 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
BEA-Base: A Benchmark for ASR of Spontaneous Hungarian
Feb 01, 2022
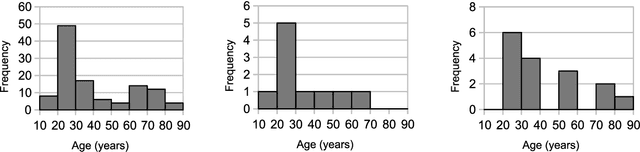
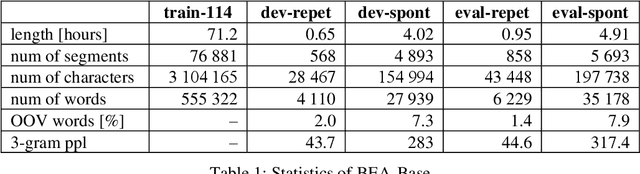
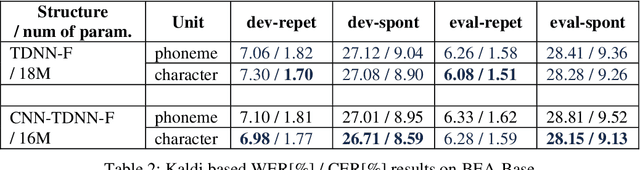
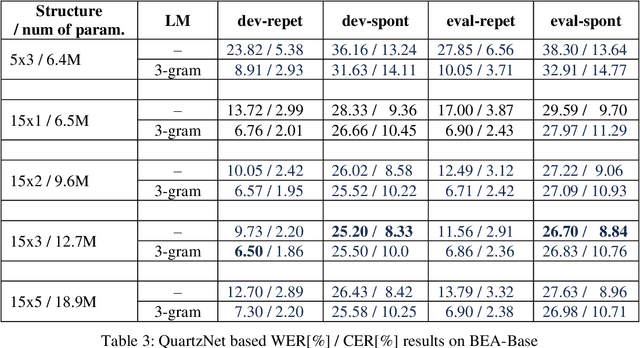
Hungarian is spoken by 15 million people, still, easily accessible Automatic Speech Recognition (ASR) benchmark datasets - especially for spontaneous speech - have been practically unavailable. In this paper, we introduce BEA-Base, a subset of the BEA spoken Hungarian database comprising mostly spontaneous speech of 140 speakers. It is built specifically to assess ASR, primarily for conversational AI applications. After defining the speech recognition subsets and task, several baselines - including classic HMM-DNN hybrid and end-to-end approaches augmented by cross-language transfer learning - are developed using open-source toolkits. The best results obtained are based on multilingual self-supervised pretraining, achieving a 45% recognition error rate reduction as compared to the classical approach - without the application of an external language model or additional supervised data. The results show the feasibility of using BEA-Base for training and evaluation of Hungarian speech recognition systems.
Iterative pseudo-forced alignment by acoustic CTC loss for self-supervised ASR domain adaptation
Oct 27, 2022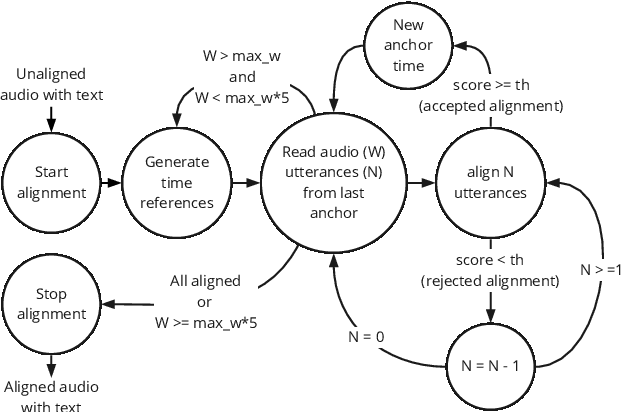
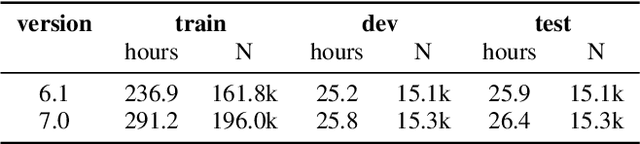
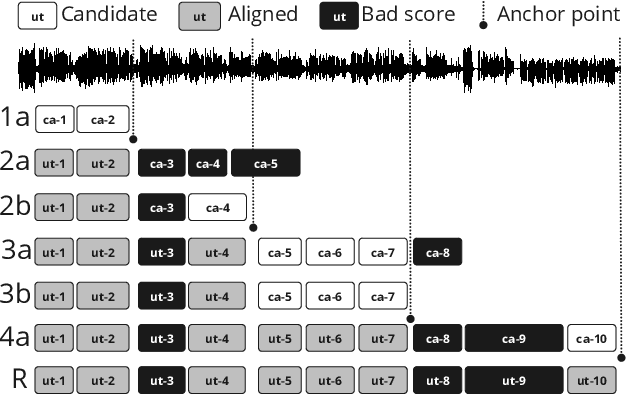

High-quality data labeling from specific domains is costly and human time-consuming. In this work, we propose a self-supervised domain adaptation method, based upon an iterative pseudo-forced alignment algorithm. The produced alignments are employed to customize an end-to-end Automatic Speech Recognition (ASR) and iteratively refined. The algorithm is fed with frame-wise character posteriors produced by a seed ASR, trained with out-of-domain data, and optimized throughout a Connectionist Temporal Classification (CTC) loss. The alignments are computed iteratively upon a corpus of broadcast TV. The process is repeated