 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Out-of-Distribution Representation Learning for Time Series Classification
Sep 26, 2022
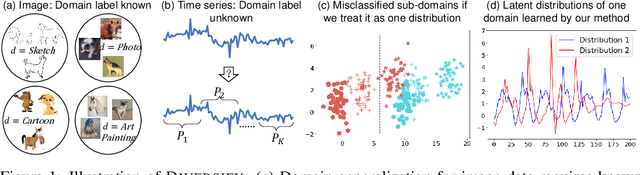
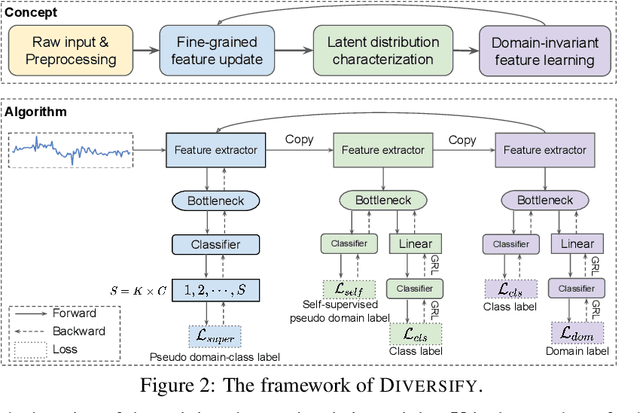
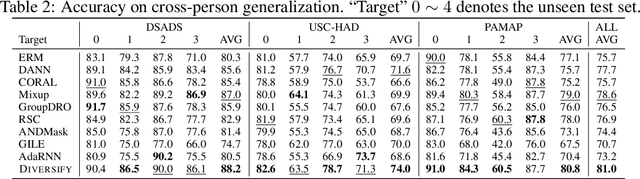
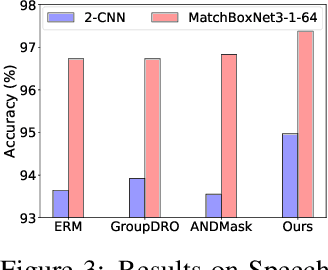
Time series classification is an important problem in real world. Due to its non-stationary property that the distribution changes over time, it remains challenging to build models for generalization to unseen distributions. In this paper, we propose to view the time series classification problem from the distribution perspective. We argue that the temporal complexity attributes to the unknown latent distributions within. To this end, we propose DIVERSIFY to learn generalized representations for time series classification. DIVERSIFY takes an iterative process: it first obtains the worst-case distribution scenario via adversarial training, then matches the distributions of the obtained sub-domains. We also present some theoretical insights. We conduct experiments on gesture recognition, speech commands recognition, wearable stress and affect detection, and sensor-based human activity recognition with a total of seven datasets in different settings. Results demonstrate that DIVERSIFY significantly outperforms other baselines and effectively characterizes the latent distributions by qualitative and quantitative analysis.
