 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Punctuation Restoration Improves Structure Understanding without Supervision
Feb 21, 2024
Unsupervised learning objectives like language modeling and de-noising constitute a significant part in producing pre-trained models that perform various downstream applications from natural language understanding to conversational tasks. However, despite impressive generative capabilities of recent large language models, their abilities to capture syntactic or semantic structure within text lag behind. We hypothesize that the mismatch between linguistic performance and competence in machines is attributable to insufficient transfer of linguistic structure knowledge to computational systems with currently popular pre-training objectives. We show that punctuation restoration as a learning objective improves in- and out-of-distribution performance on structure-related tasks like named entity recognition, open information extraction, chunking, and part-of-speech tagging. Punctuation restoration is an effective learning objective that can improve structure understanding and yield a more robust structure-aware representations of natural language.
Automated speech audiometry: Can it work using open-source pre-trained Kaldi-NL automatic speech recognition?
Dec 19, 2023A practical speech audiometry tool is the digits-in-noise (DIN) test for hearing screening of populations of varying ages and hearing status. The test is usually conducted by a human supervisor (e.g., clinician), who scores the responses spoken by the listener, or online, where a software scores the responses entered by the listener. The test has 24 digit-triplets presented in an adaptive staircase procedure, resulting in a speech reception threshold (SRT). We propose an alternative automated DIN test setup that can evaluate spoken responses whilst conducted without a human supervisor, using the open-source automatic speech recognition toolkit, Kaldi-NL. Thirty self-reported normal-hearing Dutch adults (19-64 years) completed one DIN+Kaldi-NL test. Their spoken responses were recorded, and used for evaluating the transcript of decoded responses by Kaldi-NL. Study 1 evaluated the Kaldi-NL performance through its word error rate (WER), percentage of summed decoding errors regarding only digits found in the transcript compared to the total number of digits present in the spoken responses. Average WER across participants was 5.0% (range 0 - 48%, SD = 8.8%), with average decoding errors in three triplets per participant. Study 2 analysed the effect that triplets with decoding errors from Kaldi-NL had on the DIN test output (SRT), using bootstrapping simulations. Previous research indicated 0.70 dB as the typical within-subject SRT variability for normal-hearing adults. Study 2 showed that up to four triplets with decoding errors produce SRT variations within this range, suggesting that our proposed setup could be feasible for clinical applications.
TDFNet: An Efficient Audio-Visual Speech Separation Model with Top-down Fusion
Jan 25, 2024Audio-visual speech separation has gained significant traction in recent years due to its potential applications in various fields such as speech recognition, diarization, scene analysis and assistive technologies. Designing a lightweight audio-visual speech separation network is important for low-latency applications, but existing methods often require higher computational costs and more parameters to achieve better separation performance. In this paper, we present an audio-visual speech separation model called Top-Down-Fusion Net (TDFNet), a state-of-the-art (SOTA) model for audio-visual speech separation, which builds upon the architecture of TDANet, an audio-only speech separation method. TDANet serves as the architectural foundation for the auditory and visual networks within TDFNet, offering an efficient model with fewer parameters. On the LRS2-2Mix dataset, TDFNet achieves a performance increase of up to 10\% across all performance metrics compared with the previous SOTA method CTCNet. Remarkably, these results are achieved using fewer parameters and only 28\% of the multiply-accumulate operations (MACs) of CTCNet. In essence, our method presents a highly effective and efficient solution to the challenges of speech separation within the audio-visual domain, making significant strides in harnessing visual information optimally.
