 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Learning to Count Words in Fluent Speech enables Online Speech Recognition
Jun 11, 2020
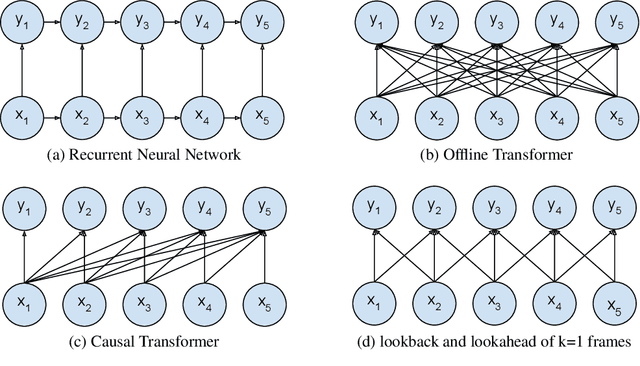

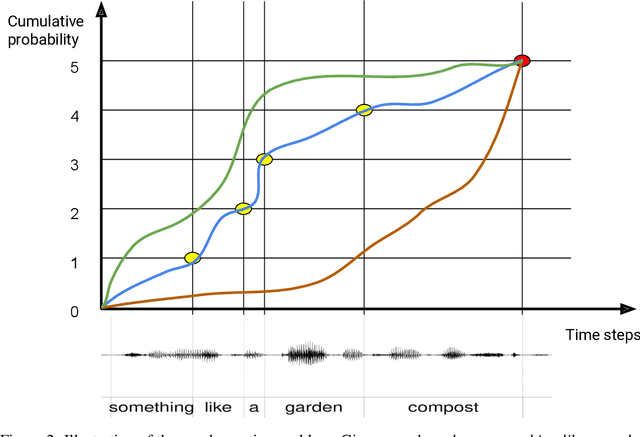
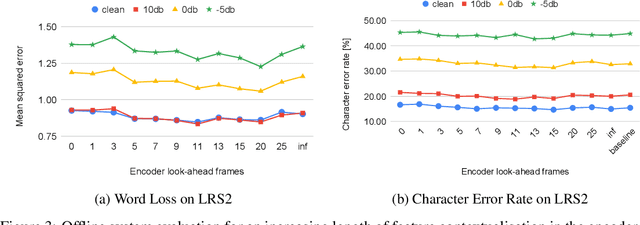
Sequence to Sequence models, in particular the Transformer, achieve state of the art results in Automatic Speech Recognition. Practical usage is however limited to cases where full utterance latency is acceptable. In this work we introduce Taris, a Transformer-based online speech recognition system aided by an auxiliary task of incremental word counting. We use the cumulative word sum to dynamically segment speech and enable its eager decoding into words. Experiments performed on the LRS2 and LibriSpeech datasets, of unconstrained and read speech respectively, show that the online system performs on a par with the offline one, while having a dynamic algorithmic delay of 5 segments. Furthermore, we show that the estimated segment length distribution resembles the word length distribution obtained with forced alignment, although our system does not require an exact segment-to-word equivalence. Taris introduces a negligible overhead compared to a standard Transformer, while the local relationship modelling between inputs and outputs grants invariance to sequence length by design.
