 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Robust Data2vec: Noise-robust Speech Representation Learning for ASR by Combining Regression and Improved Contrastive Learning
Oct 27, 2022
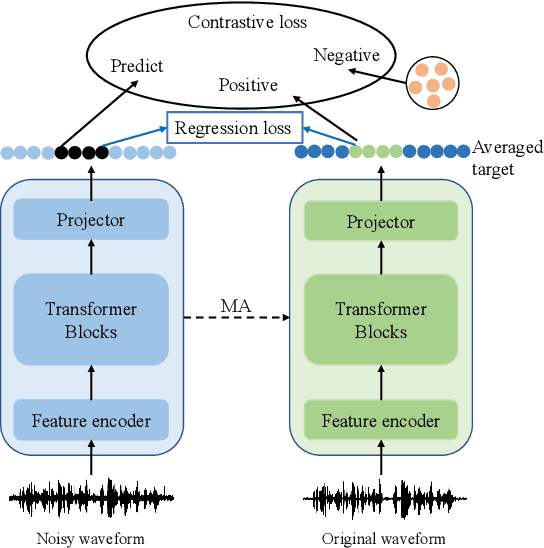
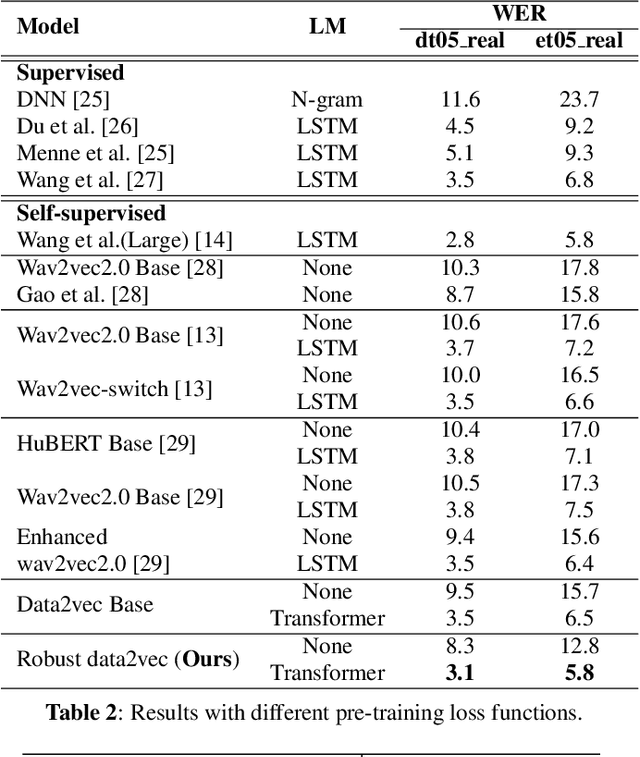

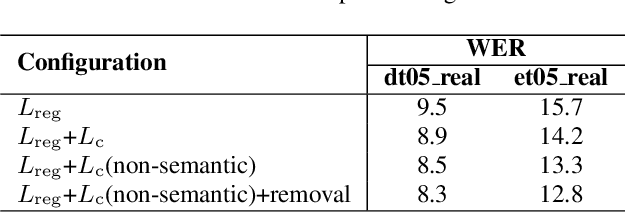
Self-supervised pre-training methods based on contrastive learning or regression tasks can utilize more unlabeled data to improve the performance of automatic speech recognition (ASR). However, the robustness impact of combining the two pre-training tasks and constructing different negative samples for contrastive learning still remains unclear. In this paper, we propose a noise-robust data2vec for self-supervised speech representation learning by jointly optimizing the contrastive learning and regression tasks in the pre-training stage. Furthermore, we present two improved methods to facilitate contrastive learning. More specifically, we first propose to construct patch-based non-semantic negative samples to boost the noise robustness of the pre-training model, which is achieved by dividing the features into patches at different sizes (i.e., so-called negative samples). Second, by analyzing the distribution of positive and negative samples, we propose to remove the easily distinguishable negative samples to improve the discriminative capacity for pre-training models. Experimental results on the CHiME-4 dataset show that our method is able to improve the performance of the pre-trained model in noisy scenarios. We find that joint training of the contrastive learning and regression tasks can avoid the model collapse to some extent compared to only training the regression task.