Deep Graph Random Process for Relational-Thinking-Based Speech Recognition
Jul 04, 2020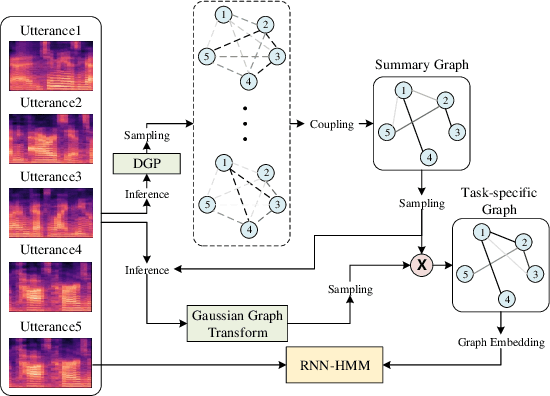
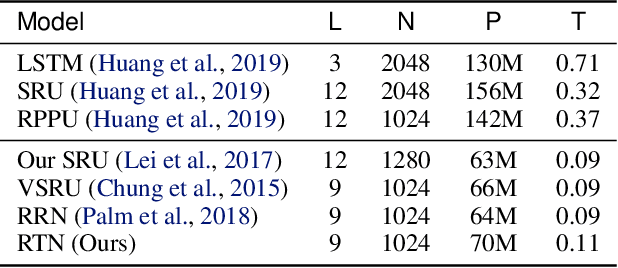
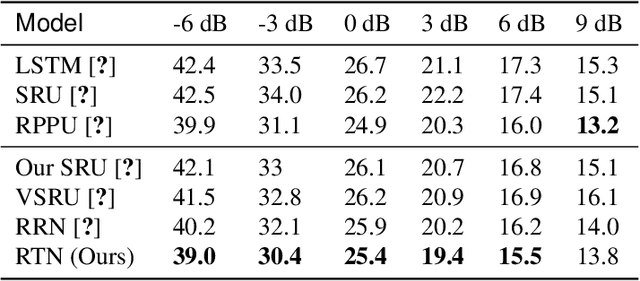

Lying at the core of human intelligence, relational thinking is characterized by initially relying on innumerable unconscious percepts pertaining to relations between new sensory signals and prior knowledge, consequently becoming a recognizable concept or object through coupling and transformation of these percepts. Such mental processes are difficult to model in real-world problems such as in conversational automatic speech recognition (ASR), as the percepts (if they are modelled as graphs indicating relationships among utterances) are supposed to be innumerable and not directly observable. In this paper, we present a Bayesian nonparametric deep learning method called deep graph random process (DGP) that can generate an infinite number of probabilistic graphs representing percepts. We further provide a closed-form solution for coupling and transformation of these percept graphs for acoustic modeling. Our approach is able to successfully infer relations among utterances without using any relational data during training. Experimental evaluations on ASR tasks including CHiME-2 and CHiME-5 demonstrate the effectiveness and benefits of our method.
Distribution Aware Metrics for Conditional Natural Language Generation
Sep 29, 2022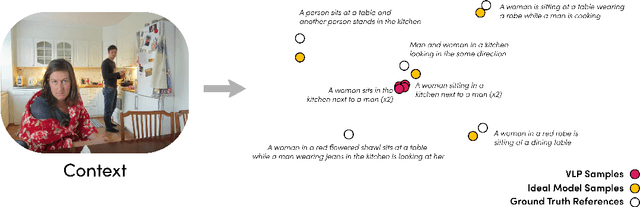
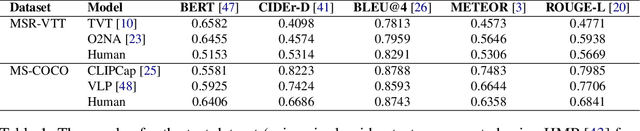
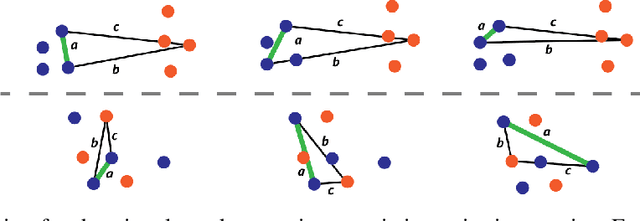

Traditional automated metrics for evaluating conditional natural language generation use pairwise comparisons between a single generated text and the best-matching gold-standard ground truth text. When multiple ground truths are available, scores are aggregated using an average or max operation across references. While this approach works well when diversity in the ground truth data (i.e. dispersion of the distribution of conditional texts) can be ascribed to noise, such as in automated speech recognition, it does not allow for robust evaluation in the case where diversity in the ground truths represents signal for the model. In this work we argue that existing metrics are not appropriate for domains such as visual description or summarization where ground truths are semantically diverse, and where the diversity in those captions captures useful additional information about the context. We propose a novel paradigm for multi-candidate evaluation of conditional language generation models, and a new family of metrics that compare the distributions of reference and model-generated caption sets using small sample sets of each. We demonstrate the utility of our approach with a case study in visual description: where we show that existing models optimize for single-description quality over diversity, and gain some insights into how sampling methods and temperature impact description quality and diversity.
