 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Dual Causal/Non-Causal Self-Attention for Streaming End-to-End Speech Recognition
Jul 02, 2021
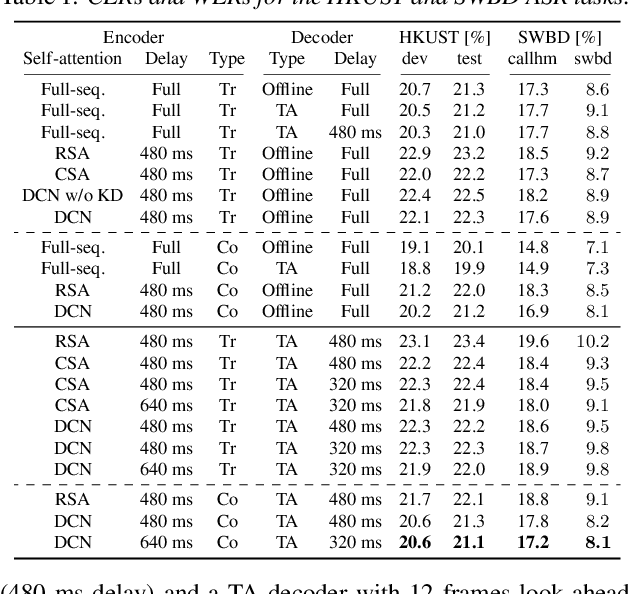
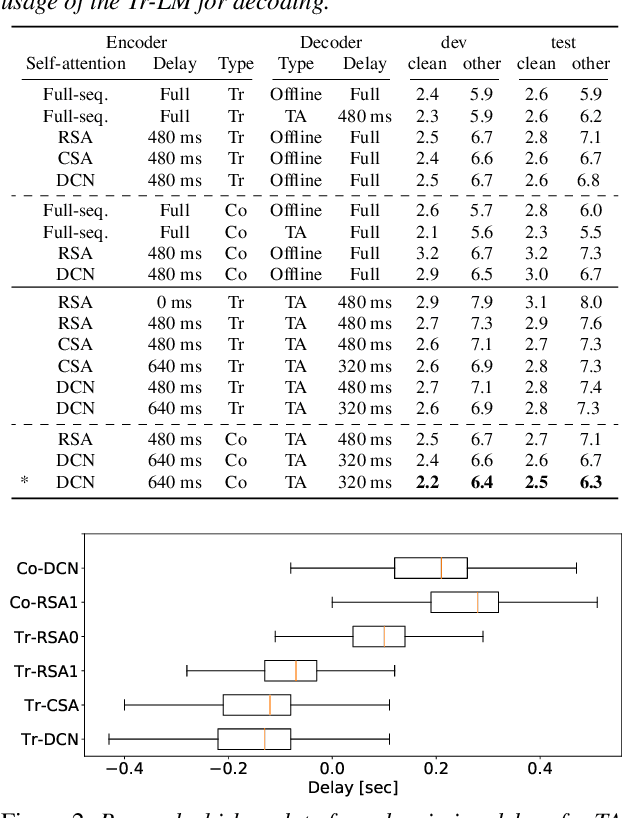
Attention-based end-to-end automatic speech recognition (ASR) systems have recently demonstrated state-of-the-art results for numerous tasks. However, the application of self-attention and attention-based encoder-decoder models remains challenging for streaming ASR, where each word must be recognized shortly after it was spoken. In this work, we present the dual causal/non-causal self-attention (DCN) architecture, which in contrast to restricted self-attention prevents the overall context to grow beyond the look-ahead of a single layer when used in a deep architecture. DCN is compared to chunk-based and restricted self-attention using streaming transformer and conformer architectures, showing improved ASR performance over restricted self-attention and competitive ASR results compared to chunk-based self-attention, while providing the advantage of frame-synchronous processing. Combined with triggered attention, the proposed streaming end-to-end ASR systems obtained state-of-the-art results on the LibriSpeech, HKUST, and Switchboard ASR tasks.
