 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
MASRI-HEADSET: A Maltese Corpus for Speech Recognition
Aug 13, 2020
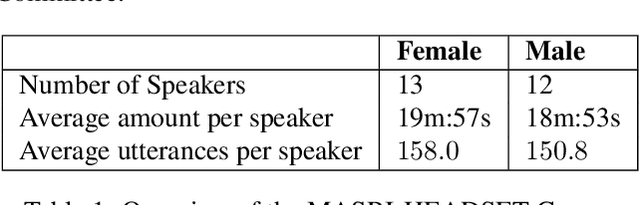
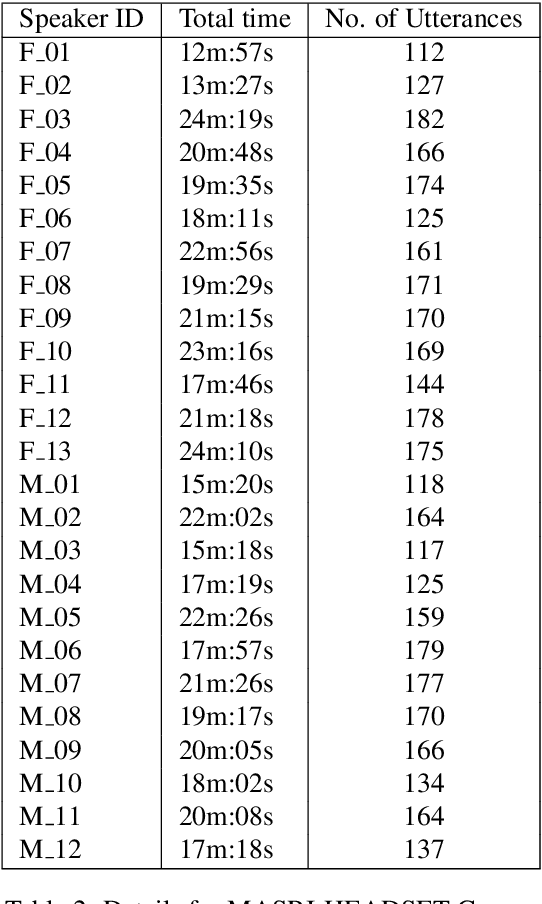
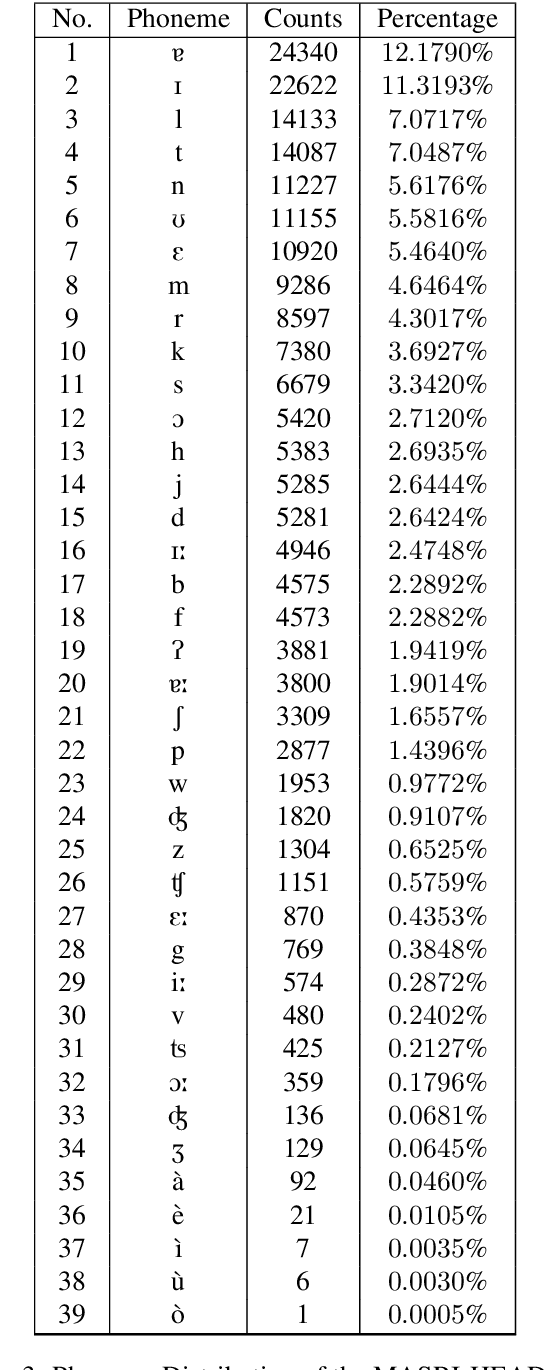
Maltese, the national language of Malta, is spoken by approximately 500,000 people. Speech processing for Maltese is still in its early stages of development. In this paper, we present the first spoken Maltese corpus designed purposely for Automatic Speech Recognition (ASR). The MASRI-HEADSET corpus was developed by the MASRI project at the University of Malta. It consists of 8 hours of speech paired with text, recorded by using short text snippets in a laboratory environment. The speakers were recruited from different geographical locations all over the Maltese islands, and were roughly evenly distributed by gender. This paper also presents some initial results achieved in baseline experiments for Maltese ASR using Sphinx and Kaldi. The MASRI-HEADSET Corpus is publicly available for research/academic purposes.
