 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
SNRi Target Training for Joint Speech Enhancement and Recognition
Nov 01, 2021
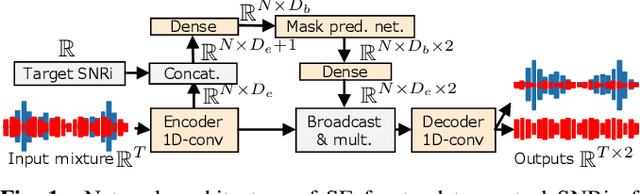

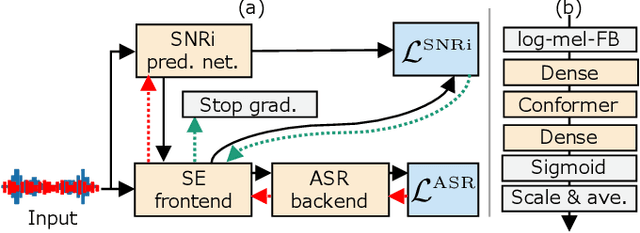
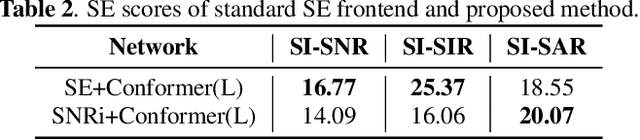
This study aims to improve the performance of automatic speech recognition (ASR) under noisy conditions. The use of a speech enhancement (SE) frontend has been widely studied for noise robust ASR. However, most single-channel SE models introduce processing artifacts in the enhanced speech resulting in degraded ASR performance. To overcome this problem, we propose Signal-to-Noise Ratio improvement (SNRi) target training; the SE frontend automatically controls its noise reduction level to avoid degrading the ASR performance due to artifacts. The SE frontend uses an auxiliary scalar input which represents the target SNRi of the output signal. The target SNRi value is estimated by the SNRi prediction network, which is trained to minimize the ASR loss. Experiments using 55,027 hours of noisy speech training data show that SNRi target training enables control of the SNRi of the output signal, and the joint training reduces word error rate by 12% compared to a state-of-the-art Conformer-based ASR model.
Non-autoregressive Error Correction for CTC-based ASR with Phone-conditioned Masked LM
Sep 08, 2022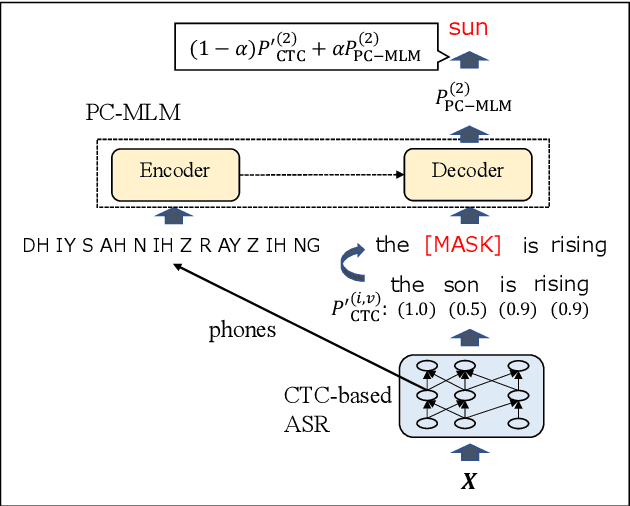
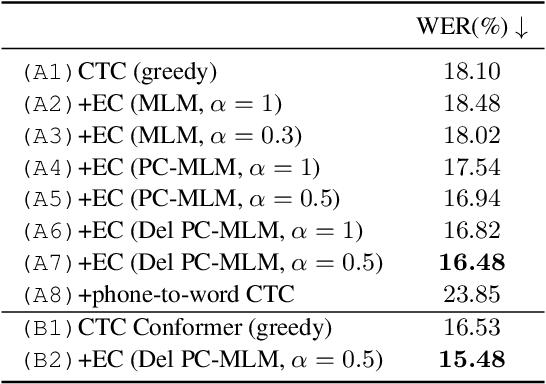
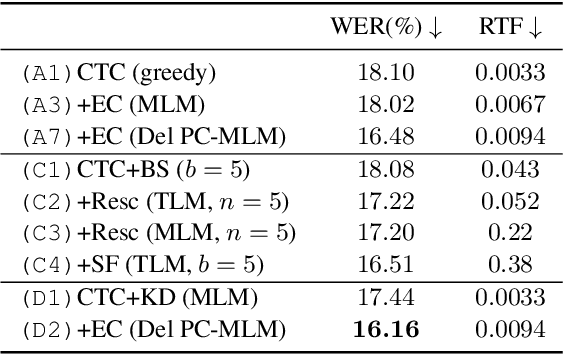
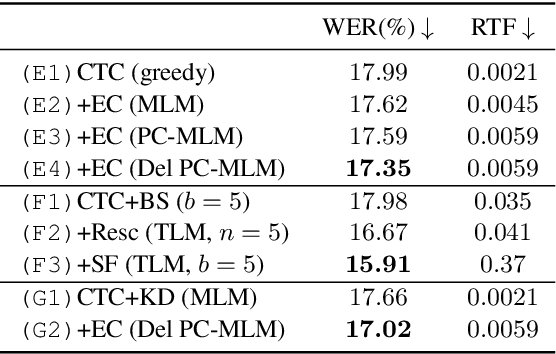
Connectionist temporal classification (CTC) -based models are attractive in automatic speech recognition (ASR) because of their non-autoregressive nature. To take advantage of text-only data, language model (LM) integration approaches such as rescoring and shallow fusion have been widely used for CTC. However, they lose CTC's non-autoregressive nature because of the need for beam search, which slows down the inference speed. In this study, we propose an error correction method with phone-conditioned masked LM (PC-MLM). In the proposed method, less confident word tokens in a greedy decoded output from CTC are masked. PC-MLM then predicts these masked word tokens given