Defending against Adversarial Audio via Diffusion Model
Mar 02, 2023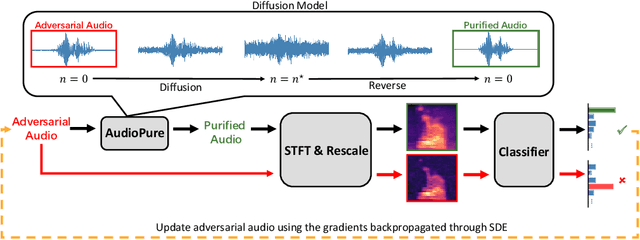

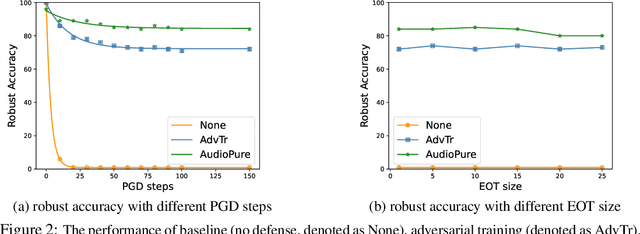

Deep learning models have been widely used in commercial acoustic systems in recent years. However, adversarial audio examples can cause abnormal behaviors for those acoustic systems, while being hard for humans to perceive. Various methods, such as transformation-based defenses and adversarial training, have been proposed to protect acoustic systems from adversarial attacks, but they are less effective against adaptive attacks. Furthermore, directly applying the methods from the image domain can lead to suboptimal results because of the unique properties of audio data. In this paper, we propose an adversarial purification-based defense pipeline, AudioPure, for acoustic systems via off-the-shelf diffusion models. Taking advantage of the strong generation ability of diffusion models, AudioPure first adds a small amount of noise to the adversarial audio and then runs the reverse sampling step to purify the noisy audio and recover clean audio. AudioPure is a plug-and-play method that can be directly applied to any pretrained classifier without any fine-tuning or re-training. We conduct extensive experiments on speech command recognition task to evaluate the robustness of AudioPure. Our method is effective against diverse adversarial attacks (e.g. $\mathcal{L}_2$ or $\mathcal{L}_\infty$-norm). It outperforms the existing methods under both strong adaptive white-box and black-box attacks bounded by $\mathcal{L}_2$ or $\mathcal{L}_\infty$-norm (up to +20\% in robust accuracy). Besides, we also evaluate the certified robustness for perturbations bounded by $\mathcal{L}_2$-norm via randomized smoothing. Our pipeline achieves a higher certified accuracy than baselines.
Token-level Speaker Change Detection Using Speaker Difference and Speech Content via Continuous Integrate-and-fire
Nov 17, 2022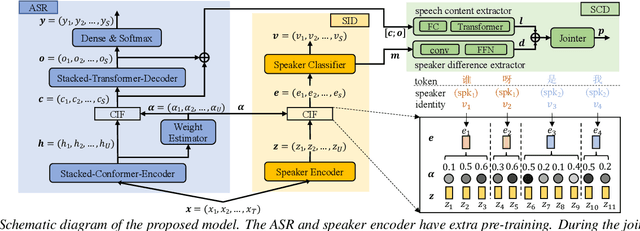
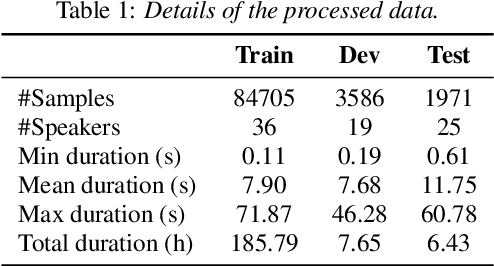
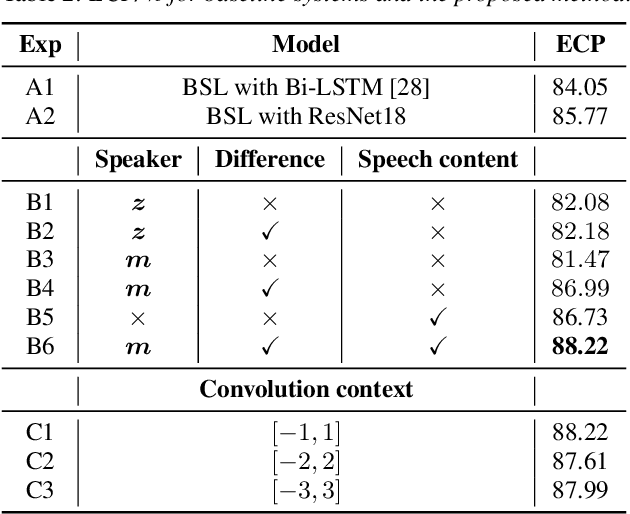
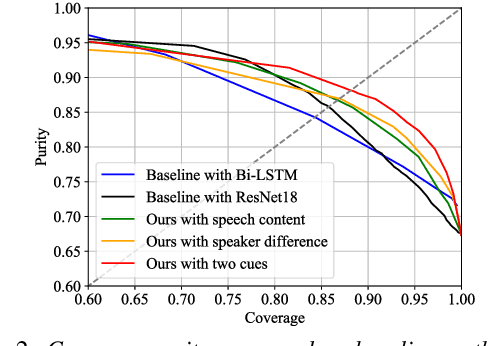
