 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Unsupervised Fine-Tuning Data Selection for ASR Using Self-Supervised Speech Models
Dec 03, 2022
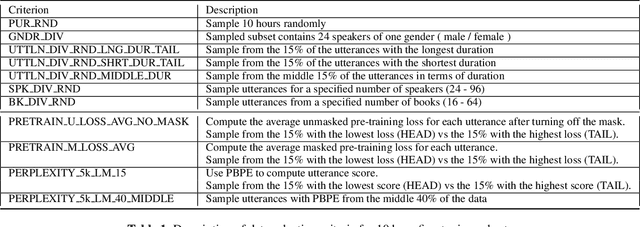
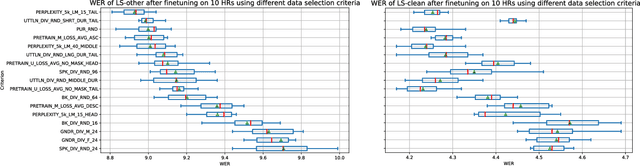
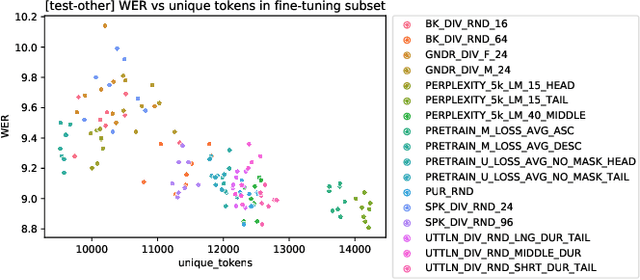

Self-supervised learning (SSL) has been able to leverage unlabeled data to boost the performance of automatic speech recognition (ASR) models when we have access to only a small amount of transcribed speech data. However, this raises the question of which subset of the available unlabeled data should be selected for transcription. Our work investigates different unsupervised data selection techniques for fine-tuning the HuBERT model under a limited transcription budget. We investigate the impact of speaker diversity, gender bias, and topic diversity on the downstream ASR performance. We also devise two novel techniques for unsupervised data selection: pre-training loss based data selection and the perplexity of byte pair encoded clustered units (PBPE) and we show how these techniques compare to pure random data selection. Finally, we analyze the correlations between the inherent characteristics of the selected fine-tuning subsets as well as how these characteristics correlate with the resultant word error rate. We demonstrate the importance of token diversity, speaker diversity, and topic diversity in achieving the best performance in terms of WER.
Device Directedness with Contextual Cues for Spoken Dialog Systems
Nov 23, 2022
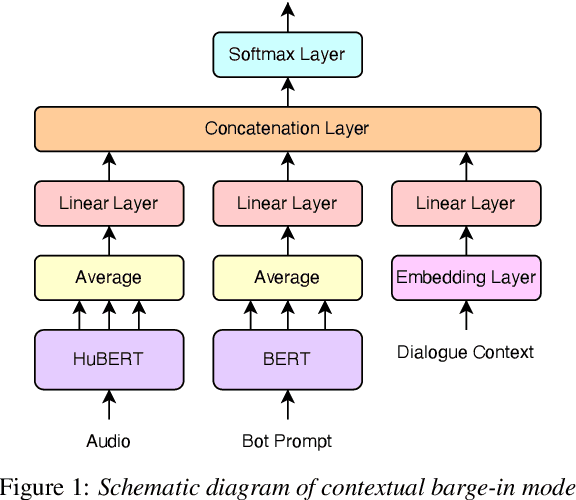
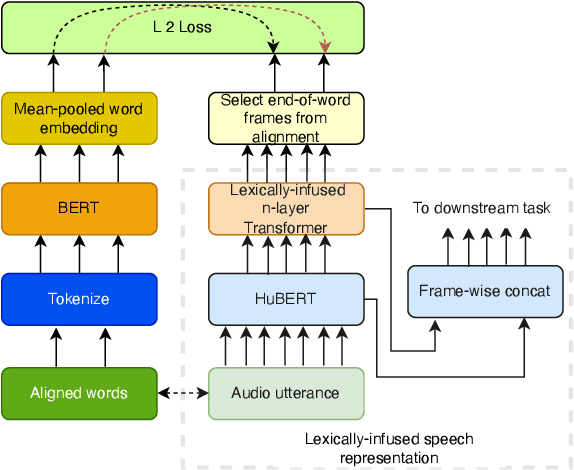
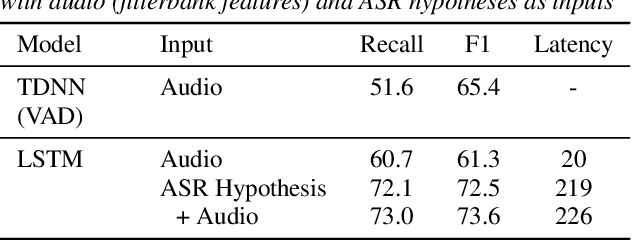
In this work, we define barge-in verification as a supervised learning task where audio-only information is used to classify user spoken dialogue into true and false barge-ins. Following the success of pre-trained models, we use low-level speech representations from a self-supervised representation learning model for our downstream classification task. Further, we propose a novel technique to infuse lexical information directly into speech representations to improve the domain-specific language information implicitly learned during pre-training. Experiments conducted on spoken dialog data show that our proposed model trained to validate barge-in entirely from speech representations is faster by 38% relative and achieves 4.5% relative F1 score improvement over a baseline LSTM model that uses both audio and Automatic Speech Recognition (ASR) 1-best hypotheses. On top of this, our best proposed model with lexically infused representations along with contextual features provides a further relative improvement of 5.7% in the F1 score but only 22% faster than the baseline.
