 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Streaming Voice Conversion Via Intermediate Bottleneck Features And Non-streaming Teacher Guidance
Oct 27, 2022
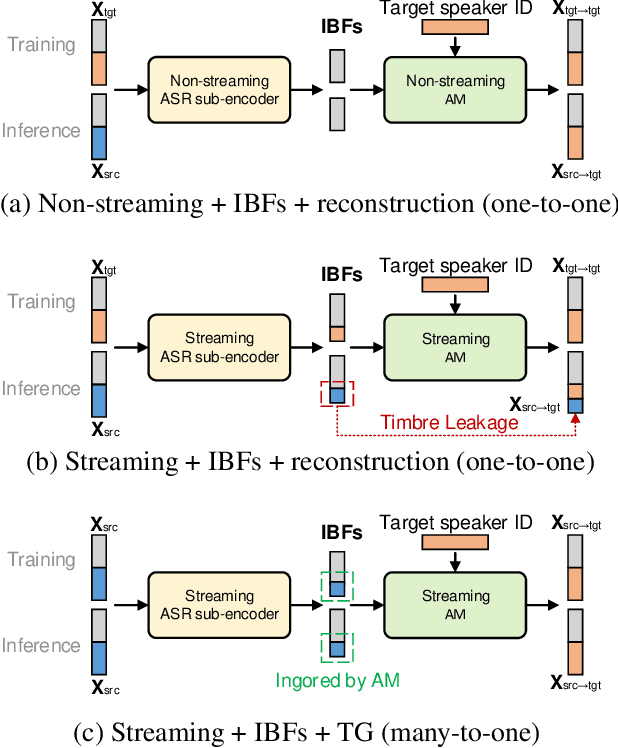
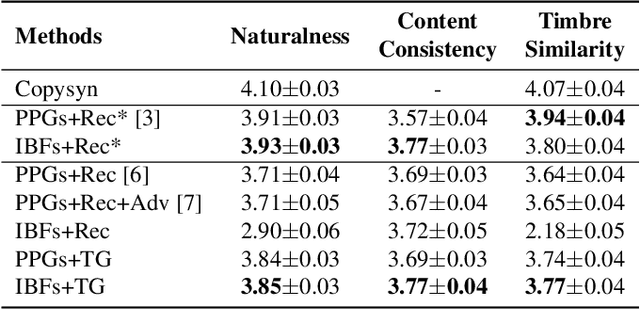
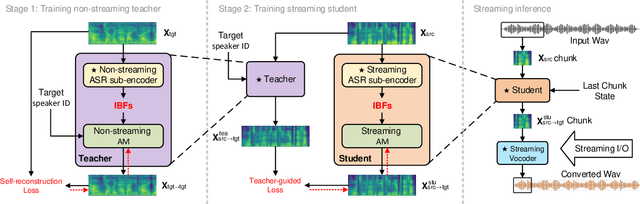
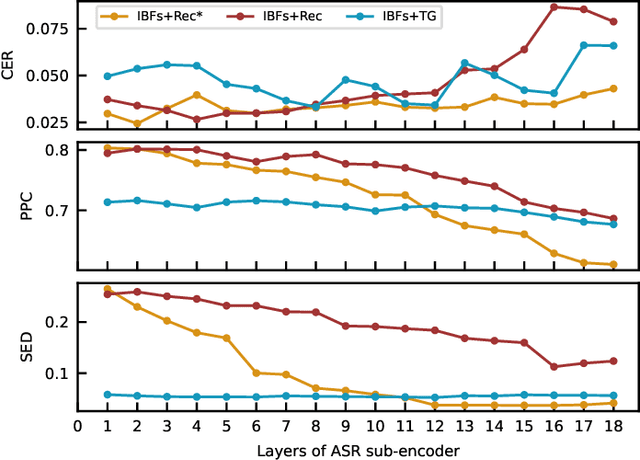
Streaming voice conversion (VC) is the task of converting the voice of one person to another in real-time. Previous streaming VC methods use phonetic posteriorgrams (PPGs) extracted from automatic speech recognition (ASR) systems to represent speaker-independent information. However, PPGs lack the prosody and vocalization information of the source speaker, and streaming PPGs contain undesired leaked timbre of the source speaker. In this paper, we propose to use intermediate bottleneck features (IBFs) to replace PPGs. VC systems trained with IBFs retain more prosody and vocalization information of the source speaker. Furthermore, we propose a non-streaming teacher guidance (TG) framework that addresses the timbre leakage problem. Experiments show that our proposed IBFs and the TG framework achieve a state-of-the-art streaming VC naturalness of 3.85, a content consistency of 3.77, and a timbre similarity of 3.77 under a future receptive field of 160 ms which significantly outperform previous streaming VC systems.