In multi-talker scenarios such as meetings and conversations, speech processing systems are usually required to segment the audio and then transcribe each segmentation. These two stages are addressed separately by speaker change detection (SCD) and automatic speech recognition (ASR). Most previous SCD systems rely solely on speaker information and ignore the importance of speech content. In this paper, we propose a novel SCD system that considers both cues of speaker difference and speech content. These two cues are converted into token-level representations by the continuous integrate-and-fire (CIF) mechanism and then combined for detecting speaker changes on the token acoustic boundaries. We evaluate the performance of our approach on a public real-recorded meeting dataset, AISHELL-4. The experiment results show that our method outperforms a competitive frame-level baseline system by 2.45% equal coverage-purity (ECP). In addition, we demonstrate the importance of speech content and speaker difference to the SCD task, and the advantages of conducting SCD on the token acoustic boundaries compared with conducting SCD frame by frame.
Sparsification via Compressed Sensing for Automatic Speech Recognition
Feb 09, 2021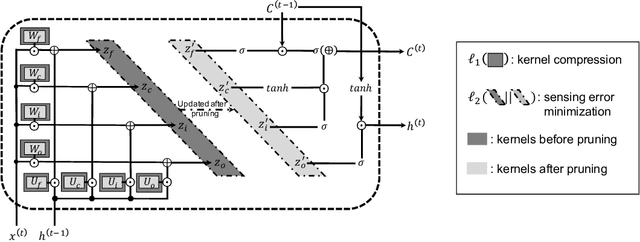
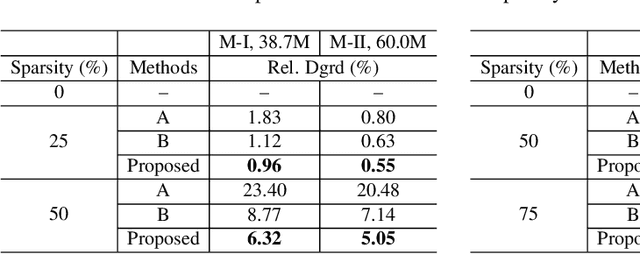
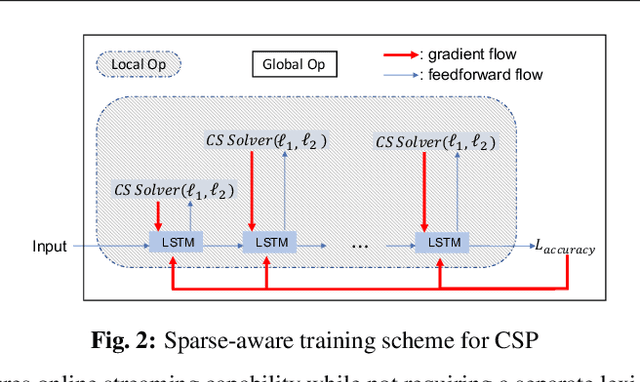
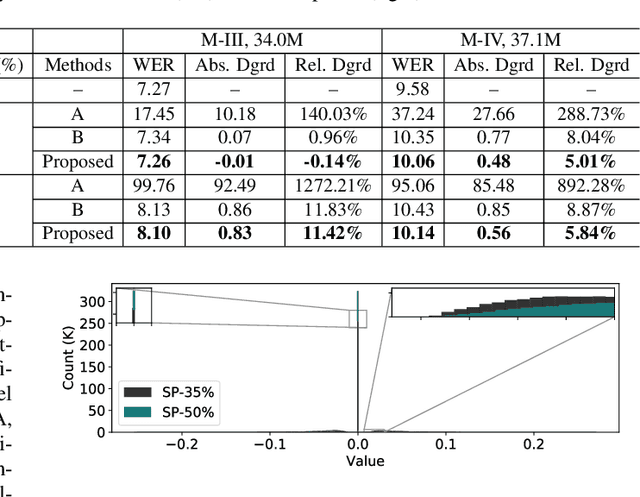
In order to achieve high accuracy for machine learning (ML) applications, it is essential to employ models with a large number of parameters. Certain applications, such as Automatic Speech Recognition (ASR), however, require real-time interactions with users, hence compelling the model to have as low latency as possible. Deploying large scale ML applications thus necessitates model quantization and compression, especially when running ML models on resource constrained devices. For example, by forcing some of the model weight values into zero, it is possible to apply zero-weight compression, which reduces both the model size and model reading time from the memory. In the literature, such methods are referred to as sparse pruning. The fundamental questions are when and which weights should be forced to zero, i.e. be pruned. In this work, we propose a compressed sensing based pruning (CSP) approach to effectively address those questions. By reformulating sparse pruning as a sparsity inducing and compression-error reduction dual problem, we introduce the classic compressed sensing process into the ML model training process. Using ASR task as an example, we show that CSP consistently outperforms existing approaches in the literature.
