 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
EURO: ESPnet Unsupervised ASR Open-source Toolkit
Dec 01, 2022
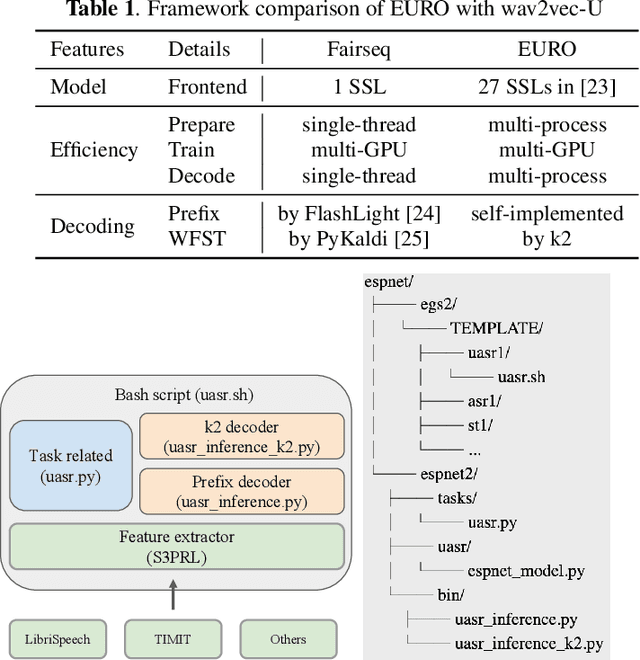
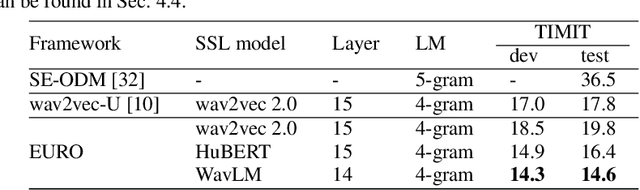

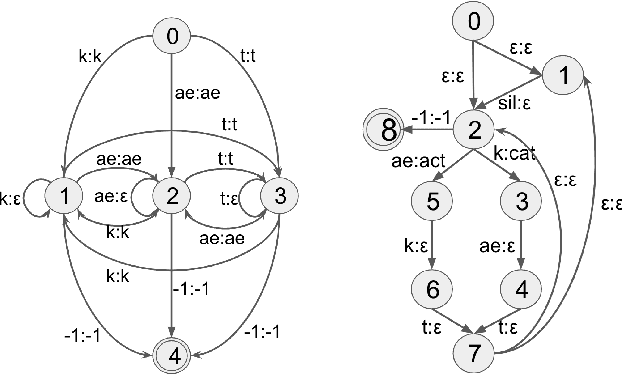
This paper describes the ESPnet Unsupervised ASR Open-source Toolkit (EURO), an end-to-end open-source toolkit for unsupervised automatic speech recognition (UASR). EURO adopts the state-of-the-art UASR learning method introduced by the Wav2vec-U, originally implemented at FAIRSEQ, which leverages self-supervised speech representations and adversarial training. In addition to wav2vec2, EURO extends the functionality and promotes reproducibility for UASR tasks by integrating S3PRL and k2, resulting in flexible frontends from 27 self-supervised models and various graph-based decoding strategies. EURO is implemented in ESPnet and follows its unified pipeline to provide UASR recipes with a complete setup. This improves the pipeline's efficiency and allows EURO to be easily applied to existing datasets in ESPnet. Extensive experiments on three mainstream self-supervised models demonstrate the toolkit's effectiveness and achieve state-of-the-art UASR performance on TIMIT and LibriSpeech datasets. EURO will be publicly available at https://github.com/espnet/espnet, aiming to promote this exciting and emerging research area based on UASR through open-source activity.
