 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Multiclass ASMA vs Targeted PGD Attack in Image Segmentation
Aug 03, 2022
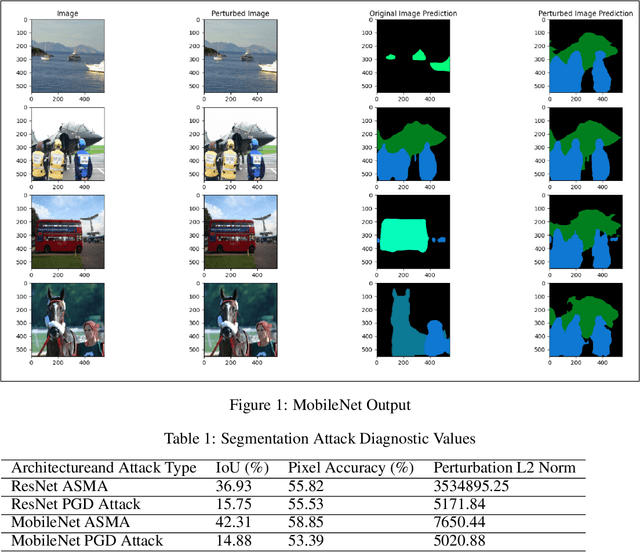
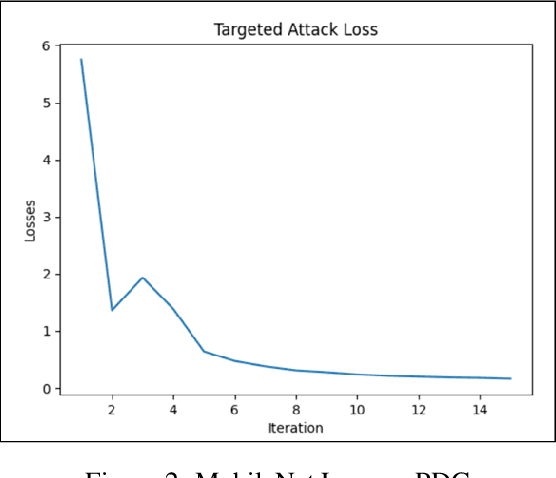


Deep learning networks have demonstrated high performance in a large variety of applications, such as image classification, speech recognition, and natural language processing. However, there exists a major vulnerability exploited by the use of adversarial attacks. An adversarial attack imputes images by altering the input image very slightly, making it nearly undetectable to the naked eye, but results in a very different classification by the network. This paper explores the projected gradient descent (PGD) attack and the Adaptive Mask Segmentation Attack (ASMA) on the image segmentation DeepLabV3 model using two types of architectures: MobileNetV3 and ResNet50, It was found that PGD was very consistent in changing the segmentation to be its target while the generalization of ASMA to a multiclass target was not as effective. The existence of such attack however puts all of image classification deep learning networks in danger of exploitation.
