 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Exploiting Beam Search Confidence for Energy-Efficient Speech Recognition
Jan 22, 2021
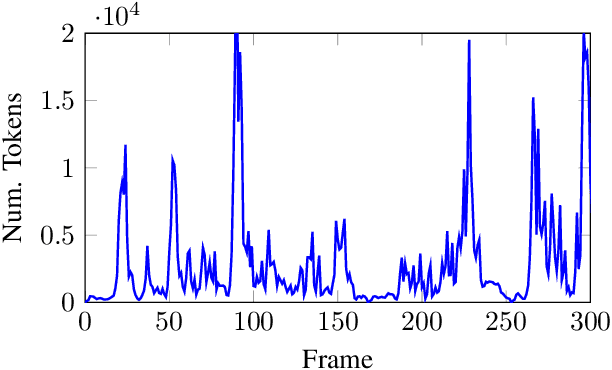
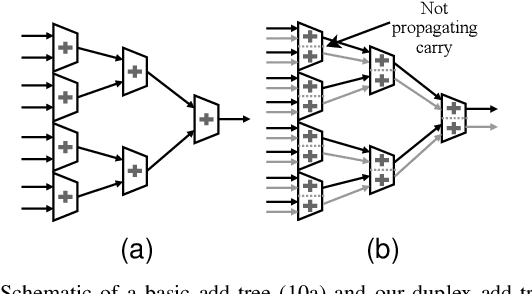
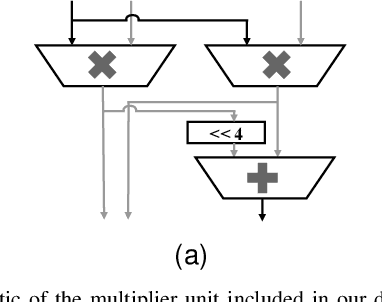
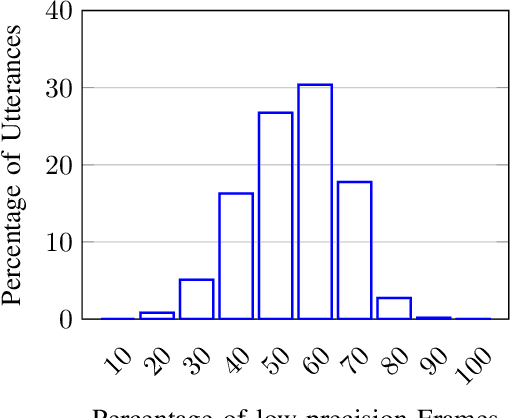
With computers getting more and more powerful and integrated in our daily lives, the focus is increasingly shifting towards more human-friendly interfaces, making Automatic Speech Recognition (ASR) a central player as the ideal means of interaction with machines. Consequently, interest in speech technology has grown in the last few years, with more systems being proposed and higher accuracy levels being achieved, even surpassing \textit{Human Accuracy}. While ASR systems become increasingly powerful, the computational complexity also increases, and the hardware support have to keep pace. In this paper, we propose a technique to improve the energy-efficiency and performance of ASR systems, focusing on low-power hardware for edge devices. We focus on optimizing the DNN-based Acoustic Model evaluation, as we have observed it to be the main bottleneck in state-of-the-art ASR systems, by leveraging run-time information from the Beam Search. By doing so, we reduce energy and execution time of the acoustic model evaluation by 25.6% and 25.9%, respectively, with negligible accuracy loss.
