 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
DuDe: Dual-Decoder Multilingual ASR for Indian Languages using Common Label Set
Oct 30, 2022
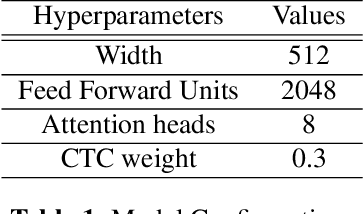

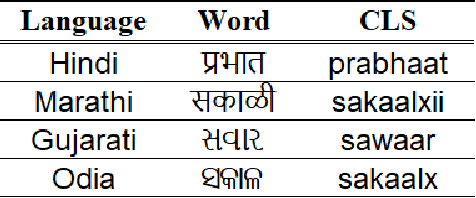
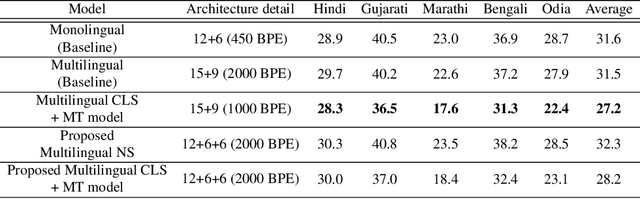
In a multilingual country like India, multilingual Automatic Speech Recognition (ASR) systems have much scope. Multilingual ASR systems exhibit many advantages like scalability, maintainability, and improved performance over the monolingual ASR systems. However, building multilingual systems for Indian languages is challenging since different languages use different scripts for writing. On the other hand, Indian languages share a lot of common sounds. Common Label Set (CLS) exploits this idea and maps graphemes of various languages with similar sounds to common labels. Since Indian languages are mostly phonetic, building a parser to convert from native script to CLS is easy. In this paper, we explore various approaches to build multilingual ASR models. We also propose a novel architecture called Encoder-Decoder-Decoder for building multilingual systems that use both CLS and native script labels. We also analyzed the effectiveness of CLS-based multilingual systems combined with machine transliteration.
Measuring Equality in Machine Learning Security Defenses
Mar 01, 2023
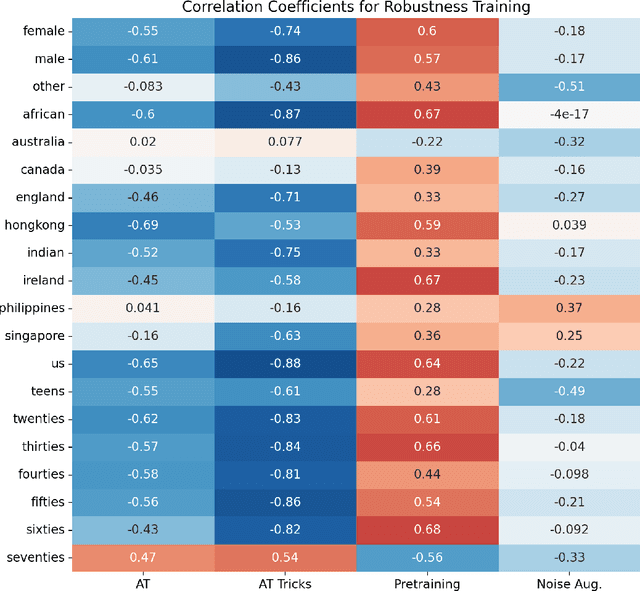
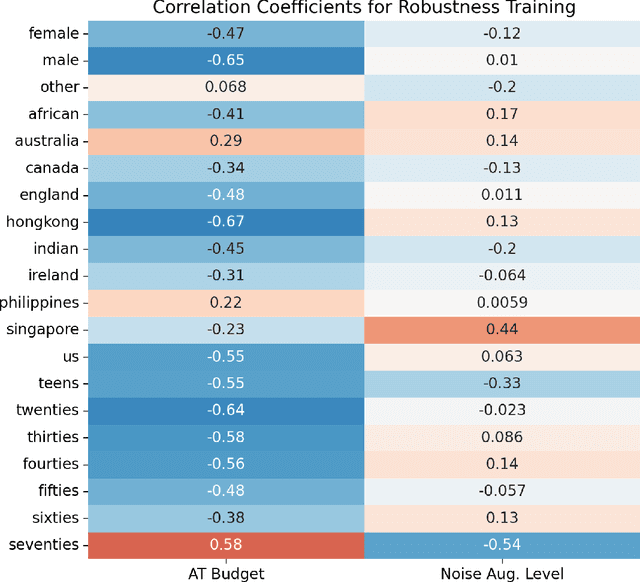
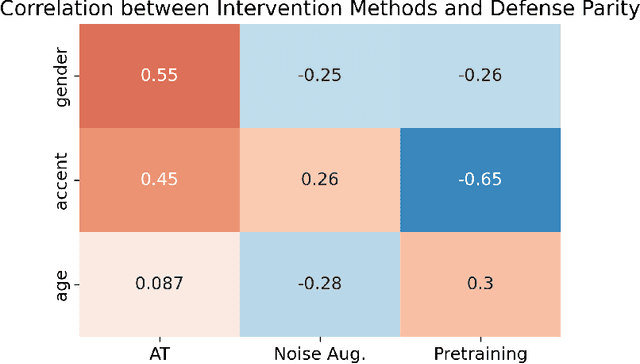
The machine learning security community has developed myriad defenses for evasion attacks over the past decade. An understudied question in that community is: for whom do these defenses defend? In this work, we consider some common approaches to defending learned systems and whether those approaches may offer unexpected performance inequities when used by different sub-populations. We outline simple parity metrics and a framework for analysis that can begin to answer this question through empirical results of the fairness implications of machine learning security methods. Many methods have been proposed that can cause direct harm, which we describe as biased vulnerability and biased rejection. Our framework and metric can be applied to robustly trained models, preprocessing-based methods, and rejection methods to capture behavior over security budgets. We identify a realistic dataset with a reasonable