 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
End-to-End Code Switching Language Models for Automatic Speech Recognition
Jun 16, 2020




In this paper, we particularly work on the code-switched text, one of the most common occurrences in the bilingual communities across the world. Due to the discrepancies in the extraction of code-switched text from an Automated Speech Recognition(ASR) module, and thereby extracting the monolingual text from the code-switched text, we propose an approach for extracting monolingual text using Deep Bi-directional Language Models(LM) such as BERT and other Machine Translation models, and also explore different ways of extracting code-switched text from the ASR model. We also explain the robustness of the model by comparing the results of Perplexity and other different metrics like WER, to the standard bi-lingual text output without any external information.
Raw Waveform Encoder with Multi-Scale Globally Attentive Locally Recurrent Networks for End-to-End Speech Recognition
Jun 08, 2021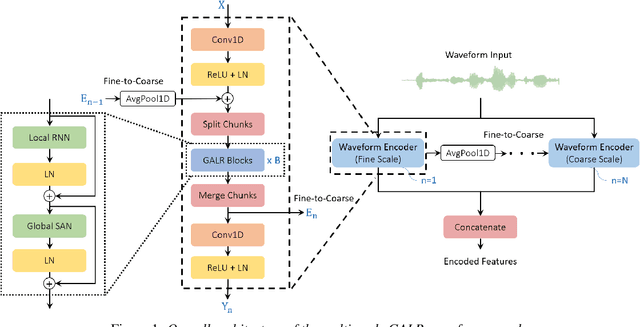
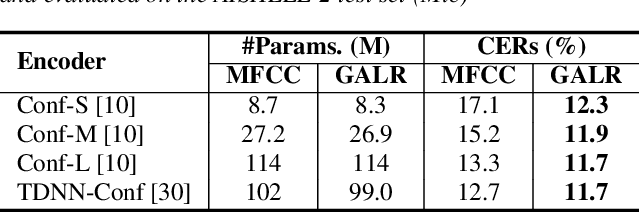
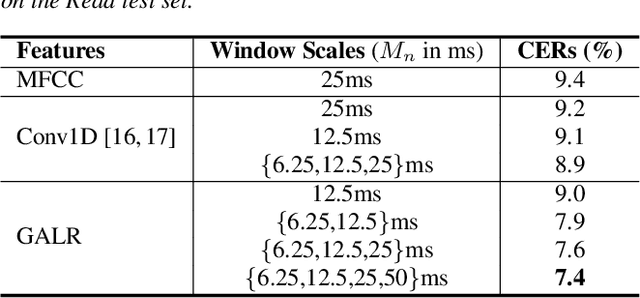
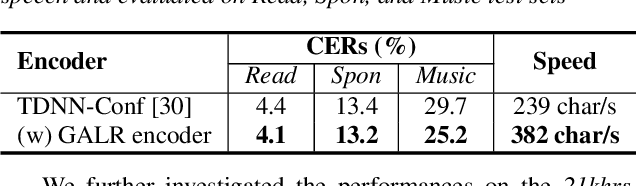
End-to-end speech recognition generally uses hand-engineered acoustic features as input and excludes the feature extraction module from its joint optimization. To extract learnable and adaptive features and mitigate information loss, we propose a new encoder that adopts globally attentive locally recurrent (GALR) networks and directly takes raw waveform as input. We observe improved ASR performance and robustness by applying GALR on different window lengths to aggregate fine-grain temporal information into multi-scale acoustic features. Experiments are conducted on a benchmark dataset AISHELL-2 and two large-scale Mandarin speech corpus of 5,000 hours and 21,000 hours. With faster speed and comparable model size, our proposed multi-scale GALR waveform encoder achieved consistent character error rate reductions (CERRs) from 7.9% to 28.1% relative over strong baselines, including Conformer and TDNN-Conformer. In particular, our approach demonstrated notable robustness than the traditional handcrafted features and outperformed the baseline MFCC-based TDNN-Conformer model by a 15.2% CERR on a music-mixed real-world speech test set.
