 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Self-Supervised Speech Representation Learning: A Review
May 21, 2022
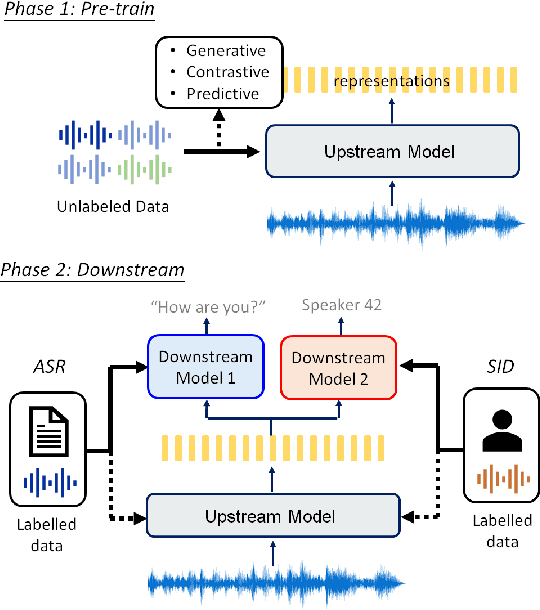
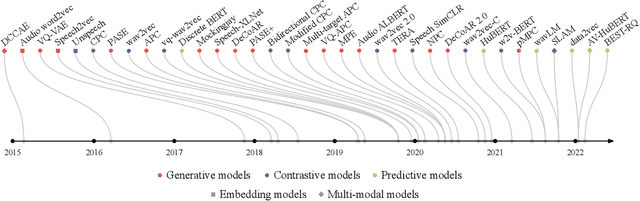
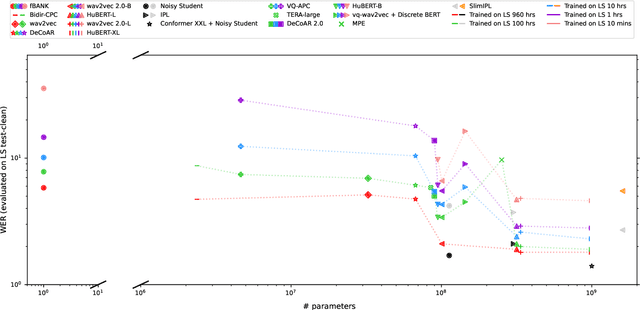
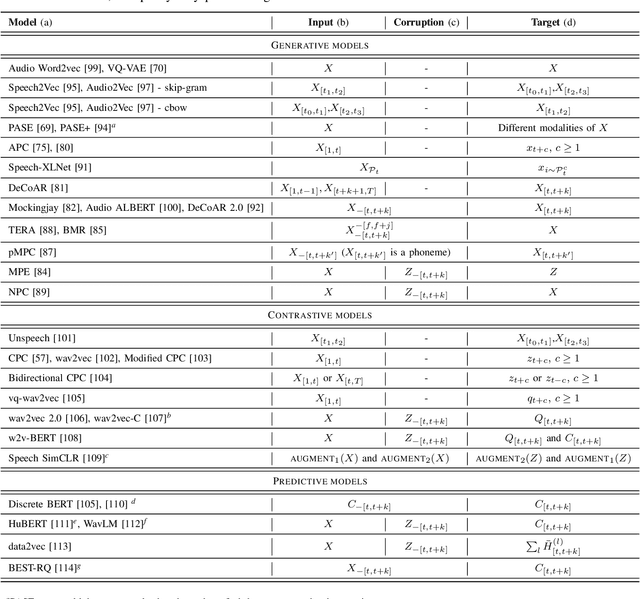
Although supervised deep learning has revolutionized speech and audio processing, it has necessitated the building of specialist models for individual tasks and application scenarios. It is likewise difficult to apply this to dialects and languages for which only limited labeled data is available. Self-supervised representation learning methods promise a single universal model that would benefit a wide variety of tasks and domains. Such methods have shown success in natural language processing and computer vision domains, achieving new levels of performance while reducing the number of labels required for many downstream scenarios. Speech representation learning is experiencing similar progress in three main categories: generative, contrastive, and predictive methods. Other approaches rely on multi-modal data for pre-training, mixing text or visual data streams with speech. Although self-supervised speech representation is still a nascent research area, it is closely related to acoustic word embedding and learning with zero lexical resources, both of which have seen active research for many years. This review presents approaches for self-supervised speech representation learning and their connection to other research areas. Since many current methods focus solely on automatic speech recognition as a downstream task, we review recent efforts on benchmarking learned representations to extend the application beyond speech recognition.