RT-1: Robotics Transformer for Real-World Control at Scale
Dec 13, 2022



By transferring knowledge from large, diverse, task-agnostic datasets, modern machine learning models can solve specific downstream tasks either zero-shot or with small task-specific datasets to a high level of performance. While this capability has been demonstrated in other fields such as computer vision, natural language processing or speech recognition, it remains to be shown in robotics, where the generalization capabilities of the models are particularly critical due to the difficulty of collecting real-world robotic data. We argue that one of the keys to the success of such general robotic models lies with open-ended task-agnostic training, combined with high-capacity architectures that can absorb all of the diverse, robotic data. In this paper, we present a model class, dubbed Robotics Transformer, that exhibits promising scalable model properties. We verify our conclusions in a study of different model classes and their ability to generalize as a function of the data size, model size, and data diversity based on a large-scale data collection on real robots performing real-world tasks. The project's website and videos can be found at robotics-transformer.github.io
Transformer Based Deliberation for Two-Pass Speech Recognition
Jan 27, 2021
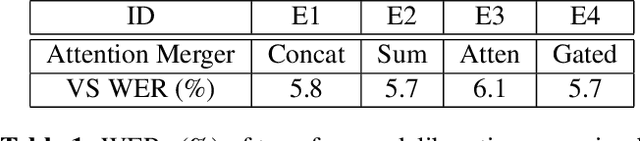
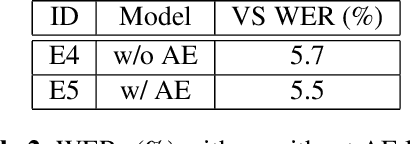
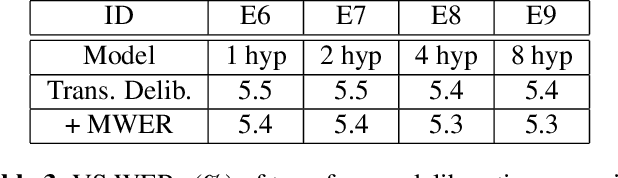
Interactive speech recognition systems must generate words quickly while also producing accurate results. Two-pass models excel at these requirements by employing a first-pass decoder that quickly emits words, and a second-pass decoder that requires more context but is more accurate. Previous work has established that a deliberation network can be an effective second-pass model. The model attends to two kinds of inputs at once: encoded audio frames and the hypothesis text from the first-pass model. In this work, we explore using transformer layers instead of long-short term memory (LSTM) layers for deliberation rescoring. In transformer layers, we generalize the "encoder-decoder" attention to attend to both encoded audio and first-pass text hypotheses. The output context vectors are then combined by a merger layer. Compared to LSTM-based deliberation, our best transformer deliberation achieves 7% relative word error rate improvements along with a 38% reduction in computation. We also compare against non-deliberation transformer rescoring, and find a 9% relative improvement.
Improving Confidence Estimation on Out-of-Domain Data for End-to-End Speech Recognition
Oct 07, 2021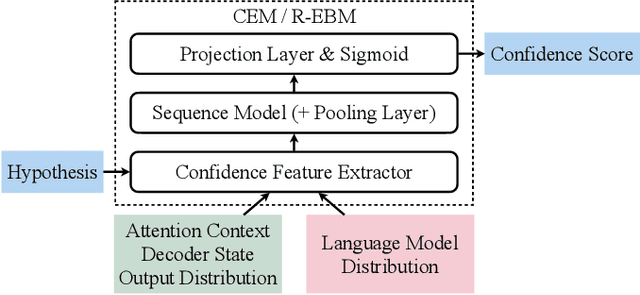
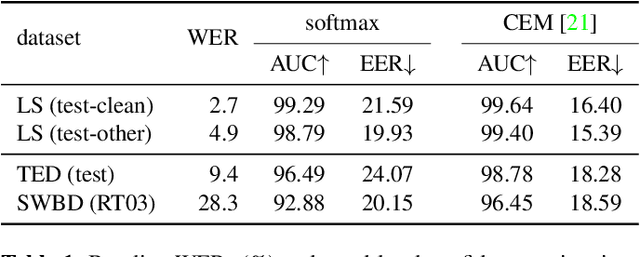
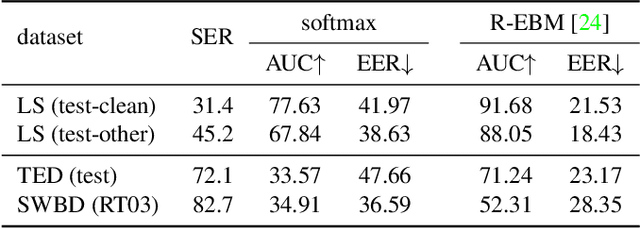
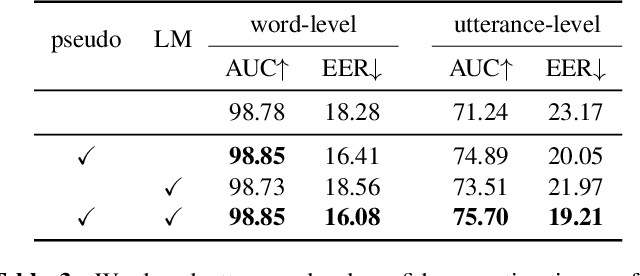
As end-to-end automatic speech recognition (ASR) models reach promising performance, various downstream tasks rely on good confidence estimators for these systems. Recent research has shown that model-based confidence estimators have a significant advantage over using the output softmax probabilities. If the input data to the speech recogniser is from mismatched acoustic and linguistic conditions, the ASR performance and the corresponding confidence estimators may exhibit severe degradation. Since confidence models are often trained on the same in-domain data as the ASR, generalising to out-of-domain (OOD) scenarios is challenging. By keeping the ASR model untouched, this paper proposes two approaches to improve the model-based confidence estimators on OOD data: using pseudo transcriptions and an additional OOD language model. With an ASR model trained on LibriSpeech, experiments show that the proposed methods can significantly improve the confidence metrics on TED-LIUM and Switchboard datasets while preserving in-domain performance. Furthermore, the improved confidence estimators are better calibrated on OOD data and can provide a much more reliable criterion for data selection.