On using the UA-Speech and TORGO databases to validate automatic dysarthric speech classification approaches
Nov 16, 2022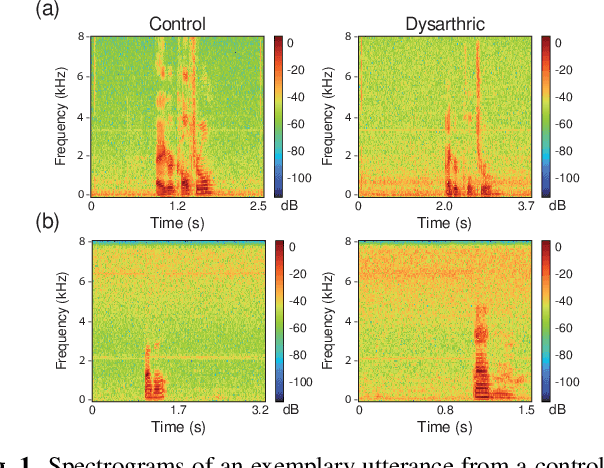


Although the UA-Speech and TORGO databases of control and dysarthric speech are invaluable resources made available to the research community with the objective of developing robust automatic speech recognition systems, they have also been used to validate a considerable number of automatic dysarthric speech classification approaches. Such approaches typically rely on the underlying assumption that recordings from control and dysarthric speakers are collected in the same noiseless environment using the same recording setup. In this paper, we show that this assumption is violated for the UA-Speech and TORGO databases. Using voice activity detection to extract speech and non-speech segments, we show that the majority of state-of-the-art dysarthria classification approaches achieve the same or a considerably better performance when using the non-speech segments of these databases than when using the speech segments. These results demonstrate that such approaches trained and validated on the UA-Speech and TORGO databases are potentially learning characteristics of the recording environment or setup rather than dysarthric speech characteristics. We hope that these results raise awareness in the research community about the importance of the quality of recordings when developing and evaluating automatic dysarthria classification approaches.
