 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
FastCorrect: Fast Error Correction with Edit Alignment for Automatic Speech Recognition
Jun 03, 2021
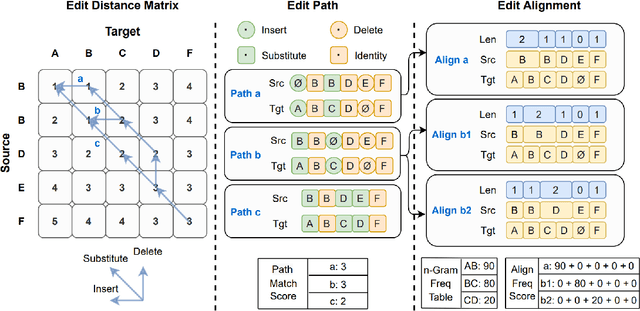
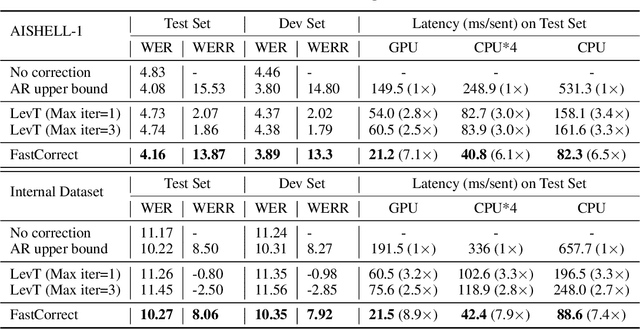
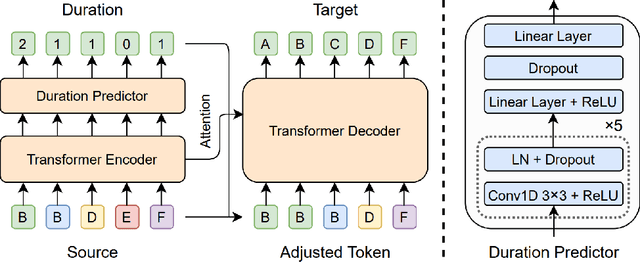
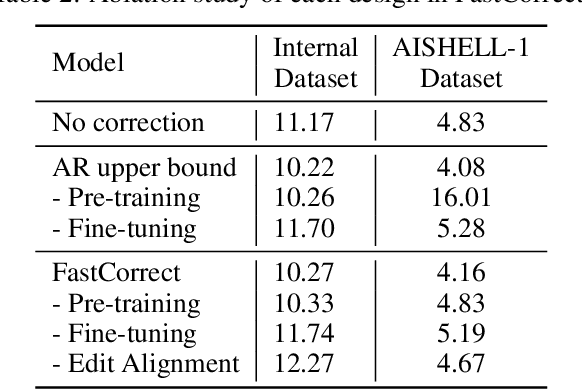
Error correction techniques have been used to refine the output sentences from automatic speech recognition (ASR) models and achieve a lower word error rate (WER) than original ASR outputs. Previous works usually use a sequence-to-sequence model to correct an ASR output sentence autoregressively, which causes large latency and cannot be deployed in online ASR services. A straightforward solution to reduce latency, inspired by non-autoregressive (NAR) neural machine translation, is to use an NAR sequence generation model for ASR error correction, which, however, comes at the cost of significantly increased ASR error rate. In this paper, observing distinctive error patterns and correction operations (i.e., insertion, deletion, and substitution) in ASR, we propose FastCorrect, a novel NAR error correction model based on edit alignment. In training, FastCorrect aligns each source token from an ASR output sentence to the target tokens from the corresponding ground-truth sentence based on the edit distance between the source and target sentences, and extracts the number of target tokens corresponding to each source token during edition/correction, which is then used to train a length predictor and to adjust the source tokens to match the length of the target sentence for parallel generation. In inference, the token number predicted by the length predictor is used to adjust the source tokens for target sequence generation. Experiments on the public AISHELL-1 dataset and an internal industrial-scale ASR dataset show the effectiveness of FastCorrect for ASR error correction: 1) it speeds up the inference by 6-9 times and maintains the accuracy (8-14% WER reduction) compared with the autoregressive correction model; and 2) it outperforms the popular NAR models adopted in neural machine translation and text edition by a large margin.
