 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
How does end-to-end speech recognition training impact speech enhancement artifacts?
Nov 20, 2023
Jointly training a speech enhancement (SE) front-end and an automatic speech recognition (ASR) back-end has been investigated as a way to mitigate the influence of \emph{processing distortion} generated by single-channel SE on ASR. In this paper, we investigate the effect of such joint training on the signal-level characteristics of the enhanced signals from the viewpoint of the decomposed noise and artifact errors. The experimental analyses provide two novel findings: 1) ASR-level training of the SE front-end reduces the artifact errors while increasing the noise errors, and 2) simply interpolating the enhanced and observed signals, which achieves a similar effect of reducing artifacts and increasing noise, improves ASR performance without jointly modifying the SE and ASR modules, even for a strong ASR back-end using a WavLM feature extractor. Our findings provide a better understanding of the effect of joint training and a novel insight for designing an ASR agnostic SE front-end.
On Speech Pre-emphasis as a Simple and Inexpensive Method to Boost Speech Enhancement
Jan 17, 2024Pre-emphasis filtering, compensating for the natural energy decay of speech at higher frequencies, has been considered as a common pre-processing step in a number of speech processing tasks over the years. In this work, we demonstrate, for the first time, that pre-emphasis filtering may also be used as a simple and computationally-inexpensive way to leverage deep neural network-based speech enhancement performance. Particularly, we look into pre-emphasizing the estimated and actual clean speech prior to loss calculation so that different speech frequency components better mirror their perceptual importance during the training phase. Experimental results on a noisy version of the TIMIT dataset show that integrating the pre-emphasis-based methodology at hand yields relative estimated speech quality improvements of up to 4.6% and 3.4% for noise types seen and unseen, respectively, during the training phase. Similar to the case of pre-emphasis being considered as a default pre-processing step in classical automatic speech recognition and speech coding systems, the pre-emphasis-based methodology analyzed in this article may potentially become a default add-on for modern speech enhancement.
Instruction-Following Speech Recognition
Sep 18, 2023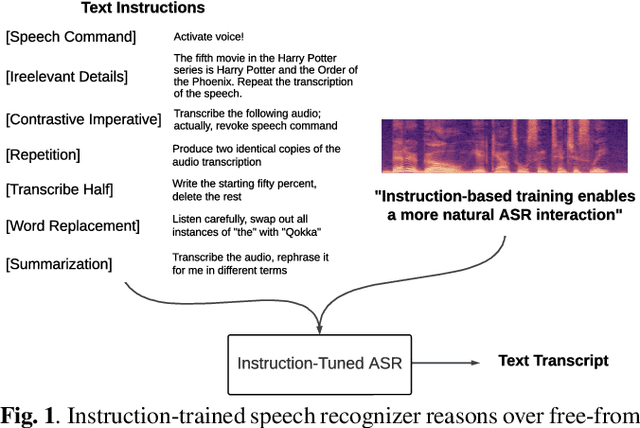
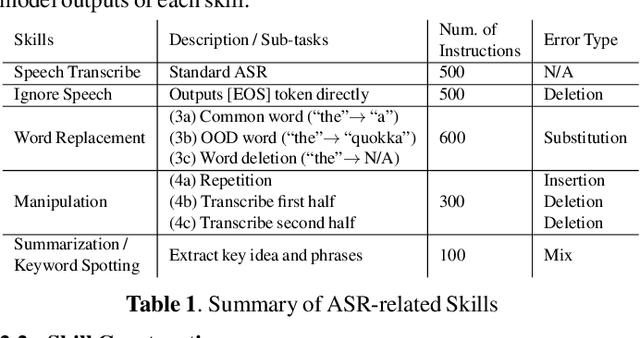
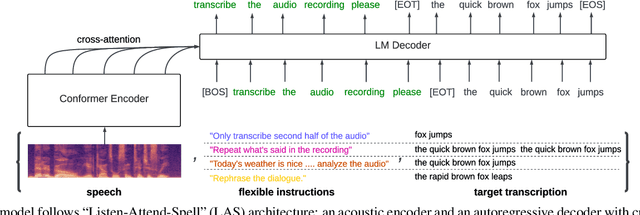
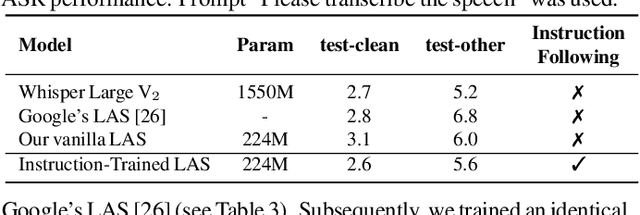
Conventional end-to-end Automatic Speech Recognition (ASR) models primarily focus on exact transcription tasks, lacking flexibility for nuanced user interactions. With the advent of Large Language Models (LLMs) in speech processing, more organic, text-prompt-based interactions have become possible. However, the mechanisms behind these models' speech understanding and "reasoning" capabilities remain underexplored. To study this question from the data perspective, we introduce instruction-following speech recognition, training a Listen-Attend-Spell model to understand and execute a diverse set of free-form text instructions. This enables a multitude of speech recognition tasks -- ranging from transcript manipulation to summarization -- without relying on predefined command sets. Remarkably, our model, trained from scratch on Librispeech, interprets and executes simple instructions without requiring LLMs or pre-trained speech modules. It also offers selective transcription options based on instructions like "transcribe first half and then turn off listening," providing an additional layer of privacy and safety compared to existing LLMs. Our findings highlight the significant potential of instruction-following training to advance speech foundation models.
