 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
FastCorrect 2: Fast Error Correction on Multiple Candidates for Automatic Speech Recognition
Oct 18, 2021
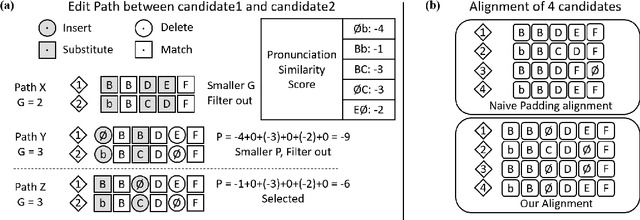
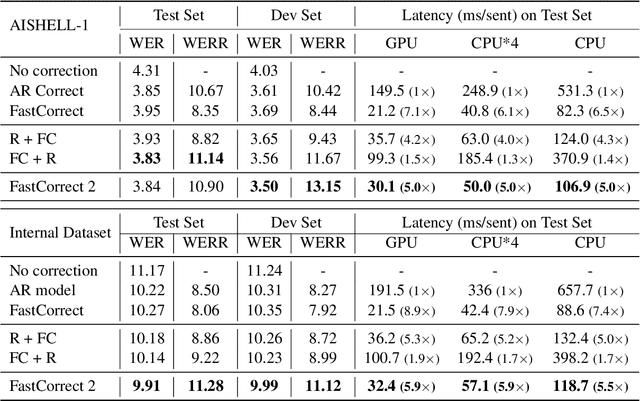
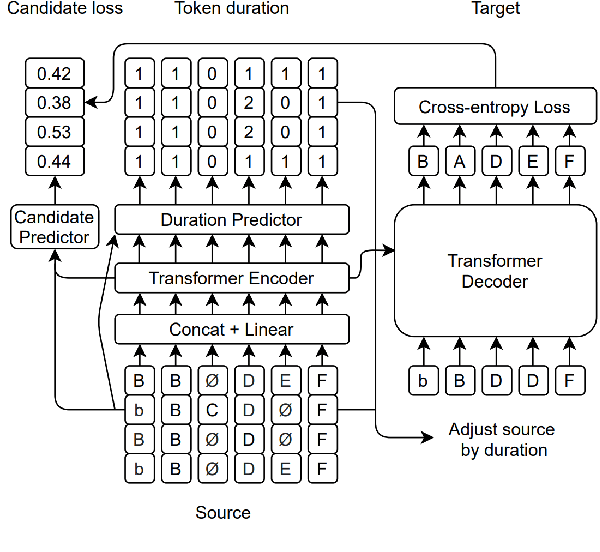
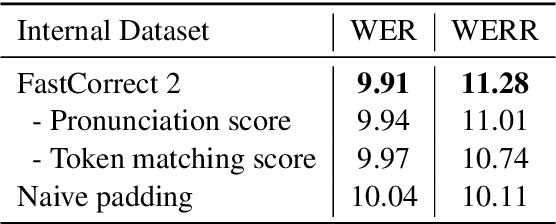
Error correction is widely used in automatic speech recognition (ASR) to post-process the generated sentence, and can further reduce the word error rate (WER). Although multiple candidates are generated by an ASR system through beam search, current error correction approaches can only correct one sentence at a time, failing to leverage the voting effect from multiple candidates to better detect and correct error tokens. In this work, we propose FastCorrect 2, an error correction model that takes multiple ASR candidates as input for better correction accuracy. FastCorrect 2 adopts non-autoregressive generation for fast inference, which consists of an encoder that processes multiple source sentences and a decoder that generates the target sentence in parallel from the adjusted source sentence, where the adjustment is based on the predicted duration of each source token. However, there are some issues when handling multiple source sentences. First, it is non-trivial to leverage the voting effect from multiple source sentences since they usually vary in length. Thus, we propose a novel alignment algorithm to maximize the degree of token alignment among multiple sentences in terms of token and pronunciation similarity. Second, the decoder can only take one adjusted source sentence as input, while there are multiple source sentences. Thus, we develop a candidate predictor to detect the most suitable candidate for the decoder. Experiments on our inhouse dataset and AISHELL-1 show that FastCorrect 2 can further reduce the WER over the previous correction model with single candidate by 3.2% and 2.6%, demonstrating the effectiveness of leveraging multiple candidates in ASR error correction. FastCorrect 2 achieves better performance than the cascaded re-scoring and correction pipeline and can serve as a unified post-processing module for ASR.