A Graph Isomorphism Network with Weighted Multiple Aggregators for Speech Emotion Recognition
Jul 03, 2022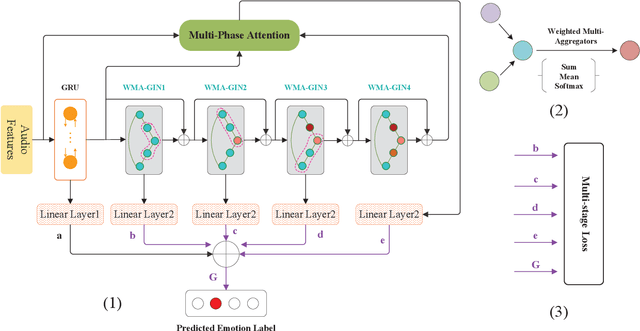

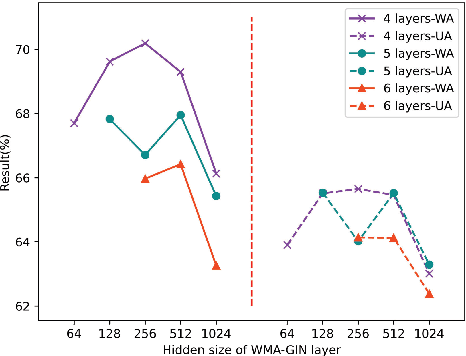
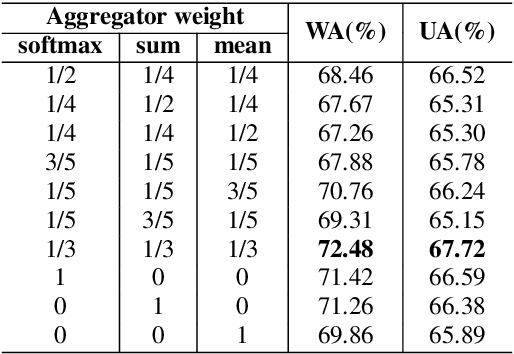
Speech emotion recognition (SER) is an essential part of human-computer interaction. In this paper, we propose an SER network based on a Graph Isomorphism Network with Weighted Multiple Aggregators (WMA-GIN), which can effectively handle the problem of information confusion when neighbour nodes' features are aggregated together in GIN structure. Moreover, a Full-Adjacent (FA) layer is adopted for alleviating the over-squashing problem, which is existed in all Graph Neural Network (GNN) structures, including GIN. Furthermore, a multi-phase attention mechanism and multi-loss training strategy are employed to avoid missing the useful emotional information in the stacked WMA-GIN layers. We evaluated the performance of our proposed WMA-GIN on the popular IEMOCAP dataset. The experimental results show that WMA-GIN outperforms other GNN-based methods and is comparable to some advanced non-graph-based methods by achieving 72.48% of weighted accuracy (WA) and 67.72% of unweighted accuracy (UA).
Improving Transformer-based Conversational ASR by Inter-Sentential Attention Mechanism
Jul 02, 2022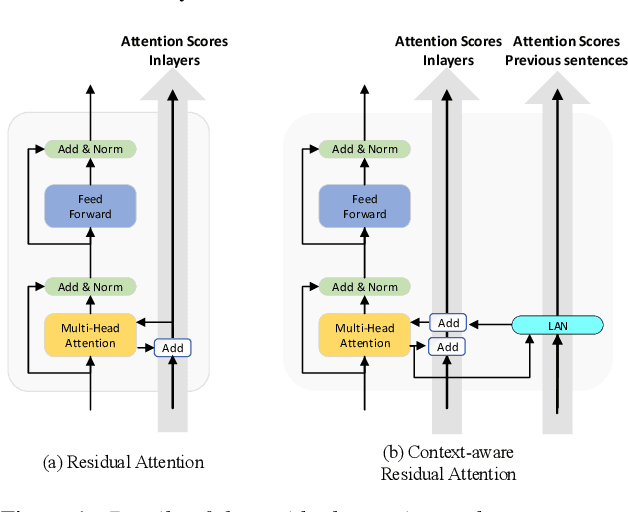
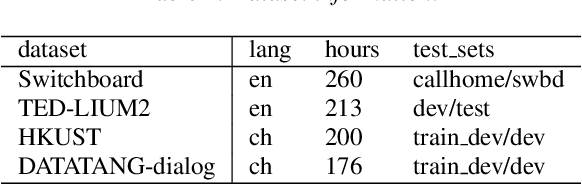
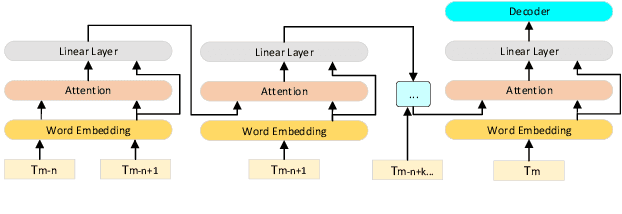

Transformer-based models have demonstrated their effectiveness in automatic speech recognition (ASR) tasks and even shown superior performance over the conventional hybrid framework. The main idea of Transformers is to capture the long-range global context within an utterance by self-attention layers. However, for scenarios like conversational speech, such utterance-level modeling will neglect contextual dependencies that span across utterances. In this paper, we propose to explicitly model the inter-sentential information in a Transformer based end-to-end architecture for conversational speech recognition. Specifically, for the encoder network, we capture the contexts of previous speech and incorporate such historic information into current input by a context-aware residual attention mechanism. For the decoder, the prediction of current utterance is also conditioned on the historic linguistic information through a conditional decoder framework. We show the effectiveness of our proposed method on several open-source dialogue corpora and the proposed method consistently improved the performance from the utterance-level Transformer-based ASR models.
