 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Dynamic Bayesian Multinets
Jan 16, 2013
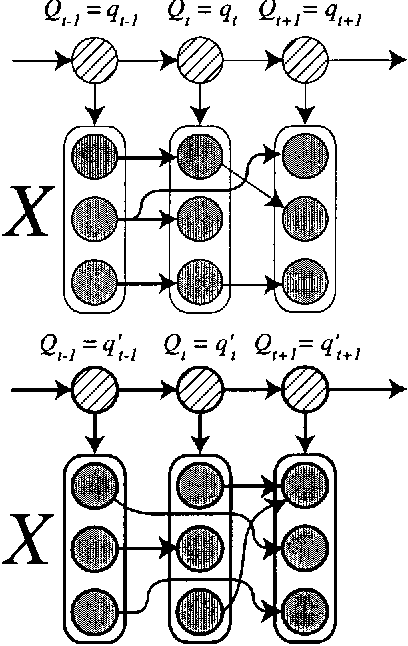
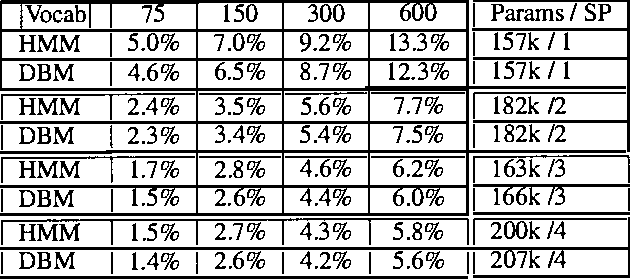
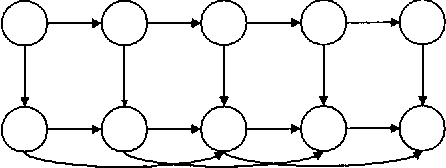
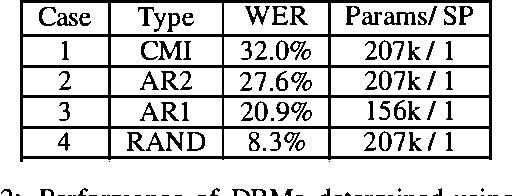
In this work, dynamic Bayesian multinets are introduced where a Markov chain state at time t determines conditional independence patterns between random variables lying within a local time window surrounding t. It is shown how information-theoretic criterion functions can be used to induce sparse, discriminative, and class-conditional network structures that yield an optimal approximation to the class posterior probability, and therefore are useful for the classification task. Using a new structure learning heuristic, the resulting models are tested on a medium-vocabulary isolated-word speech recognition task. It is demonstrated that these discriminatively structured dynamic Bayesian multinets, when trained in a maximum likelihood setting using EM, can outperform both HMMs and other dynamic Bayesian networks with a similar number of parameters.
A Hindi Speech Actuated Computer Interface for Web Search
Nov 12, 2012
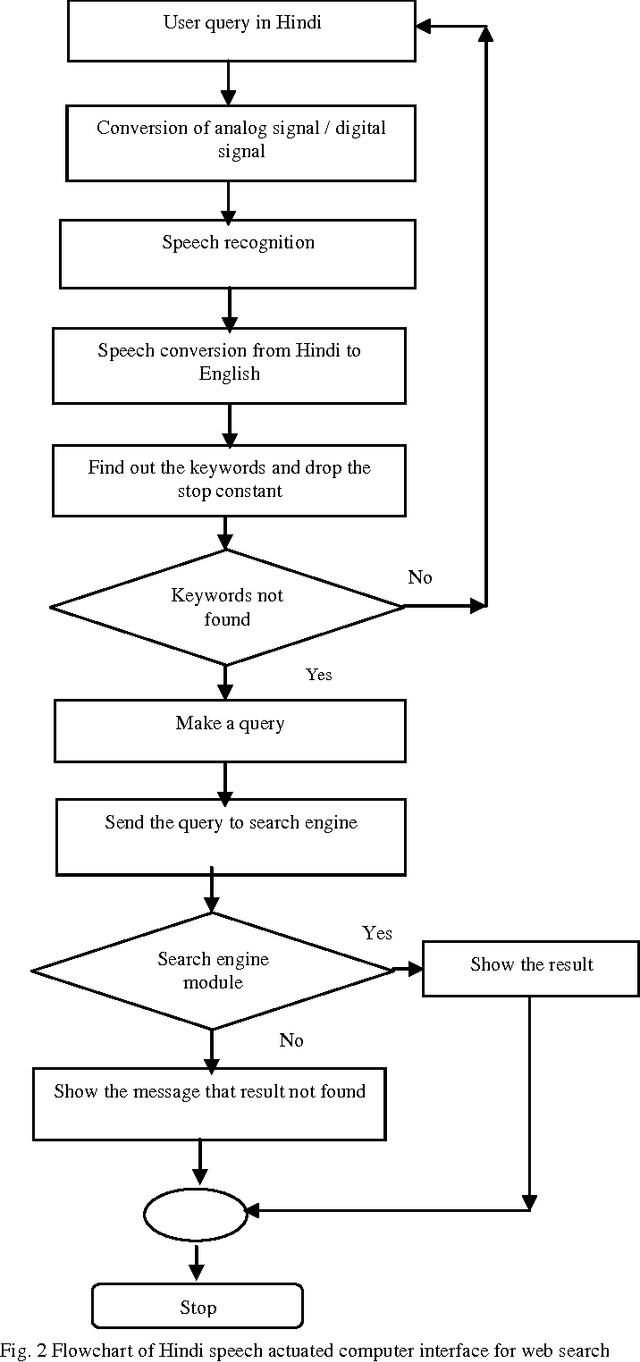

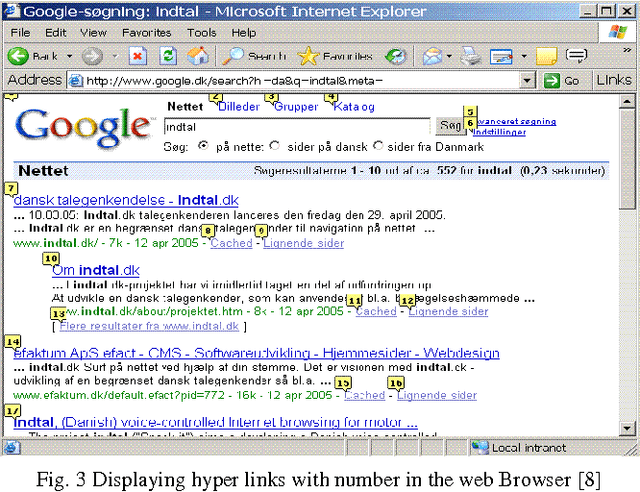
Aiming at increasing system simplicity and flexibility, an audio evoked based system was developed by integrating simplified headphone and user-friendly software design. This paper describes a Hindi Speech Actuated Computer Interface for Web search (HSACIWS), which accepts spoken queries in Hindi language and provides the search result on the screen. This system recognizes spoken queries by large vocabulary continuous speech recognition (LVCSR), retrieves relevant document by text retrieval, and provides the search result on the Web by the integration of the Web and the voice systems. The LVCSR in this system showed enough performance levels for speech with acoustic and language models derived from a query corpus with target contents.
* 7 pages
Sufficient Dimensionality Reduction with Irrelevant Statistics
Oct 19, 2012
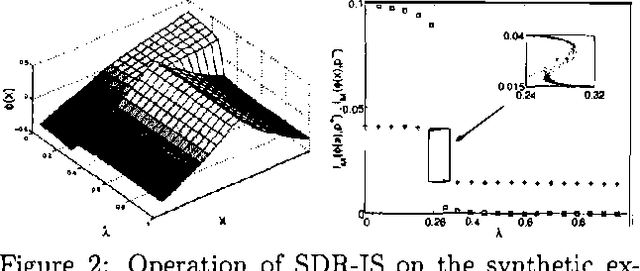

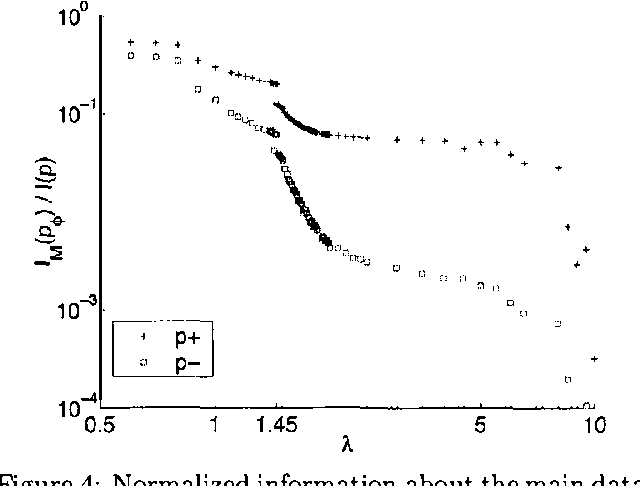
