 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Improving Mandarin Speech Recogntion with Block-augmented Transformer
Jul 24, 2022
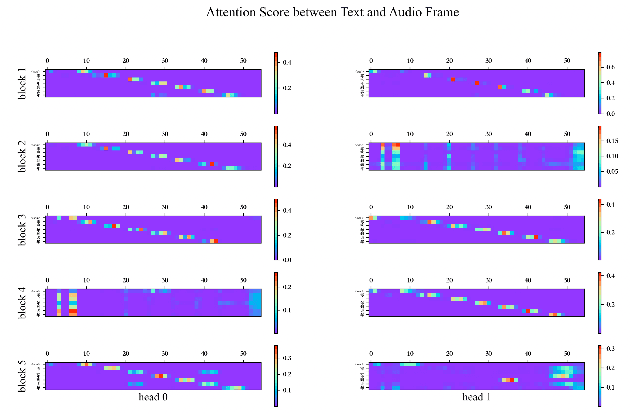
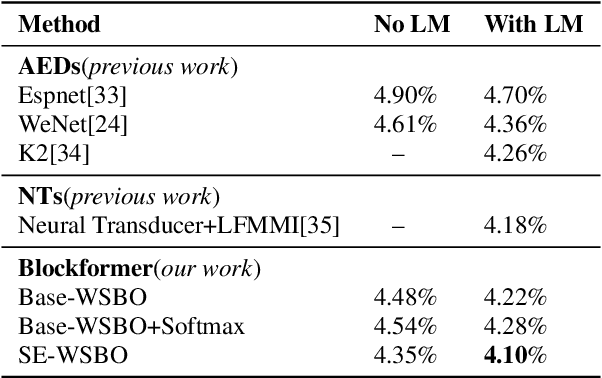
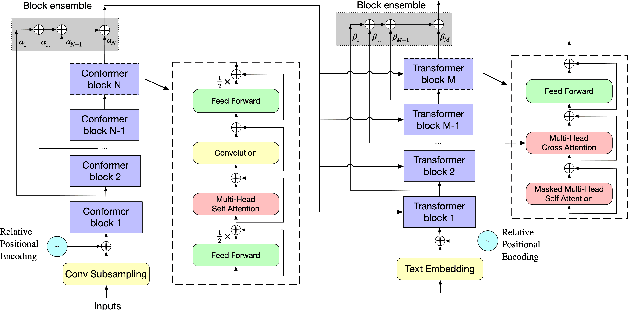

Recently Convolution-augmented Transformer (Conformer) has shown promising results in Automatic Speech Recognition (ASR), outperforming the previous best published Transformer Transducer. In this work, we believe that the output information of each block in the encoder and decoder is not completely inclusive, in other words, their output information may be complementary. We study how to take advantage of the complementary information of each block in a parameter-efficient way, and it is expected that this may lead to more robust performance. Therefore we propose the Block-augmented Transformer for speech recognition, named Blockformer. We have implemented two block ensemble methods: the base Weighted Sum of the Blocks Output (Base-WSBO), and the Squeeze-and-Excitation module to Weighted Sum of the Blocks Output (SE-WSBO). Experiments have proved that the Blockformer significantly outperforms the state-of-the-art Conformer-based models on AISHELL-1, our model achieves a CER of 4.35\% without using a language model and 4.10\% with an external language model on the testset.
