 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Data and knowledge-driven approaches for multilingual training to improve the performance of speech recognition systems of Indian languages
Jan 24, 2022

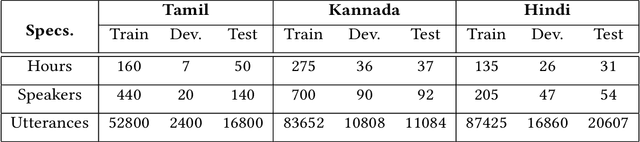
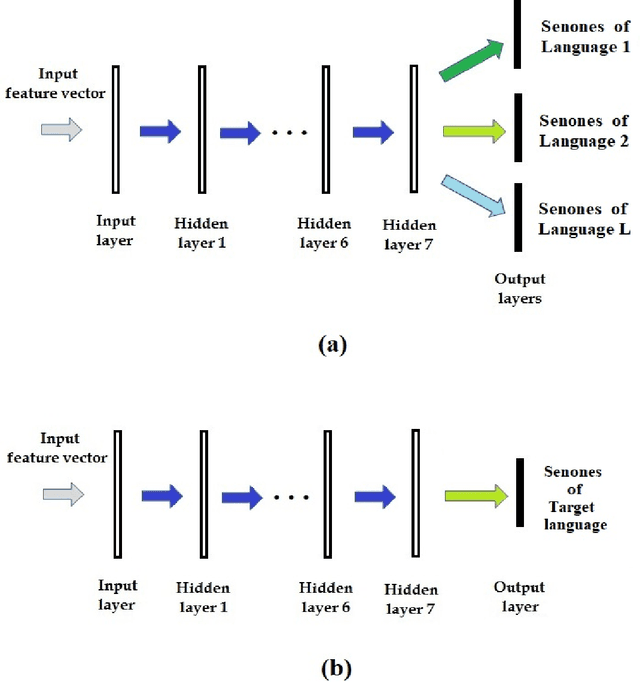
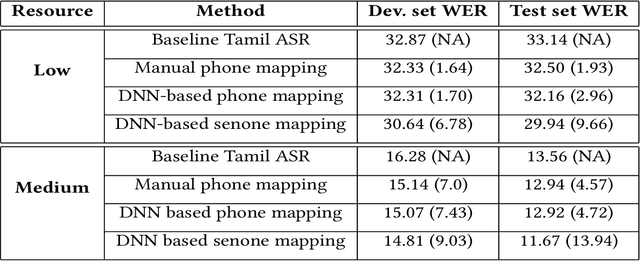
We propose data and knowledge-driven approaches for multilingual training of the automated speech recognition (ASR) system for a target language by pooling speech data from multiple source languages. Exploiting the acoustic similarities between Indian languages, we implement two approaches. In phone/senone mapping, deep neural network (DNN) learns to map senones or phones from one language to the others, and the transcriptions of the source languages are modified such that they can be used along with the target language data to train and fine-tune the target language ASR system. In the other approach, we model the acoustic information for all the languages simultaneously by training a multitask DNN (MTDNN) to predict the senones of each language in different output layers. The cross-entropy loss and the weight update procedure are modified such that only the shared layers and the output layer responsible for predicting the senone classes of a language are updated during training, if the feature vector belongs to that particular language. In the low-resource setting (LRS), 40 hours of transcribed data each for Tamil, Telugu and Gujarati languages are used for training. The DNN based senone mapping technique gives relative improvements in word error rates (WER) of 9.66%, 7.2% and 15.21% over the baseline system for Tamil, Gujarati and Telugu languages, respectively. In medium-resourced setting (MRS), 160, 275 and 135 hours of data for Tamil, Kannada and Hindi languages are used, where, the same technique gives better relative improvements of 13.94%, 10.28% and 27.24% for Tamil, Kannada and Hindi, respectively. The MTDNN with senone mapping based training in LRS, gives higher relative WER improvements of 15.0%, 17.54% and 16.06%, respectively for Tamil, Gujarati and Telugu, whereas in MRS, we see improvements of 21.24% 21.05% and 30.17% for Tamil, Kannada and Hindi languages, respectively.