Fast End-to-End Speech Recognition via a Non-Autoregressive Model and Cross-Modal Knowledge Transferring from BERT
Feb 16, 2021
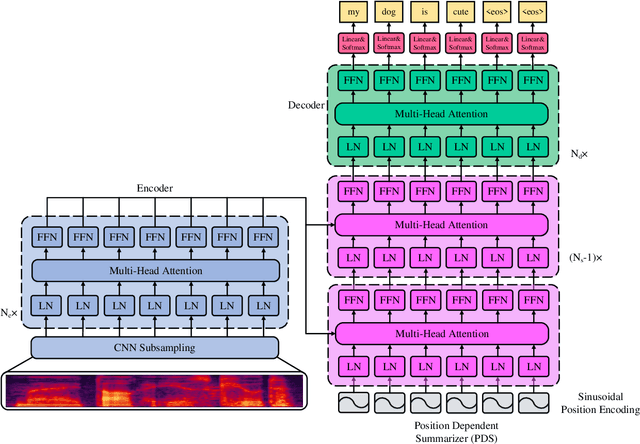
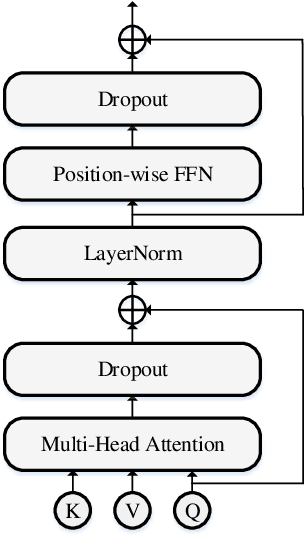
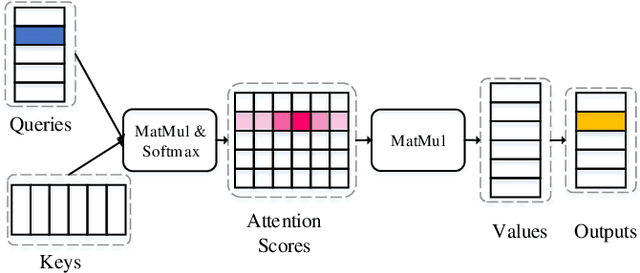
Attention-based encoder-decoder (AED) models have achieved promising performance in speech recognition. However, because the decoder predicts text tokens (such as characters or words) in an autoregressive manner, it is difficult for an AED model to predict all tokens in parallel. This makes the inference speed relatively slow. We believe that because the encoder already captures the whole speech utterance, which has the token-level relationship implicitly, we can predict a token without explicitly autoregressive language modeling. When the prediction of a token does not rely on other tokens, the parallel prediction of all tokens in the sequence is realizable. Based on this idea, we propose a non-autoregressive speech recognition model called LASO (Listen Attentively, and Spell Once). The model consists of an encoder, a decoder, and a position dependent summarizer (PDS). The three modules are based on basic attention blocks. The encoder extracts high-level representations from the speech. The PDS uses positional encodings corresponding to tokens to convert the acoustic representations into token-level representations. The decoder further captures token-level relationships with the self-attention mechanism. At last, the probability distribution on the vocabulary is computed for each token position. Therefore, speech recognition is re-formulated as a position-wise classification problem. Further, we propose a cross-modal transfer learning method to refine semantics from a large-scale pre-trained language model BERT for improving the performance.