Online Automatic Speech Recognition with Listen, Attend and Spell Model
Aug 12, 2020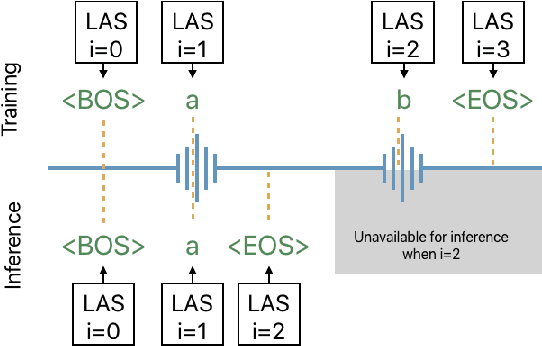
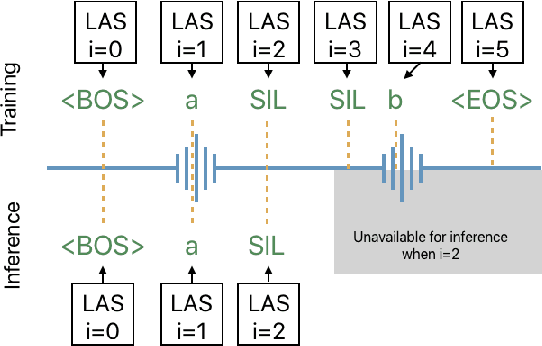
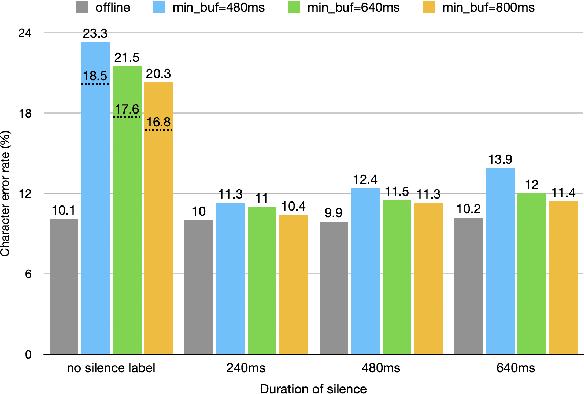
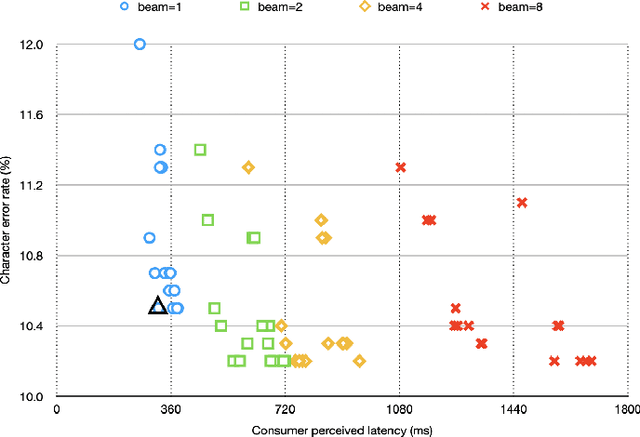
The Listen, Attend and Spell (LAS) model and other attention-based automatic speech recognition (ASR) models have known limitations when operated in a fully online mode. In this paper, we analyze the online operation of LAS models to demonstrate that these limitations stem from the handling of silence regions and the reliability of online attention mechanism at the edge of input buffers. We propose a novel and simple technique that can achieve fully online recognition while meeting accuracy and latency targets. For the Mandarin dictation task, our proposed approach can achieve a character error rate in online operation that is within 4% relative to an offline LAS model. The proposed online LAS model operates at 12% lower latency relative to a conventional neural network hidden Markov model hybrid of comparable accuracy. We have validated the proposed method through a production scale deployment, which, to the best of our knowledge, is the first such deployment of a fully online LAS model.