Automatic Speech Recognition Benchmark for Air-Traffic Communications
Jun 18, 2020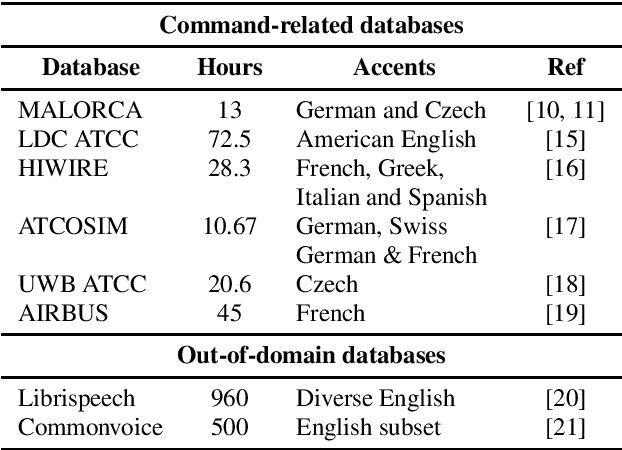
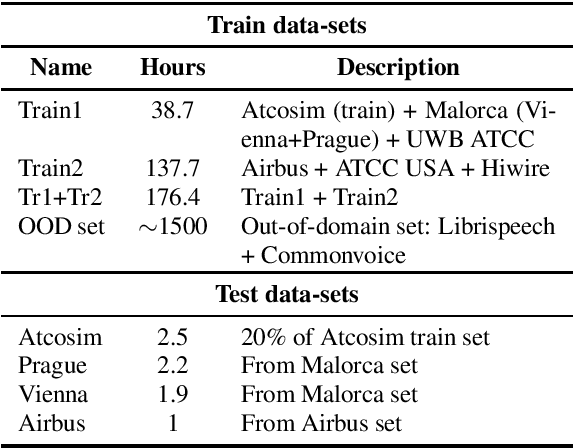
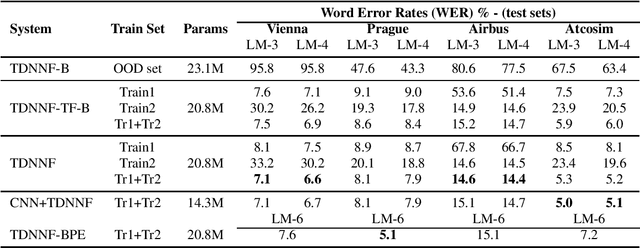
Advances in Automatic Speech Recognition (ASR) over the last decade opened new areas of speech-based automation such as in Air-Traffic Control (ATC) environment. Currently, voice communication and data links communications are the only way of contact between pilots and Air-Traffic Controllers (ATCo), where the former is the most widely used and the latter is a non-spoken method mandatory for oceanic messages and limited for some domestic issues. ASR systems on ATCo environments inherit increasing complexity due to accents from non-English speakers, cockpit noise, speaker-dependent biases, and small in-domain ATC databases for training. Hereby, we introduce CleanSky EC-H2020 ATCO2, a project that aims to develop an ASR-based platform to collect, organize and automatically pre-process ATCo speech-data from air space. This paper conveys an exploratory benchmark of several state-of-the-art ASR models trained on more than 170 hours of ATCo speech-data. We demonstrate that the cross-accent flaws due to speakers' accents are minimized due to the amount of data, making the system feasible for ATC environments. The developed ASR system achieves an averaged word error rate (WER) of 7.75% across four databases. An additional 35% relative improvement in WER is achieved on one test set when training a TDNNF system with byte-pair encoding.
Single-Channel Multi-talker Speech Recognition with Permutation Invariant Training
Jul 19, 2017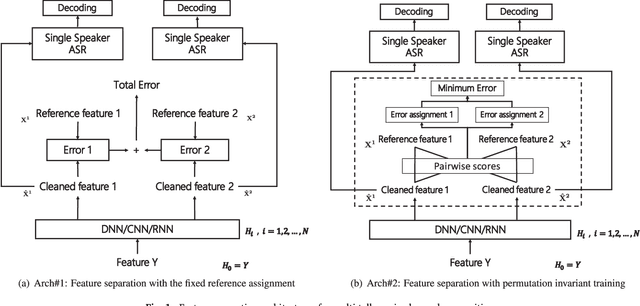

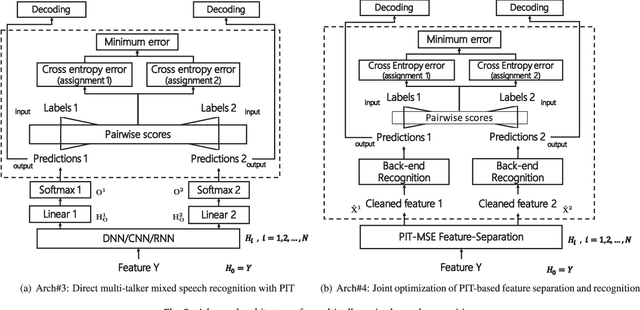

Although great progresses have been made in automatic speech recognition (ASR), significant performance degradation is still observed when recognizing multi-talker mixed speech. In this paper, we propose and evaluate several architectures to address this problem under the assumption that only a single channel of mixed signal is available. Our technique extends permutation invariant training (PIT) by introducing the front-end feature separation module with the minimum mean square error (MSE) criterion and the back-end recognition module with the minimum cross entropy (CE) criterion. More specifically, during training we compute the average MSE or CE over the whole utterance for each possible utterance-level output-target assignment, pick the one with the minimum MSE or CE, and optimize for that assignment. This strategy elegantly solves the label permutation problem observed in the deep learning based multi-talker mixed speech separation and recognition systems. The proposed architectures are evaluated and compared on an artificially mixed AMI dataset with both two- and three-talker mixed speech. The experimental results indicate that our proposed architectures can cut the word error rate (WER) by 45.0% and 25.0% relatively against the state-of-the-art single-talker speech recognition system across all speakers when their energies are comparable, for two- and three-talker mixed speech, respectively. To our knowledge, this is the first work on the multi-talker mixed speech recognition on the challenging speaker-independent spontaneous large vocabulary continuous speech task.