by reducing the quantity of text to be aligned or expanding the alignment window until finding the best possible audio-text alignment. The starting timestamps, or temporal anchors, are produced uniquely based on the confidence score of the last aligned utterance. This score is computed with the paths of the CTC-alignment matrix. With this methodology, no human-revised text references are required. Alignments from long audio files with low-quality transcriptions, like TV captions, are filtered out by confidence score and ready for further ASR adaptation. The obtained results, on both the Spanish RTVE2022 and CommonVoice databases, underpin the feasibility of using CTC-based systems to perform: highly accurate audio-text alignments, domain adaptation and semi-supervised training of end-to-end ASR.
Adaptive Natural Language Generation for Task-oriented Dialogue via Reinforcement Learning
Sep 16, 2022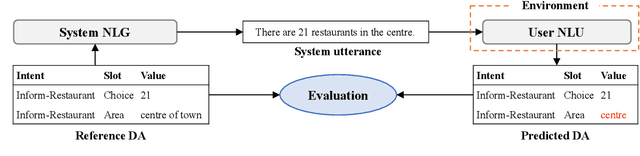
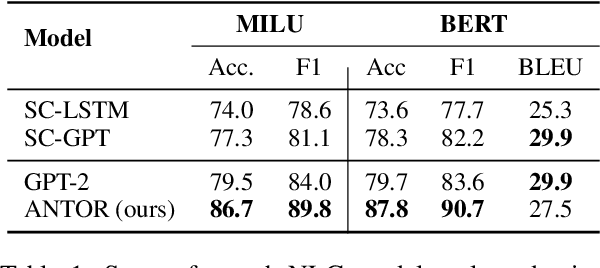
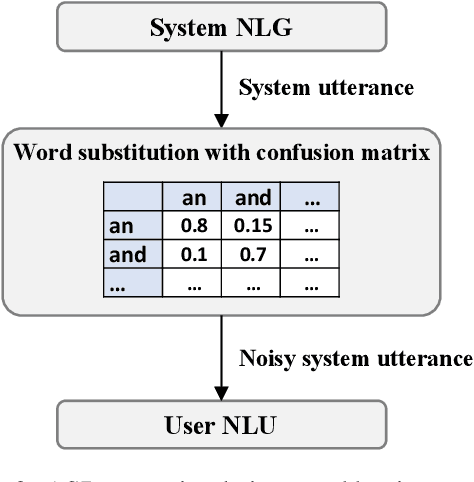
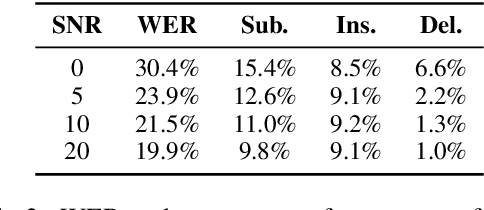
When a natural language generation (NLG) component is implemented in a real-world task-oriented dialogue system, it is necessary to generate not only natural utterances as learned on training data but also utterances adapted to the dialogue environment (e.g., noise from environmental sounds) and the user (e.g., users with low levels of understanding ability). Inspired by recent advances in reinforcement learning (RL) for language generation tasks, we propose ANTOR, a method for Adaptive Natural language generation for Task-Oriented dialogue via Reinforcement learning. In ANTOR, a natural language understanding (NLU) module, which corresponds to the user's understanding of system utterances, is incorporated into the objective function of RL. If the NLG's intentions are correctly conveyed to the NLU, which understands a system's utterances, the NLG is given a positive reward. We conducted experiments on the MultiWOZ dataset, and we confirmed that ANTOR could generate adaptive utterances against speech recognition errors and the different vocabulary levels of users.