Multimodal Grounding for Sequence-to-Sequence Speech Recognition
Nov 09, 2018
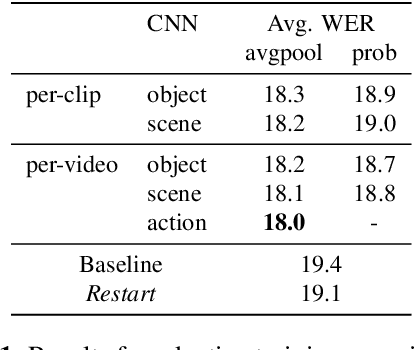
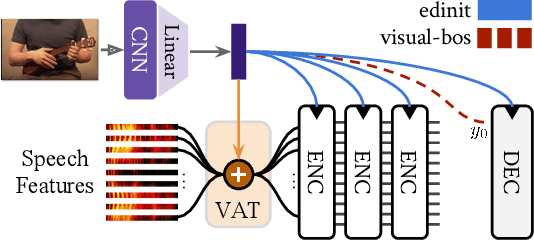
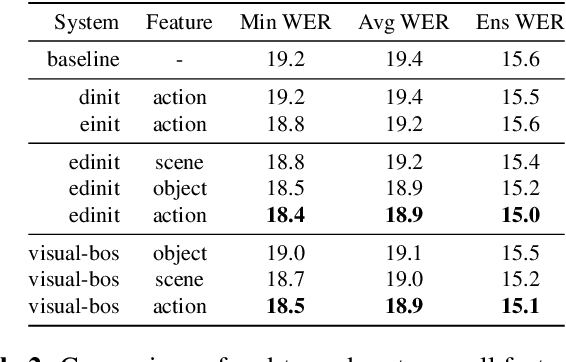
Humans are capable of processing speech by making use of multiple sensory modalities. For example, the environment where a conversation takes place generally provides semantic and/or acoustic context that helps us to resolve ambiguities or to recall named entities. Motivated by this, there have been many works studying the integration of visual information into the speech recognition pipeline. Specifically, in our previous work, we propose a multistep visual adaptive training approach which improves the accuracy of an audio-based Automatic Speech Recognition (ASR) system. This approach, however, is not end-to-end as it requires fine-tuning the whole model with an adaptation layer. In this paper, we propose novel end-to-end multimodal ASR systems and compare them to the adaptive approach by using a range of visual representations obtained from state-of-the-art convolutional neural networks. We show that adaptive training is effective for S2S models leading to an absolute improvement of 1.4% in word error rate. As for the end-to-end systems, although they perform better than baseline, the improvements are slightly less than adaptive training, 0.8 absolute WER reduction in single-best models. Using ensemble decoding, end-to-end models reach a WER of 15% which is the lowest score among all systems.
FullPack: Full Vector Utilization for Sub-Byte Quantized Inference on General Purpose CPUs
Nov 20, 2022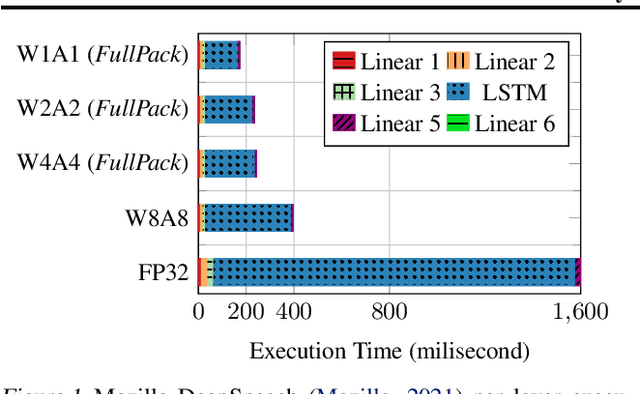
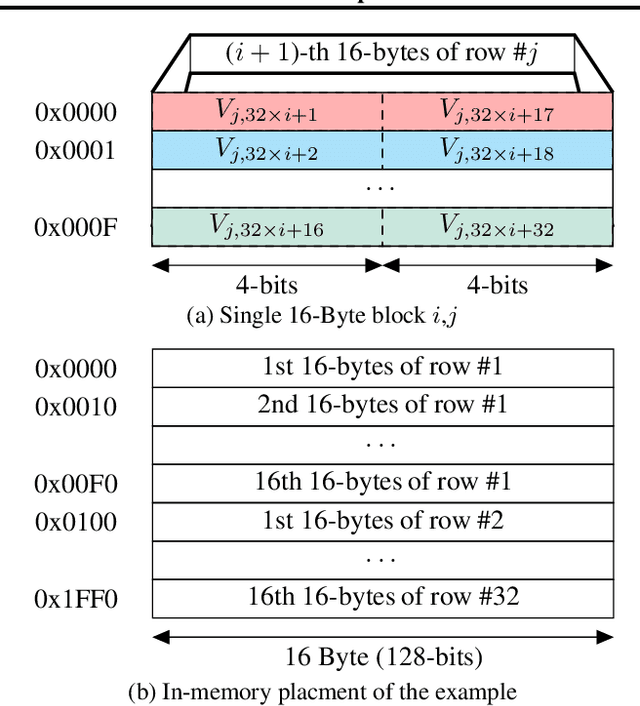

Although prior art has demonstrated negligible accuracy drop in sub-byte quantization -- where weights and/or activations are represented by less than 8 bits -- popular SIMD instructions of CPUs do not natively support these datatypes. While recent methods, such as ULPPACK, are already using sub-byte quantization on general-purpose CPUs with vector units, they leave out several empty bits between the sub-byte values in memory and in vector registers to avoid overflow to the neighbours