TRScore: A Novel GPT-based Readability Scorer for ASR Segmentation and Punctuation model evaluation and selection
Oct 27, 2022
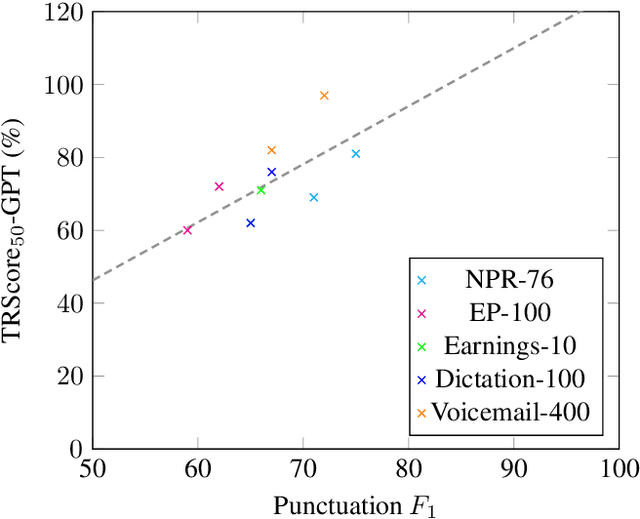
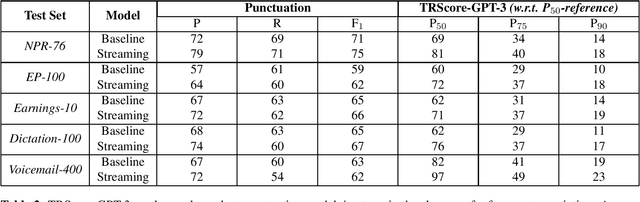
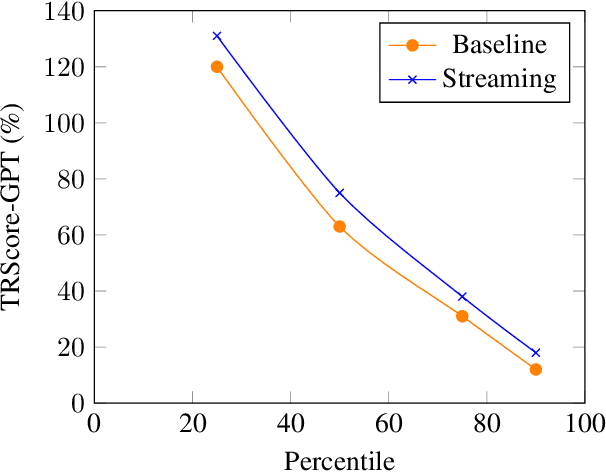
Punctuation and Segmentation are key to readability in Automatic Speech Recognition (ASR), often evaluated using F1 scores that require high-quality human transcripts and do not reflect readability well. Human evaluation is expensive, time-consuming, and suffers from large inter-observer variability, especially in conversational speech devoid of strict grammatical structures. Large pre-trained models capture a notion of grammatical structure. We present TRScore, a novel readability measure using the GPT model to evaluate different segmentation and punctuation systems. We validate our approach with human experts. Additionally, our approach enables quantitative assessment of text post-processing techniques such as capitalization, inverse text normalization (ITN), and disfluency on overall readability, which traditional word error rate (WER) and slot error rate (SER) metrics fail to capture. TRScore is strongly correlated to traditional F1 and human readability scores, with Pearson's correlation coefficients of 0.67 and 0.98, respectively. It also eliminates the need for human transcriptions for model selection.