computational cost suitable for measuring the equality of defenses. Through a case study in speech command recognition, we show how such defenses do not offer equal protection for social subgroups and how to perform such analyses for robustness training, and we present a comparison of fairness between two rejection-based defenses: randomized smoothing and neural rejection. We offer further analysis of factors that correlate to equitable defenses to stimulate the future investigation of how to assist in building such defenses. To the best of our knowledge, this is the first work that examines the fairness disparity in the accuracy-robustness trade-off in speech data and addresses fairness evaluation for rejection-based defenses.
Synchronous Speech Recognition and Speech-to-Text Translation with Interactive Decoding
Dec 16, 2019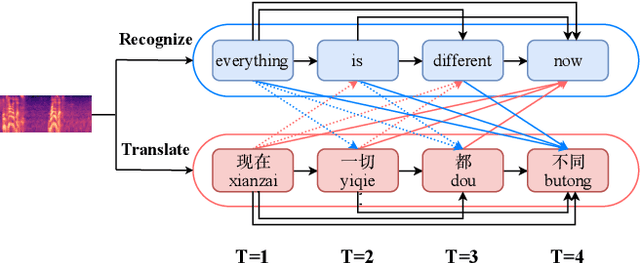
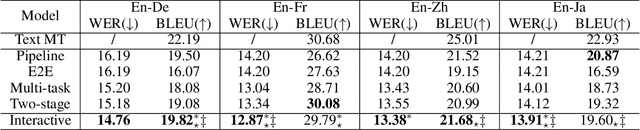
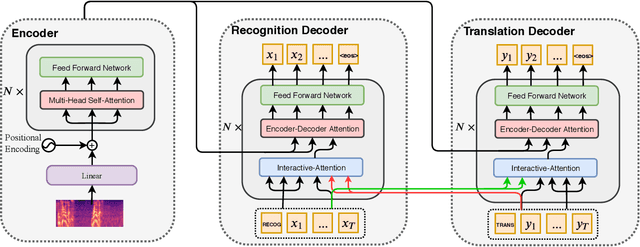
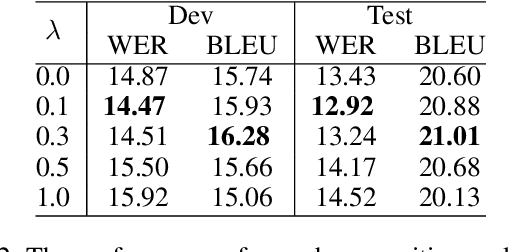
Speech-to-text translation (ST), which translates source language speech into target language text, has attracted intensive attention in recent years. Compared to the traditional pipeline system, the end-to-end ST model has potential benefits of lower latency, smaller model size, and less error propagation. However, it is notoriously difficult to implement such a model without transcriptions as intermediate. Existing works generally apply multi-task learning to improve translation quality by jointly training end-to-end ST along with automatic speech recognition (ASR). However, different tasks in this method cannot utilize information from each other, which limits the improvement. Other works propose a two-stage model where the second model can use the hidden state from the first one, but its cascade manner greatly affects the efficiency of training and inference process. In this paper, we propose a novel interactive attention mechanism which enables ASR and ST to perform synchronously and interactively in a single model. Specifically, the generation of transcriptions and translations not only relies on its previous outputs but also the outputs predicted in the other task. Experiments on TED speech translation corpora have shown that our proposed model can outperform strong baselines on the quality of speech translation and achieve better speech recognition performances as well.