Continuous Pseudo-Labeling from the Start
Oct 17, 2022
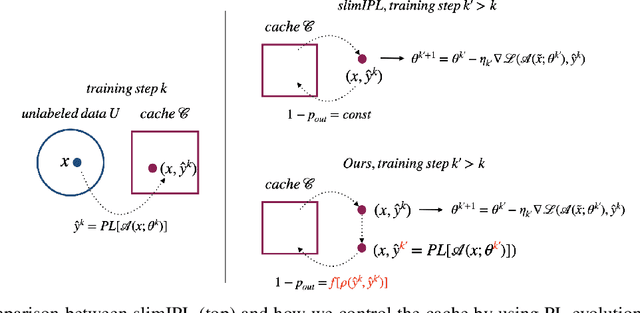
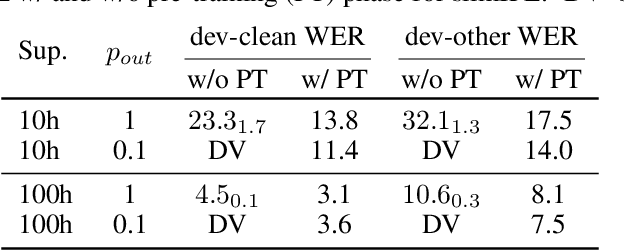
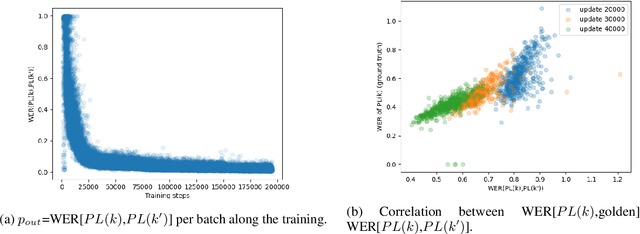
Self-training (ST), or pseudo-labeling has sparked significant interest in the automatic speech recognition (ASR) community recently because of its success in harnessing unlabeled data. Unlike prior semi-supervised learning approaches that relied on iteratively regenerating pseudo-labels (PLs) from a trained model and using them to train a new model, recent state-of-the-art methods perform `continuous training' where PLs are generated using a very recent version of the model being trained. Nevertheless, these approaches still rely on bootstrapping the ST using an initial supervised learning phase where the model is trained on labeled data alone. We believe this has the potential for over-fitting to the labeled dataset in low resource settings and that ST from the start of training should reduce over-fitting. In this paper we show how we can do this by dynamically controlling the evolution of PLs during the training process in ASR. To the best of our knowledge, this is the first study that shows the feasibility of generating PLs from the very start of the training. We are able to achieve this using two techniques that avoid instabilities which lead to degenerate models that do not generalize. Firstly, we control the evolution of PLs through a curriculum that uses the online changes in PLs to control the membership of the cache of PLs and improve generalization. Secondly, we find that by sampling transcriptions from the predictive distribution, rather than only using the best transcription, we can stabilize training further. With these techniques, our ST models match prior works without an external language model.