On Out-of-Distribution Detection for Audio with Deep Nearest Neighbors
Oct 27, 2022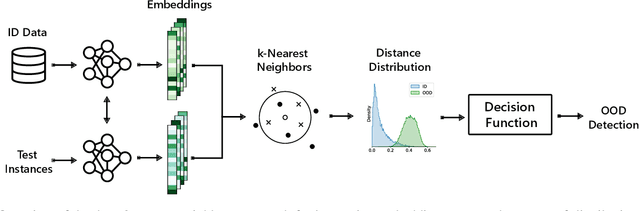
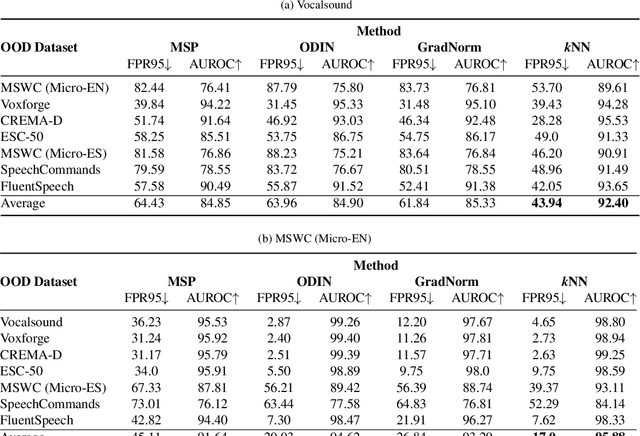
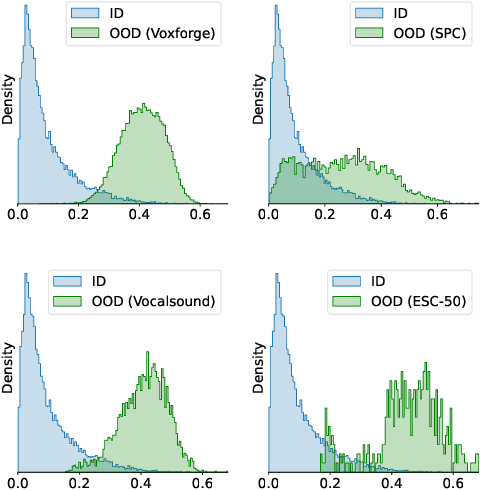
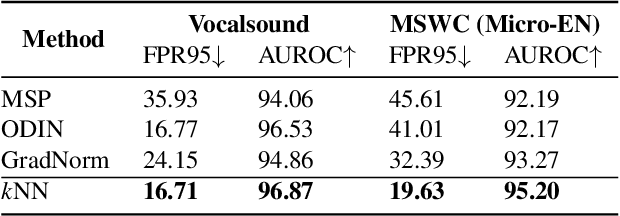
Out-of-distribution (OOD) detection is concerned with identifying data points that do not belong to the same distribution as the model's training data. For the safe deployment of predictive models in a real-world environment, it is critical to avoid making confident predictions on OOD inputs as it can lead to potentially dangerous consequences. However, OOD detection largely remains an under-explored area in the audio (and speech) domain. This is despite the fact that audio is a central modality for many tasks, such as speaker diarization, automatic speech recognition, and sound event detection. To address this, we propose to leverage feature-space of the model with deep k-nearest neighbors to detect OOD samples. We show that this simple and flexible method effectively detects OOD inputs across a broad category of audio (and speech) datasets. Specifically, it improves the false positive rate (FPR@TPR95) by 17% and the AUROC score by 7% than other prior techniques.