Research on Modeling Units of Transformer Transducer for Mandarin Speech Recognition
Apr 26, 2020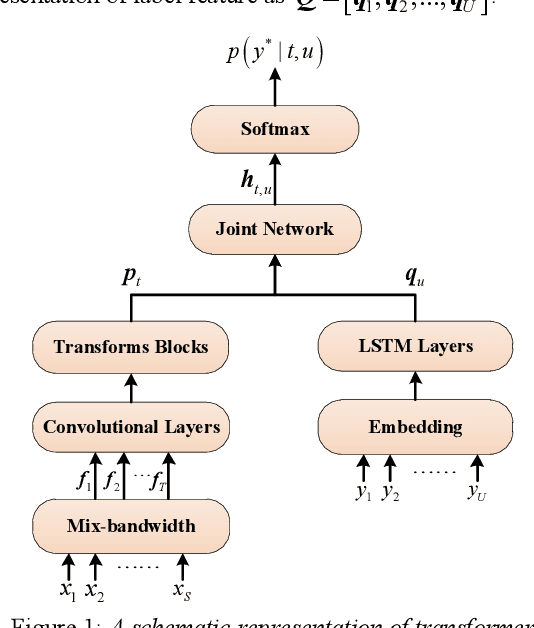
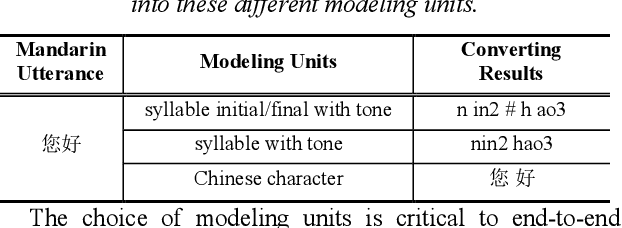
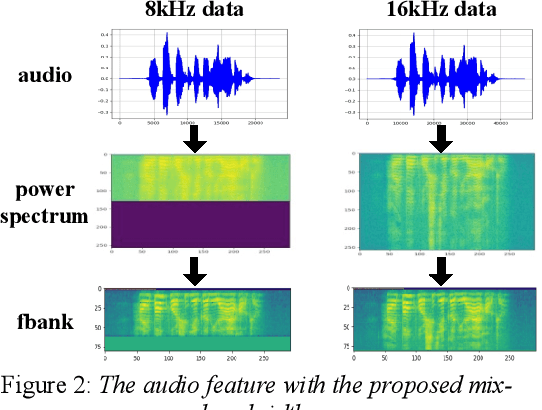
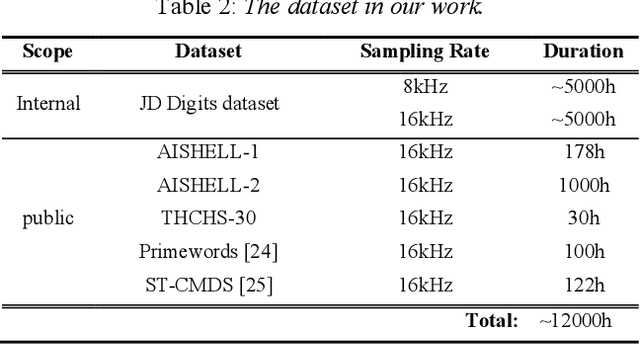
Modeling unit and model architecture are two key factors of Recurrent Neural Network Transducer (RNN-T) in end-to-end speech recognition. To improve the performance of RNN-T for Mandarin speech recognition task, a novel transformer transducer with the combination architecture of self-attention transformer and RNN is proposed. And then the choice of different modeling units for transformer transducer is explored. In addition, we present a new mix-bandwidth training method to obtain a general model that is able to accurately recognize Mandarin speech with different sampling rates simultaneously. All of our experiments are conducted on about 12,000 hours of Mandarin speech with sampling rate in 8kHz and 16kHz. Experimental results show that Mandarin transformer transducer using syllable with tone achieves the best performance. It yields an average of 14.4% and 44.1% relative Word Error Rate (WER) reduction when compared with the models using syllable initial/final with tone and Chinese character, respectively. Also, it outperforms the model based on syllable initial/final with tone with an average of 13.5% relative Character Error Rate (CER) reduction.