Exploring WavLM on Speech Enhancement
Nov 18, 2022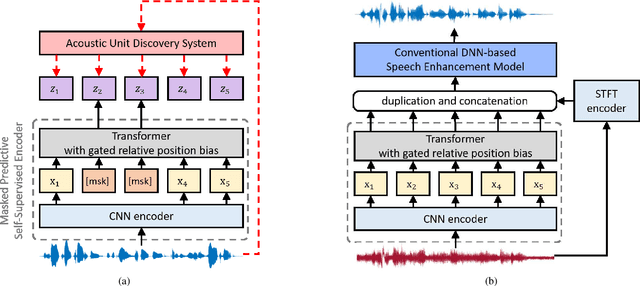
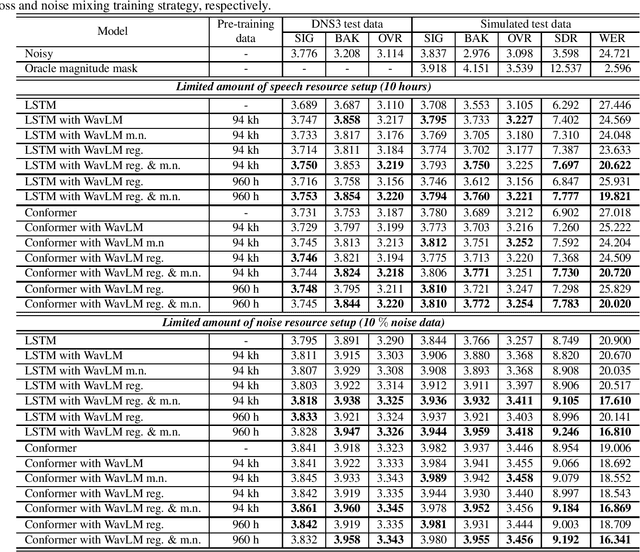
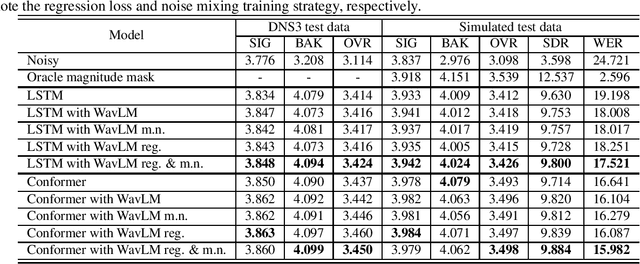
There is a surge in interest in self-supervised learning approaches for end-to-end speech encoding in recent years as they have achieved great success. Especially, WavLM showed state-of-the-art performance on various speech processing tasks. To better understand the efficacy of self-supervised learning models for speech enhancement, in this work, we design and conduct a series of experiments with three resource conditions by combining WavLM and two high-quality speech enhancement systems. Also, we propose a regression-based WavLM training objective and a noise-mixing data configuration to further boost the downstream enhancement performance. The experiments on the DNS challenge dataset and a simulation dataset show that the WavLM benefits the speech enhancement task in terms of both speech quality and speech recognition accuracy, especially for low fine-tuning resources. For the high fine-tuning resource condition, only the word error rate is substantially improved.
