 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Lookup-Table Recurrent Language Models for Long Tail Speech Recognition
Apr 09, 2021
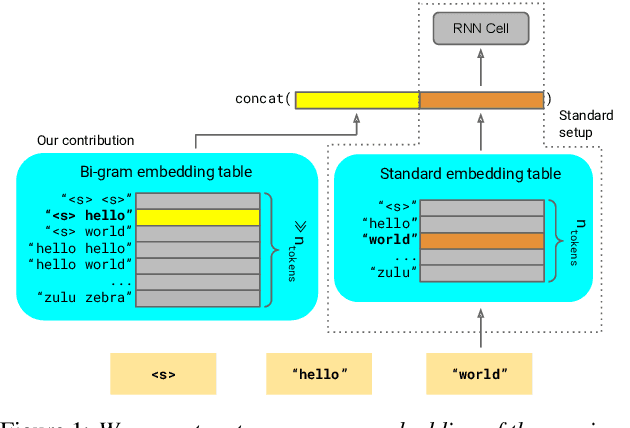
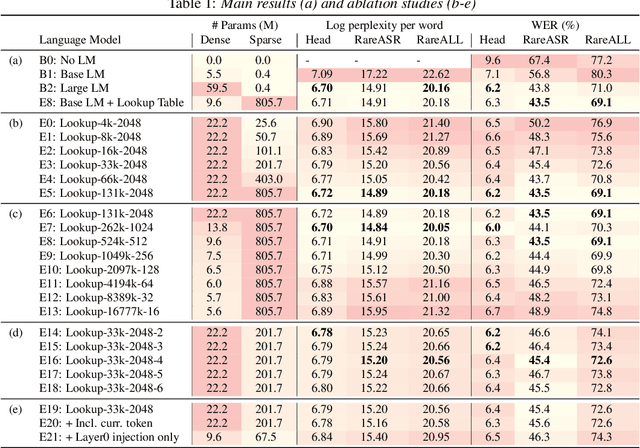
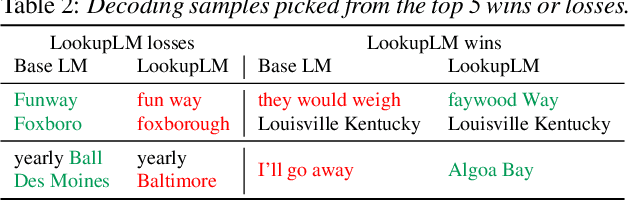

We introduce Lookup-Table Language Models (LookupLM), a method for scaling up the size of RNN language models with only a constant increase in the floating point operations, by increasing the expressivity of the embedding table. In particular, we instantiate an (additional) embedding table which embeds the previous n-gram token sequence, rather than a single token. This allows the embedding table to be scaled up arbitrarily -- with a commensurate increase in performance -- without changing the token vocabulary. Since embeddings are sparsely retrieved from the table via a lookup; increasing the size of the table adds neither extra operations to each forward pass nor extra parameters that need to be stored on limited GPU/TPU memory. We explore scaling n-gram embedding tables up to nearly a billion parameters. When trained on a 3-billion sentence corpus, we find that LookupLM improves long tail log perplexity by 2.44 and long tail WER by 23.4% on a downstream speech recognition task over a standard RNN language model baseline, an improvement comparable to a scaling up the baseline by 6.2x the number of floating point operations.
Perceptive, non-linear Speech Processing and Spiking Neural Networks
Mar 31, 2022Source separation and speech recognition are very difficult in the context of noisy and corrupted speech. Most conventional techniques need huge databases to estimate speech (or noise) density probabilities to perform separation or recognition. We discuss the potential of perceptive speech analysis and processing in combination with biologically plausible neural network processors. We illustrate the potential of such non-linear processing of speech on a source separation system inspired by an Auditory Scene Analysis paradigm. We also discuss a potential application in speech recognition.