Distilling the Knowledge of BERT for CTC-based ASR
Sep 05, 2022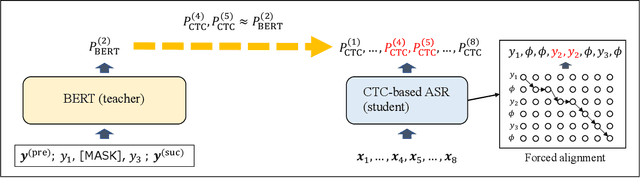
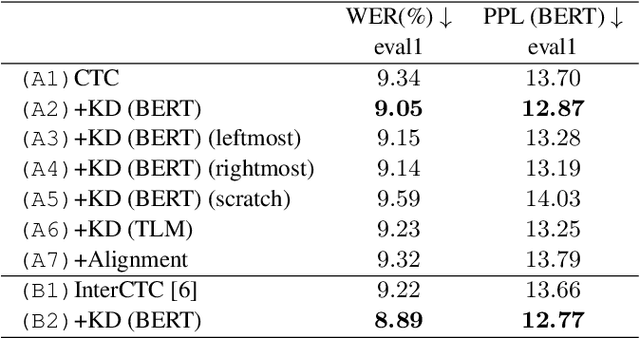
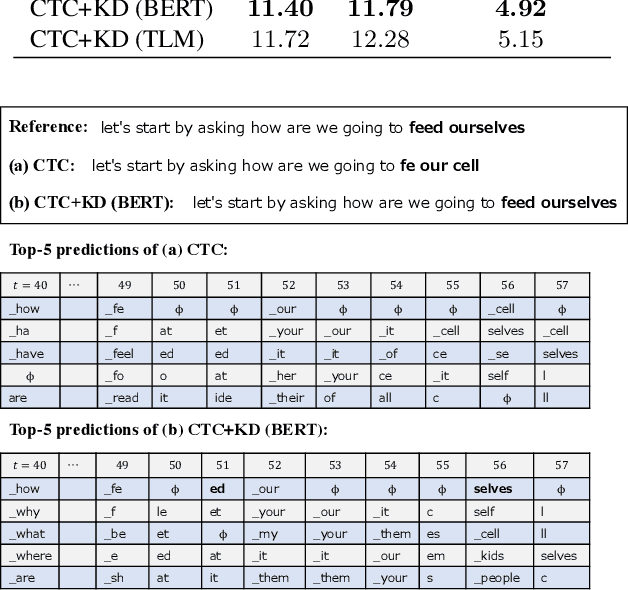
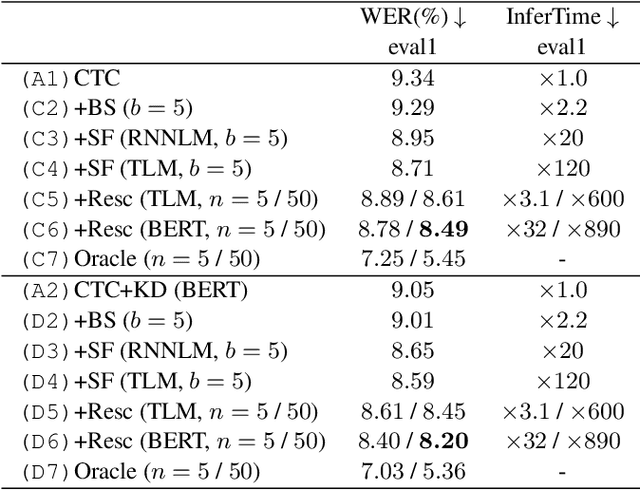
Connectionist temporal classification (CTC) -based models are attractive because of their fast inference in automatic speech recognition (ASR). Language model (LM) integration approaches such as shallow fusion and rescoring can improve the recognition accuracy of CTC-based ASR by taking advantage of the knowledge in text corpora. However, they significantly slow down the inference of CTC. In this study, we propose to distill the knowledge of BERT for CTC-based ASR, extending our previous study for attention-based ASR. CTC-based ASR learns the knowledge of BERT during training and does not use BERT during testing, which maintains the fast inference of CTC. Different from attention-based models, CTC-based models make frame-level predictions, so they need to be aligned with token-level predictions of BERT for distillation. We propose to obtain alignments by calculating the most plausible CTC paths. Experimental evaluations on the Corpus of Spontaneous Japanese (CSJ) and TED-LIUM2 show that our method improves the performance of CTC-based ASR without the cost of inference speed.