Unmanned Aerial Vehicle Control Through Domain-based Automatic Speech Recognition
Sep 09, 2020
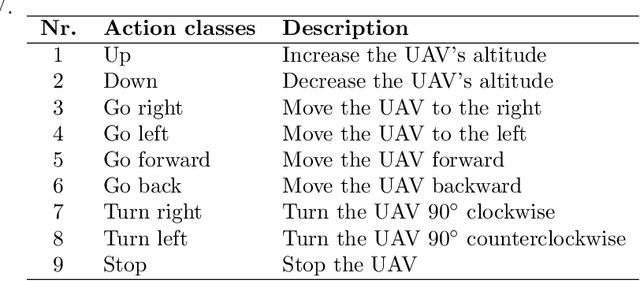
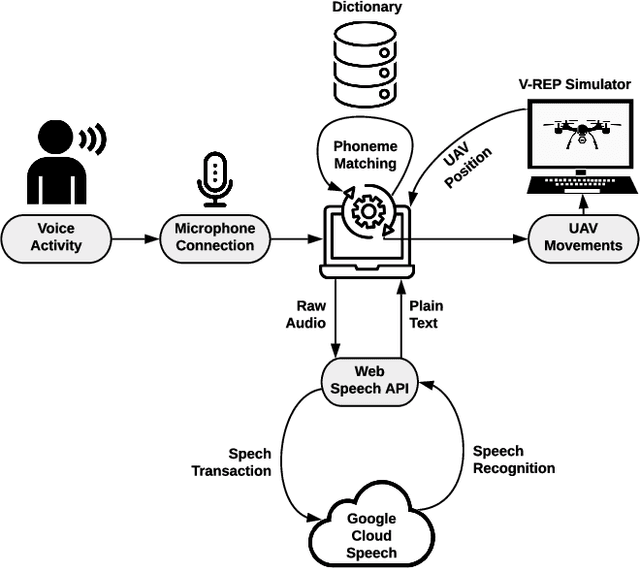
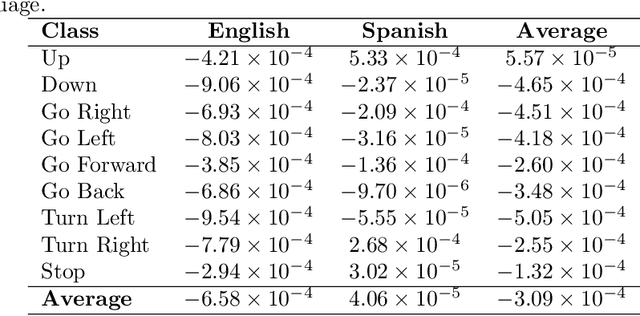
Currently, unmanned aerial vehicles, such as drones, are becoming a part of our lives and reaching out to many areas of society, including the industrialized world. A common alternative to control the movements and actions of the drone is through unwired tactile interfaces, for which different remote control devices can be found. However, control through such devices is not a natural, human-like communication interface, which sometimes is difficult to master for some users. In this work, we present a domain-based speech recognition architecture to effectively control an unmanned aerial vehicle such as a drone. The drone control is performed using a more natural, human-like way to communicate the instructions. Moreover, we implement an algorithm for command interpretation using both Spanish and English languages, as well as to control the movements of the drone in a simulated domestic environment. The conducted experiments involve participants giving voice commands to the drone in both languages in order to compare the effectiveness of each of them, considering the mother tongue of the participants in the experiment. Additionally, different levels of distortion have been applied to the voice commands in order to test the proposed approach when facing noisy input signals. The obtained results show that the unmanned aerial vehicle is capable of interpreting user voice instructions achieving an improvement in speech-to-action recognition for both languages when using phoneme matching in comparison to only using the cloud-based algorithm without domain-based instructions. Using raw audio inputs, the cloud-based approach achieves 74.81% and 97.04% accuracy for English and Spanish instructions respectively, whereas using our phoneme matching approach the results are improved achieving 93.33% and 100.00% accuracy for English and Spanish languages.