Jira: a Kurdish Speech Recognition System Designing and Building Speech Corpus and Pronunciation Lexicon
Feb 15, 2021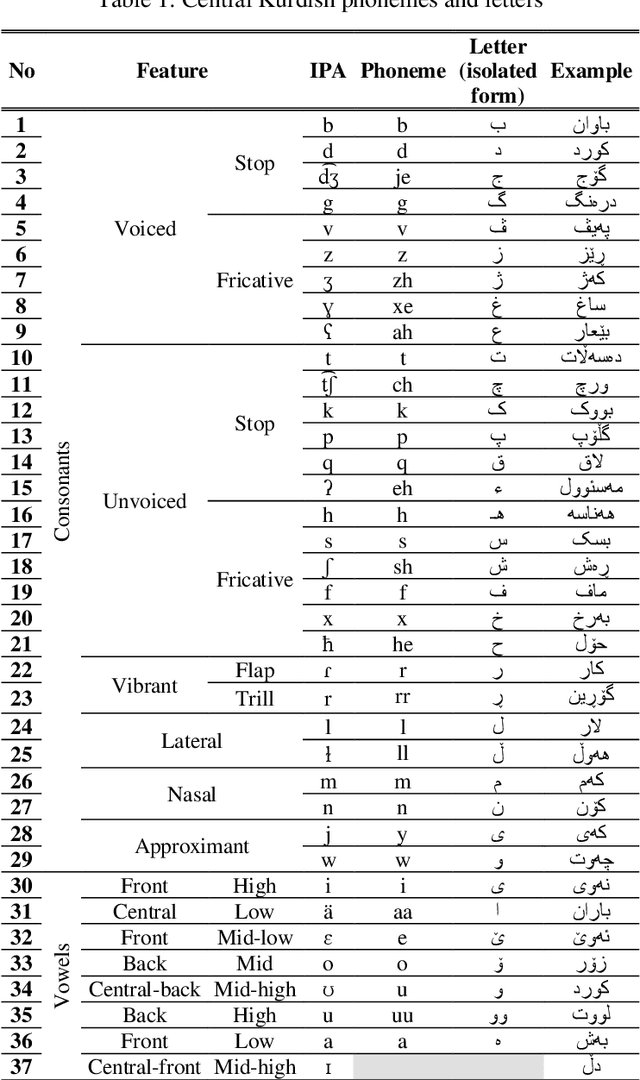
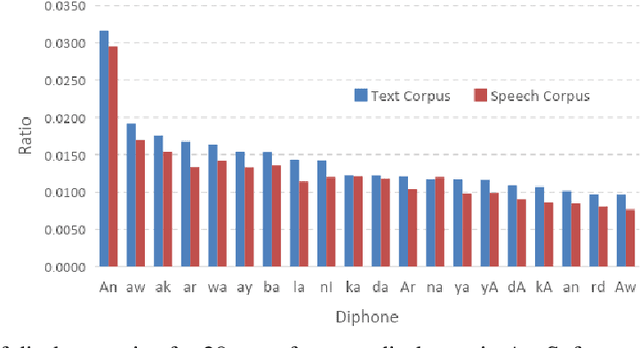

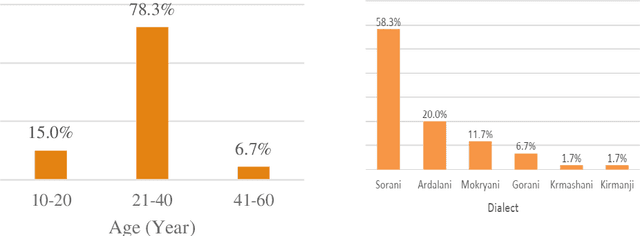
In this paper, we introduce the first large vocabulary speech recognition system (LVSR) for the Central Kurdish language, named Jira. The Kurdish language is an Indo-European language spoken by more than 30 million people in several countries, but due to the lack of speech and text resources, there is no speech recognition system for this language. To fill this gap, we introduce the first speech corpus and pronunciation lexicon for the Kurdish language. Regarding speech corpus, we designed a sentence collection in which the ratio of di-phones in the collection resembles the real data of the Central Kurdish language. The designed sentences are uttered by 576 speakers in a controlled environment with noise-free microphones (called AsoSoft Speech-Office) and in Telegram social network environment using mobile phones (denoted as AsoSoft Speech-Crowdsourcing), resulted in 43.68 hours of speech. Besides, a test set including 11 different document topics is designed and recorded in two corresponding speech conditions (i.e., Office and Crowdsourcing). Furthermore, a 60K pronunciation lexicon is prepared in this research in which we faced several challenges and proposed solutions for them. The Kurdish language has several dialects and sub-dialects that results in many lexical variations. Our methods for script standardization of lexical variations and automatic pronunciation of the lexicon tokens are presented in detail. To setup the recognition engine, we used the Kaldi toolkit. A statistical tri-gram language model that is extracted from the AsoSoft