 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Time-Frequency Localization Using Deep Convolutional Maxout Neural Network in Persian Speech Recognition
Aug 09, 2021
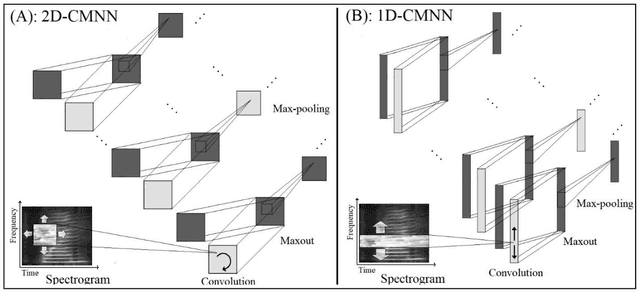
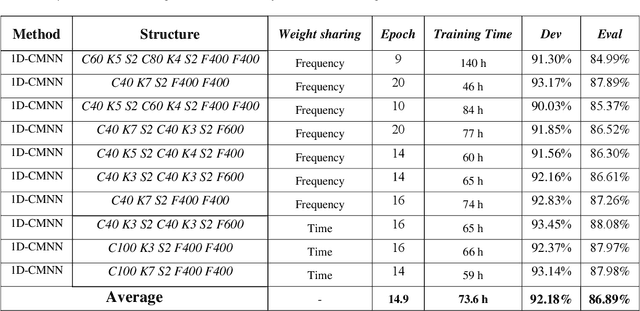
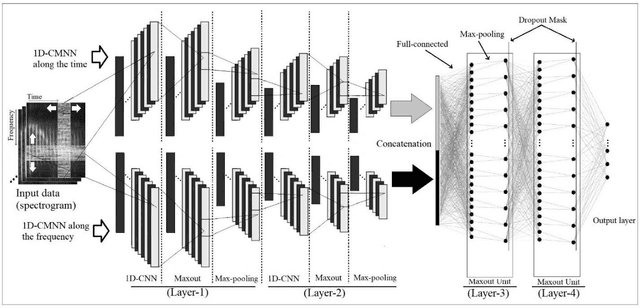
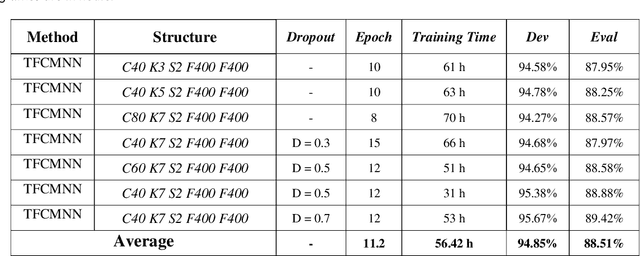
In this paper, a CNN-based structure for time-frequency localization of audio signal information in the ASR acoustic model is proposed for Persian speech recognition. Research has shown that the receptive fields' time-frequency flexibility in some mammals' auditory neurons system improves recognition performance. Biosystems have inspired many artificial systems because of their high efficiency and performance, so time-frequency localization has been used extensively to improve system performance. In the last few years, much work has been done to localize time-frequency information in ASR systems, which has used the spatial immutability properties of methods such as TDNN, CNN and LSTM-RNN. However, most of these models have large parameter volumes and are challenging to train. In the structure we have designed, called Time-Frequency Convolutional Maxout Neural Network (TFCMNN), two parallel blocks consisting of 1D-CMNN each have weight sharing in one dimension, are applied simultaneously but independently to the feature vectors. Then their output is concatenated and applied to a fully connected Maxout network for classification. To improve the performance of this structure, we have used newly developed methods and models such as the maxout, Dropout, and weight normalization. Two experimental sets were designed and implemented on the Persian FARSDAT speech data set to evaluate the performance of this model compared to conventional 1D-CMNN models. According to the experimental results, the average recognition score of TFCMNN models is about 1.6% higher than the average of conventional models. In addition, the average training time of the TFCMNN models is about 17 hours lower than the average training time of traditional models. As a result, as mentioned in other references, time-frequency localization in ASR systems increases system accuracy and speeds up the model training process.
