 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
PM-MMUT: Boosted Phone-mask Data Augmentation using Multi-modeing Unit Training for Robust Uyghur E2E Speech Recognition
Dec 13, 2021
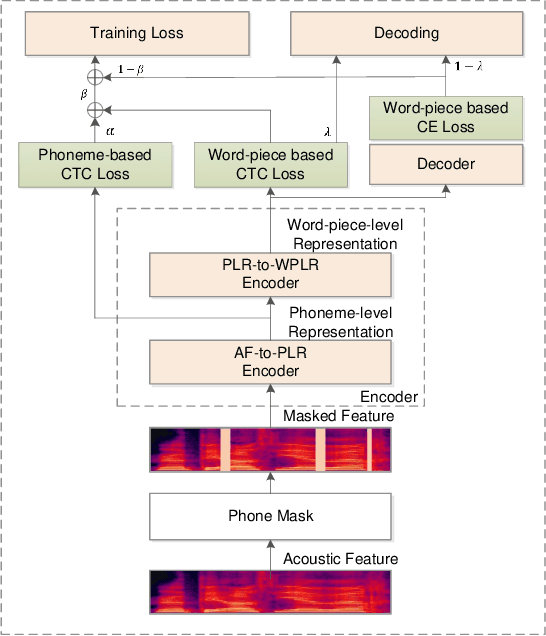
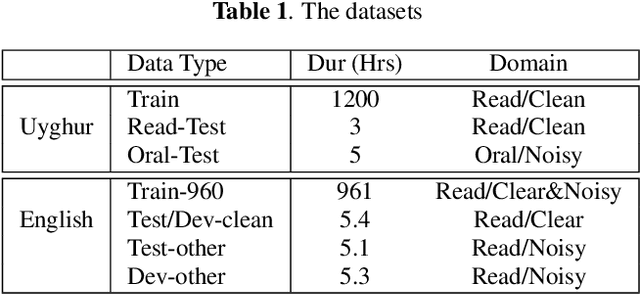
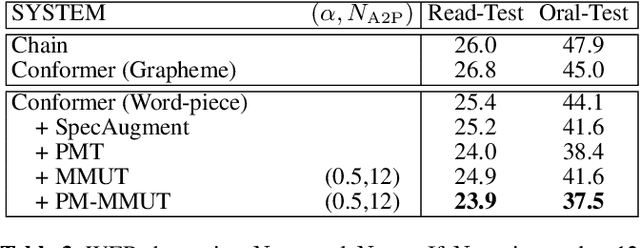
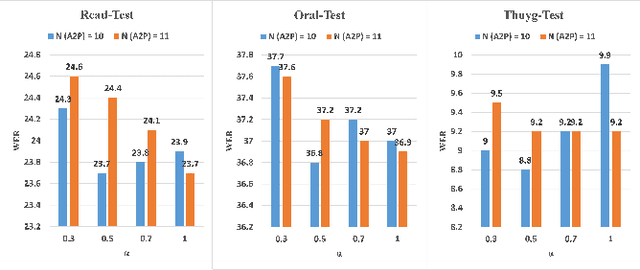
Consonant and vowel reduction are often encountered in Uyghur speech, which might cause performance degradation in Uyghur automatic speech recognition (ASR). Our recently proposed learning strategy based on masking, Phone Masking Training (PMT), alleviates the impact of such phenomenon in Uyghur ASR. Although PMT achieves remarkably improvements, there still exists room for further gains due to the granularity mismatch between masking unit of PMT (phoneme) and modeling unit (word-piece). To boost the performance of PMT, we propose multi-modeling unit training (MMUT) architecture fusion with PMT (PM-MMUT). The idea of MMUT framework is to split the Encoder into two parts including acoustic feature sequences to phoneme-level representation (AF-to-PLR) and phoneme-level representation to word-piece-level representation (PLR-to-WPLR). It allows AF-to-PLR to be optimized by an intermediate phoneme-based CTC loss to learn the rich phoneme-level context information brought by PMT. Experi-mental results on Uyghur ASR show that the proposed approaches improve significantly, outperforming the pure PMT (reduction WER from 24.0 to 23.7 on Read-Test and from 38.4 to 36.8 on Oral-Test respectively). We also conduct experiments on the 960-hour Librispeech benchmark using ESPnet1, which achieves about 10% relative WER reduction on all the test sets without LM fusion comparing with the latest official ESPnet1 pre-trained model.