The problem of finding a reduced dimensionality representation of categorical variables while preserving their most relevant characteristics is fundamental for the analysis of complex data. Specifically, given a co-occurrence matrix of two variables, one often seeks a compact representation of one variable which preserves information about the other variable. We have recently introduced ``Sufficient Dimensionality Reduction' [GT-2003], a method that extracts continuous reduced dimensional features whose measurements (i.e., expectation values) capture maximal mutual information among the variables. However, such measurements often capture information that is irrelevant for a given task. Widely known examples are illumination conditions, which are irrelevant as features for face recognition, writing style which is irrelevant as a feature for content classification, and intonation which is irrelevant as a feature for speech recognition. Such irrelevance cannot be deduced apriori, since it depends on the details of the task, and is thus inherently ill defined in the purely unsupervised case. Separating relevant from irrelevant features can be achieved using additional side data that contains such irrelevant structures. This approach was taken in [CT-2002], extending the information bottleneck method, which uses clustering to compress the data. Here we use this side-information framework to identify features whose measurements are maximally informative for the original data set, but carry as little information as possible on a side data set. In statistical terms this can be understood as extracting statistics which are maximally sufficient for the original dataset, while simultaneously maximally ancillary for the side dataset. We formulate this tradeoff as a constrained optimization problem and characterize its solutions. We then derive a gradient descent algorithm for this problem, which is based on the Generalized Iterative Scaling method for finding maximum entropy distributions. The method is demonstrated on synthetic data, as well as on real face recognition datasets, and is shown to outperform standard methods such as oriented PCA.