during the operations. This results in memory footprint and bandwidth-usage inefficiencies and suboptimal performance. In this paper, we present memory layouts for storing, and mechanisms for processing sub-byte (4-, 2-, or 1-bit) models that utilize all the bits in the memory as well as in the vector registers for the actual data. We provide compute kernels for the proposed layout for the GEMV (GEneral Matrix-Vector multiplication) operations between weights and activations of different datatypes (e.g., 8-bit activations and 4-bit weights). For evaluation, we extended the TFLite package and added our methods to it, then ran the models on the cycle-accurate gem5 simulator to compare detailed memory and CPU cycles of each method. We compare against nine other methods that are actively used in production including GEMLOWP, Ruy, XNNPack, and ULPPACK. Furthermore, we explore the effect of different input and output sizes of deep learning layers on the performance of our proposed method. Experimental results show 0.96-2.1x speedup for small sizes and 1.2-6.7x speedup for mid to large sizes. Applying our proposal to a real-world speech recognition model, Mozilla DeepSpeech, we proved that our method achieves 1.56-2.11x end-to-end speedup compared to the state-of-the-art, depending on the bit-width employed.
Two-Staged Acoustic Modeling Adaption for Robust Speech Recognition by the Example of German Oral History Interviews
Aug 19, 2019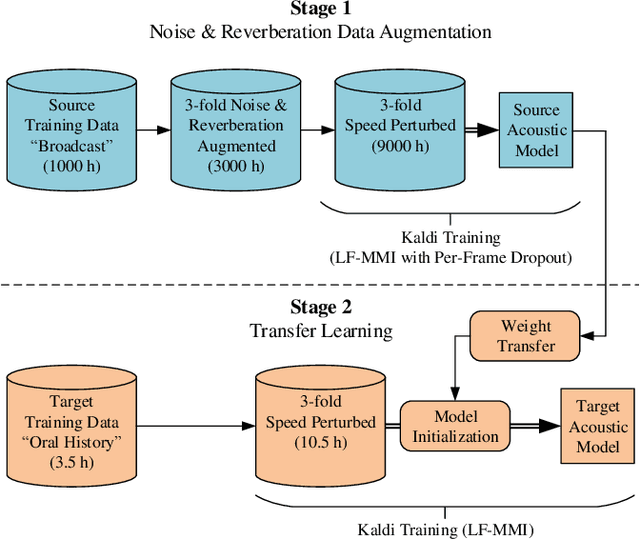


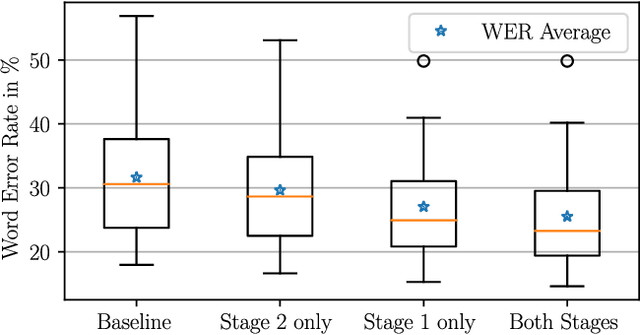
In automatic speech recognition, often little training data is available for specific challenging tasks, but training of state-of-the-art automatic speech recognition systems requires large amounts of annotated speech. To address this issue, we propose a two-staged approach to acoustic modeling that combines noise and reverberation data augmentation with transfer learning to robustly address challenges such as difficult acoustic recording conditions, spontaneous speech, and speech of elderly people. We evaluate our approach using the example of German oral history interviews, where a relative average reduction of the word error rate by 19.3% is achieved.