Pre-training in Deep Reinforcement Learning for Automatic Speech Recognition
Oct 24, 2019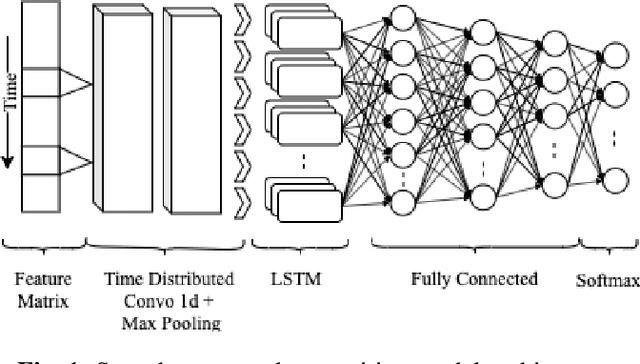

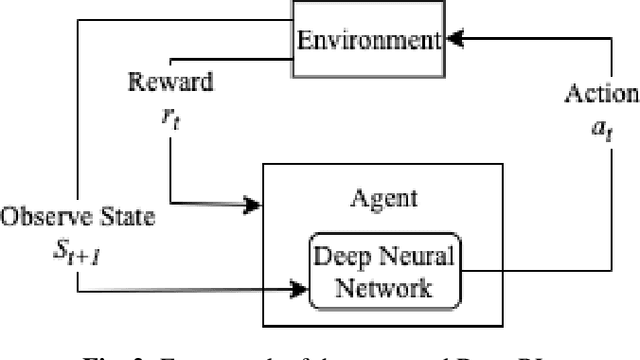
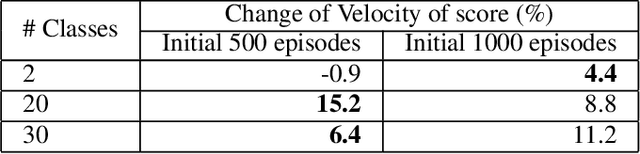
Deep reinforcement learning (deep RL) is a combination of deep learning with reinforcement learning principles to create efficient methods that can learn by interacting with its environment. This led to breakthroughs in many complex tasks that were previously difficult to solve. However, deep RL requires a large amount of training time that makes it difficult to use in various real-life applications like human-computer interaction (HCI). Therefore, in this paper, we study pre-training in deep RL to reduce the training time and improve the performance in speech recognition, a popular application of HCI. We achieve significantly improved performance in less time on a publicly available speech command recognition dataset.
G-Augment: Searching For The Meta-Structure Of Data Augmentation Policies For ASR
Oct 19, 2022
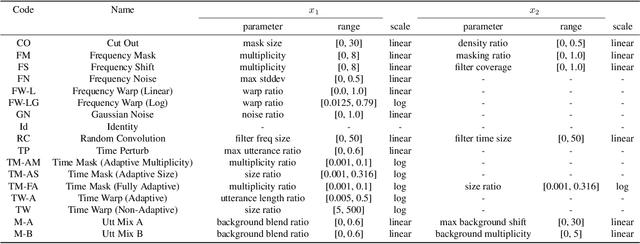
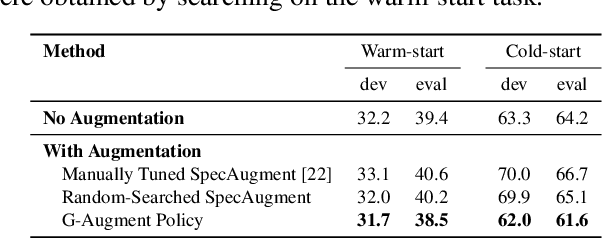
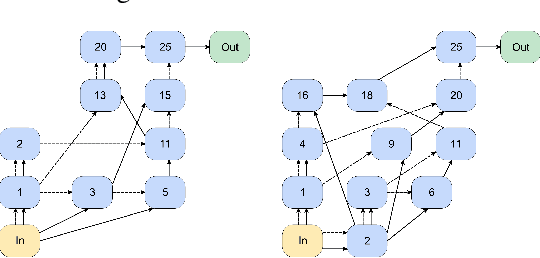
Data augmentation is a ubiquitous technique used to provide robustness to automatic speech recognition (ASR) training. However, even as so much of the ASR training process has become automated and more "end-to-end", the data augmentation policy (what