text corpus is used in the system. Several standard recipes including HMM-based models (i.e., mono, tri1, tr2, tri2, tri3), SGMM, and DNN methods are used to generate the acoustic model. These methods are trained with AsoSoft Speech-Office and AsoSoft Speech-Crowdsourcing and a combination of them. The best performance achieved by the SGMM acoustic model which results in 13.9% of the average word error rate (on different document topics) and 4.9% for the general topic.
Transfer Learning from Audio-Visual Grounding to Speech Recognition
Jul 09, 2019
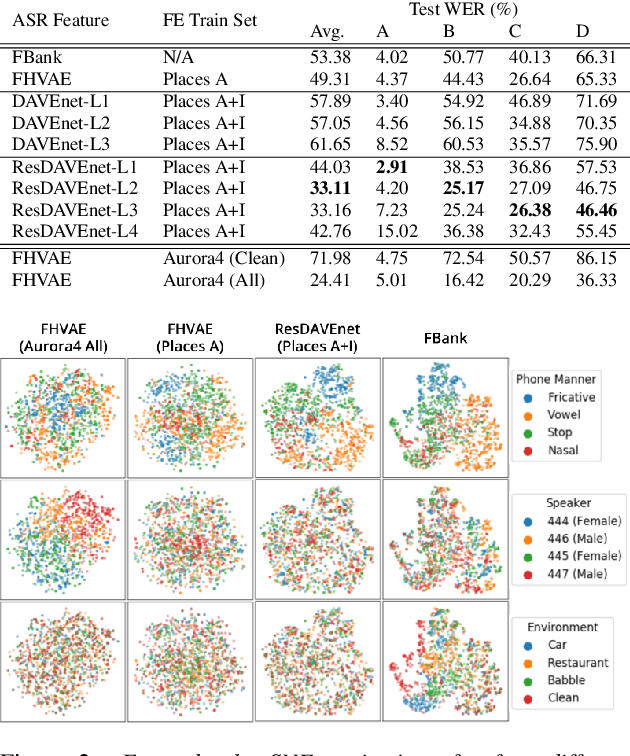
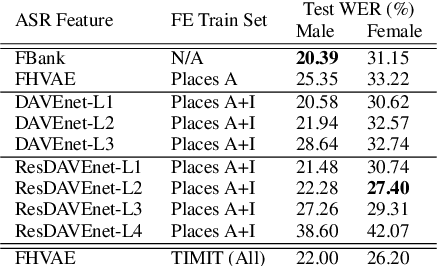
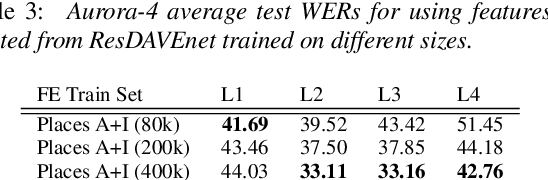
Transfer learning aims to reduce the amount of data required to excel at a new task by re-using the knowledge acquired from learning other related tasks. This paper proposes a novel transfer learning scenario, which distills robust phonetic features from grounding models that are trained to tell whether a pair of image and speech are semantically correlated, without using any textual transcripts. As semantics of speech are largely determined by its lexical content, grounding models learn to preserve phonetic information while disregarding uncorrelated factors, such as speaker and channel. To study the properties of features distilled from different layers, we use them as input separately to train multiple speech recognition models. Empirical results demonstrate that layers closer to input retain more phonetic information, while following layers exhibit greater invariance to domain shift. Moreover, while most previous studies include training data for speech recognition for feature extractor training, our grounding models are not trained on any of those data, indicating more universal applicability to new domains.