On Triangulating Dynamic Graphical Models
Oct 19, 2012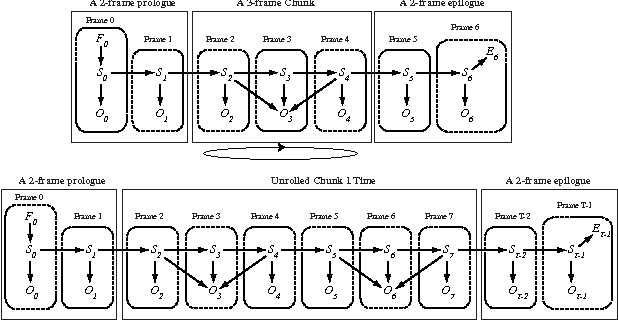
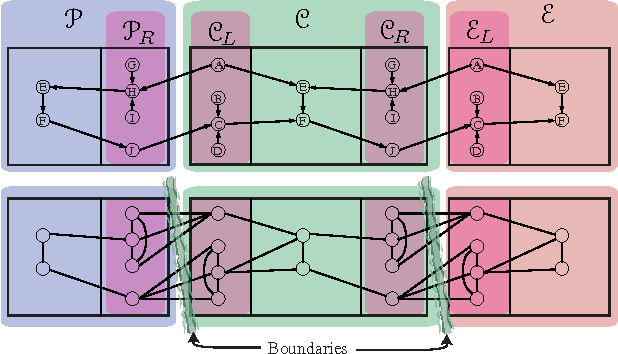
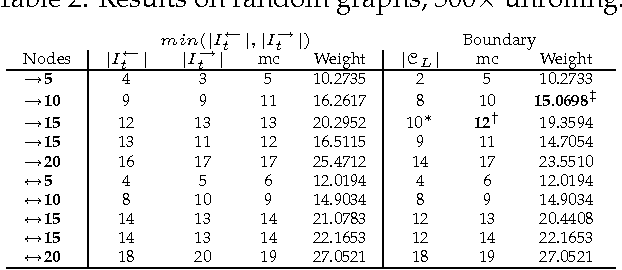
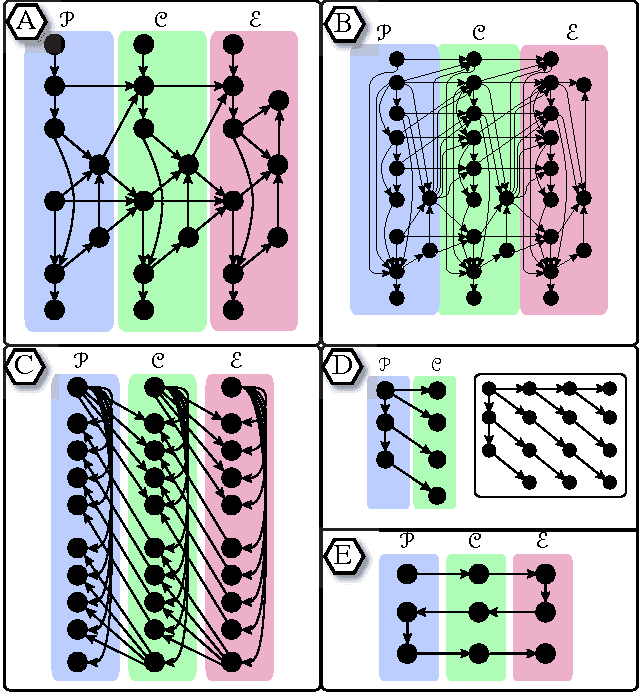
This paper introduces new methodology to triangulate dynamic Bayesian networks (DBNs) and dynamic graphical models (DGMs). While most methods to triangulate such networks use some form of constrained elimination scheme based on properties of the underlying directed graph, we find it useful to view triangulation and elimination using properties only of the resulting undirected graph, obtained after the moralization step. We first briefly introduce the Graphical model toolkit (GMTK) and its notion of dynamic graphical models, one that slightly extends the standard notion of a DBN. We next introduce the 'boundary algorithm', a method to find the best boundary between partitions in a dynamic model. We find that using this algorithm, the notions of forward- and backward-interface become moot - namely, the size and fill-in of the best forward- and backward- interface are identical. Moreover, we observe that finding a good partition boundary allows for constrained elimination orders (and therefore graph triangulations) that are not possible using standard slice-by-slice constrained eliminations. More interestingly, with certain boundaries it is possible to obtain constrained elimination schemes that lie outside the space of possible triangulations using only unconstrained elimination. Lastly, we report triangulation results on invented graphs, standard DBNs from the literature, novel DBNs used in speech recognition research systems, and also random graphs. Using a number of different triangulation quality measures (max clique size, state-space, etc.), we find that with our boundary algorithm the triangulation quality can dramatically improve.