unmasked words and phones supplementally predicted from CTC. We further extend it to Deletable PC-MLM in order to address insertion errors. Since both CTC and PC-MLM are non-autoregressive models, the method enables fast LM integration. Experimental evaluations on the Corpus of Spontaneous Japanese (CSJ) and TED-LIUM2 in domain adaptation setting shows that our proposed method outperformed rescoring and shallow fusion in terms of inference speed, and also in terms of recognition accuracy on CSJ.
Generalizing in the Real World with Representation Learning
Oct 18, 2022
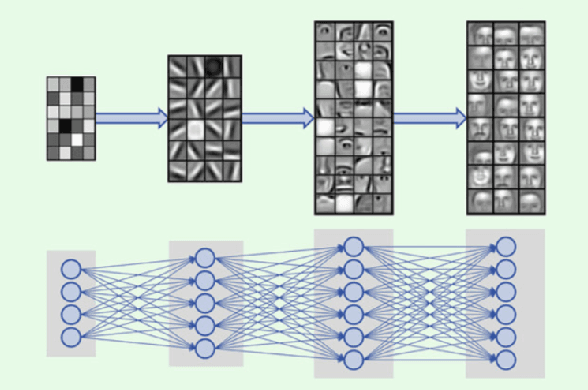
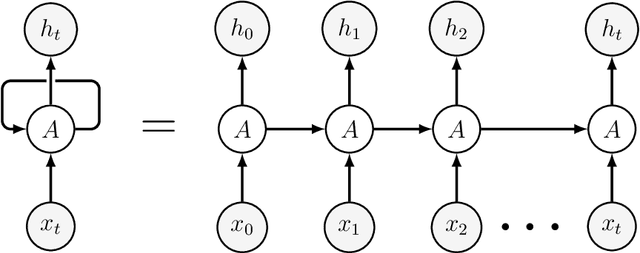
Machine learning (ML) formalizes the problem of getting computers to learn from experience as optimization of performance according to some metric(s) on a set of data examples. This is in contrast to requiring behaviour specified in advance (e.g. by hard-coded rules). Formalization of this problem has enabled great progress in many applications with large real-world impact, including translation, speech recognition, self-driving cars, and drug discovery. But practical instantiations of this formalism make many assumptions - for example, that data are i.i.d.: independent and identically distributed - whose soundness is seldom investigated. And in making great progress in such a short time, the field has developed many norms and ad-hoc standards, focused on a relatively small range of problem settings. As applications of ML, particularly in artificial intelligence (AI) systems, become more pervasive in the real world, we need to critically examine these assumptions, norms, and problem settings, as well as the methods that have become de-facto standards. There is much we still do not understand about how and why deep networks trained with stochastic gradient descent are able to generalize as well as they do, why they fail when they do, and how they will perform on out-of-distribution data. In this thesis I cover some of my work towards better understanding deep net generalization, identify several ways assumptions and problem settings fail to generalize to the real world, and propose ways to address those failures in practice.