Dysfluencies Seldom Come Alone -- Detection as a Multi-Label Problem
Oct 28, 2022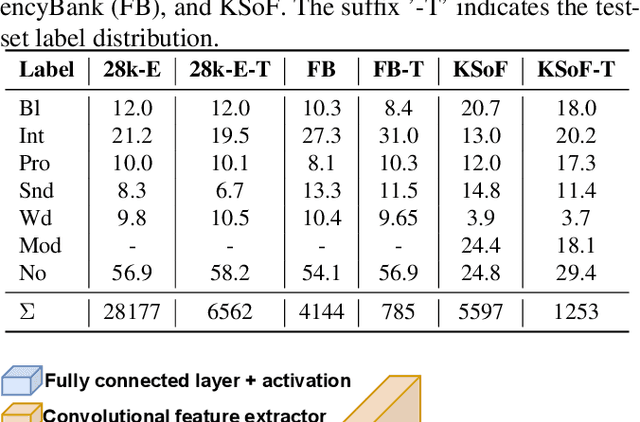
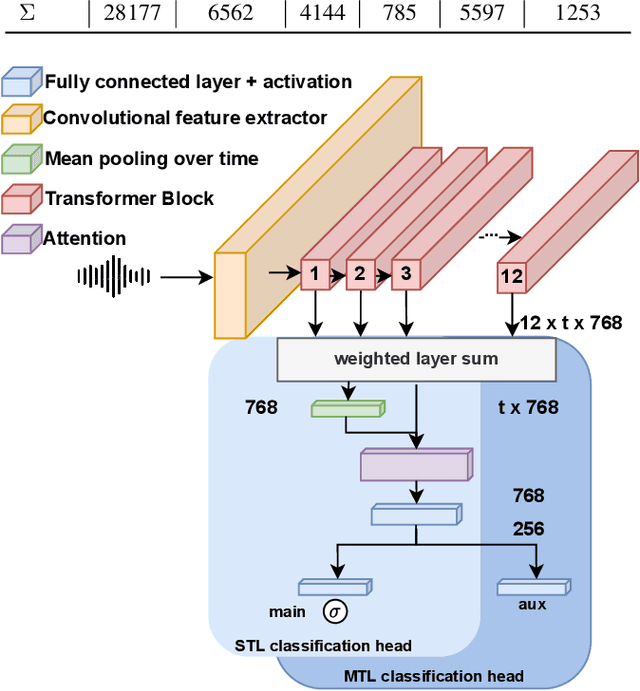
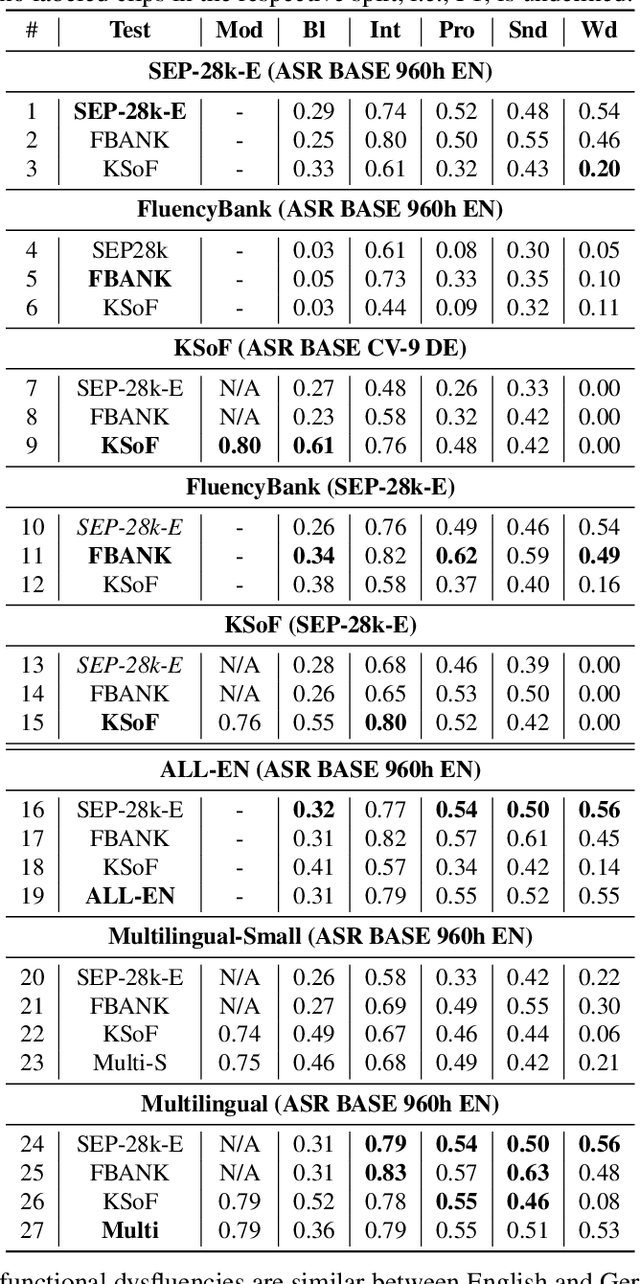
Specially adapted speech recognition models are necessary to handle stuttered speech. For these to be used in a targeted manner, stuttered speech must be reliably detected. Recent works have treated stuttering as a multi-class classification problem or viewed detecting each dysfluency type as an isolated task; that does not capture the nature of stuttering, where one dysfluency seldom comes alone, i.e., co-occurs with others. This work explores an approach based on a modified wav2vec 2.0 system for end-to-end stuttering detection and classification as a multi-label problem. The method is evaluated on combinations of three datasets containing English and German stuttered speech, yielding state-of-the-art results for stuttering detection on the SEP-28k-Extended dataset. Experimental results provide evidence for the transferability of features and the generalizability of the method across datasets and languages.