Q-ASR: Integer-only Zero-shot Quantization for Efficient Speech Recognition
Mar 31, 2021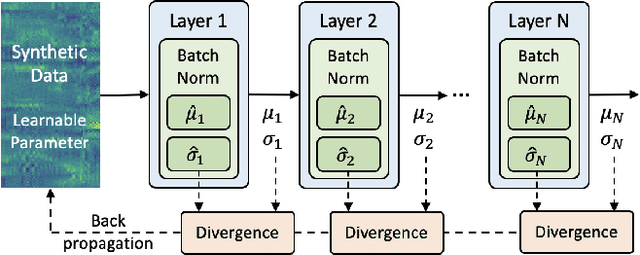
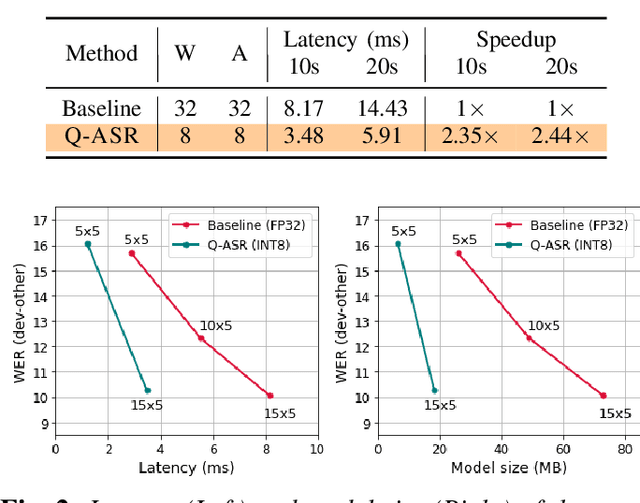
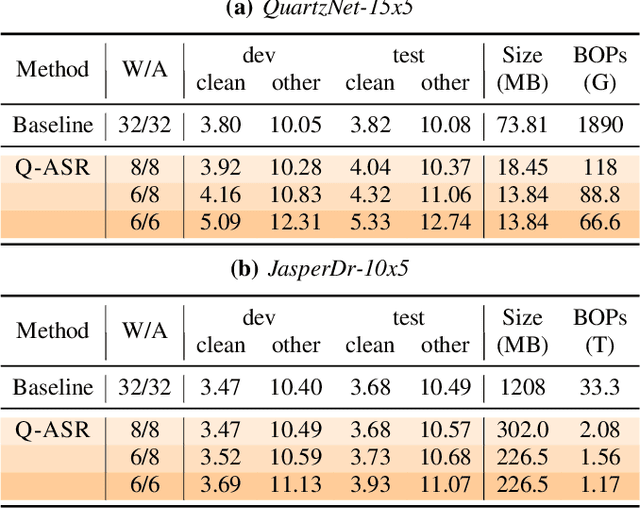
End-to-end neural network models achieve improved performance on various automatic speech recognition (ASR) tasks. However, these models perform poorly on edge hardware due to large memory and computation requirements. While quantizing model weights and/or activations to low-precision can be a promising solution, previous research on quantizing ASR models is limited. Most quantization approaches use floating-point arithmetic during inference; and thus they cannot fully exploit integer processing units, which use less power than their floating-point counterparts. Moreover, they require training/validation data during quantization for finetuning or calibration; however, this data may not be available due to security/privacy concerns. To address these limitations, we propose Q-ASR, an integer-only, zero-shot quantization scheme for ASR models. In particular, we generate synthetic data whose runtime statistics resemble the real data, and we use it to calibrate models during quantization. We then apply Q-ASR to quantize QuartzNet-15x5 and JasperDR-10x5 without any training data, and we show negligible WER change as compared to the full-precision baseline models. For INT8-only quantization, we observe a very modest WER degradation of up to 0.29%, while we achieve up to 2.44x speedup on a T4 GPU. Furthermore, Q-ASR exhibits a large compression rate of more than 4x with small WER degradation.
