 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Generating Human Readable Transcript for Automatic Speech Recognition with Pre-trained Language Model
Feb 22, 2021
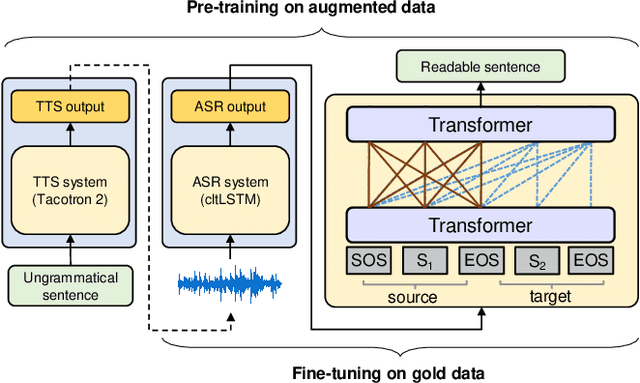
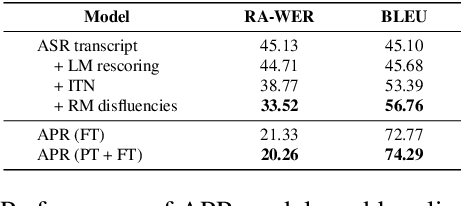

Modern Automatic Speech Recognition (ASR) systems can achieve high performance in terms of recognition accuracy. However, a perfectly accurate transcript still can be challenging to read due to disfluency, filter words, and other errata common in spoken communication. Many downstream tasks and human readers rely on the output of the ASR system; therefore, errors introduced by the speaker and ASR system alike will be propagated to the next task in the pipeline. In this work, we propose an ASR post-processing model that aims to transform the incorrect and noisy ASR output into a readable text for humans and downstream tasks. We leverage the Metadata Extraction (MDE) corpus to construct a task-specific dataset for our study. Since the dataset is small, we propose a novel data augmentation method and use a two-stage training strategy to fine-tune the RoBERTa pre-trained model. On the constructed test set, our model outperforms a production two-step pipeline-based post-processing method by a large margin of 13.26 on readability-aware WER (RA-WER) and 17.53 on BLEU metrics. Human evaluation also demonstrates that our method can generate more human-readable transcripts than the baseline method.
Assessing ASR Model Quality on Disordered Speech using BERTScore
Sep 21, 2022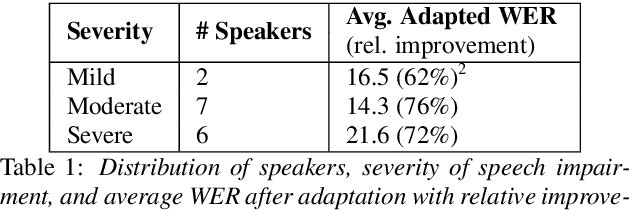
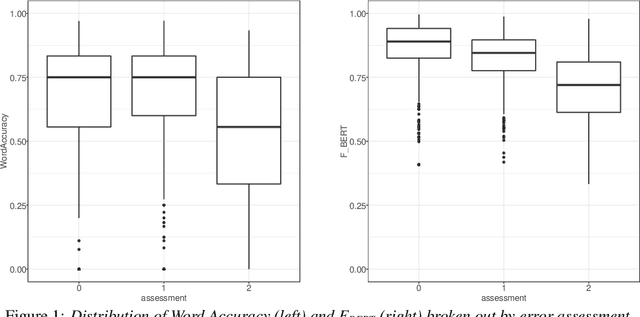
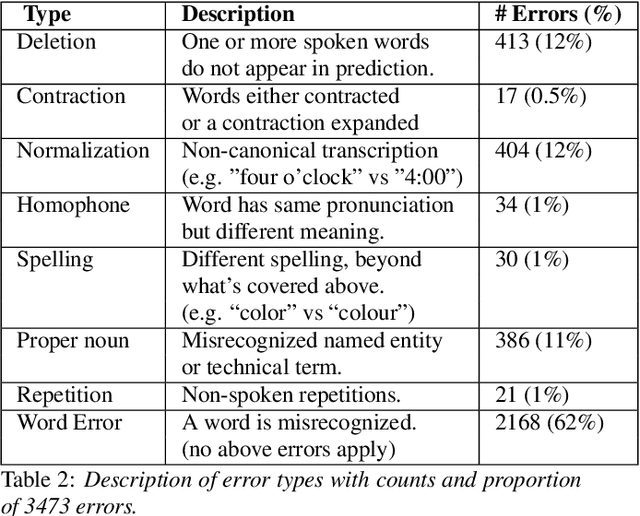
Word Error Rate (WER) is the primary metric used to assess automatic speech recognition (ASR) model quality. It has been shown that ASR models tend to have much higher WER on speakers with speech impairments than typical English speakers. It is hard to determine if models can be be useful at such high error rates. This study investigates the use of BERTScore, an evaluation metric for text generation, to provide a more informative measure of ASR model quality