Comparing the Benefit of Synthetic Training Data for Various Automatic Speech Recognition Architectures
Apr 12, 2021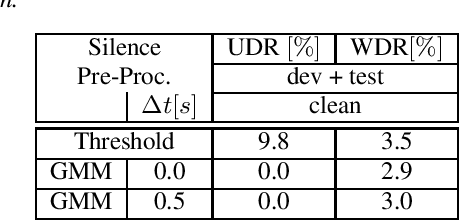
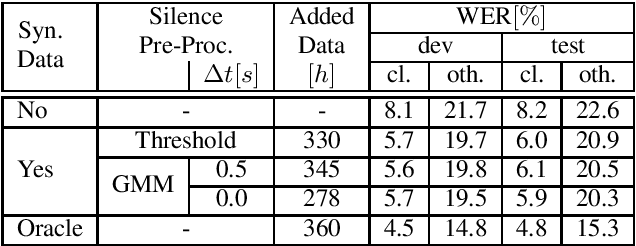
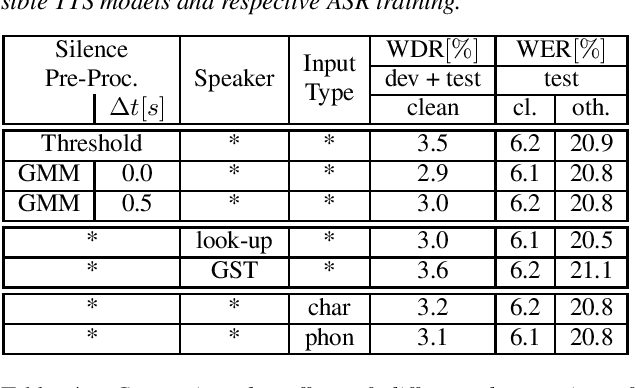
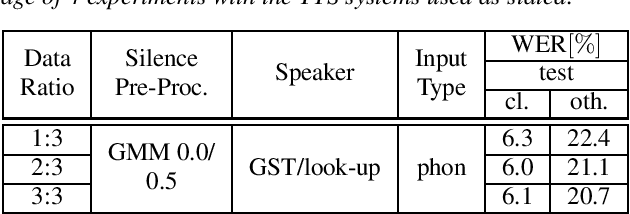
Recent publications on automatic-speech-recognition (ASR) have a strong focus on attention encoder-decoder (AED) architectures which work well for large datasets, but tend to overfit when applied in low resource scenarios. One solution to tackle this issue is to generate synthetic data with a trained text-to-speech system (TTS) if additional text is available. This was successfully applied in many publications with AED systems. We present a novel approach of silence correction in the data pre-processing for TTS systems which increases the robustness when training on corpora targeted for ASR applications. In this work we do not only show the successful application of synthetic data for AED systems, but also test the same method on a highly optimized state-of-the-art Hybrid ASR system and a competitive monophone based system using connectionist-temporal-classification (CTC). We show that for the later systems the addition of synthetic data only has a minor effect, but they still outperform the AED systems by a large margin on LibriSpeech-100h. We achieve a final word-error-rate of 3.3%/10.0% with a Hybrid system on the clean/noisy test-sets, surpassing any previous state-of-the-art systems that do not include unlabeled audio data.
