 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Monaural Multi-Talker Speech Recognition using Factorial Speech Processing Models
Oct 05, 2016
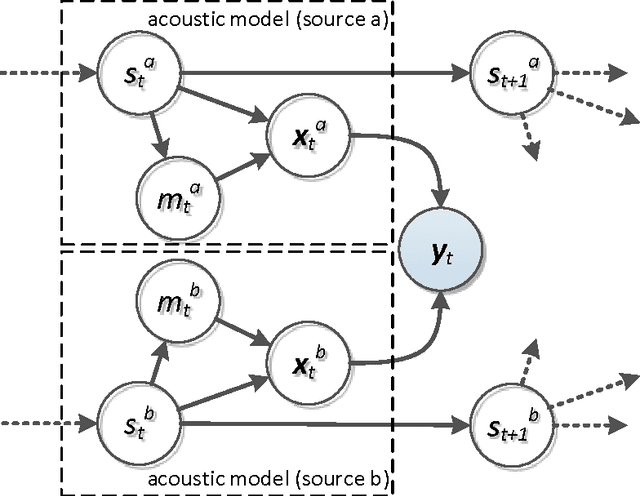

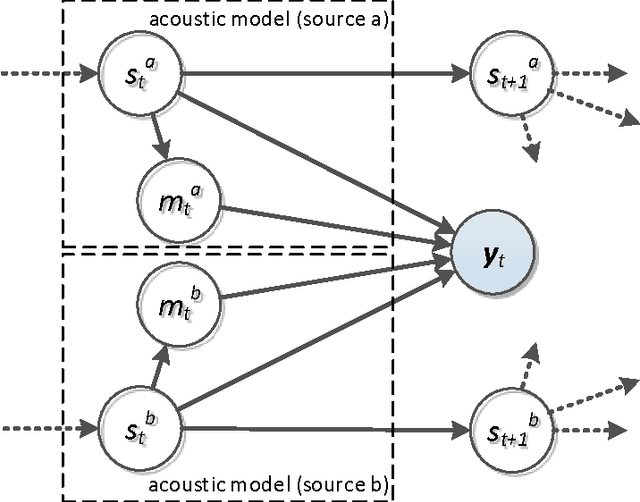
A Pascal challenge entitled monaural multi-talker speech recognition was developed, targeting the problem of robust automatic speech recognition against speech like noises which significantly degrades the performance of automatic speech recognition systems. In this challenge, two competing speakers say a simple command simultaneously and the objective is to recognize speech of the target speaker. Surprisingly during the challenge, a team from IBM research, could achieve a performance better than human listeners on this task. The proposed method of the IBM team, consist of an intermediate speech separation and then a single-talker speech recognition. This paper reconsiders the task of this challenge based on gain adapted factorial speech processing models. It develops a joint-token passing algorithm for direct utterance decoding of both target and masker speakers, simultaneously. Comparing it to the challenge winner, it uses maximum uncertainty during the decoding which cannot be used in the past two-phased method. It provides detailed derivation of inference on these models based on general inference procedures of probabilistic graphical models. As another improvement, it uses deep neural networks for joint-speaker identification and gain estimation which makes these two steps easier than before producing competitive results for these steps. The proposed method of this work outperforms past super-human results and even the results were achieved recently by Microsoft research, using deep neural networks. It achieved 5.5% absolute task performance improvement compared to the first super-human system and 2.7% absolute task performance improvement compared to its recent competitor.
Squeezeformer: An Efficient Transformer for Automatic Speech Recognition
Jun 02, 2022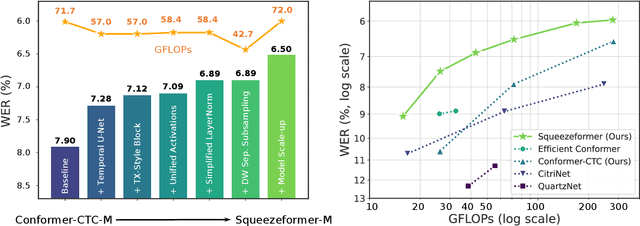
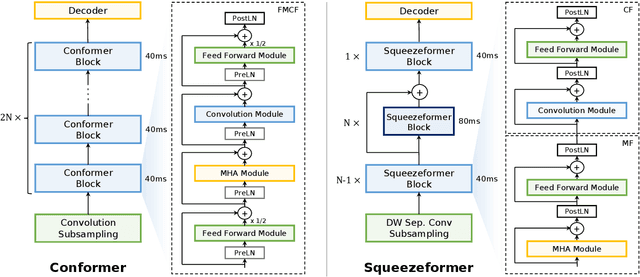
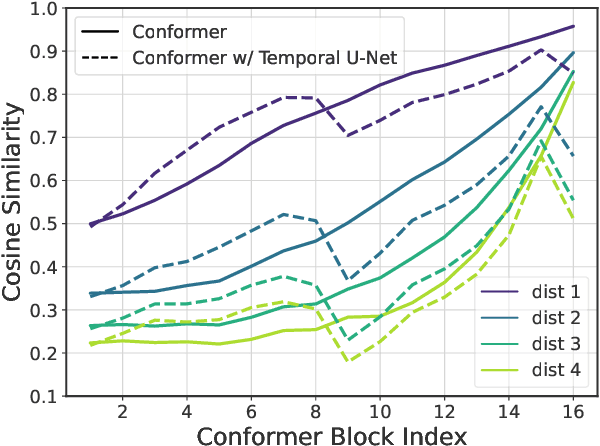
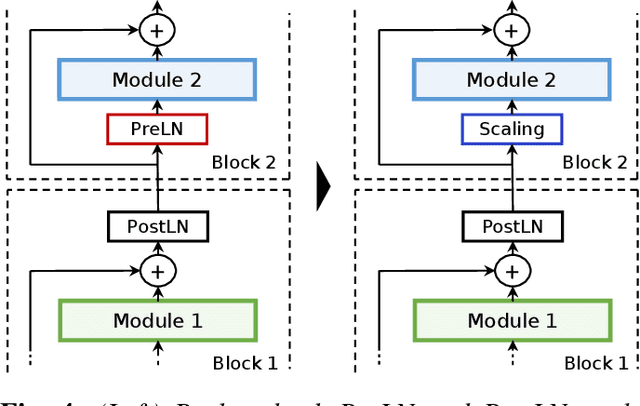
The recently proposed Conformer model has become the de facto backbone model for various downstream speech tasks based on its hybrid attention-convolution architecture that captures both local and global features. However, through a series of systematic studies, we find that the Conformer architecture's design choices are not optimal. After reexamining the design choices for both the macro