 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Unsupervised Domain Adaptation for Robust Speech Recognition via Variational Autoencoder-Based Data Augmentation
Sep 22, 2017
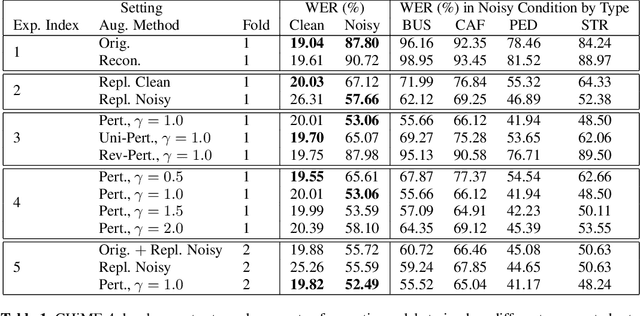
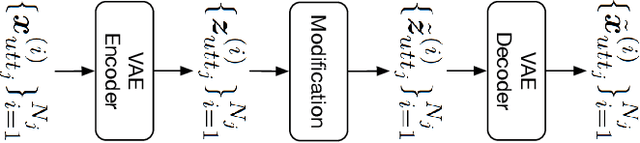
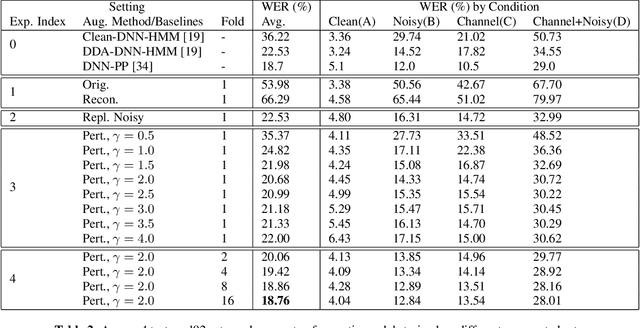
Domain mismatch between training and testing can lead to significant degradation in performance in many machine learning scenarios. Unfortunately, this is not a rare situation for automatic speech recognition deployments in real-world applications. Research on robust speech recognition can be regarded as trying to overcome this domain mismatch issue. In this paper, we address the unsupervised domain adaptation problem for robust speech recognition, where both source and target domain speech are presented, but word transcripts are only available for the source domain speech. We present novel augmentation-based methods that transform speech in a way that does not change the transcripts. Specifically, we first train a variational autoencoder on both source and target domain data (without supervision) to learn a latent representation of speech. We then transform nuisance attributes of speech that are irrelevant to recognition by modifying the latent representations, in order to augment labeled training data with additional data whose distribution is more similar to the target domain. The proposed method is evaluated on the CHiME-4 dataset and reduces the absolute word error rate (WER) by as much as 35% compared to the non-adapted baseline.