Structured Sparsity Models for Multiparty Speech Recovery from Reverberant Recordings
Oct 25, 2012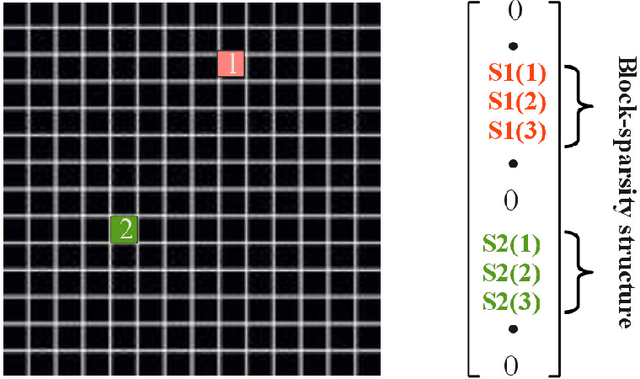
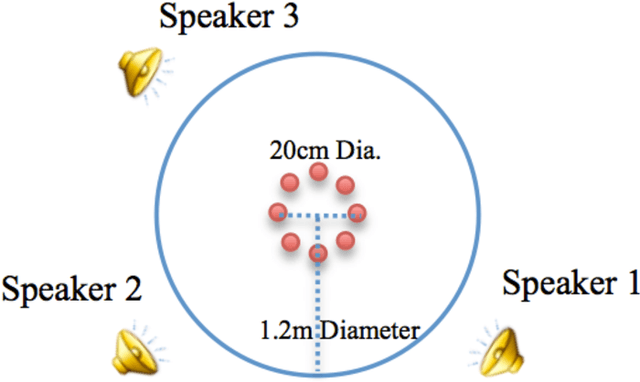
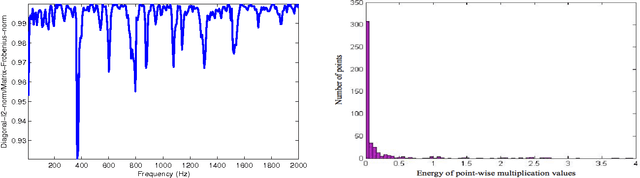
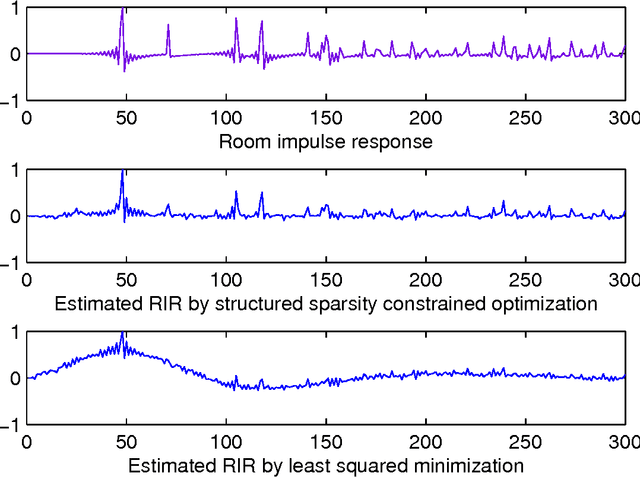
We tackle the multi-party speech recovery problem through modeling the acoustic of the reverberant chambers. Our approach exploits structured sparsity models to perform room modeling and speech recovery. We propose a scheme for characterizing the room acoustic from the unknown competing speech sources relying on localization of the early images of the speakers by sparse approximation of the spatial spectra of the virtual sources in a free-space model. The images are then clustered exploiting the low-rank structure of the spectro-temporal components belonging to each source. This enables us to identify the early support of the room impulse response function and its unique map to the room geometry. To further tackle the ambiguity of the reflection ratios, we propose a novel formulation of the reverberation model and estimate the absorption coefficients through a convex optimization exploiting joint sparsity model formulated upon spatio-spectral sparsity of concurrent speech representation. The acoustic parameters are then incorporated for separating individual speech signals through either structured sparse recovery or inverse filtering the acoustic channels. The experiments conducted on real data recordings demonstrate the effectiveness of the proposed approach for multi-party speech recovery and recognition.