Dialectal Speech Recognition and Translation of Swiss German Speech to Standard German Text: Microsoft's Submission to SwissText 2021
Jun 15, 2021

This paper describes the winning approach in the public SwissText 2021 competition on dialect recognition and translation of Swiss German speech to standard German text. Swiss German refers to the multitude of Alemannic dialects spoken in the German-speaking parts of Switzerland. Swiss German differs significantly from standard German in pronunciation, word inventory and grammar. It is mostly incomprehensible to native German speakers. Moreover, it lacks a standardized written script. To solve the challenging task, we propose a hybrid automatic speech recognition system with a lexicon that incorporates translations, a 1st pass language model that deals with Swiss German particularities, a transfer-learned acoustic model and a strong neural language model for 2nd pass rescoring. Our submission reaches 46.04% BLEU on a blind conversational test set and outperforms the second best competitor by a 12% relative margin.
Alzheimer's Dementia Detection through Spontaneous Dialogue with Proactive Robotic Listeners
Nov 15, 2022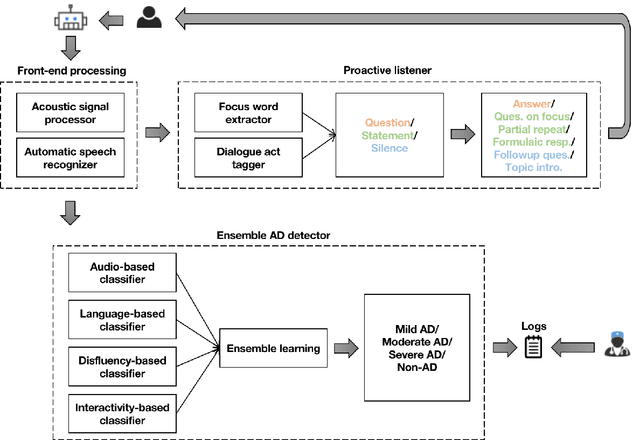
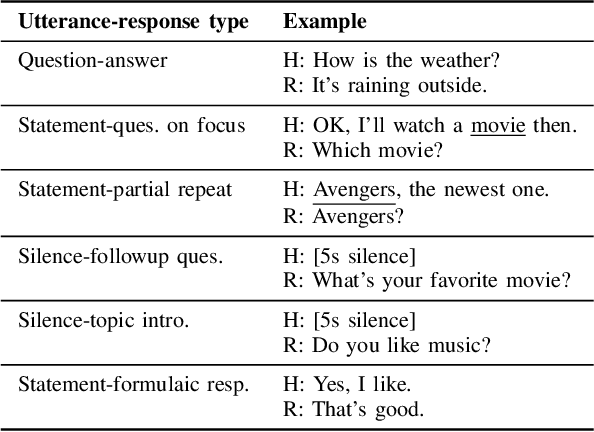
As the aging of society continues to accelerate, Alzheimer's Disease (AD) has received more and more attention from not only medical but also other fields, such as computer science, over the past decade. Since speech is considered one of the effective ways to diagnose cognitive decline, AD detection from speech has emerged as a hot topic. Nevertheless, such approaches fail to tackle several key issues: 1) AD is a complex neurocognitive disorder which means it is inappropriate to conduct AD detection using utterance information alone while ignoring dialogue information; 2) Utterances of AD patients contain many disfluencies that affect speech recognition yet are helpful to diagnosis; 3) AD patients tend to speak less, causing dialogue breakdown as the disease progresses. This fact leads to a small number of utterances, which may cause detection bias. Therefore, in this paper, we propose a novel AD detection architecture consisting of two major modules: an ensemble AD detector and a proactive listener. This architecture can be embedded in the dialogue system of conversational robots for healthcare.