Speaker Identification using Speech Recognition
May 29, 2022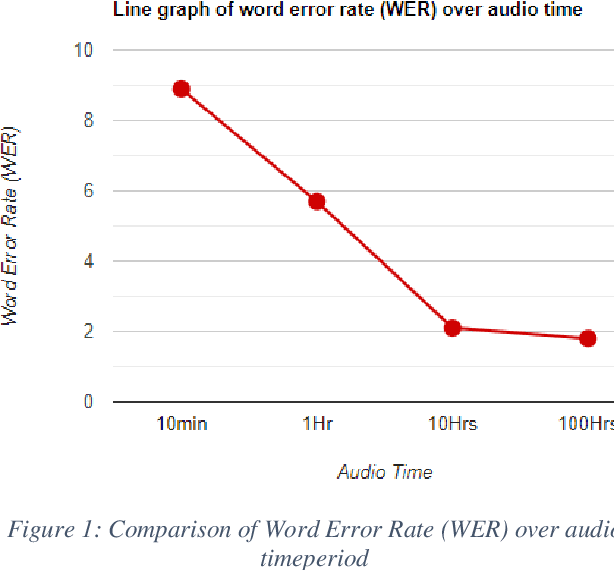
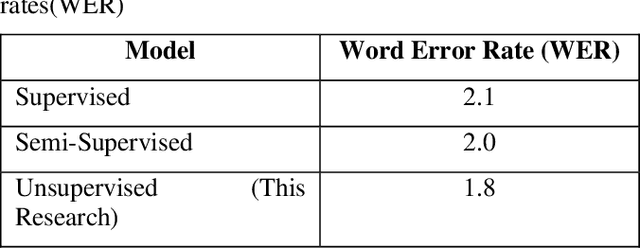
The audio data is increasing day by day throughout the globe with the increase of telephonic conversations, video conferences and voice messages. This research provides a mechanism for identifying a speaker in an audio file, based on the human voice biometric features like pitch, amplitude, frequency etc. We proposed an unsupervised learning model where the model can learn speech representation with limited dataset. Librispeech dataset was used in this research and we were able to achieve word error rate of 1.8.
Deep Spiking Neural Networks for Large Vocabulary Automatic Speech Recognition
Nov 19, 2019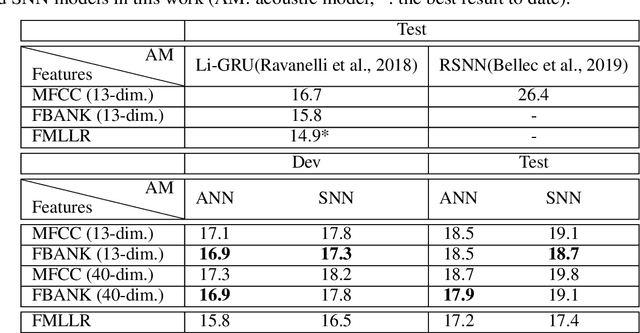
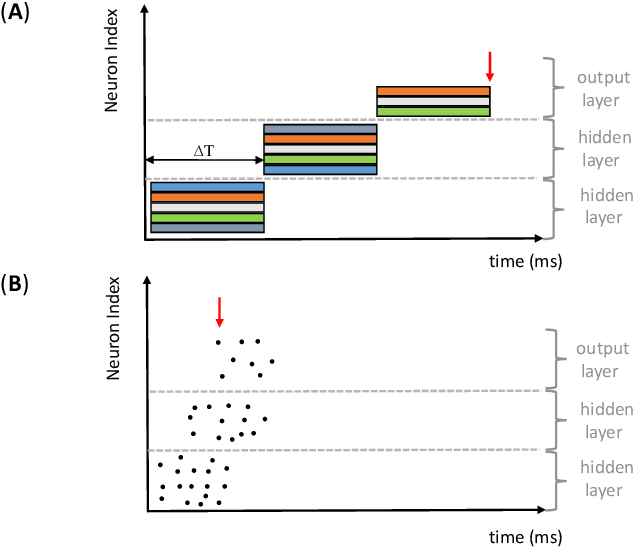
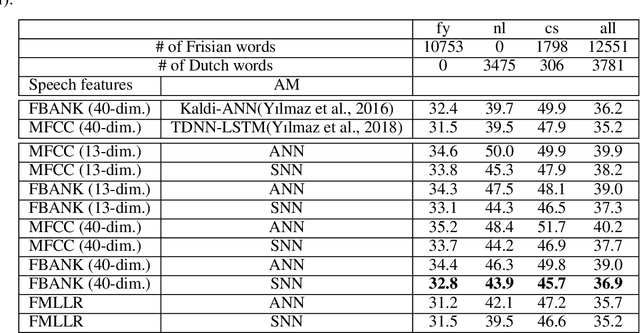
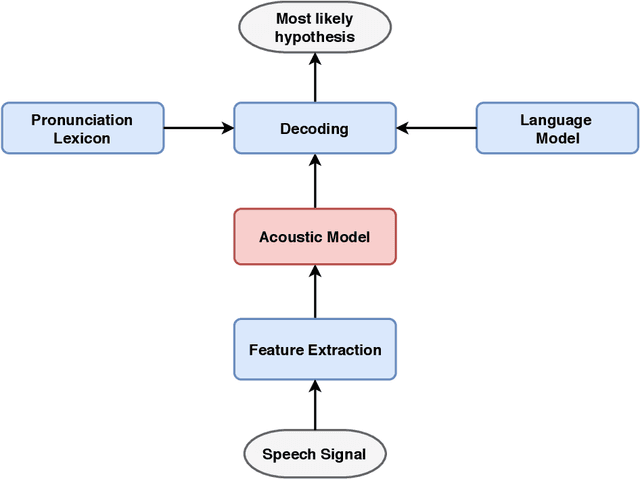
Artificial neural networks (ANN) have become the mainstream acoustic modeling technique for large vocabulary automatic speech recognition (ASR). A conventional ANN features a multi-layer architecture that requires massive amounts of computation. The brain-inspired spiking neural networks (SNN) closely mimic the biological neural networks and can operate on low-power neuromorphic hardware with spike-based computation. Motivated by their unprecedented energyefficiency and rapid information processing capability, we explore the use of SNNs for speech recognition. In this work, we use SNNs for acoustic modeling and evaluate their performance on several large vocabulary recognition scenarios. The experimental results demonstrate competitive ASR accuracies to their ANN counterparts, while require significantly reduced computational cost and inference time. Integrating the algorithmic power of deep SNNs with energy-efficient neuromorphic hardware, therefore, offer an attractive solution for ASR applications running locally on mobile and embedded devices.