ViDeBERTa: A powerful pre-trained language model for Vietnamese
Jan 25, 2023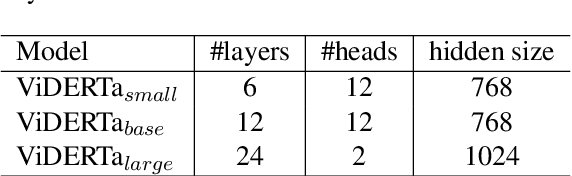
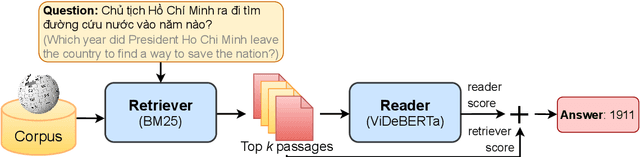
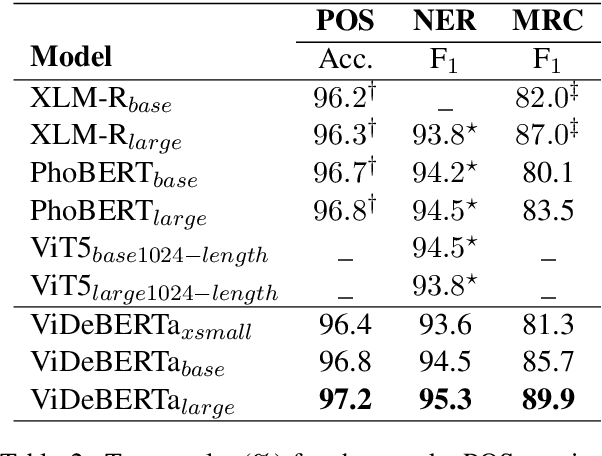
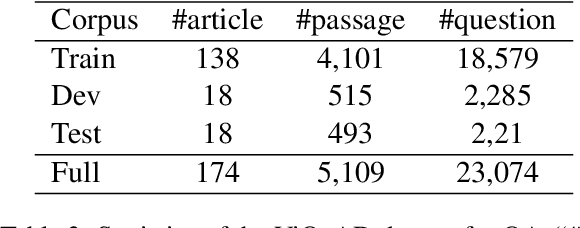
This paper presents ViDeBERTa, a new pre-trained monolingual language model for Vietnamese, with three versions - ViDeBERTa_xsmall, ViDeBERTa_base, and ViDeBERTa_large, which are pre-trained on a large-scale corpus of high-quality and diverse Vietnamese texts using DeBERTa architecture. Although many successful pre-trained language models based on Transformer have been widely proposed for the English language, there are still few pre-trained models for Vietnamese, a low-resource language, that perform good results on downstream tasks, especially Question answering. We fine-tune and evaluate our model on three important natural language downstream tasks, Part-of-speech tagging, Named-entity recognition, and Question answering. The empirical results demonstrate that ViDeBERTa with far fewer parameters surpasses the previous state-of-the-art models on multiple Vietnamese-specific natural language understanding tasks. Notably, ViDeBERTa_base with 86M parameters, which is only about 23% of PhoBERT_large with 370M parameters, still performs the same or better results than the previous state-of-the-art model. Our ViDeBERTa models are available at: https://github.com/HySonLab/ViDeBERTa.
NeuralEcho: A Self-Attentive Recurrent Neural Network For Unified Acoustic Echo Suppression And Speech Enhancement
May 20, 2022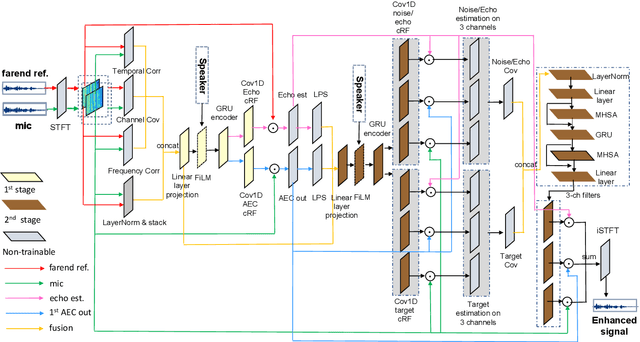
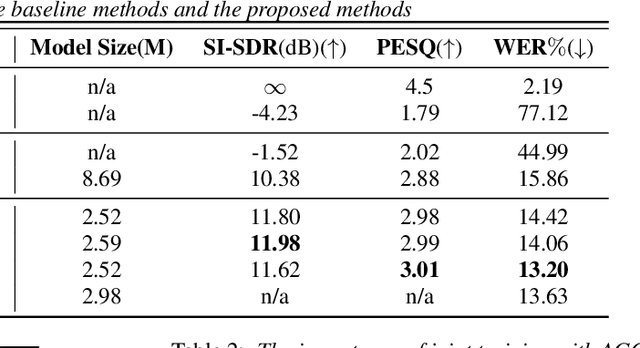
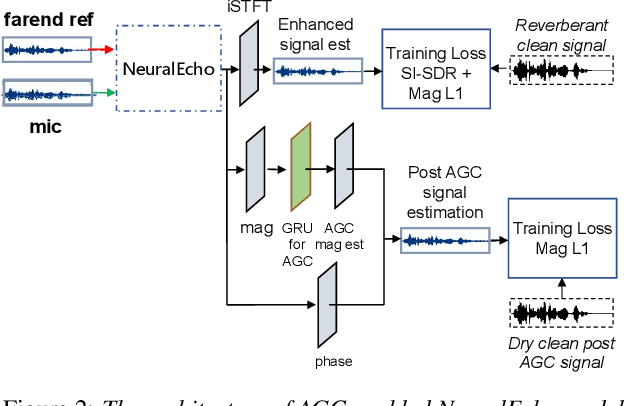