Environmental Noise Embeddings for Robust Speech Recognition
Sep 29, 2016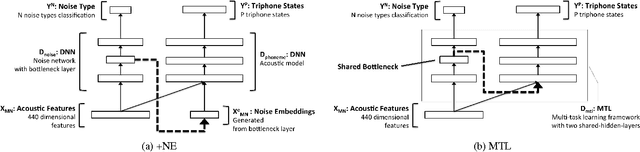
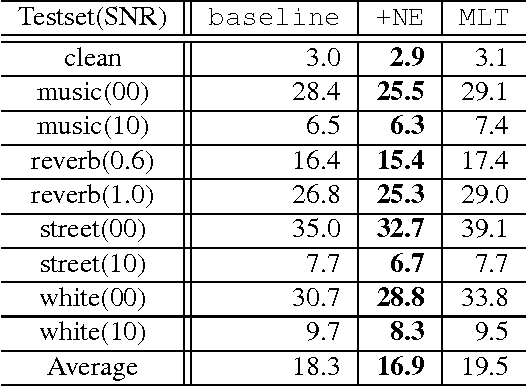
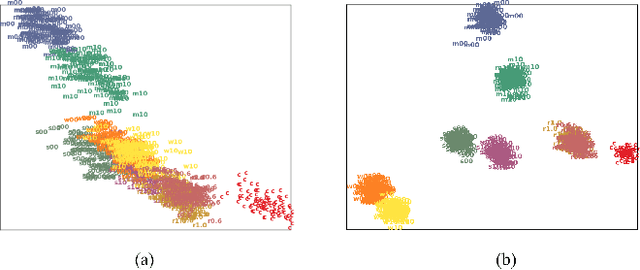
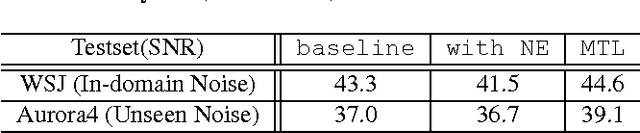
We propose a novel deep neural network architecture for speech recognition that explicitly employs knowledge of the background environmental noise within a deep neural network acoustic model. A deep neural network is used to predict the acoustic environment in which the system in being used. The discriminative embedding generated at the bottleneck layer of this network is then concatenated with traditional acoustic features as input to a deep neural network acoustic model. Through a series of experiments on Resource Management, CHiME-3 task, and Aurora4, we show that the proposed approach significantly improves speech recognition accuracy in noisy and highly reverberant environments, outperforming multi-condition training, noise-aware training, i-vector framework, and multi-task learning on both in-domain noise and unseen noise.
Is Lip Region-of-Interest Sufficient for Lipreading?
May 28, 2022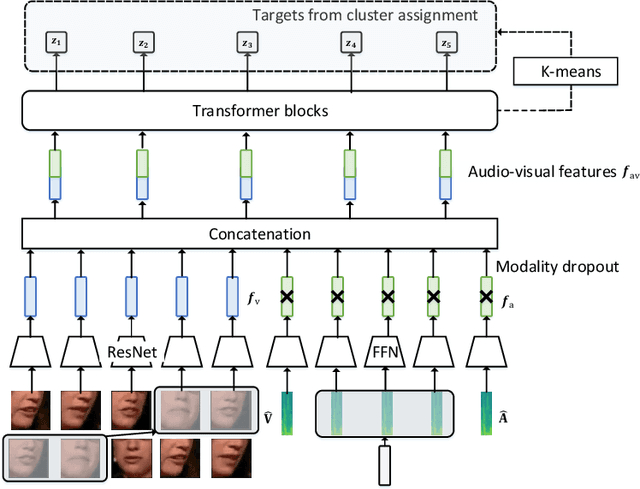
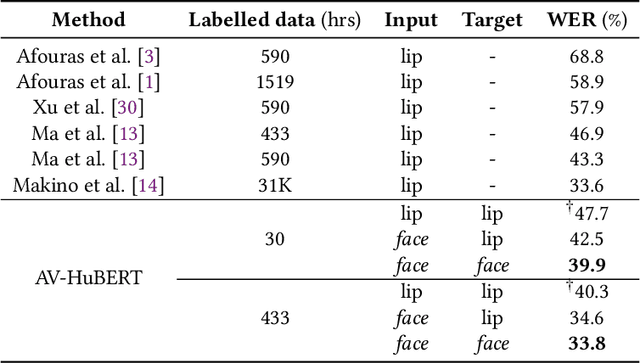

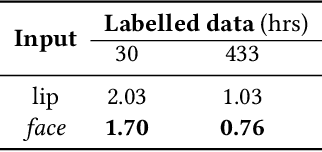
Lip region-of-interest (ROI) is conventionally used for visual input in the lipreading task. Few works have adopted the entire face as visual input because lip-excluded parts of the face are usually considered to be redundant and irrelevant to visual speech recognition. However, faces contain much more detailed information than lips, such as speakers' head pose, emotion, identity etc. We argue that such information might benefit visual speech recognition if a powerful feature extractor employing the entire face is trained. In this work, we propose to adopt the entire face for lipreading with self-supervised learning. AV-HuBERT, an audio-visual multi-modal self-supervised learning framework, was adopted in our experiments. Our experimental results showed that adopting the entire face achieved 16% relative word error rate (WER) reduction on the lipreading task, compared with the baseline method using lip as visual input. Without self-supervised pretraining, the model with face input achieved a higher WER than that using lip input in the case of limited training data (30 hours), while a slightly lower WER when using large amount of training data (433 hours).