Measuring Equality in Machine Learning Security Defenses
Feb 17, 2023
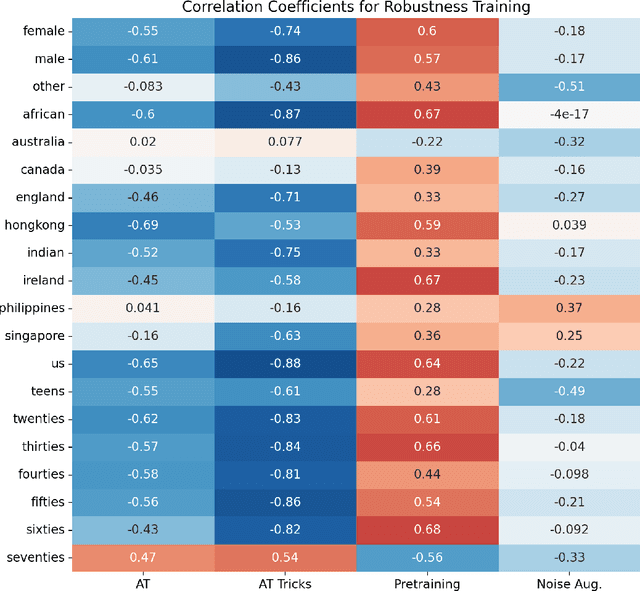
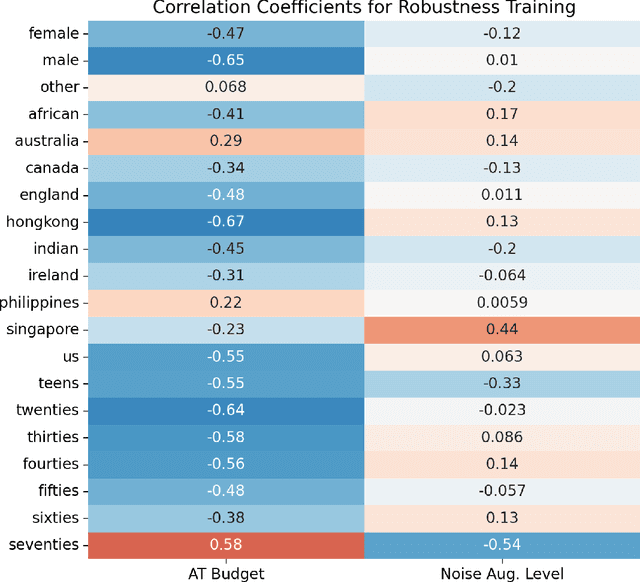
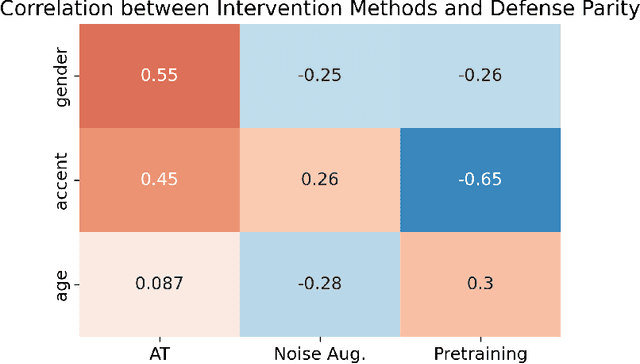
The machine learning security community has developed myriad defenses for evasion attacks over the past decade. An understudied question in that community is: for whom do these defenses defend? In this work, we consider some common approaches to defending learned systems and whether those approaches may offer unexpected performance inequities when used by different sub-populations. We outline simple parity metrics and a framework for analysis that can begin to answer this question through empirical results of the fairness implications of machine learning security methods. Many methods have been proposed that can cause direct harm, which we describe as biased vulnerability and biased rejection. Our framework and metric can be applied to robustly trained models, preprocessing-based methods, and rejection methods to capture behavior over security budgets. We identify a realistic dataset with a reasonable computational cost suitable for measuring the equality of defenses. Through a case study in speech command recognition, we show how such defenses do not offer equal protection for social subgroups and how to perform such analyses for robustness training, and we present a comparison of fairness between two rejection-based defenses: randomized smoothing and neural rejection. We offer further analysis of factors that correlate to equitable defenses to stimulate the future investigation of how to assist in building such defenses. To the best of our knowledge, this is the first work that examines the fairness disparity in the accuracy-robustness trade-off in speech data and addresses fairness evaluation for rejection-based defenses.