Training Speech Recognition Models with Federated Learning: A Quality/Cost Framework
Oct 29, 2020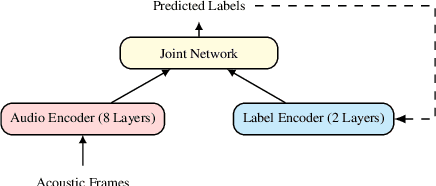
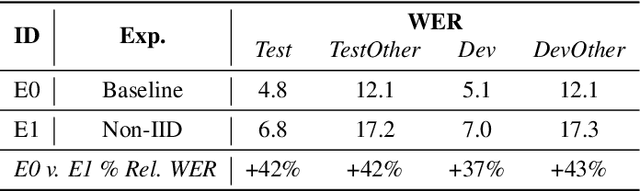
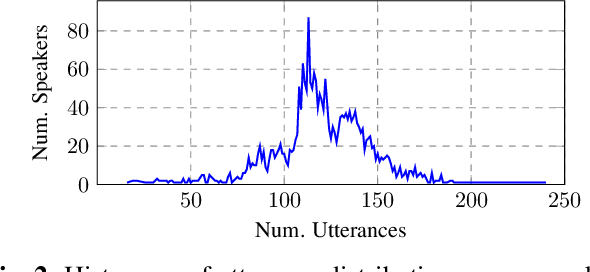
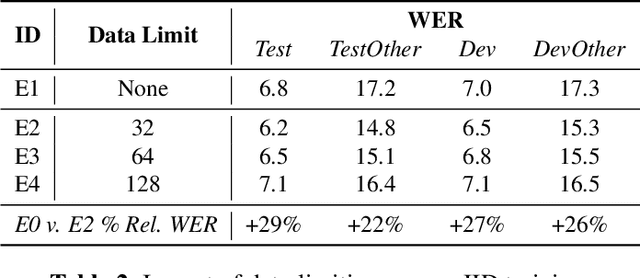
We propose using federated learning, a decentralized on-device learning paradigm, to train speech recognition models. By performing epochs of training on a per-user basis, federated learning must incur the cost of dealing with non-IID data distributions, which are expected to negatively affect the quality of the trained model. We propose a framework by which the degree of non-IID-ness can be varied, consequently illustrating a trade-off between model quality and the computational cost of federated training, which we capture through a novel metric. Finally, we demonstrate that hyper-parameter optimization and appropriate use of variational noise are sufficient to compensate for the quality impact of non-IID distributions, while decreasing the cost.
Towards A Unified Conformer Structure: from ASR to ASV Task
Nov 14, 2022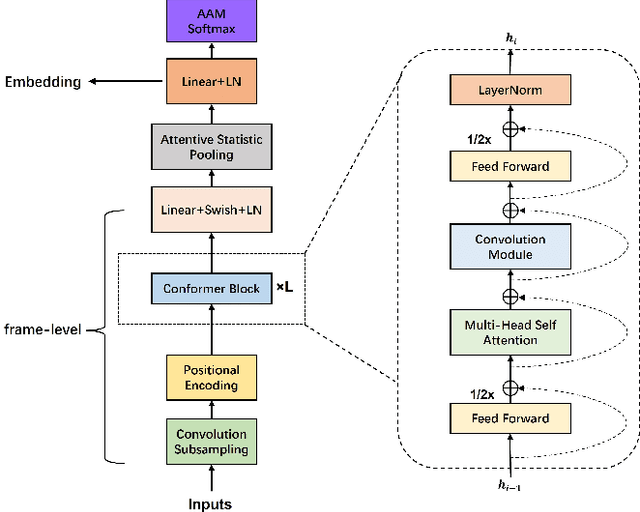
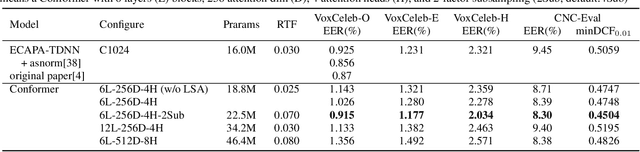
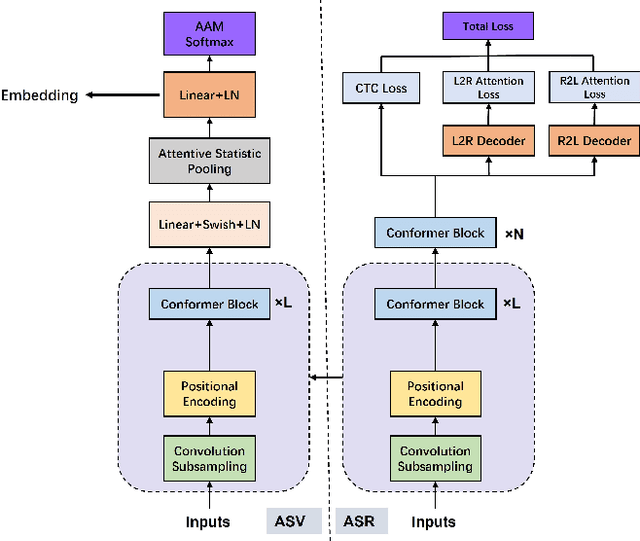
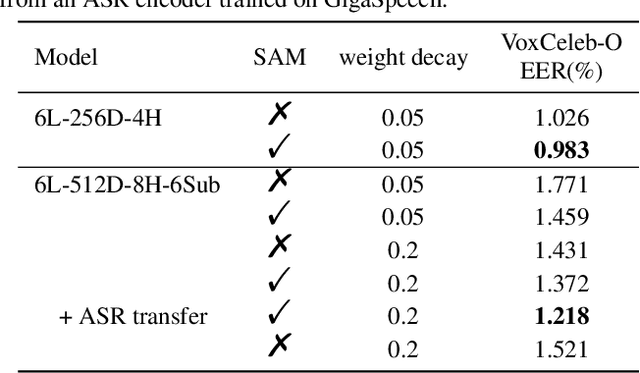
Transformer has achieved extraordinary performance in Natural Language Processing and Computer Vision tasks thanks to its powerful self-attention mechanism, and its variant Conformer has become a state-of-the-art architecture in the field of Automatic Speech Recognition (ASR). However, the main-stream architecture for Automatic Speaker Verification (ASV) is convolutional Neural Networks, and there is still much room for research on the Conformer based ASV. In this paper, firstly, we