 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
A Universally-Deployable ASR Frontend for Joint Acoustic Echo Cancellation, Speech Enhancement, and Voice Separation
Sep 14, 2022
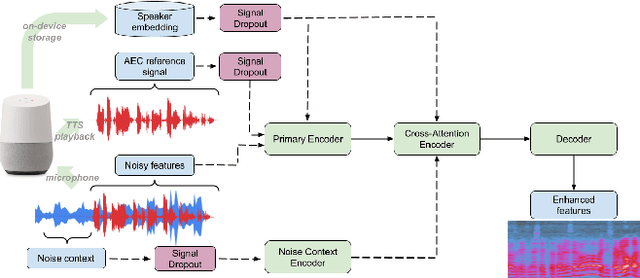

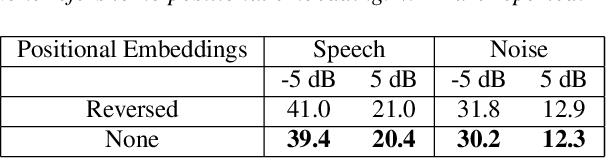
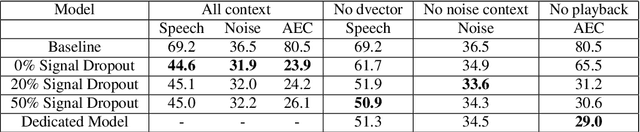
Recent work has shown that it is possible to train a single model to perform joint acoustic echo cancellation (AEC), speech enhancement, and voice separation, thereby serving as a unified frontend for robust automatic speech recognition (ASR). The joint model uses contextual information, such as a reference of the playback audio, noise context, and speaker embedding. In this work, we propose a number of novel improvements to such a model. First, we improve the architecture of the Cross-Attention Conformer that is used to ingest noise context into the model. Second, we generalize the model to be able to handle varying lengths of noise context. Third, we propose Signal Dropout, a novel strategy that models missing contextual information. In the absence of one or more signals, the proposed model performs nearly as well as task-specific models trained without these signals; and when such signals are present, our system compares well against systems that require all context signals. Over the baseline, the final model retains a relative word error rate reduction of 25.0% on background speech when speaker embedding is absent, and 61.2% on AEC when device playback is absent.
On the End-to-End Solution to Mandarin-English Code-switching Speech Recognition
Nov 01, 2018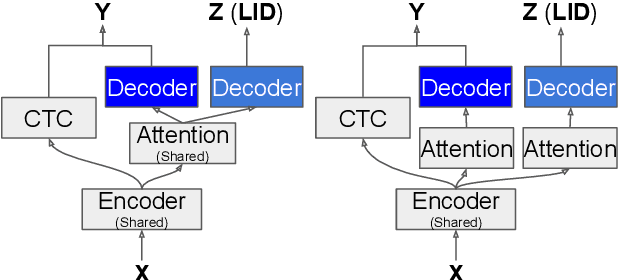
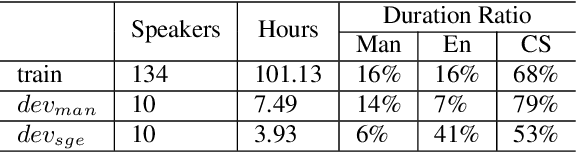
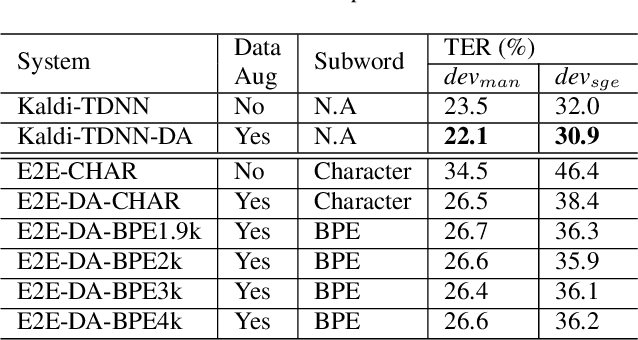
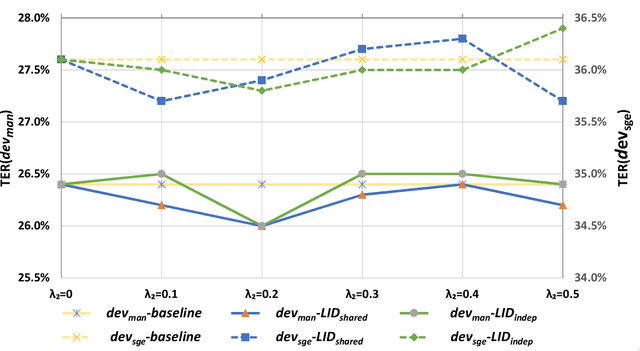
