 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
An Empirical Analysis of Deep Audio-Visual Models for Speech Recognition
Dec 21, 2018
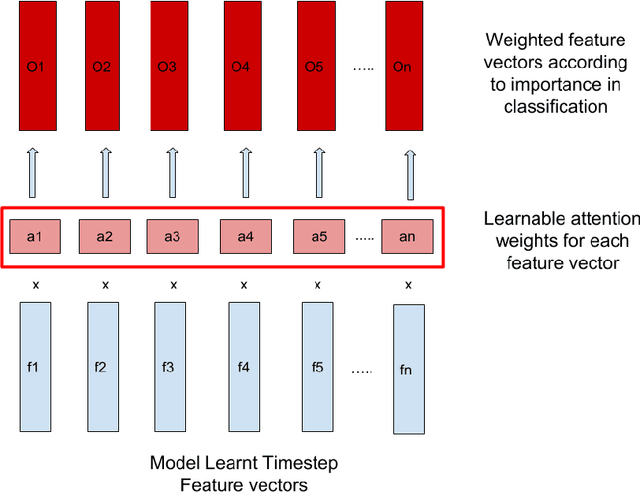

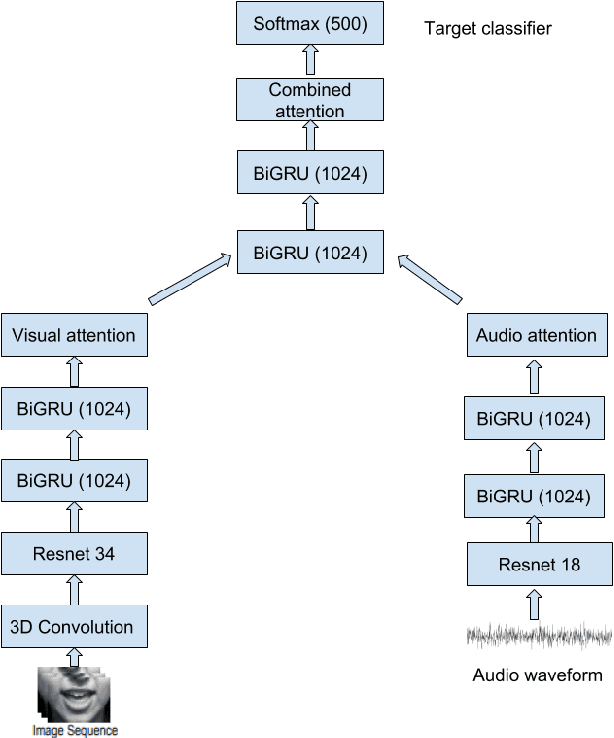
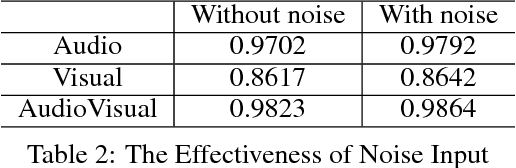
In this project, we worked on speech recognition, specifically predicting individual words based on both the video frames and audio. Empowered by convolutional neural networks, the recent speech recognition and lip reading models are comparable to human level performance. We re-implemented and made derivations of the state-of-the-art model. Then, we conducted rich experiments including the effectiveness of attention mechanism, more accurate residual network as the backbone with pre-trained weights and the sensitivity of our model with respect to audio input with/without noise.
FastCorrect 2: Fast Error Correction on Multiple Candidates for Automatic Speech Recognition
Oct 01, 2021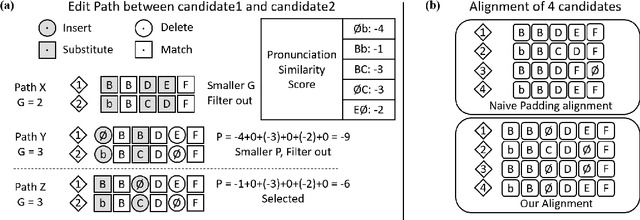
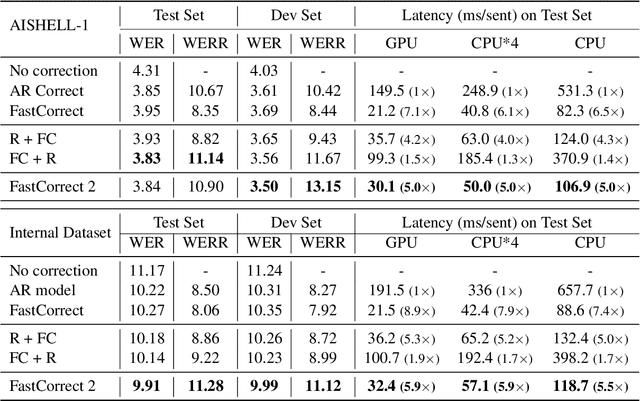
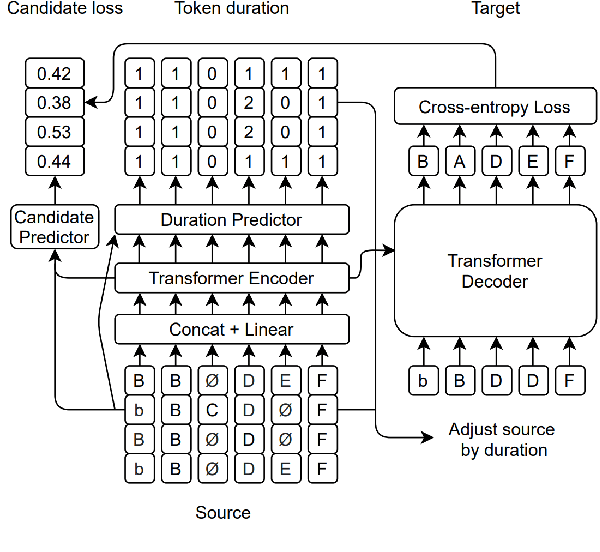
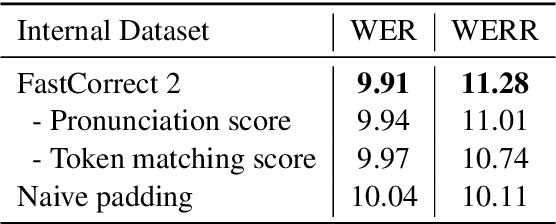
Error correction is widely used in automatic speech recognition (ASR) to post-process the generated sentence, and can further reduce the word error rate (WER). Although multiple candidates are generated by an ASR system through beam search, current error correction approaches can only correct one sentence at a time, failing to leverage the voting effect from multiple candidates to better detect and correct error tokens. In this work, we propose FastCorrect 2, an error correction model that takes multiple ASR candidates as input for better correction accuracy. FastCorrect 2 adopts non-autoregressive generation for fast inference, which consists of an encoder that