augmentation functions to use, and how to apply them) remains hand-crafted. We present Graph-Augment, a technique to define the augmentation space as directed acyclic graphs (DAGs) and search over this space to optimize the augmentation policy itself. We show that given the same computational budget, policies produced by G-Augment are able to perform better than SpecAugment policies obtained by random search on fine-tuning tasks on CHiME-6 and AMI. G-Augment is also able to establish a new state-of-the-art ASR performance on the CHiME-6 evaluation set (30.7% WER). We further demonstrate that G-Augment policies show better transfer properties across warm-start to cold-start training and model size compared to random-searched SpecAugment policies.
Transformer-based language modeling and decoding for conversational speech recognition
Jan 04, 2020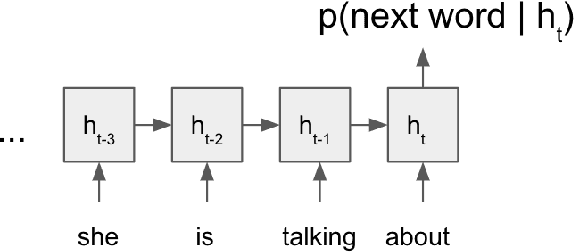
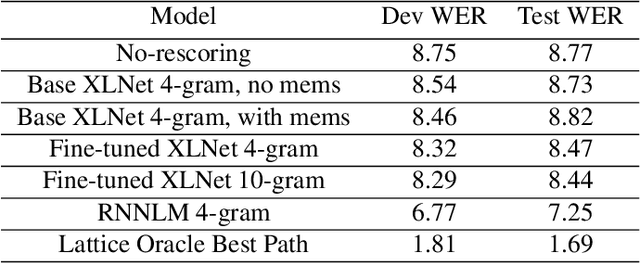
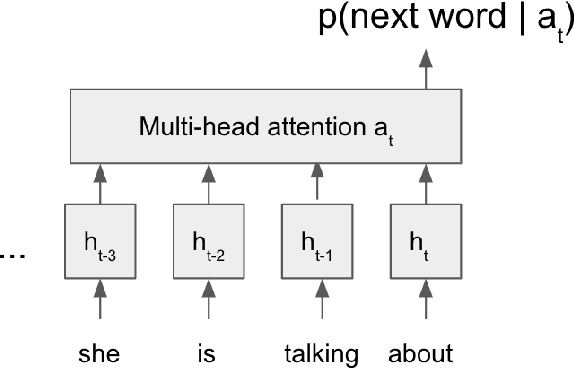
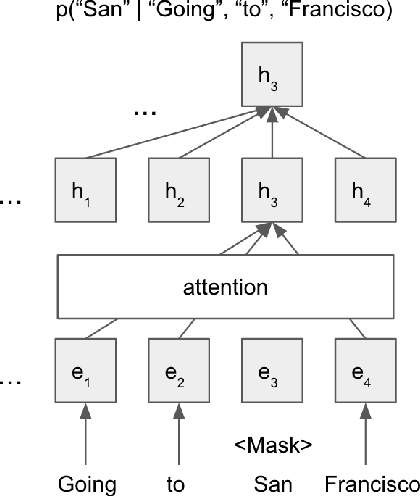
We propose a way to use a transformer-based language model in conversational speech recognition. Specifically, we focus on decoding efficiently in a weighted finite-state transducer framework. We showcase an approach to lattice re-scoring that allows for longer range history captured by a transfomer-based language model and takes advantage of a transformer's ability to avoid computing sequentially.