Token-level Speaker Change Detection Using Speaker Difference and Speech Content via Continuous Integrate-and-fire
Nov 17, 2022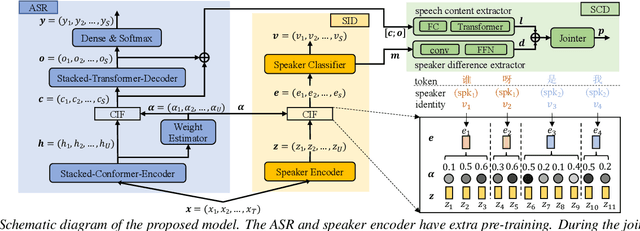
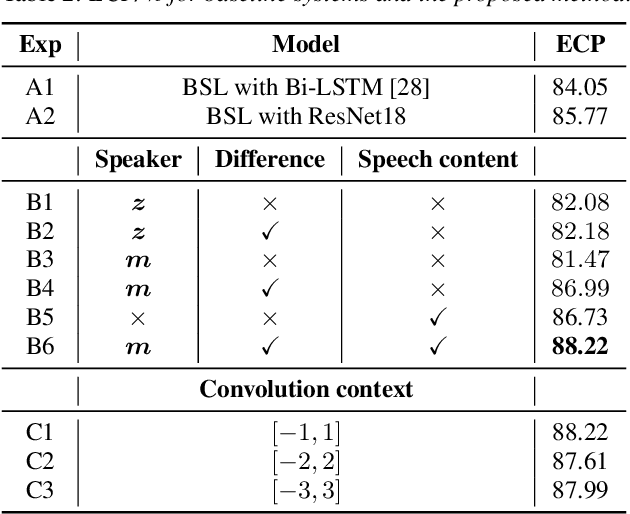
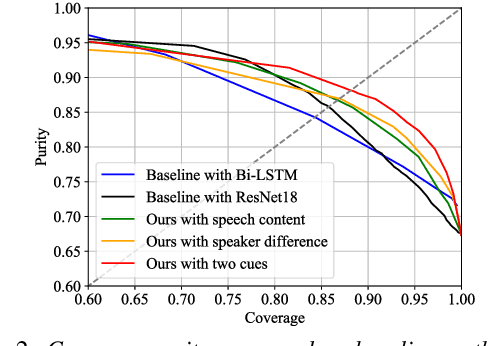
In multi-talker scenarios such as meetings and conversations, speech processing systems are usually required to segment the audio and then transcribe each segmentation. These two stages are addressed separately by speaker change detection (SCD) and automatic speech recognition (ASR). Most previous SCD systems rely solely on speaker information and ignore the importance of speech content. In this paper, we propose a novel SCD system that considers both cues of speaker difference and speech content. These two cues are converted into token-level representations by the continuous integrate-and-fire (CIF) mechanism and then combined for detecting speaker changes on the token acoustic boundaries. We evaluate the performance of our approach on a public real-recorded meeting dataset, AISHELL-4. The experiment results show that our method outperforms a competitive frame-level baseline system by 2.45% equal coverage-purity (ECP). In addition, we demonstrate the importance of speech content and speaker difference to the SCD task, and the advantages of conducting SCD on the token acoustic boundaries compared with conducting SCD frame by frame.