Automatic Documentation of ICD Codes with Far-Field Speech Recognition
Nov 04, 2018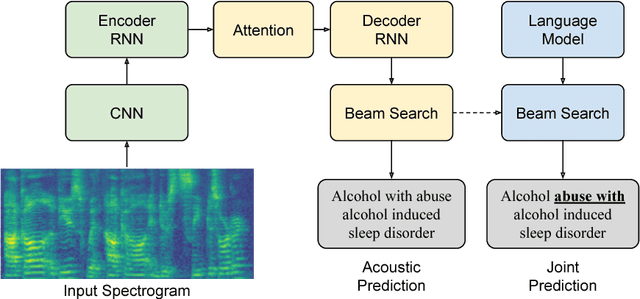
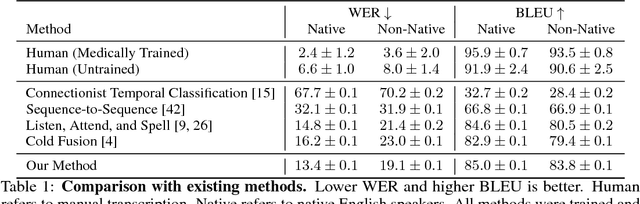
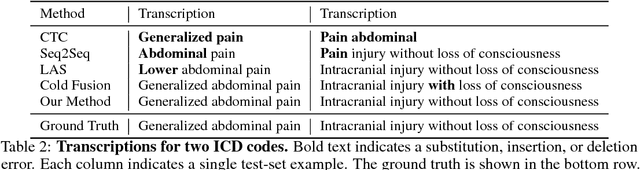
Documentation errors increase healthcare costs and cause unnecessary patient deaths. As the standard language for diagnoses and billing, ICD codes serve as the foundation for medical documentation worldwide. Despite the prevalence of electronic medical records, hospitals still witness high levels of ICD miscoding. In this paper, we propose to automatically document ICD codes with far-field speech recognition. Far-field speech occurs when the microphone is located several meters from the source, as is common with smart homes and security systems. Our method combines acoustic signal processing with recurrent neural networks to recognize and document ICD codes in real time. To evaluate our model, we collected a far-field speech dataset of ICD-10 codes and found our model to achieve 87% accuracy with a BLEU score of 85%. By sampling from an unsupervised medical language model, our method is able to outperform existing methods. Overall, this work shows the potential of automatic speech recognition to provide efficient, accurate, and cost-effective healthcare documentation.
Learning not to Discriminate: Task Agnostic Learning for Improving Monolingual and Code-switched Speech Recognition
Jun 09, 2020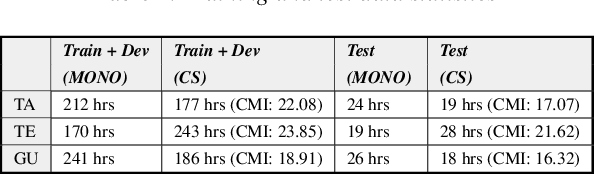
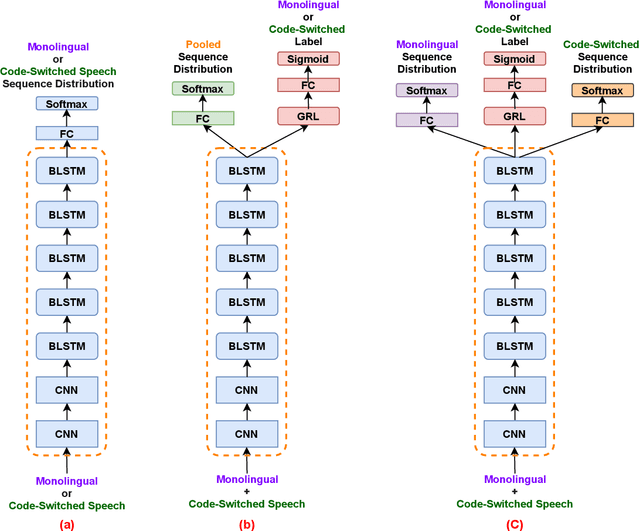
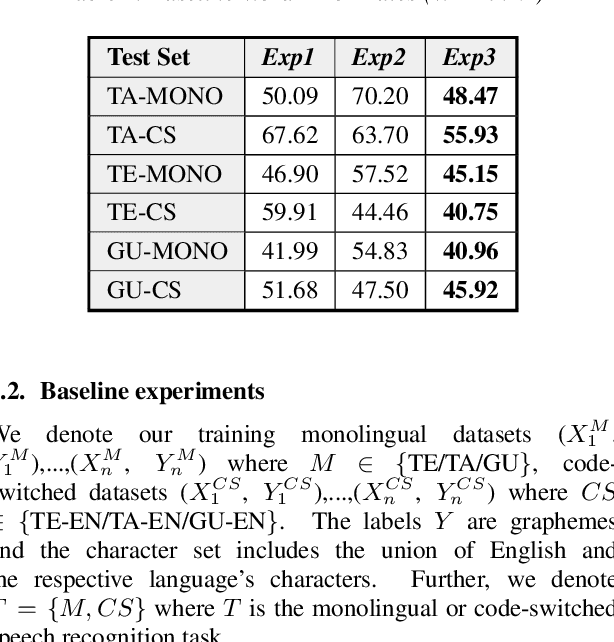
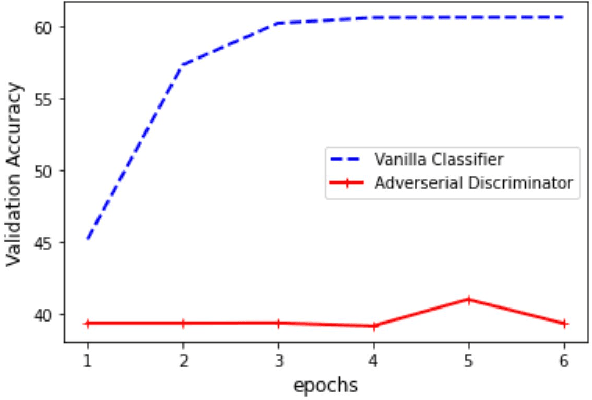