Automatic Spelling Correction with Transformer for CTC-based End-to-End Speech Recognition
Mar 27, 2019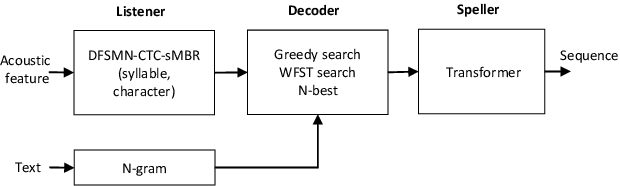

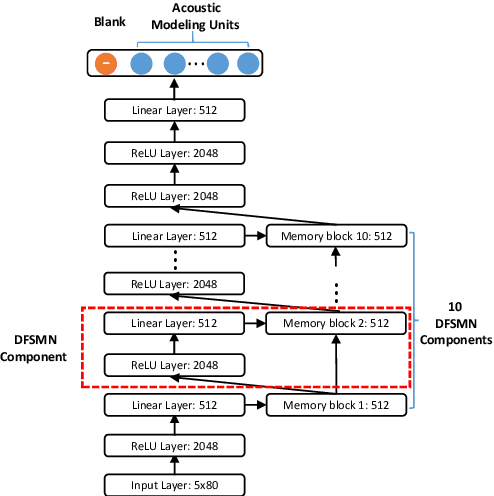
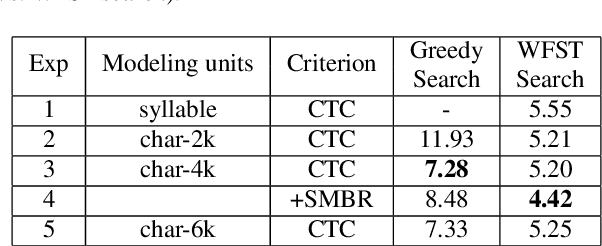
Connectionist Temporal Classification (CTC) based end-to-end speech recognition system usually need to incorporate an external language model by using WFST-based decoding in order to achieve promising results. This is more essential to Mandarin speech recognition since it owns a special phenomenon, namely homophone, which causes a lot of substitution errors. The linguistic information introduced by language model will help to distinguish these substitution errors. In this work, we propose a transformer based spelling correction model to automatically correct errors especially the substitution errors made by CTC-based Mandarin speech recognition system. Specifically, we investigate using the recognition results generated by CTC-based systems as input and the ground-truth transcriptions as output to train a transformer with encoder-decoder architecture, which is much similar to machine translation. Results in a 20,000 hours Mandarin speech recognition task show that the proposed spelling correction model can achieve a CER of 3.41%, which results in 22.9% and 53.2% relative improvement compared to the baseline CTC-based systems decoded with and without language model respectively.