AfroDigits: A Community-Driven Spoken Digit Dataset for African Languages
Mar 22, 2023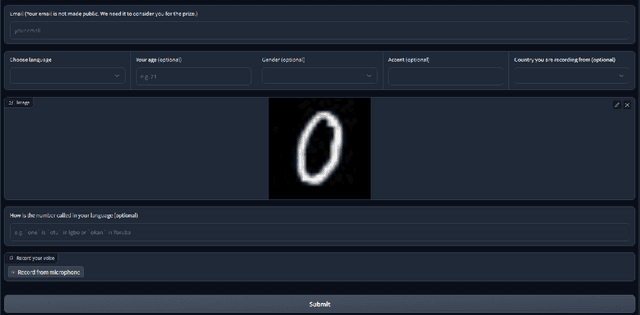
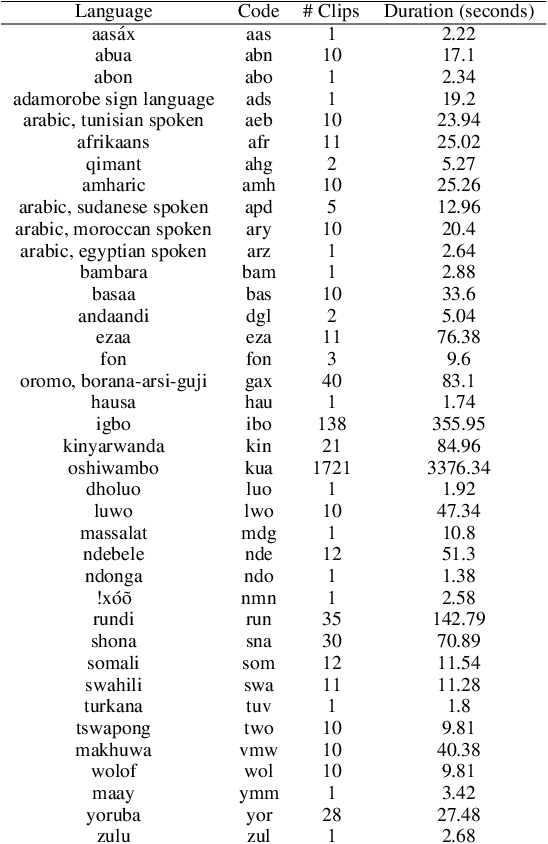
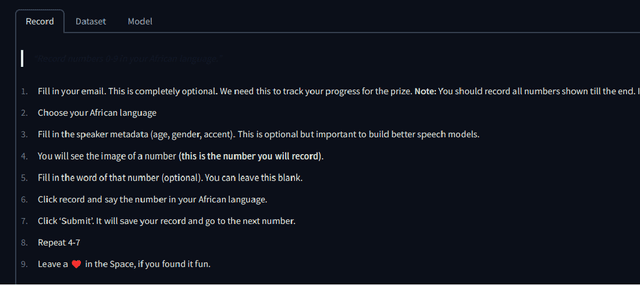
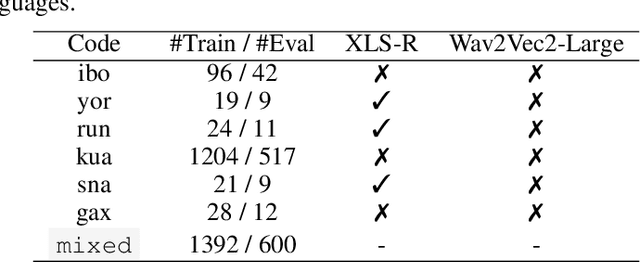
The advancement of speech technologies has been remarkable, yet its integration with African languages remains limited due to the scarcity of African speech corpora. To address this issue, we present AfroDigits, a minimalist, community-driven dataset of spoken digits for African languages, currently covering 38 African languages. As a demonstration of the practical applications of AfroDigits, we conduct audio digit classification experiments on six African languages [Igbo (ibo), Yoruba (yor), Rundi (run), Oshiwambo (kua), Shona (sna), and Oromo (gax)] using the Wav2Vec2.0-Large and XLS-R models. Our experiments reveal a useful insight on the effect of mixing African speech corpora during finetuning. AfroDigits is the first published audio digit dataset for African languages and we believe it will, among other things, pave the way for Afro-centric speech applications such as the recognition of telephone numbers, and street numbers. We release the dataset and platform publicly at https://huggingface.co/datasets/chrisjay/crowd-speech-africa and https://huggingface.co/spaces/chrisjay/afro-speech respectively.