Bridging Speech and Textual Pre-trained Models with Unsupervised ASR
Nov 06, 2022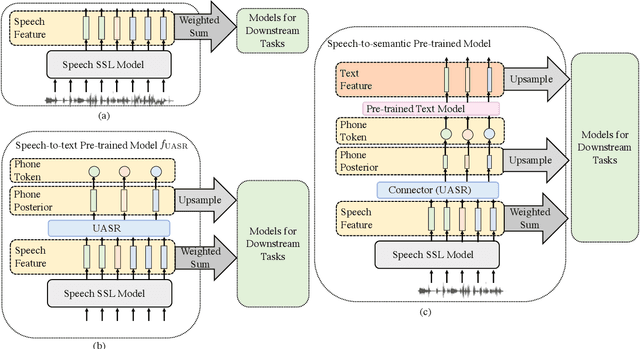
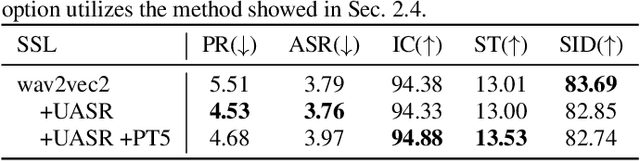
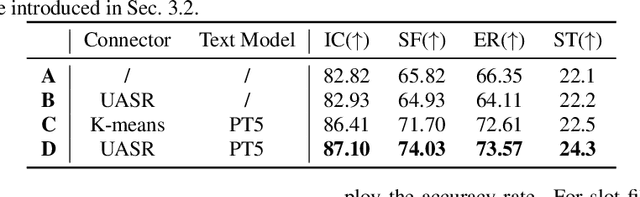
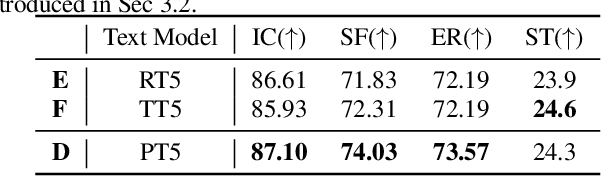
Spoken language understanding (SLU) is a task aiming to extract high-level semantics from spoken utterances. Previous works have investigated the use of speech self-supervised models and textual pre-trained models, which have shown reasonable improvements to various SLU tasks. However, because of the mismatched modalities between speech signals and text tokens, previous methods usually need complex designs of the frameworks. This work proposes a simple yet efficient unsupervised paradigm that connects speech and textual pre-trained models, resulting in an unsupervised speech-to-semantic pre-trained model for various tasks in SLU. To be specific, we propose to use unsupervised automatic speech recognition (ASR) as a connector that bridges different modalities used in speech and textual pre-trained models. Our experiments show that unsupervised ASR itself can improve the representations from speech self-supervised models. More importantly, it is shown as an efficient connector between speech and textual pre-trained models, improving the performances of five different SLU tasks. Notably, on spoken question answering, we reach the state-of-the-art result over the challenging NMSQA benchmark.