and usefulness. Both BERTScore and WER were compared to prediction errors manually annotated by Speech Language Pathologists for error type and assessment. BERTScore was found to be more correlated with human assessment of error type and assessment. BERTScore was specifically more robust to orthographic changes (contraction and normalization errors) where meaning was preserved. Furthermore, BERTScore was a better fit of error assessment than WER, as measured using an ordinal logistic regression and the Akaike's Information Criterion (AIC). Overall, our findings suggest that BERTScore can complement WER when assessing ASR model performance from a practical perspective, especially for accessibility applications where models are useful even at lower accuracy than for typical speech.
FastCorrect: Fast Error Correction with Edit Alignment for Automatic Speech Recognition
May 09, 2021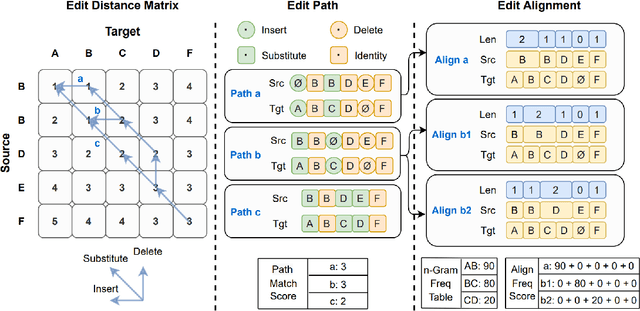
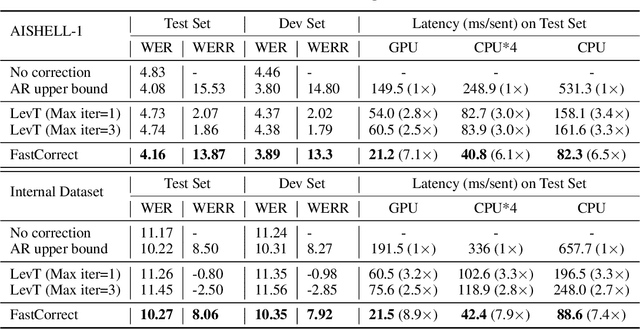
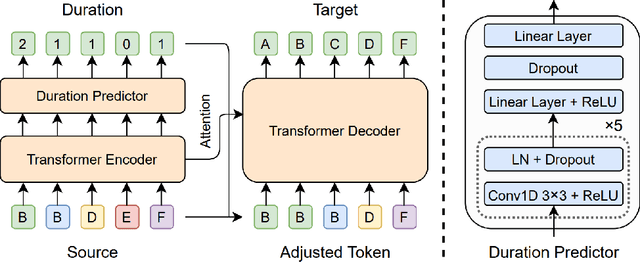
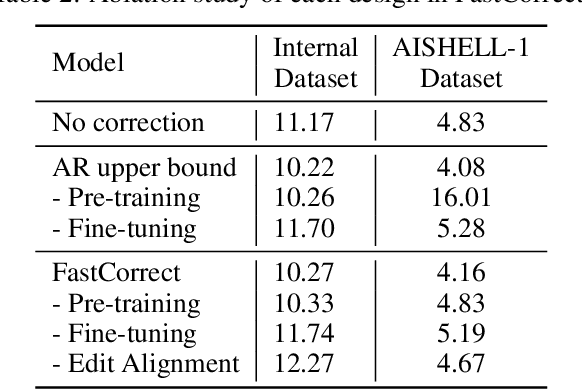
Error correction techniques have been used to refine the output sentences from automatic speech recognition (ASR) models and achieve a lower word error rate (WER) than original ASR outputs. Previous works usually use a sequence-to-sequence model to correct an ASR output sentence autoregressively, which causes large latency and cannot be deployed in online ASR services. A straightforward solution to reduce latency, inspired by non-autoregressive (NAR) neural machine translation, is to use an NAR sequence generation model for ASR error correction, which, however, comes at the cost of significantly increased ASR error rate. In this paper, observing distinctive error patterns and correction operations (i.e., insertion, deletion, and substitution) in ASR, we propose FastCorrect, a novel NAR error correction model based on edit alignment. In training, FastCorrect aligns each source token from an ASR output sentence to the target tokens from the corresponding ground-truth sentence based on the edit distance between the source and target sentences, and