Code-switching (CS) refers to a linguistic phenomenon where a speaker uses different languages in an utterance or between alternating utterances. In this work, we study end-to-end (E2E) approaches to the Mandarin-English code-switching speech recognition (CSSR) task. We first examine the effectiveness of using data augmentation and byte-pair encoding (BPE) subword units. More importantly, we propose a multitask learning recipe, where a language identification task is explicitly learned in addition to the E2E speech recognition task. Furthermore, we introduce an efficient word vocabulary expansion method for language modeling to alleviate data sparsity issues under the code-switching scenario. Experimental results on the SEAME data, a Mandarin-English CS corpus, demonstrate the effectiveness of the proposed methods.
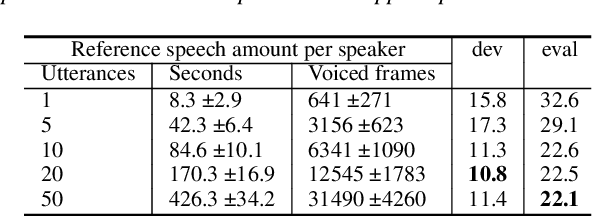
Speaker Recognition in the Wild
May 05, 2022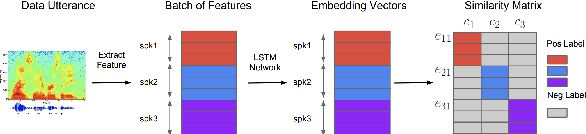

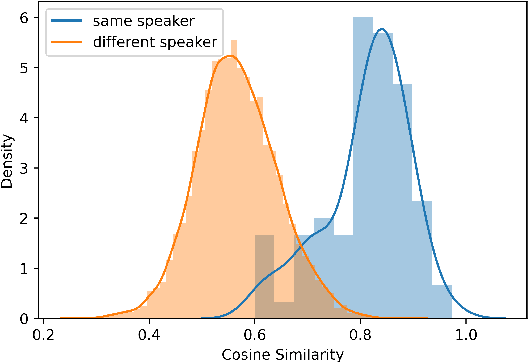
In this paper, we propose a pipeline to find the number of speakers, as well as audios belonging to each of these now identified speakers in a source of audio data where number of speakers or speaker labels are not known a priori. We used this approach as a part of our Data Preparation pipeline for Speech Recognition in Indic Languages (https://github.com/Open-Speech-EkStep/vakyansh-wav2vec2-experimentation). To understand and evaluate the accuracy of our proposed pipeline, we introduce two metrics: Cluster Purity, and Cluster Uniqueness. Cluster Purity quantifies how "pure" a cluster is. Cluster Uniqueness, on the other hand, quantifies what percentage of clusters belong only to a single dominant speaker. We discuss more on these metrics in section \ref{sec:metrics}. Since we develop this utility to aid us in identifying data based on speaker IDs before training an Automatic Speech Recognition (ASR) model, and since most of this data takes considerable effort to scrape, we also conclude that 98\% of data gets mapped to the top 80\% of clusters (computed by removing any clusters with less than a fixed number of utterances -- we do this to get rid of some very small clusters and use this threshold as 30), in the test set chosen.
