 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Parallel Rescoring with Transformer for Streaming On-Device Speech Recognition
Sep 02, 2020
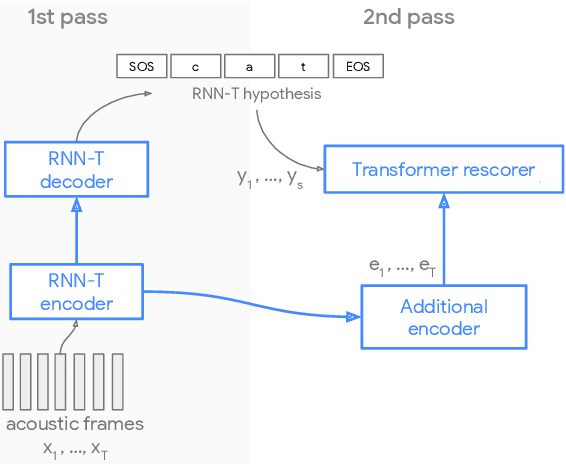
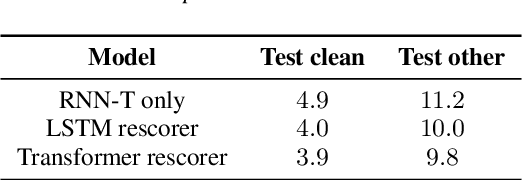
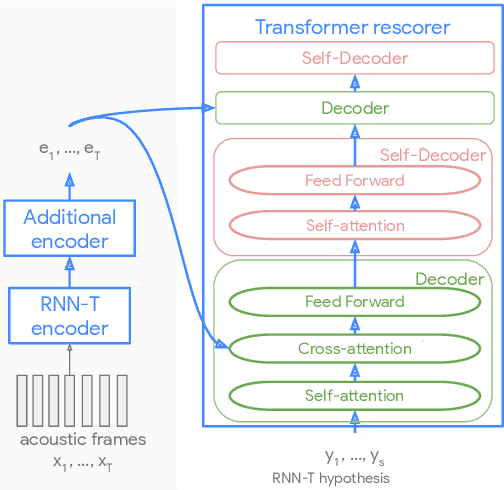
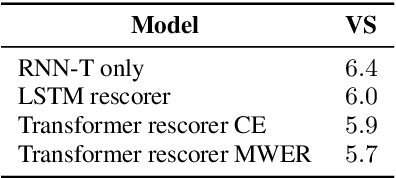
Recent advances of end-to-end models have outperformed conventional models through employing a two-pass model. The two-pass model provides better speed-quality trade-offs for on-device speech recognition, where a 1st-pass model generates hypotheses in a streaming fashion, and a 2nd-pass model re-scores the hypotheses with full audio sequence context. The 2nd-pass model plays a key role in the quality improvement of the end-to-end model to surpass the conventional model. One main challenge of the two-pass model is the computation latency introduced by the 2nd-pass model. Specifically, the original design of the two-pass model uses LSTMs for the 2nd-pass model, which are subject to long latency as they are constrained by the recurrent nature and have to run inference sequentially. In this work we explore replacing the LSTM layers in the 2nd-pass rescorer with Transformer layers, which can process the entire hypothesis sequences in parallel and can therefore utilize the on-device computation resources more efficiently. Compared with an LSTM-based baseline, our proposed Transformer rescorer achieves more than 50% latency reduction with quality improvement.