processes multiple source sentences and a decoder that generates the target sentence in parallel from the adjusted source sentence, where the adjustment is based on the predicted duration of each source token. However, there are some issues when handling multiple source sentences. First, it is non-trivial to leverage the voting effect from multiple source sentences since they usually vary in length. Thus, we propose a novel alignment algorithm to maximize the degree of token alignment among multiple sentences in terms of token and pronunciation similarity. Second, the decoder can only take one adjusted source sentence as input, while there are multiple source sentences. Thus, we develop a candidate predictor to detect the most suitable candidate for the decoder. Experiments on our inhouse dataset and AISHELL-1 show that FastCorrect 2 can further reduce the WER over the previous correction model with single candidate by 3.2% and 2.6%, demonstrating the effectiveness of leveraging multiple candidates in ASR error correction. FastCorrect 2 achieves better performance than the cascaded re-scoring and correction pipeline and can serve as a unified post-processing module for ASR.
Exploring RNN-Transducer for Chinese Speech Recognition
Nov 13, 2018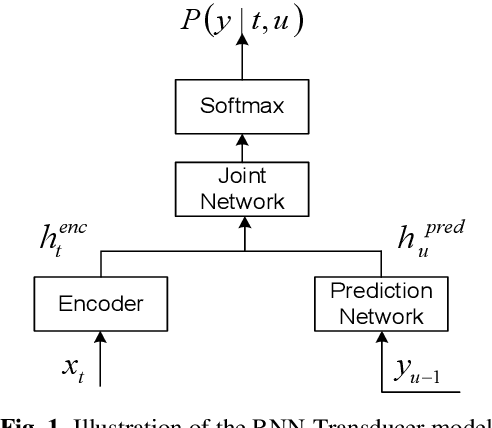
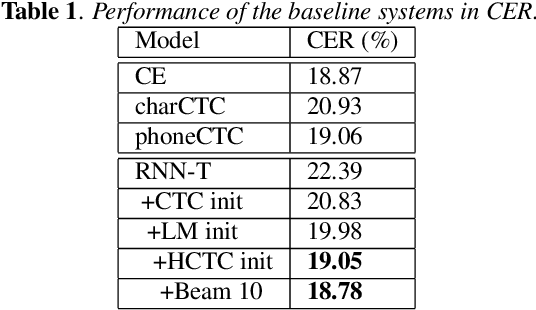
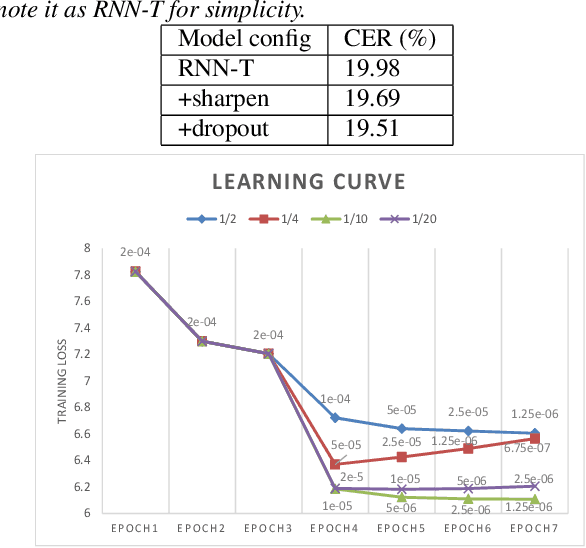
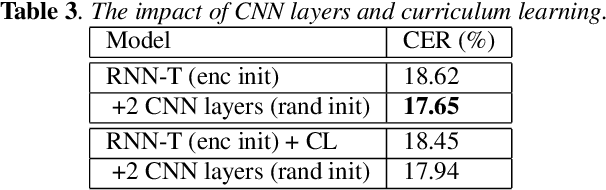
End-to-end approaches have drawn much attention recently for significantly simplifying the construction of an automatic speech recognition (ASR) system. RNN transducer (RNN-T) is one of the popular end-to-end methods. Previous studies have shown that RNN-T is difficult to train and a very complex training process is needed for a reasonable performance. In this