Unified Autoregressive Modeling for Joint End-to-End Multi-Talker Overlapped Speech Recognition and Speaker Attribute Estimation
Jul 04, 2021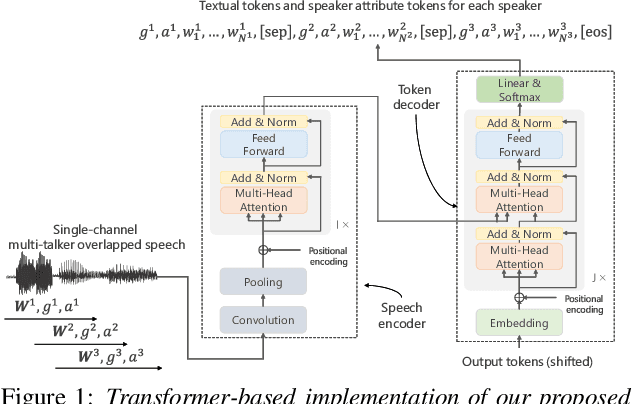
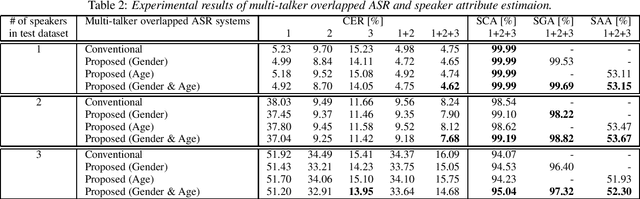
In this paper, we present a novel modeling method for single-channel multi-talker overlapped automatic speech recognition (ASR) systems. Fully neural network based end-to-end models have dramatically improved the performance of multi-taker overlapped ASR tasks. One promising approach for end-to-end modeling is autoregressive modeling with serialized output training in which transcriptions of multiple speakers are recursively generated one after another. This enables us to naturally capture relationships between speakers. However, the conventional modeling method cannot explicitly take into account the speaker attributes of individual utterances such as gender and age information. In fact, the performance deteriorates when each speaker is the same gender or is close in age. To address this problem, we propose unified autoregressive modeling for joint end-to-end multi-talker overlapped ASR and speaker attribute estimation. Our key idea is to handle gender and age estimation tasks within the unified autoregressive modeling. In the proposed method, transformer-based autoregressive model recursively generates not only textual tokens but also attribute tokens of each speaker. This enables us to effectively utilize speaker attributes for improving multi-talker overlapped ASR. Experiments on Japanese multi-talker overlapped ASR tasks demonstrate the effectiveness of the proposed method.