Attention-based Transducer for Online Speech Recognition
May 18, 2020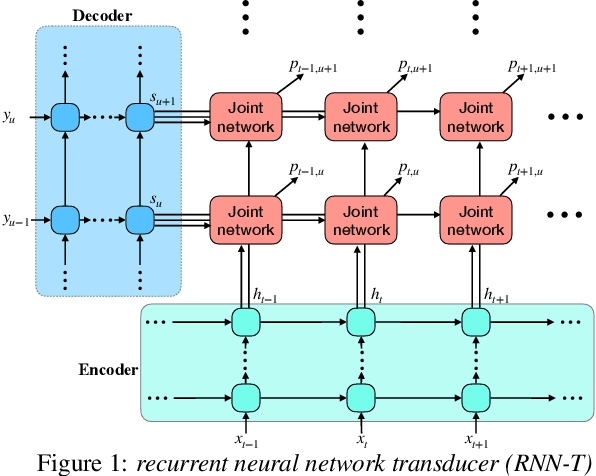
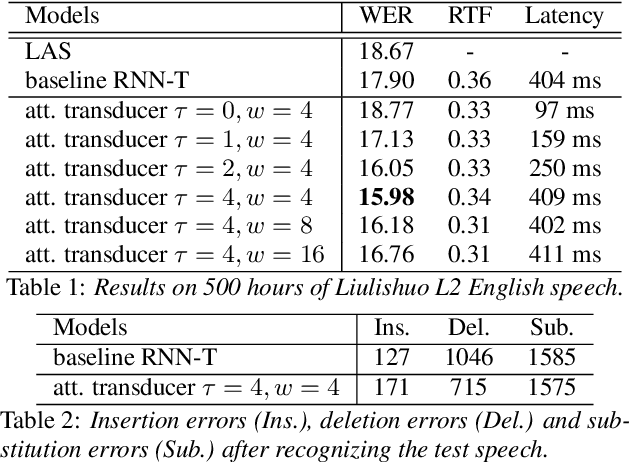
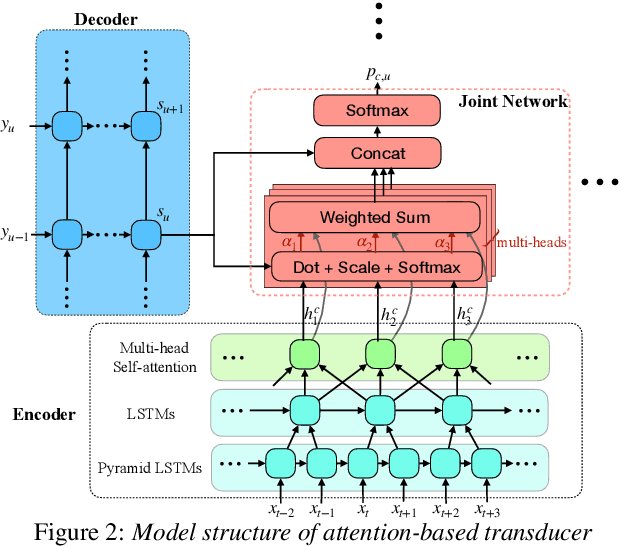
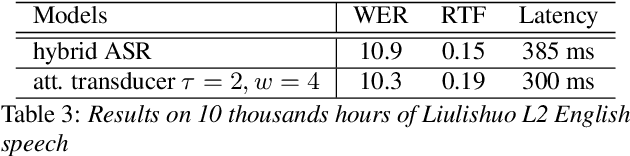
Recent studies reveal the potential of recurrent neural network transducer (RNN-T) for end-to-end (E2E) speech recognition. Among some most popular E2E systems including RNN-T, Attention Encoder-Decoder (AED), and Connectionist Temporal Classification (CTC), RNN-T has some clear advantages given that it supports streaming recognition and does not have frame-independency assumption. Although significant progresses have been made for RNN-T research, it is still facing performance challenges in terms of training speed and accuracy. We propose attention-based transducer with modification over RNN-T in two aspects. First, we introduce chunk-wise attention in the joint network. Second, self-attention is introduced in the encoder. Our proposed model outperforms RNN-T for both training speed and accuracy. For training, we achieves over 1.7x speedup. With 500 hours LAIX non-native English training data, attention-based transducer yields ~10.6% WER reduction over baseline RNN-T. Trained with full set of over 10K hours data, our final system achieves ~5.5% WER reduction over that trained with the best Kaldi TDNN-f recipe. After 8-bit weight quantization without WER degradation, RTF and latency drop to 0.34~0.36 and 268~409 milliseconds respectively on a single CPU core of a production server.