Streaming Voice Conversion Via Intermediate Bottleneck Features And Non-streaming Teacher Guidance
Oct 27, 2022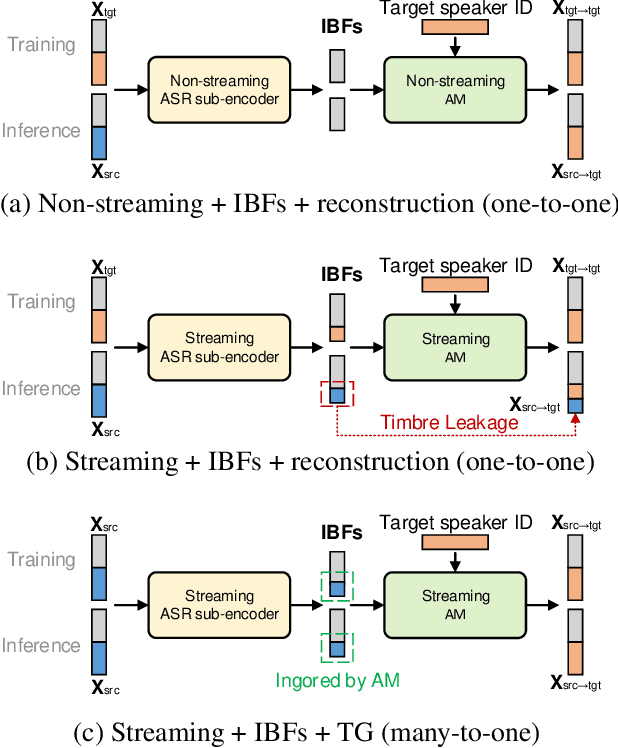
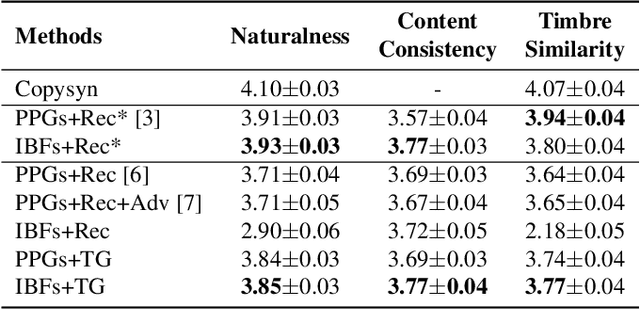
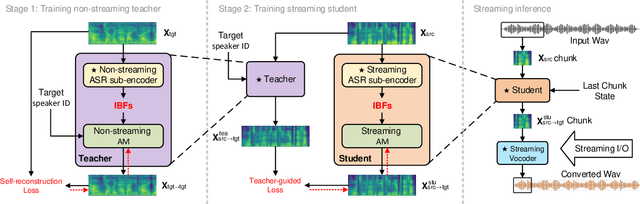
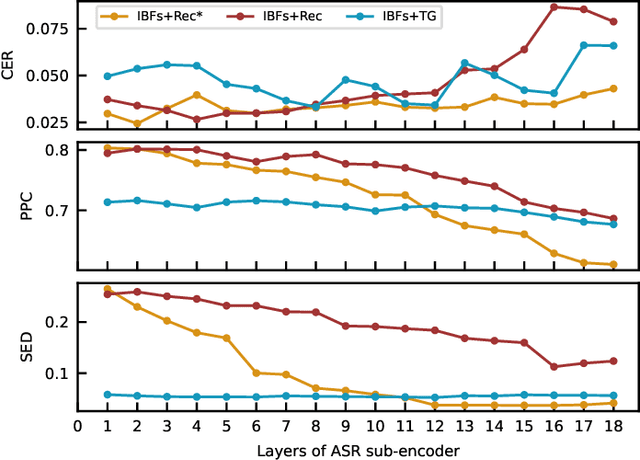
Streaming voice conversion (VC) is the task of converting the voice of one person to another in real-time. Previous streaming VC methods use phonetic posteriorgrams (PPGs) extracted from automatic speech recognition (ASR) systems to represent speaker-independent information. However, PPGs lack the prosody and vocalization information of the source speaker, and streaming PPGs contain undesired leaked timbre of the source speaker. In this paper, we propose to use intermediate bottleneck features (IBFs) to replace PPGs. VC systems trained with IBFs retain more prosody and vocalization information of the source speaker. Furthermore, we propose a non-streaming teacher guidance (TG) framework that addresses the timbre leakage problem. Experiments show that our proposed IBFs and the TG framework achieve a state-of-the-art streaming VC naturalness of 3.85, a content consistency of 3.77, and a timbre similarity of 3.77 under a future receptive field of 160 ms which significantly outperform previous streaming VC systems.