Arabic Speech Emotion Recognition Employing Wav2vec2.0 and HuBERT Based on BAVED Dataset
Oct 09, 2021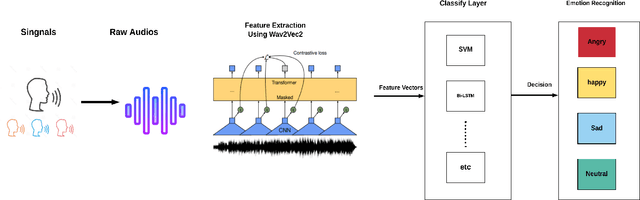

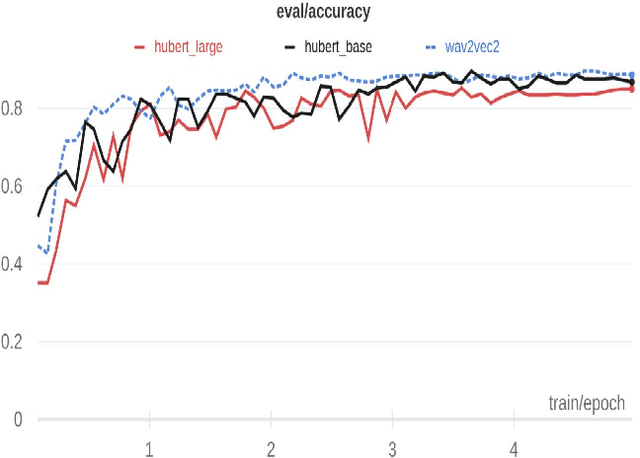
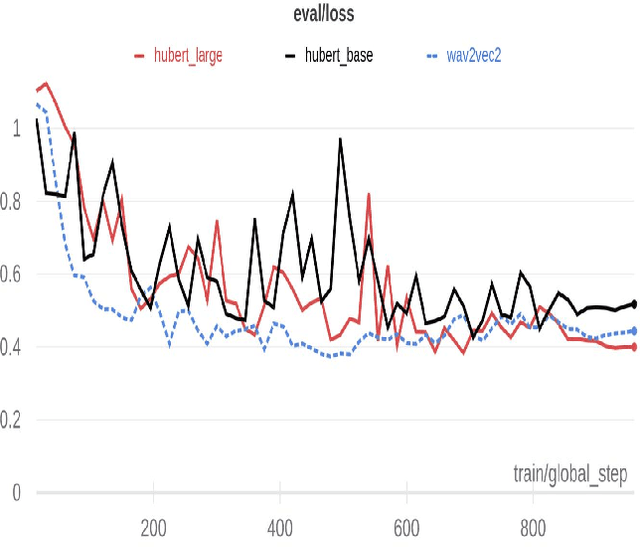
Recently, there have been tremendous research outcomes in the fields of speech recognition and natural language processing. This is due to the well-developed multi-layers deep learning paradigms such as wav2vec2.0, Wav2vecU, WavBERT, and HuBERT that provide better representation learning and high information capturing. Such paradigms run on hundreds of unlabeled data, then fine-tuned on a small dataset for specific tasks. This paper introduces a deep learning constructed emotional recognition model for Arabic speech dialogues. The developed model employs the state of the art audio representations include wav2vec2.0 and HuBERT. The experiment and performance results of our model overcome the previous known outcomes.