Visual Speech Recognition
Sep 03, 2014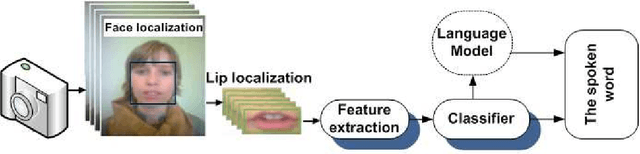
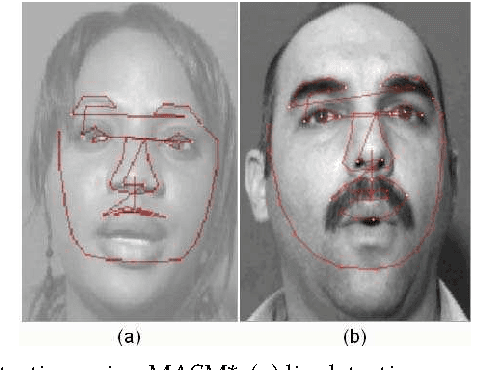
Lip reading is used to understand or interpret speech without hearing it, a technique especially mastered by people with hearing difficulties. The ability to lip read enables a person with a hearing impairment to communicate with others and to engage in social activities, which otherwise would be difficult. Recent advances in the fields of computer vision, pattern recognition, and signal processing has led to a growing interest in automating this challenging task of lip reading. Indeed, automating the human ability to lip read, a process referred to as visual speech recognition (VSR) (or sometimes speech reading), could open the door for other novel related applications. VSR has received a great deal of attention in the last decade for its potential use in applications such as human-computer interaction (HCI), audio-visual speech recognition (AVSR), speaker recognition, talking heads, sign language recognition and video surveillance. Its main aim is to recognise spoken word(s) by using only the visual signal that is produced during speech. Hence, VSR deals with the visual domain of speech and involves image processing, artificial intelligence, object detection, pattern recognition, statistical modelling, etc.
Multi-Classifier Interactive Learning for Ambiguous Speech Emotion Recognition
Dec 12, 2020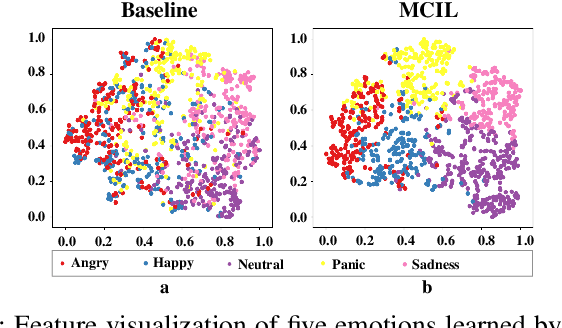
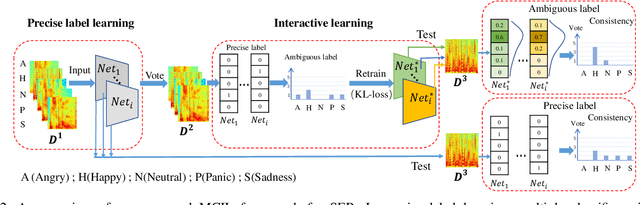
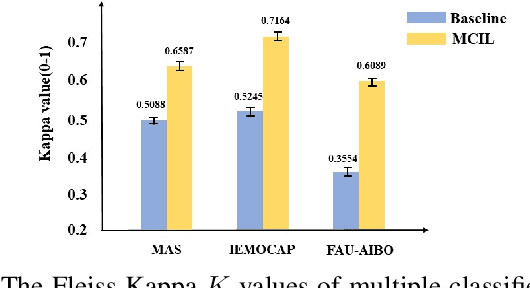
In recent years, speech emotion recognition technology is of great significance in industrial applications such as call centers, social robots and health care. The combination of speech recognition and speech emotion recognition can improve the feedback efficiency and the quality of service. Thus, the speech emotion recognition has been attracted much attention in both industry and academic. Since emotions existing in an entire utterance may have varied probabilities, speech emotion is likely to be ambiguous, which poses great challenges to recognition tasks. However, previous studies commonly assigned a single-label or multi-label to each utterance in certain. Therefore, their algorithms result in low accuracies because of the inappropriate representation. Inspired by the optimally interacting theory, we address the ambiguous speech emotions by proposing a novel multi-classifier interactive learning (MCIL) method. In MCIL, multiple different classifiers first mimic several individuals, who have inconsistent cognitions of ambiguous emotions, and construct new ambiguous labels (the emotion probability distribution). Then, they are retrained with the new labels to interact with their cognitions. This procedure enables each classifier to learn better representations of ambiguous data from others, and further improves the recognition ability. The experiments on three benchmark corpora (MAS, IEMOCAP, and FAU-AIBO) demonstrate that MCIL does not only improve each classifier's performance, but also raises their recognition consistency from moderate to substantial.