Neural Architecture Search for Speech Emotion Recognition
Mar 31, 2022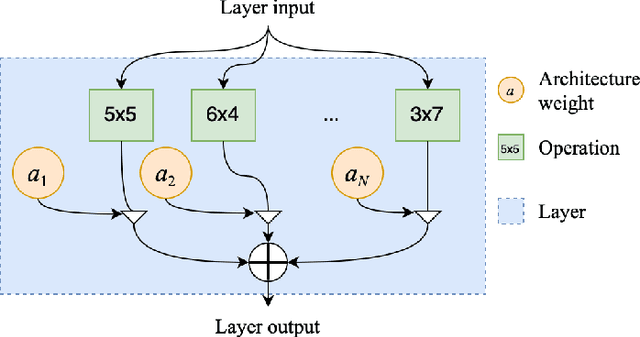
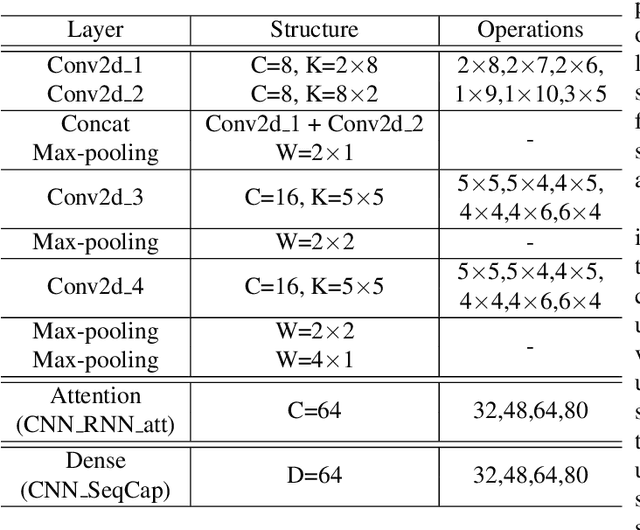
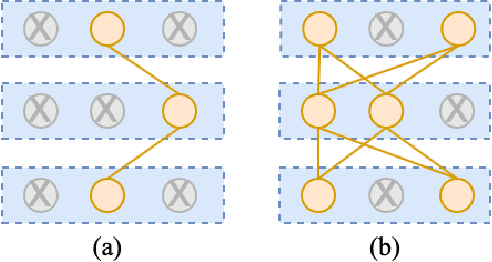
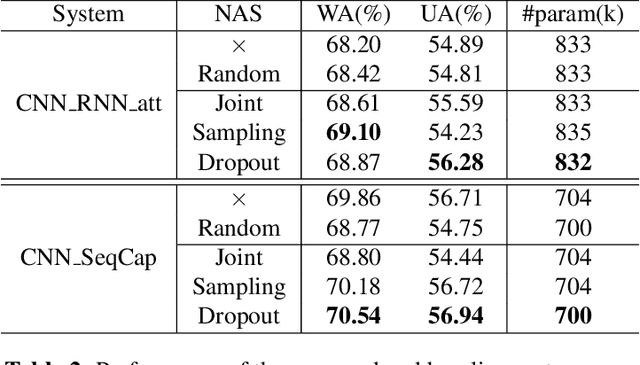
Deep neural networks have brought significant advancements to speech emotion recognition (SER). However, the architecture design in SER is mainly based on expert knowledge and empirical (trial-and-error) evaluations, which is time-consuming and resource intensive. In this paper, we propose to apply neural architecture search (NAS) techniques to automatically configure the SER models. To accelerate the candidate architecture optimization, we propose a uniform path dropout strategy to encourage all candidate architecture operations to be equally optimized. Experimental results of two different neural structures on IEMOCAP show that NAS can improve SER performance (54.89\% to 56.28\%) while maintaining model parameter sizes. The proposed dropout strategy also shows superiority over the previous approaches.