Transformer in action: a comparative study of transformer-based acoustic models for large scale speech recognition applications
Oct 29, 2020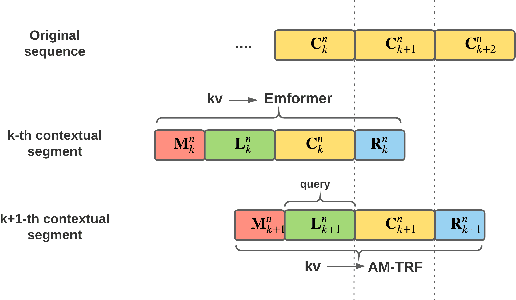
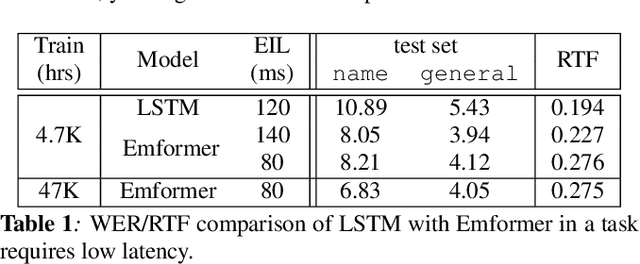
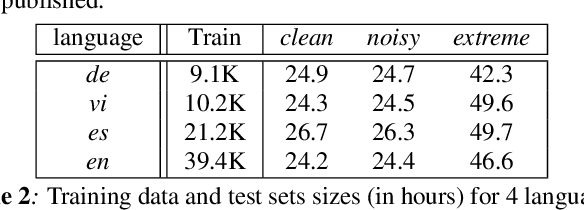
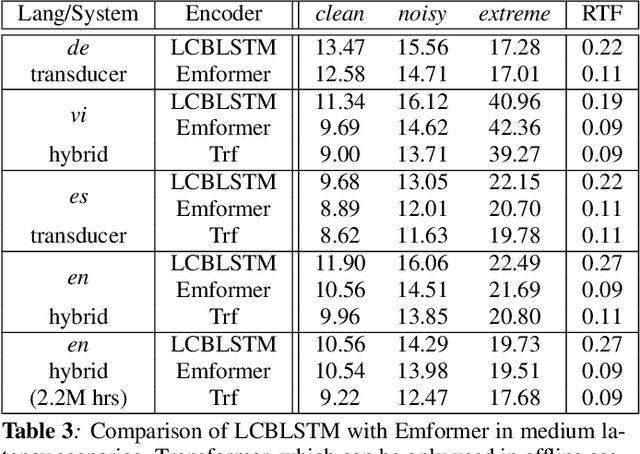
In this paper, we summarize the application of transformer and its streamable variant, Emformer based acoustic model for large scale speech recognition applications. We compare the transformer based acoustic models with their LSTM counterparts on industrial scale tasks. Specifically, we compare Emformer with latency-controlled BLSTM (LCBLSTM) on medium latency tasks and LSTM on low latency tasks. On a low latency voice assistant task, Emformer gets 24% to 26% relative word error rate reductions (WERRs). For medium latency scenarios, comparing with LCBLSTM with similar model size and latency, Emformer gets significant WERR across four languages in video captioning datasets with 2-3 times inference real-time factors reduction.