modify the Conformer architecture from ASR to ASV with very minor changes. Length-Scaled Attention (LSA) method and Sharpness-Aware Minimizationis (SAM) are adopted to improve model generalization. Experiments conducted on VoxCeleb and CN-Celeb show that our Conformer based ASV achieves competitive performance compared with the popular ECAPA-TDNN. Secondly, inspired by the transfer learning strategy, ASV Conformer is natural to be initialized from the pretrained ASR model. Via parameter transferring, self-attention mechanism could better focus on the relationship between sequence features, brings about 11% relative improvement in EER on test set of VoxCeleb and CN-Celeb, which reveals the potential of Conformer to unify ASV and ASR task. Finally, we provide a runtime in ASV-Subtools to evaluate its inference speed in production scenario. Our code is released at https://github.com/Snowdar/asv-subtools/tree/master/doc/papers/conformer.md.
Multiresolution and Multimodal Speech Recognition with Transformers
Apr 29, 2020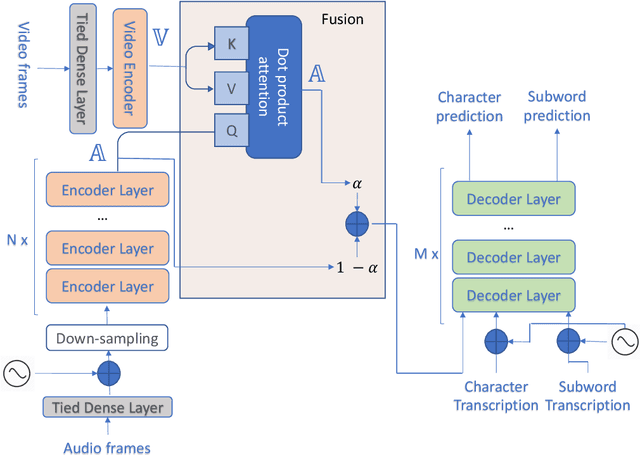
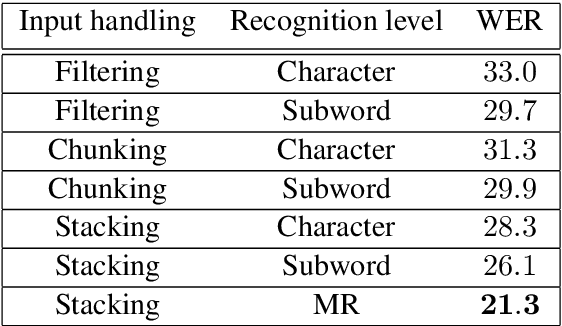
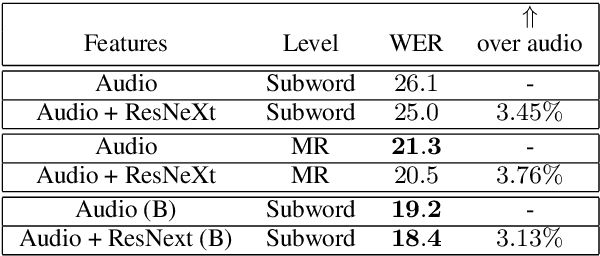

This paper presents an audio visual automatic speech recognition (AV-ASR) system using a Transformer-based architecture. We particularly focus on the scene context provided by the visual information, to ground the ASR. We extract representations for audio features in the encoder layers of the transformer and fuse video features using an additional crossmodal multihead attention layer. Additionally, we incorporate a multitask training criterion for multiresolution ASR, where we train the model to generate both character and subword level transcriptions. Experimental results on the How2 