Model Blending for Text Classification
Aug 05, 2022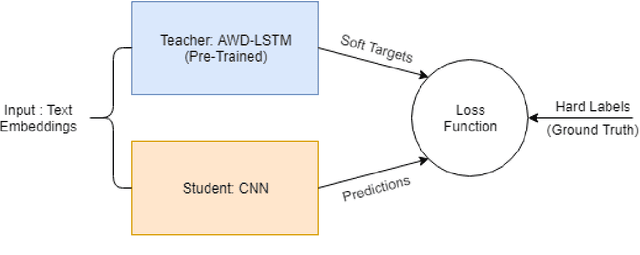
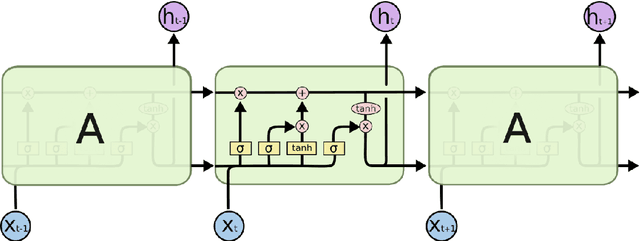
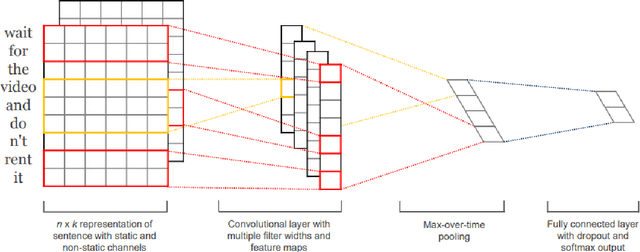
Deep neural networks (DNNs) have proven successful in a wide variety of applications such as speech recognition and synthesis, computer vision, machine translation, and game playing, to name but a few. However, existing deep neural network models are computationally expensive and memory intensive, hindering their deployment in devices with low memory resources or in applications with strict latency requirements. Therefore, a natural thought is to perform model compression and acceleration in deep networks without significantly decreasing the model performance, which is what we call reducing the complexity. In the following work, we try reducing the complexity of state of the art LSTM models for natural language tasks such as text classification, by distilling their knowledge to CNN based models, thus reducing the inference time(or latency) during testing.
Improving End-to-End Speech Recognition with Policy Learning
Dec 19, 2017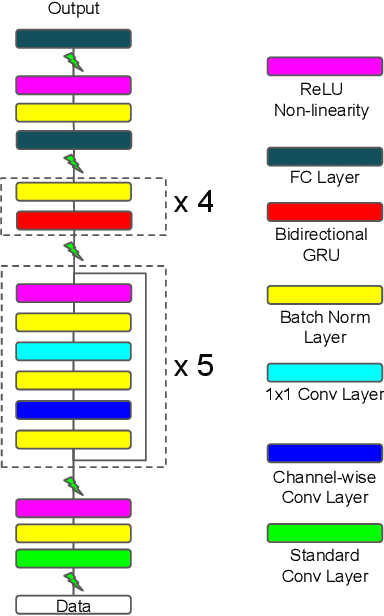
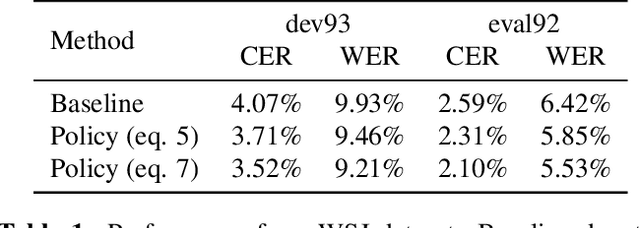
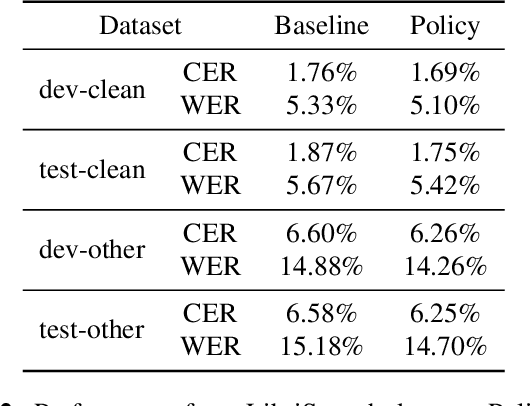
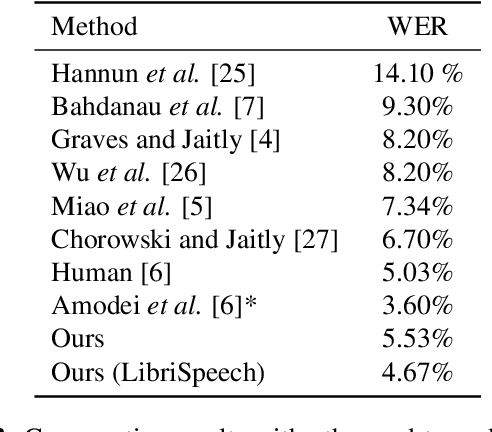
Connectionist temporal classification (CTC) is widely used for maximum likelihood learning in end-to-end speech recognition models. However, there is usually a disparity between the negative maximum likelihood and the performance metric used in speech recognition, e.g., word error rate (WER). This results in a mismatch between the objective function and metric during training. We show that the above problem can be mitigated by jointly training with maximum likelihood