A Comparative Study on Neural Architectures and Training Methods for Japanese Speech Recognition
Jun 09, 2021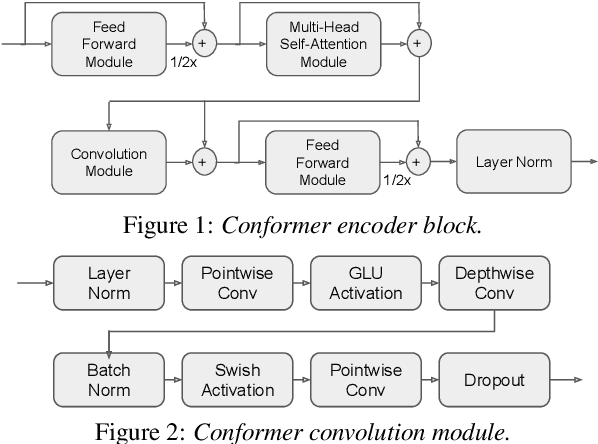
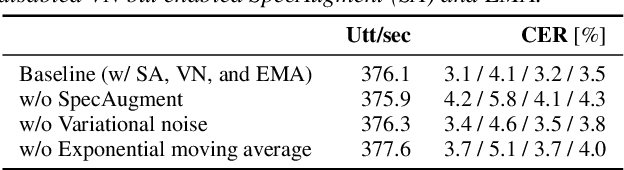
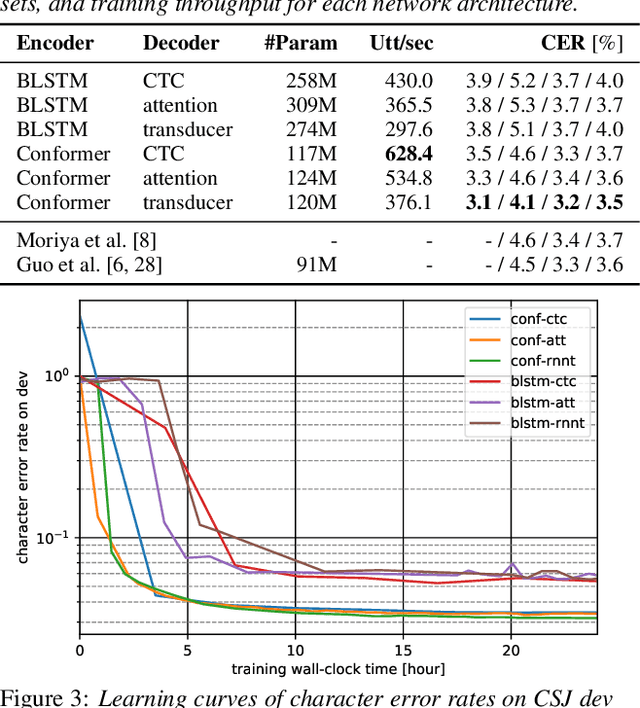
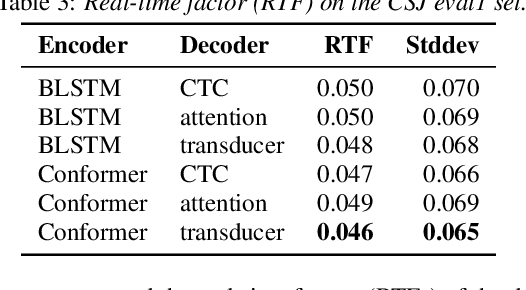
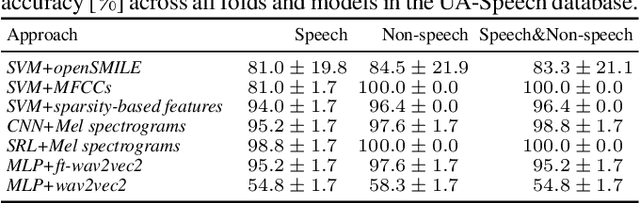
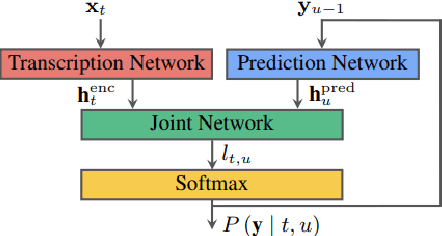
End-to-end (E2E) modeling is advantageous for automatic speech recognition (ASR) especially for Japanese since word-based tokenization of Japanese is not trivial, and E2E modeling is able to model character sequences directly. This paper focuses on the latest E2E modeling techniques, and investigates their performances on character-based Japanese ASR by conducting comparative experiments. The results are analyzed and discussed in order to understand the relative advantages of long short-term memory (LSTM), and Conformer models in combination with connectionist temporal classification, transducer, and attention-based loss functions. Furthermore, the paper investigates on effectivity of the recent training techniques such as data augmentation (SpecAugment), variational noise injection, and exponential moving average. The best configuration found in the paper achieved the state-of-the-art character error rates of 4.1%, 3.2%, and 3.5% for Corpus of Spontaneous Japanese (CSJ) eval1, eval2, and eval3 tasks, respectively. The system is also shown to be computationally efficient thanks to the efficiency of Conformer transducers.