Acoustic echo cancellation (AEC) plays an important role in the full-duplex speech communication as well as the front-end speech enhancement for recognition in the conditions when the loudspeaker plays back. In this paper, we present an all-deep-learning framework that implicitly estimates the second order statistics of echo/noise and target speech, and jointly solves echo and noise suppression through an attention based recurrent neural network. The proposed model outperforms the state-of-the-art joint echo cancellation and speech enhancement method F-T-LSTM in terms of objective speech quality metrics, speech recognition accuracy and model complexity. We show that this model can work with speaker embedding for better target speech enhancement and furthermore develop a branch for automatic gain control (AGC) task to form an all-in-one front-end speech enhancement system.
Investigating data partitioning strategies for crosslinguistic low-resource ASR evaluation
Aug 26, 2022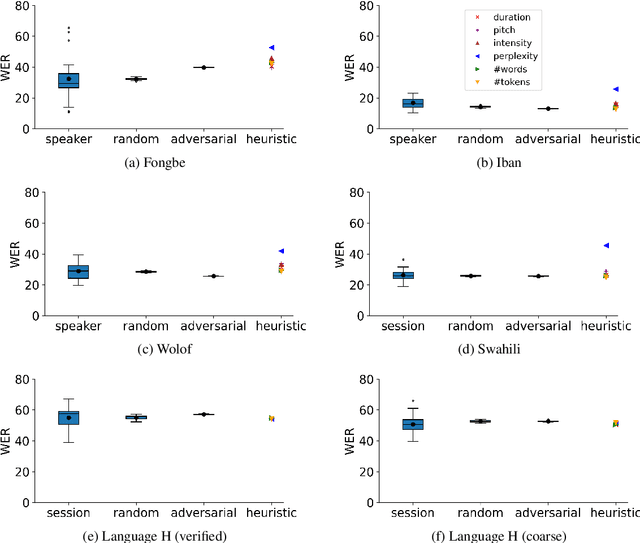
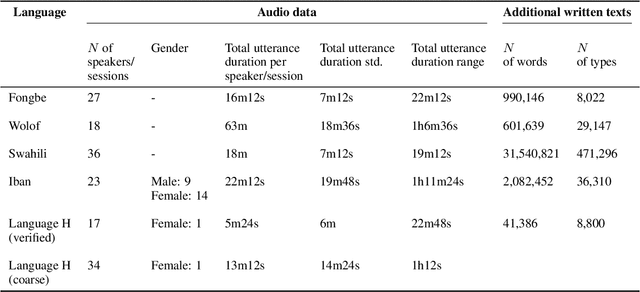
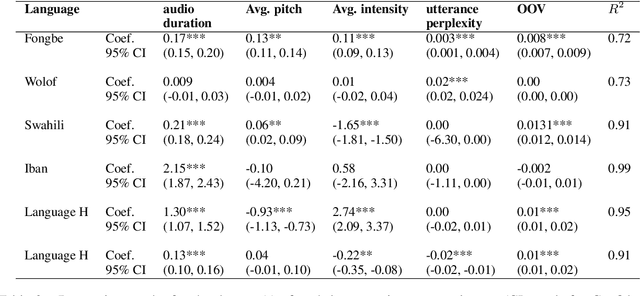
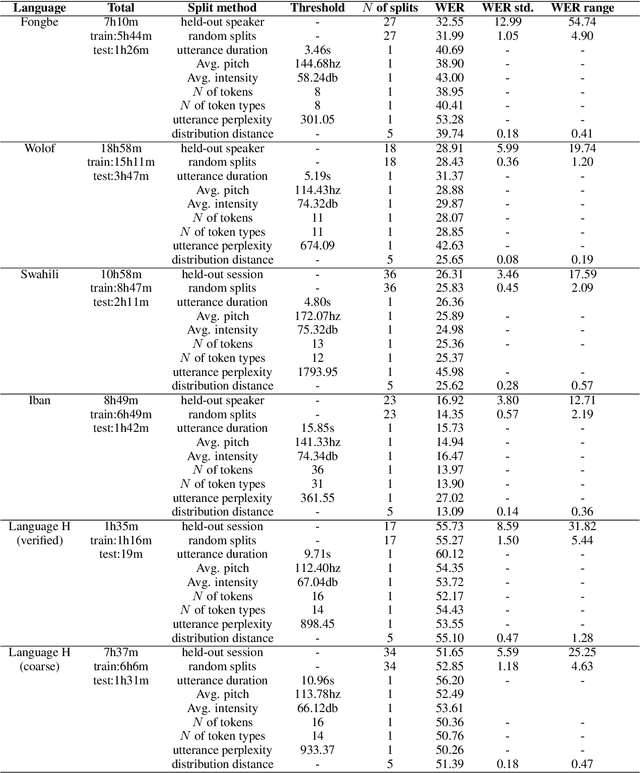
Many automatic speech recognition (ASR) data sets include a single pre-defined test set consisting of one or more speakers whose speech never appears in the training set. This "hold-speaker(s)-out" data partitioning strategy, however, may not be ideal for data sets in which the number of speakers is very small. This study investigates ten different data split methods for five languages with minimal ASR training resources. We find that (1) model performance varies greatly depending on which speaker is selected for testing; (2) the average word error rate (WER) across all held-out speakers is comparable not only to the average WER over multiple random splits but also to any given individual random split; (3) WER is also generally comparable when the data is split heuristically or adversarially; (4) utterance duration and intensity are comparatively more predictive factors of variability regardless of the data split. These results suggest that the widely used hold-speakers-out approach to ASR data partitioning can yield results that do not reflect model performance on unseen data or speakers. Random splits can yield more reliable and generalizable estimates when facing data sparsity.