and policy gradient. In particular, with policy learning we are able to directly optimize on the (otherwise non-differentiable) performance metric. We show that joint training improves relative performance by 4% to 13% for our end-to-end model as compared to the same model learned through maximum likelihood. The model achieves 5.53% WER on Wall Street Journal dataset, and 5.42% and 14.70% on Librispeech test-clean and test-other set, respectively.
Alignment Knowledge Distillation for Online Streaming Attention-based Speech Recognition
Feb 28, 2021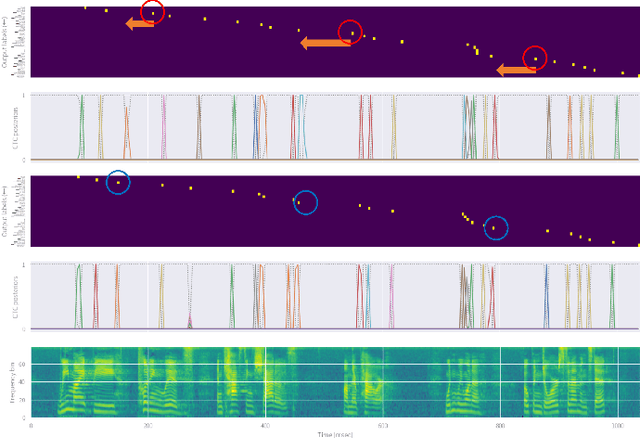
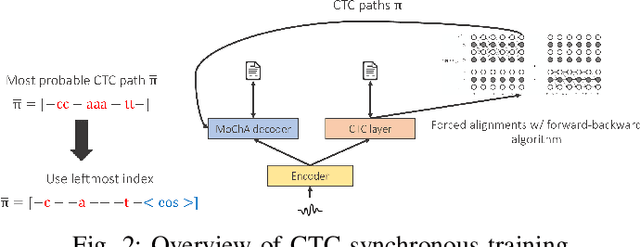
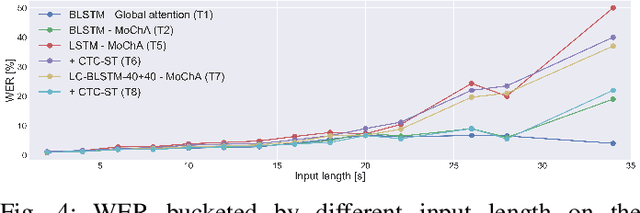
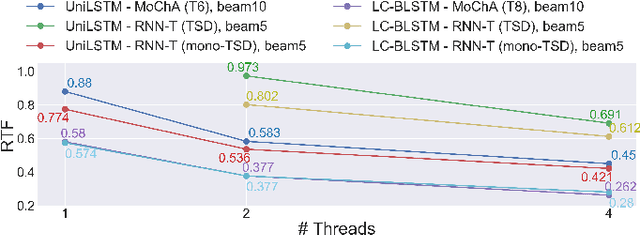
This article describes an efficient training method for online streaming attention-based encoder-decoder (AED) automatic speech recognition (ASR) systems. AED models have achieved competitive performance in offline scenarios by jointly optimizing all components. They have recently been extended to an online streaming framework via models such as monotonic chunkwise attention (MoChA). However, the elaborate attention calculation process is not robust for long-form speech utterances. Moreover, the sequence-level training objective and time-restricted streaming encoder cause a nonnegligible delay in token emission during inference. To address these problems, we propose CTC synchronous training (CTC-ST), in which CTC alignments are leveraged as a reference for token boundaries to enable a MoChA model to learn optimal monotonic input-output alignments. We formulate a purely end-to-end training objective to synchronize the boundaries of MoChA to those of CTC. The CTC model shares an encoder with the MoChA model to enhance