dataset, indicate that multiresolution training can speed up convergence by around 50% and relatively improves word error rate (WER) performance by upto 18% over subword prediction models. Further, incorporating visual information improves performance with relative gains upto 3.76% over audio only models. Our results are comparable to state-of-the-art Listen, Attend and Spell-based architectures.
KT-Speech-Crawler: Automatic Dataset Construction for Speech Recognition from YouTube Videos
Mar 01, 2019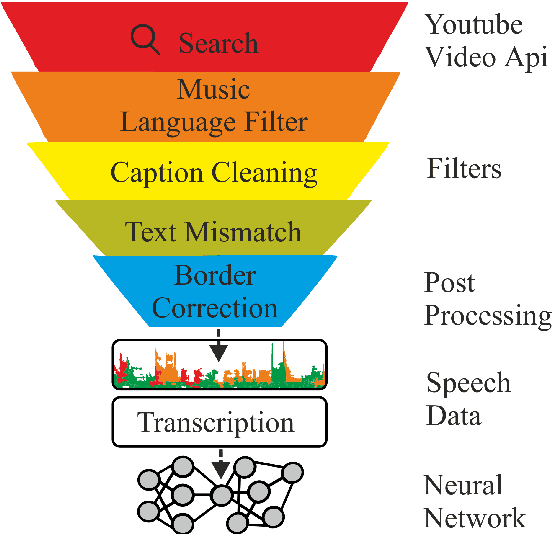
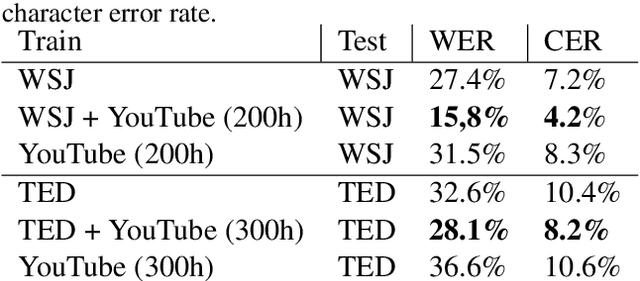
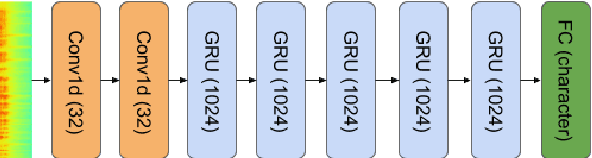
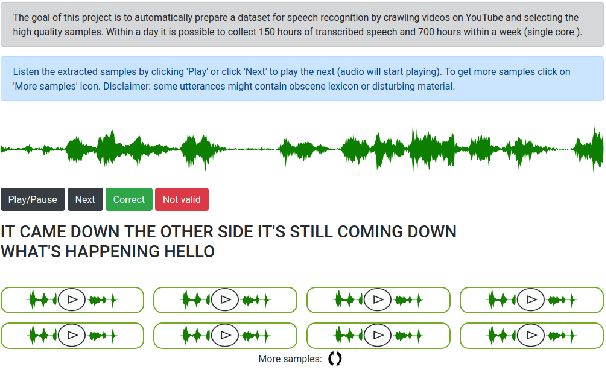
In this paper, we describe KT-Speech-Crawler: an approach for automatic dataset construction for speech recognition by crawling YouTube videos. We outline several filtering and post-processing steps, which extract samples that can be used for training end-to-end neural speech recognition systems. In our experiments, we demonstrate that a single-core version of the crawler can obtain around 150 hours of transcribed speech within a day, containing an estimated 3.5% word error rate in the transcriptions. Automatically collected samples contain reading and spontaneous speech recorded in various conditions including background noise and music, distant microphone recordings, and a variety of accents and reverberation. When training a deep neural network on speech recognition, we observed around 40\% word error rate reduction on the Wall Street Journal dataset by integrating 200 hours of the collected samples into the training set. The demo (http://emnlp-demo.lakomkin.me/) and the crawler code (https://github.com/EgorLakomkin/KTSpeechCrawler) are publicly available.