Spike Timing Dependent Competitive Learning in Recurrent Self Organizing Pulsed Neural Networks Case Study: Phoneme and Word Recognition
Sep 24, 2012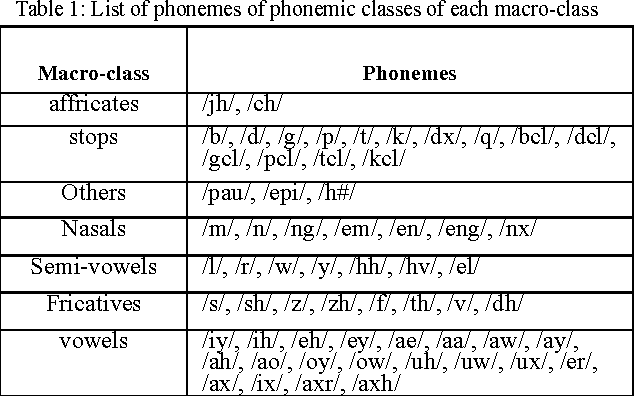
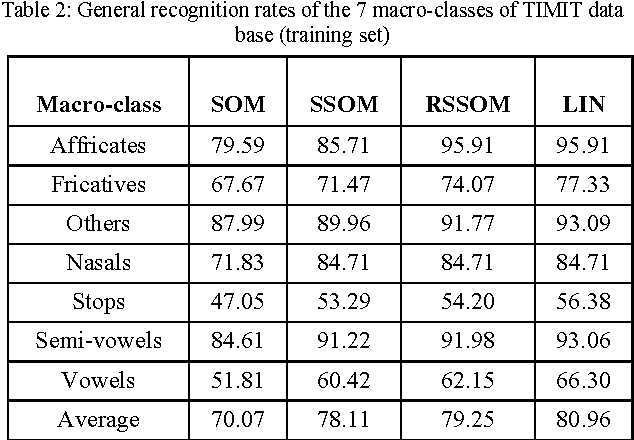
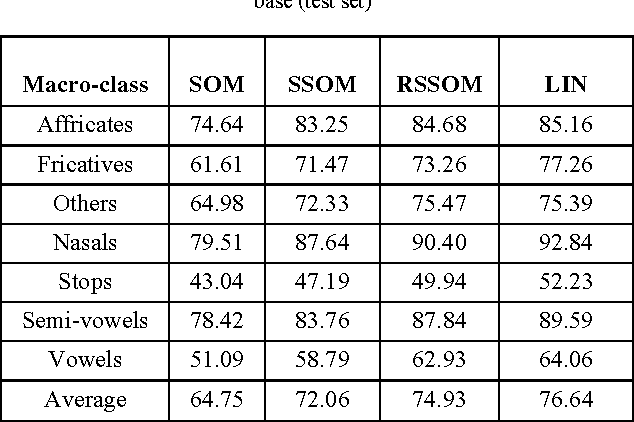
Synaptic plasticity seems to be a capital aspect of the dynamics of neural networks. It is about the physiological modifications of the synapse, which have like consequence a variation of the value of the synaptic weight. The information encoding is based on the precise timing of single spike events that is based on the relative timing of the pre- and post-synaptic spikes, local synapse competitions within a single neuron and global competition via lateral connections. In order to classify temporal sequences, we present in this paper how to use a local hebbian learning, spike-timing dependent plasticity for unsupervised competitive learning, preserving self-organizing maps of spiking neurons. In fact we present three variants of self-organizing maps (SOM) with spike-timing dependent Hebbian learning rule, the Leaky Integrators Neurons (LIN), the Spiking_SOM and the recurrent Spiking_SOM (RSSOM) models. The case study of the proposed SOM variants is phoneme classification and word recognition in continuous speech and speaker independent.