Analysis of Self-Supervised Learning and Dimensionality Reduction Methods in Clustering-Based Active Learning for Speech Emotion Recognition
Jun 21, 2022

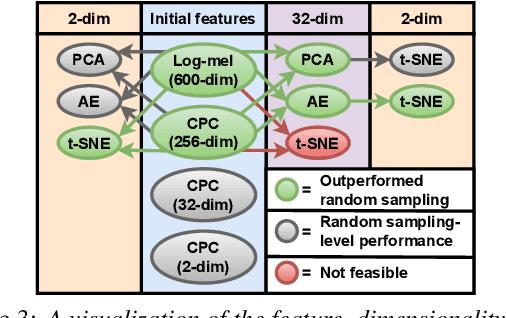
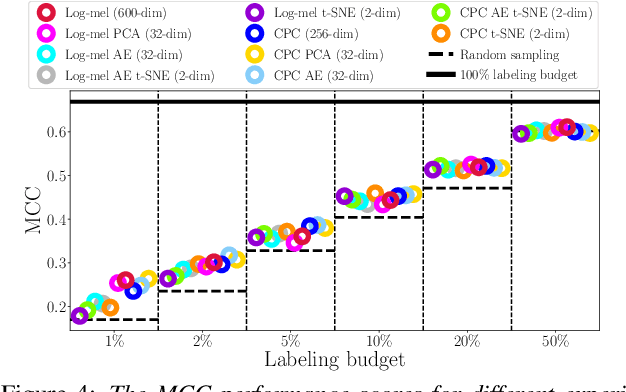
When domain experts are needed to perform data annotation for complex machine-learning tasks, reducing annotation effort is crucial in order to cut down time and expenses. For cases when there are no annotations available, one approach is to utilize the structure of the feature space for clustering-based active learning (AL) methods. However, these methods are heavily dependent on how the samples are organized in the feature space and what distance metric is used. Unsupervised methods such as contrastive predictive coding (CPC) can potentially be used to learn organized feature spaces, but these methods typically create high-dimensional features which might be challenging for estimating data density. In this paper, we combine CPC and multiple dimensionality reduction methods in search of functioning practices for clustering-based AL. Our experiments for simulating speech emotion recognition system deployment show that both the local and global topology of the feature space can be successfully used for AL, and that CPC can be used to improve clustering-based AL performance over traditional signal features. Additionally, we observe that compressing data dimensionality does not harm AL performance substantially, and that 2-D feature representations achieved similar AL performance as higher-dimensional representations when the number of annotations is not very low.