Phoneme Based Neural Transducer for Large Vocabulary Speech Recognition
Nov 09, 2020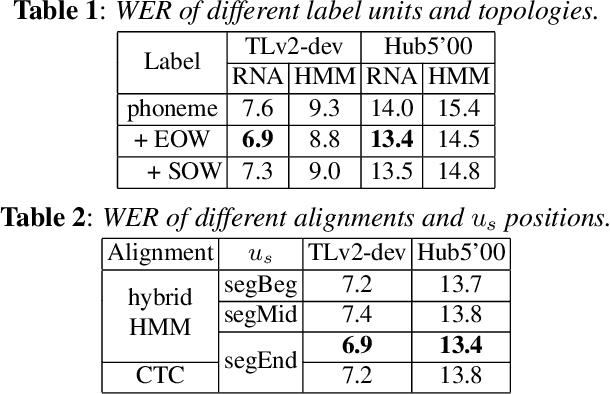
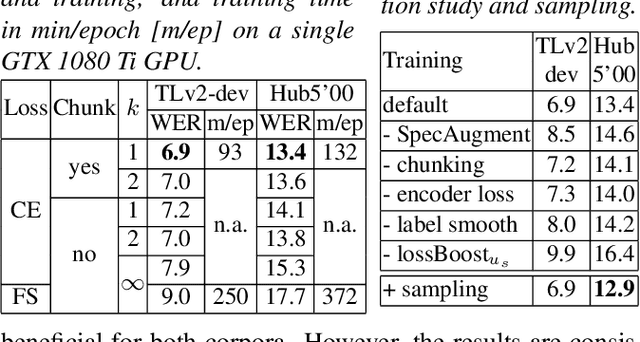

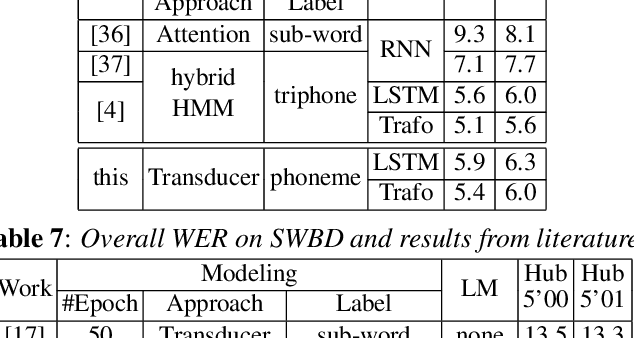
To join the advantages of classical and end-to-end approaches for speech recognition, we present a simple, novel and competitive approach for phoneme-based neural transducer modeling. Different alignment label topologies are compared and word-end-based phoneme label augmentation is proposed to improve performance. Utilizing the local dependency of phonemes, we adopt a simplified neural network structure and a straightforward integration with the external word-level language model to preserve the consistency of seq-to-seq modeling. We also present a simple, stable and efficient training procedure using frame-wise cross-entropy loss. A phonetic context size of one is shown to be sufficient for the best performance. A simplified scheduled sampling approach is applied for further improvement. We also briefly compare different decoding approaches. The overall performance of our best model is comparable to state-of-the-art results for the TED-LIUM Release 2 and Switchboard corpora.