BRENT: Bidirectional Retrieval Enhanced Norwegian Transformer
Apr 19, 2023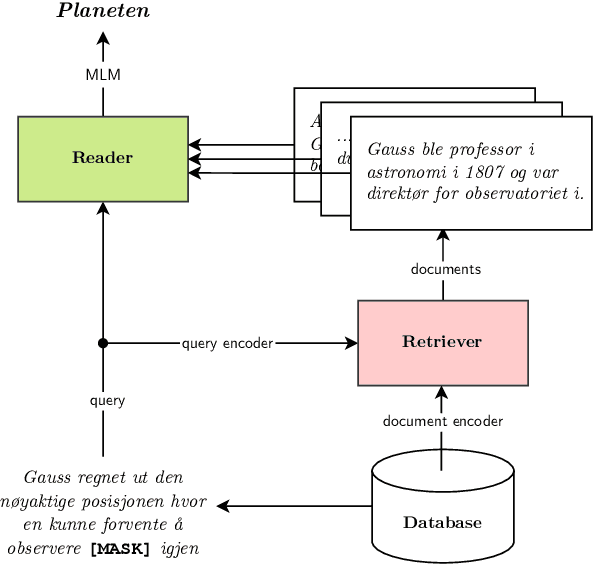
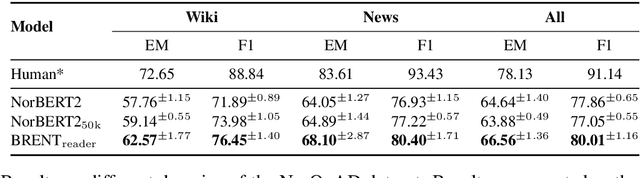
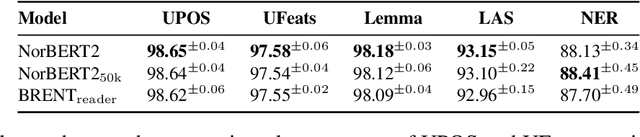
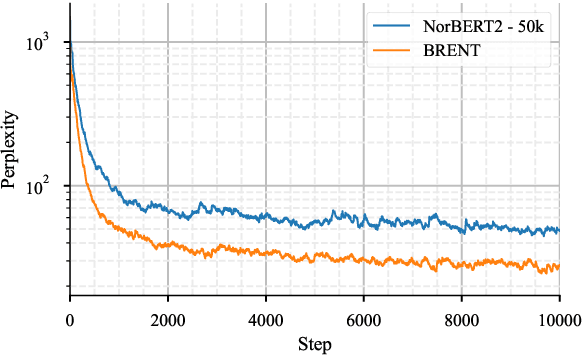
Retrieval-based language models are increasingly employed in question-answering tasks. These models search in a corpus of documents for relevant information instead of having all factual knowledge stored in its parameters, thereby enhancing efficiency, transparency, and adaptability. We develop the first Norwegian retrieval-based model by adapting the REALM framework and evaluating it on various tasks. After training, we also separate the language model, which we call the reader, from the retriever components, and show that this can be fine-tuned on a range of downstream tasks. Results show that retrieval augmented language modeling improves the reader's performance on extractive question-answering, suggesting that this type of training improves language models' general ability to use context and that this does not happen at the expense of other abilities such as part-of-speech tagging, dependency parsing, named entity recognition, and lemmatization. Code, trained models, and data are made publicly available.
Time-frequency Network for Robust Speaker Recognition
Mar 07, 2023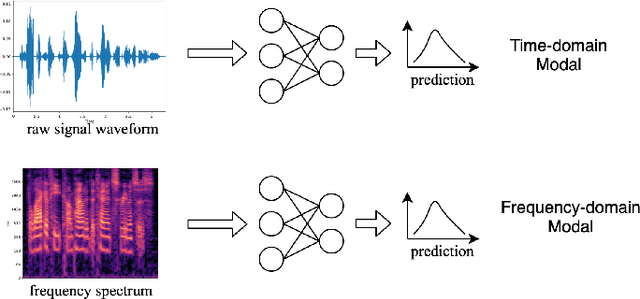
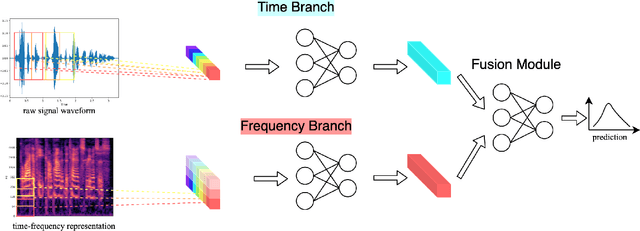
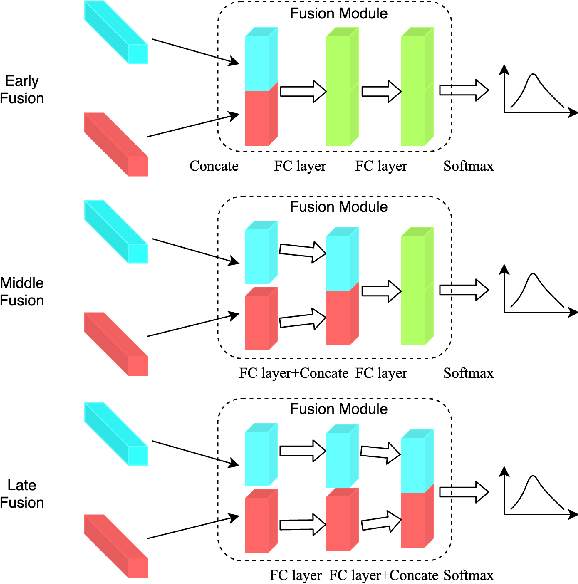