Adversarial Example Devastation and Detection on Speech Recognition System by Adding Random Noise
Sep 09, 2021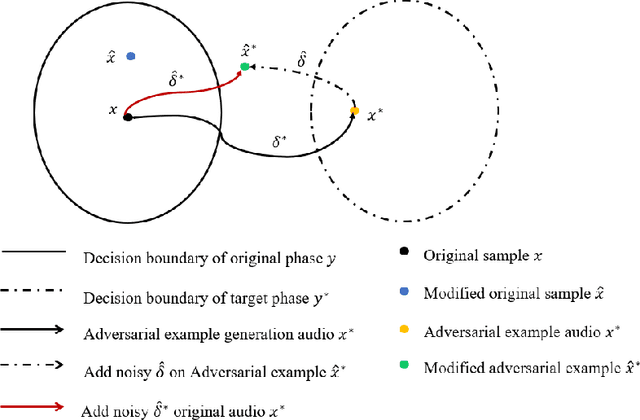

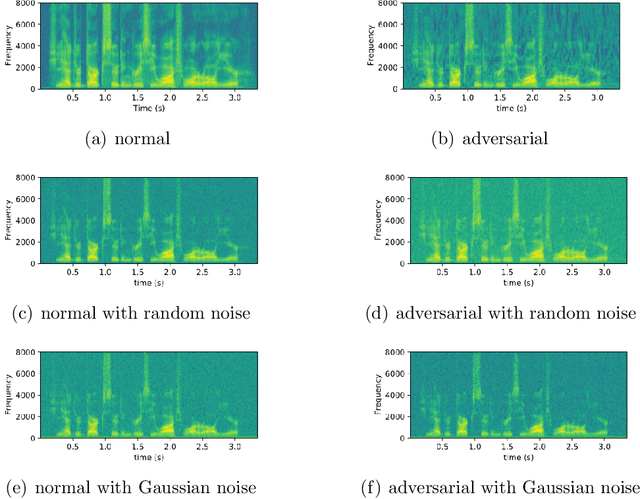
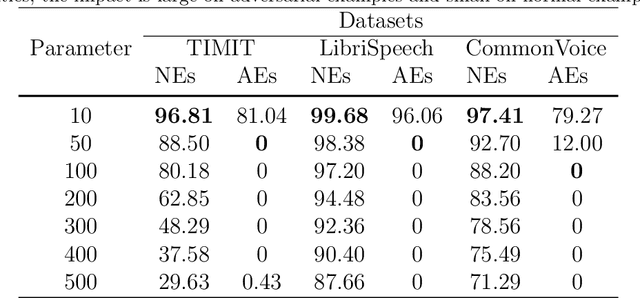
The automatic speech recognition (ASR) system based on deep neural network is easy to be attacked by an adversarial example due to the vulnerability of neural network, which is a hot topic in recent years. The adversarial example does harm to the ASR system, especially if the common-dependent ASR goes wrong, it will lead to serious consequences. To improve the robustness and security of the ASR system, the defense method against adversarial examples must be proposed. Based on this idea, we propose an algorithm of devastation and detection on adversarial examples which can attack the current advanced ASR system. We choose advanced text-dependent and command-dependent ASR system as our target system. Generating adversarial examples by the OPT on text-dependent ASR and the GA-based algorithm on command-dependent ASR. The main idea of our method is input transformation of the adversarial examples. Different random intensities and kinds of noise are added to the adversarial examples to devastate the perturbation previously added to the normal examples. From the experimental results, the method performs well. For the devastation of examples, the original speech similarity before and after adding noise can reach 99.68%, the similarity of the adversarial examples can reach 0%, and the detection rate of the adversarial examples can reach 94%.
Bidirectional Representations for Low Resource Spoken Language Understanding
Nov 24, 2022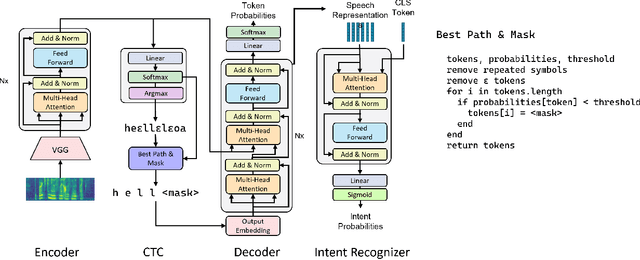


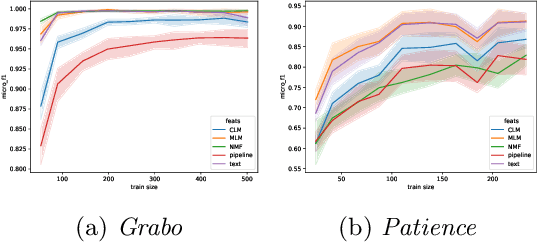
Most spoken language understanding systems use a pipeline approach composed of an automatic speech recognition interface and a natural language understanding module. This approach forces hard decisions when converting continuous inputs into discrete language symbols. Instead, we propose a representation model to encode speech in rich bidirectional encodings that can be used for downstream tasks such as intent prediction. The approach uses a masked language modelling objective to learn the representations, and thus benefits from both the left and right contexts. We show that the performance of the resulting encodings before fine-tuning is better than comparable models on multiple datasets, and that fine-tuning the top layers of the representation model improves the current state of the art on the Fluent Speech Command dataset, also in a low-data regime, when a limited amount of labelled data is used for training. Furthermore, we propose class attention as a spoken language understanding module, efficient both in terms of speed and number of parameters. Class attention can be used to visually explain the predictions of our model, which goes a long way in understanding how the model makes predictions. We perform experiments in English and in Dutch.