Continuous Pseudo-Labeling from the Start
Oct 17, 2022
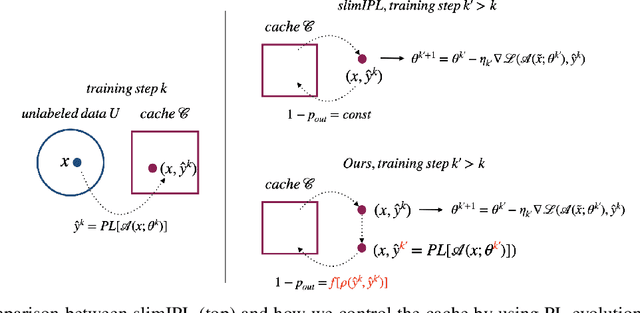
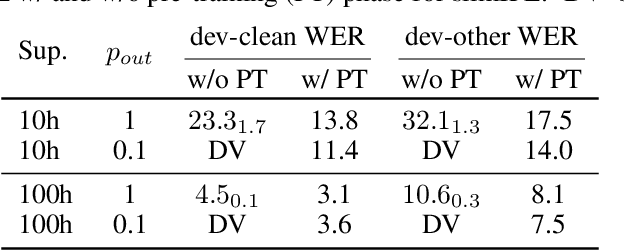
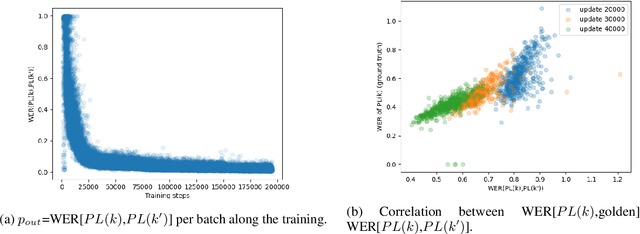
Self-training (ST), or pseudo-labeling has sparked significant interest in the automatic speech recognition (ASR) community recently because of its success in harnessing unlabeled data. Unlike prior semi-supervised learning approaches that relied on iteratively regenerating pseudo-labels (PLs) from a trained model and using them to train a new model, recent state-of-the-art methods perform `continuous training' where PLs are generated using a very recent version of the model being trained. Nevertheless, these approaches still rely on bootstrapping the ST using an initial supervised learning phase where the model is trained on labeled data alone. We believe this has the potential for over-fitting to the labeled dataset in low resource settings and that ST from the start of training should reduce over-fitting. In this paper we show how we can do this by dynamically controlling the evolution of PLs during the training process in ASR. To the best of our knowledge, this is the first study that shows the feasibility of generating PLs from the very start of the training. We are able to achieve this using two techniques that avoid instabilities which lead to degenerate models that do not generalize. Firstly, we control the evolution of PLs through a curriculum that uses the online changes in PLs to control the membership of the cache of PLs and improve generalization. Secondly, we find that by sampling transcriptions from the predictive distribution, rather than only using the best transcription, we can stabilize training further. With these techniques, our ST models match prior works without an external language model.
A Hybrid Continuity Loss to Reduce Over-Suppression for Time-domain Target Speaker Extraction
Mar 31, 2022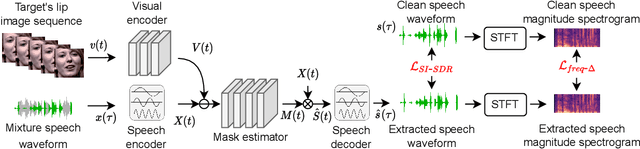
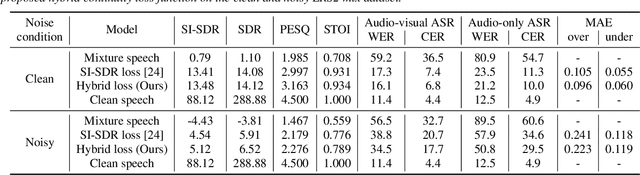
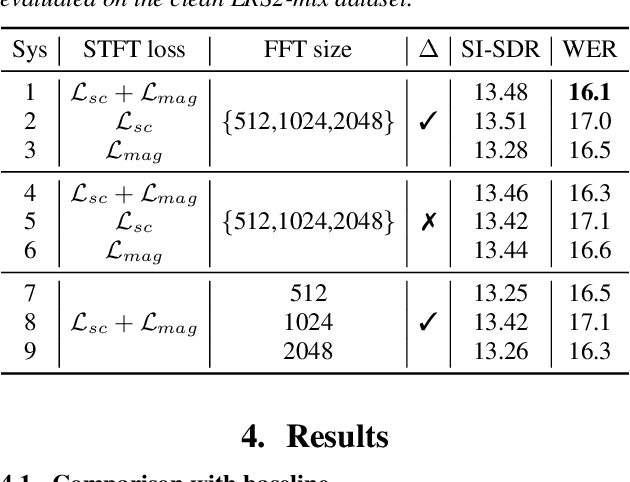
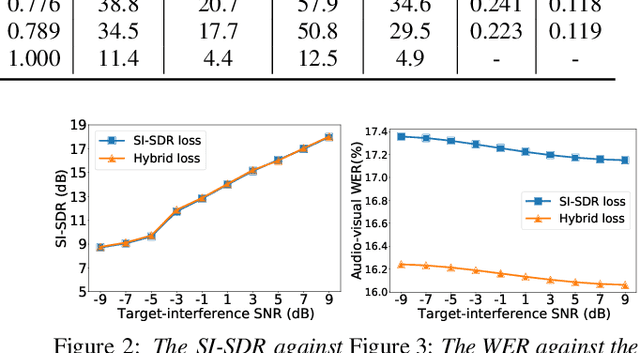