LRS3-TED: a large-scale dataset for visual speech recognition
Oct 28, 2018
This paper introduces a new multi-modal dataset for visual and audio-visual speech recognition. It includes face tracks from over 400 hours of TED and TEDx videos, along with the corresponding subtitles and word alignment boundaries. The new dataset is substantially larger in scale compared to other public datasets that are available for general research.
Espresso: A Fast End-to-end Neural Speech Recognition Toolkit
Sep 18, 2019
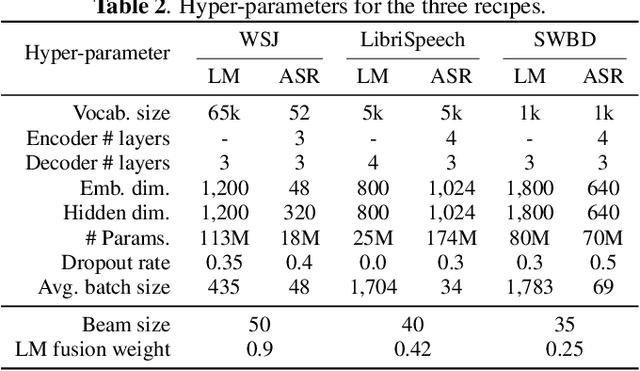
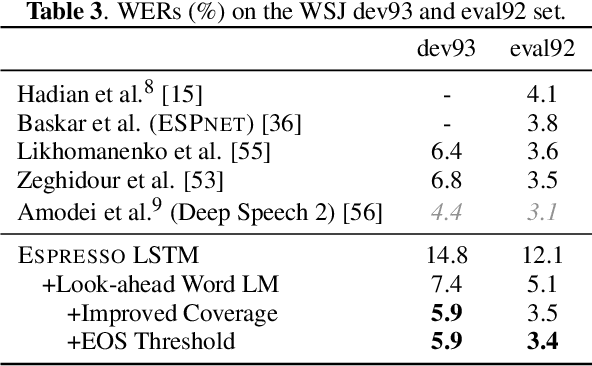
We present Espresso, an open-source, modular, extensible end-to-end neural automatic speech recognition (ASR) toolkit based on the deep learning library PyTorch and the popular neural machine translation toolkit fairseq. Espresso supports distributed training across GPUs and computing nodes, and features various decoding approaches commonly employed in ASR, including look-ahead word-based language model fusion, for which a fast, parallelized decoder is implemented. Espresso achieves state-of-the-art ASR performance on the WSJ, LibriSpeech, and Switchboard data sets among other end-to-end systems without data augmentation, and is 4--11x faster for decoding than similar systems (e.g. ESPnet).