Adversarial Meta Sampling for Multilingual Low-Resource Speech Recognition
Dec 23, 2020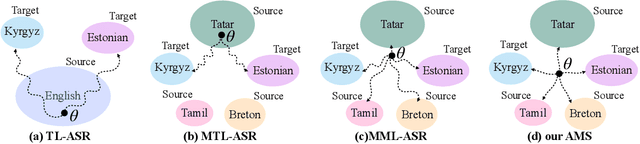
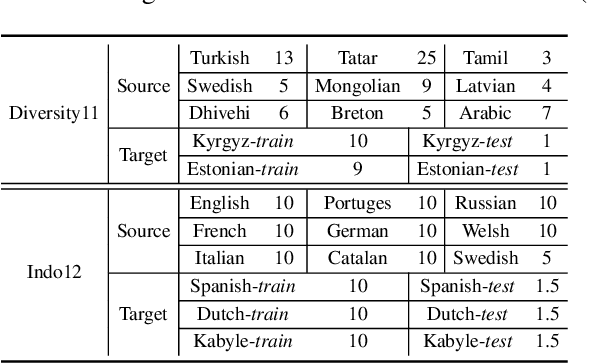
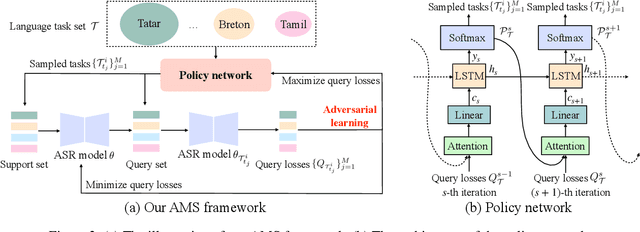

Low-resource automatic speech recognition (ASR) is challenging, as the low-resource target language data cannot well train an ASR model. To solve this issue, meta-learning formulates ASR for each source language into many small ASR tasks and meta-learns a model initialization on all tasks from different source languages to access fast adaptation on unseen target languages. However, for different source languages, the quantity and difficulty vary greatly because of their different data scales and diverse phonological systems, which leads to task-quantity and task-difficulty imbalance issues and thus a failure of multilingual meta-learning ASR (MML-ASR). In this work, we solve this problem by developing a novel adversarial meta sampling (AMS) approach to improve MML-ASR. When sampling tasks in MML-ASR, AMS adaptively determines the task sampling probability for each source language. Specifically, for each source language, if the query loss is large, it means that its tasks are not well sampled to train ASR model in terms of its quantity and difficulty and thus should be sampled more frequently for extra learning. Inspired by this fact, we feed the historical task query loss of all source language domain into a network to learn a task sampling policy for adversarially increasing the current query loss of MML-ASR. Thus, the learnt task sampling policy can master the learning situation of each language and thus predicts good task sampling probability for each language for more effective learning. Finally, experiment results on two multilingual datasets show significant performance improvement when applying our AMS on MML-ASR, and also demonstrate the applicability of AMS to other low-resource speech tasks and transfer learning ASR approaches. Our codes are available at: https://github.com/iamxiaoyubei/AMS.