A baseline model for computationally inexpensive speech recognition for Kazakh using the Coqui STT framework
Jul 19, 2021

Mobile devices are transforming the way people interact with computers, and speech interfaces to applications are ever more important. Automatic Speech Recognition systems recently published are very accurate, but often require powerful machinery (specialised Graphical Processing Units) for inference, which makes them impractical to run on commodity devices, especially in streaming mode. Impressed by the accuracy of, but dissatisfied with the inference times of the baseline Kazakh ASR model of (Khassanov et al.,2021) when not using a GPU, we trained a new baseline acoustic model (on the same dataset as the aforementioned paper) and three language models for use with the Coqui STT framework. Results look promising, but further epochs of training and parameter sweeping or, alternatively, limiting the vocabulary that the ASR system must support, is needed to reach a production-level accuracy.
Blank Collapse: Compressing CTC emission for the faster decoding
Oct 31, 2022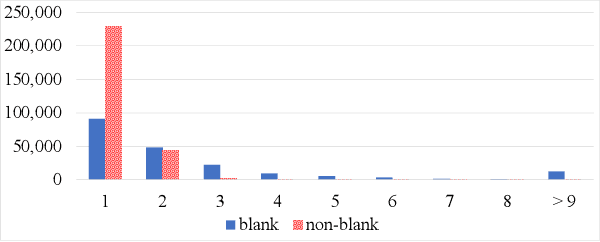
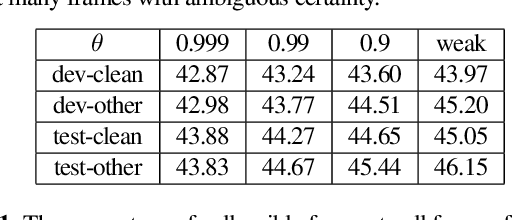
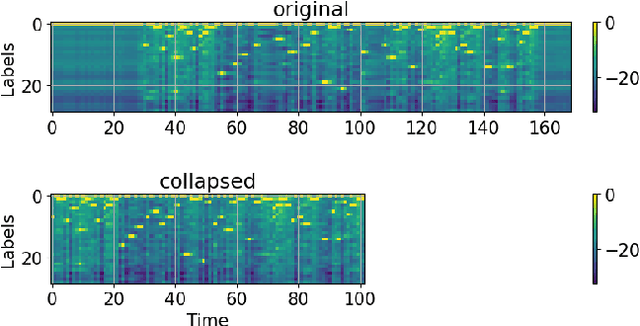
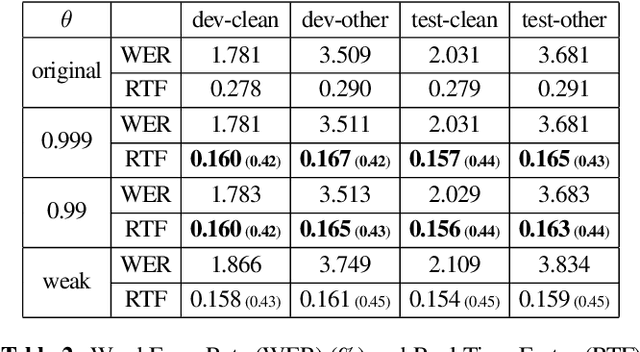
Connectionist Temporal Classification (CTC) model is a very efficient method for modeling sequences, especially for speech data. In order to use CTC model as an Automatic Speech Recognition (ASR) task, the beam search decoding with an external language model like n-gram LM is necessary to obtain reasonable results. In this paper we analyze the blank label in CTC beam search deeply and propose a very simple method to reduce the amount of calculation resulting in faster beam search decoding speed. With this method, we can get up to 78% faster decoding speed than ordinary beam search decoding with a very small loss of accuracy in LibriSpeech datasets. We prove this method is effective not only practically by experiments but also theoretically by mathematical reasoning. We also observe that this reduction is more obvious if the accuracy of the model is higher.