Arabic Speech Recognition System using CMU-Sphinx4
Apr 17, 2007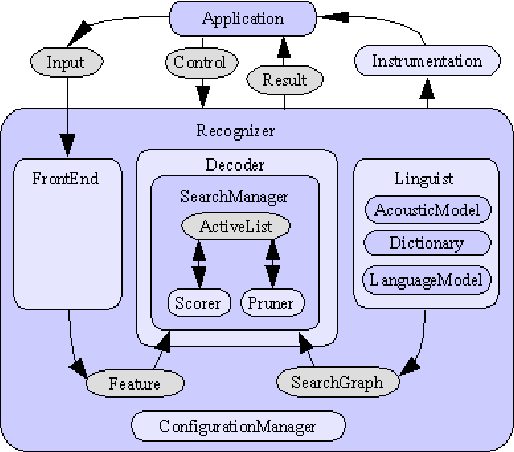
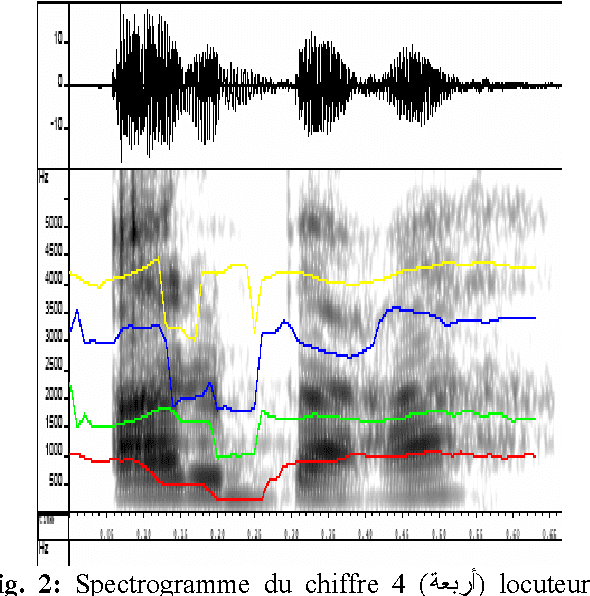

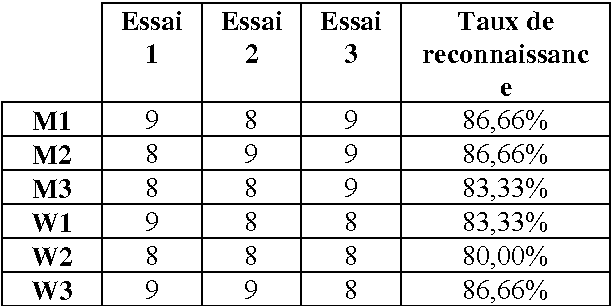
In this paper we present the creation of an Arabic version of Automated Speech Recognition System (ASR). This system is based on the open source Sphinx-4, from the Carnegie Mellon University. Which is a speech recognition system based on discrete hidden Markov models (HMMs). We investigate the changes that must be made to the model to adapt Arabic voice recognition. Keywords: Speech recognition, Acoustic model, Arabic language, HMMs, CMUSphinx-4, Artificial intelligence.
Techniques for Vocabulary Expansion in Hybrid Speech Recognition Systems
Mar 19, 2020

The problem of out of vocabulary words (OOV) is typical for any speech recognition system, hybrid systems are usually constructed to recognize a fixed set of words and rarely can include all the words that will be encountered during exploitation of the system. One of the popular approach to cover OOVs is to use subword units rather then words. Such system can potentially recognize any previously unseen word if the word can be constructed from present subword units, but also non-existing words can be recognized. The other popular approach is to modify HMM part of the system so that it can be easily and effectively expanded with custom set of words we want to add to the system. In this paper we explore different existing methods of this solution on both graph construction and search method levels. We also present a novel vocabulary expansion techniques which solve some common internal subroutine problems regarding recognition graph processing.