extracts the number of target tokens corresponding to each source token during edition/correction, which is then used to train a length predictor and to adjust the source tokens to match the length of the target sentence for parallel generation. In inference, the token number predicted by the length predictor is used to adjust the source tokens for target sequence generation. Experiments on the public AISHELL-1 dataset and an internal industrial-scale ASR dataset show the effectiveness of FastCorrect for ASR error correction: 1) it speeds up the inference by 6-9 times and maintains the accuracy (8-14% WER reduction) compared with the autoregressive correction model; and 2) it outperforms the accuracy of popular NAR models adopted in neural machine translation by a large margin.
Deep Graph Random Process for Relational-Thinking-Based Speech Recognition
Jul 08, 2020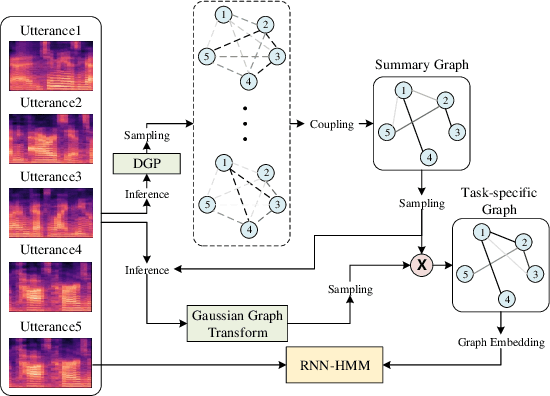
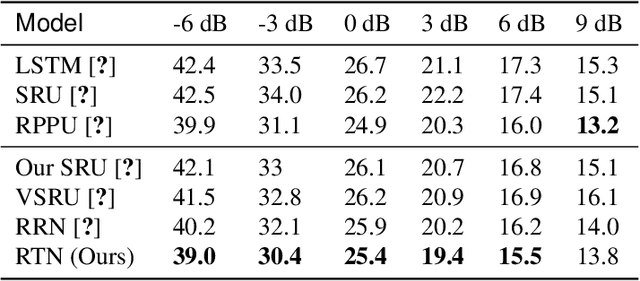

Lying at the core of human intelligence, relational thinking is characterized by initially relying on innumerable unconscious percepts pertaining to relations between new sensory signals and prior knowledge, consequently becoming a recognizable concept or object through coupling and transformation of these percepts. Such mental processes are difficult to model in real-world problems such as in conversational automatic speech recognition (ASR), as the percepts (if they are modelled as graphs indicating relationships among utterances) are supposed to be innumerable and not directly observable. In this paper, we present a Bayesian nonparametric deep learning method called deep graph random process (DGP) that can generate an infinite number of probabilistic graphs representing percepts. We further provide a closed-form solution for coupling and transformation of these percept graphs for acoustic modeling. Our approach is able to successfully infer relations among utterances without using any relational data during training. Experimental evaluations on ASR tasks including CHiME-2 and CHiME-5 demonstrate the effectiveness and benefits of our method.