Speech Recognition for Endangered and Extinct Samoyedic languages
Dec 09, 2020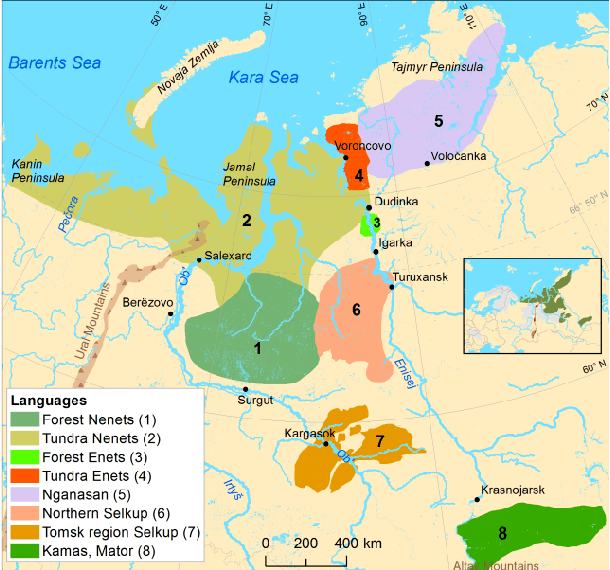
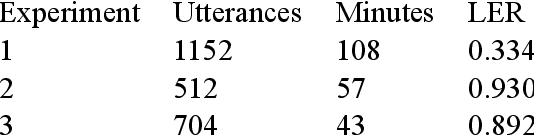

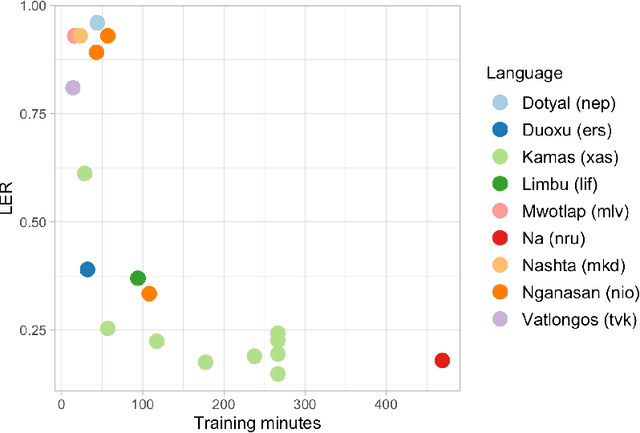
Our study presents a series of experiments on speech recognition with endangered and extinct Samoyedic languages, spoken in Northern and Southern Siberia. To best of our knowledge, this is the first time a functional ASR system is built for an extinct language. We achieve with Kamas language a Label Error Rate of 15\%, and conclude through careful error analysis that this quality is already very useful as a starting point for refined human transcriptions. Our results with related Nganasan language are more modest, with best model having the error rate of 33\%. We show, however, through experiments where Kamas training data is enlarged incrementally, that Nganasan results are in line with what is expected under low-resource circumstances of the language. Based on this, we provide recommendations for scenarios in which further language documentation or archive processing activities could benefit from modern ASR technology. All training data and processing scripts haven been published on Zenodo with clear licences to ensure further work in this important topic.