End-to-end Anchored Speech Recognition
Feb 06, 2019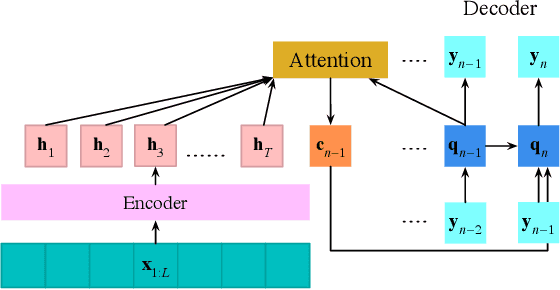
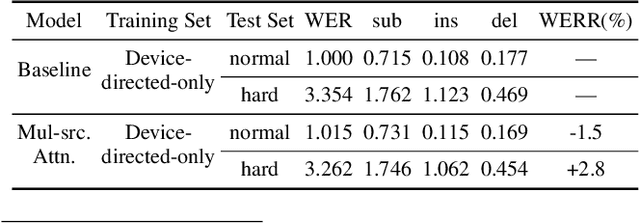

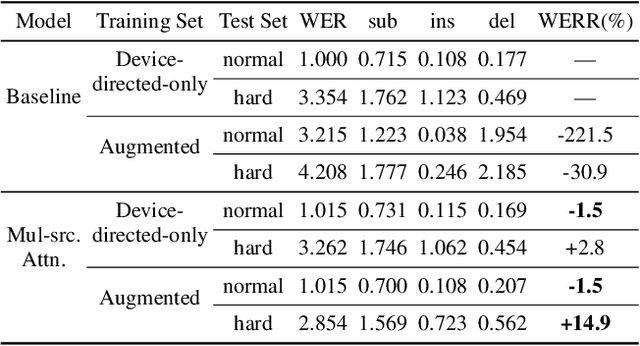
Voice-controlled house-hold devices, like Amazon Echo or Google Home, face the problem of performing speech recognition of device-directed speech in the presence of interfering background speech, i.e., background noise and interfering speech from another person or media device in proximity need to be ignored. We propose two end-to-end models to tackle this problem with information extracted from the "anchored segment". The anchored segment refers to the wake-up word part of an audio stream, which contains valuable speaker information that can be used to suppress interfering speech and background noise. The first method is called "Multi-source Attention" where the attention mechanism takes both the speaker information and decoder state into consideration. The second method directly learns a frame-level mask on top of the encoder output. We also explore a multi-task learning setup where we use the ground truth of the mask to guide the learner. Given that audio data with interfering speech is rare in our training data set, we also propose a way to synthesize "noisy" speech from "clean" speech to mitigate the mismatch between training and test data. Our proposed methods show up to 15% relative reduction in WER for Amazon Alexa live data with interfering background speech without significantly degrading on clean speech.