Dynamic Sparsity Neural Networks for Automatic Speech Recognition
May 16, 2020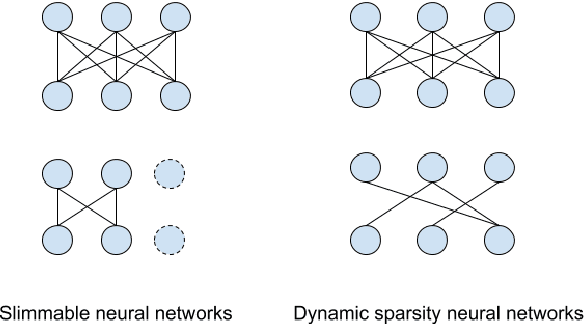
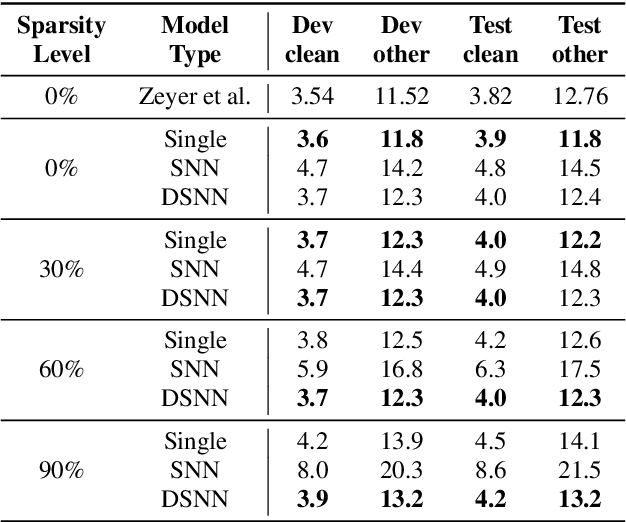
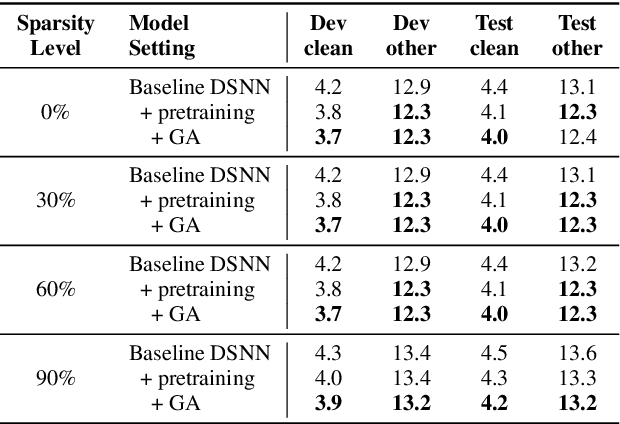
In automatic speech recognition (ASR), model pruning is a widely adopted technique that reduces model size and latency to deploy neural network models on edge devices with resource constraints. However, in order to optimize for hardware with different resource specifications and for applications that have various latency requirements, models with varying sparsity levels usually need to be trained and deployed separately. In this paper, generalizing from slimmable neural networks, we present dynamic sparsity neural networks (DSNN) that, once trained, can instantly switch to execute at any given sparsity level at run-time. We show the efficacy of such models on ASR through comprehensive experiments and demonstrate that the performance of a dynamic sparsity model is on par with, and in some cases exceeds, the performance of individually trained single sparsity networks. A trained DSNN model can therefore greatly ease the training process and simplifies deployment in diverse scenarios with resource constraints.
SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition
Apr 18, 2019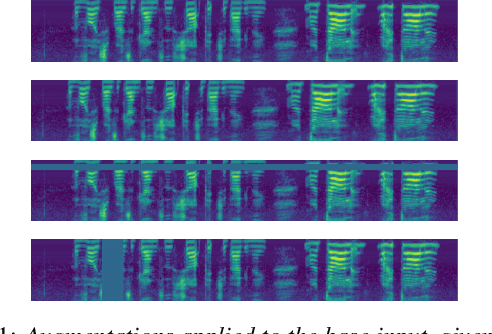
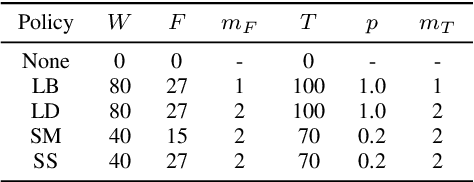
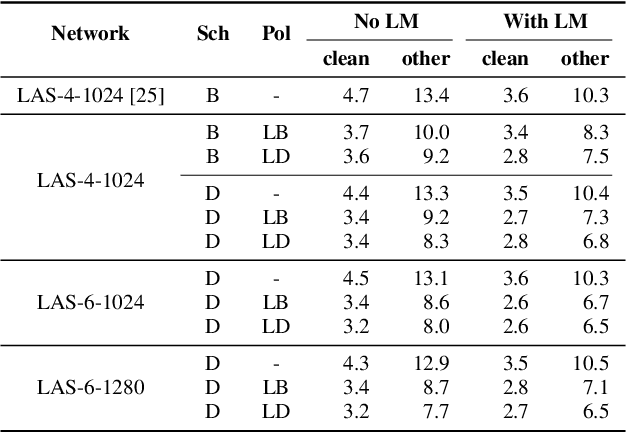
We present SpecAugment, a simple data augmentation method for speech recognition. SpecAugment is applied directly to the feature inputs of a neural network (i.e., filter bank coefficients). The augmentation policy consists of warping the features, masking blocks of frequency channels, and masking blocks of time steps. We apply SpecAugment on Listen, Attend and Spell networks for end-to-end speech recognition tasks. We achieve state-of-the-art performance on the LibriSpeech 960h and Swichboard 300h tasks, outperforming all prior work. On LibriSpeech, we achieve 6.8% WER on test-other without the use of a language model, and 5.8% WER with shallow fusion with a language model. This compares to the previous state-of-the-art hybrid system of 7.5% WER. For Switchboard, we achieve 7.2%/14.6% on the Switchboard/CallHome portion of the Hub5'00 test set without the use of a language model, and 6.8%/14.1% with shallow fusion, which compares to the previous state-of-the-art hybrid system at 8.3%/17.3% WER.