Non-Autoregressive Transformer Automatic Speech Recognition
Nov 10, 2019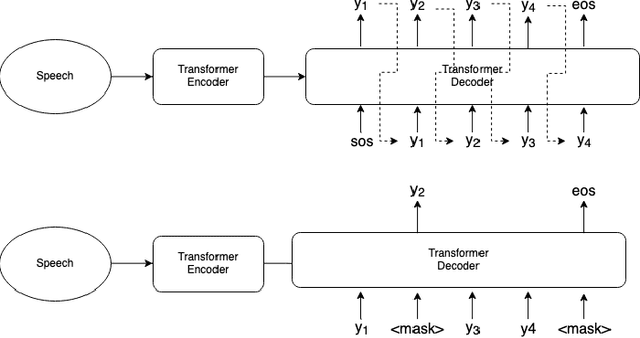
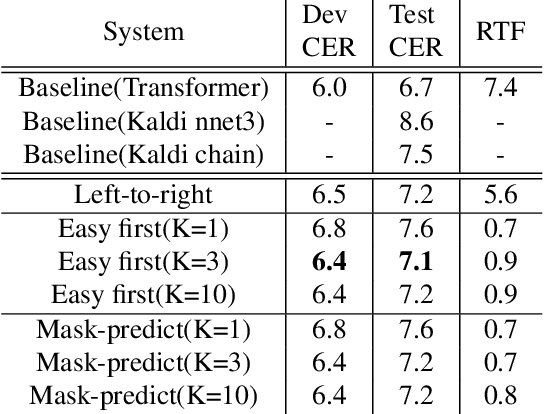
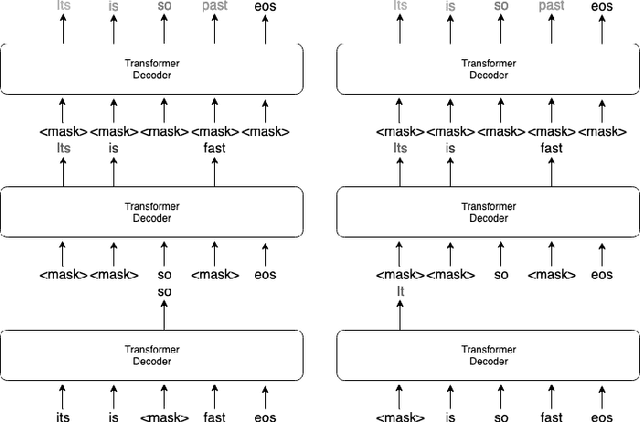
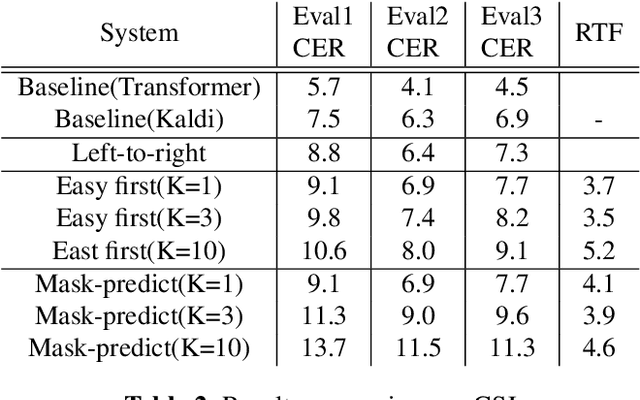
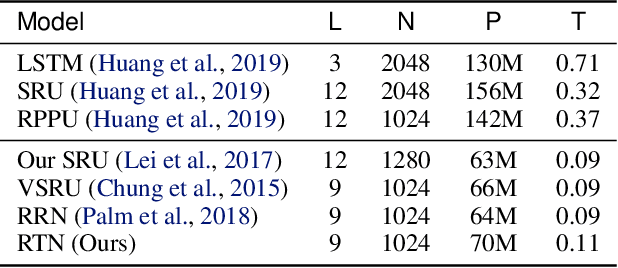
Recently very deep transformers start showing outperformed performance to traditional bi-directional long short-term memory networks by a large margin. However, to put it into production usage, inference computation cost and latency are still serious concerns in real scenarios. In this paper, we study a novel non-autoregressive transformers structure for speech recognition, which is originally introduced in machine translation. During training input tokens fed to the decoder are randomly replaced by a special mask token. The network is required to predict those mask tokens by taking both context and input speech into consideration. During inference, we start from all mask tokens and the network gradually predicts all tokens based on partial results. We show this framework can support different decoding strategies, including traditional left-to-right. A new decoding strategy is proposed as an example, which starts from the easiest predictions to difficult ones. Some preliminary results on Aishell and CSJ benchmarks show the possibility to train such a non-autoregressive network for ASR. Especially in Aishell, the proposed method outperformed Kaldi nnet3 and chain model setup and is quite closed to the performance of the start-of-the-art end-to-end model.