Stochastic Attention Head Removal: A Simple and Effective Method for Improving Automatic Speech Recognition with Transformers
Nov 08, 2020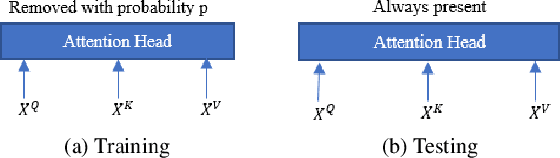
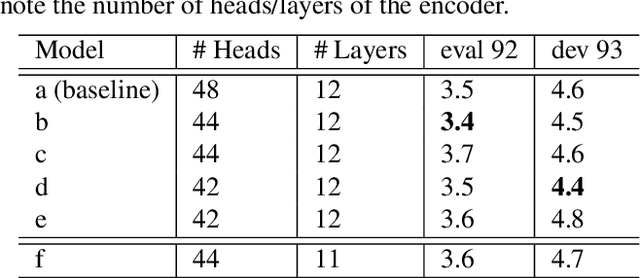
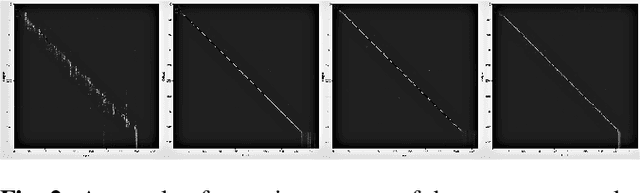
Recently, Transformers have shown competitive automatic speech recognition (ASR) results. One key factor to the success of these models is the multi-head attention mechanism. However, we observed in trained models, the diagonal attention matrices indicating the redundancy of the corresponding attention heads. Furthermore, we found some architectures with reduced numbers of attention heads have better performance. Since the search for the best structure is time prohibitive, we propose to randomly remove attention heads during training and keep all attention heads at test time, thus the final model can be viewed as an average of models with different architectures. This method gives consistent performance gains on the Wall Street Journal, AISHELL, Switchboard and AMI ASR tasks. On the AISHELL dev/test sets, the proposed method achieves state-of-the-art Transformer results with 5.8%/6.3% word error rates.
A Purely End-to-end System for Multi-speaker Speech Recognition
May 15, 2018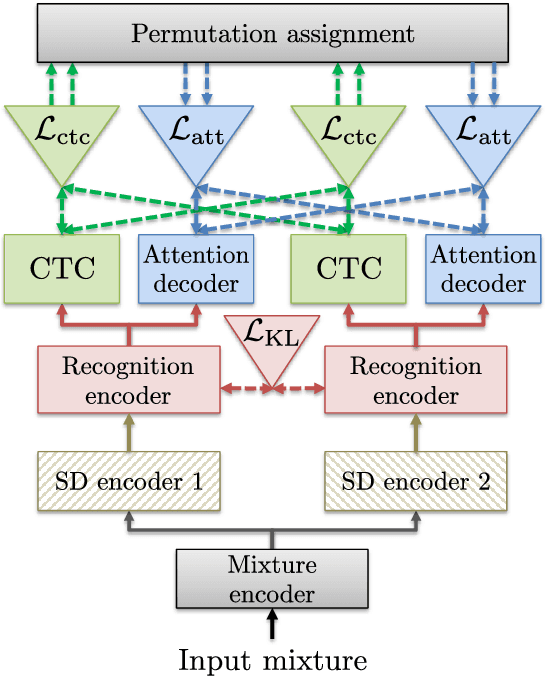

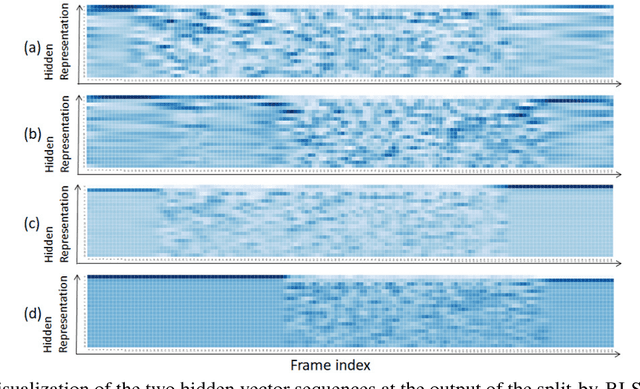
Recently, there has been growing interest in multi-speaker speech recognition, where the utterances of multiple speakers are recognized from their mixture. Promising techniques have been proposed for this task, but earlier works have required additional training data such as isolated source signals or senone alignments for effective learning. In this paper, we propose a new sequence-to-sequence framework to directly decode multiple label sequences from a single speech sequence by unifying source separation and speech recognition functions in an end-to-end manner. We further propose a new objective function to improve the contrast between the hidden vectors to avoid generating similar hypotheses. Experimental results show that the model is directly able to learn a mapping from a speech mixture to multiple label sequences, achieving 83.1 % relative improvement compared to a model trained without the proposed objective. Interestingly, the results are comparable to those produced by previous end-to-end works featuring explicit separation and recognition modules.