Speaker extraction algorithm extracts the target speech from a mixture speech containing interference speech and background noise. The extraction process sometimes over-suppresses the extracted target speech, which not only creates artifacts during listening but also harms the performance of downstream automatic speech recognition algorithms. We propose a hybrid continuity loss function for time-domain speaker extraction algorithms to settle the over-suppression problem. On top of the waveform-level loss used for superior signal quality, i.e., SI-SDR, we introduce a multi-resolution delta spectrum loss in the frequency-domain, to ensure the continuity of an extracted speech signal, thus alleviating the over-suppression. We examine the hybrid continuity loss function using a time-domain audio-visual speaker extraction algorithm on the YouTube LRS2-BBC dataset. Experimental results show that the proposed loss function reduces the over-suppression and improves the word error rate of speech recognition on both clean and noisy two-speakers mixtures, without harming the reconstructed speech quality.
Multiclass ASMA vs Targeted PGD Attack in Image Segmentation
Aug 03, 2022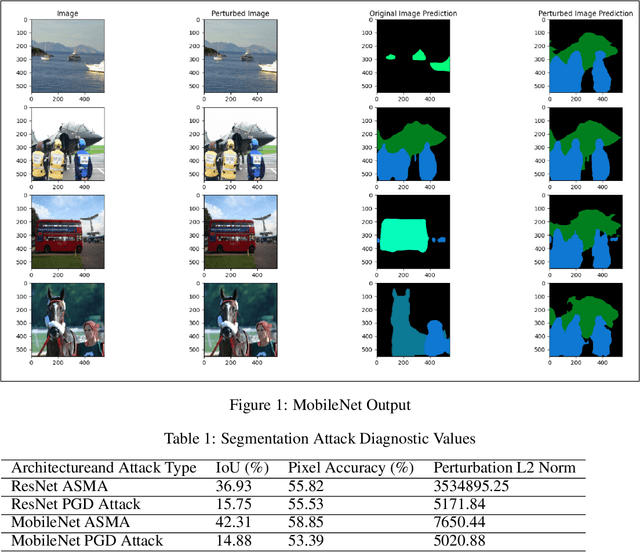
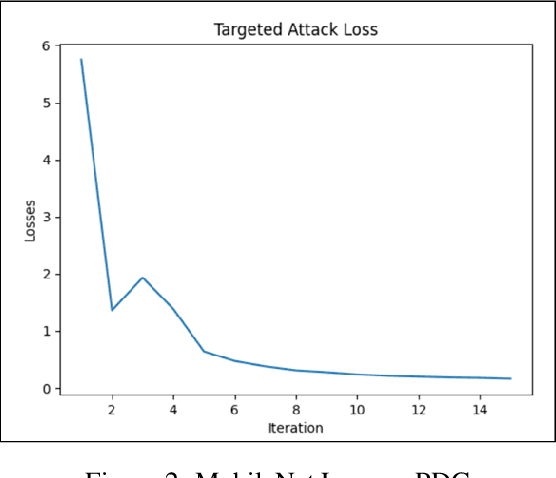


Deep learning networks have demonstrated high performance in a large variety of applications, such as image classification, speech recognition, and natural language processing. However, there exists a major vulnerability exploited by the use of adversarial attacks. An adversarial attack imputes images by altering the input image very slightly, making it nearly undetectable to the naked eye, but results in a very different classification by the network. This paper explores the projected gradient descent (PGD) attack and the Adaptive Mask Segmentation Attack (ASMA) on the image segmentation DeepLabV3 model using two types of architectures: MobileNetV3 and ResNet50, It was found that PGD was very consistent in changing the segmentation to be its target while the generalization of ASMA to a multiclass target was not as effective. The existence of such attack however puts all of image classification deep learning networks in danger of exploitation.