Automatic Severity Assessment of Dysarthric speech by using Self-supervised Model with Multi-task Learning
Oct 27, 2022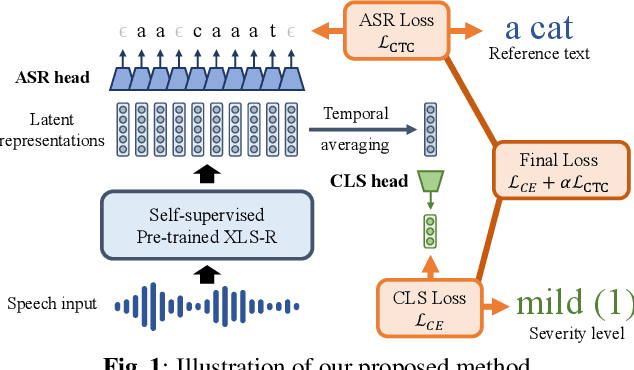

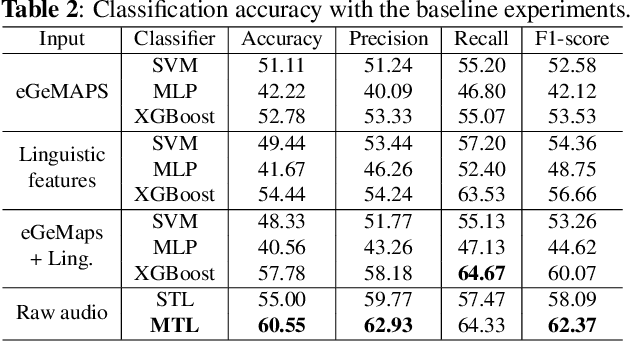
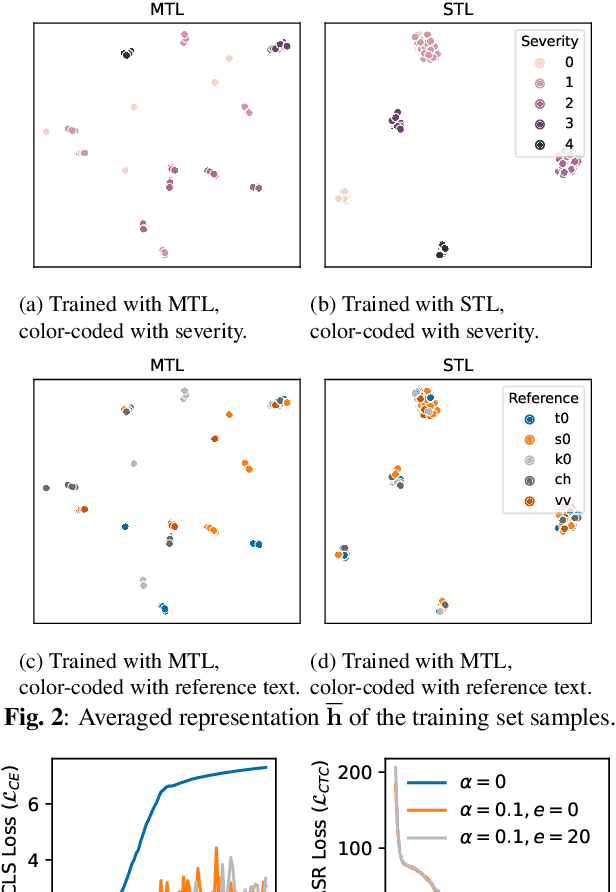
Automatic assessment of dysarthric speech is essential for sustained treatments and rehabilitation. However, obtaining atypical speech is challenging, often leading to data scarcity issues. To tackle the problem, we propose a novel automatic severity assessment method for dysarthric speech, using the self-supervised model in conjunction with multi-task learning. Wav2vec 2.0 XLS-R is jointly trained for two different tasks: severity level classification and an auxilary automatic speech recognition (ASR). For the baseline experiments, we employ hand-crafted features such as eGeMaps and linguistic features, and SVM, MLP, and XGBoost classifiers. Explored on the Korean dysarthric speech QoLT database, our model outperforms the traditional baseline methods, with a relative percentage increase of 4.79% for classification accuracy. In addition, the proposed model surpasses the model trained without ASR head, achieving 10.09% relative percentage improvements. Furthermore, we present how multi-task learning affects the severity classification performance by analyzing the latent representations and regularization effect.