Progressive Joint Modeling in Unsupervised Single-channel Overlapped Speech Recognition
Oct 20, 2017
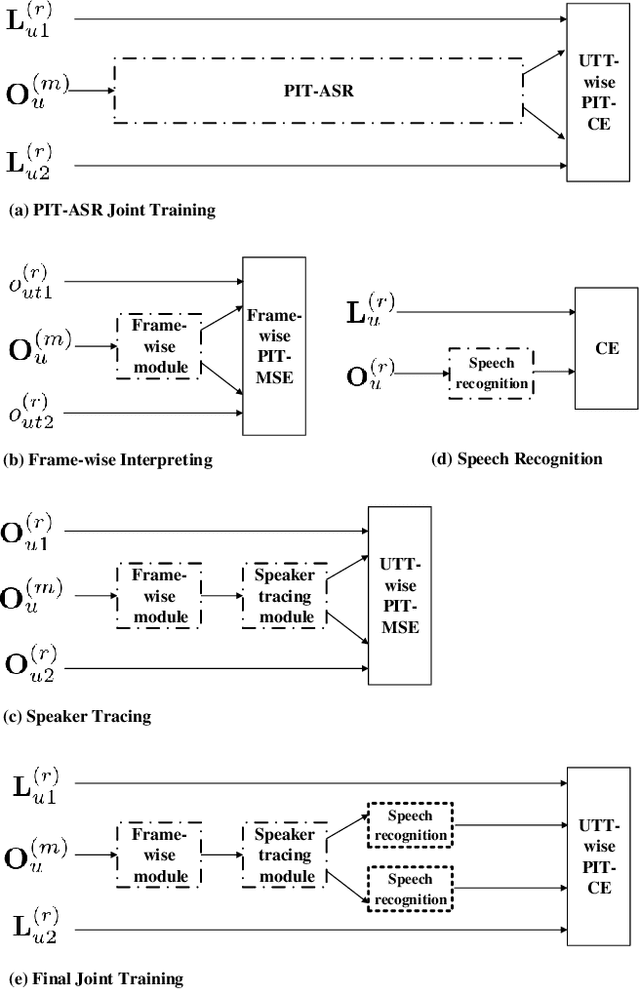
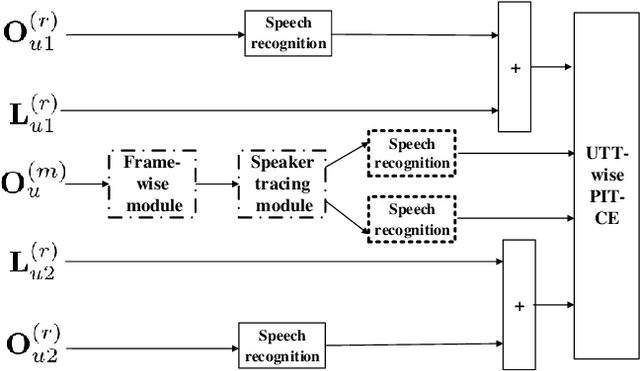
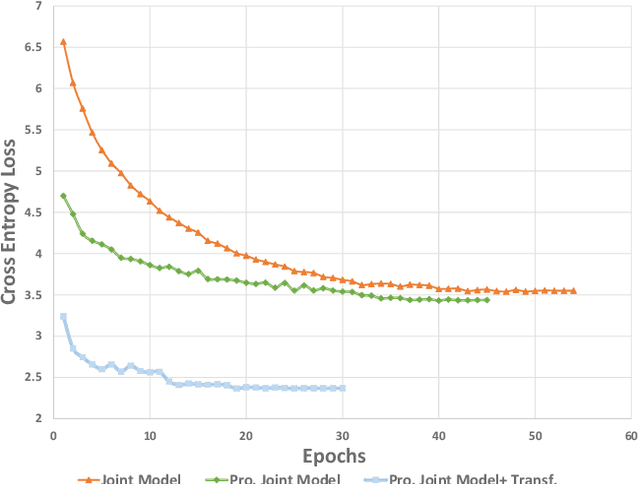
Unsupervised single-channel overlapped speech recognition is one of the hardest problems in automatic speech recognition (ASR). Permutation invariant training (PIT) is a state of the art model-based approach, which applies a single neural network to solve this single-input, multiple-output modeling problem. We propose to advance the current state of the art by imposing a modular structure on the neural network, applying a progressive pretraining regimen, and improving the objective function with transfer learning and a discriminative training criterion. The modular structure splits the problem into three sub-tasks: frame-wise interpreting, utterance-level speaker tracing, and speech recognition. The pretraining regimen uses these modules to solve progressively harder tasks. Transfer learning leverages parallel clean speech to improve the training targets for the network. Our discriminative training formulation is a modification of standard formulations, that also penalizes competing outputs of the system. Experiments are conducted on the artificial overlapped Switchboard and hub5e-swb dataset. The proposed framework achieves over 30% relative improvement of WER over both a strong jointly trained system, PIT for ASR, and a separately optimized system, PIT for speech separation with clean speech ASR model. The improvement comes from better model generalization, training efficiency and the sequence level linguistic knowledge integration.