Endpoint Detection for Streaming End-to-End Multi-talker ASR
Jan 24, 2022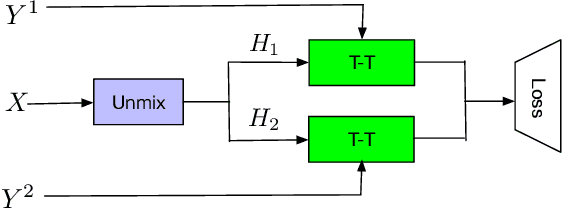
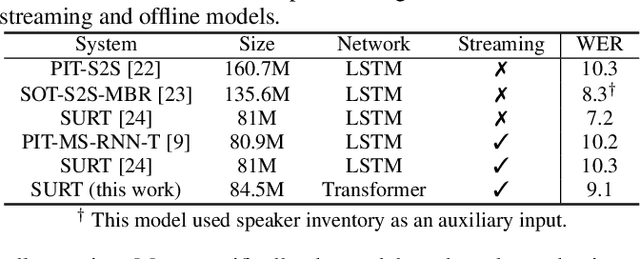
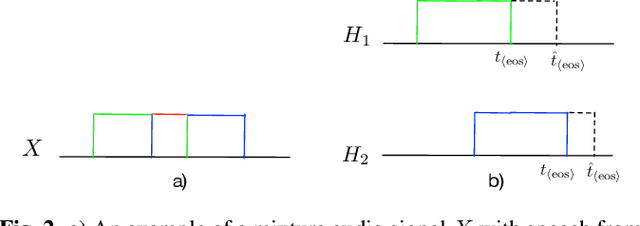
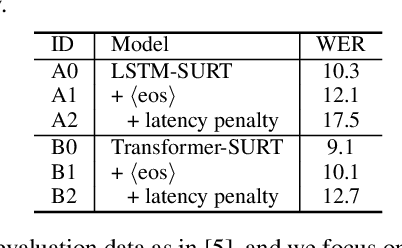
Streaming end-to-end multi-talker speech recognition aims at transcribing the overlapped speech from conversations or meetings with an all-neural model in a streaming fashion, which is fundamentally different from a modular-based approach that usually cascades the speech separation and the speech recognition models trained independently. Previously, we proposed the Streaming Unmixing and Recognition Transducer (SURT) model based on recurrent neural network transducer (RNN-T) for this problem and presented promising results. However, for real applications, the speech recognition system is also required to determine the timestamp when a speaker finishes speaking for prompt system response. This problem, known as endpoint (EP) detection, has not been studied previously for multi-talker end-to-end models. In this work, we address the EP detection problem in the SURT framework by introducing an end-of-sentence token as an output unit, following the practice of single-talker end-to-end models. Furthermore, we also present a latency penalty approach that can significantly cut down the EP detection latency. Our experimental results based on the 2-speaker LibrispeechMix dataset show that the SURT model can achieve promising EP detection without significantly degradation of the recognition accuracy.