Efficient Use of Large Pre-Trained Models for Low Resource ASR
Oct 26, 2022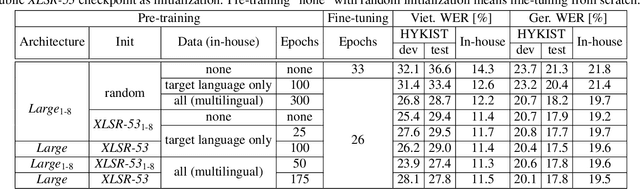
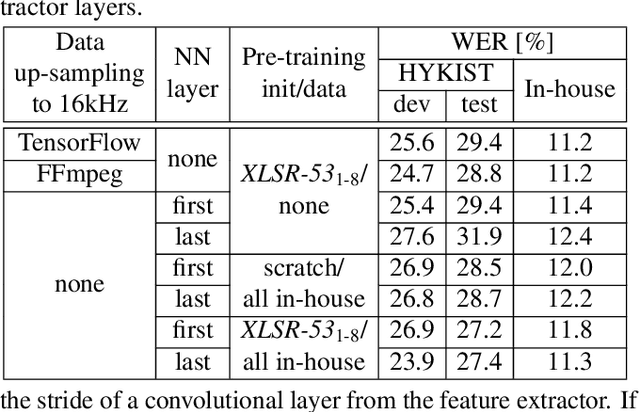
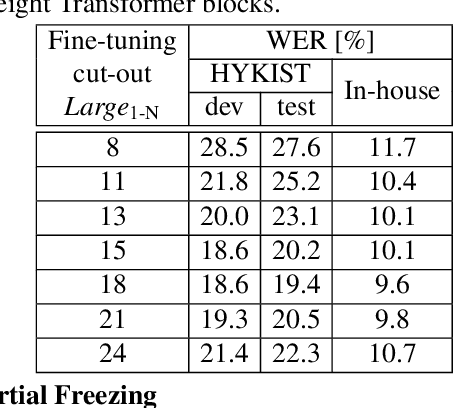
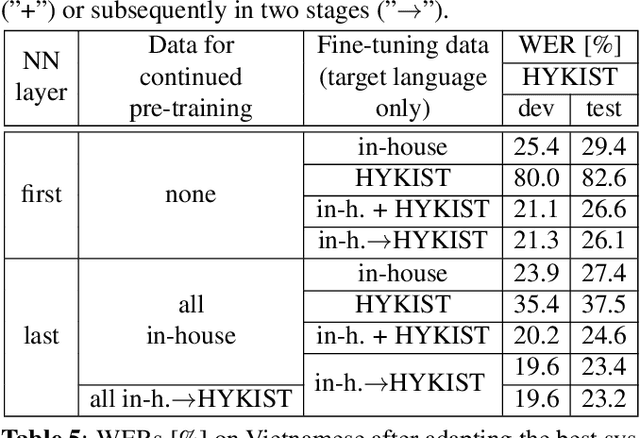
Automatic speech recognition (ASR) has been established as a well-performing technique for many scenarios where lots of labeled data is available. Additionally, unsupervised representation learning recently helped to tackle tasks with limited data. Following this, hardware limitations and applications give rise to the question how to efficiently take advantage of large pretrained models and reduce their complexity for downstream tasks. In this work, we study a challenging low resource conversational telephony speech corpus from the medical domain in Vietnamese and German. We show the benefits of using unsupervised techniques beyond simple fine-tuning of large pre-trained models, discuss how to adapt them to a practical telephony task including bandwidth transfer and investigate different data conditions for pre-training and fine-tuning. We outperform the project baselines by 22% relative using pretraining techniques. Further gains of 29% can be achieved by refinements of architecture and training and 6% by adding 0.8 h of in-domain adaptation data.