the encoder representation. Moreover, the proposed method provides alignment information learned in the CTC branch to the attention-based decoder. Therefore, CTC-ST can be regarded as self-distillation of alignment knowledge from CTC to MoChA. Experimental evaluations on a variety of benchmark datasets show that the proposed method significantly reduces recognition errors and emission latency simultaneously, especially for long-form and noisy speech. We also compare CTC-ST with several methods that distill alignment knowledge from a hybrid ASR system and show that the CTC-ST can achieve a comparable tradeoff of accuracy and latency without relying on external alignment information. The best MoChA system shows performance comparable to that of RNN-transducer (RNN-T).
Exploring Neural Transducers for End-to-End Speech Recognition
Jul 24, 2017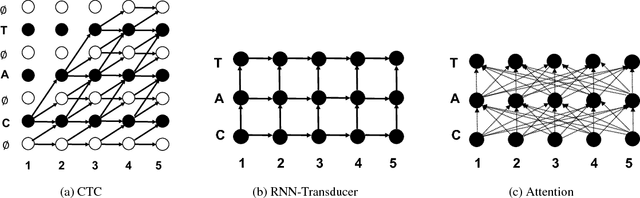
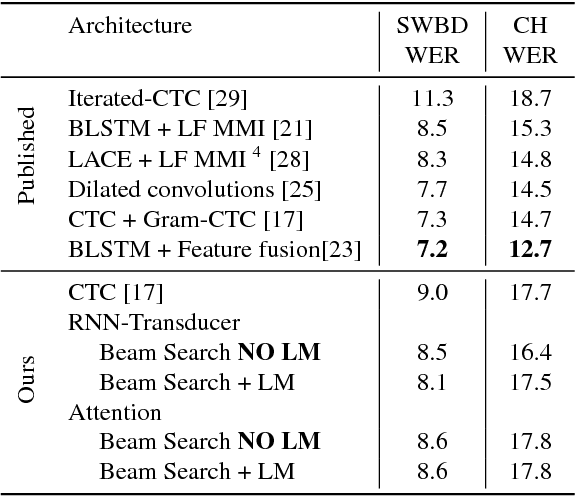
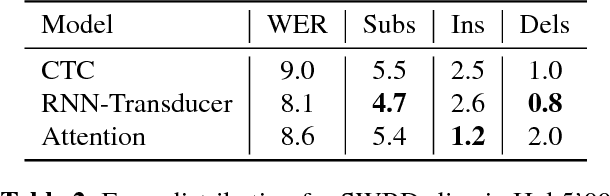
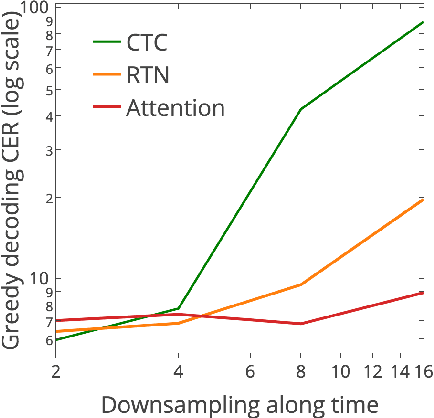
In this work, we perform an empirical comparison among the CTC, RNN-Transducer, and attention-based Seq2Seq models for end-to-end speech recognition. We show that, without any language model, Seq2Seq and RNN-Transducer models both outperform the best reported CTC models with a language model, on the popular Hub5'00 benchmark. On our internal diverse dataset, these trends continue - RNNTransducer models rescored with a language model after beam search outperform our best CTC models. These results simplify the speech recognition pipeline so that decoding can now be expressed purely as neural network operations. We also study how the choice of encoder architecture affects the performance of the three models - when all encoder layers are forward only, and when encoders downsample the input representation aggressively.