Smart Speech Segmentation using Acousto-Linguistic Features with look-ahead
Oct 27, 2022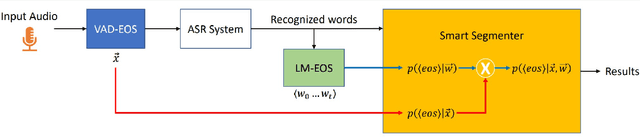
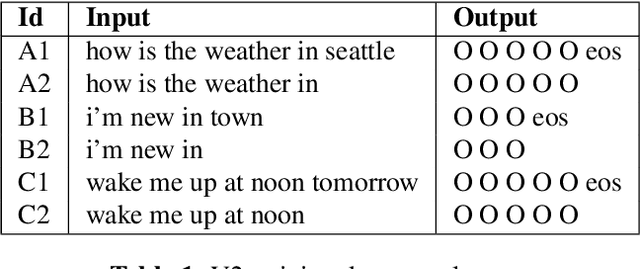

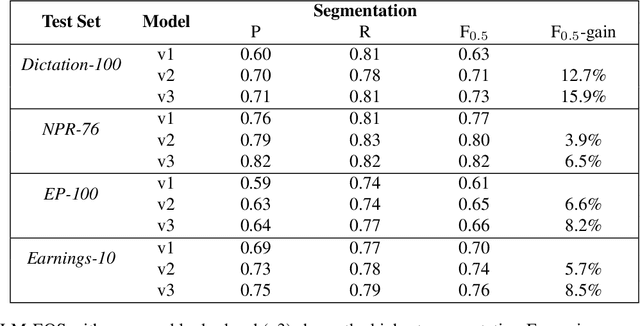
Segmentation for continuous Automatic Speech Recognition (ASR) has traditionally used silence timeouts or voice activity detectors (VADs), which are both limited to acoustic features. This segmentation is often overly aggressive, given that people naturally pause to think as they speak. Consequently, segmentation happens mid-sentence, hindering both punctuation and downstream tasks like machine translation for which high-quality segmentation is critical. Model-based segmentation methods that leverage acoustic features are powerful, but without an understanding of the language itself, these approaches are limited. We present a hybrid approach that leverages both acoustic and language information to improve segmentation. Furthermore, we show that including one word as a look-ahead boosts segmentation quality. On average, our models improve segmentation-F0.5 score by 9.8% over baseline. We show that this approach works for multiple languages. For the downstream task of machine translation, it improves the translation BLEU score by an average of 1.05 points.
Align-Refine: Non-Autoregressive Speech Recognition via Iterative Realignment
Oct 24, 2020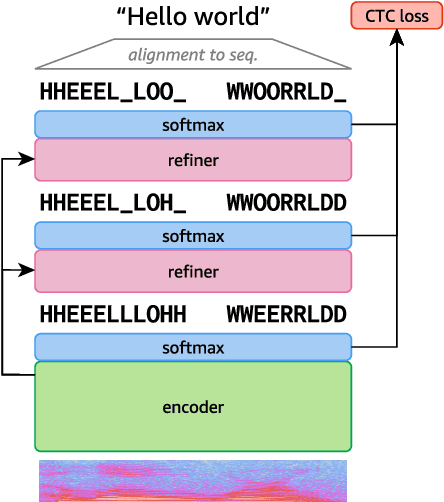
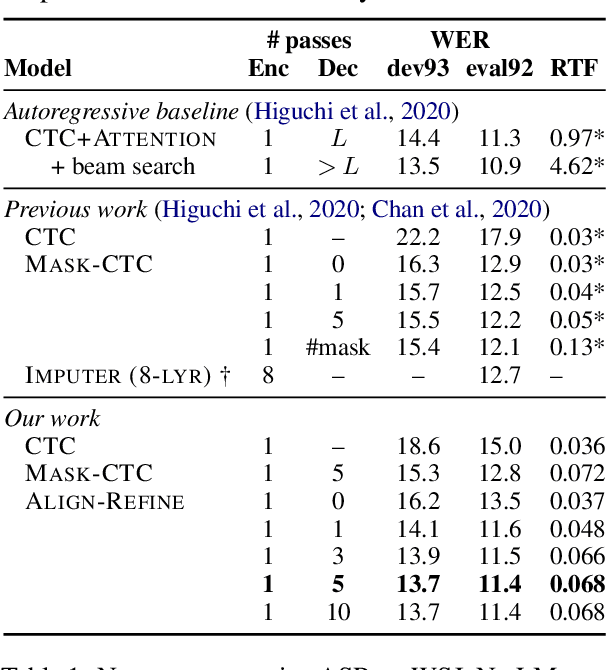
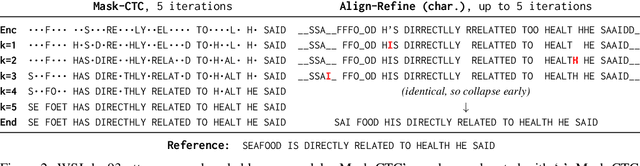
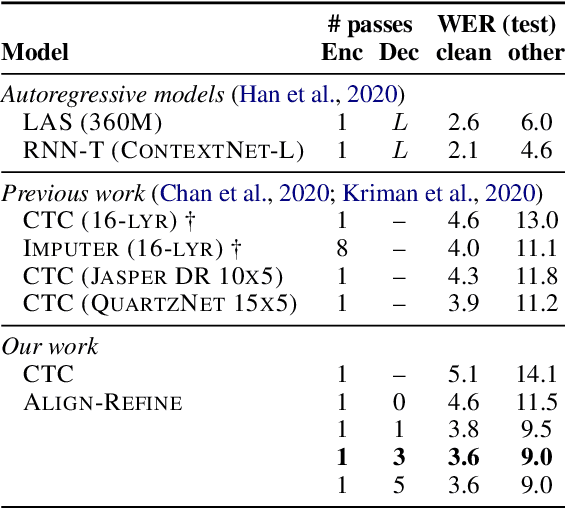
Non-autoregressive models greatly improve decoding speed over typical sequence-to-sequence models, but suffer from degraded performance. Infilling and iterative refinement models make up some of this gap by editing the outputs of a non-autoregressive model, but are constrained in the edits that they can make. We propose iterative realignment, where refinements occur over latent alignments rather than output sequence space. We demonstrate this in speech