and micro-architecture of Conformer, we propose the Squeezeformer model, which consistently outperforms the state-of-the-art ASR models under the same training schemes. In particular, for the macro-architecture, Squeezeformer incorporates (i) the Temporal U-Net structure, which reduces the cost of the multi-head attention modules on long sequences, and (ii) a simpler block structure of feed-forward module, followed up by multi-head attention or convolution modules, instead of the Macaron structure proposed in Conformer. Furthermore, for the micro-architecture, Squeezeformer (i) simplifies the activations in the convolutional block, (ii) removes redundant Layer Normalization operations, and (iii) incorporates an efficient depth-wise downsampling layer to efficiently sub-sample the input signal. Squeezeformer achieves state-of-the-art results of 7.5%, 6.5%, and 6.0% word-error-rate on Librispeech test-other without external language models. This is 3.1%, 1.4%, and 0.6% better than Conformer-CTC with the same number of FLOPs. Our code is open-sourced and available online.
cif-based collaborative decoding for end-to-end contextual speech recognition
Dec 17, 2020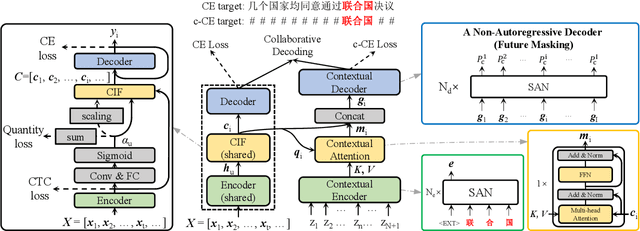
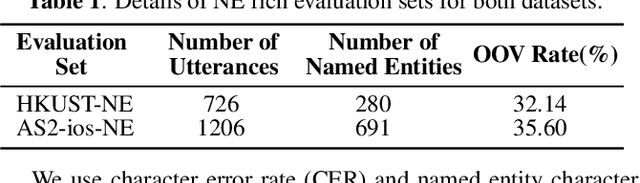
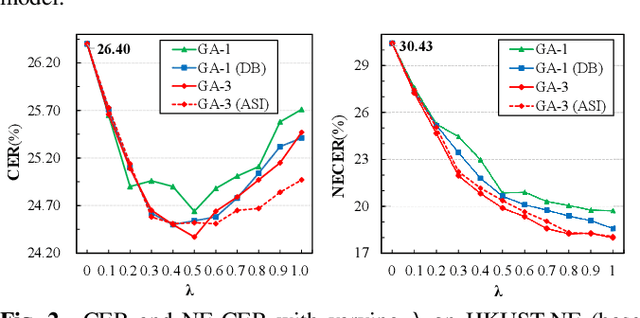
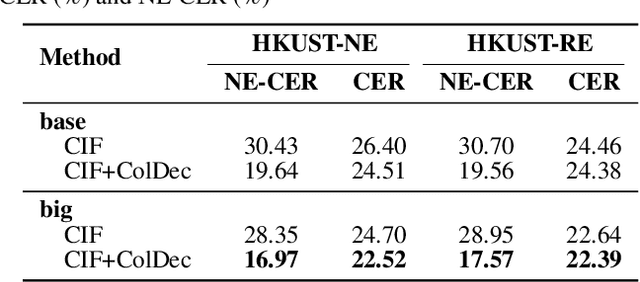
End-to-end (E2E) models have achieved promising results on multiple speech recognition benchmarks, and shown the potential to become the mainstream. However, the unified structure and the E2E training hamper injecting contextual information into them for contextual biasing. Though contextual LAS (CLAS) gives an excellent all-neural solution, the degree of biasing to given context information is not explicitly controllable. In this paper, we focus on incorporating context information into the continuous integrate-and-fire (CIF) based model that supports contextual biasing in a more controllable fashion. Specifically, an extra context processing network is introduced to extract contextual embeddings, integrate acoustically relevant context information and decode the contextual output distribution, thus forming a collaborative decoding with the decoder of the CIF-based model. Evaluated on the named entity rich evaluation sets of HKUST/AISHELL-2, our method brings relative character error rate (CER) reduction of 8.83%/21.13% and relative named entity character error rate (NE-CER) reduction of 40.14%/51.50% when compared with a strong baseline. Besides, it keeps the performance on original evaluation set without degradation.