ESE: Efficient Speech Recognition Engine with Sparse LSTM on FPGA
Feb 20, 2017

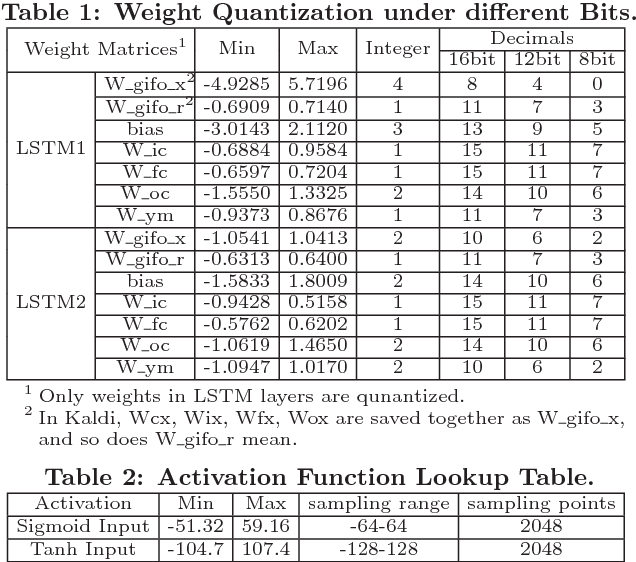
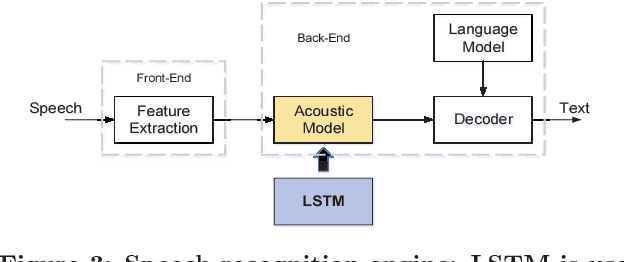
Long Short-Term Memory (LSTM) is widely used in speech recognition. In order to achieve higher prediction accuracy, machine learning scientists have built larger and larger models. Such large model is both computation intensive and memory intensive. Deploying such bulky model results in high power consumption and leads to high total cost of ownership (TCO) of a data center. In order to speedup the prediction and make it energy efficient, we first propose a load-balance-aware pruning method that can compress the LSTM model size by 20x (10x from pruning and 2x from quantization) with negligible loss of the prediction accuracy. The pruned model is friendly for parallel processing. Next, we propose scheduler that encodes and partitions the compressed model to each PE for parallelism, and schedule the complicated LSTM data flow. Finally, we design the hardware architecture, named Efficient Speech Recognition Engine (ESE) that works directly on the compressed model. Implemented on Xilinx XCKU060 FPGA running at 200MHz, ESE has a performance of 282 GOPS working directly on the compressed LSTM network, corresponding to 2.52 TOPS on the uncompressed one, and processes a full LSTM for speech recognition with a power dissipation of 41 Watts. Evaluated on the LSTM for speech recognition benchmark, ESE is 43x and 3x faster than Core i7 5930k CPU and Pascal Titan X GPU implementations. It achieves 40x and 11.5x higher energy efficiency compared with the CPU and GPU respectively.