Essence Knowledge Distillation for Speech Recognition
Jun 26, 2019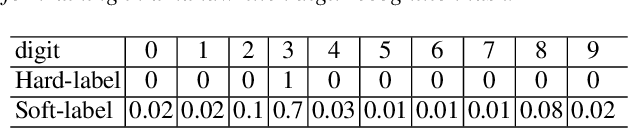
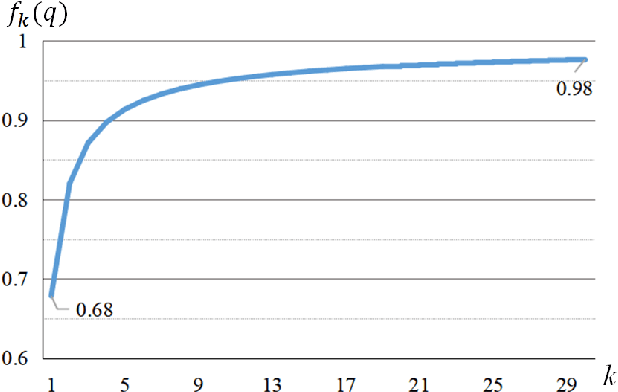
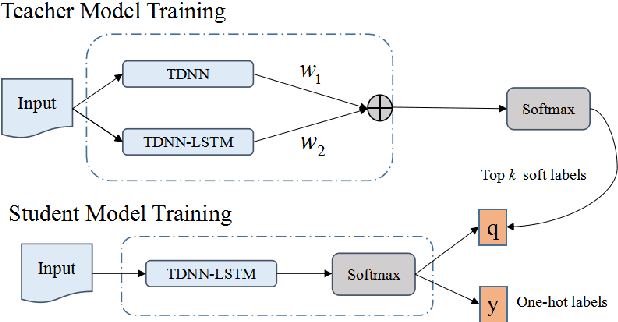
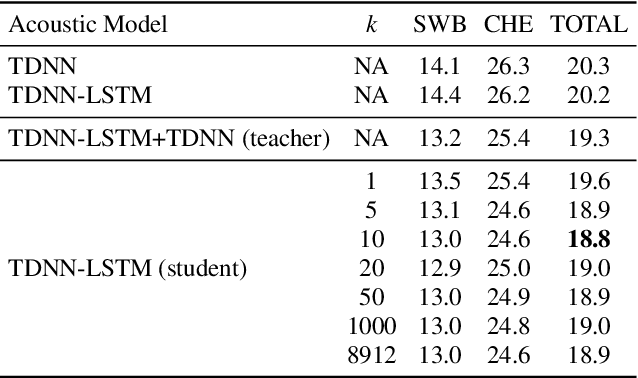
It is well known that a speech recognition system that combines multiple acoustic models trained on the same data significantly outperforms a single-model system. Unfortunately, real time speech recognition using a whole ensemble of models is too computationally expensive. In this paper, we propose to distill the knowledge of essence in an ensemble of models (i.e. the teacher model) to a single model (i.e. the student model) that needs much less computation to deploy. Previously, all the soften outputs of the teacher model are used to optimize the student model. We argue that not all the outputs of the ensemble are necessary to be distilled. Some of the outputs may even contain noisy information that is useless or even harmful to the training of the student model. In addition, we propose to train the student model with a multitask learning approach by utilizing both the soften outputs of the teacher model and the correct hard labels. The proposed method achieves some surprising results on the Switchboard data set. When the student model is trained together with the correct labels and the essence knowledge from the teacher model, it not only significantly outperforms another single model with the same architecture that is trained only with the correct labels, but also consistently outperforms the teacher model that is used to generate the soft labels.