paper, we explore RNN-T for a Chinese large vocabulary continuous speech recognition (LVCSR) task and aim to simplify the training process while maintaining performance. First, a new strategy of learning rate decay is proposed to accelerate the model convergence. Second, we find that adding convolutional layers at the beginning of the network and using ordered data can discard the pre-training process of the encoder without loss of performance. Besides, we design experiments to find a balance among the usage of GPU memory, training circle and model performance. Finally, we achieve 16.9% character error rate (CER) on our test set which is 2% absolute improvement from a strong BLSTM CE system with language model trained on the same text corpus.
Gated Embeddings in End-to-End Speech Recognition for Conversational-Context Fusion
Jun 27, 2019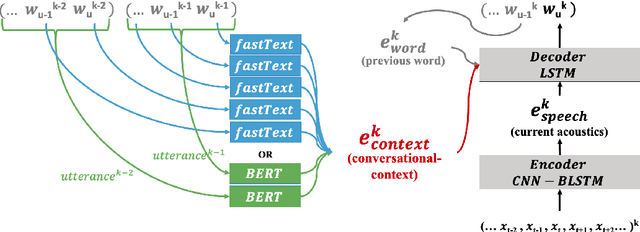
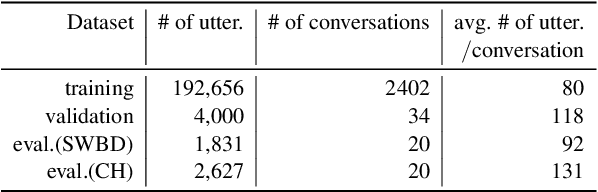
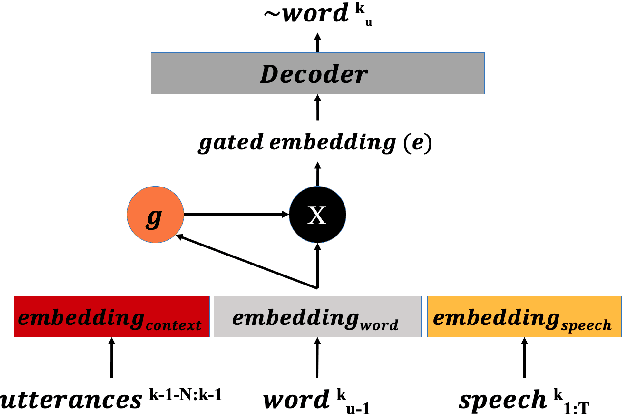
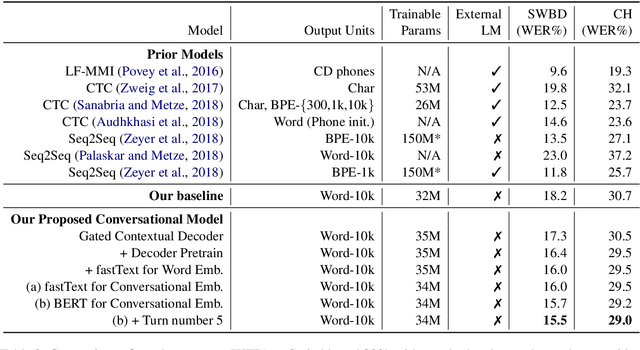
We present a novel conversational-context aware end-to-end speech recognizer based on a gated neural network that incorporates conversational-context/word/speech embeddings. Unlike conventional speech recognition models, our model learns longer conversational-context information that spans across sentences and is consequently better at recognizing long conversations. Specifically, we propose to use the text-based external word and/or sentence embeddings (i.e., fastText, BERT) within an end-to-end framework, yielding a significant improvement in word error rate with better conversational-context representation. We evaluated the models on the Switchboard conversational speech corpus and show that our model outperforms standard end-to-end speech recognition models.