Voice Conversion Can Improve ASR in Very Low-Resource Settings
Nov 04, 2021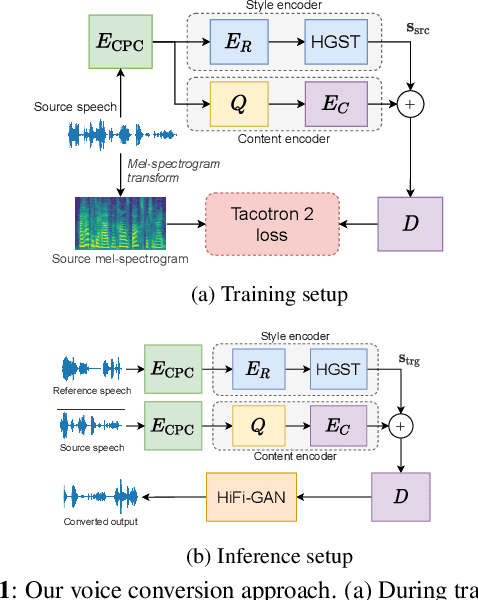
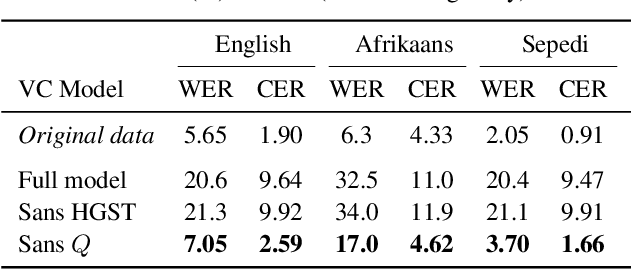
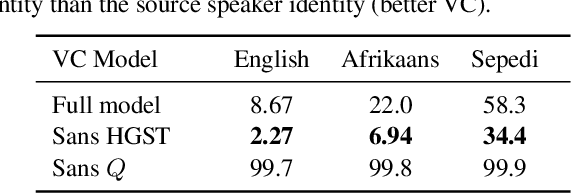

Voice conversion (VC) has been proposed to improve speech recognition systems in low-resource languages by using it to augment limited training data. But until recently, practical issues such as compute speed have limited the use of VC for this purpose. Moreover, it is still unclear whether a VC model trained on one well-resourced language can be applied to speech from another low-resource language for the purpose of data augmentation. In this work we assess whether a VC system can be used cross-lingually to improve low-resource speech recognition. Concretely, we combine several recent techniques to design and train a practical VC system in English, and then use this system to augment data for training a speech recognition model in several low-resource languages. We find that when using a sensible amount of augmented data, speech recognition performance is improved in all four low-resource languages considered.