Snow Mountain: Dataset of Audio Recordings of The Bible in Low Resource Languages
Jun 01, 2022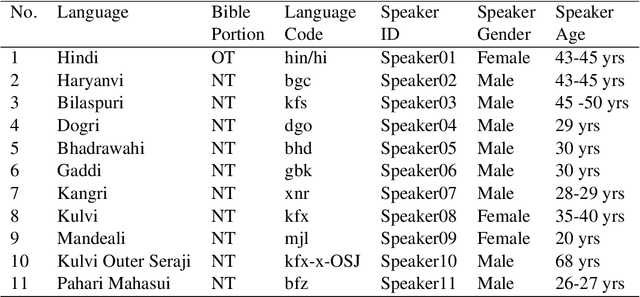
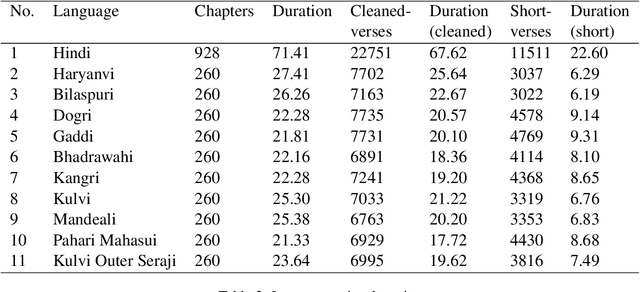
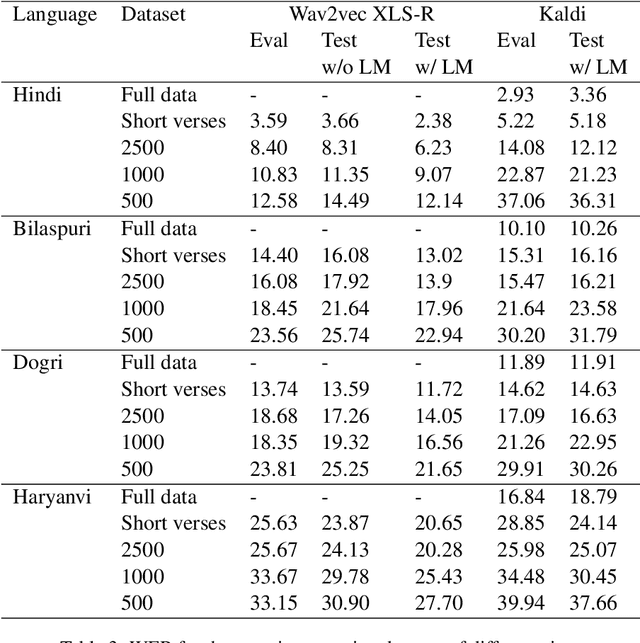

Automatic Speech Recognition (ASR) has increasing utility in the modern world. There are a many ASR models available for languages with large amounts of training data like English. However, low-resource languages are poorly represented. In response we create and release an open-licensed and formatted dataset of audio recordings of the Bible in low-resource northern Indian languages. We setup multiple experimental splits and train and analyze two competitive ASR models to serve as the baseline for future research using this data.
Parallel Rescoring with Transformer for Streaming On-Device Speech Recognition
Sep 02, 2020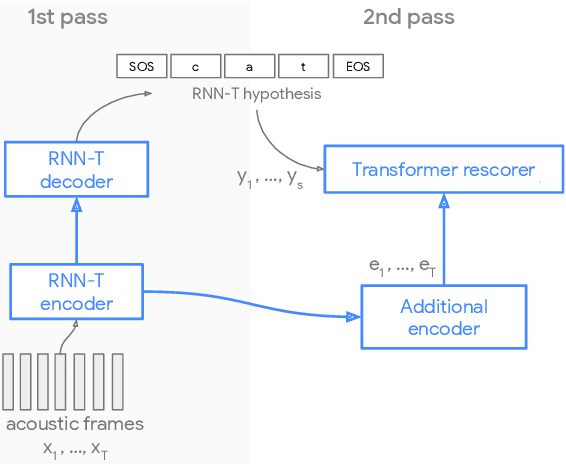
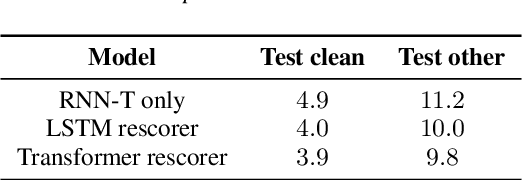
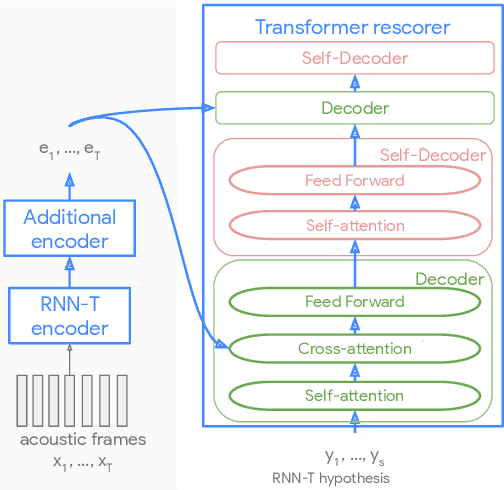
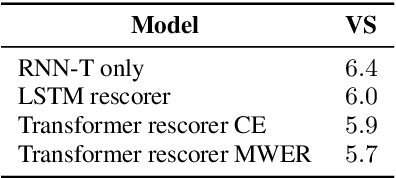
Recent advances of end-to-end models have outperformed conventional models through employing a two-pass model. The two-pass model provides better speed-quality trade-offs for on-device speech recognition, where a 1st-pass model generates hypotheses in a streaming fashion, and a 2nd-pass model re-scores the hypotheses with full audio sequence context. The 2nd-pass model plays a key role in the quality improvement of the end-to-end model to surpass the conventional model. One main challenge of the two-pass model is the computation latency introduced by the 2nd-pass model. Specifically, the original design of the two-pass model uses LSTMs for the 2nd-pass model, which are subject to long latency as they are constrained by the recurrent nature and have to run inference sequentially. In this