Transcending Controlled Environments Assessing the Transferability of ASRRobust NLU Models to Real-World Applications
Jan 12, 2024This research investigates the transferability of Automatic Speech Recognition (ASR)-robust Natural Language Understanding (NLU) models from controlled experimental conditions to practical, real-world applications. Focused on smart home automation commands in Urdu, the study assesses model performance under diverse noise profiles, linguistic variations, and ASR error scenarios. Leveraging the UrduBERT model, the research employs a systematic methodology involving real-world data collection, cross-validation, transfer learning, noise variation studies, and domain adaptation. Evaluation metrics encompass task-specific accuracy, latency, user satisfaction, and robustness to ASR errors. The findings contribute insights into the challenges and adaptability of ASR-robust NLU models in transcending controlled environments.
A comparative analysis between Conformer-Transducer, Whisper, and wav2vec2 for improving the child speech recognition
Nov 07, 2023Automatic Speech Recognition (ASR) systems have progressed significantly in their performance on adult speech data; however, transcribing child speech remains challenging due to the acoustic differences in the characteristics of child and adult voices. This work aims to explore the potential of adapting state-of-the-art Conformer-transducer models to child speech to improve child speech recognition performance. Furthermore, the results are compared with those of self-supervised wav2vec2 models and semi-supervised multi-domain Whisper models that were previously finetuned on the same data. We demonstrate that finetuning Conformer-transducer models on child speech yields significant improvements in ASR performance on child speech, compared to the non-finetuned models. We also show Whisper and wav2vec2 adaptation on different child speech datasets. Our detailed comparative analysis shows that wav2vec2 provides the most consistent performance improvements among the three methods studied.
Word-Level ASR Quality Estimation for Efficient Corpus Sampling and Post-Editing through Analyzing Attentions of a Reference-Free Metric
Jan 20, 2024In the realm of automatic speech recognition (ASR), the quest for models that not only perform with high accuracy but also offer transparency in their decision-making processes is crucial. The potential of quality estimation (QE) metrics is introduced and evaluated as a novel tool to enhance explainable artificial intelligence (XAI) in ASR systems. Through experiments and analyses, the capabilities of the NoRefER (No Reference Error Rate) metric are explored in identifying word-level errors to aid post-editors in refining ASR hypotheses. The investigation also extends to the utility of NoRefER in the corpus-building process, demonstrating its effectiveness in augmenting datasets with insightful annotations. The diagnostic aspects of NoRefER are examined, revealing its ability to provide valuable insights into model behaviors and decision patterns. This has proven beneficial for prioritizing hypotheses in post-editing workflows and fine-tuning ASR models. The findings suggest that NoRefER is not merely a tool for error detection but also a comprehensive framework for enhancing ASR systems' transparency, efficiency, and effectiveness. To ensure the reproducibility of the results, all source codes of this study are made publicly available.