Fast and parallel decoding for transducer
Oct 31, 2022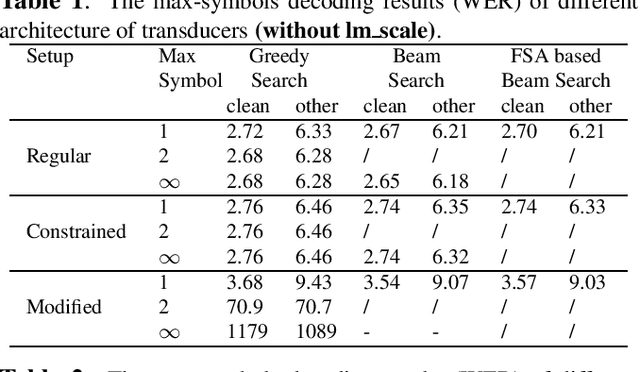
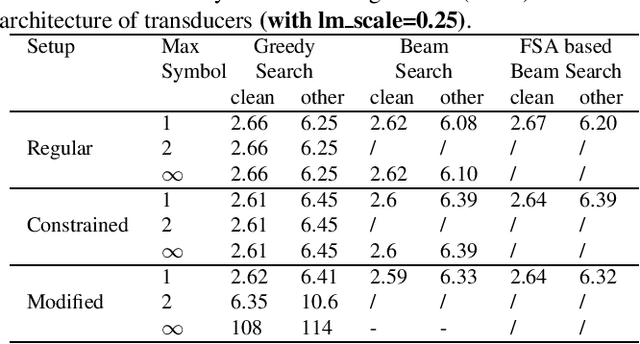
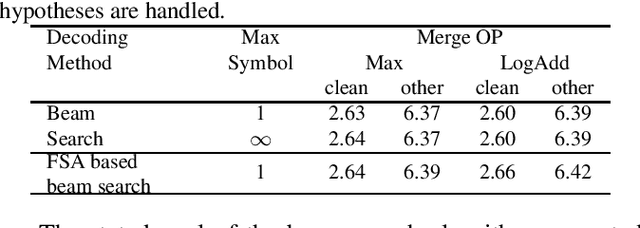
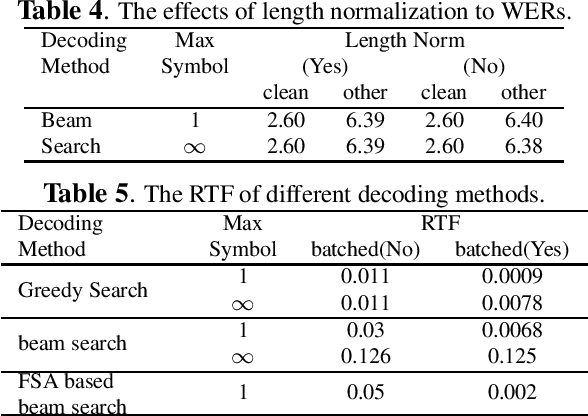
The transducer architecture is becoming increasingly popular in the field of speech recognition, because it is naturally streaming as well as high in accuracy. One of the drawbacks of transducer is that it is difficult to decode in a fast and parallel way due to an unconstrained number of symbols that can be emitted per time step. In this work, we introduce a constrained version of transducer loss to learn strictly monotonic alignments between the sequences; we also improve the standard greedy search and beam search algorithms by limiting the number of symbols that can be emitted per time step in transducer decoding, making it more efficient to decode in parallel with batches. Furthermore, we propose an finite state automaton-based (FSA) parallel beam search algorithm that can run with graphs on GPU efficiently. The experiment results show that we achieve slight word error rate (WER) improvement as well as significant speedup in decoding. Our work is open-sourced and publicly available\footnote{https://github.com/k2-fsa/icefall}.
Speaker-Targeted Audio-Visual Models for Speech Recognition in Cocktail-Party Environments
Jun 13, 2019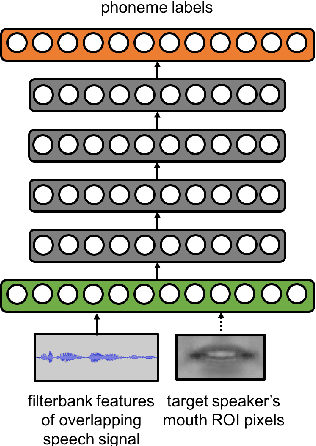
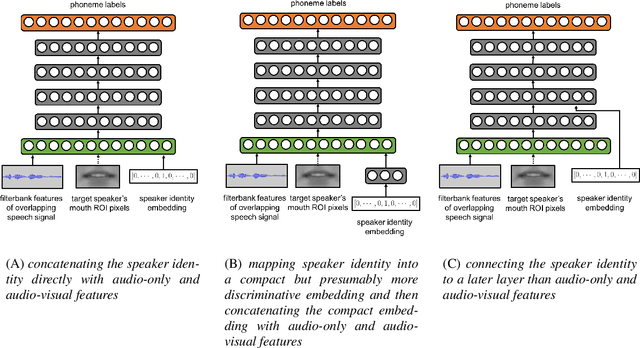

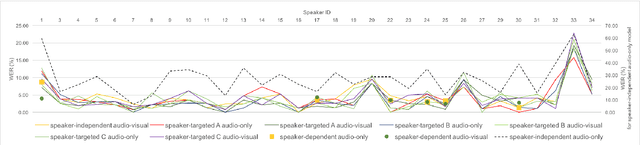
Speech recognition in cocktail-party environments remains a significant challenge for state-of-the-art speech recognition systems, as it is extremely difficult to extract an acoustic signal of an individual speaker from a background of overlapping speech with similar frequency and temporal characteristics. We propose the use of speaker-targeted acoustic and audio-visual models for this task. We complement the acoustic features in a hybrid DNN-HMM model with information of the target speaker's identity as well as visual features from the mouth region of the target speaker. Experimentation was performed using simulated cocktail-party data generated from the GRID audio-visual corpus by overlapping two speakers's speech on a single acoustic channel. Our audio-only baseline achieved a WER of 26.3%. The audio-visual model improved the WER to 4.4%. Introducing speaker identity information had an even more pronounced effect, improving the WER to 3.6%. Combining both approaches, however, did not significantly improve performance further. Our work demonstrates that speaker-targeted models can significantly improve the speech recognition in cocktail party environments.