Arabic Speech Recognition System using CMU-Sphinx4
Apr 17, 2007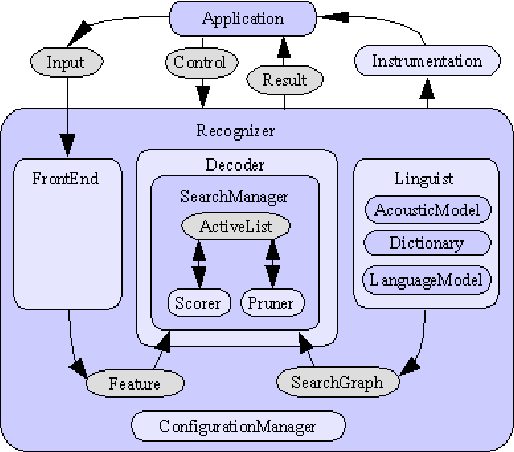
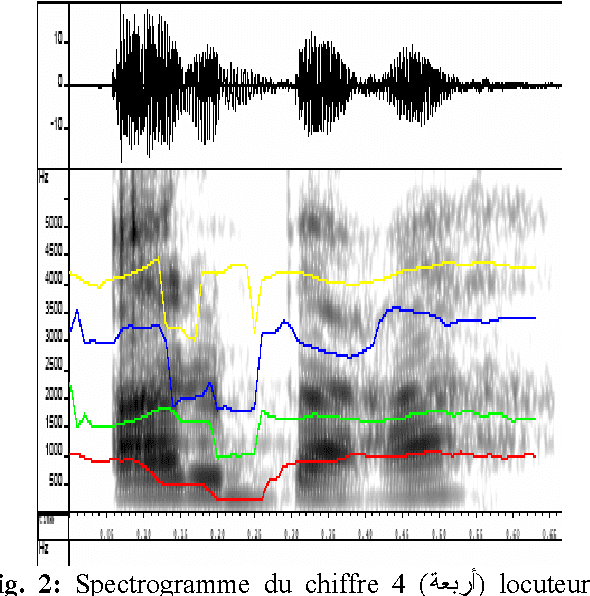

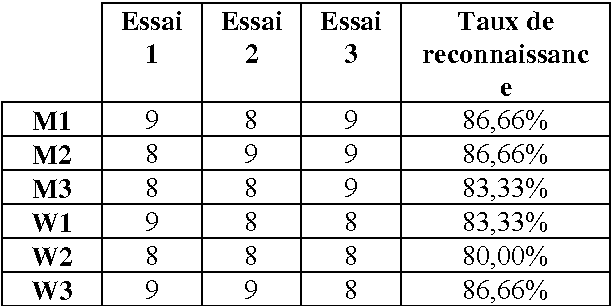
In this paper we present the creation of an Arabic version of Automated Speech Recognition System (ASR). This system is based on the open source Sphinx-4, from the Carnegie Mellon University. Which is a speech recognition system based on discrete hidden Markov models (HMMs). We investigate the changes that must be made to the model to adapt Arabic voice recognition. Keywords: Speech recognition, Acoustic model, Arabic language, HMMs, CMUSphinx-4, Artificial intelligence.