End-to-End Dereverberation, Beamforming, and Speech Recognition with Improved Numerical Stability and Advanced Frontend
Feb 23, 2021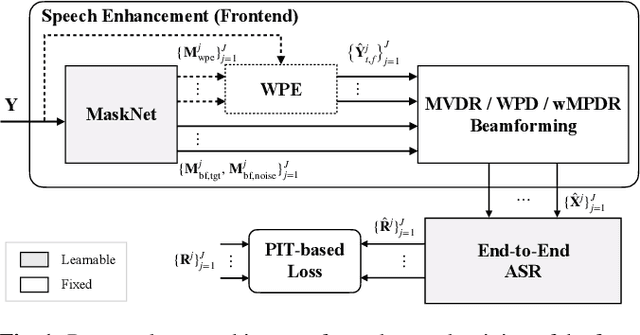
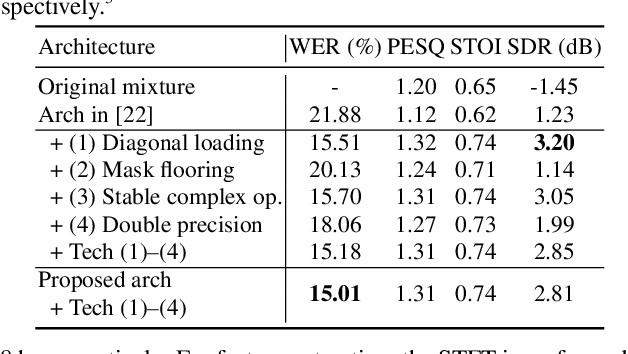
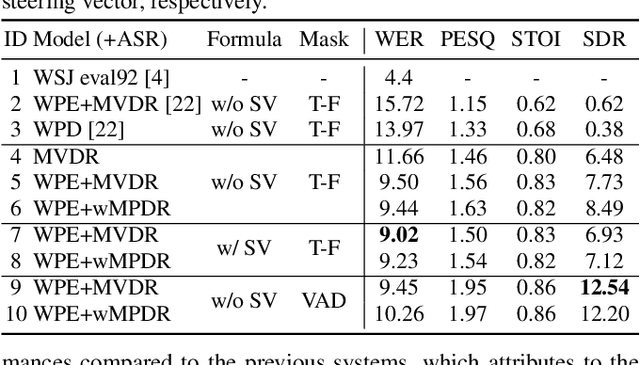
Recently, the end-to-end approach has been successfully applied to multi-speaker speech separation and recognition in both single-channel and multichannel conditions. However, severe performance degradation is still observed in the reverberant and noisy scenarios, and there is still a large performance gap between anechoic and reverberant conditions. In this work, we focus on the multichannel multi-speaker reverberant condition, and propose to extend our previous framework for end-to-end dereverberation, beamforming, and speech recognition with improved numerical stability and advanced frontend subnetworks including voice activity detection like masks. The techniques significantly stabilize the end-to-end training process. The experiments on the spatialized wsj1-2mix corpus show that the proposed system achieves about 35% WER relative reduction compared to our conventional multi-channel E2E ASR system, and also obtains decent speech dereverberation and separation performance (SDR=12.5 dB) in the reverberant multi-speaker condition while trained only with the ASR criterion.