Improving Voice Separation by Incorporating End-to-end Speech Recognition
Nov 29, 2019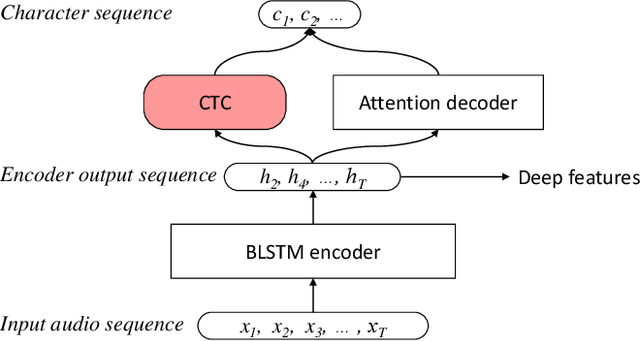
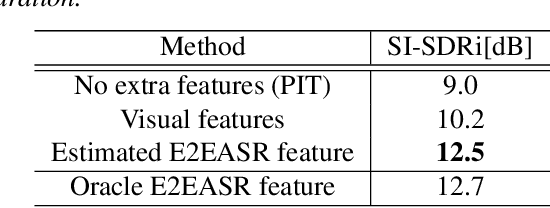
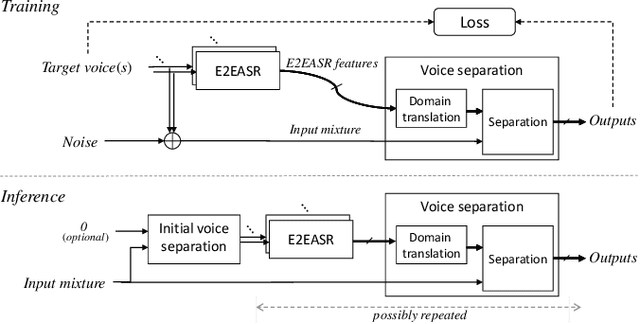

Despite recent advances in voice separation methods, many challenges remain in realistic scenarios such as noisy recording and the limits of available data. In this work, we propose to explicitly incorporate the phonetic and linguistic nature of speech by taking a transfer learning approach using an end-to-end automatic speech recognition (E2EASR) system. The voice separation is conditioned on deep features extracted from E2EASR to cover the long-term dependence of phonetic aspects. Experimental results on speech separation and enhancement task on the AVSpeech dataset show that the proposed method significantly improves the signal-to-distortion ratio over the baseline model and even outperforms an audio visual model, that utilizes visual information of lip movements.
Densely Connected Convolutional Networks for Speech Recognition
Aug 10, 2018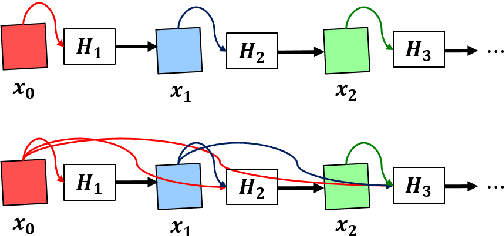
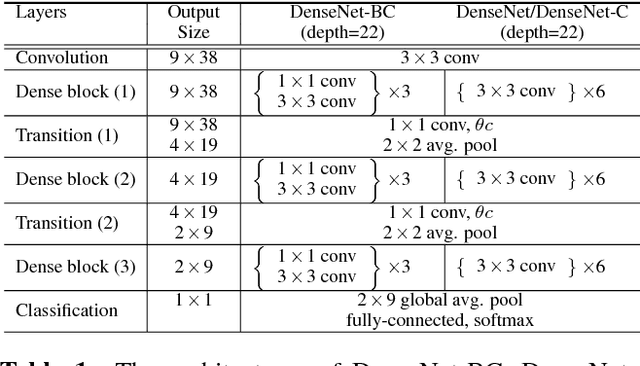

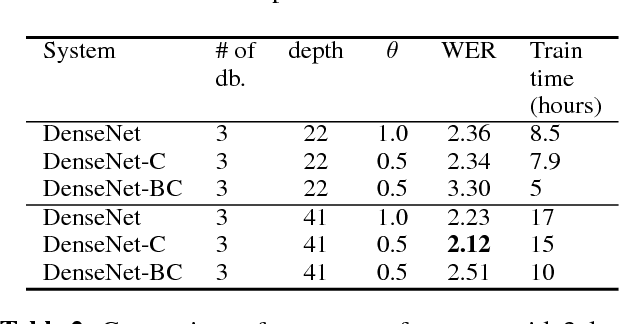
This paper presents our latest investigation on Densely Connected Convolutional Networks (DenseNets) for acoustic modelling (AM) in automatic speech recognition. DenseN-ets are very deep, compact convolutional neural networks, which have demonstrated incredible improvements over the state-of-the-art results on several data sets in computer vision. Our experimental results show that DenseNet can be used for AM significantly outperforming other neural-based models such as DNNs, CNNs, VGGs. Furthermore, results on Wall Street Journal revealed that with only a half of the training data DenseNet was able to outperform other models trained with the full data set by a large margin.