Recognizing code-switched speech is challenging for Automatic Speech Recognition (ASR) for a variety of reasons, including the lack of code-switched training data. Recently, we showed that monolingual ASR systems fine-tuned on code-switched data deteriorate in performance on monolingual speech recognition, which is not desirable as ASR systems deployed in multilingual scenarios should recognize both monolingual and code-switched speech with high accuracy. Our experiments indicated that this loss in performance could be mitigated by using certain strategies for fine-tuning and regularization, leading to improvements in both monolingual and code-switched ASR. In this work, we present further improvements over our previous work by using domain adversarial learning to train task agnostic models. We evaluate the classification accuracy of an adversarial discriminator and show that it can learn shared layer parameters that are task agnostic. We train end-to-end ASR systems starting with a pooled model that uses monolingual and code-switched data along with the adversarial discriminator. Our proposed technique leads to reductions in Word Error Rates (WER) in monolingual and code-switched test sets across three language pairs.
A comparable study of modeling units for end-to-end Mandarin speech recognition
May 14, 2018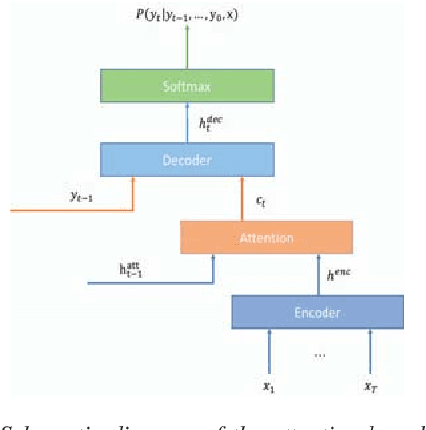
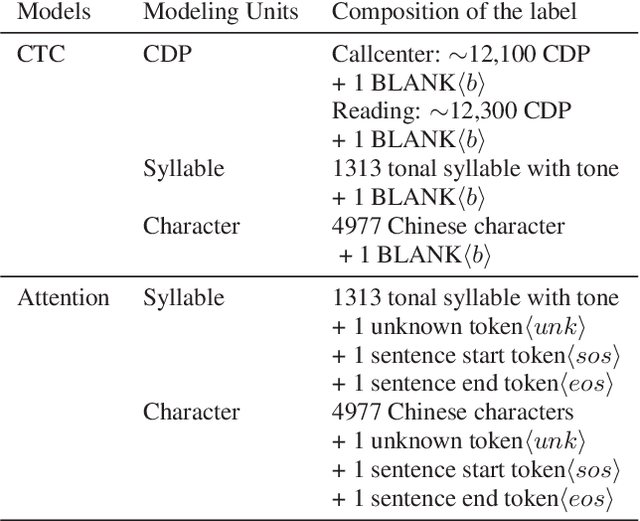
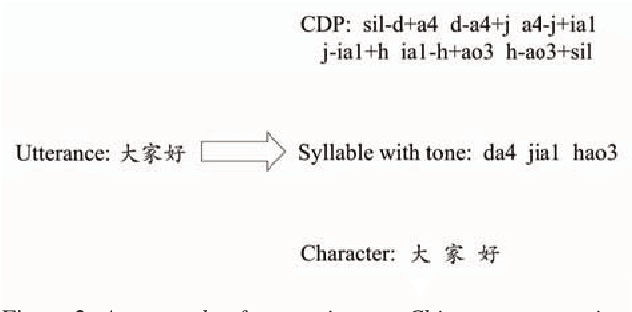
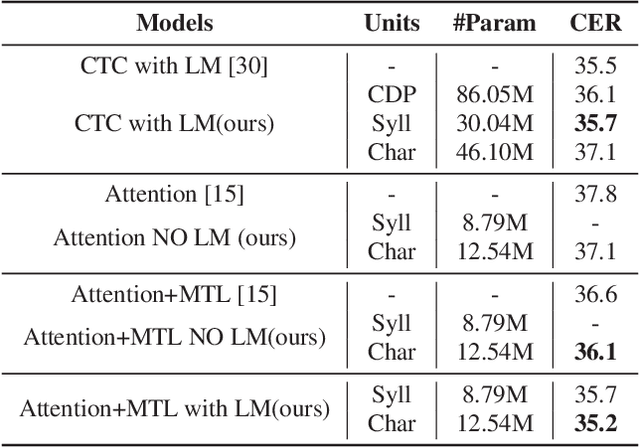
End-To-End speech recognition have become increasingly popular in mandarin speech recognition and achieved delightful performance. Mandarin is a tonal language which is different from English and requires special treatment for the acoustic modeling units. There have been several different kinds of modeling units for mandarin such as phoneme, syllable and Chinese character. In this work, we explore two major end-to-end models: connectionist temporal classification (CTC) model and attention based