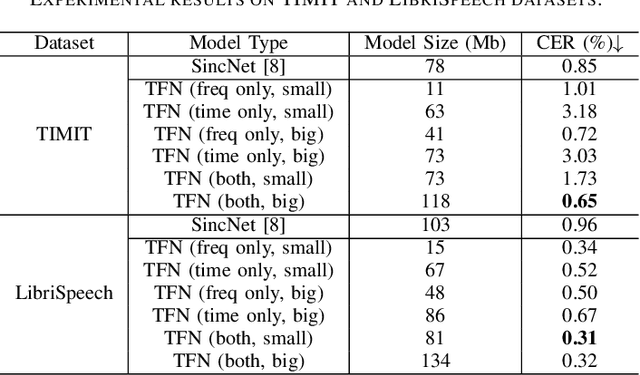
The wide deployment of speech-based biometric systems usually demands high-performance speaker recognition algorithms. However, most of the prior works for speaker recognition either process the speech in the frequency domain or time domain, which may produce suboptimal results because both time and frequency domains are important for speaker recognition. In this paper, we attempt to analyze the speech signal in both time and frequency domains and propose the time-frequency network~(TFN) for speaker recognition by extracting and fusing the features in the two domains. Based on the recent advance of deep neural networks, we propose a convolution neural network to encode the raw speech waveform and the frequency spectrum into domain-specific features, which are then fused and transformed into a classification feature space for speaker recognition. Experimental results on the publicly available datasets TIMIT and LibriSpeech show that our framework is effective to combine the information in the two domains and performs better than the state-of-the-art methods for speaker recognition.
SpeechFormer++: A Hierarchical Efficient Framework for Paralinguistic Speech Processing
Feb 27, 2023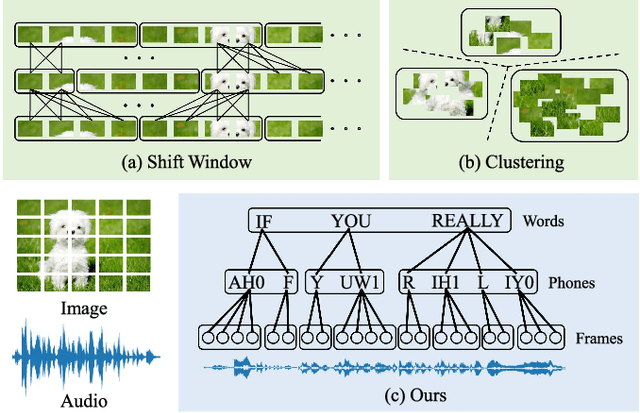
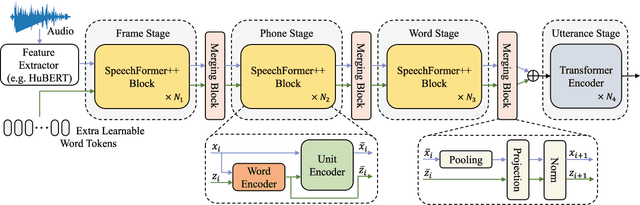
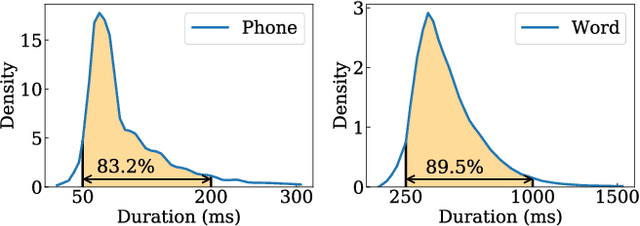
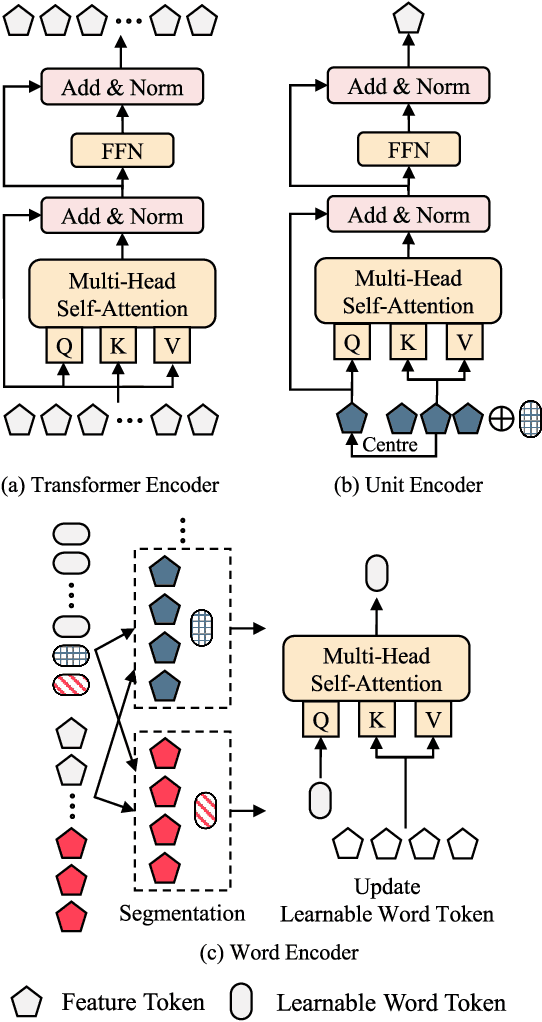
Paralinguistic speech processing is important in addressing many issues, such as sentiment and neurocognitive disorder analyses. Recently, Transformer has achieved remarkable success in the natural language processing field and has demonstrated its adaptation to speech. However, previous works on Transformer in the speech field have not incorporated the properties of speech, leaving the full potential of Transformer unexplored. In this paper, we consider the characteristics of speech and propose a general structure-based framework, called SpeechFormer++, for paralinguistic speech processing. More concretely, following the component relationship in the speech signal, we design a unit encoder to model the intra- and inter-unit information (i.e., frames, phones, and words) efficiently. According to the hierarchical relationship, we utilize merging blocks to generate features at different granularities, which is consistent with the structural pattern in the speech signal. Moreover, a word encoder is introduced to integrate word-grained features into each unit encoder, which effectively balances fine-grained and coarse-grained information. SpeechFormer++ is evaluated on the speech emotion recognition (IEMOCAP & MELD), depression classification (DAIC-WOZ) and Alzheimer's disease detection (Pitt) tasks. The results show that SpeechFormer++ outperforms the standard Transformer while greatly reducing the computational cost. Furthermore, it delivers superior results compared to the state-of-the-art approaches.