Cross-Lingual Machine Speech Chain for Javanese, Sundanese, Balinese, and Bataks Speech Recognition and Synthesis
Nov 04, 2020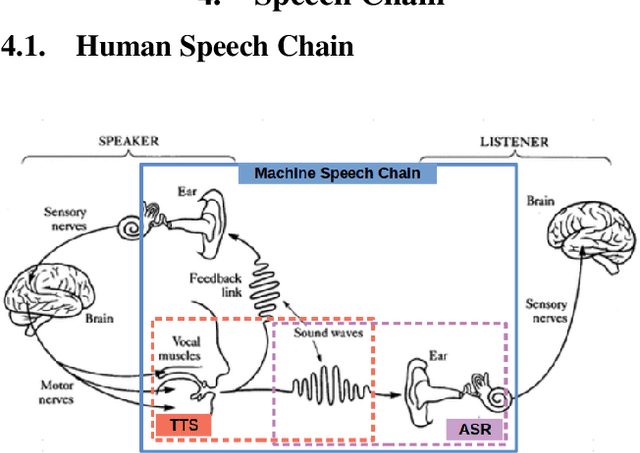

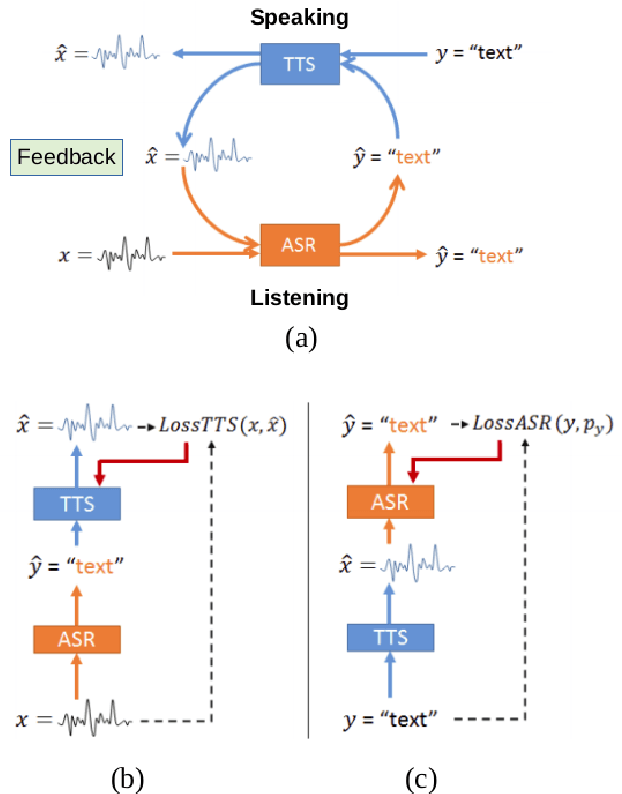

Even though over seven hundred ethnic languages are spoken in Indonesia, the available technology remains limited that could support communication within indigenous communities as well as with people outside the villages. As a result, indigenous communities still face isolation due to cultural barriers; languages continue to disappear. To accelerate communication, speech-to-speech translation (S2ST) technology is one approach that can overcome language barriers. However, S2ST systems require machine translation (MT), speech recognition (ASR), and synthesis (TTS) that rely heavily on supervised training and a broad set of language resources that can be difficult to collect from ethnic communities. Recently, a machine speech chain mechanism was proposed to enable ASR and TTS to assist each other in semi-supervised learning. The framework was initially implemented only for monolingual languages. In this study, we focus on developing speech recognition and synthesis for these Indonesian ethnic languages: Javanese, Sundanese, Balinese, and Bataks. We first separately train ASR and TTS of standard Indonesian in supervised training. We then develop ASR and TTS of ethnic languages by utilizing Indonesian ASR and TTS in a cross-lingual machine speech chain framework with only text or only speech data removing the need for paired speech-text data of those ethnic languages.