Instant One-Shot Word-Learning for Context-Specific Neural Sequence-to-Sequence Speech Recognition
Jul 05, 2021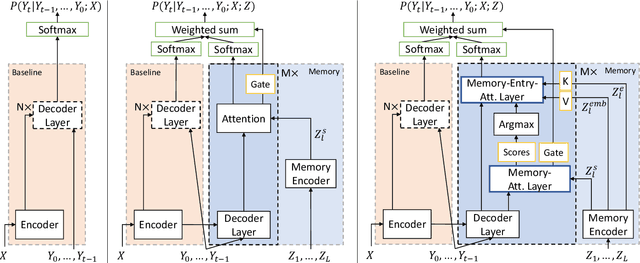
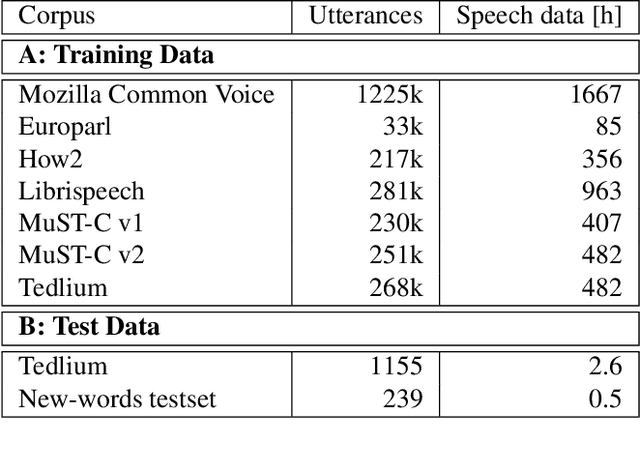
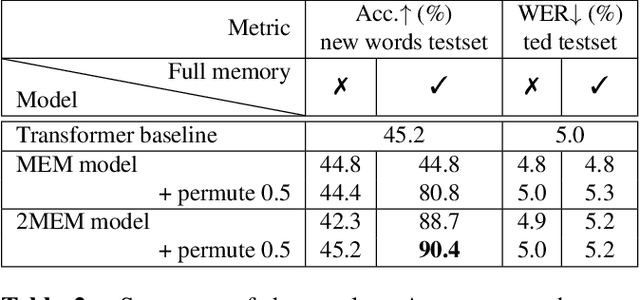
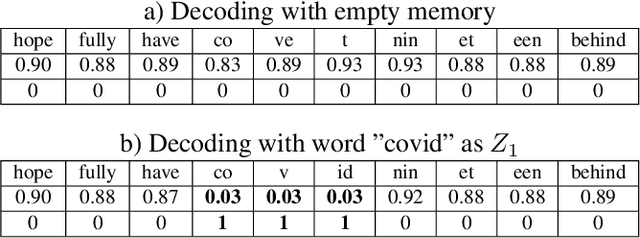
Neural sequence-to-sequence systems deliver state-of-the-art performance for automatic speech recognition (ASR). When using appropriate modeling units, e.g., byte-pair encoded characters, these systems are in principal open vocabulary systems. In practice, however, they often fail to recognize words not seen during training, e.g., named entities, numbers or technical terms. To alleviate this problem we supplement an end-to-end ASR system with a word/phrase memory and a mechanism to access this memory to recognize the words and phrases correctly. After the training of the ASR system, and when it has already been deployed, a relevant word can be added or subtracted instantly without the need for further training. In this paper we demonstrate that through this mechanism our system is able to recognize more than 85% of newly added words that it previously failed to recognize compared to a strong baseline.