* 10 pages, 15 tables
ASR Context-Sensitive Error Correction Based on Microsoft N-Gram Dataset
Mar 23, 2012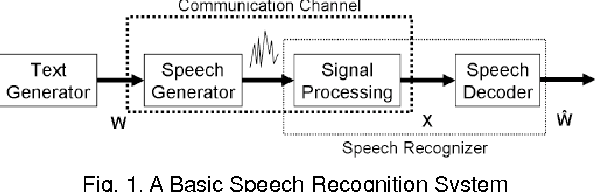

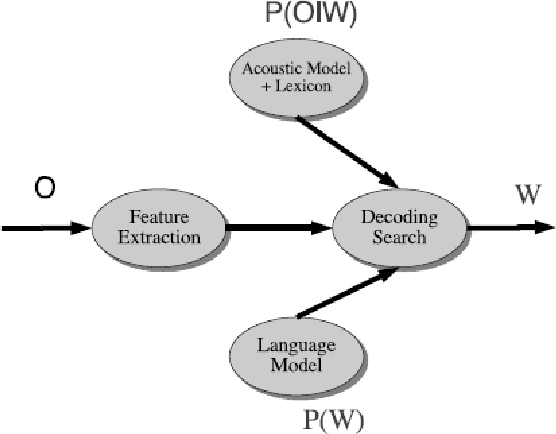
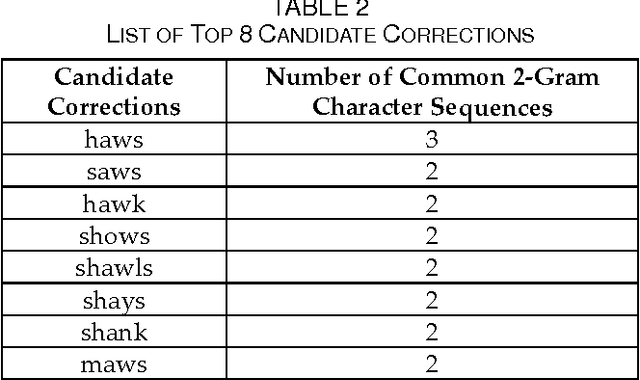
At the present time, computers are employed to solve complex tasks and problems ranging from simple calculations to intensive digital image processing and intricate algorithmic optimization problems to computationally-demanding weather forecasting problems. ASR short for Automatic Speech Recognition is yet another type of computational problem whose purpose is to recognize human spoken speech and convert it into text that can be processed by a computer. Despite that ASR has many versatile and pervasive real-world applications,it is still relatively erroneous and not perfectly solved as it is prone to produce spelling errors in the recognized text, especially if the ASR system is operating in a noisy environment, its vocabulary size is limited, and its input speech is of bad or low quality. This paper proposes a post-editing ASR error correction method based on MicrosoftN-Gram dataset for detecting and correcting spelling errors generated by ASR systems. The proposed method comprises an error detection algorithm for detecting word errors; a candidate corrections generation algorithm for generating correction suggestions for the detected word errors; and a context-sensitive error correction algorithm for selecting the best candidate for correction. The virtue of using the Microsoft N-Gram dataset is that it contains real-world data and word sequences extracted from the web which canmimica comprehensive dictionary of words having a large and all-inclusive vocabulary. Experiments conducted on numerous speeches, performed by different speakers, showed a remarkable reduction in ASR errors. Future research can improve upon the proposed algorithm so much so that it can be parallelized to take advantage of multiprocessor and distributed systems.