Improving Speech-to-Speech Translation Through Unlabeled Text
Oct 26, 2022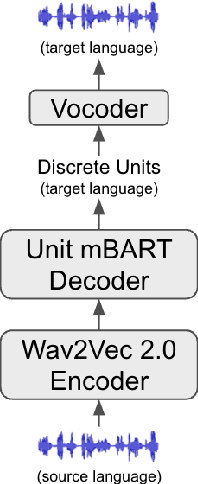
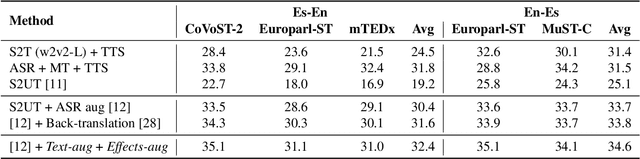
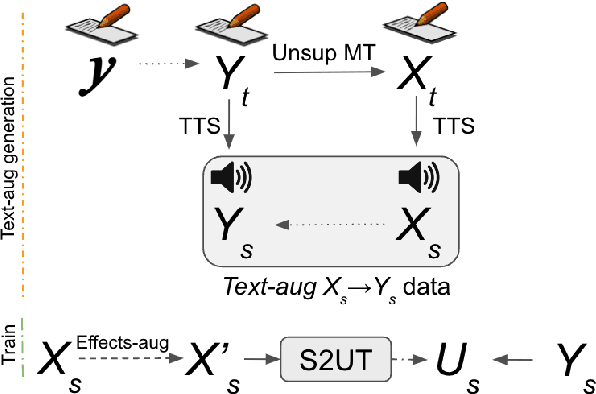
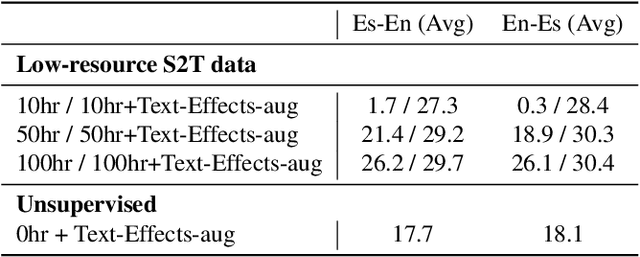
Direct speech-to-speech translation (S2ST) is among the most challenging problems in the translation paradigm due to the significant scarcity of S2ST data. While effort has been made to increase the data size from unlabeled speech by cascading pretrained speech recognition (ASR), machine translation (MT) and text-to-speech (TTS) models; unlabeled text has remained relatively under-utilized to improve S2ST. We propose an effective way to utilize the massive existing unlabeled text from different languages to create a large amount of S2ST data to improve S2ST performance by applying various acoustic effects to the generated synthetic data. Empirically our method outperforms the state of the art in Spanish-English translation by up to 2 BLEU. Significant gains by the proposed method are demonstrated in extremely low-resource settings for both Spanish-English and Russian-English translations.
Adapting GPT, GPT-2 and BERT Language Models for Speech Recognition
Jul 29, 2021
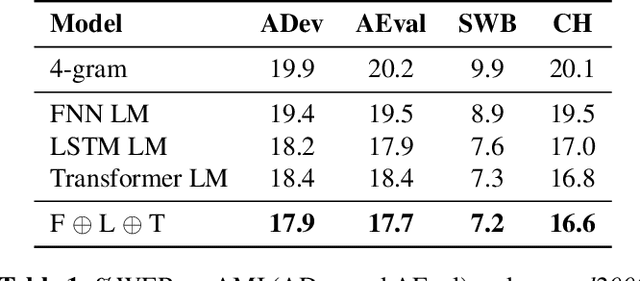
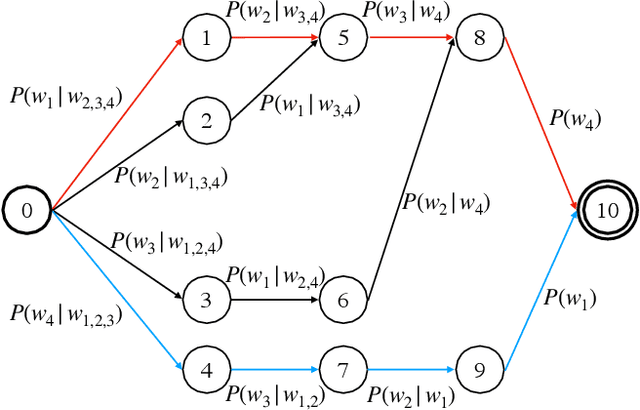
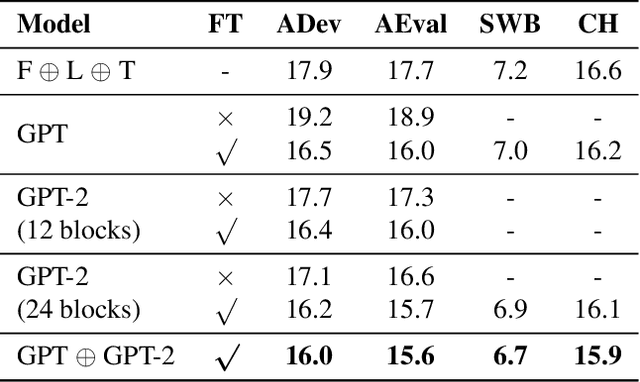
Language models (LMs) pre-trained on massive amounts of text, in particular bidirectional encoder representations from Transformers (BERT), generative pre-training (GPT), and GPT-2, have become a key technology for many natural language processing tasks. In this paper, we present results using fine-tuned GPT, GPT-2, and their combination for automatic speech recognition (ASR). Unlike unidirectional LM GPT and GPT-2, BERT is bidirectional whose direct product of the output probabilities is no longer a valid language prior probability. A conversion method is proposed to compute the correct language prior probability based on bidirectional LM outputs in a mathematically exact way. Experimental results on the widely used AMI and Switchboard ASR tasks showed that the combination of the fine-tuned GPT and GPT-2 outperformed the combination of three neural LMs with different architectures trained from scratch on the in-domain text by up to a 12% relative word error rate reduction (WERR). Furthermore, the proposed conversion for language prior probabilities enables BERT to receive an extra 3% relative WERR, and the combination of BERT, GPT and GPT-2 results in further improvements.