Self-training and Pre-training are Complementary for Speech Recognition
Oct 22, 2020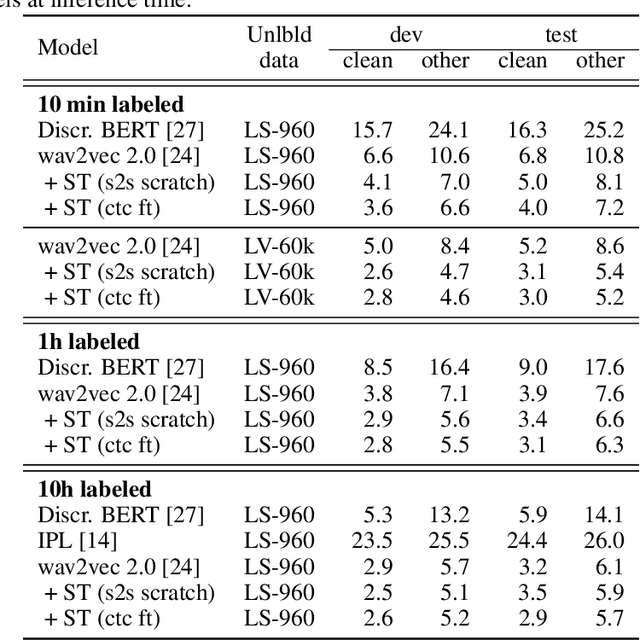
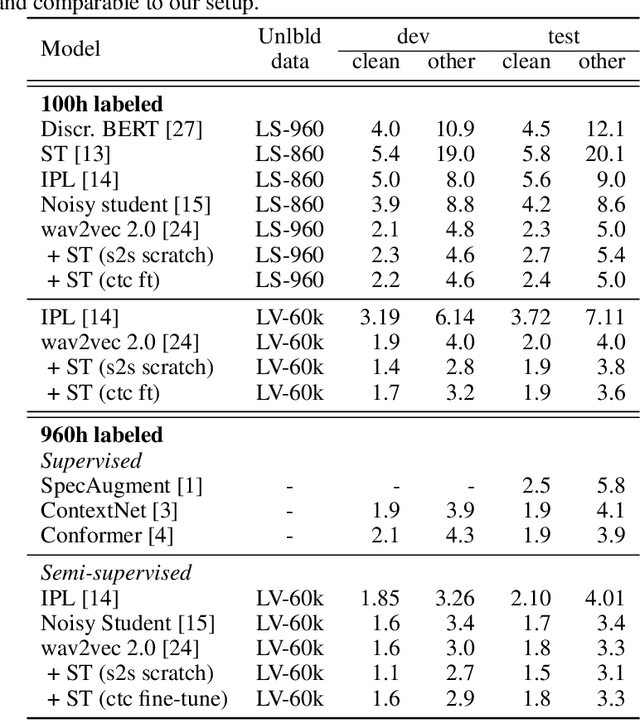
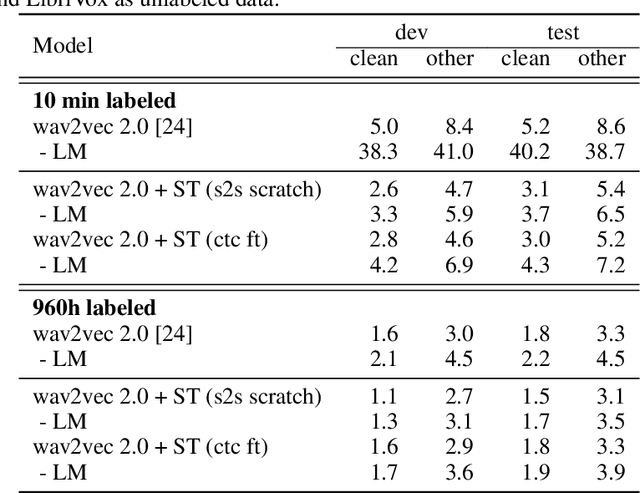
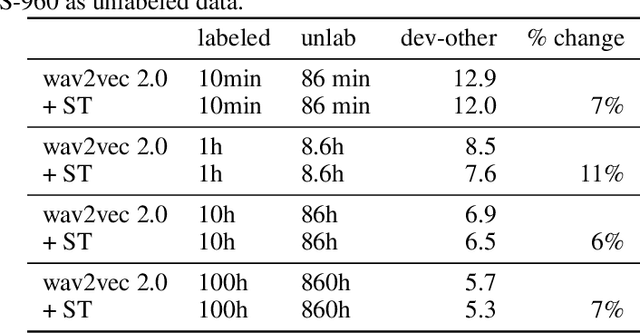
Self-training and unsupervised pre-training have emerged as effective approaches to improve speech recognition systems using unlabeled data. However, it is not clear whether they learn similar patterns or if they can be effectively combined. In this paper, we show that pseudo-labeling and pre-training with wav2vec 2.0 are complementary in a variety of labeled data setups. Using just 10 minutes of labeled data from Libri-light as well as 53k hours of unlabeled data from LibriVox achieves WERs of 3.0%/5.2% on the clean and other test sets of Librispeech - rivaling the best published systems trained on 960 hours of labeled data only a year ago. Training on all labeled data of Librispeech achieves WERs of 1.5%/3.1%.
CNN-based MultiChannel End-to-End Speech Recognition for everyday home environments