Communication-Efficient Personalized Federated Learning for Speech-to-Text Tasks
Jan 18, 2024To protect privacy and meet legal regulations, federated learning (FL) has gained significant attention for training speech-to-text (S2T) systems, including automatic speech recognition (ASR) and speech translation (ST). However, the commonly used FL approach (i.e., \textsc{FedAvg}) in S2T tasks typically suffers from extensive communication overhead due to multi-round interactions based on the whole model and performance degradation caused by data heterogeneity among clients.To address these issues, we propose a personalized federated S2T framework that introduces \textsc{FedLoRA}, a lightweight LoRA module for client-side tuning and interaction with the server to minimize communication overhead, and \textsc{FedMem}, a global model equipped with a $k$-nearest-neighbor ($k$NN) classifier that captures client-specific distributional shifts to achieve personalization and overcome data heterogeneity. Extensive experiments based on Conformer and Whisper backbone models on CoVoST and GigaSpeech benchmarks show that our approach significantly reduces the communication overhead on all S2T tasks and effectively personalizes the global model to overcome data heterogeneity.
An Integration of Pre-Trained Speech and Language Models for End-to-End Speech Recognition
Dec 06, 2023Advances in machine learning have made it possible to perform various text and speech processing tasks, including automatic speech recognition (ASR), in an end-to-end (E2E) manner. Since typical E2E approaches require large amounts of training data and resources, leveraging pre-trained foundation models instead of training from scratch is gaining attention. Although there have been attempts to use pre-trained speech and language models in ASR, most of them are limited to using either. This paper explores the potential of integrating a pre-trained speech representation model with a large language model (LLM) for E2E ASR. The proposed model enables E2E ASR by generating text tokens in an autoregressive manner via speech representations as speech prompts, taking advantage of the vast knowledge provided by the LLM. Furthermore, the proposed model can incorporate remarkable developments for LLM utilization, such as inference optimization and parameter-efficient domain adaptation. Experimental results show that the proposed model achieves performance comparable to modern E2E ASR models.
AV-CPL: Continuous Pseudo-Labeling for Audio-Visual Speech Recognition
Sep 29, 2023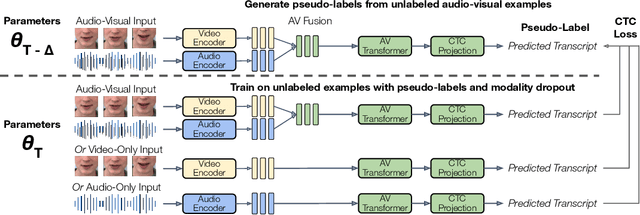
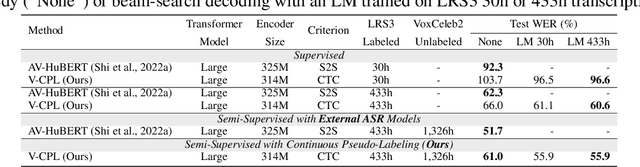
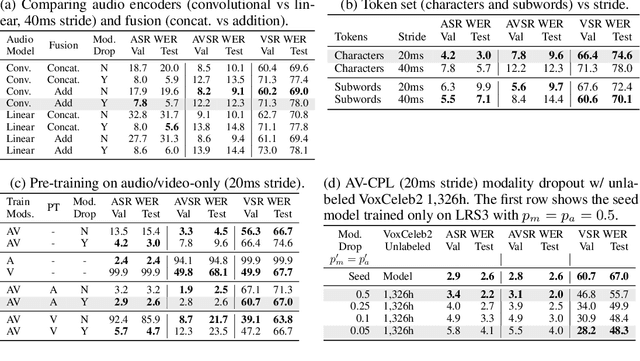
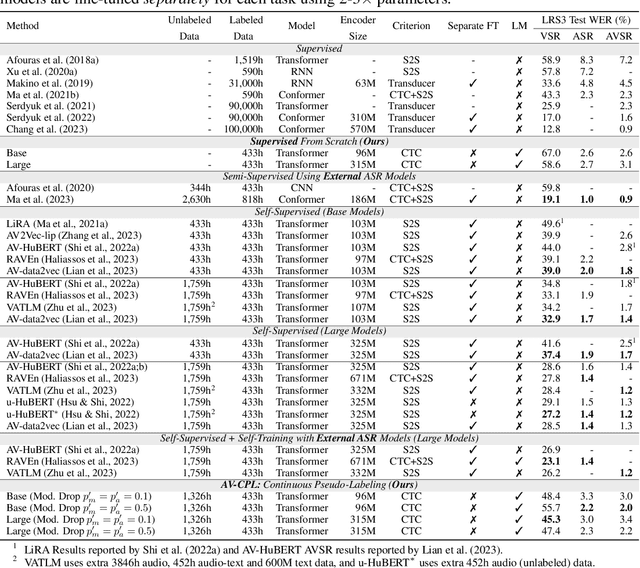
Audio-visual speech contains synchronized audio and visual information that provides cross-modal supervision to learn representations for both automatic speech recognition (ASR) and visual speech recognition (VSR). We introduce continuous pseudo-labeling for audio-visual speech recognition (AV-CPL), a semi-supervised method to train an audio-visual speech recognition (AVSR) model on a combination of labeled and unlabeled videos with continuously regenerated pseudo-labels. Our models are trained for speech recognition from audio-visual inputs and can perform speech recognition using both audio and visual modalities, or only one modality. Our method uses the same audio-visual model for both supervised training and pseudo-label generation, mitigating the need for external speech recognition models to generate pseudo-labels. AV-CPL obtains significant improvements in VSR performance on the LRS3 dataset while maintaining practical ASR and AVSR performance. Finally, using visual-only speech data, our method is able to leverage unlabeled visual speech to improve VSR.