A Wavelet Transform Based Scheme to Extract Speech Pitch and Formant Frequencies
Sep 07, 2022
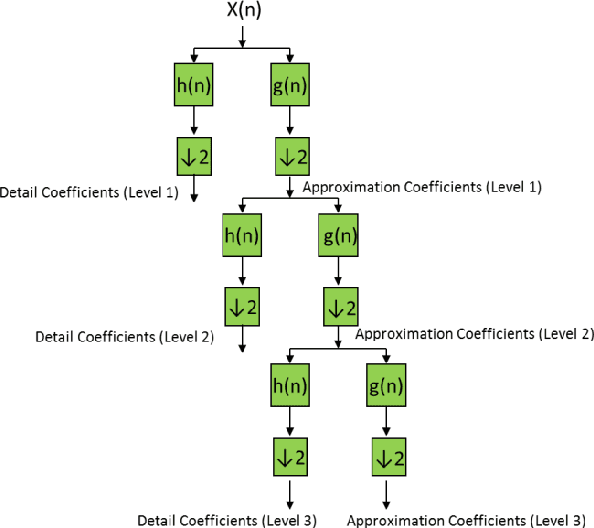
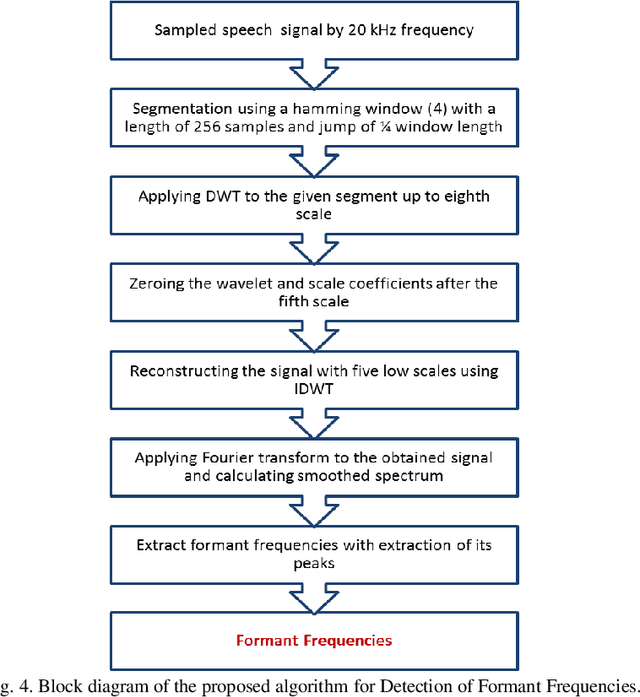
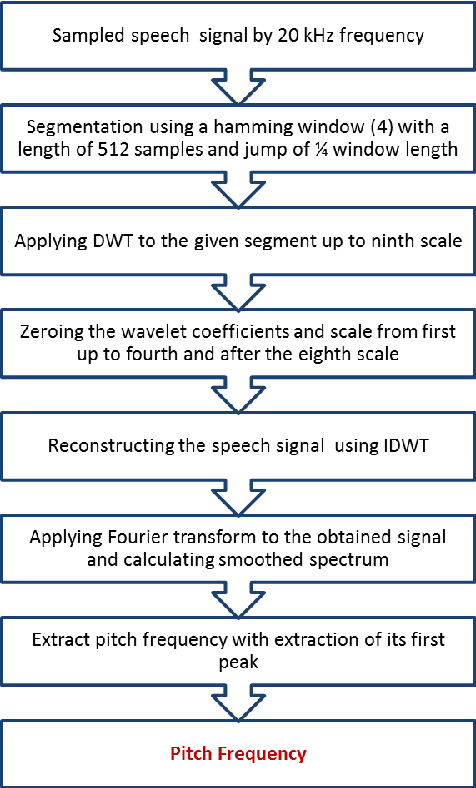
Pitch and Formant frequencies are important features in speech processing applications. The period of the vocal cord's output for vowels is known as the pitch or the fundamental frequency, and formant frequencies are essentially resonance frequencies of the vocal tract. These features vary among different persons and even words, but they are within a certain frequency range. In practice, just the first three formants are enough for the most of speech processing. Feature extraction and classification are the main components of each speech recognition system. In this article, two wavelet based approaches are proposed to extract the mentioned features with help of the filter bank idea. By comparing the results of the presented feature extraction methods on several speech signals, it was found out that the wavelet transform has a good accuracy compared to the cepstrum method and it has no sensitivity to noise. In addition, several fuzzy based classification techniques for speech processing are reviewed.