encoder-decoder model for mandarin speech recognition. We compare the performance of three different scaled modeling units: context dependent phoneme(CDP), syllable with tone and Chinese character. We find that all types of modeling units can achieve approximate character error rate (CER) in CTC model and the performance of Chinese character attention model is better than syllable attention model. Furthermore, we find that Chinese character is a reasonable unit for mandarin speech recognition. On DidiCallcenter task, Chinese character attention model achieves a CER of 5.68% and CTC model gets a CER of 7.29%, on the other DidiReading task, CER are 4.89% and 5.79%, respectively. Moreover, attention model achieves a better performance than CTC model on both datasets.
Deep LSTM for Large Vocabulary Continuous Speech Recognition
Mar 21, 2017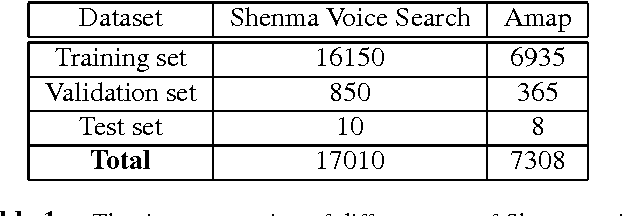
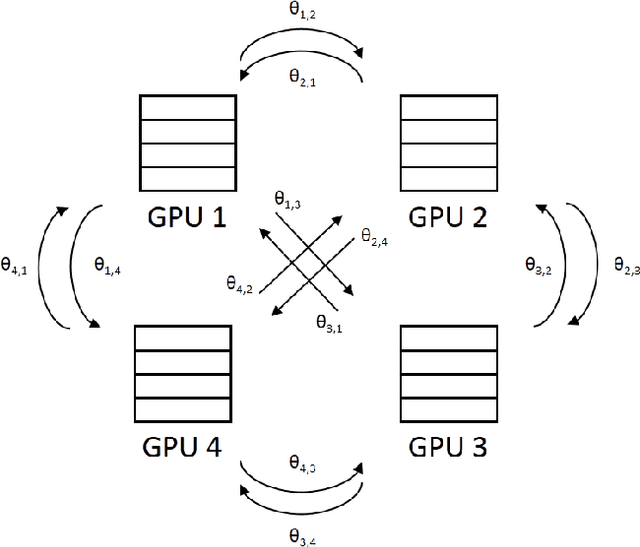
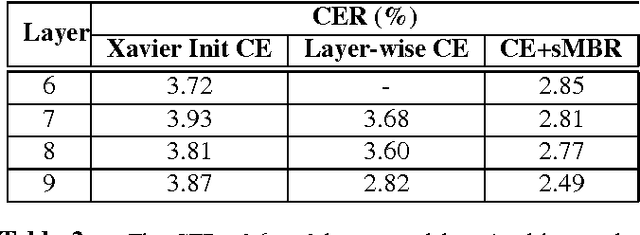
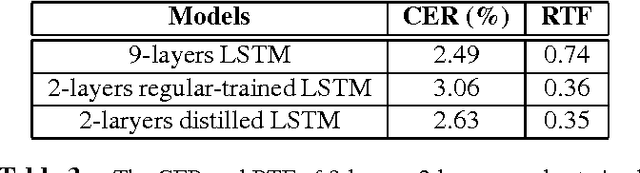
Recurrent neural networks (RNNs), especially long short-term memory (LSTM) RNNs, are effective network for sequential task like speech recognition. Deeper LSTM models perform well on large vocabulary continuous speech recognition, because of their impressive learning ability. However, it is more difficult to train a deeper network. We introduce a training framework with layer-wise training and exponential moving average methods for deeper LSTM models. It is a competitive framework that LSTM models of more than 7 layers are successfully trained on Shenma voice search data in Mandarin and they outperform the deep LSTM models trained by conventional approach. Moreover, in order for online streaming speech recognition applications, the shallow model with low real time factor