Self-Attention Networks for Connectionist Temporal Classification in Speech Recognition
Jan 22, 2019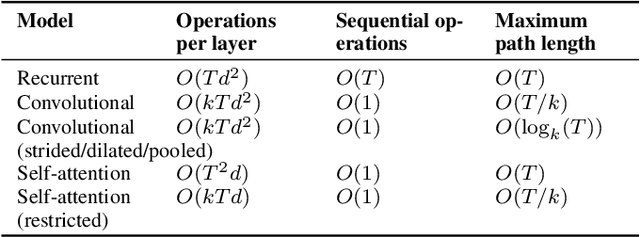
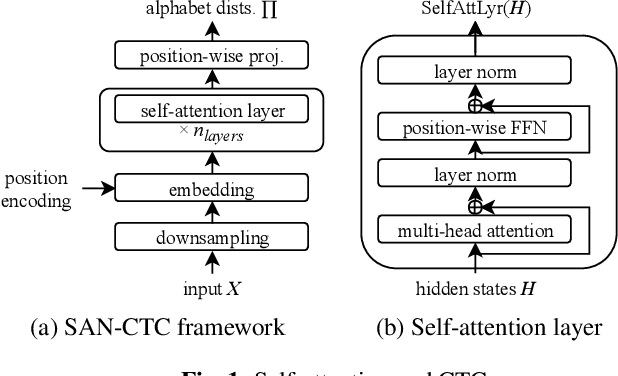
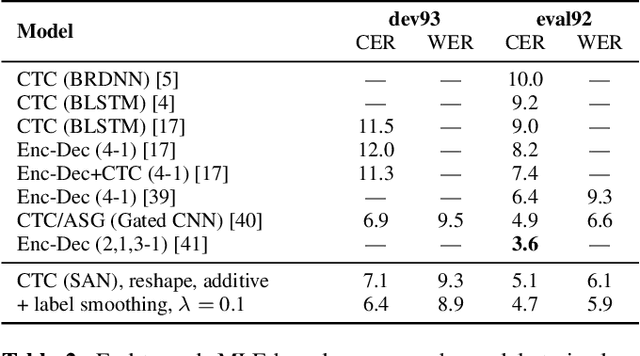
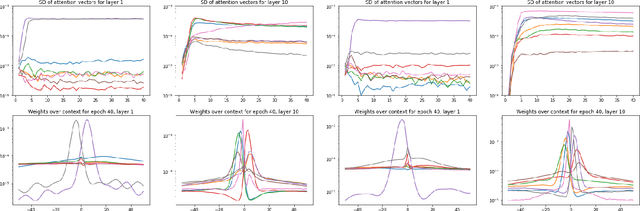
Self-attention has demonstrated great success in sequence-to-sequence tasks in natural language processing, with preliminary work applying it to end-to-end encoder-decoder approaches in speech recognition. Separately, connectionist temporal classification (CTC) has matured as an alignment-free strategy for monotonic sequence transduction, either by itself or in various multitask and decoding frameworks. We propose SAN-CTC, a deep, fully self-attentional network for CTC, and show it is tractable and competitive for speech recognition. On the Wall Street Journal and LibriSpeech datasets, SAN-CTC trains quickly and outperforms existing CTC models and most encoder-decoder models, attaining 4.7% CER in 1 day and 2.8% CER in 1 week respectively, using the same architecture and one GPU. We motivate the architecture for speech, evaluate position and downsampling approaches, and explore how the label alphabet affects attention head and performance outcomes.
Speech Emotion Recognition using Self-Supervised Features
Feb 07, 2022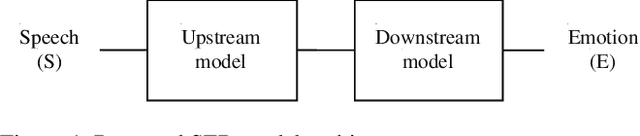
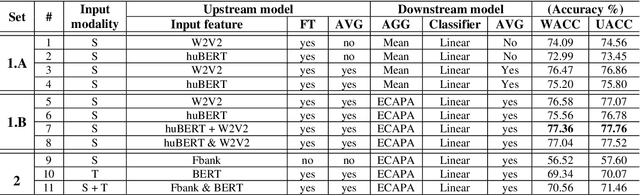
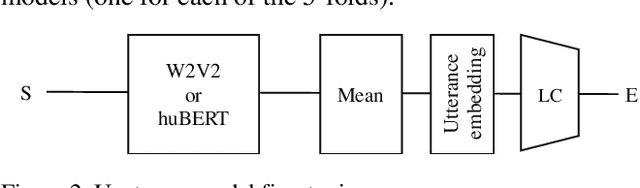
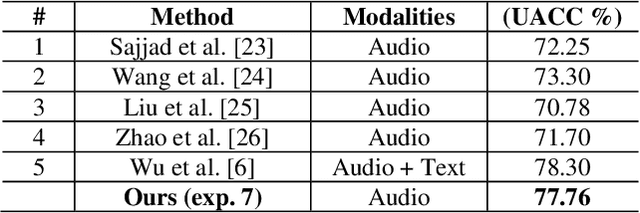
Self-supervised pre-trained features have consistently delivered state-of-art results in the field of natural language processing (NLP); however, their merits in the field of speech emotion recognition (SER) still need further investigation. In this paper we introduce a modular End-to- End (E2E) SER system based on an Upstream + Downstream architecture paradigm, which allows easy use/integration of a large variety of self-supervised features. Several SER