Compact Graph Architecture for Speech Emotion Recognition
Aug 06, 2020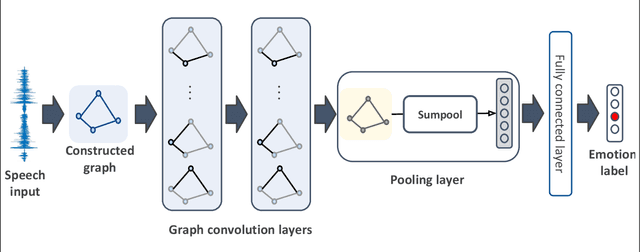
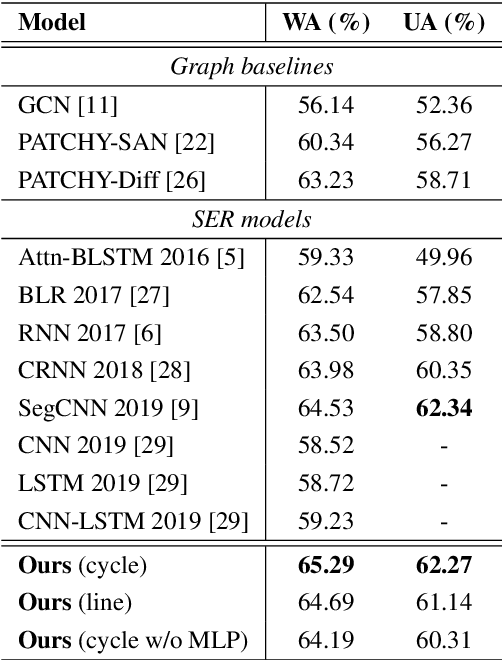
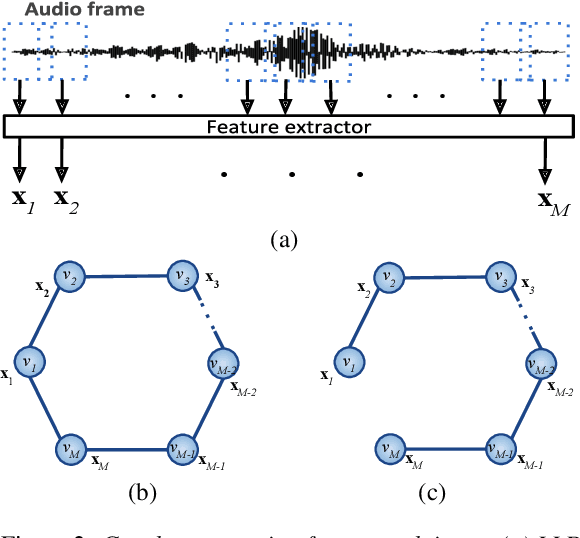

We propose a deep graph approach to address the task of speech emotion recognition. A compact, efficient and scalable way to represent data is in the form of graphs. Following the theory of graph signal processing, we propose to model speech signal as a cycle graph or a line graph. Such graph structure enables us to construct a graph convolution network (GCN)-based architecture that can perform an \emph{accurate} graph convolution in contrast to the approximate convolution used in standard GCNs. We evaluated the performance of our model for speech emotion recognition on the popular IEMOCAP database. Our model outperforms standard GCN and other relevant deep graph architectures indicating the effectiveness of our approach. When compared with existing speech emotion recognition methods, our model achieves state-of-the-art performance (4-class, $65.29\%$) with significantly fewer learnable parameters.