Speech Recognition by Machine, A Review
Jan 13, 2010
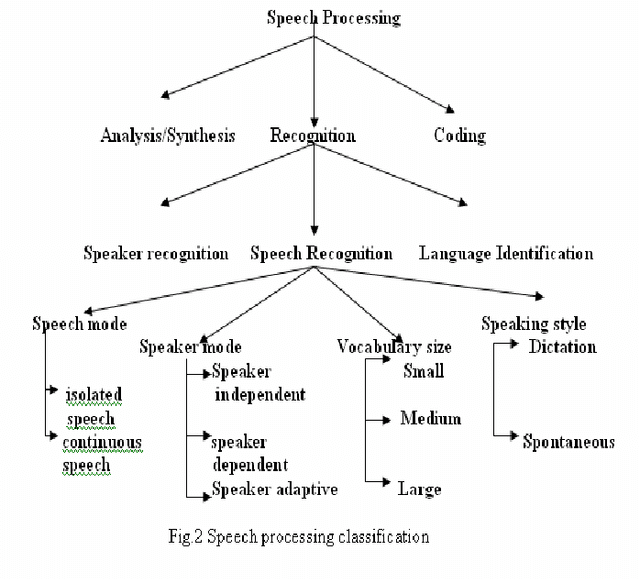
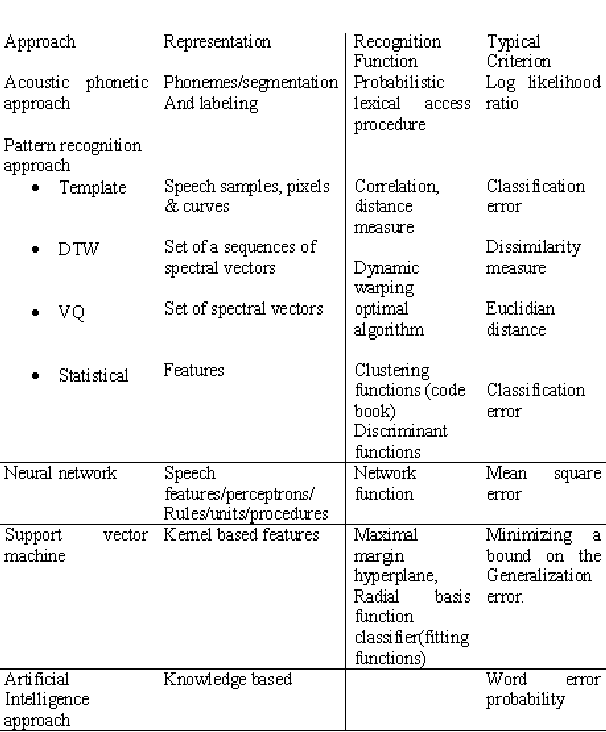
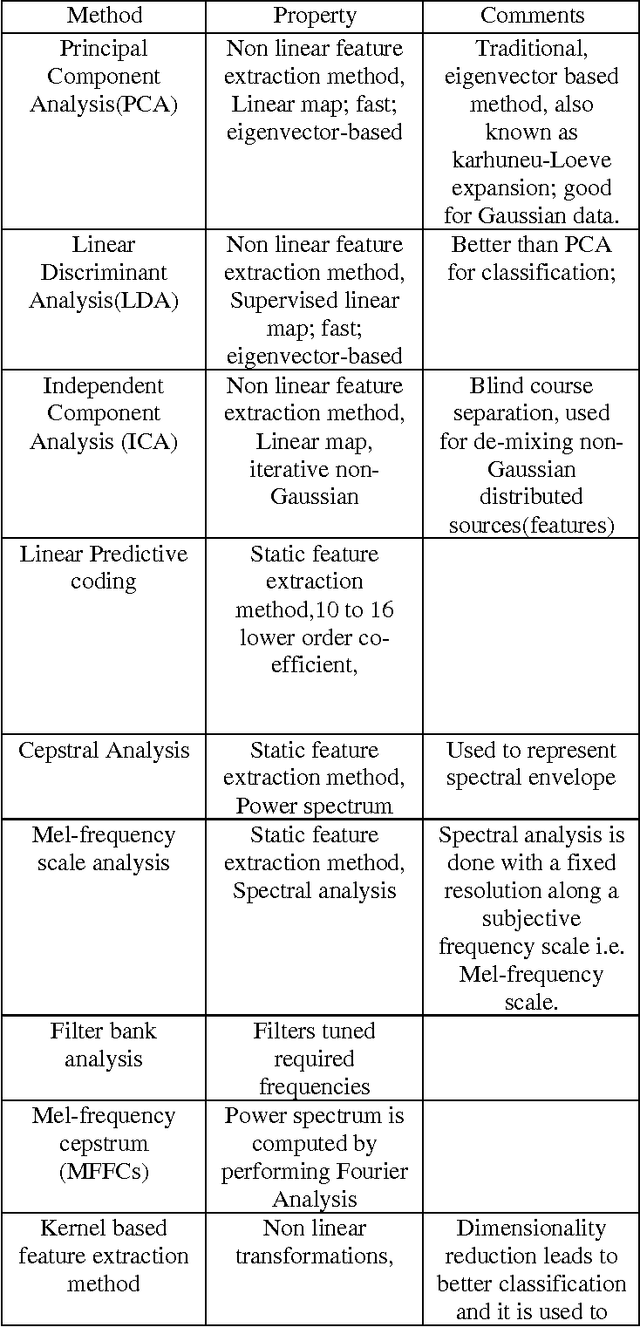
This paper presents a brief survey on Automatic Speech Recognition and discusses the major themes and advances made in the past 60 years of research, so as to provide a technological perspective and an appreciation of the fundamental progress that has been accomplished in this important area of speech communication. After years of research and development the accuracy of automatic speech recognition remains one of the important research challenges (e.g., variations of the context, speakers, and environment).The design of Speech Recognition system requires careful attentions to the following issues: Definition of various types of speech classes, speech representation, feature extraction techniques, speech classifiers, database and performance evaluation. The problems that are existing in ASR and the various techniques to solve these problems constructed by various research workers have been presented in a chronological order. Hence authors hope that this work shall be a contribution in the area of speech recognition. The objective of this review paper is to summarize and compare some of the well known methods used in various stages of speech recognition system and identify research topic and applications which are at the forefront of this exciting and challenging field.