Multimodal Speech Emotion Recognition using Cross Attention with Aligned Audio and Text
Jul 26, 2022
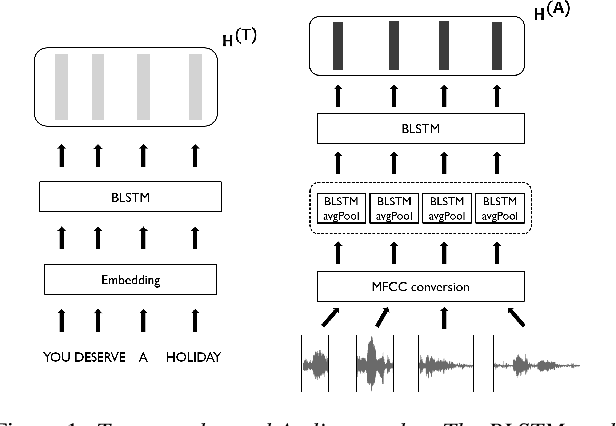
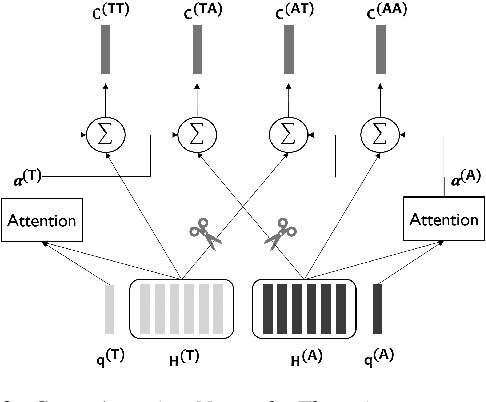
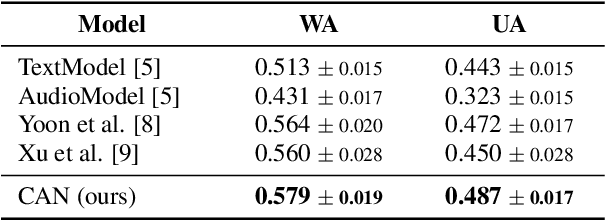
In this paper, we propose a novel speech emotion recognition model called Cross Attention Network (CAN) that uses aligned audio and text signals as inputs. It is inspired by the fact that humans recognize speech as a combination of simultaneously produced acoustic and textual signals. First, our method segments the audio and the underlying text signals into equal number of steps in an aligned way so that the same time steps of the sequential signals cover the same time span in the signals. Together with this technique, we apply the cross attention to aggregate the sequential information from the aligned signals. In the cross attention, each modality is aggregated independently by applying the global attention mechanism onto each modality. Then, the attention weights of each modality are applied directly to the other modality in a crossed way, so that the CAN gathers the audio and text information from the same time steps based on each modality. In the experiments conducted on the standard IEMOCAP dataset, our model outperforms the state-of-the-art systems by 2.66% and 3.18% relatively in terms of the weighted and unweighted accuracy.
* 5 pages, accepted by INTERSPEECH 2020
Speech Aware Dialog System Technology Challenge (DSTC11)
Dec 16, 2022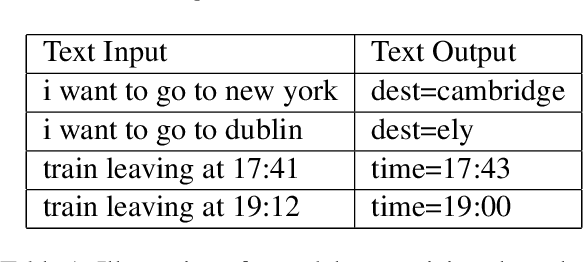
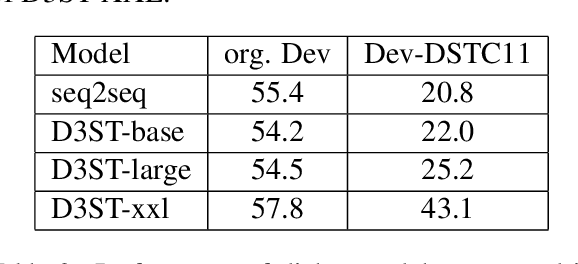
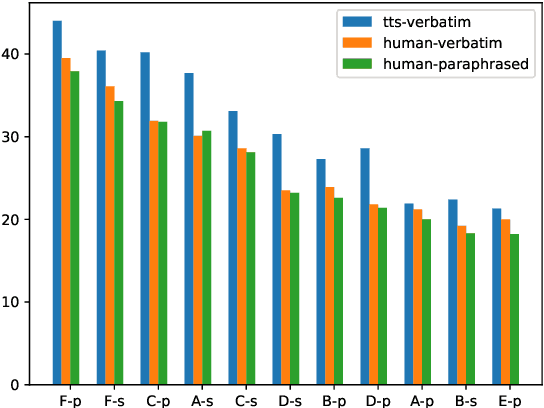
Most research on task oriented dialog modeling is based on written text input. However, users interact with practical dialog systems often using speech as input. Typically, systems convert speech into text using an Automatic Speech Recognition (ASR) system, introducing errors. Furthermore, these systems do not address the differences in written and spoken language. The research on this topic is stymied by the lack of a public corpus. Motivated by these considerations, our goal in hosting the speech-aware dialog state tracking challenge was to create a public corpus or task which can be used to investigate the performance gap between the written and spoken forms of input, develop models that could alleviate this gap, and