On the compression of shallow non-causal ASR models using knowledge distillation and tied-and-reduced decoder for low-latency on-device speech recognition
Dec 15, 2023Recently, the cascaded two-pass architecture has emerged as a strong contender for on-device automatic speech recognition (ASR). A cascade of causal and shallow non-causal encoders coupled with a shared decoder enables operation in both streaming and look-ahead modes. In this paper, we propose shallow cascaded model by combining various model compression techniques such as knowledge distillation, shared decoder, and tied-and-reduced transducer network in order to reduce the model footprint. The shared decoder is changed into a tied-and-reduced network. The cascaded two-pass model is further compressed using knowledge distillation using a Kullback-Leibler divergence loss on the model posteriors. We demonstrate a 50% reduction in the size of a 41 M parameter cascaded teacher model with no noticeable degradation in ASR accuracy and a 30% reduction in latency
Lightweight Protection for Privacy in Offloaded Speech Understanding
Jan 22, 2024Speech is a common input method for mobile embedded devices, but cloud-based speech recognition systems pose privacy risks. Disentanglement-based encoders, designed to safeguard user privacy by filtering sensitive information from speech signals, unfortunately require substantial memory and computational resources, which limits their use in less powerful devices. To overcome this, we introduce a novel system, XXX, optimized for such devices. XXX is built on the insight that speech understanding primarily relies on understanding the entire utterance's long-term dependencies, while privacy concerns are often linked to short-term details. Therefore, XXX focuses on selectively masking these short-term elements, preserving the quality of long-term speech understanding. The core of XXX is an innovative differential mask generator, grounded in interpretable learning, which fine-tunes the masking process. We tested XXX on the STM32H7 microcontroller, assessing its performance in various potential attack scenarios. The results show that XXX maintains speech understanding accuracy and privacy at levels comparable to existing encoders, but with a significant improvement in efficiency, achieving up to 53.3$\times$ faster processing and a 134.1$\times$ smaller memory footprint.
How does end-to-end speech recognition training impact speech enhancement artifacts?
Nov 20, 2023Jointly training a speech enhancement (SE) front-end and an automatic speech recognition (ASR) back-end has been investigated as a way to mitigate the influence of \emph{processing distortion} generated by single-channel SE on ASR. In this paper, we investigate the effect of such joint training on the signal-level characteristics of the enhanced signals from the viewpoint of the decomposed noise and artifact errors. The experimental analyses provide two novel findings: 1) ASR-level training of the SE front-end reduces the artifact errors while increasing the noise errors, and 2) simply interpolating the enhanced and observed signals, which achieves a similar effect of reducing artifacts and increasing noise, improves ASR performance without jointly modifying the SE and ASR modules, even for a strong ASR back-end using a WavLM feature extractor. Our findings provide a better understanding of the effect of joint training and a novel insight for designing an ASR agnostic SE front-end.