Speech Aware Dialog System Technology Challenge (DSTC11)
Dec 16, 2022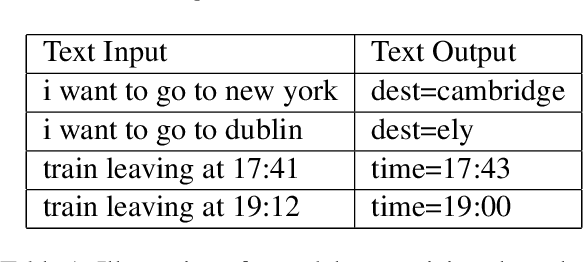
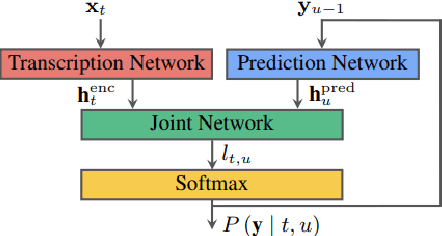
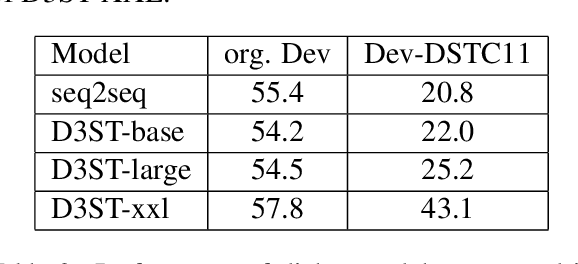
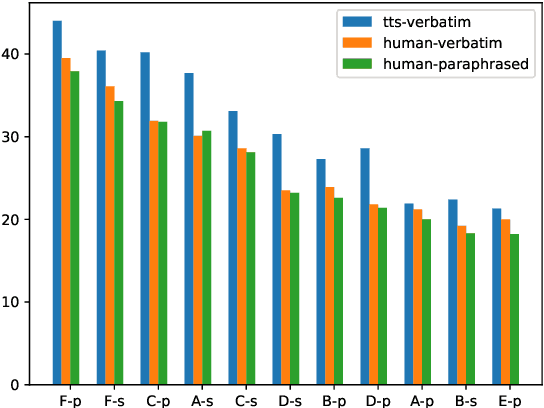
Most research on task oriented dialog modeling is based on written text input. However, users interact with practical dialog systems often using speech as input. Typically, systems convert speech into text using an Automatic Speech Recognition (ASR) system, introducing errors. Furthermore, these systems do not address the differences in written and spoken language. The research on this topic is stymied by the lack of a public corpus. Motivated by these considerations, our goal in hosting the speech-aware dialog state tracking challenge was to create a public corpus or task which can be used to investigate the performance gap between the written and spoken forms of input, develop models that could alleviate this gap, and establish whether Text-to-Speech-based (TTS) systems is a reasonable surrogate to the more-labor intensive human data collection. We created three spoken versions of the popular written-domain MultiWoz task -- (a) TTS-Verbatim: written user inputs were converted into speech waveforms using a TTS system, (b) Human-Verbatim: humans spoke the user inputs verbatim, and (c) Human-paraphrased: humans paraphrased the user inputs. Additionally, we provided different forms of ASR output to encourage wider participation from teams that may not have access to state-of-the-art ASR systems. These included ASR transcripts, word time stamps, and latent representations of the audio (audio encoder outputs). In this paper, we describe the corpus, report results from participating teams, provide preliminary analyses of their results, and summarize the current state-of-the-art in this domain.