SpeechEQ: Speech Emotion Recognition based on Multi-scale Unified Datasets and Multitask Learning
Jun 27, 2022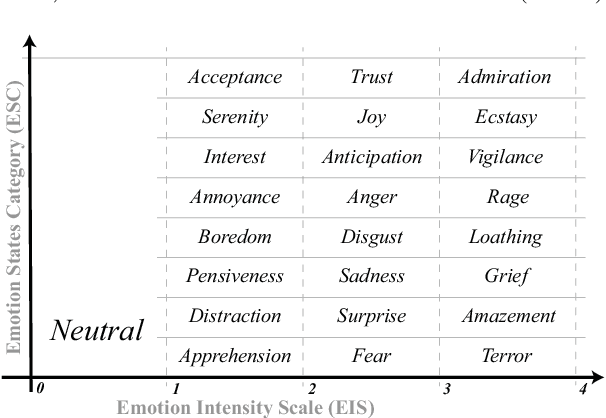

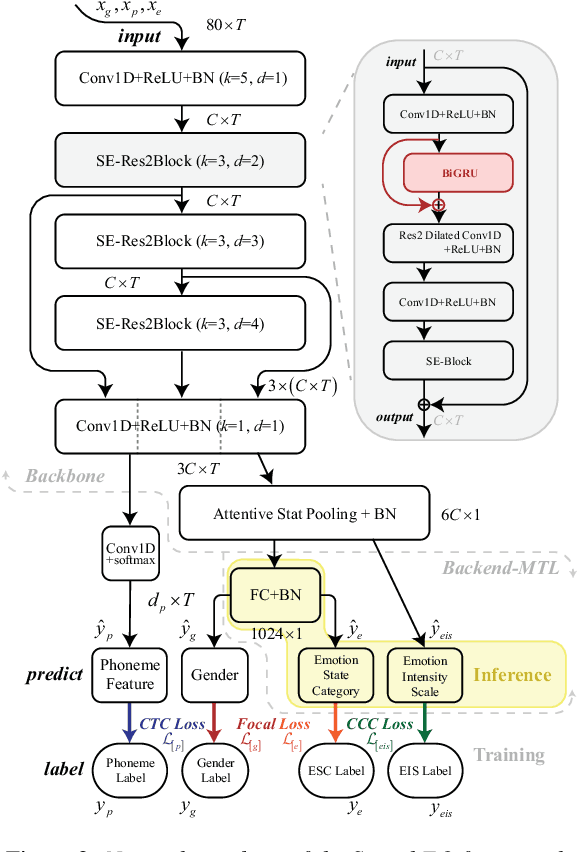
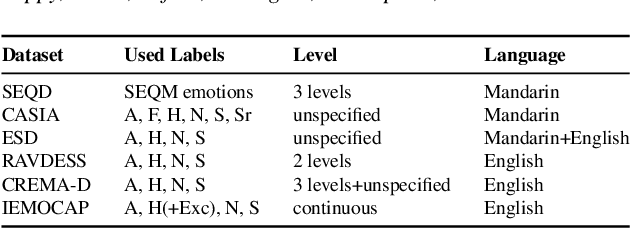
Speech emotion recognition (SER) has many challenges, but one of the main challenges is that each framework does not have a unified standard. In this paper, we propose SpeechEQ, a framework for unifying SER tasks based on a multi-scale unified metric. This metric can be trained by Multitask Learning (MTL), which includes two emotion recognition tasks of Emotion States Category (EIS) and Emotion Intensity Scale (EIS), and two auxiliary tasks of phoneme recognition and gender recognition. For this framework, we build a Mandarin SER dataset - SpeechEQ Dataset (SEQD). We conducted experiments on the public CASIA and ESD datasets in Mandarin, which exhibit that our method outperforms baseline methods by a relatively large margin, yielding 8.0\% and 6.5\% improvement in accuracy respectively. Additional experiments on IEMOCAP with four emotion categories (i.e., angry, happy, sad, and neutral) also show the proposed method achieves a state-of-the-art of both weighted accuracy (WA) of 78.16% and unweighted accuracy (UA) of 77.47%.
Wav2Seq: Pre-training Speech-to-Text Encoder-Decoder Models Using Pseudo Languages
May 02, 2022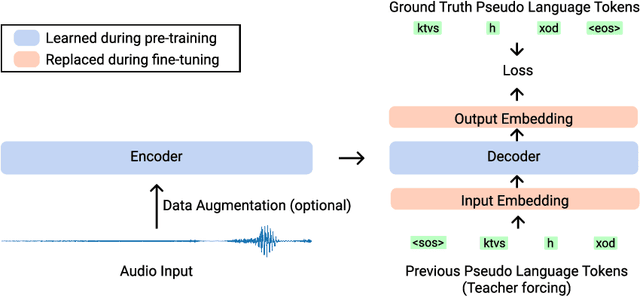

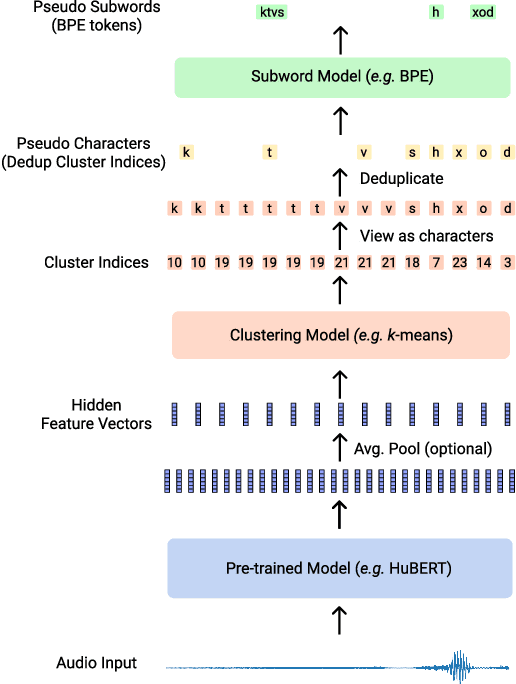
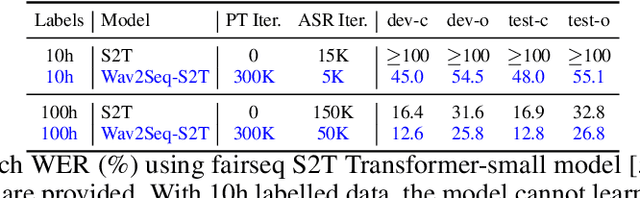
We introduce Wav2Seq, the first self-supervised approach to pre-train both parts of encoder-decoder models for speech data. We induce a pseudo language as a compact discrete representation, and formulate a self-supervised pseudo speech recognition task -- transcribing audio inputs into pseudo subword sequences. This process stands on its own, or can be applied as low-cost second-stage pre-training. We experiment with automatic speech recognition (ASR), spoken named entity recognition, and speech-to-text translation. We set new state-of-the-art results for