Thai Wav2Vec2.0 with CommonVoice V8
Aug 09, 2022

Recently, Automatic Speech Recognition (ASR), a system that converts audio into text, has caught a lot of attention in the machine learning community. Thus, a lot of publicly available models were released in HuggingFace. However, most of these ASR models are available in English; only a minority of the models are available in Thai. Additionally, most of the Thai ASR models are closed-sourced, and the performance of existing open-sourced models lacks robustness. To address this problem, we train a new ASR model on a pre-trained XLSR-Wav2Vec model with the Thai CommonVoice corpus V8 and train a trigram language model to boost the performance of our ASR model. We hope that our models will be beneficial to individuals and the ASR community in Thailand.
A comparison of end-to-end models for long-form speech recognition
Nov 06, 2019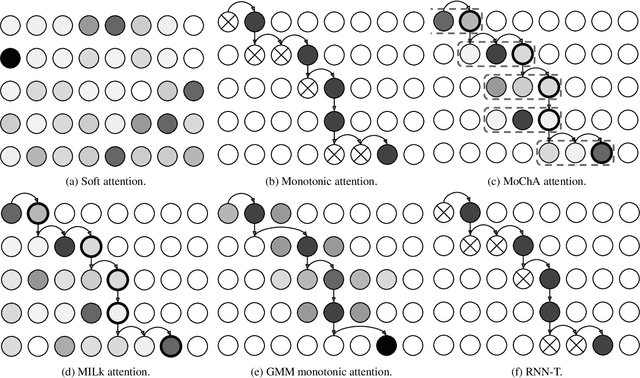

End-to-end automatic speech recognition (ASR) models, including both attention-based models and the recurrent neural network transducer (RNN-T), have shown superior performance compared to conventional systems. However, previous studies have focused primarily on short utterances that typically last for just a few seconds or, at most, a few tens of seconds. Whether such architectures are practical on long utterances that last from minutes to hours remains an open question. In this paper, we both investigate and improve the performance of end-to-end models on long-form transcription. We first present an empirical comparison of different end-to-end models on a real world long-form task and demonstrate that the RNN-T model is much more robust than attention-based systems in this regime. We next explore two improvements to attention-based systems that significantly improve its performance: restricting the attention to be monotonic, and applying a novel decoding algorithm that breaks long utterances into shorter overlapping segments. Combining these two improvements, we show that attention-based end-to-end models can be very competitive to RNN-T on long-form speech recognition.