Minimal Feature Analysis for Isolated Digit Recognition for varying encoding rates in noisy environments
Aug 27, 2022
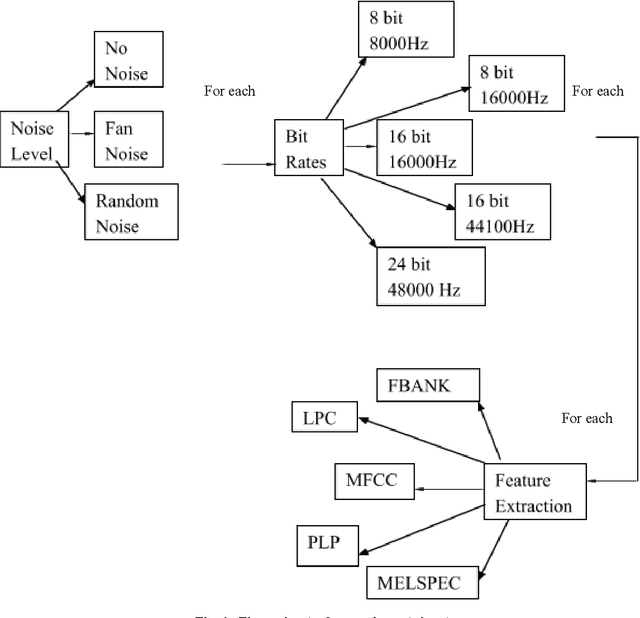
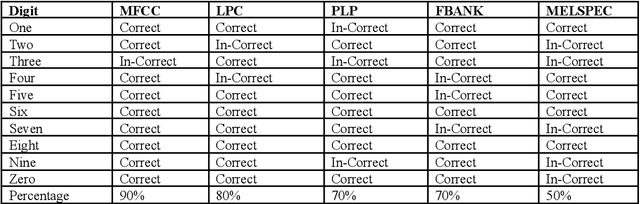
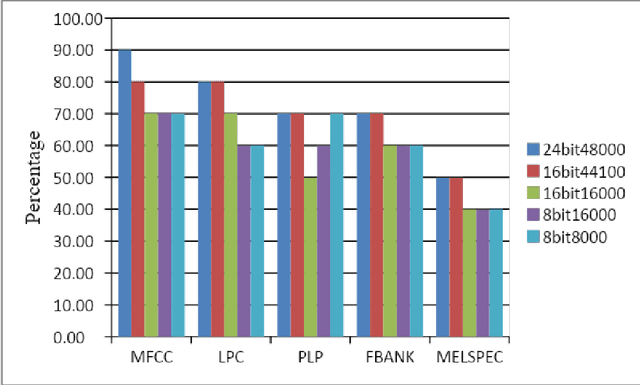
This research work is about recent development made in speech recognition. In this research work, analysis of isolated digit recognition in the presence of different bit rates and at different noise levels has been performed. This research work has been carried using audacity and HTK toolkit. Hidden Markov Model (HMM) is the recognition model which was used to perform this experiment. The feature extraction techniques used are Mel Frequency Cepstrum coefficient (MFCC), Linear Predictive Coding (LPC), perceptual linear predictive (PLP), mel spectrum (MELSPEC), filter bank (FBANK). There were three types of different noise levels which have been considered for testing of data. These include random noise, fan noise and random noise in real time environment. This was done to analyse the best environment which can used for real time applications. Further, five different types of commonly used bit rates at different sampling rates were considered to find out the most optimum bit rate.
Generalizing in the Real World with Representation Learning
Oct 18, 2022
Machine learning (ML) formalizes the problem of getting computers to learn from experience as optimization of performance according to some metric(s) on a set of data examples. This is in contrast to requiring behaviour specified in advance (e.g. by hard-coded rules). Formalization of this problem has enabled great progress in many applications with large real-world impact, including translation, speech recognition, self-driving cars, and drug discovery. But practical instantiations of this formalism make many assumptions - for example, that data are i.i.d.: independent and identically distributed - whose soundness is seldom investigated. And in making great progress in such a short time, the field has developed many norms and ad-hoc standards, focused on a relatively small range of problem settings. As applications of ML, particularly in artificial intelligence (AI) systems, become more pervasive in the real world, we need to critically examine these assumptions, norms, and problem settings, as well as the methods that have become de-facto standards. There is much we still do not understand about how and why deep networks trained with stochastic gradient descent are able to generalize as well as they do, why they fail when they do, and how they will perform on out-of-distribution data. In this thesis I cover some of my work towards better understanding deep net generalization, identify several ways assumptions and problem settings fail to generalize to the real world, and propose ways to address those failures in practice.