User-Level Differential Privacy against Attribute Inference Attack of Speech Emotion Recognition in Federated Learning
Apr 05, 2022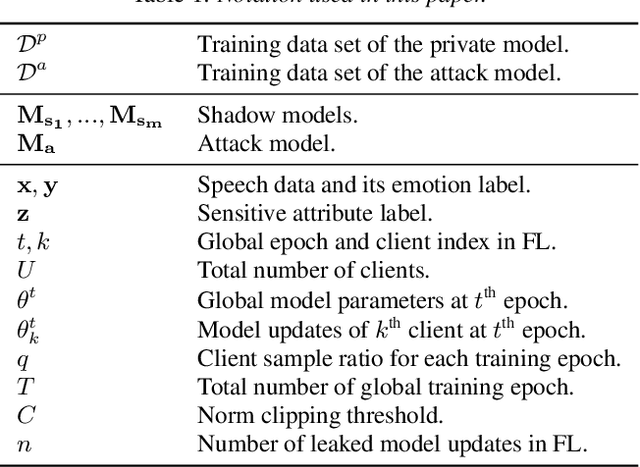
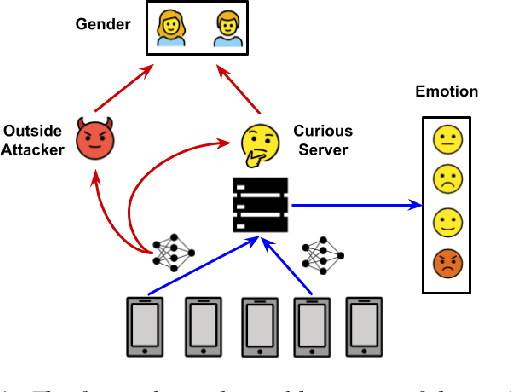
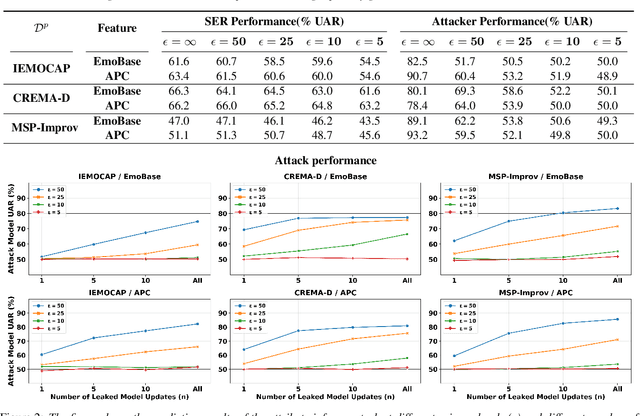
Many existing privacy-enhanced speech emotion recognition (SER) frameworks focus on perturbing the original speech data through adversarial training within a centralized machine learning setup. However, this privacy protection scheme can fail since the adversary can still access the perturbed data. In recent years, distributed learning algorithms, especially federated learning (FL), have gained popularity to protect privacy in machine learning applications. While FL provides good intuition to safeguard privacy by keeping the data on local devices, prior work has shown that privacy attacks, such as attribute inference attacks, are achievable for SER systems trained using FL. In this work, we propose to evaluate the user-level differential privacy (UDP) in mitigating the privacy leaks of the SER system in FL. UDP provides theoretical privacy guarantees with privacy parameters $\epsilon$ and $\delta$. Our results show that the UDP can effectively decrease attribute information leakage while keeping the utility of the SER system with the adversary accessing one model update. However, the efficacy of the UDP suffers when the FL system leaks more model updates to the adversary. We make the code publicly available to reproduce the results in https://github.com/usc-sail/fed-ser-leakage.