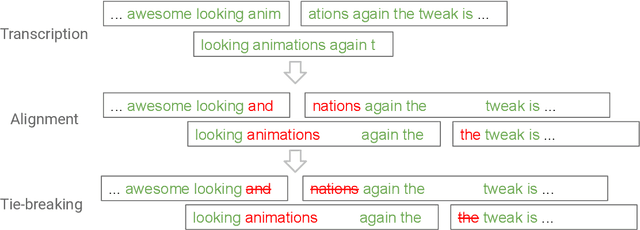
FastCorrect: Fast Error Correction with Edit Alignment for Automatic Speech Recognition
Jun 03, 2021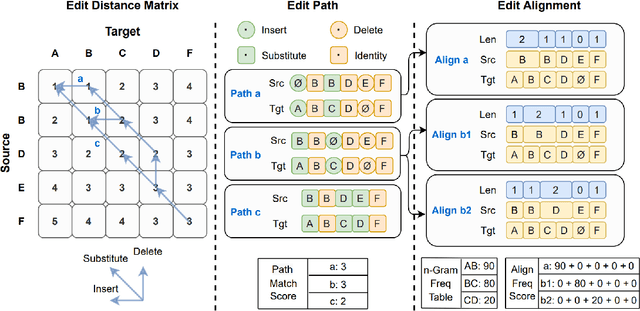
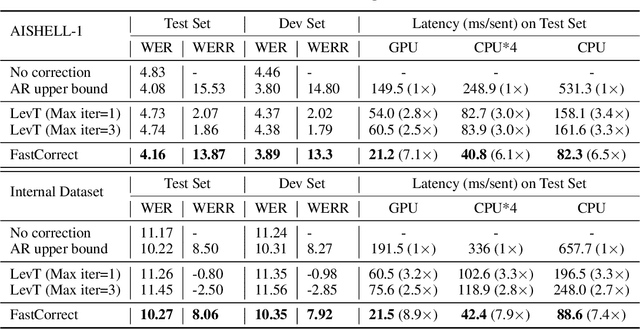
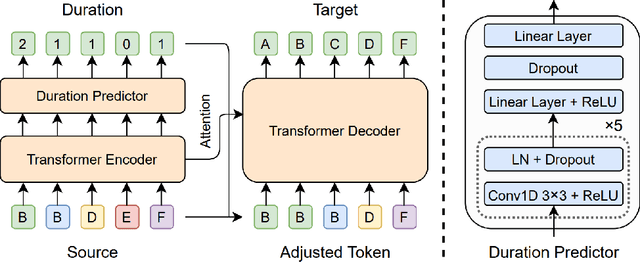
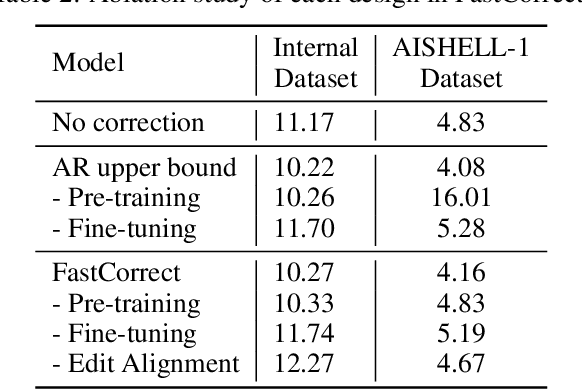
Error correction techniques have been used to refine the output sentences from automatic speech recognition (ASR) models and achieve a lower word error rate (WER) than original ASR outputs. Previous works usually use a sequence-to-sequence model to correct an ASR output sentence autoregressively, which causes large latency and cannot be deployed in online ASR services. A straightforward solution to reduce latency, inspired by non-autoregressive (NAR) neural machine translation, is to use an NAR sequence generation model for ASR error correction, which, however, comes at the cost of significantly increased ASR error rate. In this paper, observing distinctive error patterns and correction operations (i.e., insertion, deletion, and substitution) in ASR, we propose FastCorrect, a novel NAR error correction model based on edit alignment. In training, FastCorrect aligns each source token from an ASR output sentence to the target tokens from the corresponding ground-truth sentence based on the edit distance between the source and target sentences, and extracts the number of target tokens corresponding to each source token during edition/correction, which is then used to train a length predictor and to adjust the source tokens to match the length of the target sentence for parallel generation. In inference, the token number predicted by the length predictor is used to adjust the source tokens for target sequence generation. Experiments on the public AISHELL-1 dataset and an internal industrial-scale ASR dataset show the effectiveness of FastCorrect for ASR error correction: 1) it speeds up the inference by 6-9 times and maintains the accuracy (8-14% WER reduction) compared with the autoregressive correction model; and 2) it outperforms the popular NAR models adopted in neural machine translation and text edition by a large margin.