A Policy-based Approach to the SpecAugment Method for Low Resource E2E ASR
Oct 16, 2022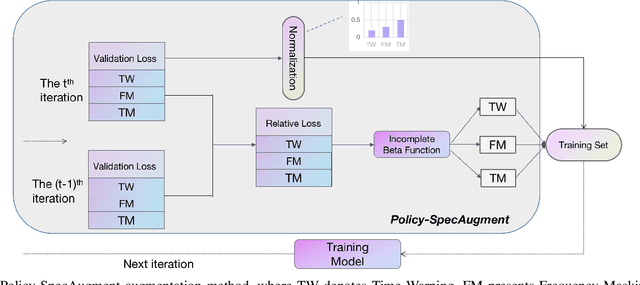
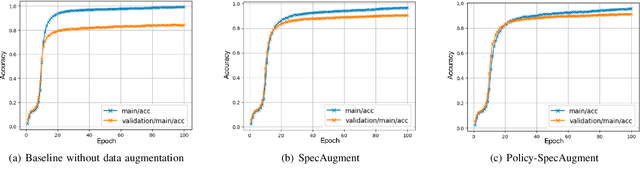
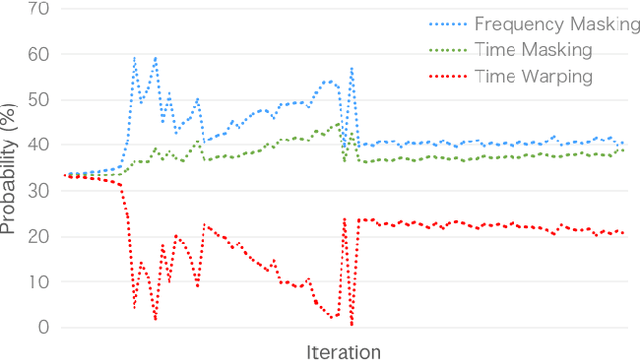
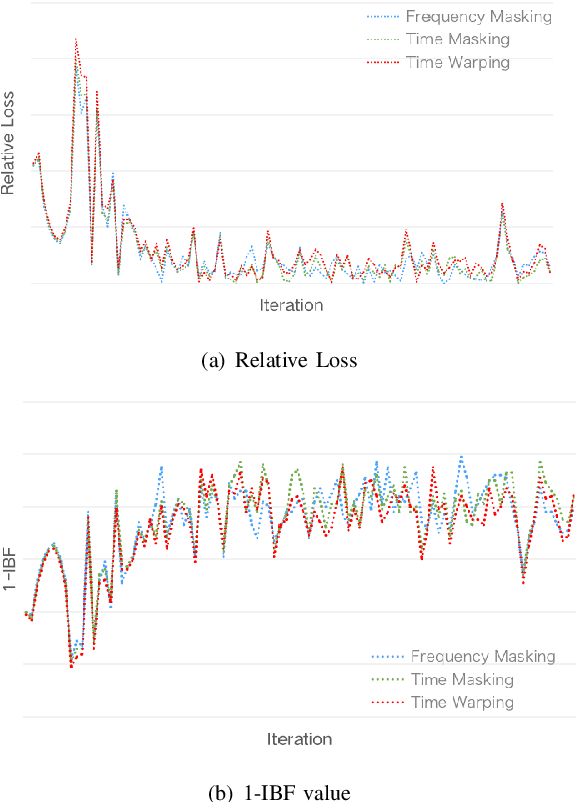
SpecAugment is a very effective data augmentation method for both HMM and E2E-based automatic speech recognition (ASR) systems. Especially, it also works in low-resource scenarios. However, SpecAugment masks the spectrum of time or the frequency domain in a fixed augmentation policy, which may bring relatively less data diversity to the low-resource ASR. In this paper, we propose a policy-based SpecAugment (Policy-SpecAugment) method to alleviate the above problem. The idea is to use the augmentation-select policy and the augmentation-parameter changing policy to solve the fixed way. These policies are learned based on the loss of validation set, which is applied to the corresponding augmentation policies. It aims to encourage the model to learn more diverse data, which the model relatively requires. In experiments, we evaluate the effectiveness of our approach in low-resource scenarios, i.e., the 100 hours librispeech task. According to the results and analysis, we can see that the above issue can be obviously alleviated using our proposal. In addition, the experimental results show that, compared with the state-of-the-art SpecAugment, the proposed Policy-SpecAugment has a relative WER reduction of more than 10% on the Test/Dev-clean set, more than 5% on the Test/Dev-other set, and an absolute WER reduction of more than 1% on all test sets.