work we explore replacing the LSTM layers in the 2nd-pass rescorer with Transformer layers, which can process the entire hypothesis sequences in parallel and can therefore utilize the on-device computation resources more efficiently. Compared with an LSTM-based baseline, our proposed Transformer rescorer achieves more than 50% latency reduction with quality improvement.
A Universally-Deployable ASR Frontend for Joint Acoustic Echo Cancellation, Speech Enhancement, and Voice Separation
Sep 14, 2022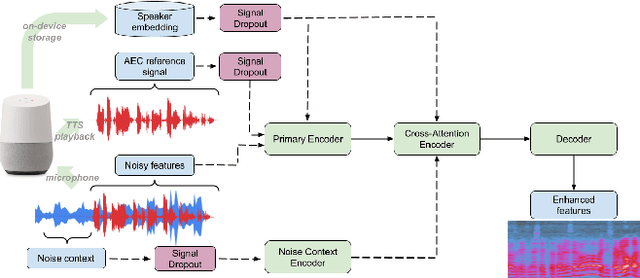

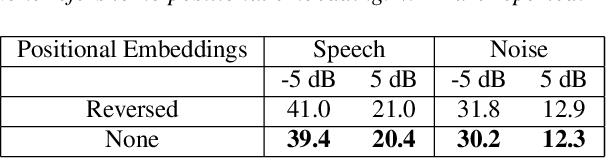
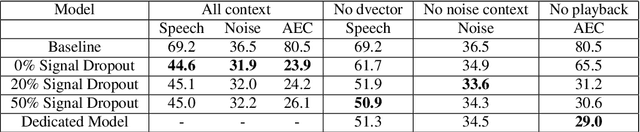
Recent work has shown that it is possible to train a single model to perform joint acoustic echo cancellation (AEC), speech enhancement, and voice separation, thereby serving as a unified frontend for robust automatic speech recognition (ASR). The joint model uses contextual information, such as a reference of the playback audio, noise context, and speaker embedding. In this work, we propose a number of novel improvements to such a model. First, we improve the architecture of the Cross-Attention Conformer that is used to ingest noise context into the model. Second, we generalize the model to be able to handle varying lengths of noise context. Third, we propose Signal Dropout, a novel strategy that models missing contextual information. In the absence of one or more signals, the proposed model performs nearly as well as task-specific models trained without these signals; and when such signals are present, our system compares well against systems that require all context signals. Over the baseline, the final model retains a relative word error rate reduction of 25.0% on background speech when speaker embedding is absent, and 61.2% on AEC when device playback is absent.