establish whether Text-to-Speech-based (TTS) systems is a reasonable surrogate to the more-labor intensive human data collection. We created three spoken versions of the popular written-domain MultiWoz task -- (a) TTS-Verbatim: written user inputs were converted into speech waveforms using a TTS system, (b) Human-Verbatim: humans spoke the user inputs verbatim, and (c) Human-paraphrased: humans paraphrased the user inputs. Additionally, we provided different forms of ASR output to encourage wider participation from teams that may not have access to state-of-the-art ASR systems. These included ASR transcripts, word time stamps, and latent representations of the audio (audio encoder outputs). In this paper, we describe the corpus, report results from participating teams, provide preliminary analyses of their results, and summarize the current state-of-the-art in this domain.
Bridging Speech and Textual Pre-trained Models with Unsupervised ASR
Nov 06, 2022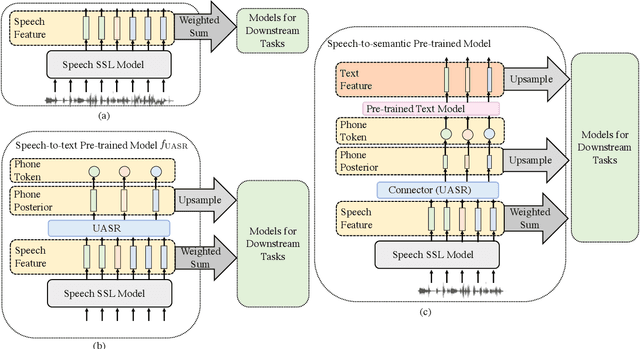
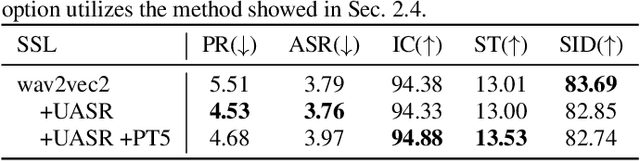
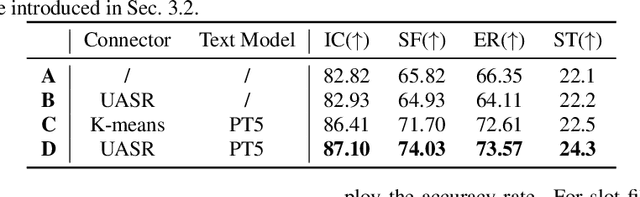
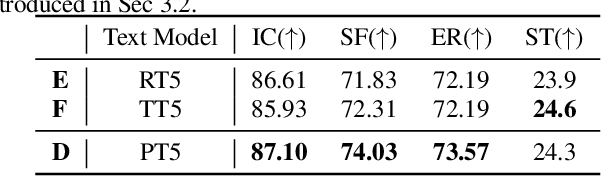
Spoken language understanding (SLU) is a task aiming to extract high-level semantics from spoken utterances. Previous works have investigated the use of speech self-supervised models and textual pre-trained models, which have shown reasonable improvements to various SLU tasks. However, because of the mismatched modalities between speech signals and text tokens, previous methods usually need complex designs of the frameworks. This work proposes a simple yet efficient unsupervised paradigm that connects speech and textual pre-trained models, resulting in an unsupervised speech-to-semantic pre-trained model for various tasks in SLU. To be specific, we propose to use unsupervised automatic speech recognition (ASR) as a connector that bridges different modalities used in speech and textual pre-trained models. Our experiments show that unsupervised ASR itself can improve the representations from speech self-supervised models. More importantly, it is shown as an efficient connector between speech and textual pre-trained models, improving the performances of five different SLU tasks. Notably, on spoken question answering, we reach the state-of-the-art result over the challenging NMSQA benchmark.