Multi-head Monotonic Chunkwise Attention For Online Speech Recognition
May 01, 2020
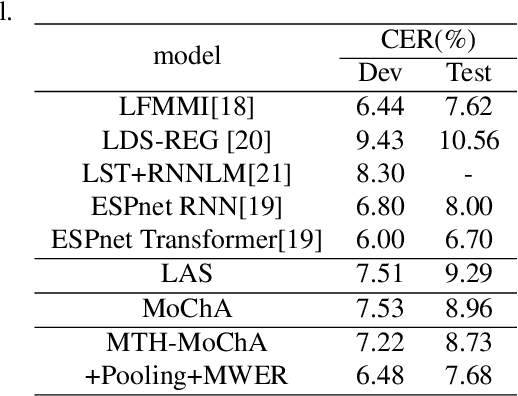
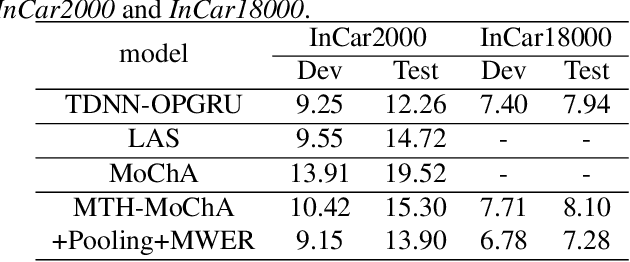
The attention mechanism of the Listen, Attend and Spell (LAS) model requires the whole input sequence to calculate the attention context and thus is not suitable for online speech recognition. To deal with this problem, we propose multi-head monotonic chunk-wise attention (MTH-MoChA), an improved version of MoChA. MTH-MoChA splits the input sequence into small chunks and computes multi-head attentions over the chunks. We also explore useful training strategies such as LSTM pooling, minimum world error rate training and SpecAugment to further improve the performance of MTH-MoChA. Experiments on AISHELL-1 data show that the proposed model, along with the training strategies, improve the character error rate (CER) of MoChA from 8.96% to 7.68% on test set. On another 18000 hours in-car speech data set, MTH-MoChA obtains 7.28% CER, which is significantly better than a state-of-the-art hybrid system.
Internal Language Model Training for Domain-Adaptive End-to-End Speech Recognition
Feb 02, 2021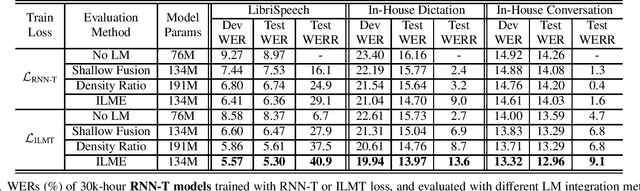
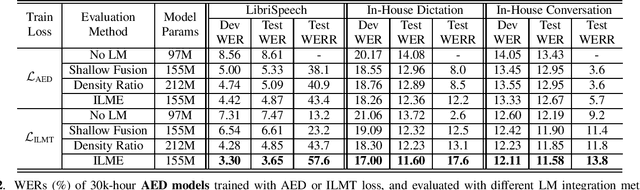
The efficacy of external language model (LM) integration with existing end-to-end (E2E) automatic speech recognition (ASR) systems can be improved significantly using the internal language model estimation (ILME) method. In this method, the internal LM score is subtracted from the score obtained by interpolating the E2E score with the external LM score, during inference. To improve the ILME-based inference, we propose an internal LM training (ILMT) method to minimize an additional internal LM loss by updating only the E2E model components that affect the internal LM estimation. ILMT encourages the E2E model to form a standalone LM inside its existing components, without sacrificing ASR accuracy. After ILMT, the more modular E2E model with matched training and inference criteria enables a more thorough elimination of the source-domain internal LM, and therefore leads to a more effective integration of the target-domain external LM. Experimented with 30K-hour trained recurrent neural network transducer and attention-based encoder-decoder models, ILMT with ILME-based inference achieves up to 31.5% and 11.4% relative word error rate reductions from standard E2E training with Shallow Fusion on out-of-domain LibriSpeech and in-domain Microsoft production test sets, respectively.