end-to-end spoken named entity recognition, and show consistent improvements on 20 language pairs for speech-to-text translation, even when competing methods use additional text data for training. Finally, on ASR, our approach enables encoder-decoder methods to benefit from pre-training for all parts of the network, and shows comparable performance to highly optimized recent methods.
EdgeSpeechNets: Highly Efficient Deep Neural Networks for Speech Recognition on the Edge
Oct 18, 2018
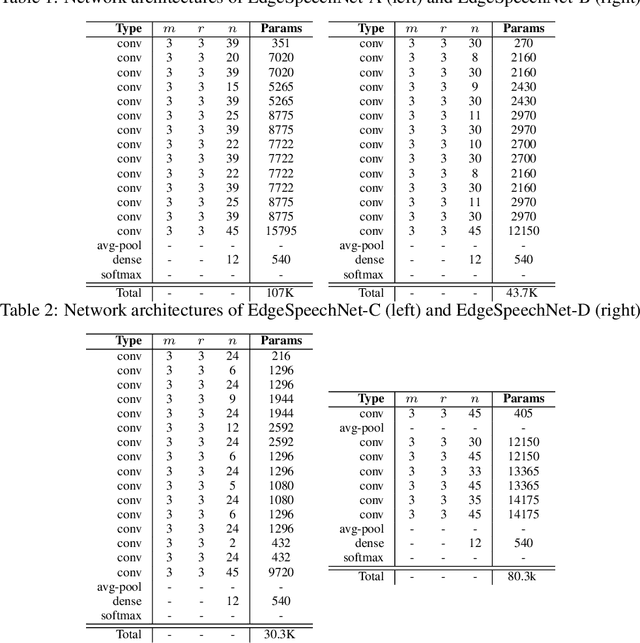
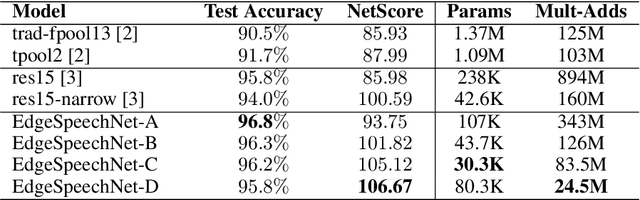
Despite showing state-of-the-art performance, deep learning for speech recognition remains challenging to deploy in on-device edge scenarios such as mobile and other consumer devices. Recently, there have been greater efforts in the design of small, low-footprint deep neural networks (DNNs) that are more appropriate for edge devices, with much of the focus on design principles for hand-crafting efficient network architectures. In this study, we explore a human-machine collaborative design strategy for building low-footprint DNN architectures for speech recognition through a marriage of human-driven principled network design prototyping and machine-driven design exploration. The efficacy of this design strategy is demonstrated through the design of a family of highly-efficient DNNs (nicknamed EdgeSpeechNets) for limited-vocabulary speech recognition. Experimental results using the Google Speech Commands dataset for limited-vocabulary speech recognition showed that EdgeSpeechNets have higher accuracies than state-of-the-art DNNs (with the best EdgeSpeechNet achieving ~97% accuracy), while achieving significantly smaller network sizes (as much as 7.8x smaller) and lower computational cost (as much as 36x fewer multiply-add operations, 10x lower prediction latency, and 16x smaller memory footprint on a Motorola Moto E phone), making them very well-suited for on-device edge voice interface applications.
Can we use Common Voice to train a Multi-Speaker TTS system?