experiments for predicting categorical emotion classes from the IEMOCAP dataset are performed. These experiments investigate interactions among fine-tuning of self-supervised feature models, aggregation of frame-level features into utterance-level features and back-end classification networks. The proposed monomodal speechonly based system not only achieves SOTA results, but also brings light to the possibility of powerful and well finetuned self-supervised acoustic features that reach results similar to the results achieved by SOTA multimodal systems using both Speech and Text modalities.
Distilling Knowledge from Ensembles of Acoustic Models for Joint CTC-Attention End-to-End Speech Recognition
May 19, 2020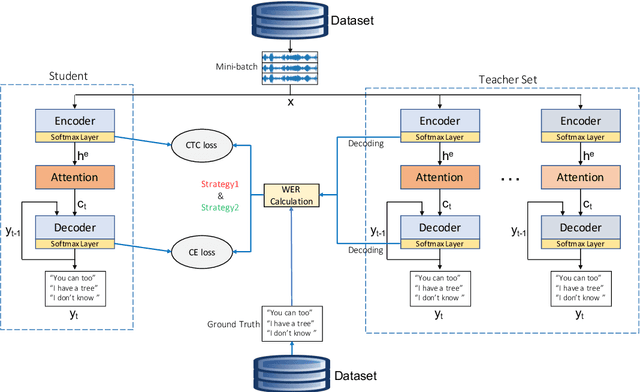
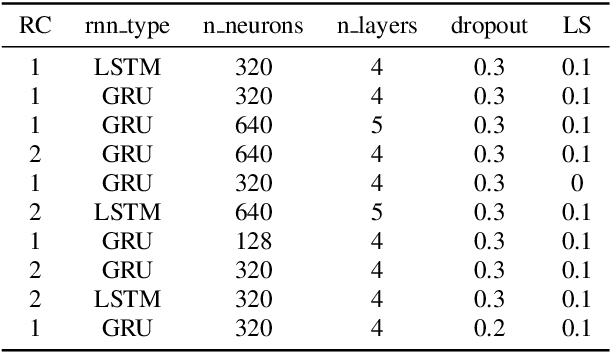
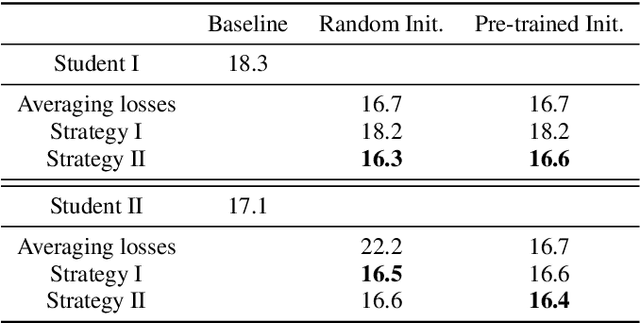
Knowledge distillation has been widely used to compress existing deep learning models while preserving the performance on a wide range of applications. In the specific context of Automatic Speech Recognition (ASR), distillation from ensembles of acoustic models has recently shown promising results in increasing recognition performance. In this paper, we propose an extension of multi-teacher distillation methods to joint ctc-atention end-to-end ASR systems. We also introduce two novel distillation strategies. The core intuition behind both is to integrate the error rate metric to the teacher selection rather than solely focusing on the observed losses. This way, we directly distillate and optimize the student toward the relevant metric for speech recognition. We evaluated these strategies under a selection of training procedures on the TIMIT phoneme recognition task and observed promising error rate for these strategies compared to a common baseline. Indeed, the best obtained phoneme error rate of 16.4% represents a state-of-the-art score for end-to-end ASR systems.