* 25 pages IEEE format, International Journal of Computer Science and Information Security, IJCSIS December 2009, ISSN 1947 5500, http://sites.google.com/site/ijcsis/
Multiple Confidence Gates For Joint Training Of SE And ASR
Apr 01, 2022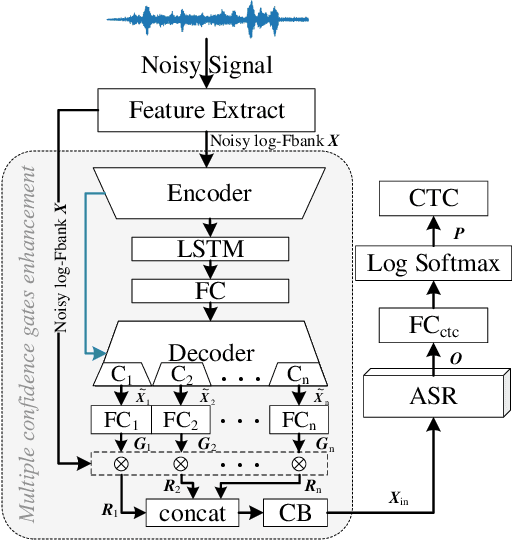
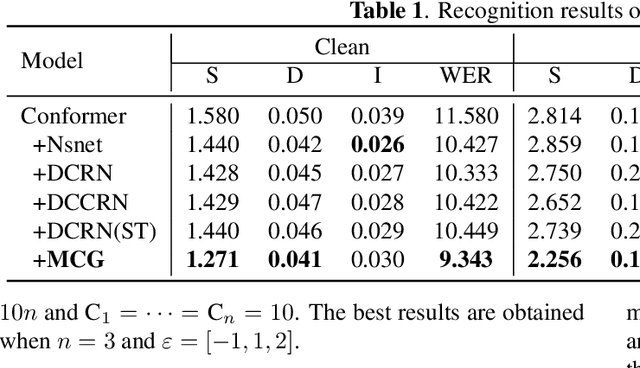
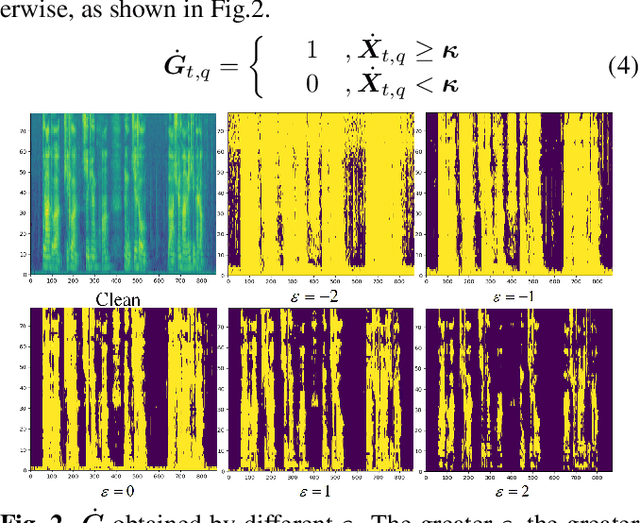
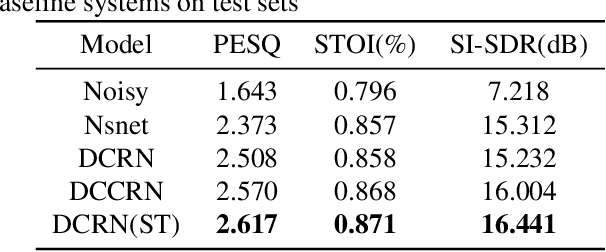
Joint training of speech enhancement model (SE) and speech recognition model (ASR) is a common solution for robust ASR in noisy environments. SE focuses on improving the auditory quality of speech, but the enhanced feature distribution is changed, which is uncertain and detrimental to the ASR. To tackle this challenge, an approach with multiple confidence gates for jointly training of SE and ASR is proposed. A speech confidence gates prediction module is designed to replace the former SE module in joint training. The noisy speech is filtered by gates to obtain features that are easier to be fitting by the ASR network. The experimental results show that the proposed method has better performance than the traditional robust speech recognition system on test sets of clean speech, synthesized noisy speech, and real noisy speech.