Oct 12, 2022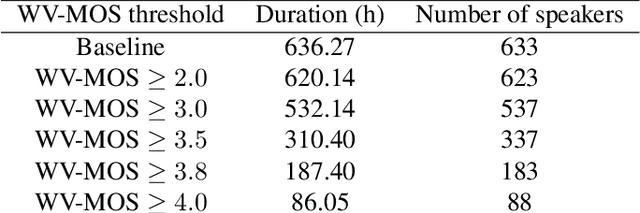
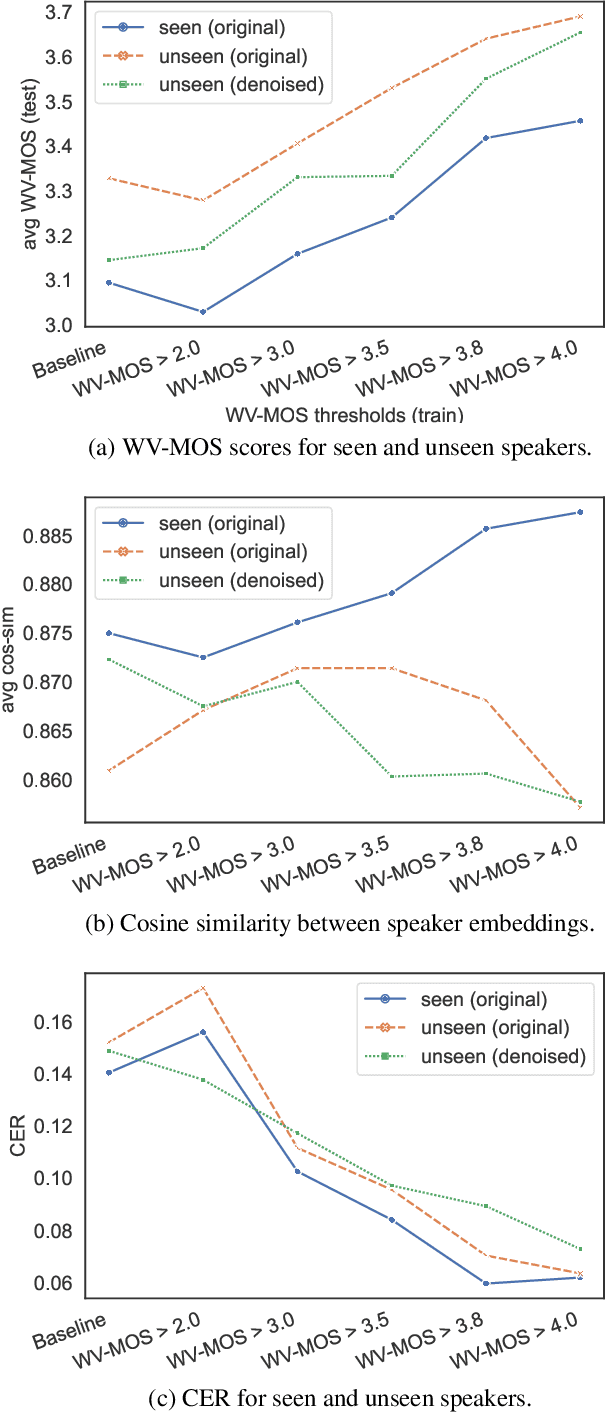
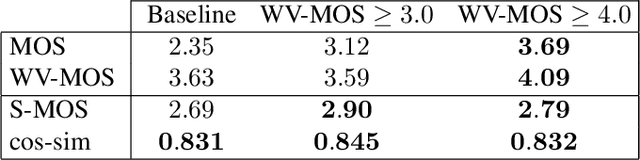
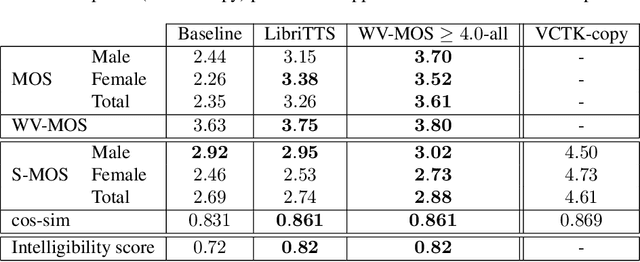
Training of multi-speaker text-to-speech (TTS) systems relies on curated datasets based on high-quality recordings or audiobooks. Such datasets often lack speaker diversity and are expensive to collect. As an alternative, recent studies have leveraged the availability of large, crowdsourced automatic speech recognition (ASR) datasets. A major problem with such datasets is the presence of noisy and/or distorted samples, which degrade TTS quality. In this paper, we propose to automatically select high-quality training samples using a non-intrusive mean opinion score (MOS) estimator, WV-MOS. We show the viability of this approach for training a multi-speaker GlowTTS model on the Common Voice English dataset. Our approach improves the overall quality of generated utterances by 1.26 MOS point with respect to training on all the samples and by 0.35 MOS point with respect to training on the LibriTTS dataset. This opens the door to automatic TTS dataset curation for a wider range of languages.