Maestro-U: Leveraging joint speech-text representation learning for zero supervised speech ASR
Oct 18, 2022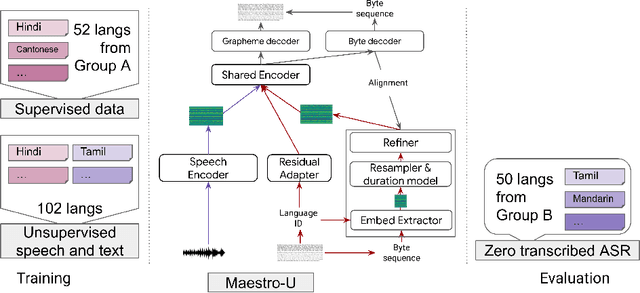
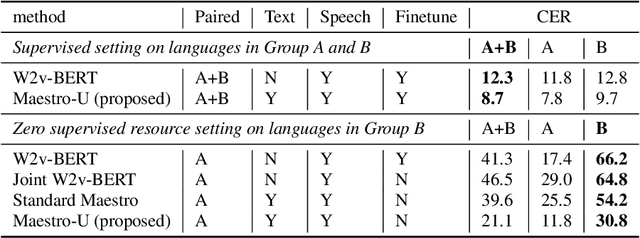
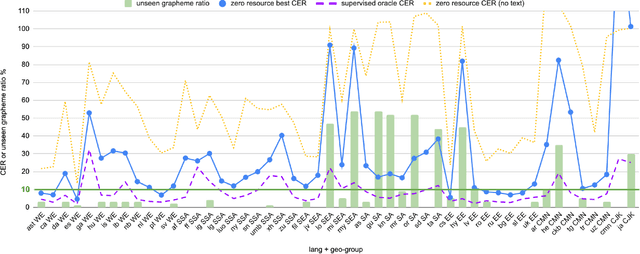
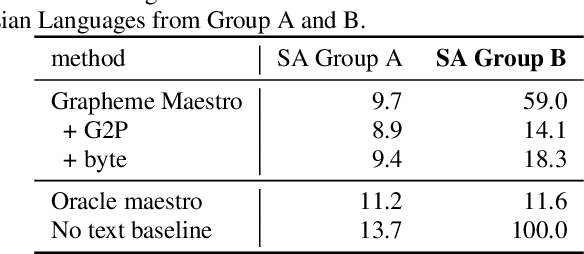
Training state-of-the-art Automated Speech Recognition (ASR) models typically requires a substantial amount of transcribed speech. In this work, we demonstrate that a modality-matched joint speech and text model can be leveraged to train a massively multilingual ASR model without any supervised (manually transcribed) speech for some languages. This paper explores the use of jointly learnt speech and text representations in a massively multilingual, zero supervised speech, real-world setting to expand the set of languages covered by ASR with only unlabeled speech and text in the target languages. Using the FLEURS dataset, we define the task to cover $102$ languages, where transcribed speech is available in $52$ of these languages and can be used to improve end-to-end ASR quality on the remaining $50$. First, we show that by combining speech representations with byte-level text representations and use of language embeddings, we can dramatically reduce the Character Error Rate (CER) on languages with no supervised speech from 64.8\% to 30.8\%, a relative reduction of 53\%. Second, using a subset of South Asian languages we show that Maestro-U can promote knowledge transfer from languages with supervised speech even when there is limited to no graphemic overlap. Overall, Maestro-U closes the gap to oracle performance by 68.5\% relative and reduces the CER of 19 languages below 15\%.