Learning ASR pathways: A sparse multilingual ASR model
Sep 13, 2022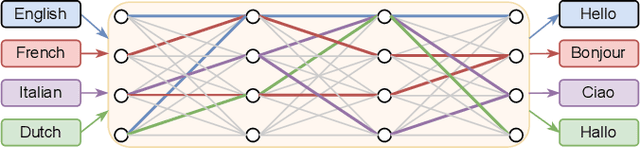
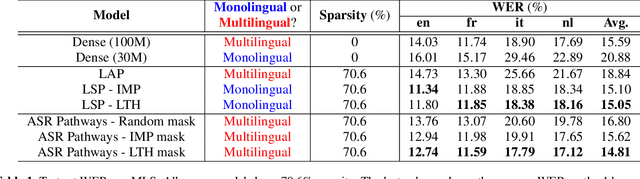
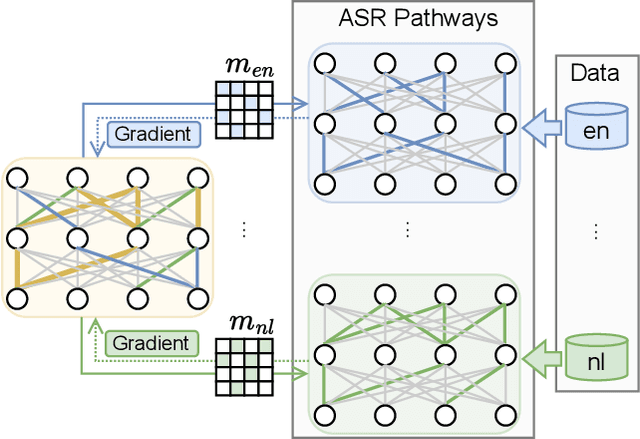
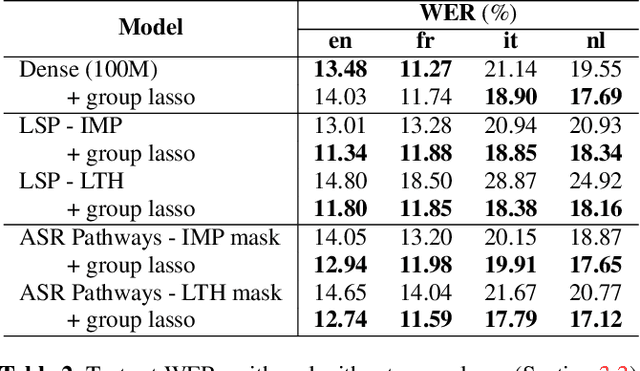
Neural network pruning can be effectively applied to compress automatic speech recognition (ASR) models. However, in multilingual ASR, performing language-agnostic pruning may lead to severe performance degradation on some languages because language-agnostic pruning masks may not fit all languages and discard important language-specific parameters. In this work, we present ASR pathways, a sparse multilingual ASR model that activates language-specific sub-networks ("pathways"), such that the parameters for each language are learned explicitly. With the overlapping sub-networks, the shared parameters can also enable knowledge transfer for lower resource languages via joint multilingual training. We propose a novel algorithm to learn ASR pathways, and evaluate the proposed method on 4 languages with a streaming RNN-T model. Our proposed ASR pathways outperform both dense models (-5.0% average WER) and a language-agnostically pruned model (-21.4% average WER), and provide better performance on low-resource languages compared to the monolingual sparse models.