* 5 pages, ICASSP 2021
Reducing Geographic Disparities in Automatic Speech Recognition via Elastic Weight Consolidation
Jul 16, 2022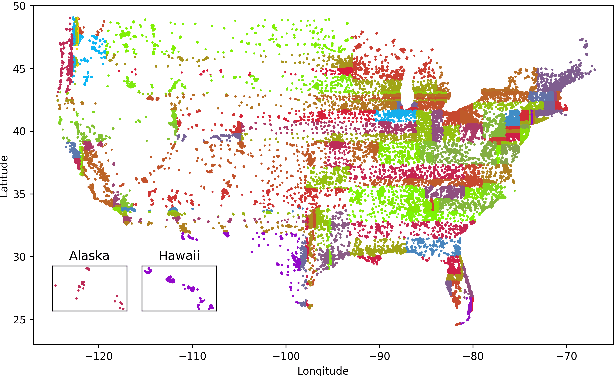

We present an approach to reduce the performance disparity between geographic regions without degrading performance on the overall user population for ASR. A popular approach is to fine-tune the model with data from regions where the ASR model has a higher word error rate (WER). However, when the ASR model is adapted to get better performance on these high-WER regions, its parameters wander from the previous optimal values, which can lead to worse performance in other regions. In our proposed method, we utilize the elastic weight consolidation (EWC) regularization loss to identify directions in parameters space along which the ASR weights can vary to improve for high-error regions, while still maintaining performance on the speaker population overall. Our results demonstrate that EWC can reduce the word error rate (WER) in the region with highest WER by 3.2% relative while reducing the overall WER by 1.3% relative. We also evaluate the role of language and acoustic models in ASR fairness and propose a clustering algorithm to identify WER disparities based on geographic region.
AISHELL-NER: Named Entity Recognition from Chinese Speech
Feb 17, 2022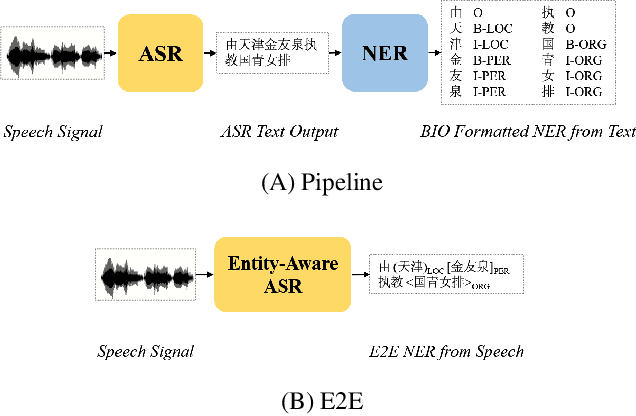
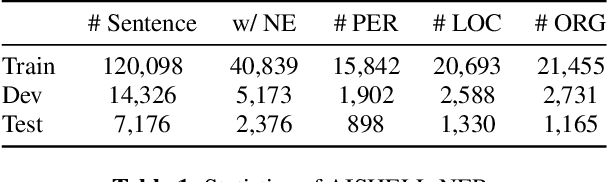
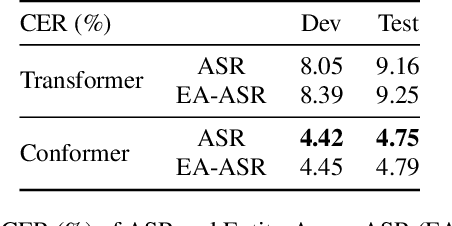
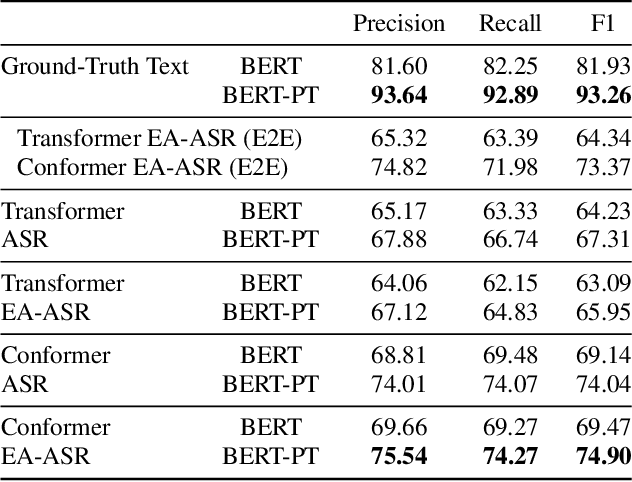
Named Entity Recognition (NER) from speech is among Spoken Language Understanding (SLU) tasks, aiming to extract semantic information from the speech signal. NER from speech is usually made through a two-step pipeline that consists of (1) processing the audio using an Automatic Speech Recognition (ASR) system and (2) applying an NER tagger to the ASR outputs. Recent works have shown the capability of the End-to-End (E2E) approach for NER from English and French speech, which is essentially