Dialectal Speech Recognition and Translation of Swiss German Speech to Standard German Text: Microsoft's Submission to SwissText 2021
Jul 01, 2021

This paper describes the winning approach in the Shared Task 3 at SwissText 2021 on Swiss German Speech to Standard German Text, a public competition on dialect recognition and translation. Swiss German refers to the multitude of Alemannic dialects spoken in the German-speaking parts of Switzerland. Swiss German differs significantly from standard German in pronunciation, word inventory and grammar. It is mostly incomprehensible to native German speakers. Moreover, it lacks a standardized written script. To solve the challenging task, we propose a hybrid automatic speech recognition system with a lexicon that incorporates translations, a 1st pass language model that deals with Swiss German particularities, a transfer-learned acoustic model and a strong neural language model for 2nd pass rescoring. Our submission reaches 46.04% BLEU on a blind conversational test set and outperforms the second best competitor by a 12% relative margin.
Evolutionary optimization of contexts for phonetic correction in speech recognition systems
Feb 23, 2021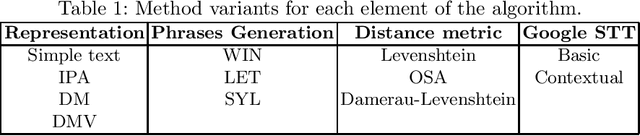
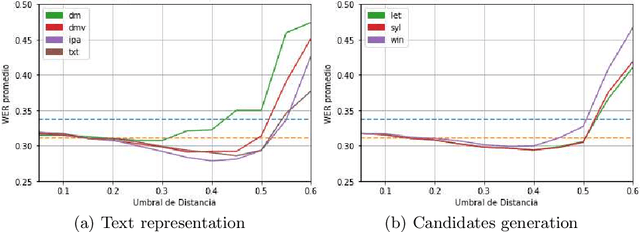
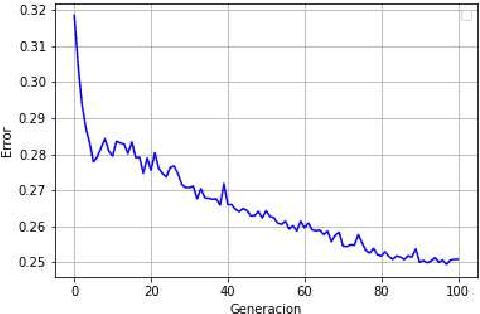
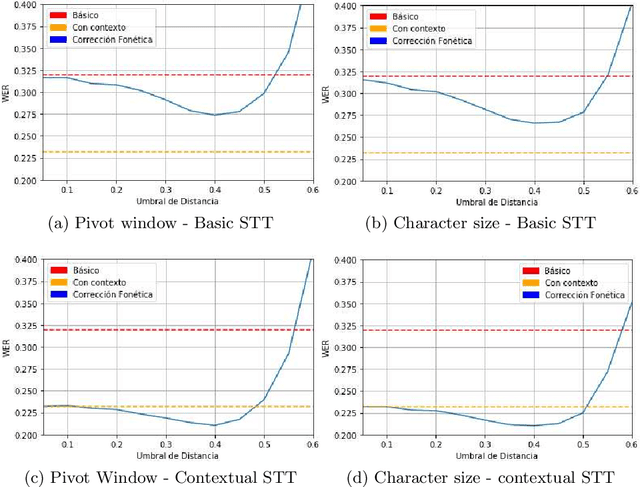
Automatic Speech Recognition (ASR) is an area of growing academic and commercial interest due to the high demand for applications that use it to provide a natural communication method. It is common for general purpose ASR systems to fail in applications that use a domain-specific language. Various strategies have been used to reduce the error, such as providing a context that modifies the language model and post-processing correction methods. This article explores the use of an evolutionary process to generate an optimized context for a specific application domain, as well as different correction techniques based on phonetic distance metrics. The results show the viability of a genetic algorithm as a tool for context optimization, which, added to a post-processing correction based on phonetic representations, can reduce the errors on the recognized speech.