MVNet: Memory Assistance and Vocal Reinforcement Network for Speech Enhancement
Sep 15, 2022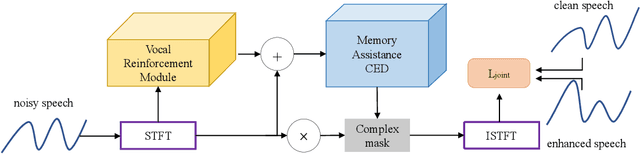
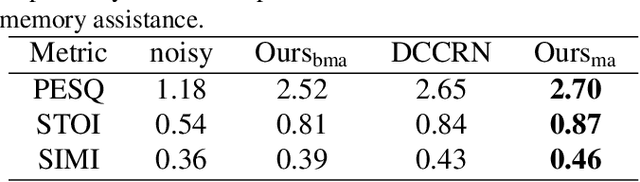
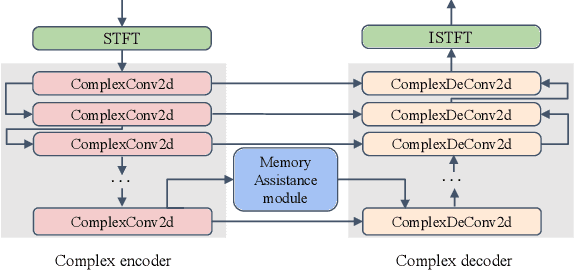
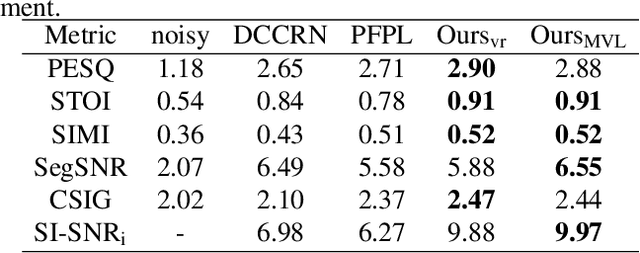
Speech enhancement improves speech quality and promotes the performance of various downstream tasks. However, most current speech enhancement work was mainly devoted to improving the performance of downstream automatic speech recognition (ASR), only a relatively small amount of work focused on the automatic speaker verification (ASV) task. In this work, we propose a MVNet consisted of a memory assistance module which improves the performance of downstream ASR and a vocal reinforcement module which boosts the performance of ASV. In addition, we design a new loss function to improve speaker vocal similarity. Experimental results on the Libri2mix dataset show that our method outperforms baseline methods in several metrics, including speech quality, intelligibility, and speaker vocal similarity et al.
Efficient spike encoding algorithms for neuromorphic speech recognition
Jul 14, 2022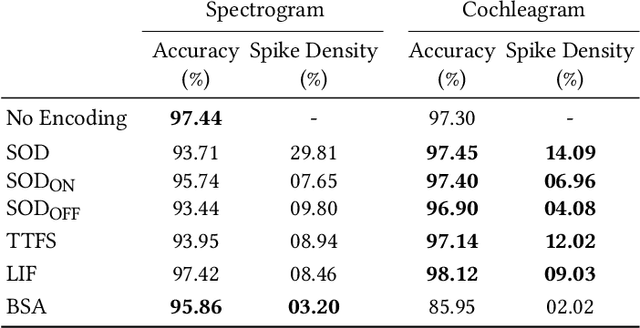
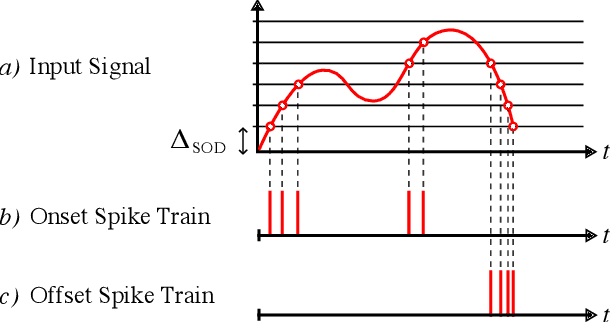

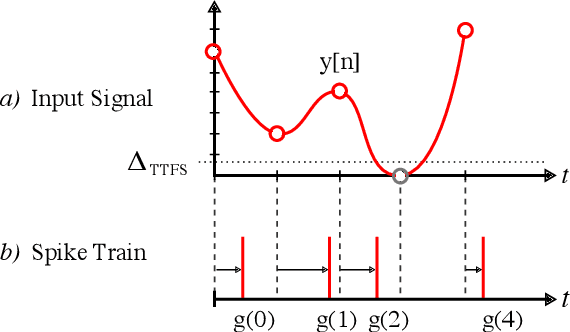
Spiking Neural Networks (SNN) are known to be very effective for neuromorphic processor implementations, achieving orders of magnitude improvements in energy efficiency and computational latency over traditional deep learning approaches. Comparable algorithmic performance was recently made possible as well with the adaptation of supervised training algorithms to the context of SNN. However, information including audio, video, and other sensor-derived data are typically encoded as real-valued signals that are not well-suited to SNN, preventing the network from leveraging spike timing