Nov 07, 2018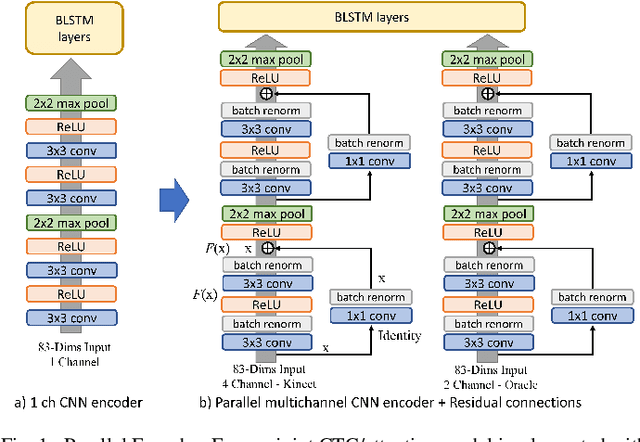

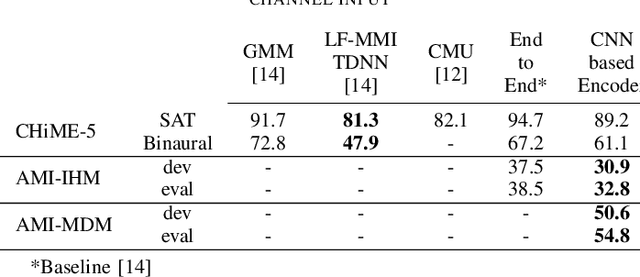
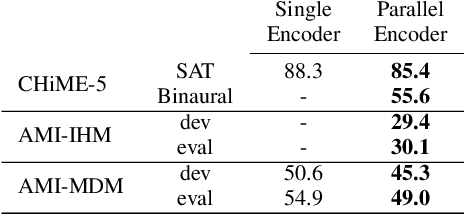
Casual conversations involving multiple speakers and noises from surrounding devices are part of everyday environments and pose challenges for automatic speech recognition systems. These challenges in speech recognition are target for the CHiME-5 challenge. In the present study, an attempt is made to overcome these challenges by employing a convolutional neural network (CNN)-based multichannel end-to-end speech recognition system. The system comprises an attention-based encoder-decoder neural network that directly generates a text as an output from a sound input. The mulitchannel CNN encoder, which uses residual connections and batch renormalization, is trained with augmented data, including white noise injection. The experimental results show that the word error rate (WER) was reduced by 11.9% absolute from the end-to-end baseline.