A Graph Isomorphism Network with Weighted Multiple Aggregators for Speech Emotion Recognition
Jul 03, 2022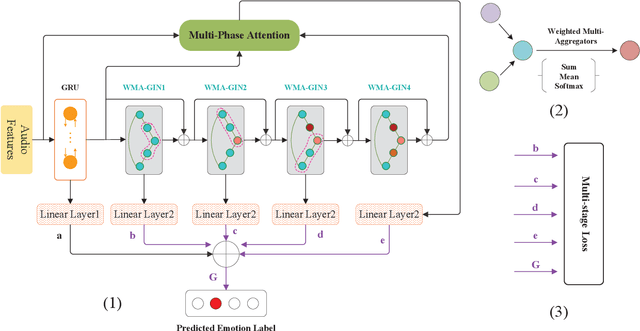

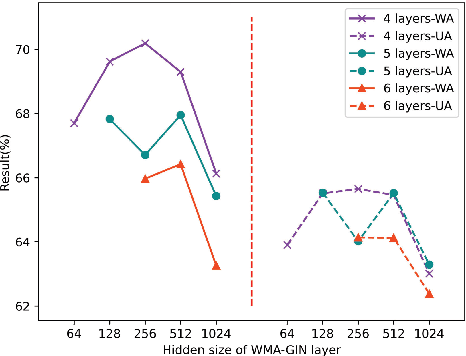
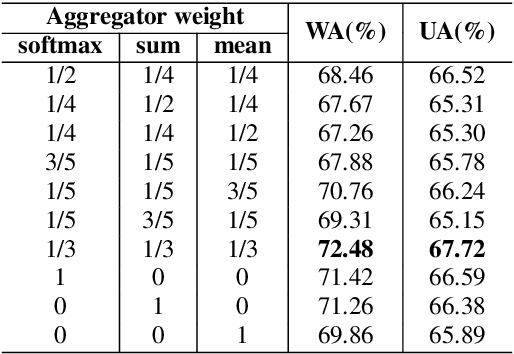
Speech emotion recognition (SER) is an essential part of human-computer interaction. In this paper, we propose an SER network based on a Graph Isomorphism Network with Weighted Multiple Aggregators (WMA-GIN), which can effectively handle the problem of information confusion when neighbour nodes' features are aggregated together in GIN structure. Moreover, a Full-Adjacent (FA) layer is adopted for alleviating the over-squashing problem, which is existed in all Graph Neural Network (GNN) structures, including GIN. Furthermore, a multi-phase attention mechanism and multi-loss training strategy are employed to avoid missing the useful emotional information in the stacked WMA-GIN layers. We evaluated the performance of our proposed WMA-GIN on the popular IEMOCAP dataset. The experimental results show that WMA-GIN outperforms other GNN-based methods and is comparable to some advanced non-graph-based methods by achieving 72.48% of weighted accuracy (WA) and 67.72% of unweighted accuracy (UA).