information. Efficient encoding from real-valued signals to spikes is therefore critical and significantly impacts the performance of the overall system. To efficiently encode signals into spikes, both the preservation of information relevant to the task at hand as well as the density of the encoded spikes must be considered. In this paper, we study four spike encoding methods in the context of a speaker independent digit classification system: Send on Delta, Time to First Spike, Leaky Integrate and Fire Neuron and Bens Spiker Algorithm. We first show that all encoding methods yield higher classification accuracy using significantly fewer spikes when encoding a bio-inspired cochleagram as opposed to a traditional short-time Fourier transform. We then show that two Send On Delta variants result in classification results comparable with a state of the art deep convolutional neural network baseline, while simultaneously reducing the encoded bit rate. Finally, we show that several encoding methods result in improved performance over the conventional deep learning baseline in certain cases, further demonstrating the power of spike encoding algorithms in the encoding of real-valued signals and that neuromorphic implementation has the potential to outperform state of the art techniques.
Foundation Transformers
Oct 12, 2022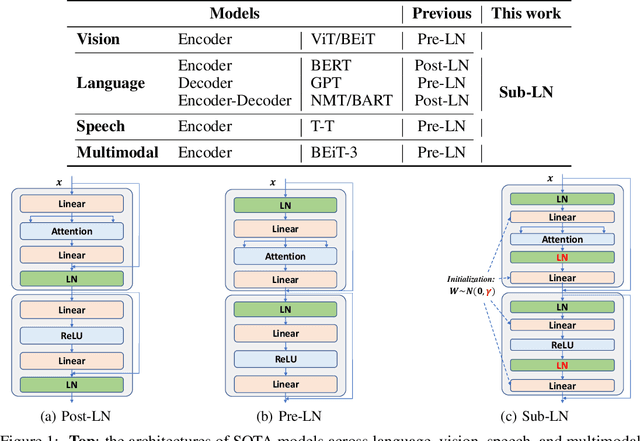
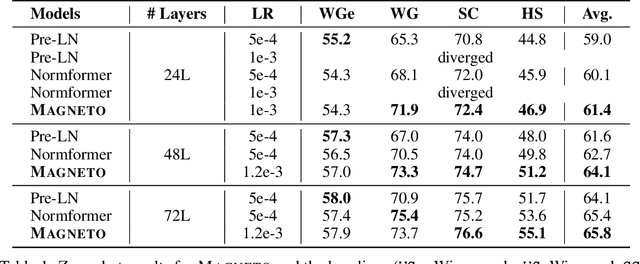
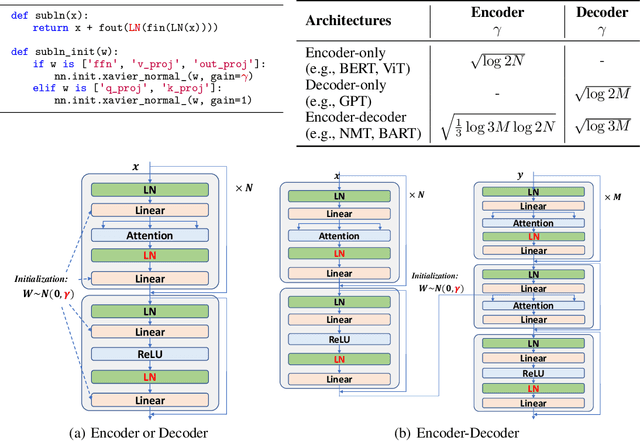
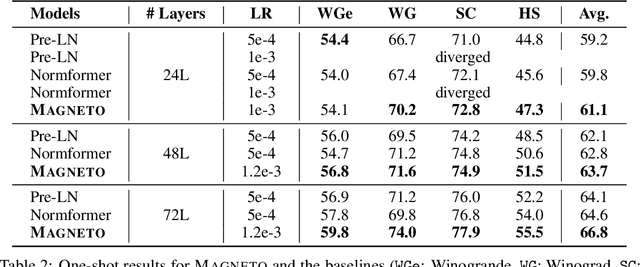
A big convergence of model architectures across language, vision, speech, and multimodal is emerging. However, under the same name "Transformers", the above areas use different implementations for better performance, e.g., Post-LayerNorm for BERT, and Pre-LayerNorm for GPT and vision Transformers. We call for the development of Foundation Transformer for true general-purpose