LiteLSTM Architecture Based on Weights Sharing for Recurrent Neural Networks
Jan 12, 2023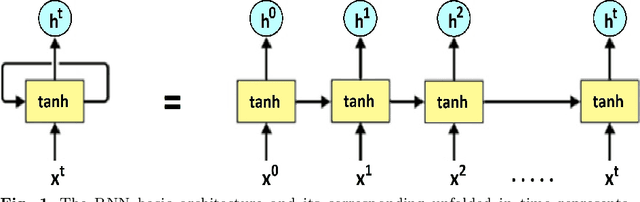

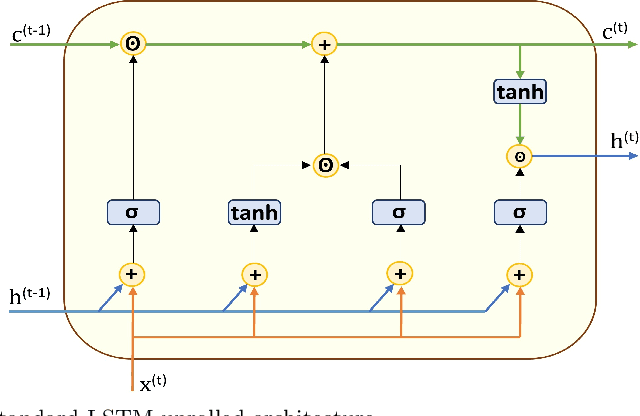
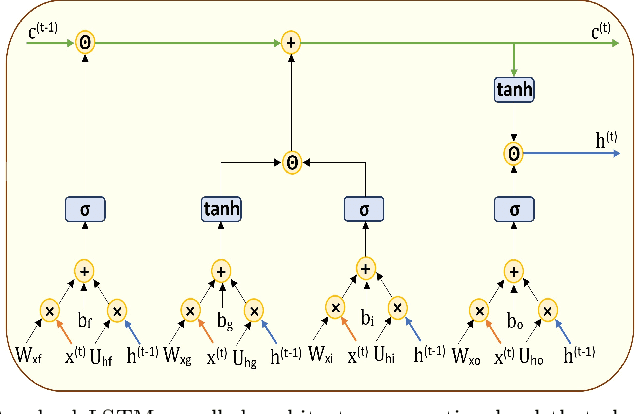
Long short-term memory (LSTM) is one of the robust recurrent neural network architectures for learning sequential data. However, it requires considerable computational power to learn and implement both software and hardware aspects. This paper proposed a novel LiteLSTM architecture based on reducing the LSTM computation components via the weights sharing concept to reduce the overall architecture computation cost and maintain the architecture performance. The proposed LiteLSTM can be significant for processing large data where time-consuming is crucial while hardware resources are limited, such as the security of IoT devices and medical data processing. The proposed model was evaluated and tested empirically on three different datasets from the computer vision, cybersecurity, speech emotion recognition domains. The proposed LiteLSTM has comparable accuracy to the other state-of-the-art recurrent architecture while using a smaller computation budget.
Speaker-Targeted Audio-Visual Models for Speech Recognition in Cocktail-Party Environments
Jun 13, 2019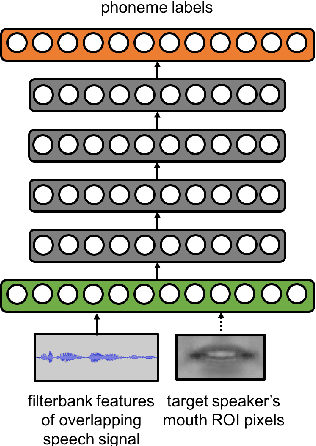
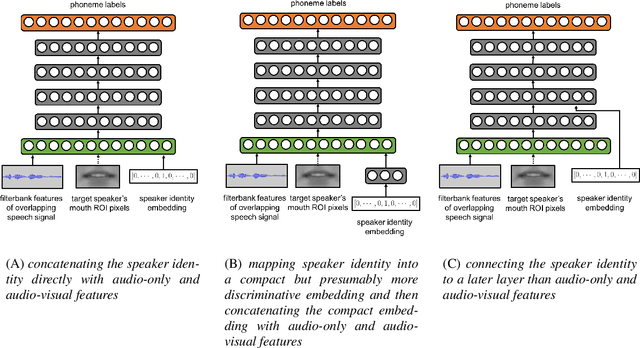

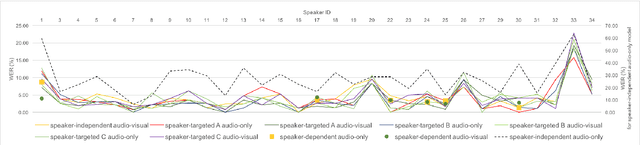
Speech recognition in cocktail-party environments remains a significant challenge for state-of-the-art speech recognition systems, as it is extremely difficult to extract an acoustic signal of an individual speaker from a background of overlapping speech with similar frequency and temporal characteristics. We propose the use of speaker-targeted acoustic and audio-visual models for this task. We complement the acoustic features in a hybrid DNN-HMM model with information of the target speaker's identity as well as visual features from the mouth region of the target speaker. Experimentation was performed using simulated cocktail-party data generated from the GRID audio-visual corpus by overlapping two speakers's speech on a single acoustic channel. Our audio-only baseline achieved a WER of 26.3%. The audio-visual model improved the WER to 4.4%. Introducing speaker identity information had an even more pronounced effect, improving the WER to 3.6%. Combining both approaches, however, did not significantly improve performance further. Our work demonstrates that speaker-targeted models can significantly improve the speech recognition in cocktail party environments.