Provable Robustness for Streaming Models with a Sliding Window
Mar 28, 2023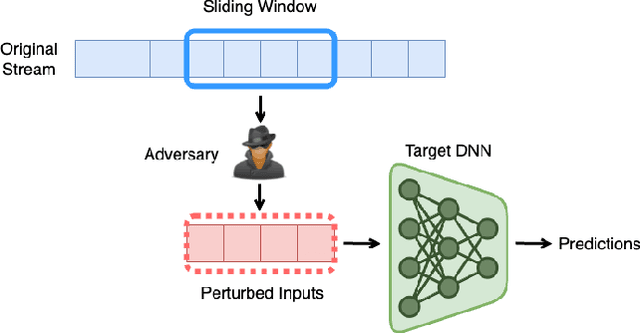
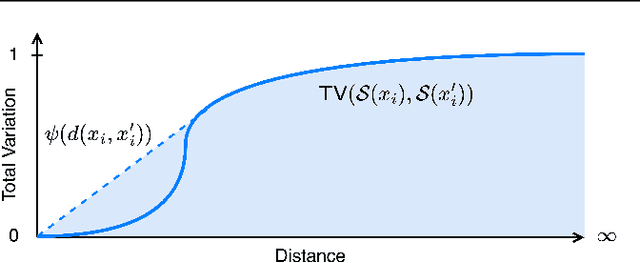

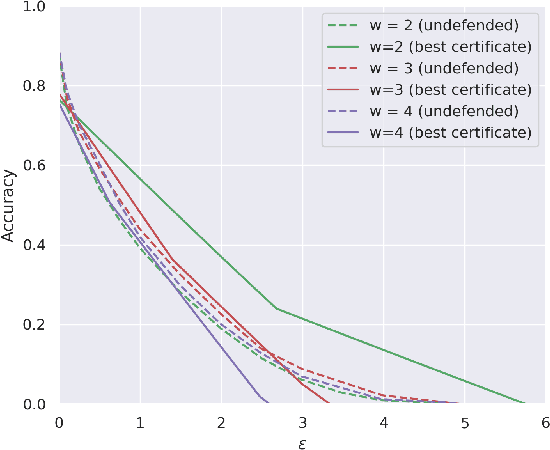
The literature on provable robustness in machine learning has primarily focused on static prediction problems, such as image classification, in which input samples are assumed to be independent and model performance is measured as an expectation over the input distribution. Robustness certificates are derived for individual input instances with the assumption that the model is evaluated on each instance separately. However, in many deep learning applications such as online content recommendation and stock market analysis, models use historical data to make predictions. Robustness certificates based on the assumption of independent input samples are not directly applicable in such scenarios. In this work, we focus on the provable robustness of machine learning models in the context of data streams, where inputs are presented as a sequence of potentially correlated items. We derive robustness certificates for models that use a fixed-size sliding window over the input stream. Our guarantees hold for the average model performance across the entire stream and are independent of stream size, making them suitable for large data streams. We perform experiments on speech detection and human activity recognition tasks and show that our certificates can produce meaningful performance guarantees against adversarial perturbations.
Pre-training in Deep Reinforcement Learning for Automatic Speech Recognition
Oct 26, 2019

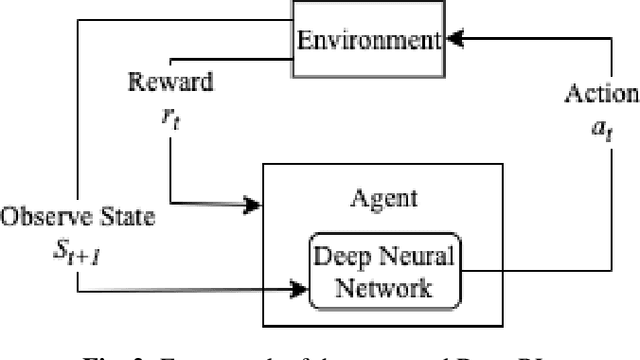
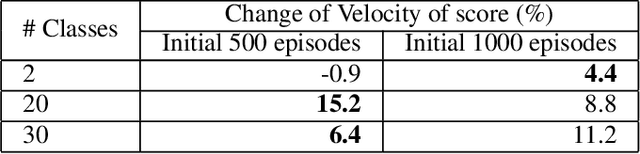
Deep reinforcement learning (deep RL) is a combination of deep learning with reinforcement learning principles to create efficient methods that can learn by interacting with its environment. This led to breakthroughs in many complex tasks that were previously difficult to solve. However, deep RL requires a large amount of training time that makes it difficult to use in various real-life applications like human-computer interaction (HCI). Therefore, in this paper, we study pre-training in deep RL to reduce the training time and improve the performance in speech recognition, a popular application of HCI. We achieve significantly improved performance in less time on a publicly available speech command recognition dataset.