Brouhaha: multi-task training for voice activity detection, speech-to-noise ratio, and C50 room acoustics estimation
Oct 27, 2022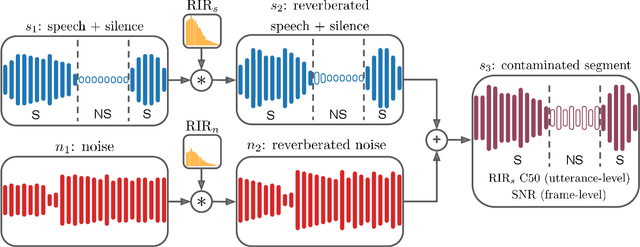
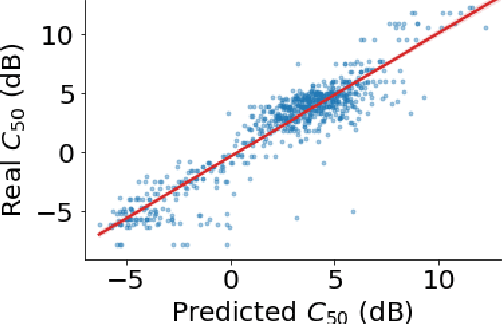
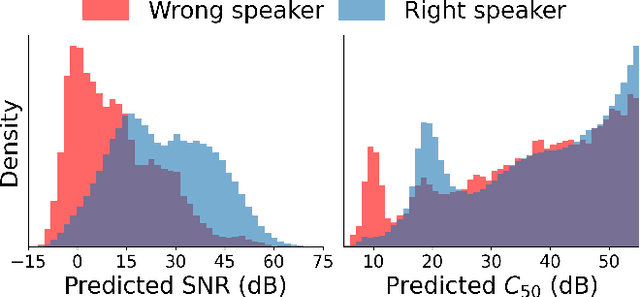
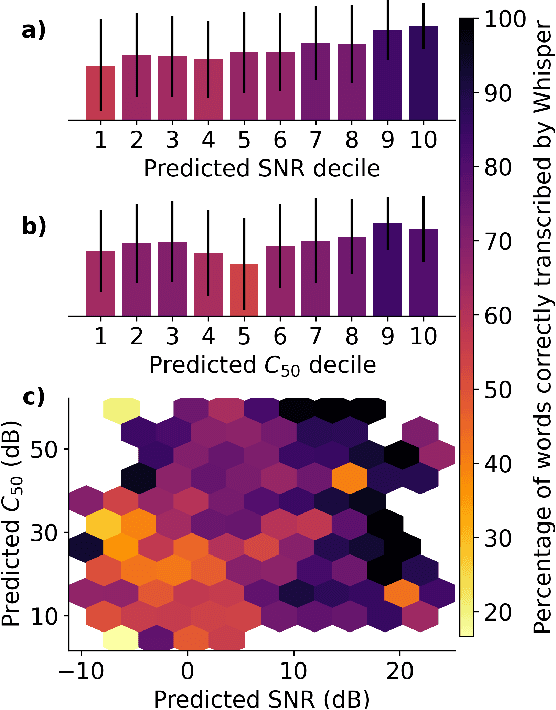
Most automatic speech processing systems are sensitive to the acoustic environment, with degraded performance when applied to noisy or reverberant speech. But how can one tell whether speech is noisy or reverberant? We propose Brouhaha, a pipeline to simulate audio segments recorded in noisy and reverberant conditions. We then use the simulated audio to jointly train the Brouhaha model for voice activity detection, signal-to-noise ratio estimation, and C50 room acoustics prediction. We show how the predicted SNR and C50 values can be used to investigate and help diagnose errors made by automatic speech processing tools (such as pyannote.audio for speaker diarization or OpenAI's Whisper for automatic speech recognition). Both our pipeline and a pretrained model are open source and shared with the speech community.