Simplified Self-Attention for Transformer-based End-to-End Speech Recognition
May 21, 2020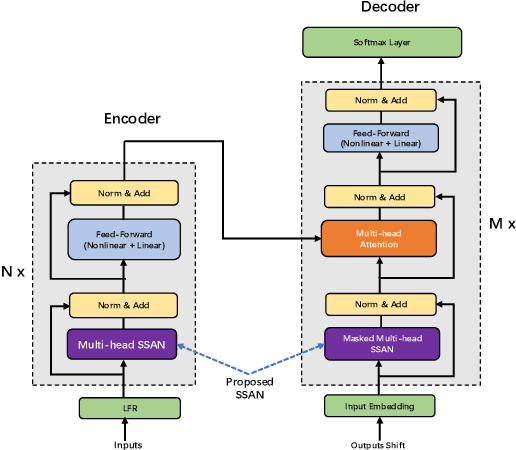
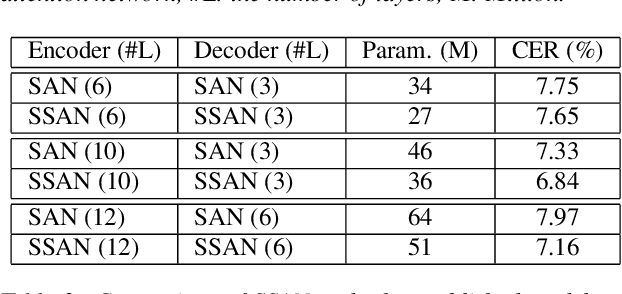
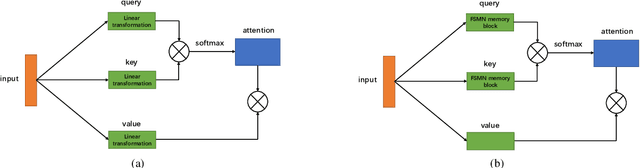
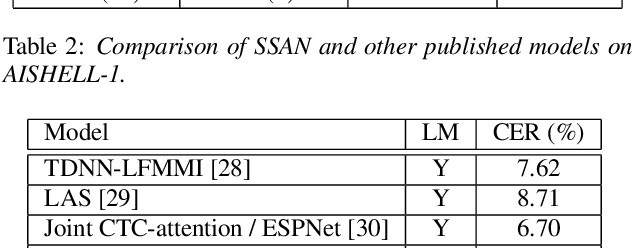
Transformer models have been introduced into end-to-end speech recognition with state-of-the-art performance on various tasks owing to their superiority in modeling long-term dependencies. However, such improvements are usually obtained through the use of very large neural networks. Transformer models mainly include two submodules - position-wise feedforward layers and self-attention (SAN) layers. In this paper, to reduce the model complexity while maintaining good performance, we propose a simplified self-attention (SSAN) layer which employs FSMN memory block instead of projection layers to form query and key vectors for transformer-based end-to-end speech recognition. We evaluate the SSAN-based and the conventional SAN-based transformers on the public AISHELL-1, internal 1000-hour and 20,000-hour large-scale Mandarin tasks. Results show that our proposed SSAN-based transformer model can achieve over 20% relative reduction in model parameters and 6.7% relative CER reduction on the AISHELL-1 task. With impressively 20% parameter reduction, our model shows no loss of recognition performance on the 20,000-hour large-scale task.
Cross-Modal Transformer-Based Neural Correction Models for Automatic Speech Recognition
Jul 04, 2021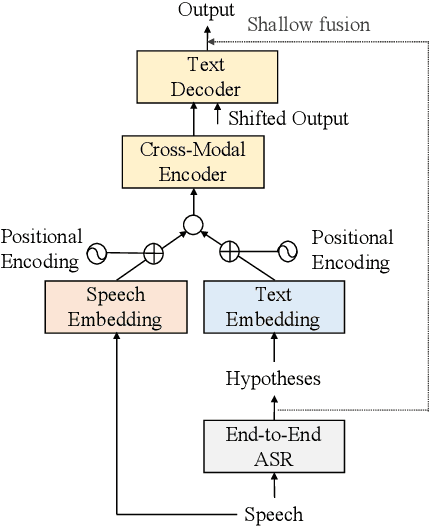
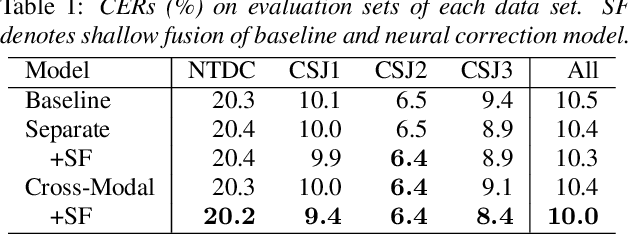
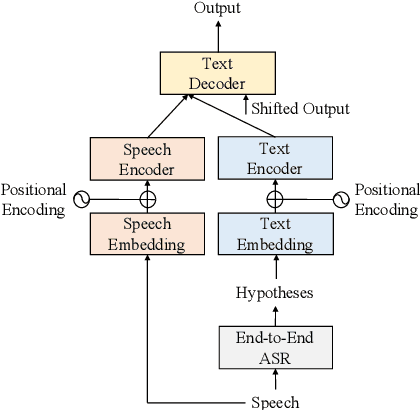
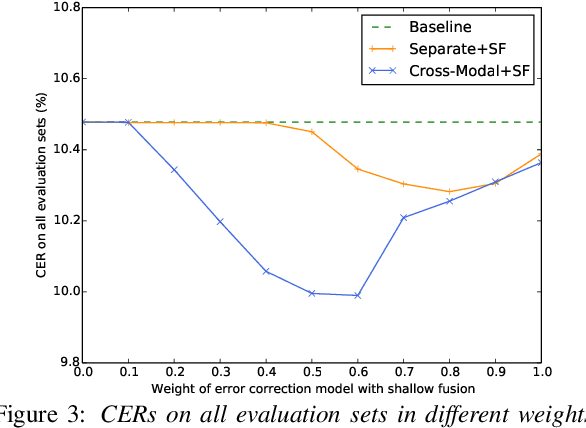
We propose a cross-modal transformer-based neural correction models that refines the output of an automatic speech recognition (ASR) system so as to exclude ASR errors. Generally, neural correction models are composed of encoder-decoder networks, which can directly model sequence-to-sequence mapping problems. The most successful method is to use both input