A context-aware knowledge transferring strategy for CTC-based ASR
Oct 12, 2022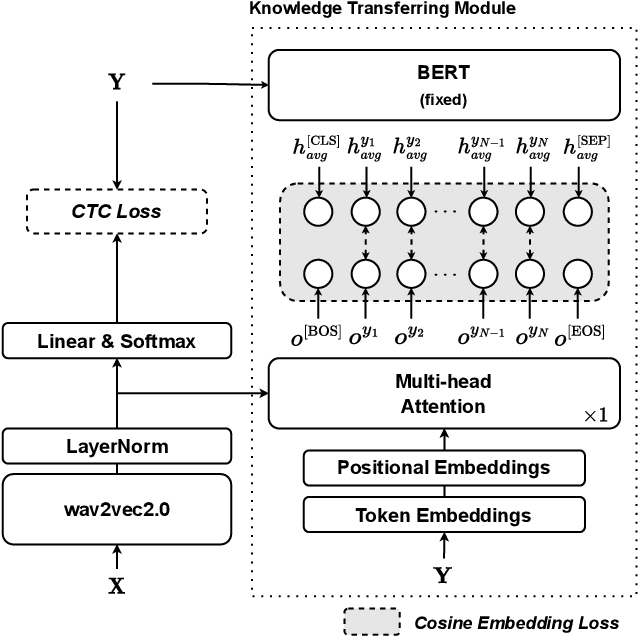
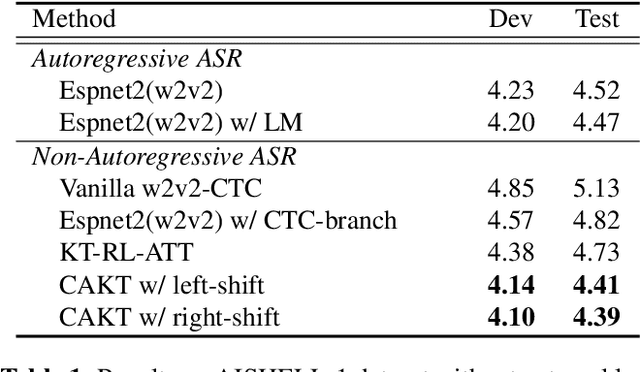
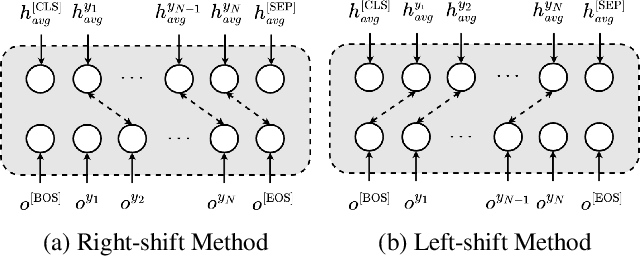
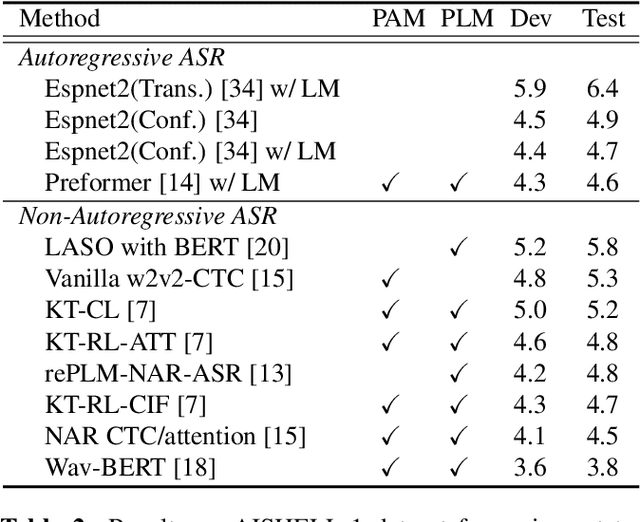
Non-autoregressive automatic speech recognition (ASR) modeling has received increasing attention recently because of its fast decoding speed and superior performance. Among representatives, methods based on the connectionist temporal classification (CTC) are still a dominating stream. However, the theoretically inherent flaw, the assumption of independence between tokens, creates a performance barrier for the school of works. To mitigate the challenge, we propose a context-aware knowledge transferring strategy, consisting of a knowledge transferring module and a context-aware training strategy, for CTC-based ASR. The former is designed to distill linguistic information from a pre-trained language model, and the latter is framed to modulate the limitations caused by the conditional independence assumption. As a result, a knowledge-injected context-aware CTC-based ASR built upon the wav2vec2.0 is presented in this paper. A series of experiments on the AISHELL-1 and AISHELL-2 datasets demonstrate the effectiveness of the proposed method.