modeling, which serves as a go-to architecture for various tasks and modalities with guaranteed training stability. In this work, we introduce a Transformer variant, named Magneto, to fulfill the goal. Specifically, we propose Sub-LayerNorm for good expressivity, and the initialization strategy theoretically derived from DeepNet for stable scaling up. Extensive experiments demonstrate its superior performance and better stability than the de facto Transformer variants designed for various applications, including language modeling (i.e., BERT, and GPT), machine translation, vision pretraining (i.e., BEiT), speech recognition, and multimodal pretraining (i.e., BEiT-3).
Multitask Learning from Augmented Auxiliary Data for Improving Speech Emotion Recognition
Jul 12, 2022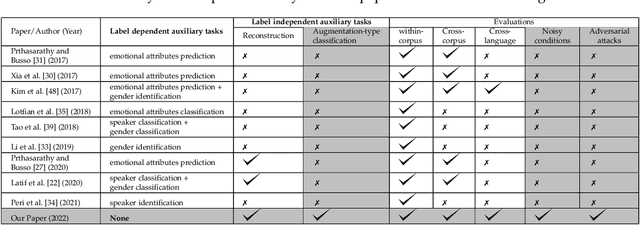
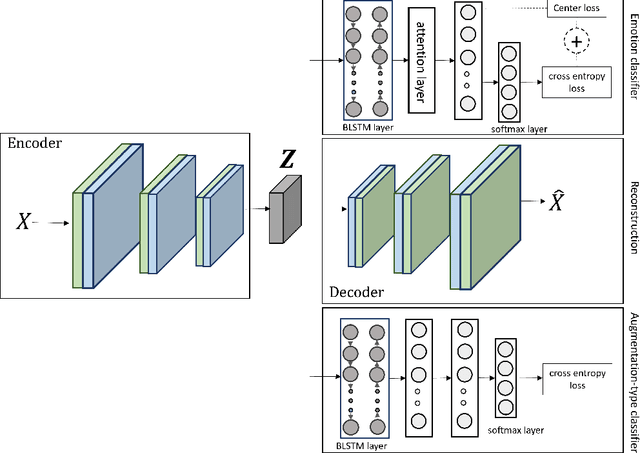
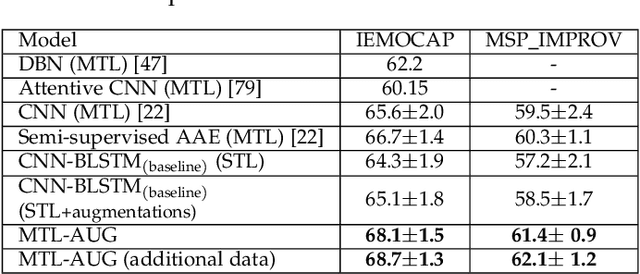
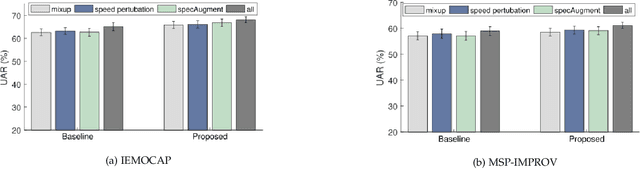
Despite the recent progress in speech emotion recognition (SER), state-of-the-art systems lack generalisation across different conditions. A key underlying reason for poor generalisation is the scarcity of emotion datasets, which is a significant roadblock to designing robust machine learning (ML) models. Recent works in SER focus on utilising multitask learning (MTL) methods to improve generalisation by learning shared representations. However, most of these studies propose MTL solutions with the requirement of meta labels for auxiliary tasks, which limits the training of SER systems. This paper proposes an MTL framework (MTL-AUG) that learns generalised representations from augmented data. We utilise augmentation-type classification and unsupervised reconstruction as auxiliary tasks, which allow training SER systems on augmented data without requiring any meta labels for auxiliary tasks. The semi-supervised nature