is distilled from the very deep model. The recognition accuracy have little loss in the distillation process. Therefore, the model trained with the proposed training framework reduces relative 14\% character error rate, compared to original model which has the similar real-time capability. Furthermore, the novel transfer learning strategy with segmental Minimum Bayes-Risk is also introduced in the framework. The strategy makes it possible that training with only a small part of dataset could outperform full dataset training from the beginning.
Deep word embeddings for visual speech recognition
Oct 30, 2017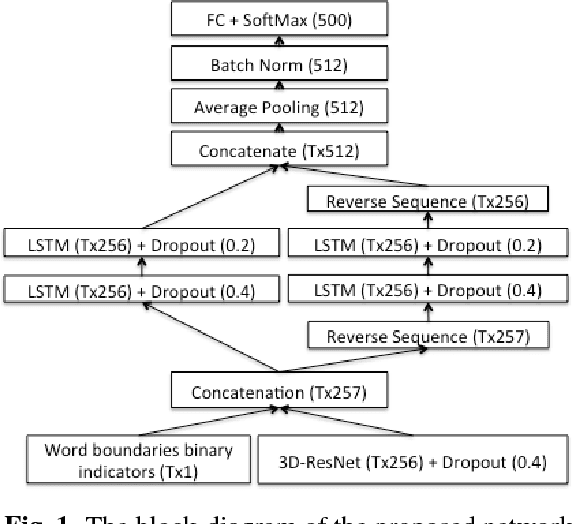
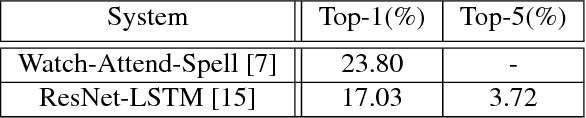
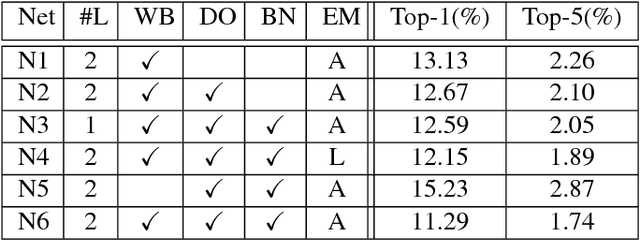

In this paper we present a deep learning architecture for extracting word embeddings for visual speech recognition. The embeddings summarize the information of the mouth region that is relevant to the problem of word recognition, while suppressing other types of variability such as speaker, pose and illumination. The system is comprised of a spatiotemporal convolutional layer, a Residual Network and bidirectional LSTMs and is trained on the Lipreading in-the-wild database. We first show that the proposed architecture goes beyond state-of-the-art on closed-set word identification, by attaining 11.92% error rate on a vocabulary of 500 words. We then examine the capacity of the embeddings in modelling words unseen during training. We deploy Probabilistic Linear Discriminant Analysis (PLDA) to model the embeddings and perform low-shot learning experiments on words unseen during training. The experiments demonstrate that word-level visual speech recognition is feasible even in cases where the target words are not included in the training set.