How to Teach DNNs to Pay Attention to the Visual Modality in Speech Recognition
Apr 17, 2020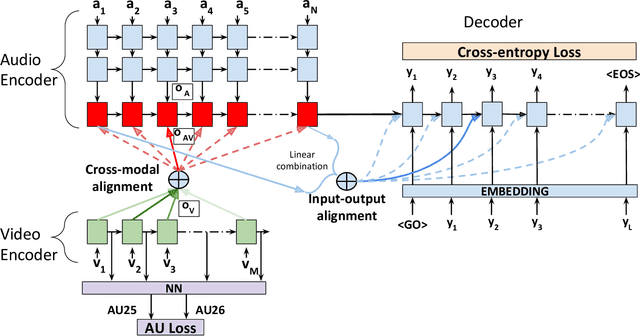
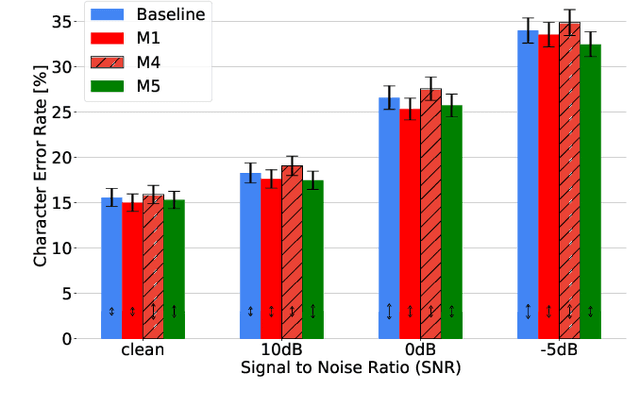
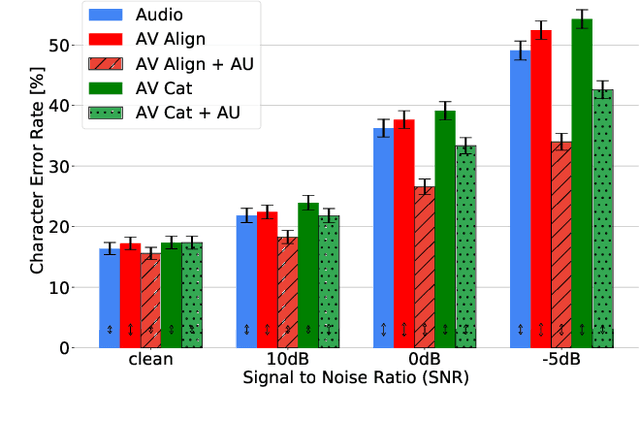
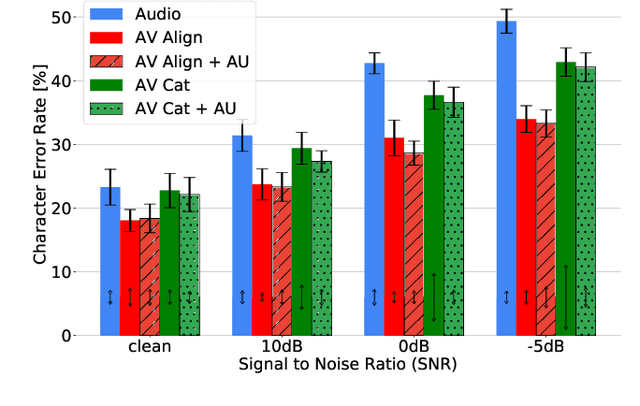
Audio-Visual Speech Recognition (AVSR) seeks to model, and thereby exploit, the dynamic relationship between a human voice and the corresponding mouth movements. A recently proposed multimodal fusion strategy, AV Align, based on state-of-the-art sequence to sequence neural networks, attempts to model this relationship by explicitly aligning the acoustic and visual representations of speech. This study investigates the inner workings of AV Align and visualises the audio-visual alignment patterns. Our experiments are performed on two of the largest publicly available AVSR datasets, TCD-TIMIT and LRS2. We find that AV Align learns to align acoustic and visual representations of speech at the frame level on TCD-TIMIT in a generally monotonic pattern. We also determine the cause of initially seeing no improvement over audio-only speech recognition on the more challenging LRS2. We propose a regularisation method which involves predicting lip-related Action Units from visual representations. Our regularisation method leads to better exploitation of the visual modality, with performance improvements between 7% and 30% depending on the noise level. Furthermore, we show that the alternative Watch, Listen, Attend, and Spell network is affected by the same problem as AV Align, and that our proposed approach can effectively help it learn visual representations. Our findings validate the suitability of the regularisation method to AVSR and encourage researchers to rethink the multimodal convergence problem when having one dominant modality.