A Hybrid Continuity Loss to Reduce Over-Suppression for Time-domain Target Speaker Extraction
Mar 31, 2022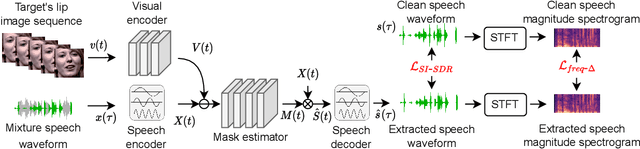
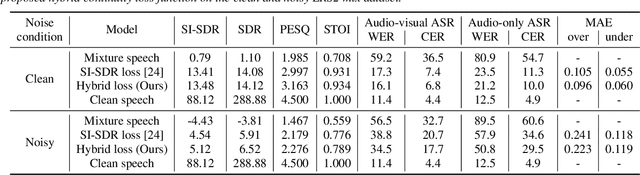
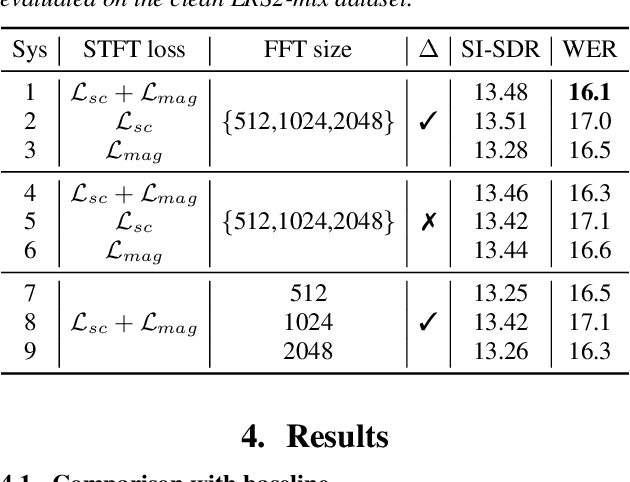
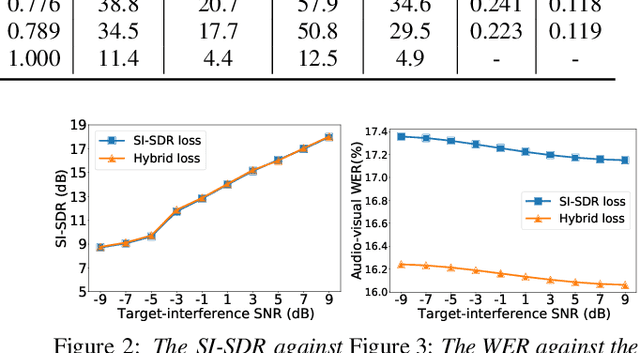
Speaker extraction algorithm extracts the target speech from a mixture speech containing interference speech and background noise. The extraction process sometimes over-suppresses the extracted target speech, which not only creates artifacts during listening but also harms the performance of downstream automatic speech recognition algorithms. We propose a hybrid continuity loss function for time-domain speaker extraction algorithms to settle the over-suppression problem. On top of the waveform-level loss used for superior signal quality, i.e., SI-SDR, we introduce a multi-resolution delta spectrum loss in the frequency-domain, to ensure the continuity of an extracted speech signal, thus alleviating the over-suppression. We examine the hybrid continuity loss function using a time-domain audio-visual speaker extraction algorithm on the YouTube LRS2-BBC dataset. Experimental results show that the proposed loss function reduces the over-suppression and improves the word error rate of speech recognition on both clean and noisy two-speakers mixtures, without harming the reconstructed speech quality.