Squeezeformer: An Efficient Transformer for Automatic Speech Recognition
Jun 02, 2022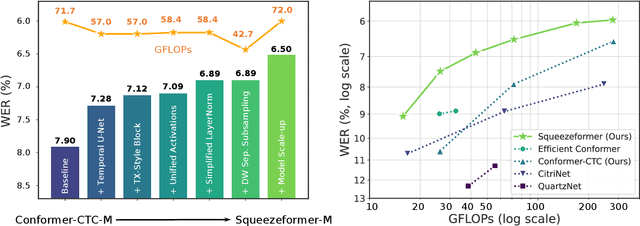
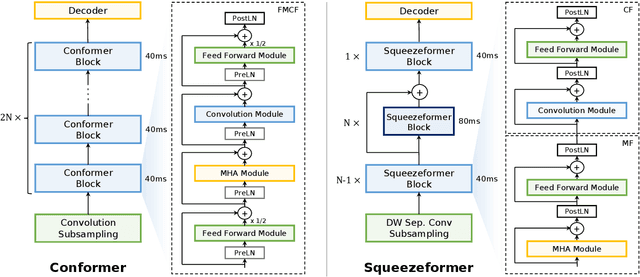
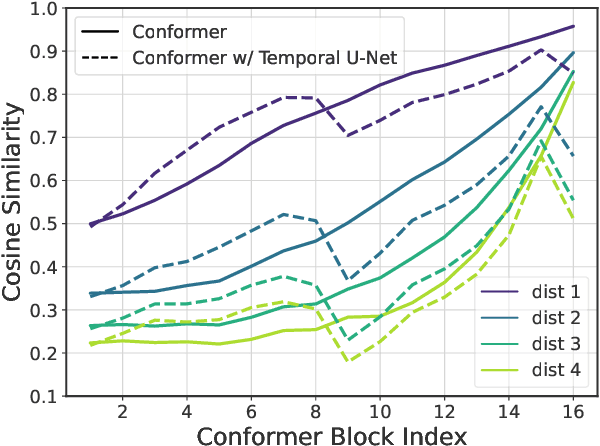
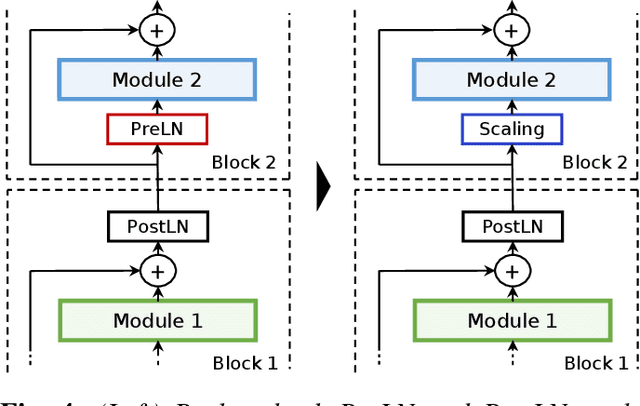
The recently proposed Conformer model has become the de facto backbone model for various downstream speech tasks based on its hybrid attention-convolution architecture that captures both local and global features. However, through a series of systematic studies, we find that the Conformer architecture's design choices are not optimal. After reexamining the design choices for both the macro and micro-architecture of Conformer, we propose the Squeezeformer model, which consistently outperforms the state-of-the-art ASR models under the same training schemes. In particular, for the macro-architecture, Squeezeformer incorporates (i) the Temporal U-Net structure, which reduces the cost of the multi-head attention modules on long sequences, and (ii) a simpler block structure of feed-forward module, followed up by multi-head attention or convolution modules, instead of the Macaron structure proposed in Conformer. Furthermore, for the micro-architecture, Squeezeformer (i) simplifies the activations in the convolutional block, (ii) removes redundant Layer Normalization operations, and (iii) incorporates an efficient depth-wise downsampling layer to efficiently sub-sample the input signal. Squeezeformer achieves state-of-the-art results of 7.5%, 6.5%, and 6.0% word-error-rate on Librispeech test-other without external language models. This is 3.1%, 1.4%, and 0.6% better than Conformer-CTC with the same number of FLOPs. Our code is open-sourced and available online.