of MTL-AUG allows for the exploitation of the abundant unlabelled data to further boost the performance of SER. We comprehensively evaluate the proposed framework in the following settings: (1) within corpus, (2) cross-corpus and cross-language, (3) noisy speech, (4) and adversarial attacks. Our evaluations using the widely used IEMOCAP, MSP-IMPROV, and EMODB datasets show improved results compared to existing state-of-the-art methods.
Using heterogeneity in semi-supervised transcription hypotheses to improve code-switched speech recognition
Jun 14, 2021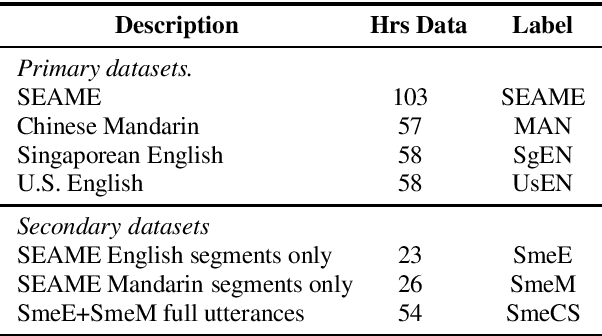
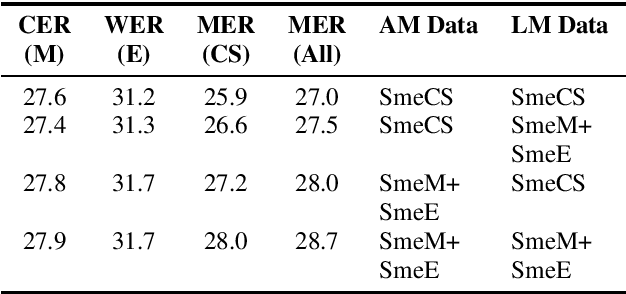
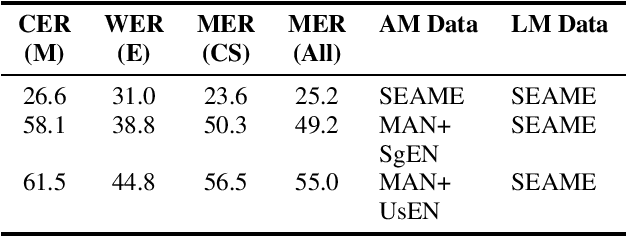
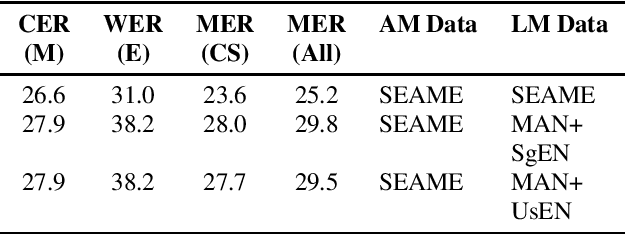
Modeling code-switched speech is an important problem in automatic speech recognition (ASR). Labeled code-switched data are rare, so monolingual data are often used to model code-switched speech. These monolingual data may be more closely matched to one of the languages in the code-switch pair. We show that such asymmetry can bias prediction toward the better-matched language and degrade overall model performance. To address this issue, we propose a semi-supervised approach for code-switched ASR. We consider the case of English-Mandarin code-switching, and the problem of using monolingual data to build bilingual "transcription models'' for annotation of unlabeled code-switched data. We first build multiple transcription models so that their individual predictions are variously biased toward either English or Mandarin. We then combine these biased transcriptions using confidence-based selection. This strategy generates a superior transcript for semi-supervised training, and obtains a 19% relative improvement compared to a semi-supervised system that relies on a transcription model built with only the best-matched monolingual data.