* LACSC - Lebanese Association for Computational Sciences - http://www.lacsc.org
A Novel Windowing Technique for Efficient Computation of MFCC for Speaker Recognition
Jun 12, 2012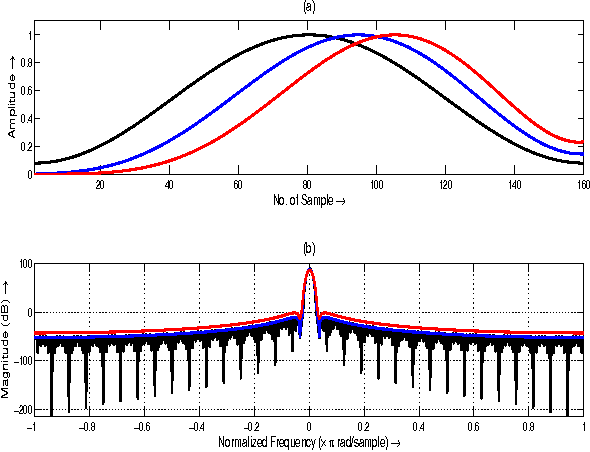
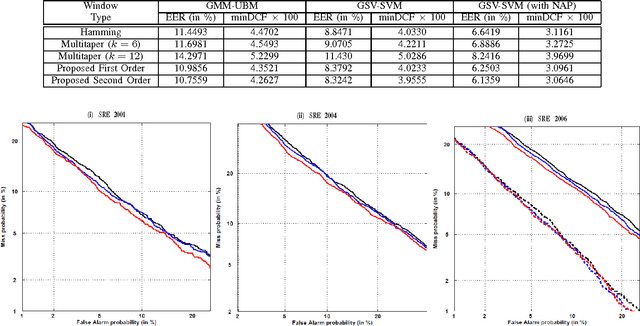
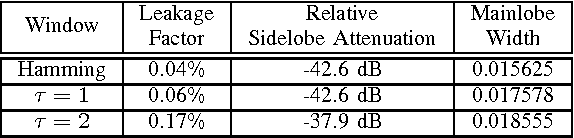
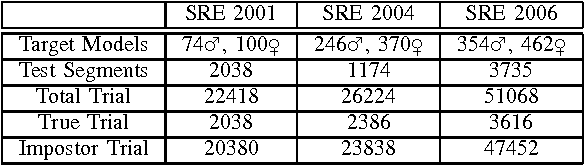
In this paper, we propose a novel family of windowing technique to compute Mel Frequency Cepstral Coefficient (MFCC) for automatic speaker recognition from speech. The proposed method is based on fundamental property of discrete time Fourier transform (DTFT) related to differentiation in frequency domain. Classical windowing scheme such as Hamming window is modified to obtain derivatives of discrete time Fourier transform coefficients. It has been mathematically shown that the slope and phase of power spectrum are inherently incorporated in newly computed cepstrum. Speaker recognition systems based on our proposed family of window functions are shown to attain substantial and consistent performance improvement over baseline single tapered Hamming window as well as recently proposed multitaper windowing technique.
Improving neural networks by preventing co-adaptation of feature detectors
Jul 03, 2012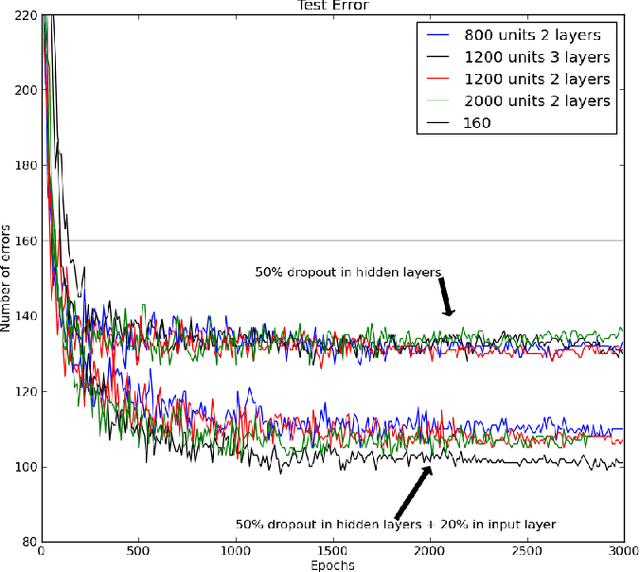
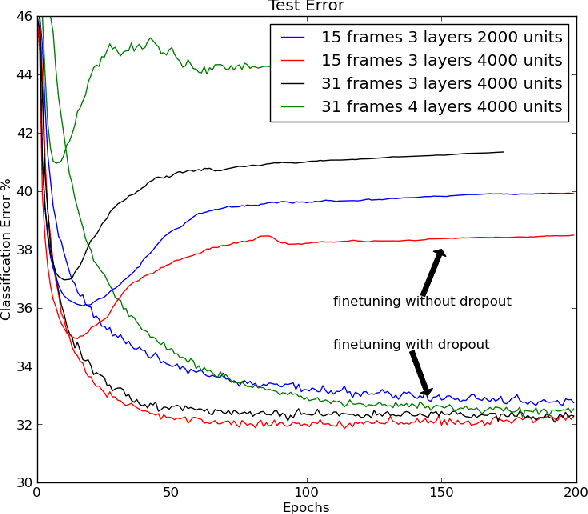


When a large feedforward neural network is trained on a small training set, it typically performs poorly on held-out test data. This "overfitting" is greatly reduced by randomly omitting half of the feature detectors on each training case. This prevents complex co-adaptations in which a feature detector is only helpful in the context of several other specific feature detectors. Instead, each neuron learns to detect a feature that is generally helpful for producing the correct answer given the combinatorially large variety of internal contexts in which it must operate. Random "dropout" gives big improvements on many benchmark tasks and sets new records for speech and object recognition.
