingual recognition task. The results show that the proposed multi-task recurrent model can improve performance of multilingual recognition systems.
RTMobile: Beyond Real-Time Mobile Acceleration of RNNs for Speech Recognition
Feb 19, 2020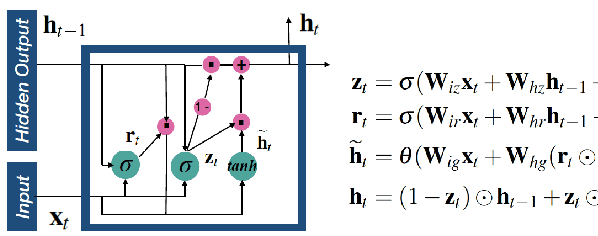
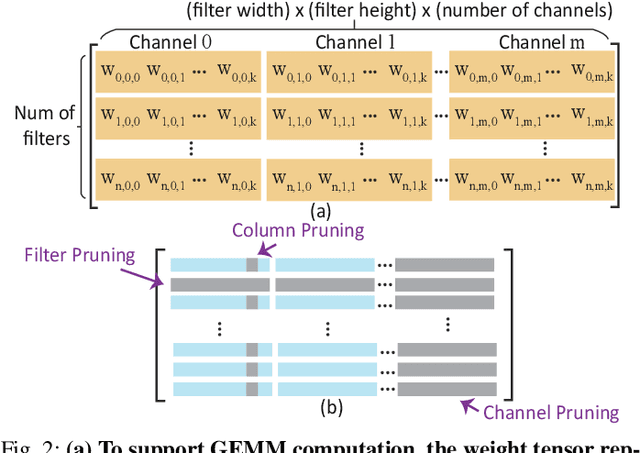
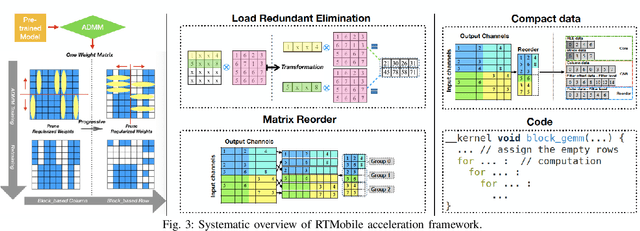
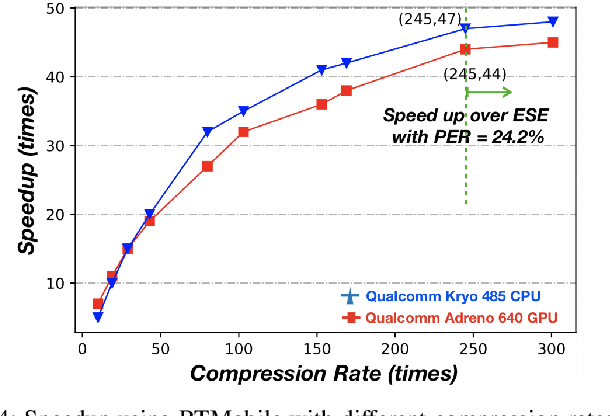
Recurrent neural networks (RNNs) based automatic speech recognition has nowadays become prevalent on mobile devices such as smart phones. However, previous RNN compression techniques either suffer from hardware performance overhead due to irregularity or significant accuracy loss due to the preserved regularity for hardware friendliness. In this work, we propose RTMobile that leverages both a novel block-based pruning approach and compiler optimizations to accelerate RNN inference on mobile devices. Our proposed RTMobile is the first work that can achieve real-time RNN inference on mobile platforms. Experimental results demonstrate that RTMobile can significantly outperform existing RNN hardware acceleration methods in terms of inference accuracy and time. Compared with prior work on FPGA, RTMobile using Adreno 640 embedded GPU on GRU can improve the energy-efficiency by about 40$\times$ while maintaining the same inference time.