* submitted to TASLP, 07/20/2017; accepted by TASLP, 10/13/2017
Out-of-Distribution Representation Learning for Time Series Classification
Sep 26, 2022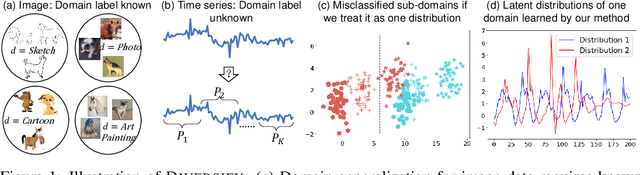
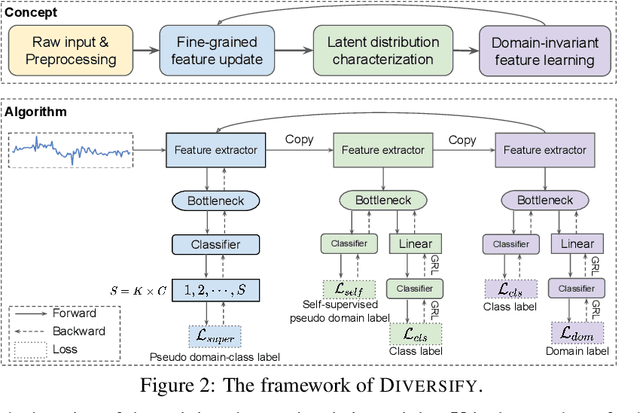
Time series classification is an important problem in real world. Due to its non-stationary property that the distribution changes over time, it remains challenging to build models for generalization to unseen distributions. In this paper, we propose to view the time series classification problem from the distribution perspective. We argue that the temporal complexity attributes to the unknown latent distributions within. To this end, we propose DIVERSIFY to learn generalized representations for time series classification. DIVERSIFY takes an iterative process: it first obtains the worst-case distribution scenario via adversarial training, then matches the distributions of the obtained sub-domains. We also present some theoretical insights. We conduct experiments on gesture recognition, speech commands recognition, wearable stress and affect detection, and sensor-based human activity recognition with a total of seven datasets in different settings. Results demonstrate that DIVERSIFY significantly outperforms other baselines and effectively characterizes the latent distributions by qualitative and quantitative analysis.