Acoustic Data-Driven Subword Modeling for End-to-End Speech Recognition
Apr 19, 2021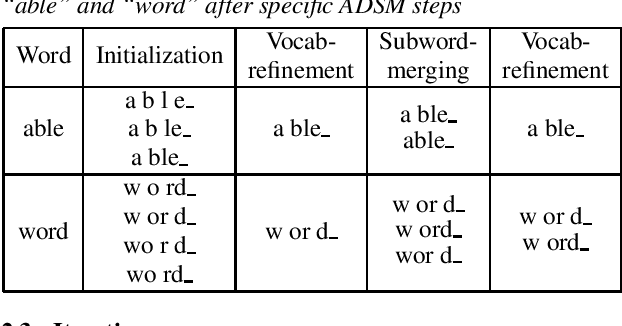
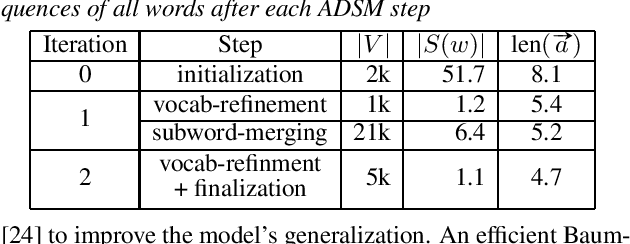
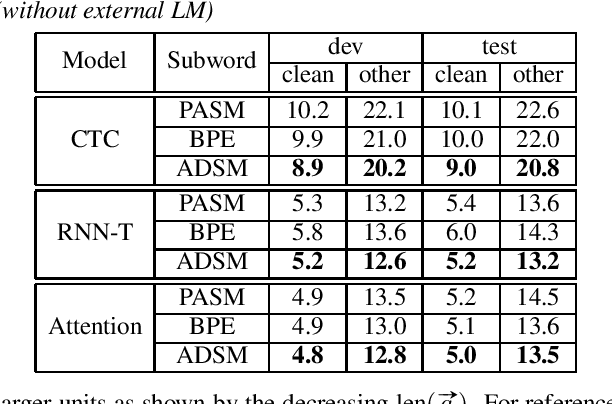

Subword units are commonly used for end-to-end automatic speech recognition (ASR), while a fully acoustic-oriented subword modeling approach is somewhat missing. We propose an acoustic data-driven subword modeling (ADSM) approach that adapts the advantages of several text-based and acoustic-based subword methods into one pipeline. With a fully acoustic-oriented label design and learning process, ADSM produces acoustic-structured subword units and acoustic-matched target sequence for further ASR training. The obtained ADSM labels are evaluated with different end-to-end ASR approaches including CTC, RNN-transducer and attention models. Experiments on the LibriSpeech corpus show that ADSM clearly outperforms both byte pair encoding (BPE) and pronunciation-assisted subword modeling (PASM) in all cases. Detailed analysis shows that ADSM achieves acoustically more logical word segmentation and more balanced sequence length, and thus, is suitable for both time-synchronous and label-synchronous models. We also briefly describe how to apply acoustic-based subword regularization and unseen text segmentation using ADSM.
AfroDigits: A Community-Driven Spoken Digit Dataset for African Languages
Apr 04, 2023
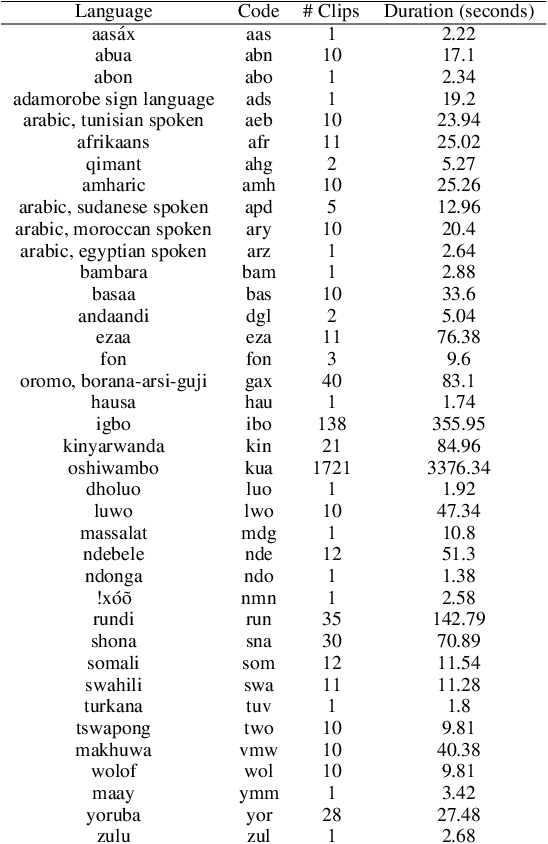
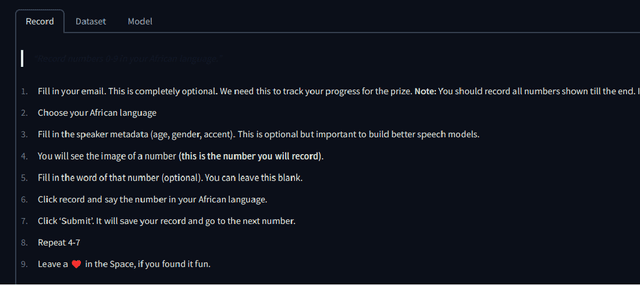
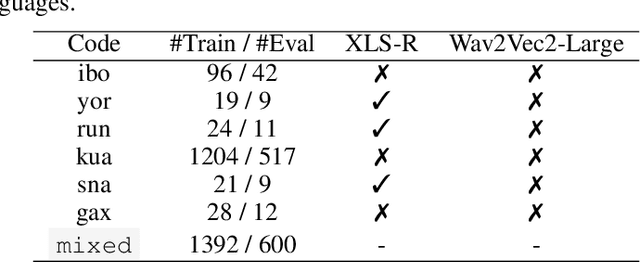
The advancement of speech technologies has been remarkable, yet its integration with African languages remains limited due to the scarcity of African speech corpora. To address this issue, we present AfroDigits, a minimalist, community-driven dataset of spoken digits for African languages, currently covering 38 African languages. As a demonstration of the