End-to-End Label Uncertainty Modeling in Speech Emotion Recognition using Bayesian Neural Networks and Label Distribution Learning
Sep 30, 2022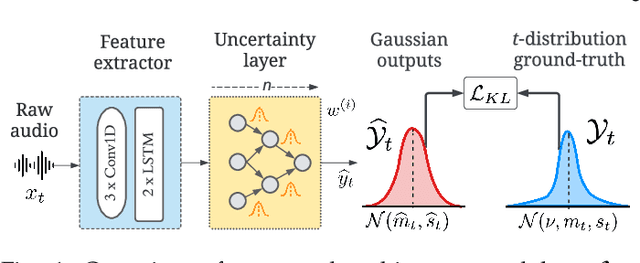
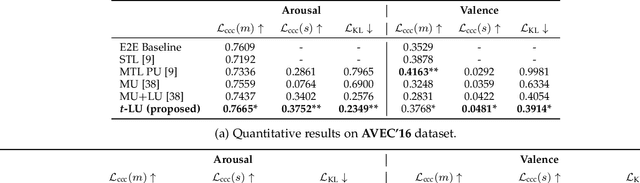
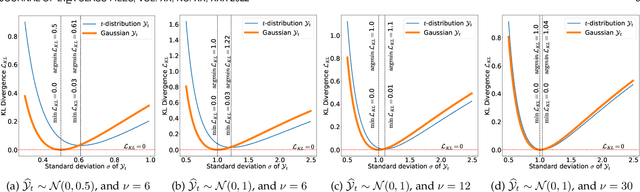
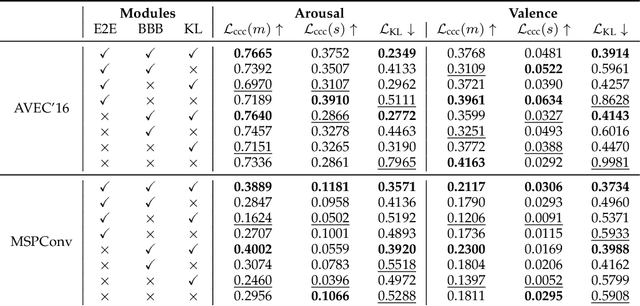
To train machine learning algorithms to predict emotional expressions in terms of arousal and valence, annotated datasets are needed. However, as different people perceive others' emotional expressions differently, their annotations are per se subjective. For this, annotations are typically collected from multiple annotators and averaged to obtain ground-truth labels. However, when exclusively trained on this averaged ground-truth, the trained network is agnostic to the inherent subjectivity in emotional expressions. In this work, we therefore propose an end-to-end Bayesian neural network capable of being trained on a distribution of labels to also capture the subjectivity-based label uncertainty. Instead of a Gaussian, we model the label distribution using Student's t-distribution, which also accounts for the number of annotations. We derive the corresponding Kullback-Leibler divergence loss and use it to train an estimator for the distribution of labels, from which the mean and uncertainty can be inferred. We validate the proposed method using two in-the-wild datasets. We show that the proposed t-distribution based approach achieves state-of-the-art uncertainty modeling results in speech emotion recognition, and also consistent results in cross-corpora evaluations. Furthermore, analyses reveal that the advantage of a t-distribution over a Gaussian grows with increasing inter-annotator correlation and a decreasing number of annotators.