Model Blending for Text Classification
Aug 05, 2022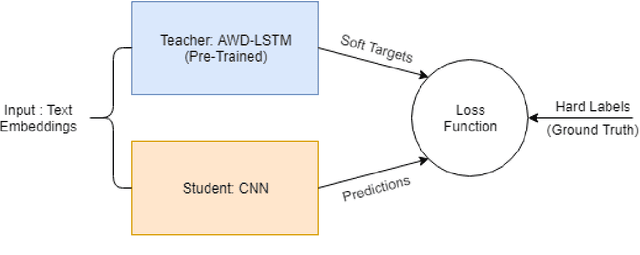
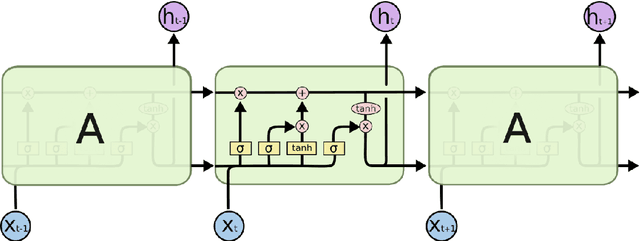
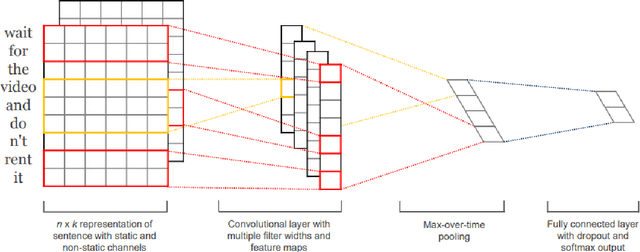
Deep neural networks (DNNs) have proven successful in a wide variety of applications such as speech recognition and synthesis, computer vision, machine translation, and game playing, to name but a few. However, existing deep neural network models are computationally expensive and memory intensive, hindering their deployment in devices with low memory resources or in applications with strict latency requirements. Therefore, a natural thought is to perform model compression and acceleration in deep networks without significantly decreasing the model performance, which is what we call reducing the complexity. In the following work, we try reducing the complexity of state of the art LSTM models for natural language tasks such as text classification, by distilling their knowledge to CNN based models, thus reducing the inference time(or latency) during testing.
Unleashing the True Potential of Sequence-to-Sequence Models for Sequence Tagging and Structure Parsing
Feb 05, 2023
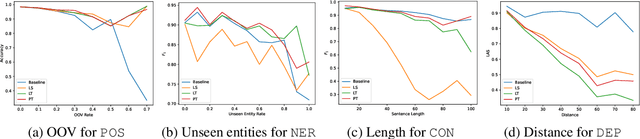
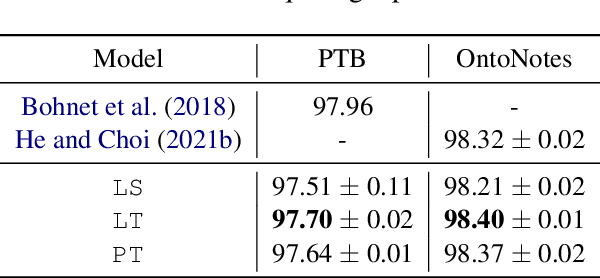
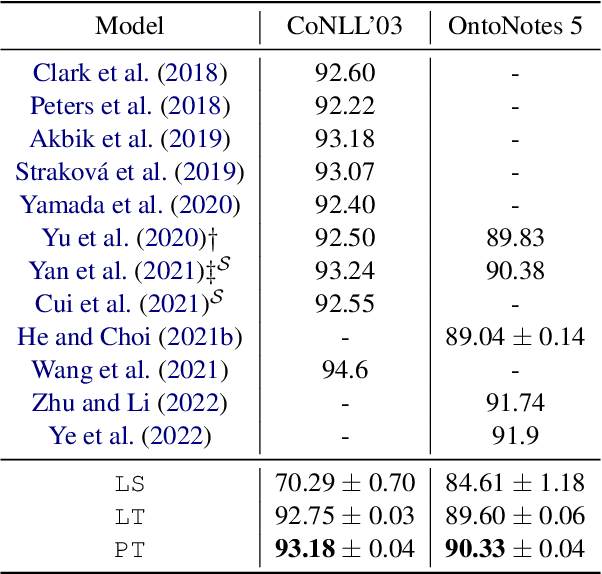
Sequence-to-Sequence (S2S) models have achieved remarkable success on various text generation tasks. However, learning complex structures with S2S models remains challenging as external neural modules and additional lexicons are often supplemented to predict non-textual outputs. We present a systematic study of S2S modeling using contained decoding on four core tasks: part-of-speech tagging, named entity recognition, constituency and dependency parsing, to develop efficient exploitation methods costing zero extra parameters. In particular, 3 lexically diverse linearization schemas and corresponding constrained decoding methods are designed and evaluated. Experiments show that although more lexicalized schemas yield longer output sequences that require heavier training, their sequences being closer to natural language makes them easier to learn. Moreover, S2S models using our constrained decoding outperform other S2S approaches using external resources. Our best models perform better than or comparably to the state-of-the-art for all 4 tasks, lighting a promise for S2S models to generate non-sequential structures.