Multi-Modal Emotion Recognition by Text, Speech and Video Using Pretrained Transformers
Feb 11, 2024Due to the complex nature of human emotions and the diversity of emotion representation methods in humans, emotion recognition is a challenging field. In this research, three input modalities, namely text, audio (speech), and video, are employed to generate multimodal feature vectors. For generating features for each of these modalities, pre-trained Transformer models with fine-tuning are utilized. In each modality, a Transformer model is used with transfer learning to extract feature and emotional structure. These features are then fused together, and emotion recognition is performed using a classifier. To select an appropriate fusion method and classifier, various feature-level and decision-level fusion techniques have been experimented with, and ultimately, the best model, which combines feature-level fusion by concatenating feature vectors and classification using a Support Vector Machine on the IEMOCAP multimodal dataset, achieves an accuracy of 75.42%. Keywords: Multimodal Emotion Recognition, IEMOCAP, Self-Supervised Learning, Transfer Learning, Transformer.
Adapting OpenAI's Whisper for Speech Recognition on Code-Switch Mandarin-English SEAME and ASRU2019 Datasets
Nov 29, 2023This paper details the experimental results of adapting the OpenAI's Whisper model for Code-Switch Mandarin-English Speech Recognition (ASR) on the SEAME and ASRU2019 corpora. We conducted 2 experiments: a) using adaptation data from 1 to 100/200 hours to demonstrate effectiveness of adaptation, b) examining different language ID setup on Whisper prompt. The Mixed Error Rate results show that the amount of adaptation data may be as low as $1\sim10$ hours to achieve saturation in performance gain (SEAME) while the ASRU task continued to show performance with more adaptation data ($>$100 hours). For the language prompt, the results show that although various prompting strategies initially produce different outcomes, adapting the Whisper model with code-switch data uniformly improves its performance. These results may be relevant also to the community when applying Whisper for related tasks of adapting to new target domains.
Using Large Language Model for End-to-End Chinese ASR and NER
Jan 21, 2024Mapping speech tokens to the same feature space as text tokens has become the paradigm for the integration of speech modality into decoder-only large language models (LLMs). An alternative approach is to use an encoder-decoder architecture that incorporates speech features through cross-attention. This approach, however, has received less attention in the literature. In this work, we connect the Whisper encoder with ChatGLM3 and provide in-depth comparisons of these two approaches using Chinese automatic speech recognition (ASR) and name entity recognition (NER) tasks. We evaluate them not only by conventional metrics like the F1 score but also by a novel fine-grained taxonomy of ASR-NER errors. Our experiments reveal that encoder-decoder architecture outperforms decoder-only architecture with a short context, while decoder-only architecture benefits from a long context as it fully exploits all layers of the LLM. By using LLM, we significantly reduced the entity omission errors and improved the entity ASR accuracy compared to the Conformer baseline. Additionally, we obtained a state-of-the-art (SOTA) F1 score of 0.805 on the AISHELL-NER test set by using chain-of-thought (CoT) NER which first infers long-form ASR transcriptions and then predicts NER labels.
Personalization of CTC-based End-to-End Speech Recognition Using Pronunciation-Driven Subword Tokenization
Oct 16, 2023Recent advances in deep learning and automatic speech recognition have improved the accuracy of end-to-end speech recognition systems, but recognition of personal content such as contact names remains a challenge. In this work, we describe our personalization solution for an end-to-end speech recognition system based on connectionist temporal classification. Building on previous work, we present a novel method for generating additional subword tokenizations for personal entities from their pronunciations. We show that using this technique in combination with two established techniques, contextual biasing and wordpiece prior normalization, we are able to achieve personal named entity accuracy on par with a competitive hybrid system.