End-to-end contextual speech recognition using class language models and a token passing decoder
Dec 05, 2018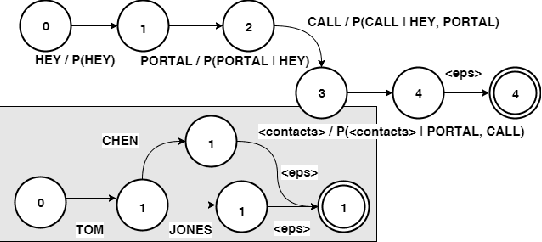
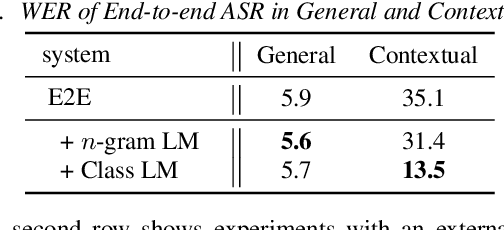
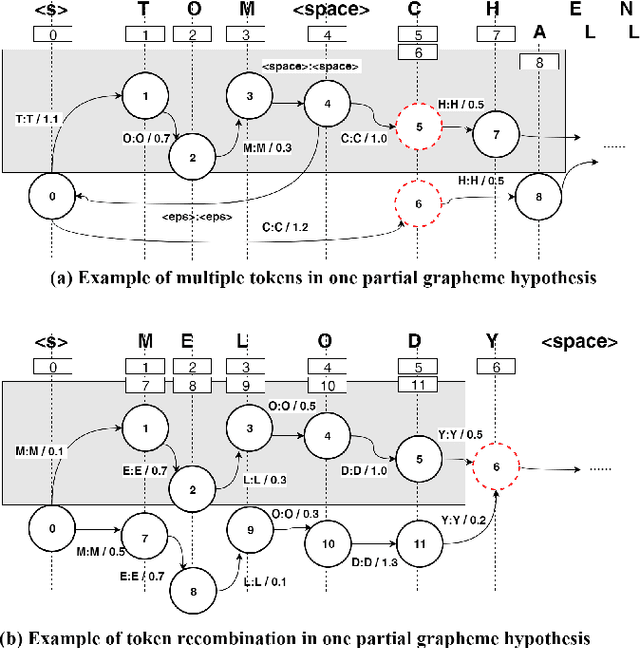
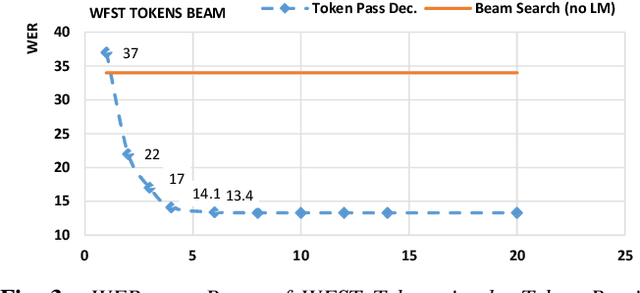
End-to-end modeling (E2E) of automatic speech recognition (ASR) blends all the components of a traditional speech recognition system into a unified model. Although it simplifies training and decoding pipelines, the unified model is hard to adapt when mismatch exists between training and test data. In this work, we focus on contextual speech recognition, which is particularly challenging for E2E models because it introduces significant mismatch between training and test data. To improve the performance in the presence of complex contextual information, we propose to use class-based language models(CLM) that can populate the classes with contextdependent information in real-time. To enable this approach to scale to a large number of class members and minimize search errors, we propose a token passing decoder with efficient token recombination for E2E systems for the first time. We evaluate the proposed system on general and contextual ASR, and achieve relative 62% Word Error Rate(WER) reduction for contextual ASR without hurting performance for general ASR. We show that the proposed method performs well without modification of the decoding hyper-parameters across tasks, making it a general solution for E2E ASR.