CIF: Continuous Integrate-and-Fire for End-to-End Speech Recognition
May 27, 2019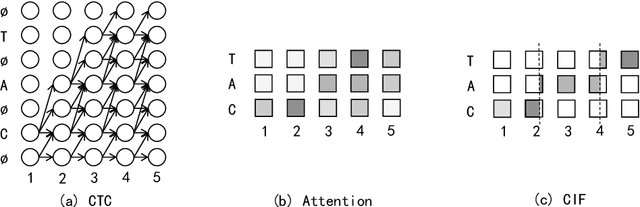

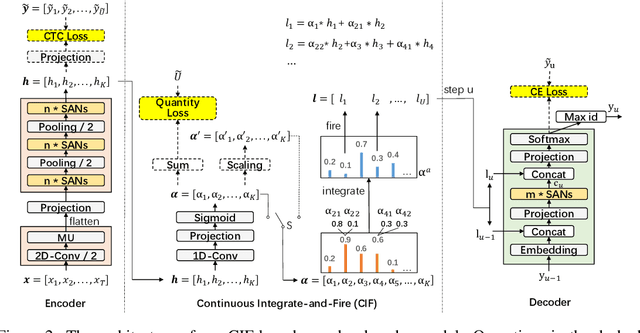
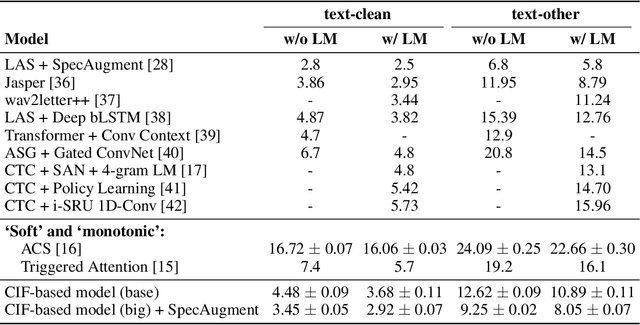
Automatic speech recognition (ASR) system is undergoing an exciting pathway to be more simplified and practical with the spring up of various end-to-end models. However, the mainstream of them neglects the positioning of token boundaries from continuous speech, which is considered crucial in human language learning and instant speech recognition. In this work, we propose Continuous Integrate-and-Fire (CIF), a 'soft' and 'monotonic' acoustic-to-linguistic alignment mechanism that addresses the boundary positioning by simulating the integrate-and-fire neuron model using continuous functions under the encoder-decoder framework. As the connection between the encoder and decoder, the CIF forwardly integrates the information in the encoded acoustic representations to determine a boundary and instantly fires the integrated information to the decoder once a boundary is located. Multiple effective strategies are introduced to the CIF-based model to alleviate the problems brought by the inaccurate positioning. Besides, multi-task learning is performed during training and an external language model is incorporated during inference to further boost the model performance. Evaluated on multiple ASR datasets that cover different languages and speech types, the CIF-based model shows stable convergence and competitive performance. Especially, it achieves a word error rate (WER) of 3.70% on the test-clean of Librispeech.
End-to-End Multi-Speaker Speech Recognition using Speaker Embeddings and Transfer Learning
Aug 13, 2019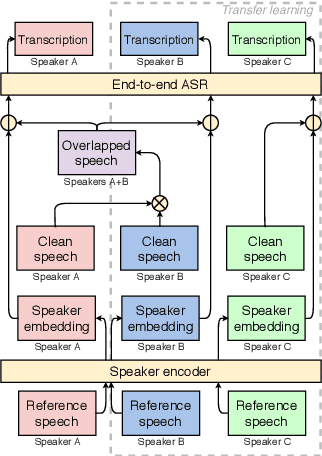

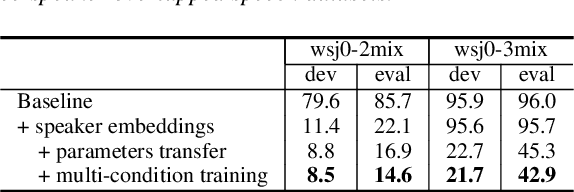
This paper presents our latest investigation on end-to-end automatic speech recognition (ASR) for overlapped speech. We propose to train an end-to-end system conditioned on speaker embeddings and further improved by transfer learning from clean speech. This proposed framework does not require any parallel non-overlapped speech materials and is independent of the number of speakers. Our experimental results on overlapped speech datasets show that joint conditioning on speaker embeddings and transfer learning significantly improves the ASR performance.