Speech recognition with quaternion neural networks
Nov 21, 2018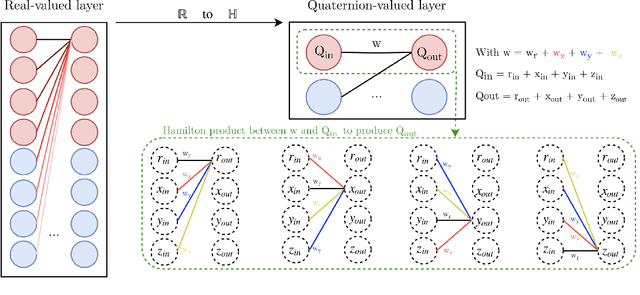
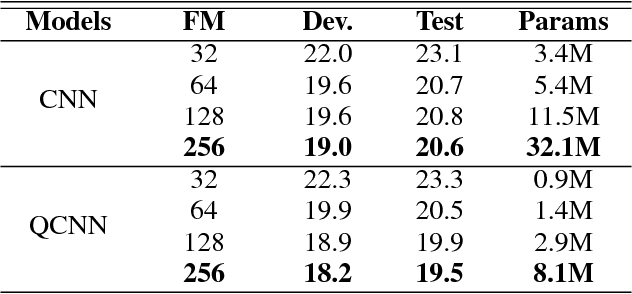
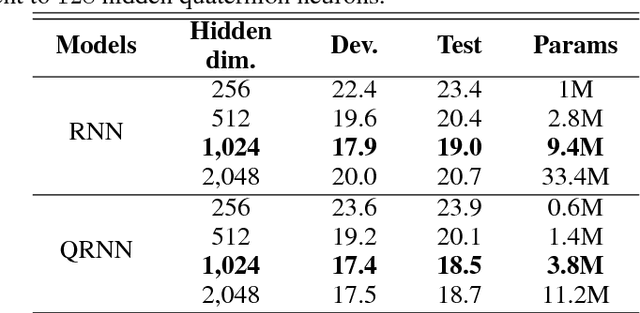
Neural network architectures are at the core of powerful automatic speech recognition systems (ASR). However, while recent researches focus on novel model architectures, the acoustic input features remain almost unchanged. Traditional ASR systems rely on multidimensional acoustic features such as the Mel filter bank energies alongside with the first, and second order derivatives to characterize time-frames that compose the signal sequence. Considering that these components describe three different views of the same element, neural networks have to learn both the internal relations that exist within these features, and external or global dependencies that exist between the time-frames. Quaternion-valued neural networks (QNN), recently received an important interest from researchers to process and learn such relations in multidimensional spaces. Indeed, quaternion numbers and QNNs have shown their efficiency to process multidimensional inputs as entities, to encode internal dependencies, and to solve many tasks with up to four times less learning parameters than real-valued models. We propose to investigate modern quaternion-valued models such as convolutional and recurrent quaternion neural networks in the context of speech recognition with the TIMIT dataset. The experiments show that QNNs always outperform real-valued equivalent models with way less free parameters, leading to a more efficient, compact, and expressive representation of the relevant information.
Transformer with Bidirectional Decoder for Speech Recognition
Aug 11, 2020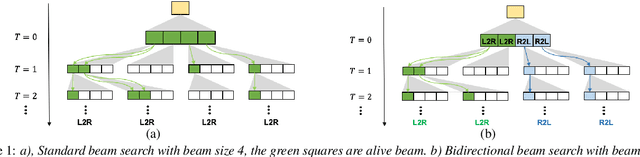
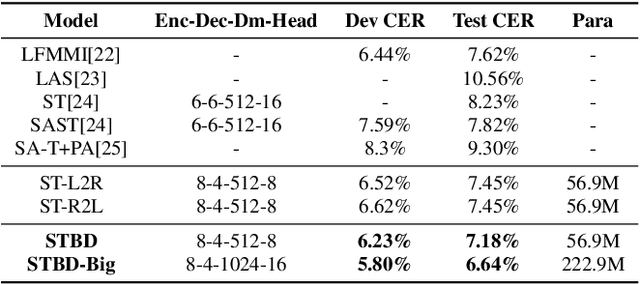
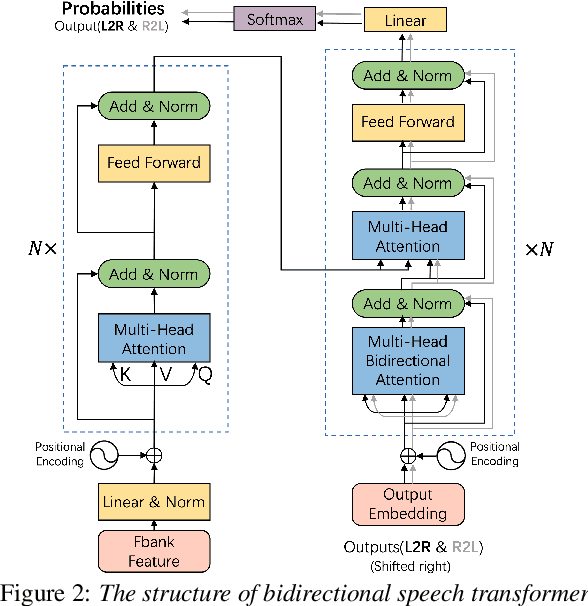

Attention-based models have made tremendous progress on end-to-end automatic speech recognition(ASR) recently. However, the conventional transformer-based approaches usually generate the sequence results token by token from left to right, leaving the right-to-left contexts unexploited. In this work, we introduce a bidirectional speech transformer to utilize the different directional contexts simultaneously. Specifically, the outputs of our proposed transformer include a left-to-right target, and a right-to-left target. In inference stage, we use the introduced bidirectional beam search method, which can not only generate left-to-right candidates but also generate right-to-left candidates, and determine the best hypothesis by the score. To demonstrate our proposed speech transformer with a bidirectional decoder(STBD), we conduct extensive experiments on the AISHELL-1 dataset. The results of experiments show that STBD achieves a 3.6\% relative CER reduction(CERR) over the unidirectional speech transformer baseline. Besides, the strongest model in this paper called STBD-Big can achieve 6.64\% CER on the test set, without language model rescoring and any extra data augmentation strategies.