The Role of Phonetic Units in Speech Emotion Recognition
Aug 02, 2021
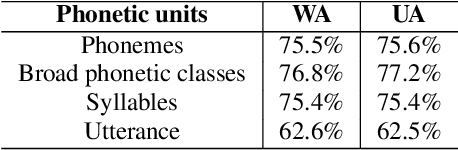
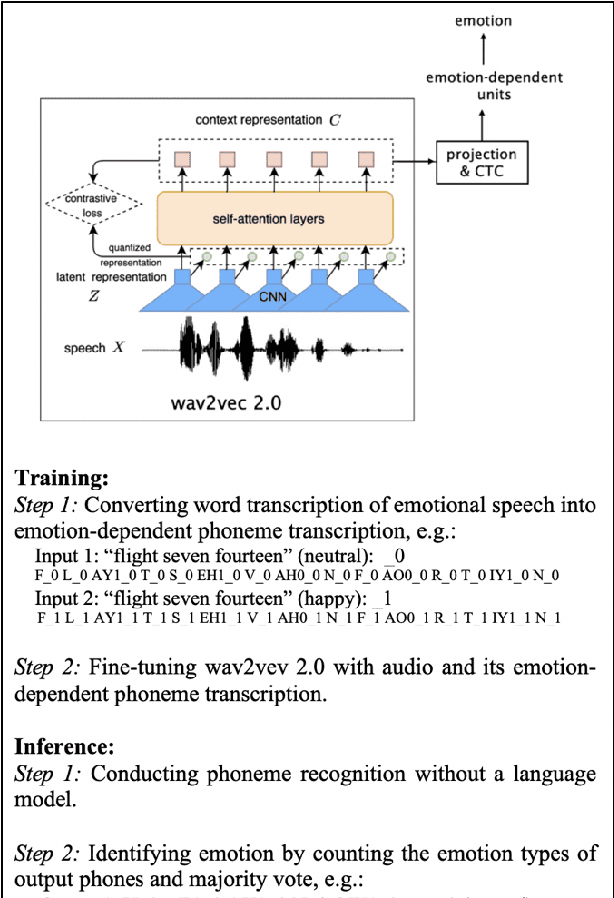
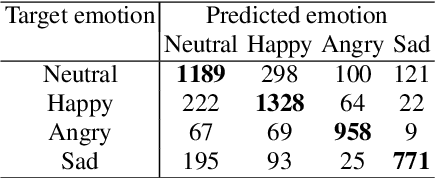
We propose a method for emotion recognition through emotiondependent speech recognition using Wav2vec 2.0. Our method achieved a significant improvement over most previously reported results on IEMOCAP, a benchmark emotion dataset. Different types of phonetic units are employed and compared in terms of accuracy and robustness of emotion recognition within and across datasets and languages. Models of phonemes, broad phonetic classes, and syllables all significantly outperform the utterance model, demonstrating that phonetic units are helpful and should be incorporated in speech emotion recognition. The best performance is from using broad phonetic classes. Further research is needed to investigate the optimal set of broad phonetic classes for the task of emotion recognition. Finally, we found that Wav2vec 2.0 can be fine-tuned to recognize coarser-grained or larger phonetic units than phonemes, such as broad phonetic classes and syllables.