recognition with Align-Refine, an end-to-end Transformer-based model which refines connectionist temporal classification (CTC) alignments to allow length-changing insertions and deletions. Align-Refine outperforms Imputer and Mask-CTC, matching an autoregressive baseline on WSJ at 1/14th the real-time factor and attaining a LibriSpeech test-other WER of 9.0% without an LM. Our model is strong even in one iteration with a shallower decoder.
On using the UA-Speech and TORGO databases to validate automatic dysarthric speech classification approaches
Nov 16, 2022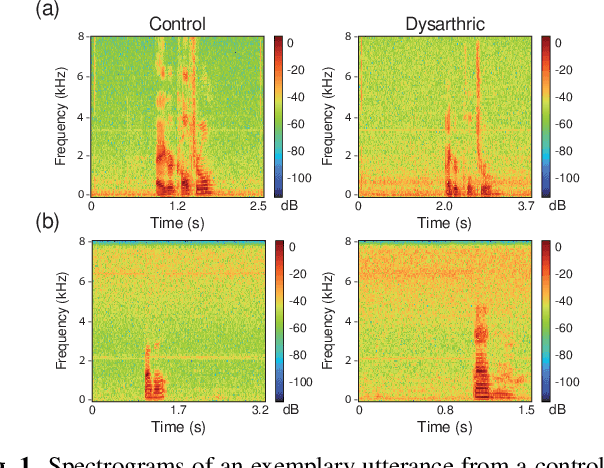


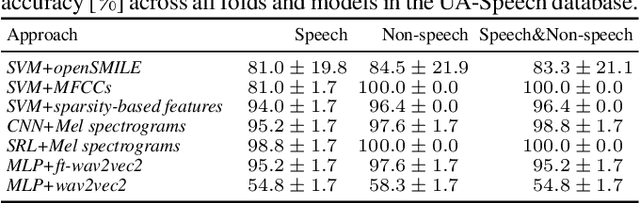
Although the UA-Speech and TORGO databases of control and dysarthric speech are invaluable resources made available to the research community with the objective of developing robust automatic speech recognition systems, they have also been used to validate a considerable number of automatic dysarthric speech classification approaches. Such approaches typically rely on the underlying assumption that recordings from control and dysarthric speakers are collected in the same noiseless environment using the same recording setup. In this paper, we show that this assumption is violated for the UA-Speech and TORGO databases. Using voice activity detection to extract speech and non-speech segments, we show that the majority of state-of-the-art dysarthria classification approaches achieve the same or a considerably better performance when using the non-speech segments of these databases than when using the speech segments. These results demonstrate that such approaches trained and validated on the UA-Speech and TORGO databases are potentially learning characteristics of the recording environment or setup rather than dysarthric speech characteristics. We hope that these results raise awareness in the research community about the importance of the quality of recordings when developing and evaluating automatic dysarthria classification approaches.