SNRi Target Training for Joint Speech Enhancement and Recognition
Nov 01, 2021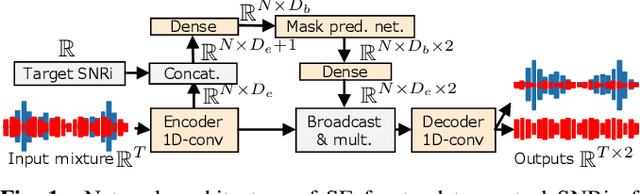

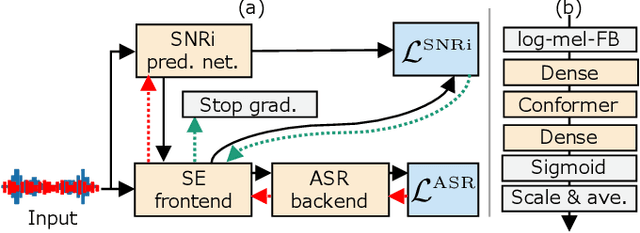
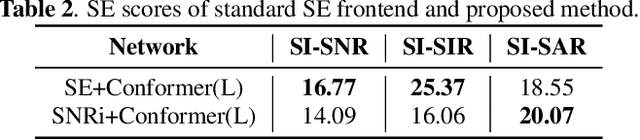
This study aims to improve the performance of automatic speech recognition (ASR) under noisy conditions. The use of a speech enhancement (SE) frontend has been widely studied for noise robust ASR. However, most single-channel SE models introduce processing artifacts in the enhanced speech resulting in degraded ASR performance. To overcome this problem, we propose Signal-to-Noise Ratio improvement (SNRi) target training; the SE frontend automatically controls its noise reduction level to avoid degrading the ASR performance due to artifacts. The SE frontend uses an auxiliary scalar input which represents the target SNRi of the output signal. The target SNRi value is estimated by the SNRi prediction network, which is trained to minimize the ASR loss. Experiments using 55,027 hours of noisy speech training data show that SNRi target training enables control of the SNRi of the output signal, and the joint training reduces word error rate by 12% compared to a state-of-the-art Conformer-based ASR model.