Massively Multilingual Adversarial Speech Recognition
Apr 03, 2019
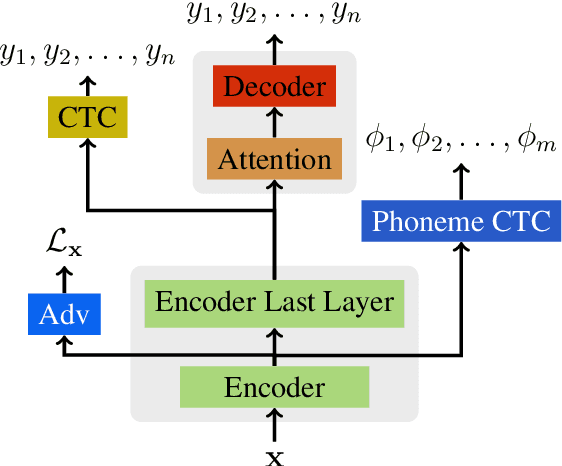
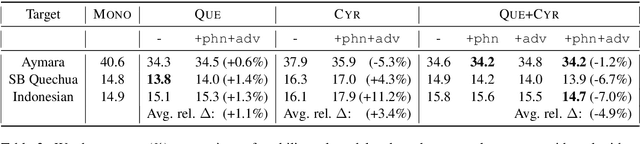

We report on adaptation of multilingual end-to-end speech recognition models trained on as many as 100 languages. Our findings shed light on the relative importance of similarity between the target and pretraining languages along the dimensions of phonetics, phonology, language family, geographical location, and orthography. In this context, experiments demonstrate the effectiveness of two additional pretraining objectives in encouraging language-independent encoder representations: a context-independent phoneme objective paired with a language-adversarial classification objective.
End-to-End Speech to Intent Prediction to improve E-commerce Customer Support Voicebot in Hindi and English
Oct 26, 2022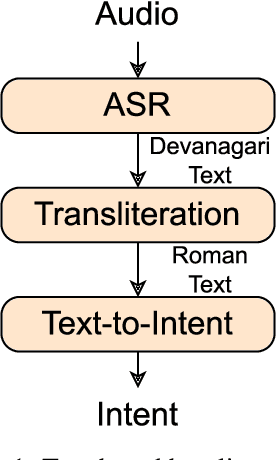

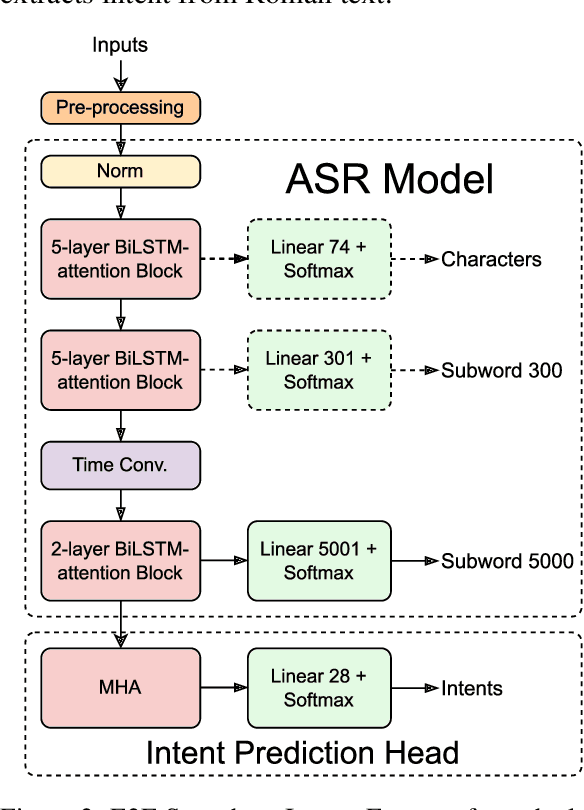
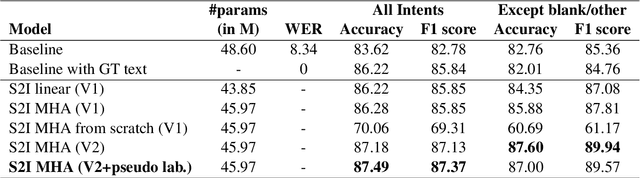
Automation of on-call customer support relies heavily on accurate and efficient speech-to-intent (S2I) systems. Building such systems using multi-component pipelines can pose various challenges because they require large annotated datasets, have higher latency, and have complex deployment. These pipelines are also prone to compounding errors. To overcome these challenges, we discuss an end-to-end (E2E) S2I model for customer support voicebot task in a bilingual setting. We show how we can solve E2E intent classification by leveraging a pre-trained automatic speech recognition (ASR) model with slight modification and fine-tuning on small annotated datasets. Experimental results show that our best E2E model outperforms a conventional pipeline by a relative ~27% on the F1 score.