English Accent Accuracy Analysis in a State-of-the-Art Automatic Speech Recognition System
May 09, 2021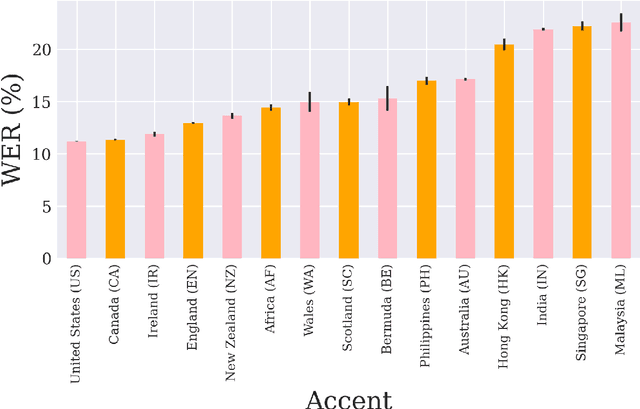

Nowadays, research in speech technologies has gotten a lot out thanks to recently created public domain corpora that contain thousands of recording hours. These large amounts of data are very helpful for training the new complex models based on deep learning technologies. However, the lack of dialectal diversity in a corpus is known to cause performance biases in speech systems, mainly for underrepresented dialects. In this work, we propose to evaluate a state-of-the-art automatic speech recognition (ASR) deep learning-based model, using unseen data from a corpus with a wide variety of labeled English accents from different countries around the world. The model has been trained with 44.5K hours of English speech from an open access corpus called Multilingual LibriSpeech, showing remarkable results in popular benchmarks. We test the accuracy of such ASR against samples extracted from another public corpus that is continuously growing, the Common Voice dataset. Then, we present graphically the accuracy in terms of Word Error Rate of each of the different English included accents, showing that there is indeed an accuracy bias in terms of accentual variety, favoring the accents most prevalent in the training corpus.
Efficiently Fusing Pretrained Acoustic and Linguistic Encoders for Low-resource Speech Recognition
Jan 24, 2021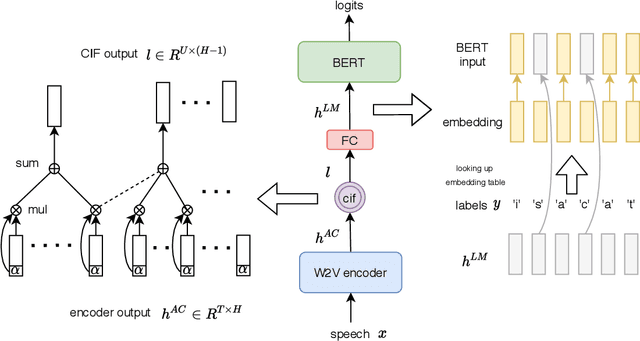
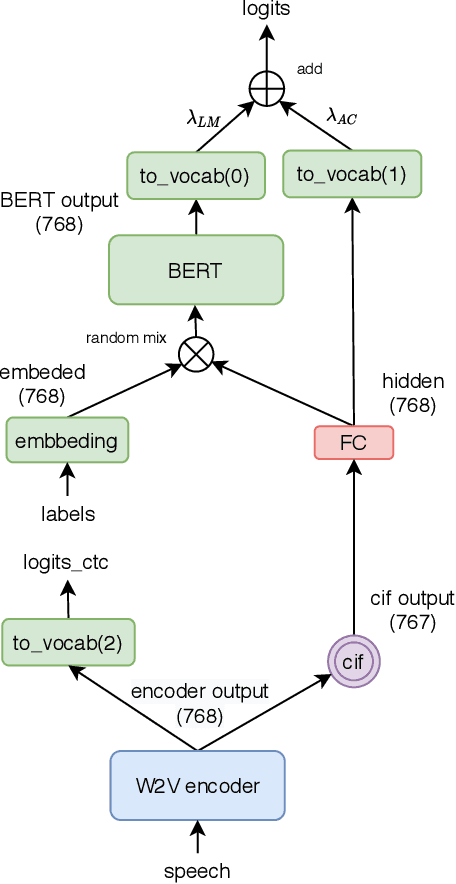
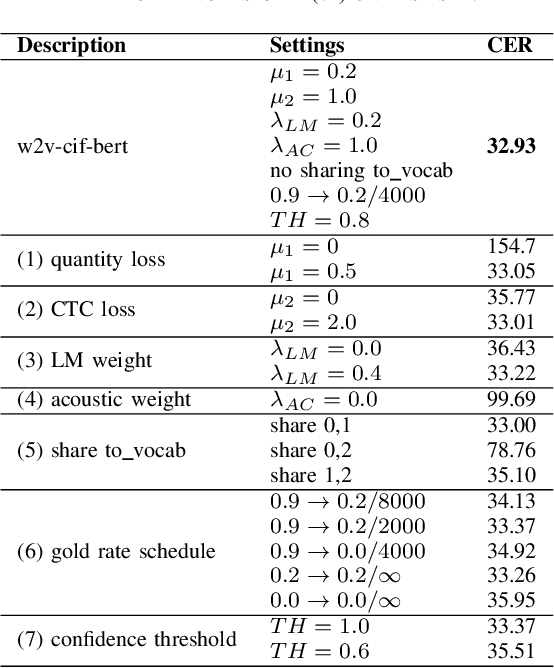
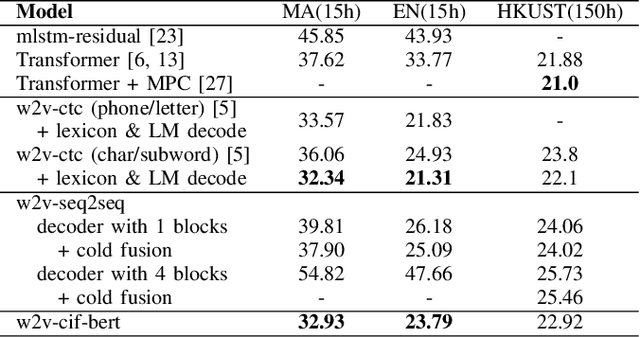
End-to-end models have achieved impressive results on the task of automatic speech recognition (ASR). For low-resource ASR tasks, however, labeled data can hardly satisfy the demand of end-to-end models. Self-supervised acoustic pre-training has already shown its amazing ASR performance, while the transcription is still inadequate for language modeling in end-to-end models. In this work, we fuse a pre-trained acoustic encoder (wav2vec2.0) and a pre-trained linguistic encoder (BERT) into an end-to-end ASR model. The fused model only needs to learn the transfer from speech to language during fine-tuning on limited labeled data. The length of the two modalities is matched by a monotonic attention mechanism without additional parameters. Besides, a fully connected layer is introduced for the hidden mapping between modalities. We further propose a scheduled fine-tuning strategy to preserve and utilize the text context modeling ability of the pre-trained linguistic encoder. Experiments show our effective utilizing of pre-trained modules. Our model achieves better recognition performance on CALLHOME corpus (15 hours) than other end-to-end models.