speech and its ASR output text as the input contexts for the encoder-decoder networks. However, the conventional method cannot take into account the relationships between these two different modal inputs because the input contexts are separately encoded for each modal. To effectively leverage the correlated information between the two different modal inputs, our proposed models encode two different contexts jointly on the basis of cross-modal self-attention using a transformer. We expect that cross-modal self-attention can effectively capture the relationships between two different modals for refining ASR hypotheses. We also introduce a shallow fusion technique to efficiently integrate the first-pass ASR model and our proposed neural correction model. Experiments on Japanese natural language ASR tasks demonstrated that our proposed models achieve better ASR performance than conventional neural correction models.
Modality Attention for End-to-End Audio-visual Speech Recognition
Nov 13, 2018
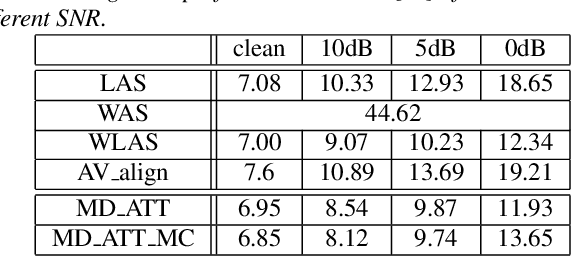
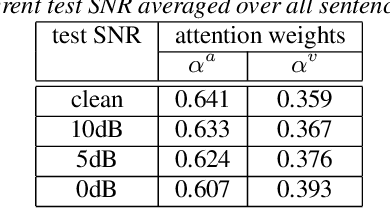
Audio-visual speech recognition (AVSR) system is thought to be one of the most promising solutions for robust speech recognition, especially in noisy environment. In this paper, we propose a novel multimodal attention based method for audio-visual speech recognition which could automatically learn the fused representation from both modalities based on their importance. Our method is realized using state-of-the-art sequence-to-sequence (Seq2seq) architectures. Experimental results show that relative improvements from 2% up to 36% over the auditory modality alone are obtained depending on the different signal-to-noise-ratio (SNR). Compared to the traditional feature concatenation methods, our proposed approach can achieve better recognition performance under both clean and noisy conditions. We believe modality attention based end-to-end method can be easily generalized to other multimodal tasks with correlated information.