Unsupervised Fine-Tuning Data Selection for ASR Using Self-Supervised Speech Models
Dec 03, 2022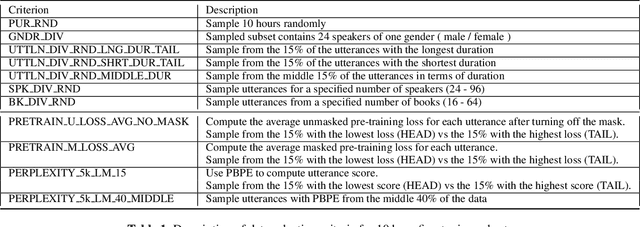
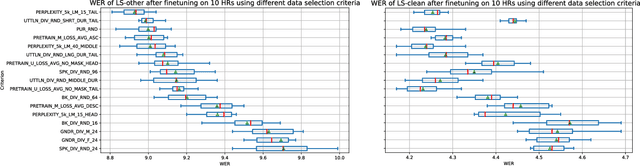
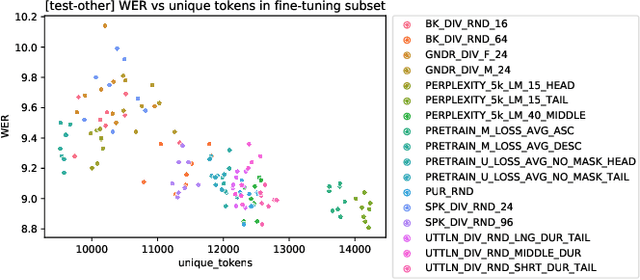

Self-supervised learning (SSL) has been able to leverage unlabeled data to boost the performance of automatic speech recognition (ASR) models when we have access to only a small amount of transcribed speech data. However, this raises the question of which subset of the available unlabeled data should be selected for transcription. Our work investigates different unsupervised data selection techniques for fine-tuning the HuBERT model under a limited transcription budget. We investigate the impact of speaker diversity, gender bias, and topic diversity on the downstream ASR performance. We also devise two novel techniques for unsupervised data selection: pre-training loss based data selection and the perplexity of byte pair encoded clustered units (PBPE) and we show how these techniques compare to pure random data selection. Finally, we analyze the correlations between the inherent characteristics of the selected fine-tuning subsets as well as how these characteristics correlate with the resultant word error rate. We demonstrate the importance of token diversity, speaker diversity, and topic diversity in achieving the best performance in terms of WER.
Device Directedness with Contextual Cues for Spoken Dialog Systems
Nov 23, 2022
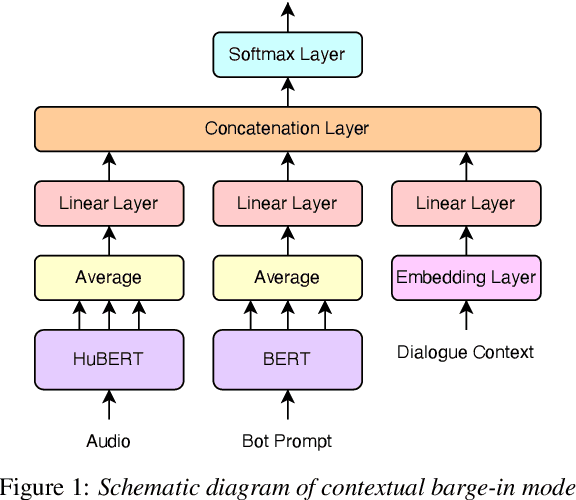
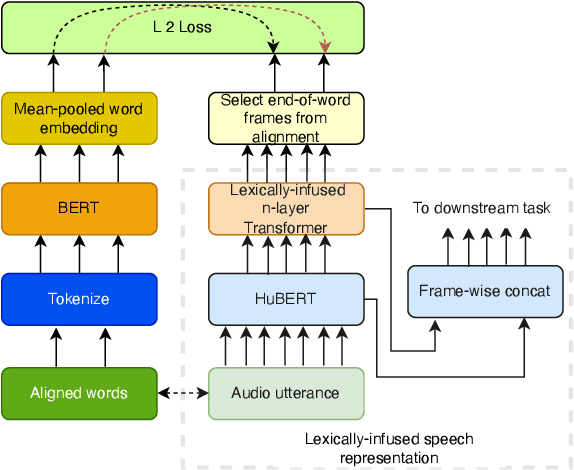
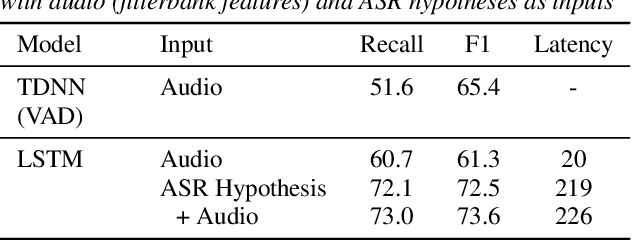
In this work, we define barge-in verification as a supervised learning task where audio-only information is used to classify user spoken dialogue into true and false barge-ins. Following the success of pre-trained models, we use low-level speech representations from a self-supervised representation learning model for our downstream