Sentiment recognition of Italian elderly through domain adaptation on cross-corpus speech dataset
Nov 14, 2022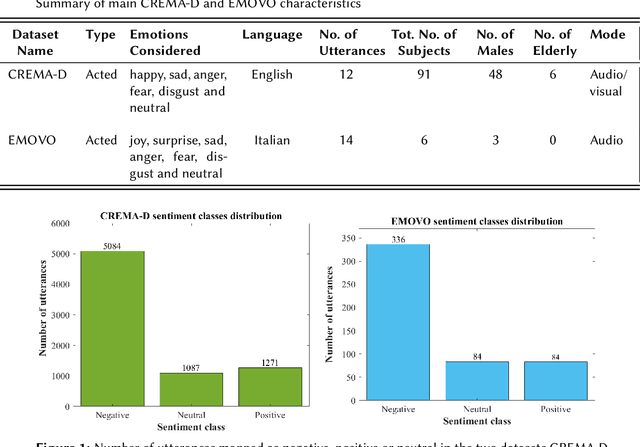
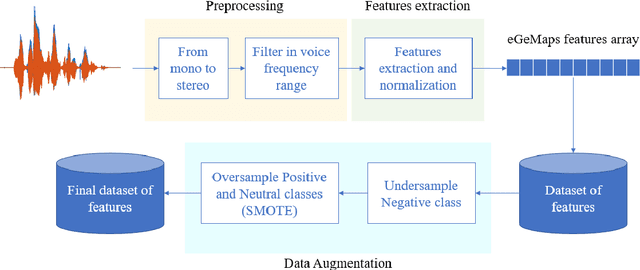
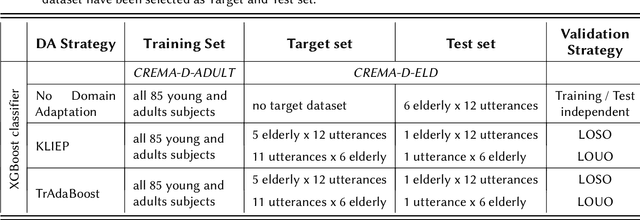
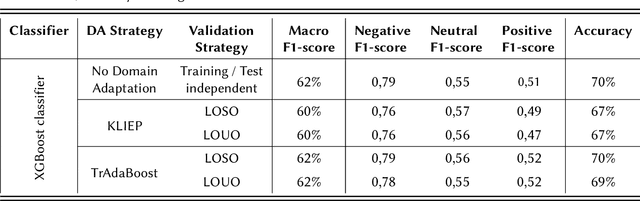
The aim of this work is to define a speech emotion recognition (SER) model able to recognize positive, neutral and negative emotions in natural conversations of Italian elderly people. Several datasets for SER are available in the literature. However most of them are in English or Chinese, have been recorded while actors and actresses pronounce short phrases and thus are not related to natural conversation. Moreover only few speeches among all the databases are related to elderly people. Therefore, in this work, a multi-language and multi-age corpus is considered merging a dataset in English, that includes also elderly people, with a dataset in Italian. A general model, trained on young and adult English actors and actresses is proposed, based on XGBoost. Then two strategies of domain adaptation are proposed to adapt the model either to elderly people and to Italian speakers. The results suggest that this approach increases the classification performance, underlining also that new datasets should be collected.