Fundamental Frequency Feature Normalization and Data Augmentation for Child Speech Recognition
Feb 18, 2021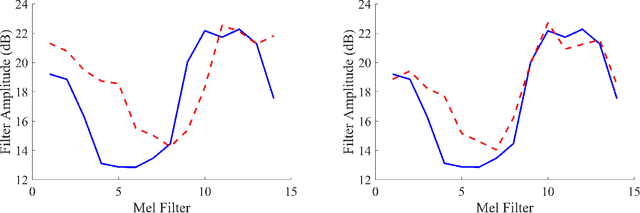
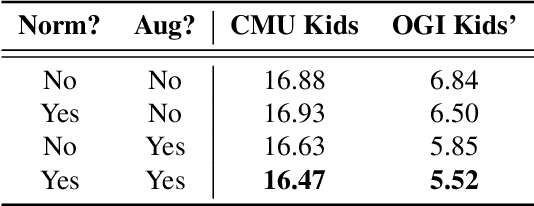
Automatic speech recognition (ASR) systems for young children are needed due to the importance of age-appropriate educational technology. Because of the lack of publicly available young child speech data, feature extraction strategies such as feature normalization and data augmentation must be considered to successfully train child ASR systems. This study proposes a novel technique for child ASR using both feature normalization and data augmentation methods based on the relationship between formants and fundamental frequency ($f_o$). Both the $f_o$ feature normalization and data augmentation techniques are implemented as a frequency shift in the Mel domain. These techniques are evaluated on a child read speech ASR task. Child ASR systems are trained by adapting a BLSTM-based acoustic model trained on adult speech. Using both $f_o$ normalization and data augmentation results in a relative word error rate (WER) improvement of 19.3% over the baseline when tested on the OGI Kids' Speech Corpus, and the resulting child ASR system achieves the best WER currently reported on this corpus.
Improved Robustness to Disfluencies in RNN-Transducer Based Speech Recognition
Dec 11, 2020



Automatic Speech Recognition (ASR) based on Recurrent Neural Network Transducers (RNN-T) is gaining interest in the speech community. We investigate data selection and preparation choices aiming for improved robustness of RNN-T ASR to speech disfluencies with a focus on partial words. For evaluation we use clean data, data with disfluencies and a separate dataset with speech affected by stuttering. We show that after including a small amount of data with disfluencies in the training set the recognition accuracy on the tests with disfluencies and stuttering improves. Increasing the amount of training data with disfluencies gives additional gains without degradation on the clean data. We also show that replacing partial words with a dedicated token helps to get even better accuracy on utterances with disfluencies and stutter. The evaluation of our best model shows 22.5% and 16.4% relative WER reduction on those two evaluation sets.