Hierarchical Multitask Learning for CTC-based Speech Recognition
Jul 17, 2018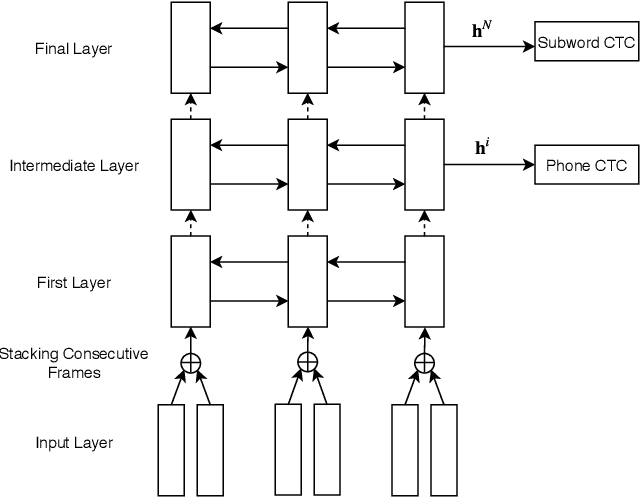
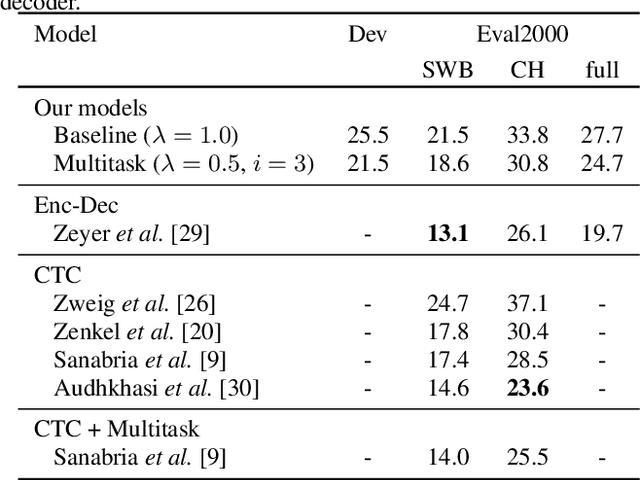
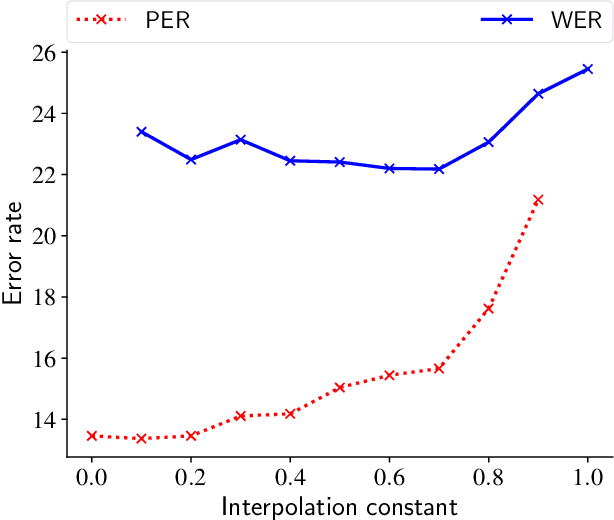
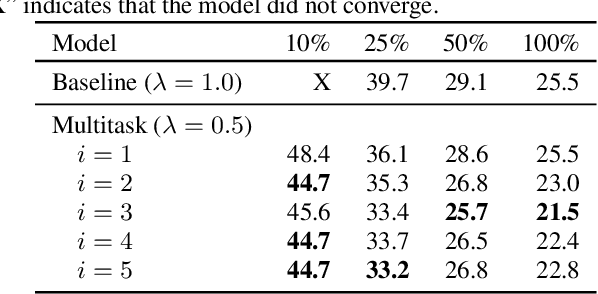
Previous work has shown that neural encoder-decoder speech recognition can be improved with hierarchical multitask learning, where auxiliary tasks are added at intermediate layers of a deep encoder. We explore the effect of hierarchical multitask learning in the context of connectionist temporal classification (CTC)-based speech recognition, and investigate several aspects of this approach. Consistent with previous work, we observe performance improvements on telephone conversational speech recognition (specifically the Eval2000 test sets) when training a subword-level CTC model with an auxiliary phone loss at an intermediate layer. We analyze the effects of a number of experimental variables (like interpolation constant and position of the auxiliary loss function), performance in lower-resource settings, and the relationship between pretraining and multitask learning. We observe that the hierarchical multitask approach improves over standard multitask training in our higher-data experiments, while in the low-resource settings standard multitask training works well. The best results are obtained by combining hierarchical multitask learning and pretraining, which improves word error rates by 3.4% absolute on the Eval2000 test sets.