Bayesian Recurrent Units and the Forward-Backward Algorithm
Jul 21, 2022

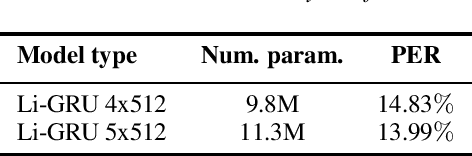
Using Bayes's theorem, we derive a unit-wise recurrence as well as a backward recursion similar to the forward-backward algorithm. The resulting Bayesian recurrent units can be integrated as recurrent neural networks within deep learning frameworks, while retaining a probabilistic interpretation from the direct correspondence with hidden Markov models. Whilst the contribution is mainly theoretical, experiments on speech recognition indicate that adding the derived units at the end of state-of-the-art recurrent architectures can improve the performance at a very low cost in terms of trainable parameters.
Acoustic-to-articulatory Speech Inversion with Multi-task Learning
May 27, 2022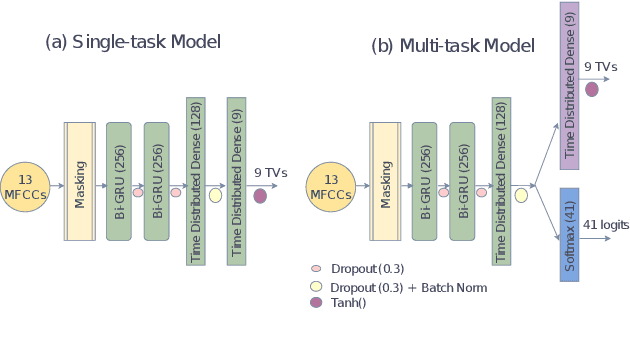


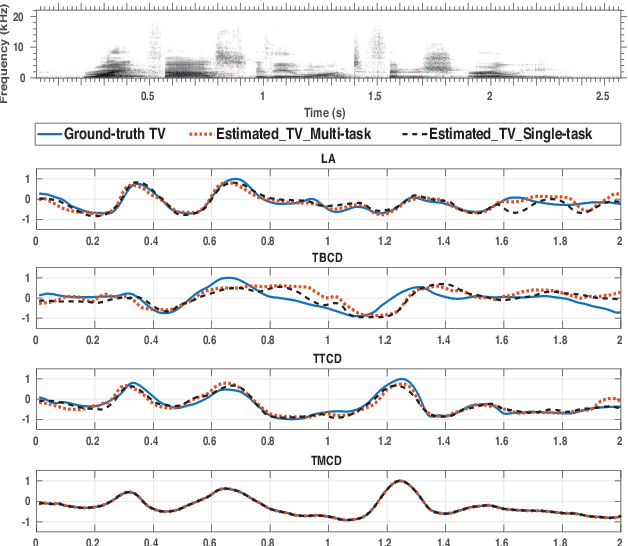
Multi-task learning (MTL) frameworks have proven to be effective in diverse speech related tasks like automatic speech recognition (ASR) and speech emotion recognition. This paper proposes a MTL framework to perform acoustic-to-articulatory speech inversion by simultaneously learning an acoustic to phoneme mapping as a shared task. We use the Haskins Production Rate Comparison (HPRC) database which has both the electromagnetic articulography (EMA) data and the corresponding phonetic transcriptions. Performance of the system was measured by computing the correlation between estimated and actual tract variables (TVs) from the acoustic to articulatory speech inversion task. The proposed MTL based Bidirectional Gated Recurrent Neural Network (RNN) model learns to map the input acoustic features to nine TVs while outperforming the baseline model trained to perform only acoustic to articulatory inversion.