* 13 pages, 4 figures, This article is a translation of the paper "Optimizaci\'on evolutiva de contextos para la correcci\'on fon\'etica en sistemas de reconocimiento del habla" presented in COMIA 2019
DiaCorrect: End-to-end error correction for speaker diarization
Oct 31, 2022
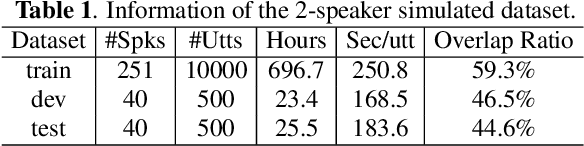
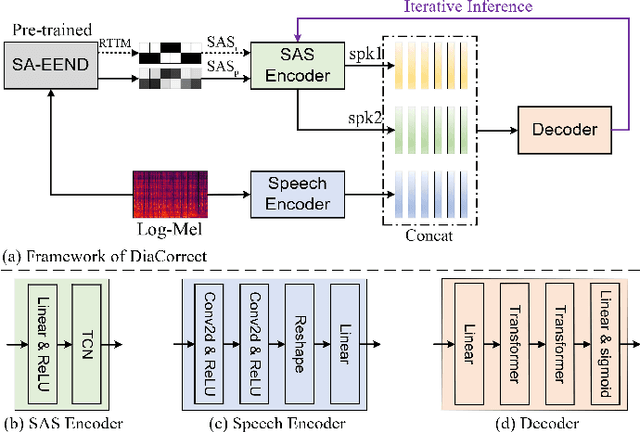
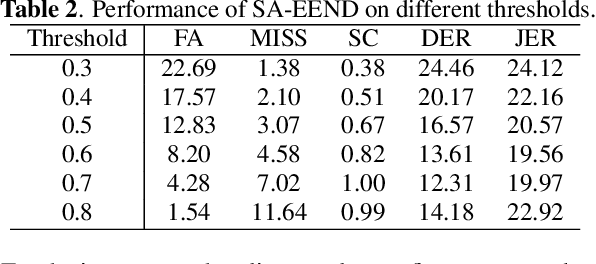
In recent years, speaker diarization has attracted widespread attention. To achieve better performance, some studies propose to diarize speech in multiple stages. Although these methods might bring additional benefits, most of them are quite complex. Motivated by spelling correction in automatic speech recognition (ASR), in this paper, we propose an end-to-end error correction framework, termed DiaCorrect, to refine the initial diarization results in a simple but efficient way. By exploiting the acoustic interactions between input mixture and its corresponding speaker activity, DiaCorrect could automatically adapt the initial speaker activity to minimize the diarization errors. Without bells and whistles, experiments on LibriSpeech based 2-speaker meeting-like data show that, the self-attentitive end-to-end neural diarization (SA-EEND) baseline with DiaCorrect could reduce its diarization error rate (DER) by over 62.4% from 12.31% to 4.63%. Our source code is available online at https://github.com/jyhan03/diacorrect.