Phoneme Based Neural Transducer for Large Vocabulary Speech Recognition
Oct 30, 2020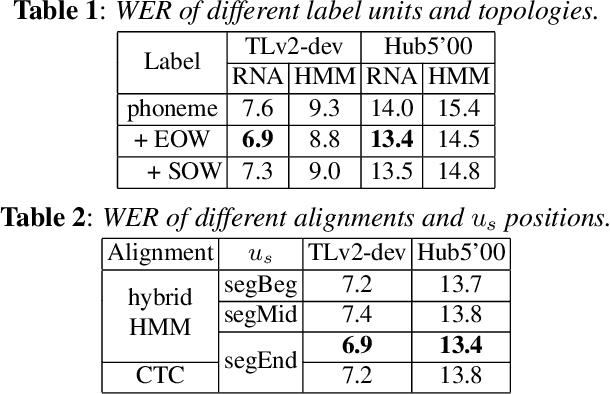
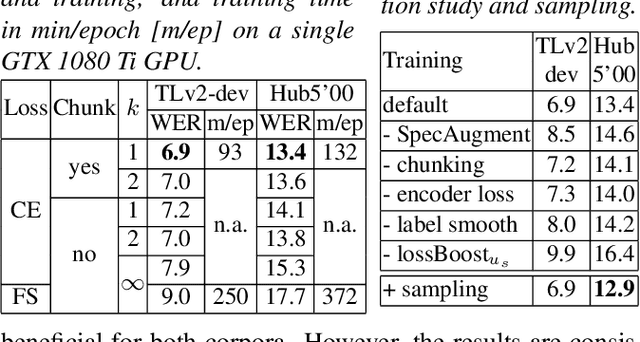

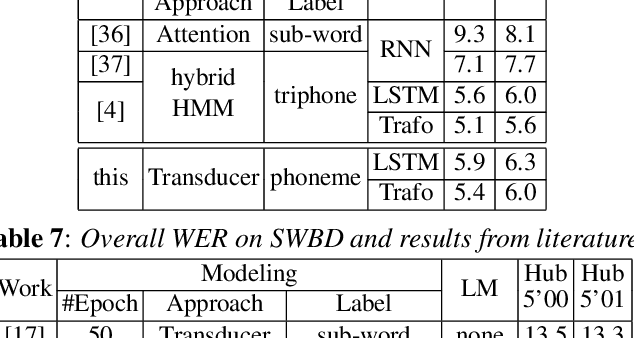
To join the advantages of classical and end-to-end approaches for speech recognition, we present a simple, novel and competitive approach for phoneme-based neural transducer modeling. Different alignment label topologies are compared and word-end-based phoneme label augmentation is proposed to improve performance. Utilizing the local dependency of phonemes, we adopt a simplified neural network structure and a straightforward integration with the external word-level language model to preserve the consistency of seq-to-seq modeling. We also present a simple, stable and efficient training procedure using frame-wise cross-entropy loss. A phonetic context size of one is shown to be sufficient for the best performance. A simplified scheduled sampling approach is applied for further improvement. We also briefly compare different decoding approaches. The overall performance of our best model is comparable to state-of-the-art results for the TED-LIUM Release 2 and Switchboard corpora.