Deep Contextualized Acoustic Representations For Semi-Supervised Speech Recognition
Dec 03, 2019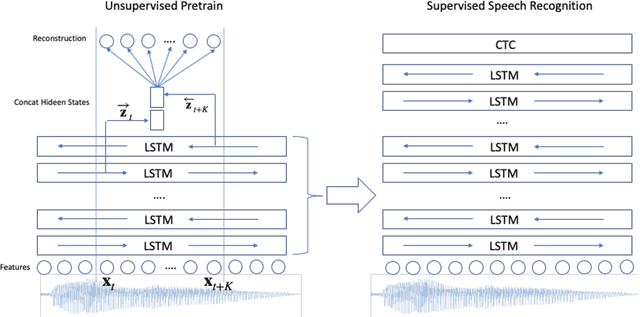

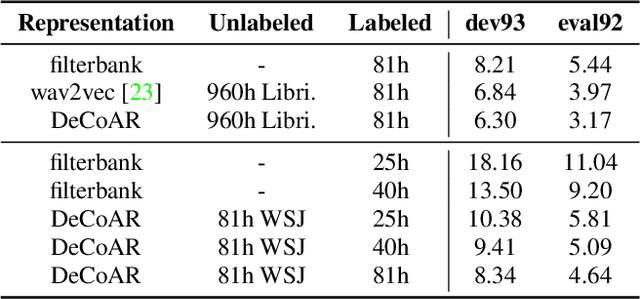

We propose a novel approach to semi-supervised automatic speech recognition (ASR). We first exploit a large amount of unlabeled audio data via representation learning, where we reconstruct a temporal slice of filterbank features from past and future context frames. The resulting deep contextualized acoustic representations (DeCoAR) are then used to train a CTC-based end-to-end ASR system using a smaller amount of labeled audio data. In our experiments, we show that systems trained on DeCoAR consistently outperform ones trained on conventional filterbank features, giving 42% and 19% relative improvement over the baseline on WSJ eval92 and LibriSpeech test-clean, respectively. Our approach can drastically reduce the amount of labeled data required; unsupervised training on LibriSpeech then supervision with 100 hours of labeled data achieves performance on par with training on all 960 hours directly.
Generalized Representations Learning for Time Series Classification
Sep 15, 2022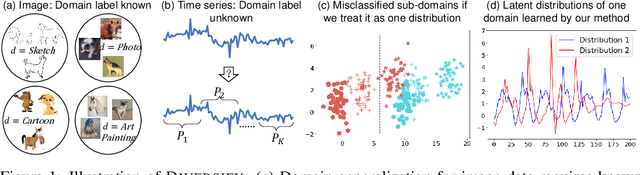
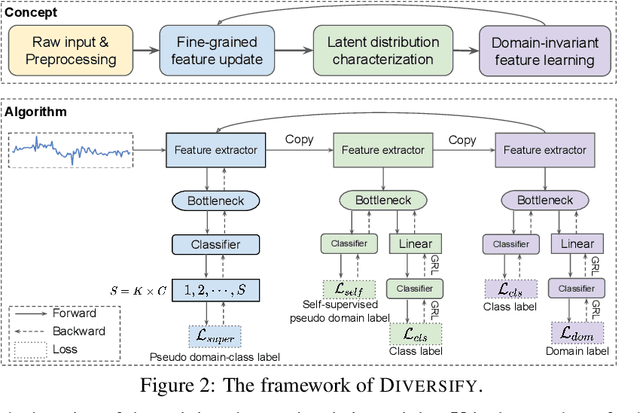
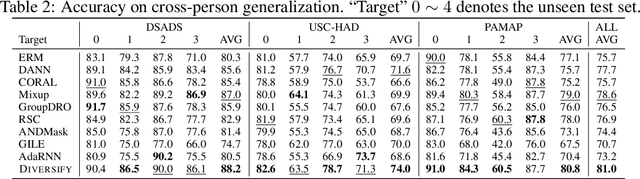
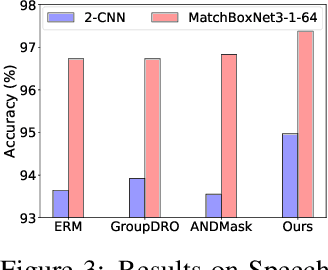
Time series classification is an important problem in real world. Due to its non-stationary property that the distribution changes over time, it remains challenging to build models for generalization to unseen distributions. In this paper, we propose to view the time series classification problem from the distribution perspective. We argue that the temporal complexity attributes to the unknown latent distributions within. To this end, we propose DIVERSIFY to learn generalized representations for time series classification. DIVERSIFY takes an iterative process: it first obtains the worst-case distribution scenario via adversarial training, then matches the distributions of the obtained sub-domains. We also present some theoretical insights. We conduct experiments on gesture recognition, speech commands recognition, wearable stress and affect detection, and sensor-based human activity recognition with a total of seven datasets in different settings. Results demonstrate that DIVERSIFY significantly outperforms other baselines and effectively characterizes the latent distributions by qualitative and quantitative analysis.