entity-aware ASR. However, due to the many homophones and polyphones that exist in Chinese, NER from Chinese speech is effectively a more challenging task. In this paper, we introduce a new dataset AISEHLL-NER for NER from Chinese speech. Extensive experiments are conducted to explore the performance of several state-of-the-art methods. The results demonstrate that the performance could be improved by combining entity-aware ASR and pretrained NER tagger, which can be easily applied to the modern SLU pipeline. The dataset is publicly available at github.com/Alibaba-NLP/AISHELL-NER.
ESSumm: Extractive Speech Summarization from Untranscribed Meeting
Sep 14, 2022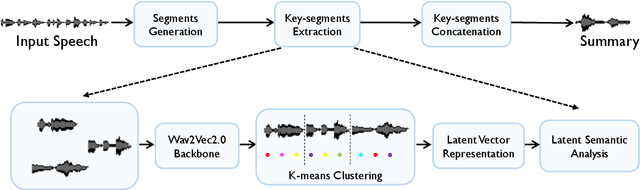
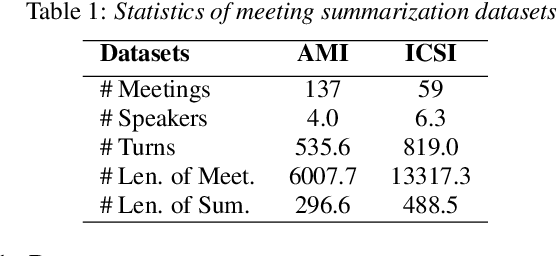

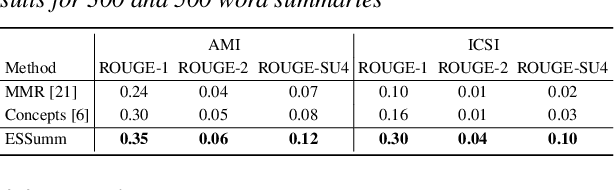
In this paper, we propose a novel architecture for direct extractive speech-to-speech summarization, ESSumm, which is an unsupervised model without dependence on intermediate transcribed text. Different from previous methods with text presentation, we are aimed at generating a summary directly from speech without transcription. First, a set of smaller speech segments are extracted based on speech signal's acoustic features. For each candidate speech segment, a distance-based summarization confidence score is designed for latent speech representation measure. Specifically, we leverage the off-the-shelf self-supervised convolutional neural network to extract the deep speech features from raw audio. Our approach automatically predicts the optimal sequence of speech segments that capture the key information with a target summary length. Extensive results on two well-known meeting datasets (AMI and ICSI corpora) show the effectiveness of our direct speech-based method to improve the summarization quality with untranscribed data. We also observe that our unsupervised speech-based method even performs on par with recent transcript-based summarization approaches, where extra speech recognition is required.