Iterative Pseudo-Labeling for Speech Recognition
May 19, 2020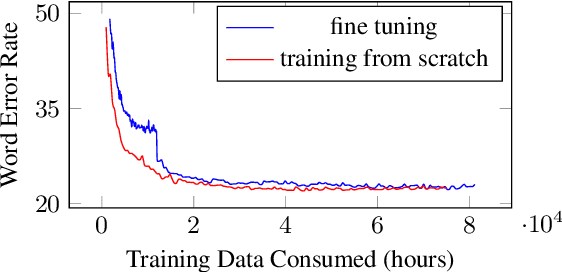
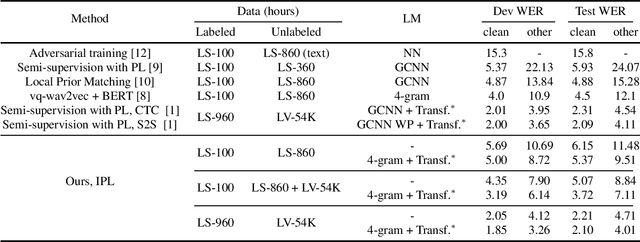
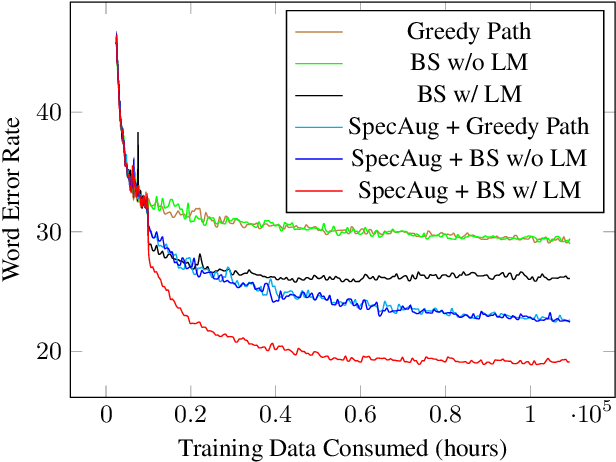

Pseudo-labeling has recently shown promise in end-to-end automatic speech recognition (ASR). We study Iterative Pseudo-Labeling (IPL), a semi-supervised algorithm which efficiently performs multiple iterations of pseudo-labeling on unlabeled data as the acoustic model evolves. In particular, IPL fine-tunes an existing model at each iteration using both labeled data and a subset of unlabeled data. We study the main components of IPL: decoding with a language model and data augmentation. We then demonstrate the effectiveness of IPL by achieving state-of-the-art word-error rate on the Librispeech test sets in both standard and low-resource setting. We also study the effect of language models trained on different corpora to show IPL can effectively utilize additional text. Finally, we release a new large in-domain text corpus which does not overlap with the Librispeech training transcriptions to foster research in low-resource, semi-supervised ASR
Efficient Use of Large Pre-Trained Models for Low Resource ASR
Oct 26, 2022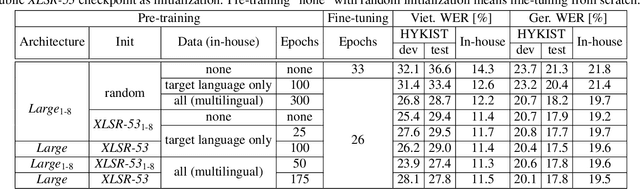
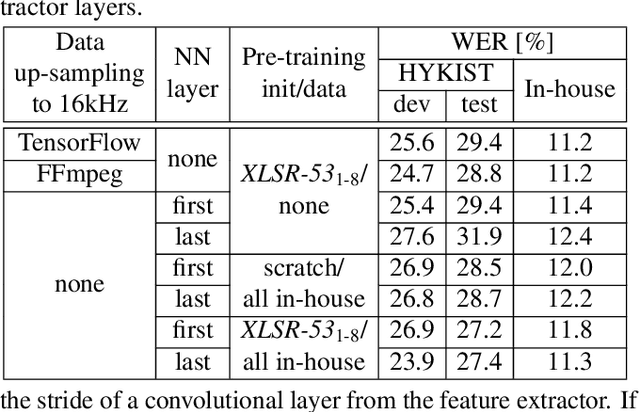
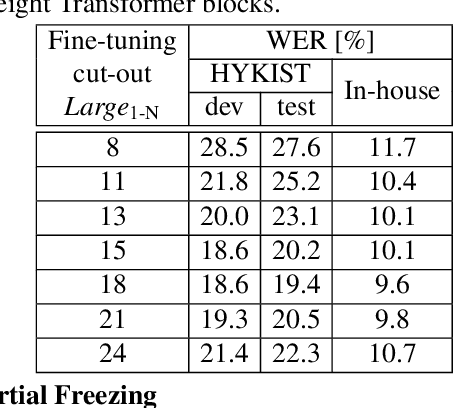
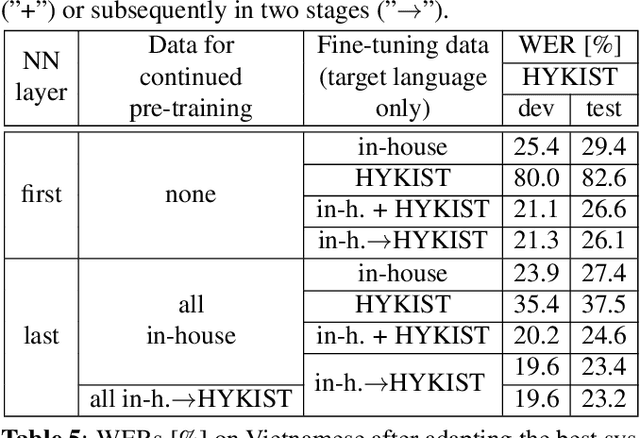
Automatic speech recognition (ASR) has been established as a well-performing technique for many scenarios where lots of labeled data is available. Additionally, unsupervised representation learning recently helped to tackle tasks with limited data. Following this, hardware limitations and applications give rise to the question how to efficiently take advantage of large pretrained models and reduce their complexity for downstream tasks. In this work, we study a challenging low resource conversational telephony