* Accepted for IEEE International Conference on Multimedia and Expo (ICME), Shanghai, China, July 2019
End-to-End Code Switching Language Models for Automatic Speech Recognition
Jun 16, 2020



In this paper, we particularly work on the code-switched text, one of the most common occurrences in the bilingual communities across the world. Due to the discrepancies in the extraction of code-switched text from an Automated Speech Recognition(ASR) module, and thereby extracting the monolingual text from the code-switched text, we propose an approach for extracting monolingual text using Deep Bi-directional Language Models(LM) such as BERT and other Machine Translation models, and also explore different ways of extracting code-switched text from the ASR model. We also explain the robustness of the model by comparing the results of Perplexity and other different metrics like WER, to the standard bi-lingual text output without any external information.
Multi-channel Opus compression for far-field automatic speech recognition with a fixed bitrate budget
Jun 15, 2021

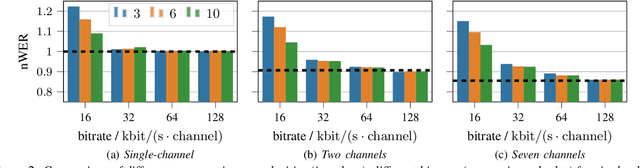
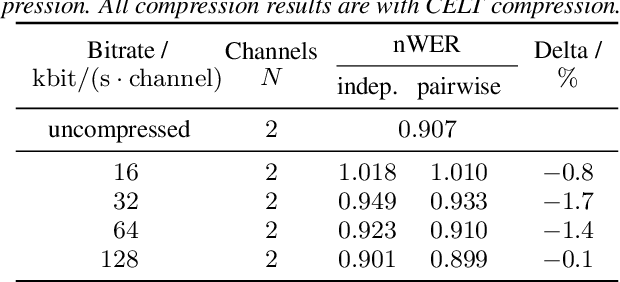
Automatic speech recognition (ASR) in the cloud allows the use of larger models and more powerful multi-channel signal processing front-ends compared to on-device processing. However, it also adds an inherent latency due to the transmission of the audio signal, especially when transmitting multiple channels of a microphone array. One way to reduce the network bandwidth requirements is client-side compression with a lossy codec such as Opus. However, this compression can have a detrimental effect especially on multi-channel ASR front-ends, due to the distortion and loss of spatial information introduced by the codec. In this publication, we propose an improved approach for the compression of microphone array signals based on Opus, using a modified joint channel coding approach and additionally introducing a multi-channel spatial decorrelating transform to reduce redundancy in the transmission. We illustrate the effect of the proposed approach on the spatial information retained in multi-channel signals after compression, and evaluate the performance on far-field ASR with a multi-channel beamforming front-end. We demonstrate that our approach can lead to a 37.5 % bitrate reduction or a 5.1 % relative word error rate reduction for a fixed bitrate budget in a seven channel setup.