practical applications of AfroDigits, we conduct audio digit classification experiments on six African languages [Igbo (ibo), Yoruba (yor), Rundi (run), Oshiwambo (kua), Shona (sna), and Oromo (gax)] using the Wav2Vec2.0-Large and XLS-R models. Our experiments reveal a useful insight on the effect of mixing African speech corpora during finetuning. AfroDigits is the first published audio digit dataset for African languages and we believe it will, among other things, pave the way for Afro-centric speech applications such as the recognition of telephone numbers, and street numbers. We release the dataset and platform publicly at https://huggingface.co/datasets/chrisjay/crowd-speech-africa and https://huggingface.co/spaces/chrisjay/afro-speech respectively.
A Further Study of Unsupervised Pre-training for Transformer Based Speech Recognition
Jun 23, 2020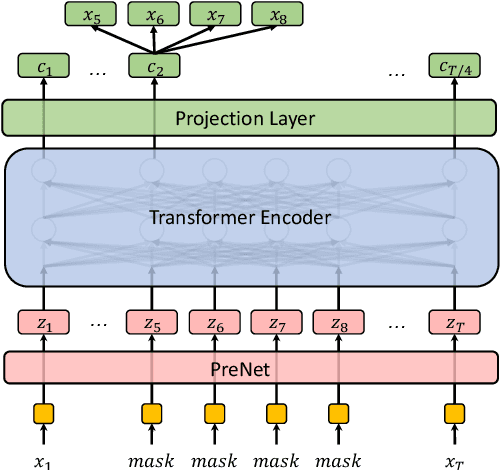

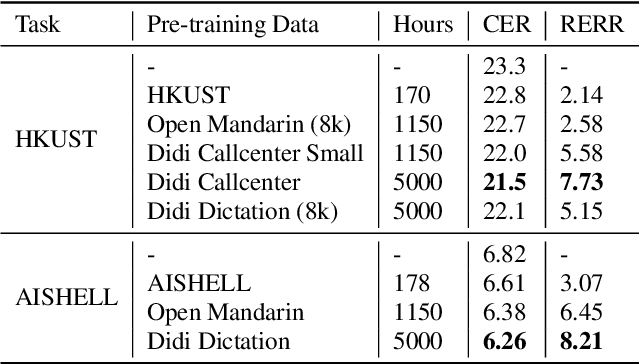
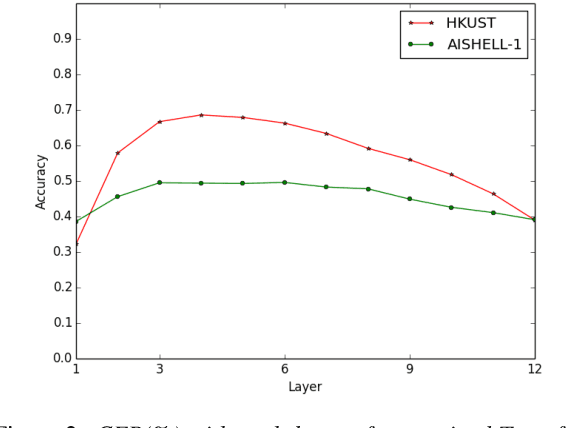
Building a good speech recognition system usually requires large amounts of transcribed data, which is expensive to collect. To tackle this problem, many unsupervised pre-training methods have been proposed. Among these methods, Masked Predictive Coding achieved significant improvements on various speech recognition datasets with BERT-like Masked Reconstruction loss and Transformer backbone. However, many aspects of MPC have not been fully investigated. In this paper, we conduct a further study on MPC and focus on three important aspects: the effect of pre-training data speaking style, its extension on streaming model, and how to better transfer learned knowledge from pre-training stage to downstream tasks. Experiments reveled that pre-training data with matching speaking style is more useful on downstream recognition tasks. A unified training objective with APC and MPC provided 8.46% relative error reduction on streaming model trained on HKUST. Also, the combination of target data adaption and layer-wise discriminative training helped the knowledge transfer of MPC, which achieved 3.99% relative error reduction on AISHELL over a strong baseline.