Speech Emotion Recognition with Global-Aware Fusion on Multi-scale Feature Representation
Apr 12, 2022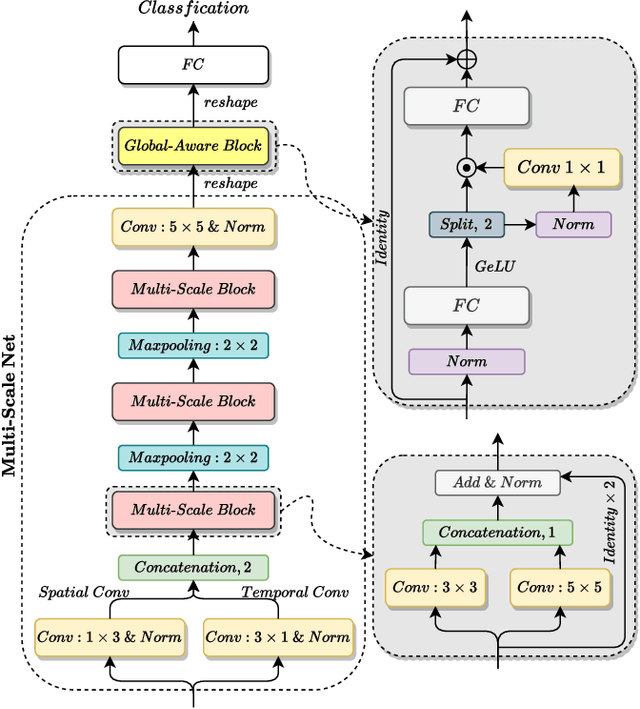
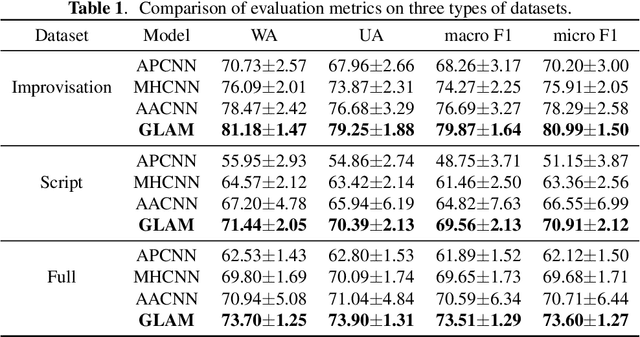
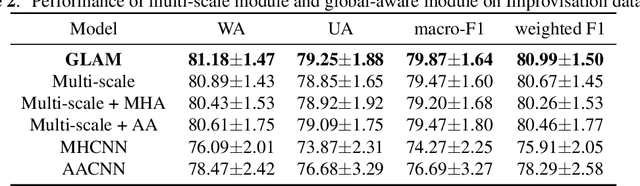
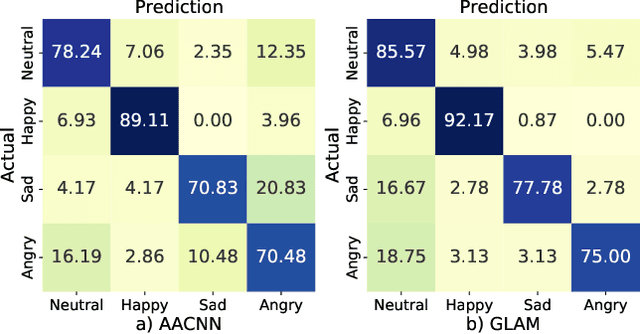
Speech Emotion Recognition (SER) is a fundamental task to predict the emotion label from speech data. Recent works mostly focus on using convolutional neural networks~(CNNs) to learn local attention map on fixed-scale feature representation by viewing time-varied spectral features as images. However, rich emotional feature at different scales and important global information are not able to be well captured due to the limits of existing CNNs for SER. In this paper, we propose a novel GLobal-Aware Multi-scale (GLAM) neural network (The code is available at https://github.com/lixiangucas01/GLAM) to learn multi-scale feature representation with global-aware fusion module to attend emotional information. Specifically, GLAM iteratively utilizes multiple convolutional kernels with different scales to learn multiple feature representation. Then, instead of using attention-based methods, a simple but effective global-aware fusion module is applied to grab most important emotional information globally. Experiments on the benchmark corpus IEMOCAP over four emotions demonstrates the superiority of our proposed model with 2.5% to 4.5% improvements on four common metrics compared to previous state-of-the-art approaches.