MASRI-HEADSET: A Maltese Corpus for Speech Recognition
Aug 13, 2020
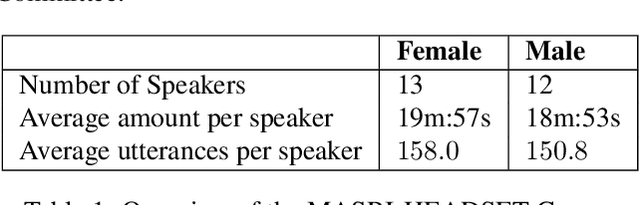
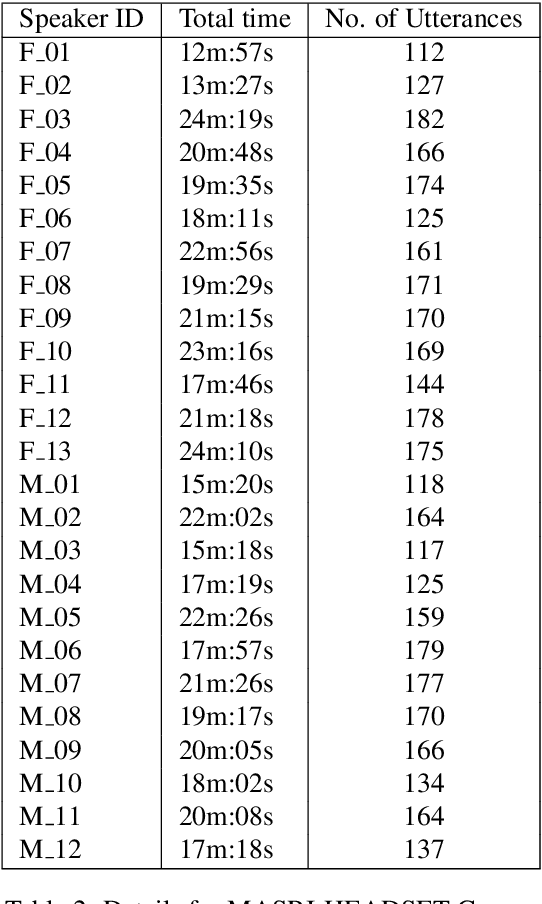
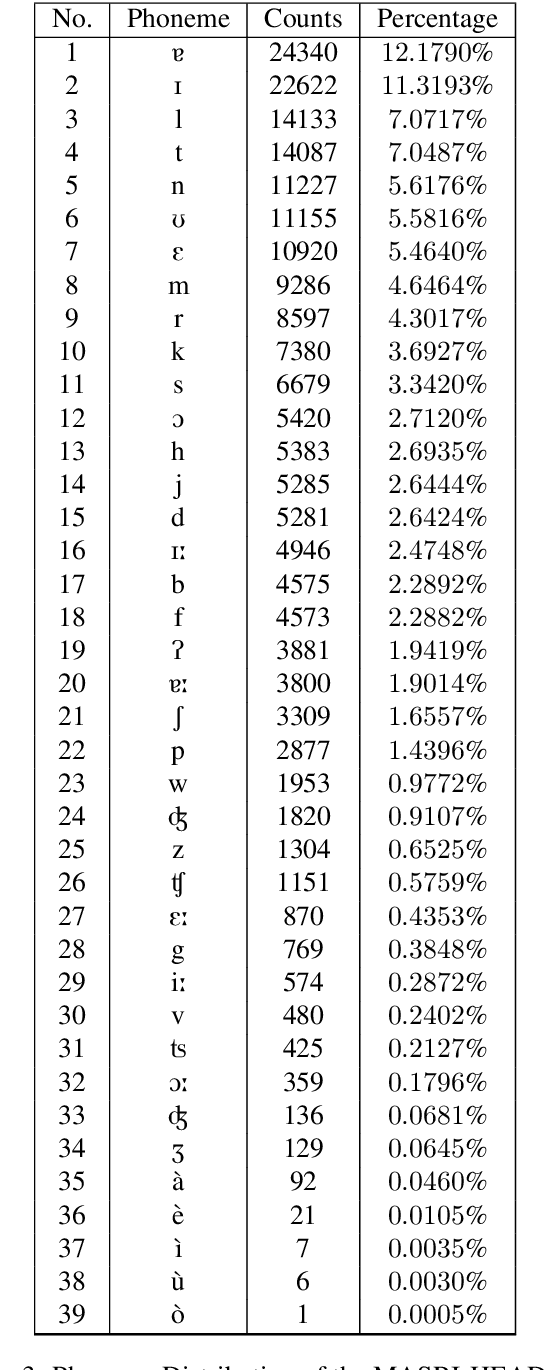
Maltese, the national language of Malta, is spoken by approximately 500,000 people. Speech processing for Maltese is still in its early stages of development. In this paper, we present the first spoken Maltese corpus designed purposely for Automatic Speech Recognition (ASR). The MASRI-HEADSET corpus was developed by the MASRI project at the University of Malta. It consists of 8 hours of speech paired with text, recorded by using short text snippets in a laboratory environment. The speakers were recruited from different geographical locations all over the Maltese islands, and were roughly evenly distributed by gender. This paper also presents some initial results achieved in baseline experiments for Maltese ASR using Sphinx and Kaldi. The MASRI-HEADSET Corpus is publicly available for research/academic purposes.