Attention-based Transducer for Online Speech Recognition
May 18, 2020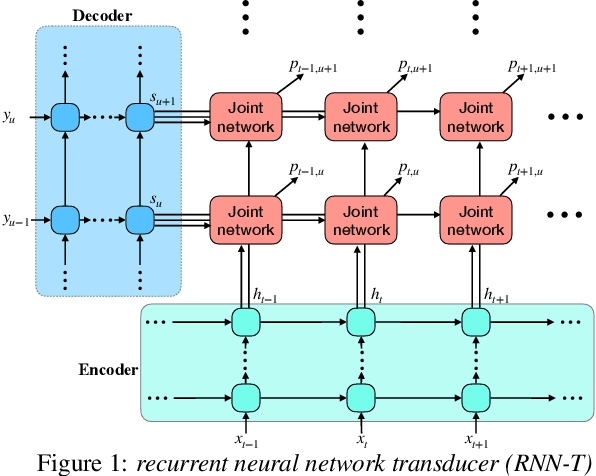
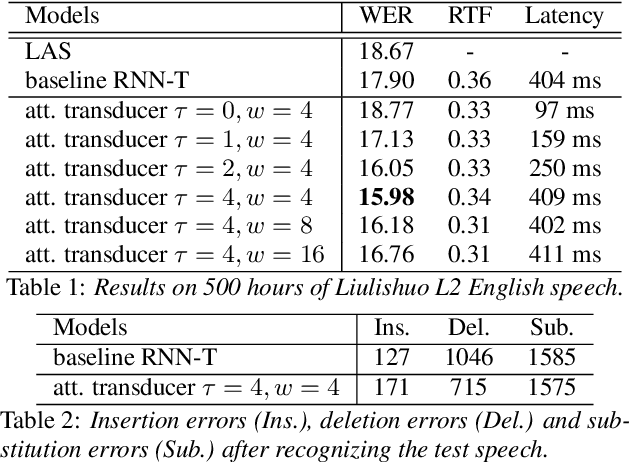
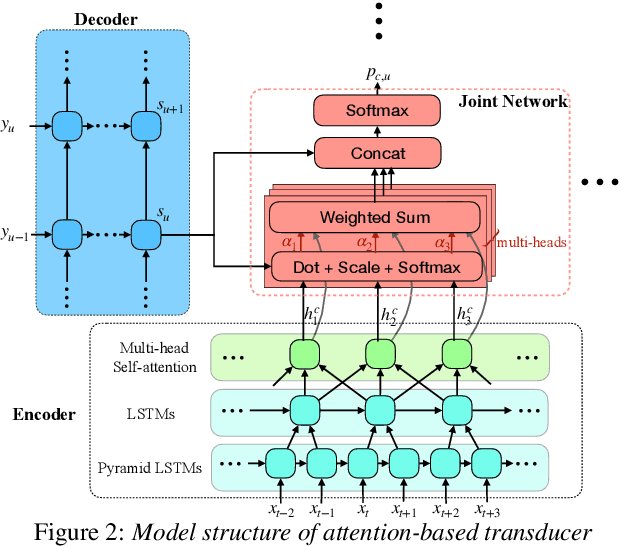
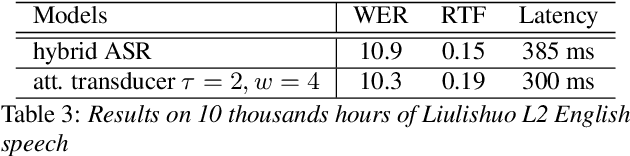
Recent studies reveal the potential of recurrent neural network transducer (RNN-T) for end-to-end (E2E) speech recognition. Among some most popular E2E systems including RNN-T, Attention Encoder-Decoder (AED), and Connectionist Temporal Classification (CTC), RNN-T has some clear advantages given that it supports streaming recognition and does not have frame-independency assumption. Although significant progresses have been made for RNN-T research, it is still facing performance challenges in terms of training speed and accuracy. We propose attention-based transducer with modification over RNN-T in two aspects. First, we introduce chunk-wise attention in the joint network. Second, self-attention is introduced in the encoder. Our proposed model outperforms RNN-T for both training speed and accuracy. For training, we achieves over 1.7x speedup. With 500 hours LAIX non-native English training data, attention-based transducer yields ~10.6% WER reduction over baseline RNN-T. Trained with full set of over 10K hours data, our final system achieves ~5.5% WER reduction over that trained with the best Kaldi TDNN-f recipe. After 8-bit weight quantization without WER degradation, RTF and latency drop to 0.34~0.36 and 268~409 milliseconds respectively on a single CPU core of a production server.
Is Lip Region-of-Interest Sufficient for Lipreading?