Transformer-based Acoustic Modeling for Hybrid Speech Recognition
Oct 22, 2019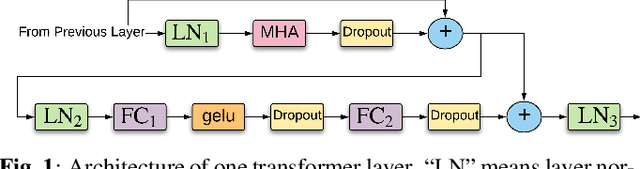
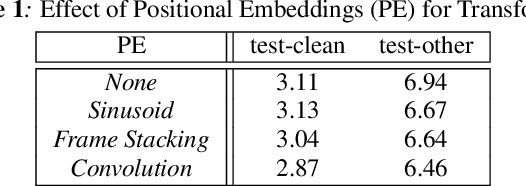
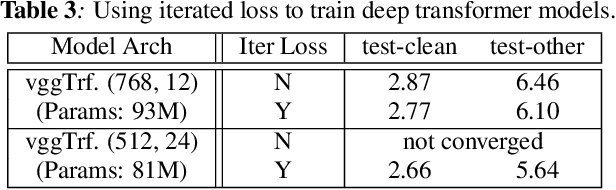
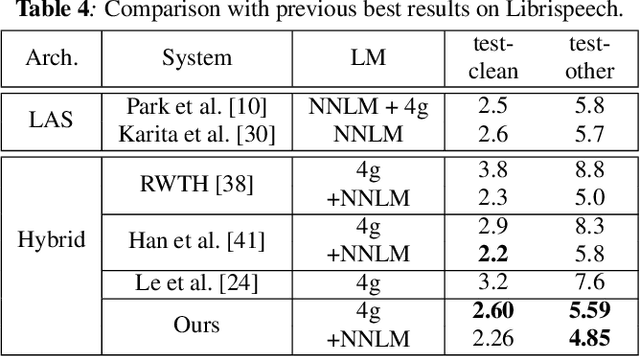
We propose and evaluate transformer-based acoustic models (AMs) for hybrid speech recognition. Several modeling choices are discussed in this work, including various positional embedding methods and an iterated loss to enable training deep transformers. We also present a preliminary study of using limited right context in transformer models, which makes it possible for streaming applications. We demonstrate that on the widely used Librispeech benchmark, our transformer-based AM outperforms the best published hybrid result by 19% to 26% relative when the standard n-gram language model (LM) is used. Combined with neural network LM for rescoring, our proposed approach achieves state-of-the-art results on Librispeech. Our findings are also confirmed on a much larger internal dataset.
End-to-End Visual Speech Recognition for Small-Scale Datasets
Apr 02, 2019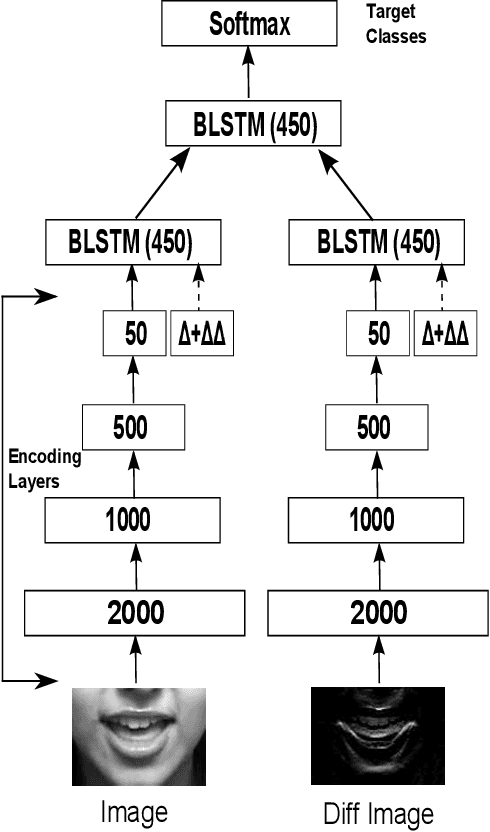
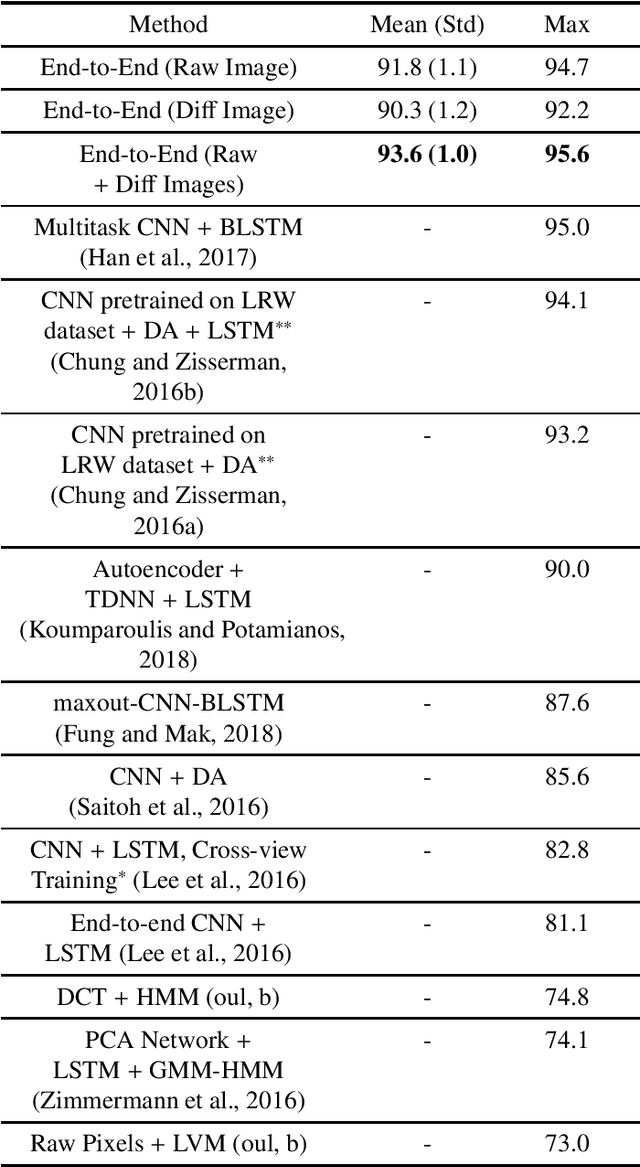