A neuromorphic hardware architecture using the Neural Engineering Framework for pattern recognition
Jul 21, 2015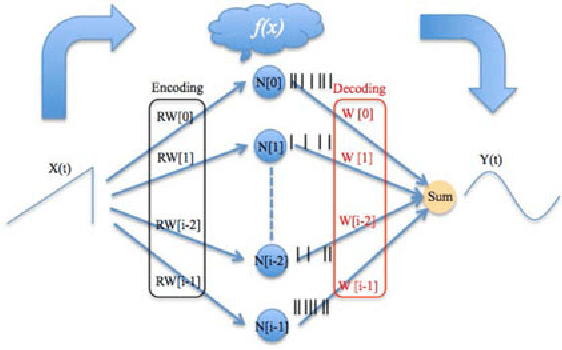
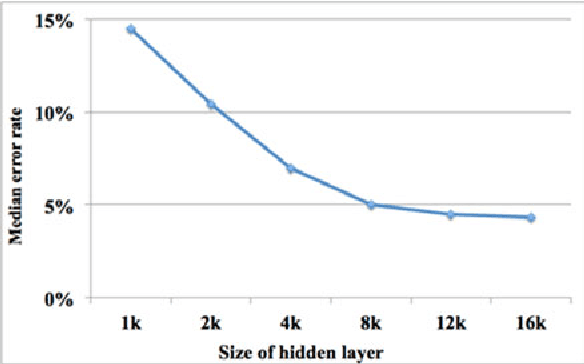
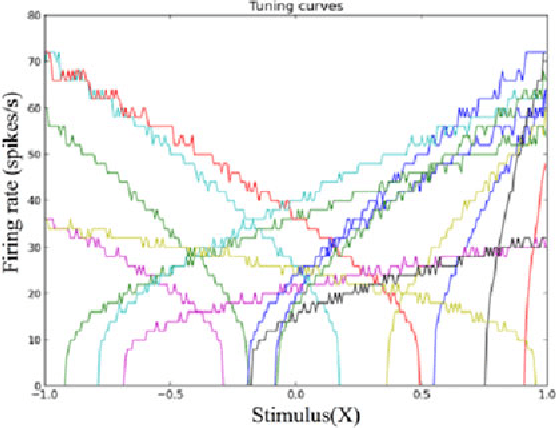
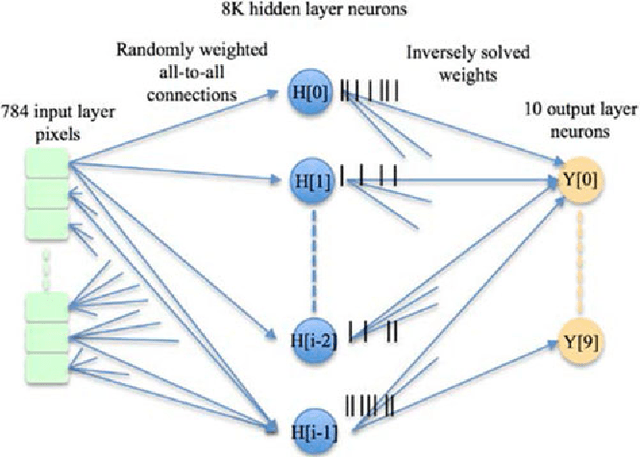
We present a hardware architecture that uses the Neural Engineering Framework (NEF) to implement large-scale neural networks on Field Programmable Gate Arrays (FPGAs) for performing pattern recognition in real time. NEF is a framework that is capable of synthesising large-scale cognitive systems from subnetworks. We will first present the architecture of the proposed neural network implemented using fixed-point numbers and demonstrate a routine that computes the decoding weights by using the online pseudoinverse update method (OPIUM) in a parallel and distributed manner. The proposed system is efficiently implemented on a compact digital neural core. This neural core consists of 64 neurons that are instantiated by a single physical neuron using a time-multiplexing approach. As a proof of concept, we combined 128 identical neural cores together to build a handwritten digit recognition system using the MNIST database and achieved a recognition rate of 96.55%. The system is implemented on a state-of-the-art FPGA and can process 5.12 million digits per second. The architecture is not limited to handwriting recognition, but is generally applicable as an extremely fast pattern recognition processor for various kinds of patterns such as speech and images.