Combining Frame-Synchronous and Label-Synchronous Systems for Speech Recognition
Jul 01, 2021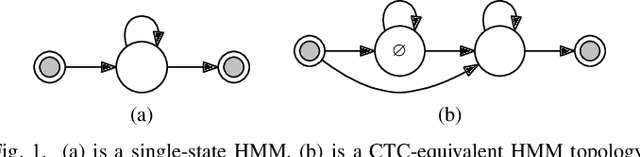
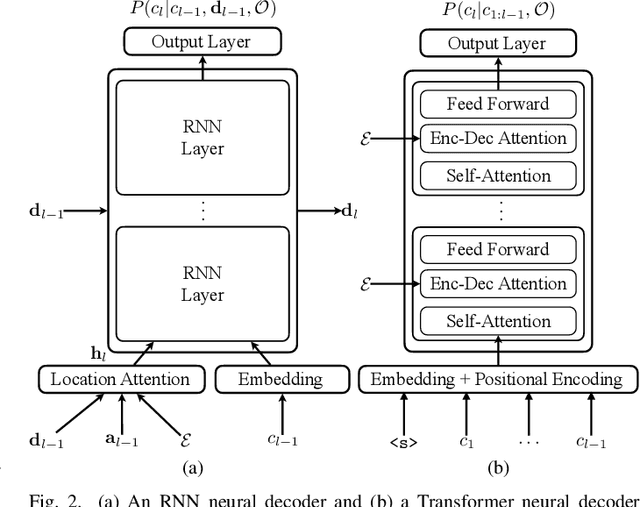
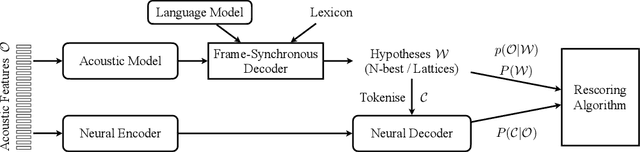
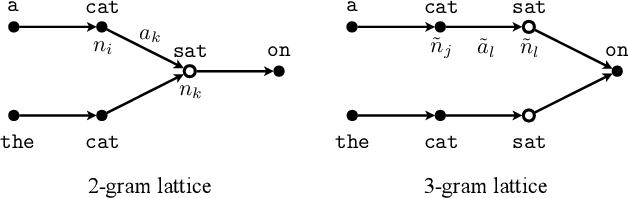
Commonly used automatic speech recognition (ASR) systems can be classified into frame-synchronous and label-synchronous categories, based on whether the speech is decoded on a per-frame or per-label basis. Frame-synchronous systems, such as traditional hidden Markov model systems, can easily incorporate existing knowledge and can support streaming ASR applications. Label-synchronous systems, based on attention-based encoder-decoder models, can jointly learn the acoustic and language information with a single model, which can be regarded as audio-grounded language models. In this paper, we propose rescoring the N-best hypotheses or lattices produced by a first-pass frame-synchronous system with a label-synchronous system in a second-pass. By exploiting the complementary modelling of the different approaches, the combined two-pass systems achieve competitive performance without using any extra speech or text data on two standard ASR tasks. For the 80-hour AMI IHM dataset, the combined system has a 13.7% word error rate (WER) on the evaluation set, which is up to a 29% relative WER reduction over the individual systems. For the 300-hour Switchboard dataset, the WERs of the combined system are 5.7% and 12.1% on Switchboard and CallHome subsets of Hub5'00, and 13.2% and 7.6% on Switchboard Cellular and Fisher subsets of RT03, up to a 33% relative reduction in WER over the individual systems.