Speech Emotion Recognition with Global-Aware Fusion on Multi-scale Feature Representation
Apr 12, 2022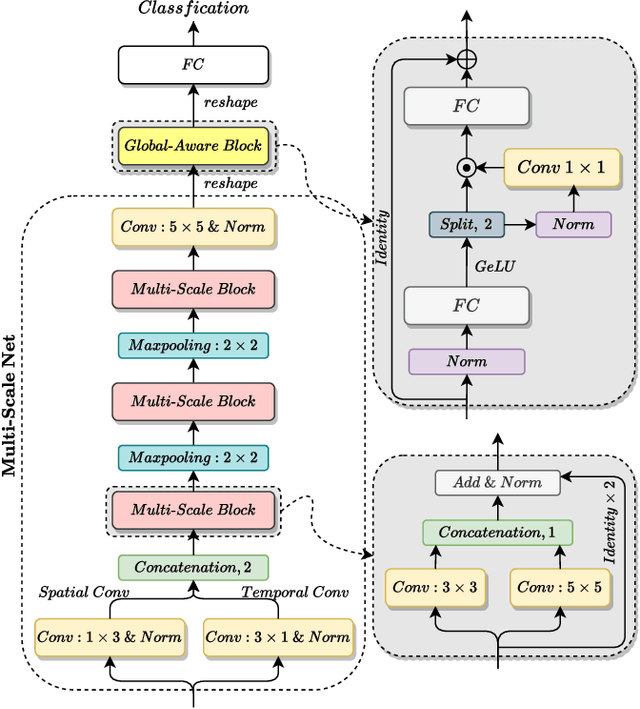
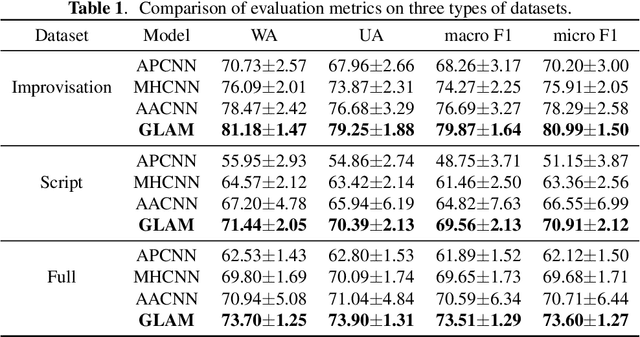
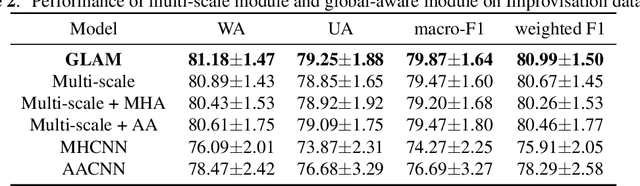
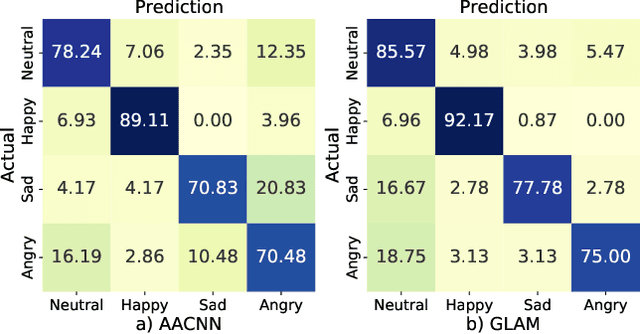
Speech Emotion Recognition (SER) is a fundamental task to predict the emotion label from speech data. Recent works mostly focus on using convolutional neural networks~(CNNs) to learn local attention map on fixed-scale feature representation by viewing time-varied spectral features as images. However, rich emotional feature at different scales and important global information are not able to be well captured due to the limits of existing CNNs for SER. In this paper, we propose a novel GLobal-Aware Multi-scale (GLAM) neural network (The code is available at https://github.com/lixiangucas01/GLAM) to learn multi-scale feature representation with global-aware fusion module to attend emotional information. Specifically, GLAM iteratively utilizes multiple convolutional kernels with different scales to learn multiple feature representation. Then, instead of using attention-based methods, a simple but effective global-aware fusion module is applied to grab most important emotional information globally. Experiments on the benchmark corpus IEMOCAP over four emotions demonstrates the superiority of our proposed model with 2.5% to 4.5% improvements on four common metrics compared to previous state-of-the-art approaches.