Achieving Human Parity in Conversational Speech Recognition
Feb 17, 2017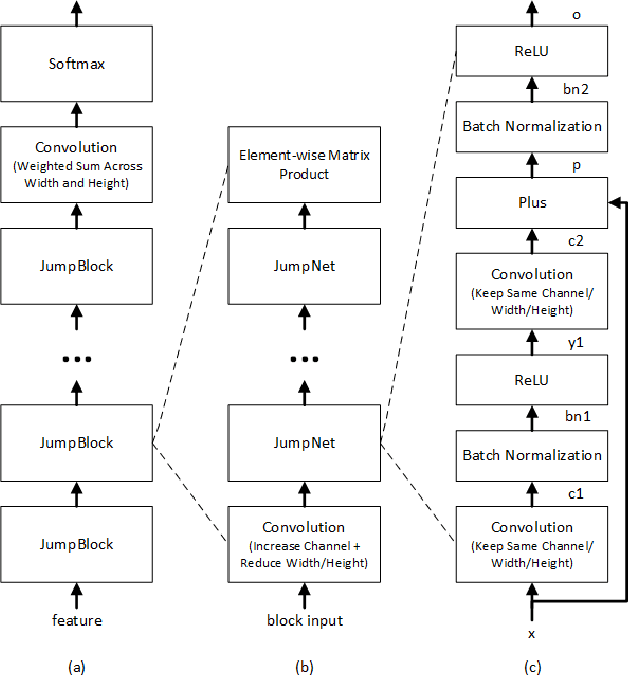
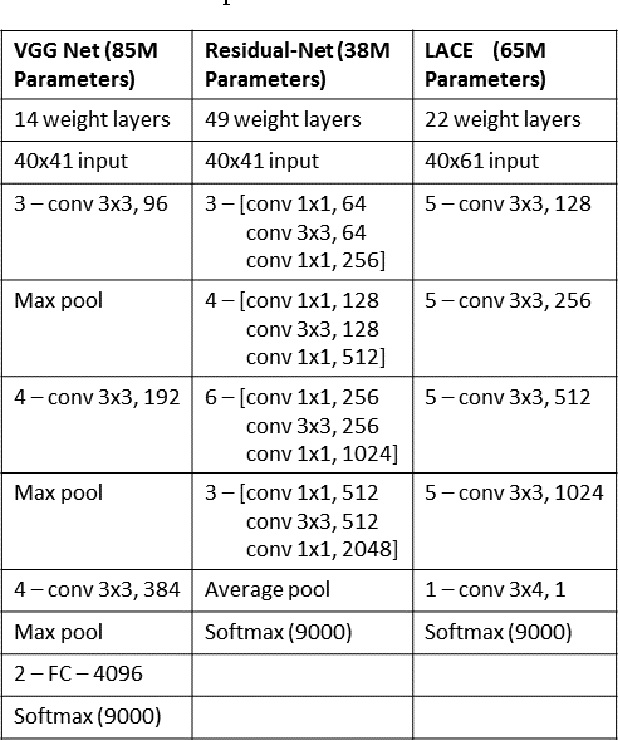
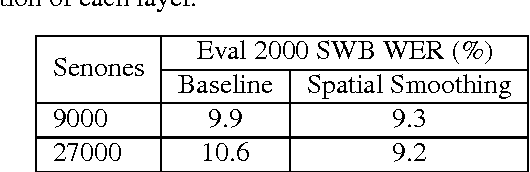
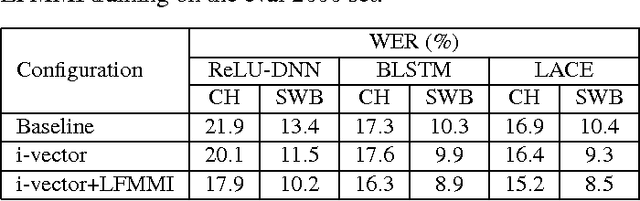
Conversational speech recognition has served as a flagship speech recognition task since the release of the Switchboard corpus in the 1990s. In this paper, we measure the human error rate on the widely used NIST 2000 test set, and find that our latest automated system has reached human parity. The error rate of professional transcribers is 5.9% for the Switchboard portion of the data, in which newly acquainted pairs of people discuss an assigned topic, and 11.3% for the CallHome portion where friends and family members have open-ended conversations. In both cases, our automated system establishes a new state of the art, and edges past the human benchmark, achieving error rates of 5.8% and 11.0%, respectively. The key to our system's performance is the use of various convolutional and LSTM acoustic model architectures, combined with a novel spatial smoothing method and lattice-free MMI acoustic training, multiple recurrent neural network language modeling approaches, and a systematic use of system combination.