Defending against Adversarial Audio via Diffusion Model
Mar 02, 2023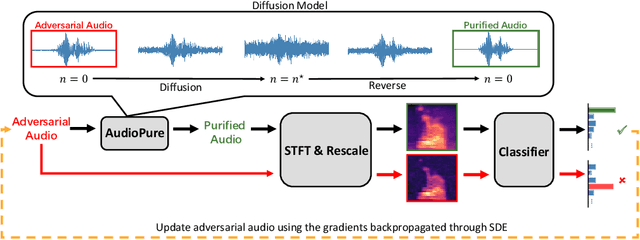

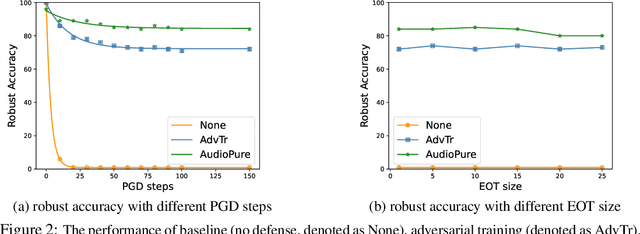

Deep learning models have been widely used in commercial acoustic systems in recent years. However, adversarial audio examples can cause abnormal behaviors for those acoustic systems, while being hard for humans to perceive. Various methods, such as transformation-based defenses and adversarial training, have been proposed to protect acoustic systems from adversarial attacks, but they are less effective against adaptive attacks. Furthermore, directly applying the methods from the image domain can lead to suboptimal results because of the unique properties of audio data. In this paper, we propose an adversarial purification-based defense pipeline, AudioPure, for acoustic systems via off-the-shelf diffusion models. Taking advantage of the strong generation ability of diffusion models, AudioPure first adds a small amount of noise to the adversarial audio and then runs the reverse sampling step to purify the noisy audio and recover clean audio. AudioPure is a plug-and-play method that can be directly applied to any pretrained classifier without any fine-tuning or re-training. We conduct extensive experiments on speech command recognition task to evaluate the robustness of AudioPure. Our method is effective against diverse adversarial attacks (e.g. $\mathcal{L}_2$ or $\mathcal{L}_\infty$-norm). It outperforms the existing methods under both strong adaptive white-box and black-box attacks bounded by $\mathcal{L}_2$ or $\mathcal{L}_\infty$-norm (up to +20\% in robust accuracy). Besides, we also evaluate the certified robustness for perturbations bounded by $\mathcal{L}_2$-norm via randomized smoothing. Our pipeline achieves a higher certified accuracy than baselines.