Transformer in action: a comparative study of transformer-based acoustic models for large scale speech recognition applications
Oct 29, 2020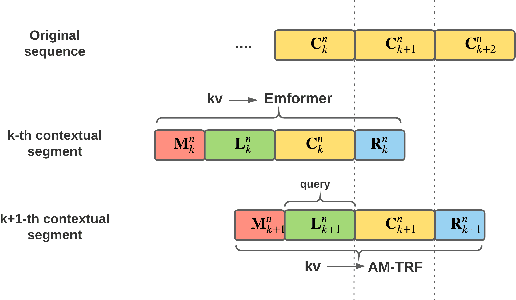
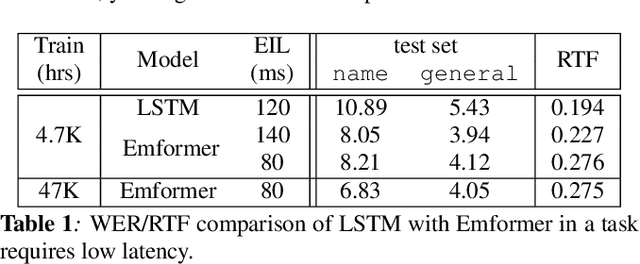
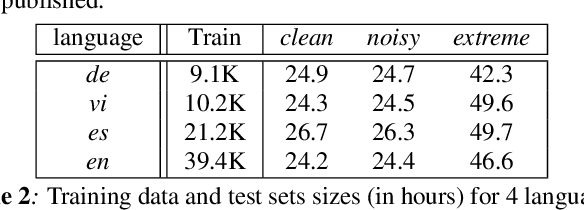
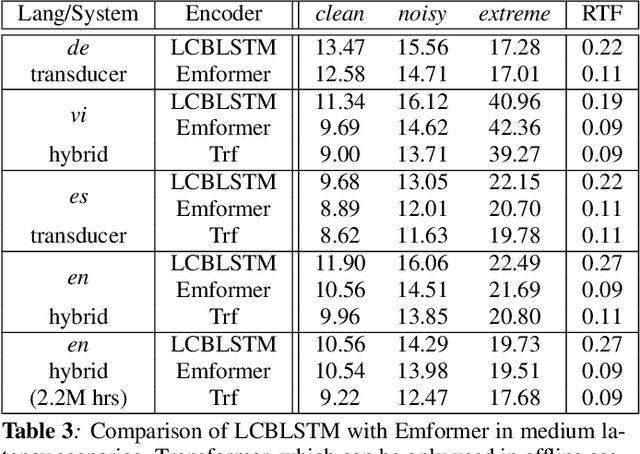
In this paper, we summarize the application of transformer and its streamable variant, Emformer based acoustic model for large scale speech recognition applications. We compare the transformer based acoustic models with their LSTM counterparts on industrial scale tasks. Specifically, we compare Emformer with latency-controlled BLSTM (LCBLSTM) on medium latency tasks and LSTM on low latency tasks. On a low latency voice assistant task, Emformer gets 24% to 26% relative word error rate reductions (WERRs). For medium latency scenarios, comparing with LCBLSTM with similar model size and latency, Emformer gets significant WERR across four languages in video captioning datasets with 2-3 times inference real-time factors reduction.
Incorporating End-to-End Speech Recognition Models for Sentiment Analysis
Feb 28, 2019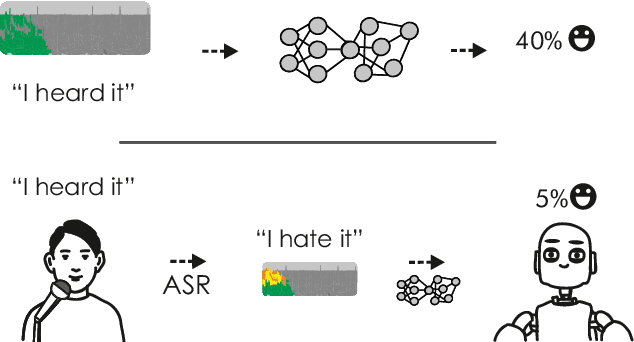
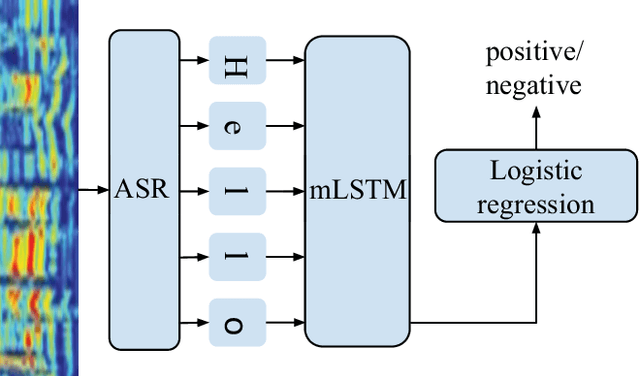
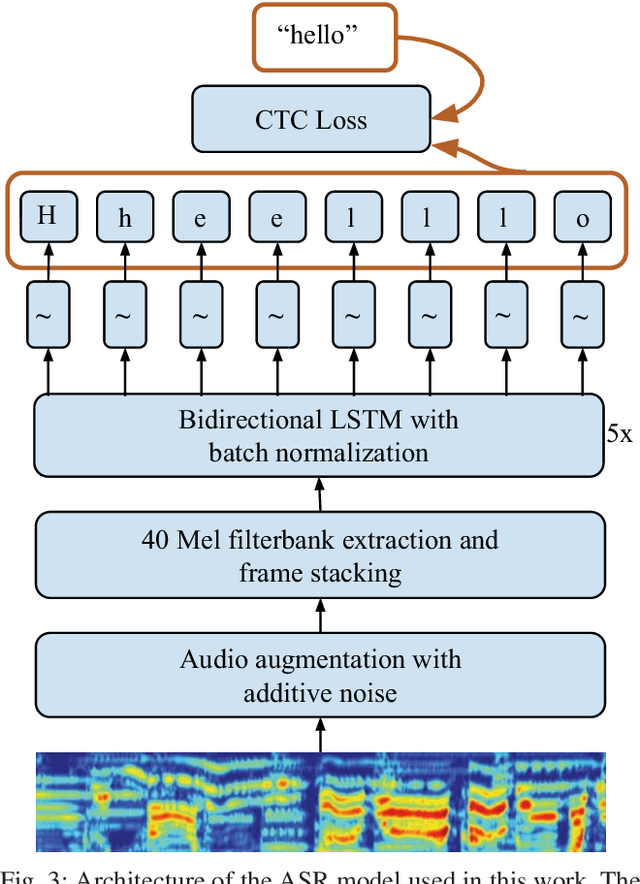
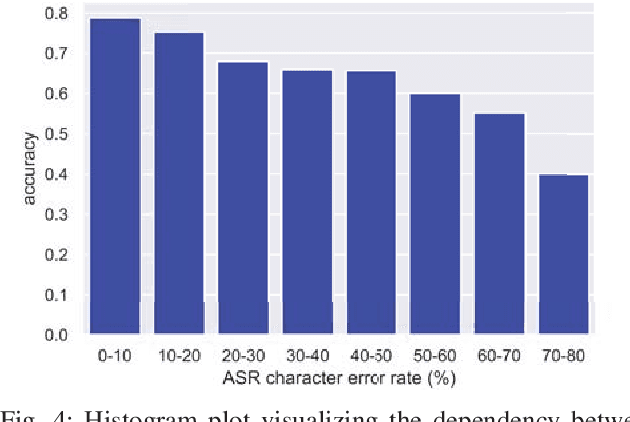
Previous work on emotion recognition demonstrated a synergistic effect of combining several modalities such as auditory, visual, and transcribed text to estimate the affective state of a speaker. Among these, the linguistic modality is crucial for the evaluation of an expressed emotion. However, manually transcribed spoken text cannot be given as input to a system practically. We argue that using ground-truth transcriptions during training and evaluation phases leads to a significant discrepancy in performance compared to real-world conditions, as the spoken text has to be recognized on the fly and can contain speech recognition mistakes. In this paper, we propose a method of integrating an automatic speech recognition (ASR) output with a character-level recurrent neural network for sentiment recognition. In addition, we conduct several experiments investigating sentiment recognition for human-robot interaction in a noise-realistic scenario which is challenging for the ASR systems. We quantify the improvement compared to using only the acoustic modality in sentiment recognition. We demonstrate the effectiveness of this approach on the Multimodal Corpus of Sentiment Intensity (MOSI) by achieving 73,6% accuracy in a binary sentiment classification task, exceeding previously reported results that use only acoustic input. In addition, we set a new state-of-the-art performance on the MOSI dataset (80.4% accuracy, 2% absolute improvement).