classification task. Further, we propose a novel technique to infuse lexical information directly into speech representations to improve the domain-specific language information implicitly learned during pre-training. Experiments conducted on spoken dialog data show that our proposed model trained to validate barge-in entirely from speech representations is faster by 38% relative and achieves 4.5% relative F1 score improvement over a baseline LSTM model that uses both audio and Automatic Speech Recognition (ASR) 1-best hypotheses. On top of this, our best proposed model with lexically infused representations along with contextual features provides a further relative improvement of 5.7% in the F1 score but only 22% faster than the baseline.
Simulating realistic speech overlaps improves multi-talker ASR
Nov 17, 2022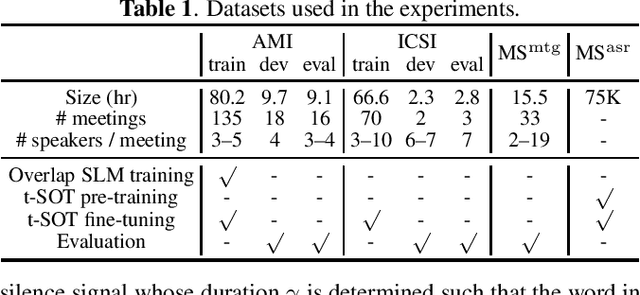
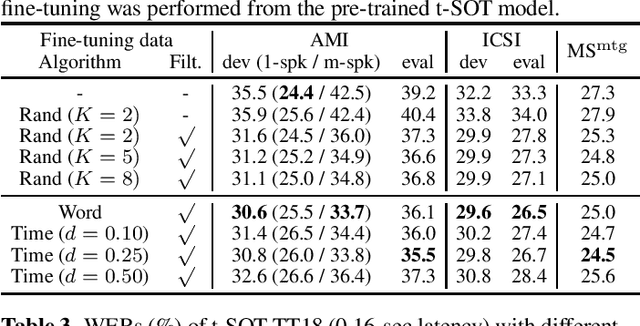

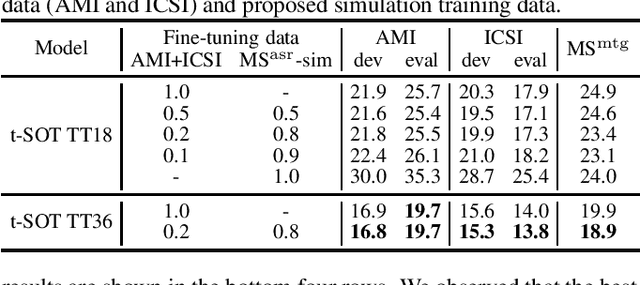
Multi-talker automatic speech recognition (ASR) has been studied to generate transcriptions of natural conversation including overlapping speech of multiple speakers. Due to the difficulty in acquiring real conversation data with high-quality human transcriptions, a na\"ive simulation of multi-talker speech by randomly mixing multiple utterances was conventionally used for model training. In this work, we propose an improved technique to simulate multi-talker overlapping speech with realistic speech overlaps, where an arbitrary pattern of speech overlaps is represented by a sequence of discrete tokens. With this representation, speech overlapping patterns can be learned from real conversations based on a statistical language model, such as N-gram, which can be then used to generate multi-talker speech for training. In our experiments, multi-talker ASR models trained with the proposed method show consistent improvement on the word error rates across multiple datasets.