DiaCorrect: End-to-end error correction for speaker diarization
Oct 31, 2022
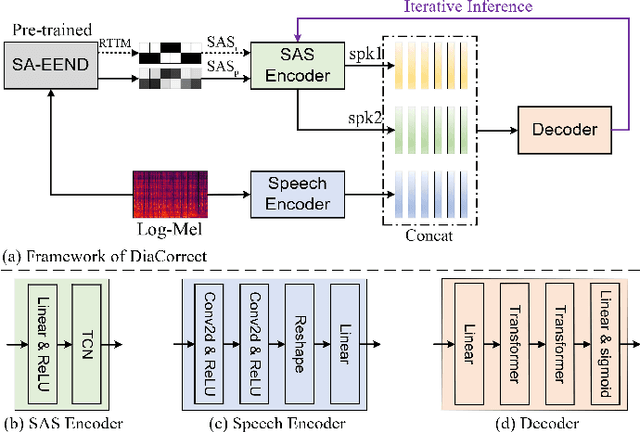
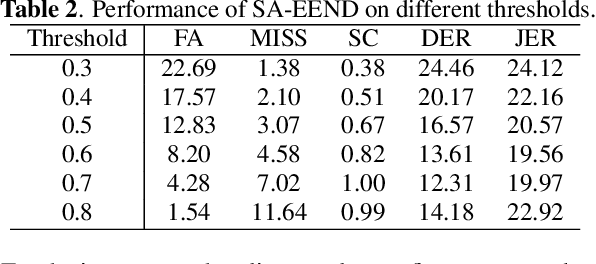
In recent years, speaker diarization has attracted widespread attention. To achieve better performance, some studies propose to diarize speech in multiple stages. Although these methods might bring additional benefits, most of them are quite complex. Motivated by spelling correction in automatic speech recognition (ASR), in this paper, we propose an end-to-end error correction framework, termed DiaCorrect, to refine the initial diarization results in a simple but efficient way. By exploiting the acoustic interactions between input mixture and its corresponding speaker activity, DiaCorrect could automatically adapt the initial speaker activity to minimize the diarization errors. Without bells and whistles, experiments on LibriSpeech based 2-speaker meeting-like data show that, the self-attentitive end-to-end neural diarization (SA-EEND) baseline with DiaCorrect could reduce its diarization error rate (DER) by over 62.4% from 12.31% to 4.63%. Our source code is available online at https://github.com/jyhan03/diacorrect.
Synchronous Speech Recognition and Speech-to-Text Translation with Interactive Decoding
Dec 16, 2019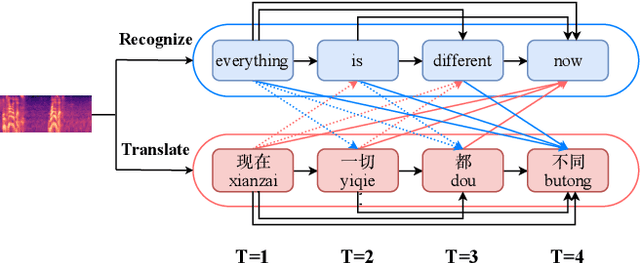
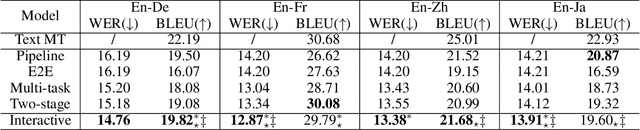
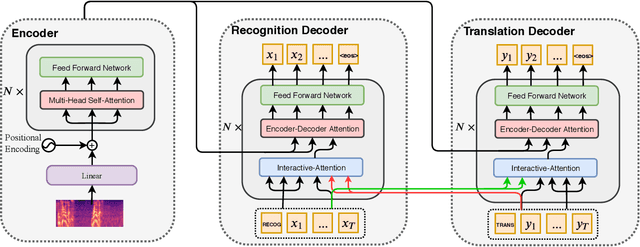
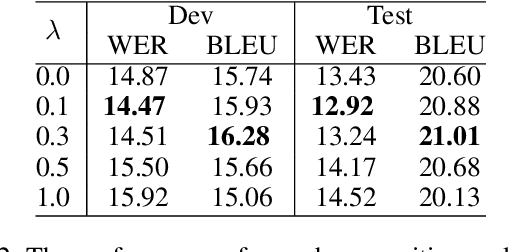
Speech-to-text translation (ST), which translates source language speech into target language text, has attracted intensive attention in recent years. Compared to the traditional pipeline system, the end-to-end ST model has potential benefits of lower latency, smaller model size, and less error propagation. However, it is notoriously difficult to implement such a model without transcriptions as intermediate. Existing works generally apply multi-task learning to improve translation quality by jointly training end-to-end ST along with automatic speech recognition (ASR). However, different tasks in this method cannot utilize information from each other, which limits the improvement. Other works propose a two-stage model where the second model can use the hidden state from the first one, but its cascade manner greatly affects the efficiency of training and inference process. In this paper, we propose a novel interactive attention mechanism which enables ASR and ST to perform synchronously and interactively in a single model. Specifically, the generation of transcriptions and translations not only relies on its previous outputs but also the outputs predicted in the other task. Experiments on TED speech translation corpora have shown that our proposed model can outperform strong baselines on the quality of speech translation and achieve better speech recognition performances as well.