Discrete Cross-Modal Alignment Enables Zero-Shot Speech Translation
Oct 18, 2022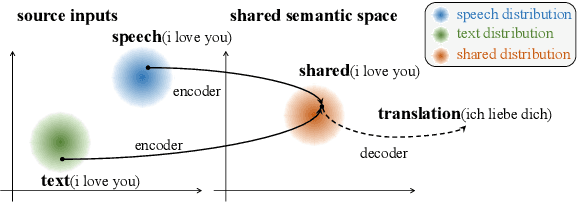
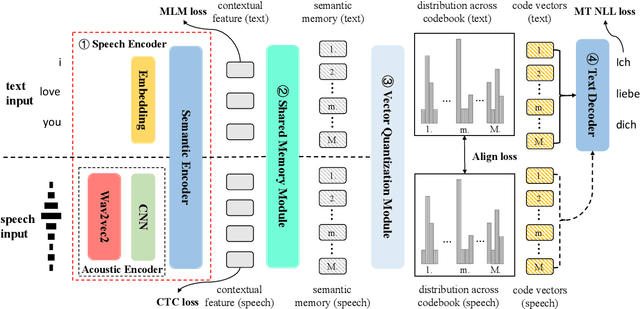
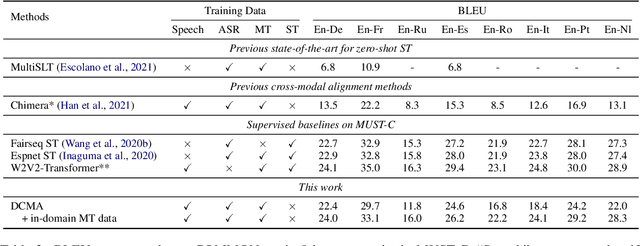
End-to-end Speech Translation (ST) aims at translating the source language speech into target language text without generating the intermediate transcriptions. However, the training of end-to-end methods relies on parallel ST data, which are difficult and expensive to obtain. Fortunately, the supervised data for automatic speech recognition (ASR) and machine translation (MT) are usually more accessible, making zero-shot speech translation a potential direction. Existing zero-shot methods fail to align the two modalities of speech and text into a shared semantic space, resulting in much worse performance compared to the supervised ST methods. In order to enable zero-shot ST, we propose a novel Discrete Cross-Modal Alignment (DCMA) method that employs a shared discrete vocabulary space to accommodate and match both modalities of speech and text. Specifically, we introduce a vector quantization module to discretize the continuous representations of speech and text into a finite set of virtual tokens, and use ASR data to map corresponding speech and text to the same virtual token in a shared codebook. This way, source language speech can be embedded in the same semantic space as the source language text, which can be then transformed into target language text with an MT module. Experiments on multiple language pairs demonstrate that our zero-shot ST method significantly improves the SOTA, and even performers on par with the strong supervised ST baselines.
Listen Attentively, and Spell Once: Whole Sentence Generation via a Non-Autoregressive Architecture for Low-Latency Speech Recognition
May 30, 2020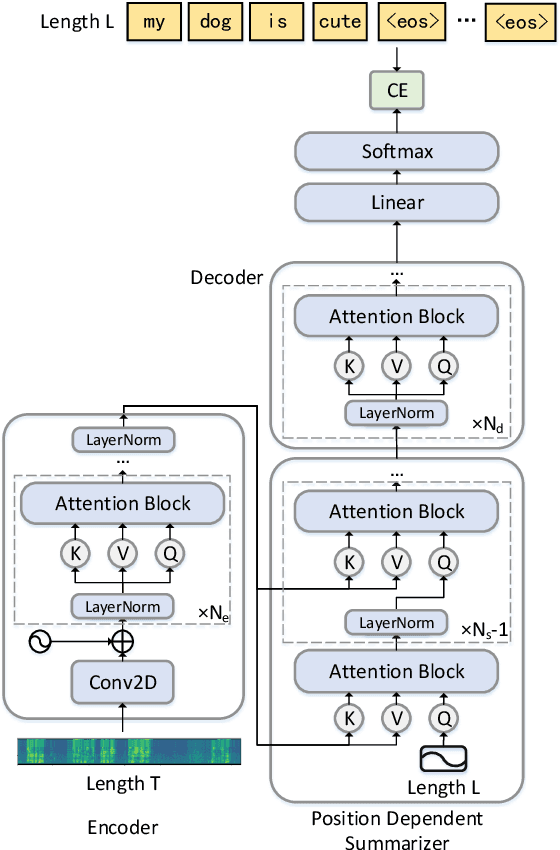
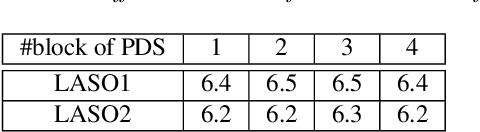
Although attention based end-to-end models have achieved promising performance in speech recognition, the multi-pass forward computation in beam-search increases inference time cost, which limits their practical applications. To address this issue, we propose a non-autoregressive end-to-end speech recognition system called LASO (listen attentively, and spell once). Because of the non-autoregressive property, LASO predicts a textual token in the sequence without the dependence on other tokens. Without beam-search, the one-pass propagation much reduces inference time cost of LASO. And because the model is based on the attention based feedforward structure, the computation can be implemented in parallel efficiently. We conduct experiments on publicly available Chinese dataset AISHELL-1. LASO achieves a character error rate of 6.4%, which outperforms the state-of-the-art autoregressive transformer model (6.7%). The average inference latency is 21 ms, which is 1/50 of the autoregressive transformer model.