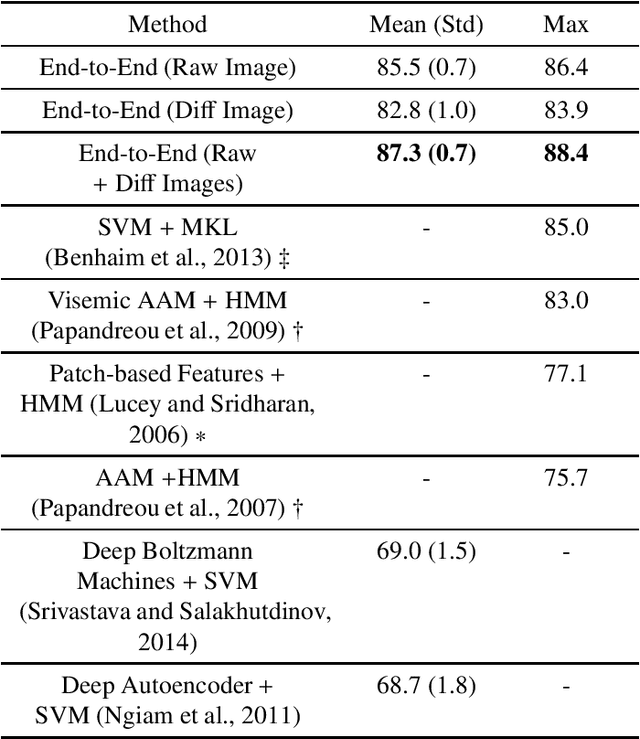
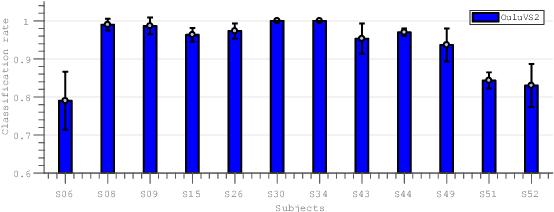
Traditional visual speech recognition systems consist of two stages, feature extraction and classification. Recently, several deep learning approaches have been presented which automatically extract features from the mouth images and aim to replace the feature extraction stage. However, research on joint learning of features and classification remains limited. In addition, most of the existing methods require large amounts of data in order to achieve state-of-the-art performance, otherwise they under-perform. In this work, we present an end-to-end visual speech recognition system based on fully-connected layers and Long-Short Memory (LSTM) networks which is suitable for small-scale datasets. The model consists of two streams which extract features directly from the mouth and difference images, respectively. The temporal dynamics in each stream are modelled by a Bidirectional LSTM (BLSTM) and the fusion of the two streams takes place via another BLSTM. An absolute improvement of 0.6%, 3.4%, 3.9%, 11.4% over the state-of-the-art is reported on the OuluVS2, CUAVE, AVLetters and AVLetters2 databases, respectively.