May 28, 2022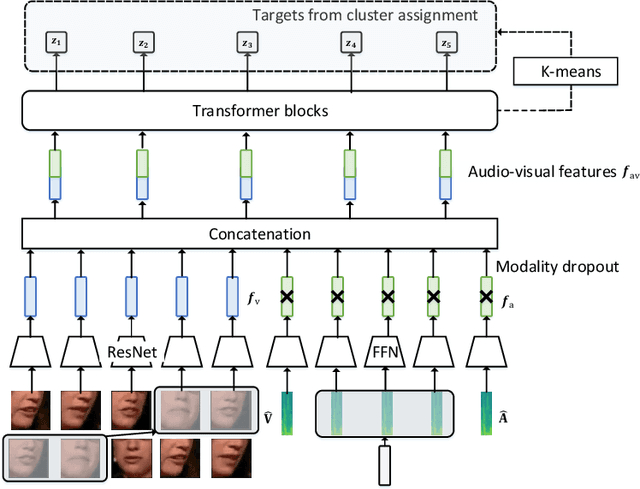
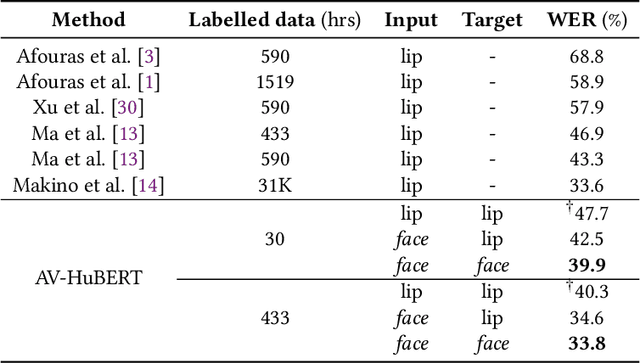

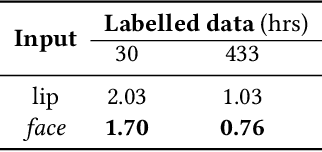
Lip region-of-interest (ROI) is conventionally used for visual input in the lipreading task. Few works have adopted the entire face as visual input because lip-excluded parts of the face are usually considered to be redundant and irrelevant to visual speech recognition. However, faces contain much more detailed information than lips, such as speakers' head pose, emotion, identity etc. We argue that such information might benefit visual speech recognition if a powerful feature extractor employing the entire face is trained. In this work, we propose to adopt the entire face for lipreading with self-supervised learning. AV-HuBERT, an audio-visual multi-modal self-supervised learning framework, was adopted in our experiments. Our experimental results showed that adopting the entire face achieved 16% relative word error rate (WER) reduction on the lipreading task, compared with the baseline method using lip as visual input. Without self-supervised pretraining, the model with face input achieved a higher WER than that using lip input in the case of limited training data (30 hours), while a slightly lower WER when using large amount of training data (433 hours).
Multi-head Monotonic Chunkwise Attention For Online Speech Recognition
May 01, 2020
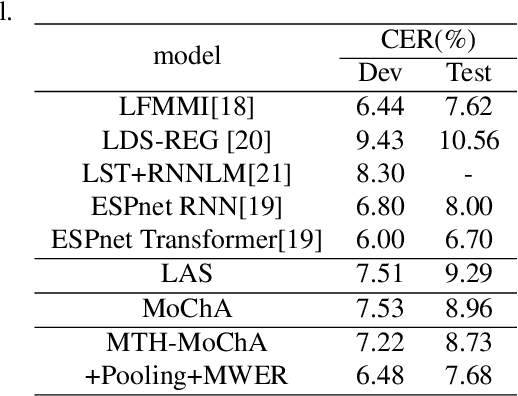
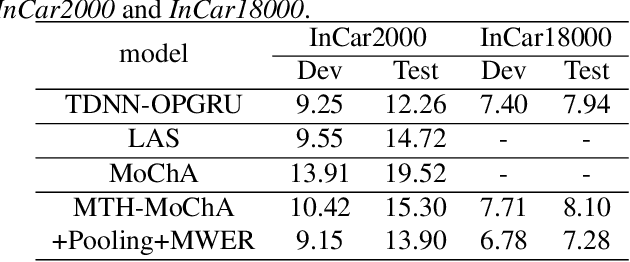
The attention mechanism of the Listen, Attend and Spell (LAS) model requires the whole input sequence to calculate the attention context and thus is not suitable for online speech recognition. To deal with this problem, we propose multi-head monotonic chunk-wise attention (MTH-MoChA), an improved version of MoChA. MTH-MoChA splits the input sequence into small chunks and computes multi-head attentions over the chunks. We also explore useful training strategies such as LSTM pooling, minimum world error rate training and SpecAugment to further improve the performance of MTH-MoChA. Experiments on AISHELL-1 data show that the proposed model, along with the training strategies, improve the character error rate (CER) of MoChA from 8.96% to 7.68% on test set. On another 18000 hours in-car speech data set, MTH-MoChA obtains 7.28% CER, which is significantly better than a state-of-the-art hybrid system.