speech corpus from the medical domain in Vietnamese and German. We show the benefits of using unsupervised techniques beyond simple fine-tuning of large pre-trained models, discuss how to adapt them to a practical telephony task including bandwidth transfer and investigate different data conditions for pre-training and fine-tuning. We outperform the project baselines by 22% relative using pretraining techniques. Further gains of 29% can be achieved by refinements of architecture and training and 6% by adding 0.8 h of in-domain adaptation data.
Improving Transformer-based Conversational ASR by Inter-Sentential Attention Mechanism
Jul 02, 2022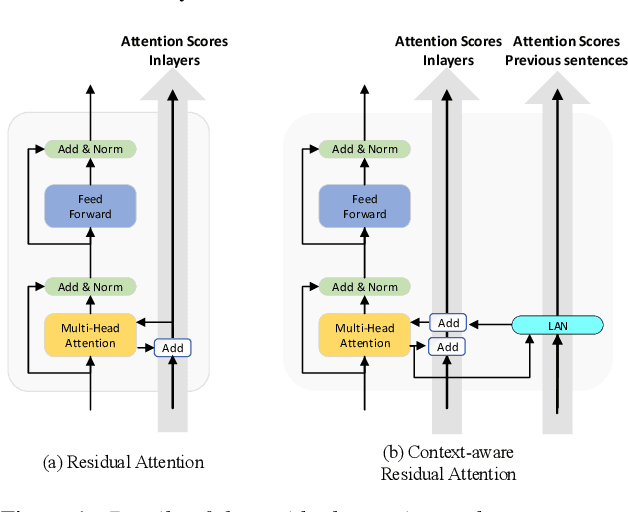
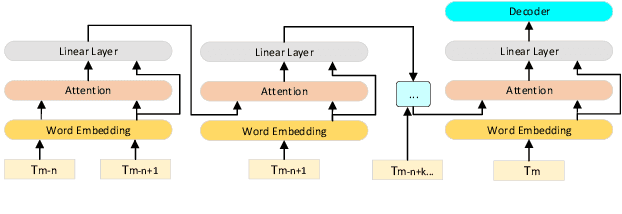

Transformer-based models have demonstrated their effectiveness in automatic speech recognition (ASR) tasks and even shown superior performance over the conventional hybrid framework. The main idea of Transformers is to capture the long-range global context within an utterance by self-attention layers. However, for scenarios like conversational speech, such utterance-level modeling will neglect contextual dependencies that span across utterances. In this paper, we propose to explicitly model the inter-sentential information in a Transformer based end-to-end architecture for conversational speech recognition. Specifically, for the encoder network, we capture the contexts of previous speech and incorporate such historic information into current input by a context-aware residual attention mechanism. For the decoder, the prediction of current utterance is also conditioned on the historic linguistic information through a conditional decoder framework. We show the effectiveness of our proposed method on several open-source dialogue corpora and the proposed method consistently improved the performance from the utterance-level Transformer-based ASR models.