Streaming automatic speech recognition with the transformer model
Jan 09, 2020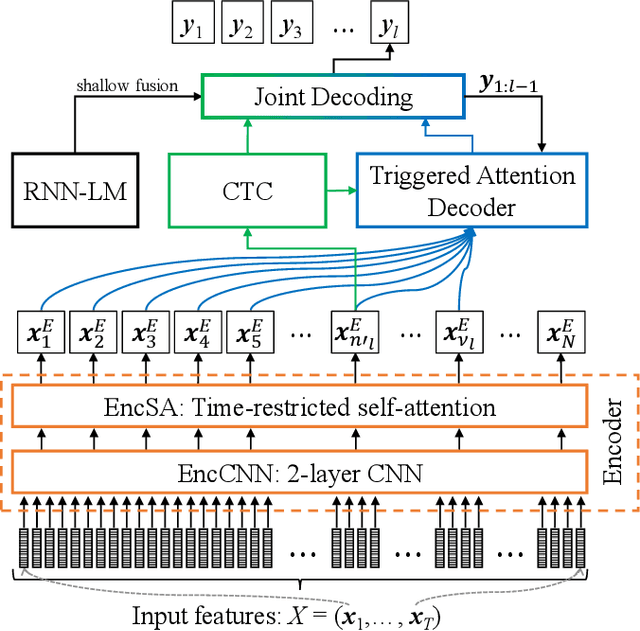
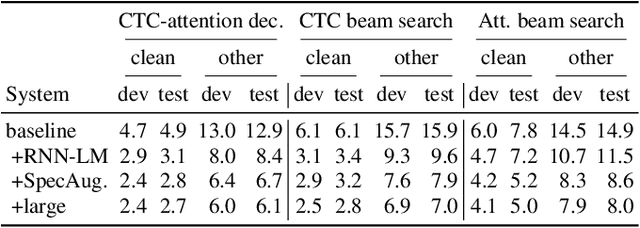
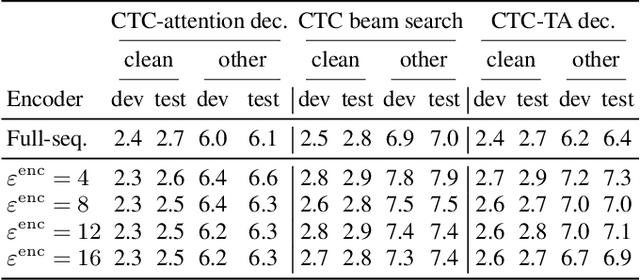
Encoder-decoder based sequence-to-sequence models have demonstrated state-of-the-art results in end-to-end automatic speech recognition (ASR). Recently, the transformer architecture, which uses self-attention to model temporal context information, has been shown to achieve significantly lower word error rates (WERs) compared to recurrent neural network (RNN) based system architectures. Despite its success, the practical usage is limited to offline ASR tasks, since encoder-decoder architectures typically require an entire speech utterance as input. In this work, we propose a transformer based end-to-end ASR system for streaming ASR, where an output must be generated shortly after each spoken word. To achieve this, we apply time-restricted self-attention for the encoder and triggered attention for the encoder-decoder attention mechanism. Our proposed streaming transformer architecture achieves 2.7% and 7.0% WER for the "clean" and "other" test data of LibriSpeech, which to our knowledge is the best published streaming end-to-end ASR result for this task.