Measuring Equality in Machine Learning Security Defenses
Mar 01, 2023
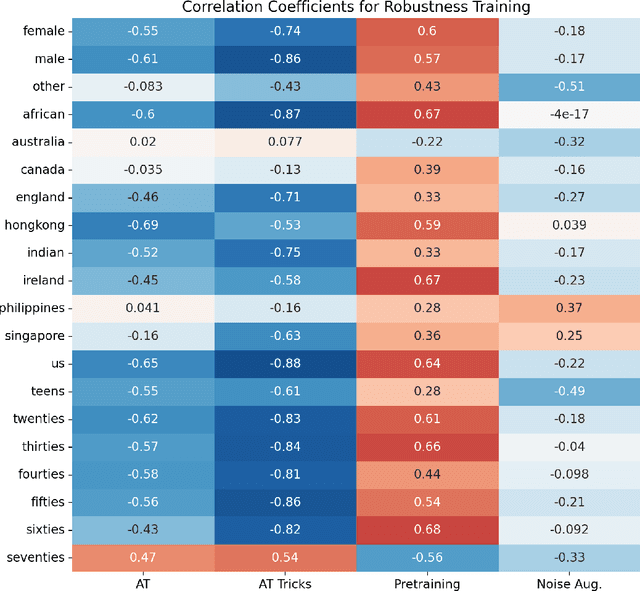
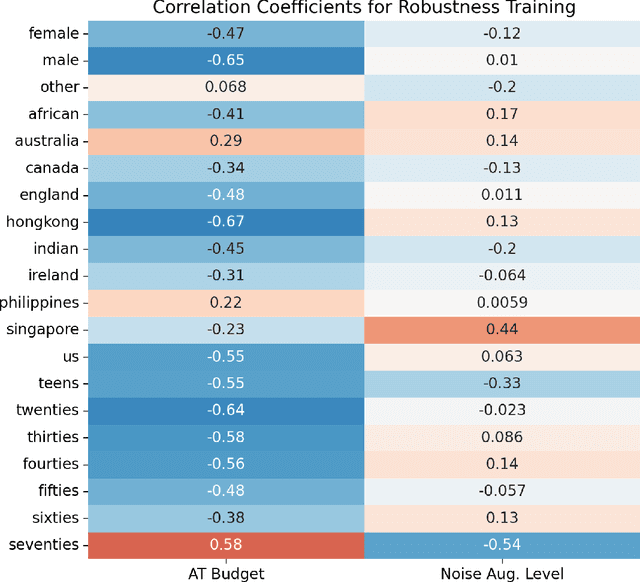
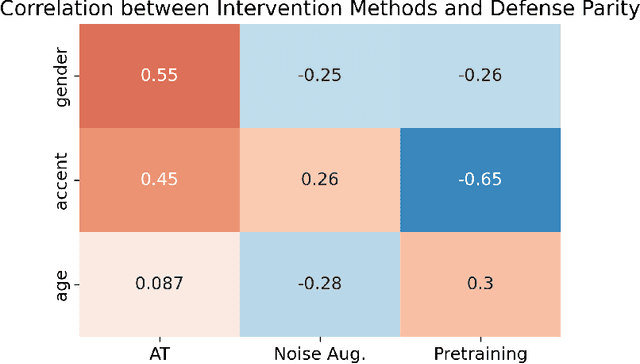
The machine learning security community has developed myriad defenses for evasion attacks over the past decade. An understudied question in that community is: for whom do these defenses defend? In this work, we consider some common approaches to defending learned systems and whether those approaches may offer unexpected performance inequities when used by different sub-populations. We outline simple parity metrics and a framework for analysis that can begin to answer this question through empirical results of the fairness implications of machine learning security methods. Many methods have been proposed that can cause direct harm, which we describe as biased vulnerability and biased rejection. Our framework and metric can be applied to robustly trained models, preprocessing-based methods, and rejection methods to capture behavior over security budgets. We identify a realistic dataset with a reasonable computational cost suitable for measuring the equality of defenses. Through a case study in speech command recognition, we show how such defenses do not offer equal protection for social subgroups and how to perform such analyses for robustness training, and we present a comparison of fairness between two rejection-based defenses: randomized smoothing and neural rejection. We offer further analysis of factors that correlate to equitable defenses to stimulate the future investigation of how to assist in building such defenses. To the best of our knowledge, this is the first work that examines the fairness disparity in the accuracy-robustness trade-off in speech data and addresses fairness evaluation for rejection-based defenses.