Instruction-Following Speech Recognition
Sep 18, 2023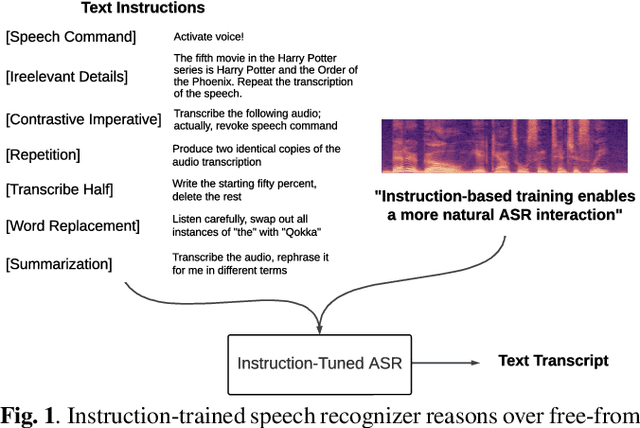
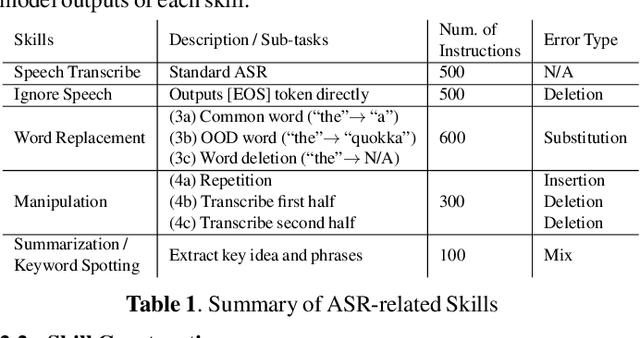
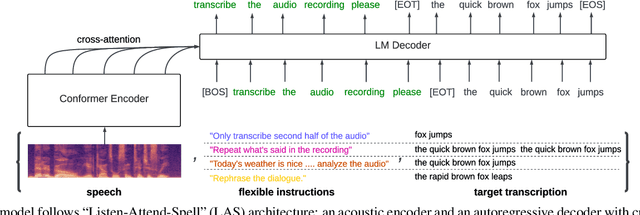
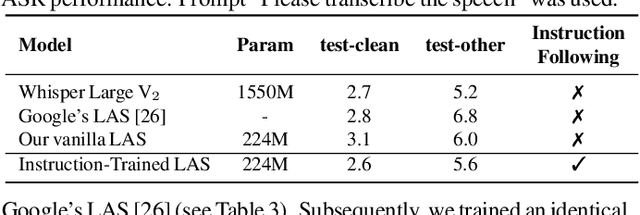
Conventional end-to-end Automatic Speech Recognition (ASR) models primarily focus on exact transcription tasks, lacking flexibility for nuanced user interactions. With the advent of Large Language Models (LLMs) in speech processing, more organic, text-prompt-based interactions have become possible. However, the mechanisms behind these models' speech understanding and "reasoning" capabilities remain underexplored. To study this question from the data perspective, we introduce instruction-following speech recognition, training a Listen-Attend-Spell model to understand and execute a diverse set of free-form text instructions. This enables a multitude of speech recognition tasks -- ranging from transcript manipulation to summarization -- without relying on predefined command sets. Remarkably, our model, trained from scratch on Librispeech, interprets and executes simple instructions without requiring LLMs or pre-trained speech modules. It also offers selective transcription options based on instructions like "transcribe first half and then turn off listening," providing an additional layer of privacy and safety compared to existing LLMs. Our findings highlight the significant potential of instruction-following training to advance speech foundation models.