Dysfluencies Seldom Come Alone -- Detection as a Multi-Label Problem
Oct 28, 2022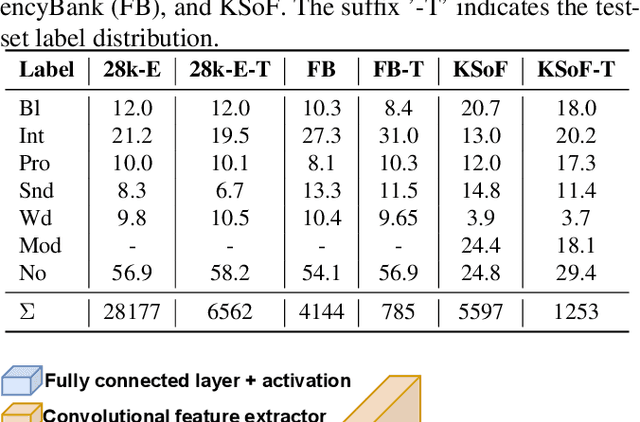
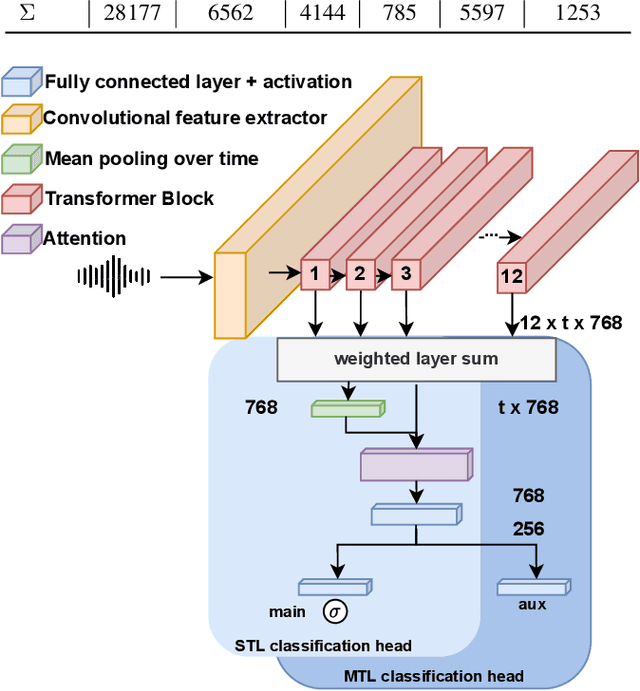
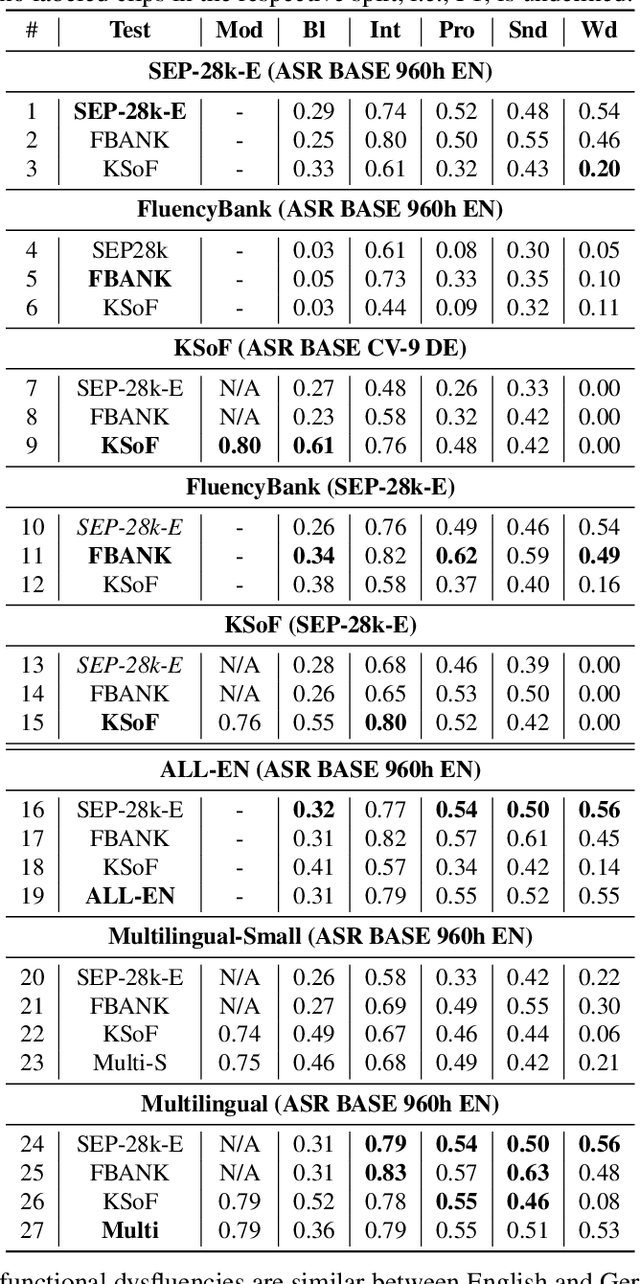
Specially adapted speech recognition models are necessary to handle stuttered speech. For these to be used in a targeted manner, stuttered speech must be reliably detected. Recent works have treated stuttering as a multi-class classification problem or viewed detecting each dysfluency type as an isolated task; that does not capture the nature of stuttering, where one dysfluency seldom comes alone, i.e., co-occurs with others. This work explores an approach based on a modified wav2vec 2.0 system for end-to-end stuttering detection and classification as a multi-label problem. The method is evaluated on combinations of three datasets containing English and German stuttered speech, yielding state-of-the-art results for stuttering detection on the SEP-28k-Extended dataset. Experimental results provide evidence for the transferability of features and the generalizability of the method across datasets and languages.
Robust Multi-channel Speech Recognition using Frequency Aligned Network
Feb 06, 2020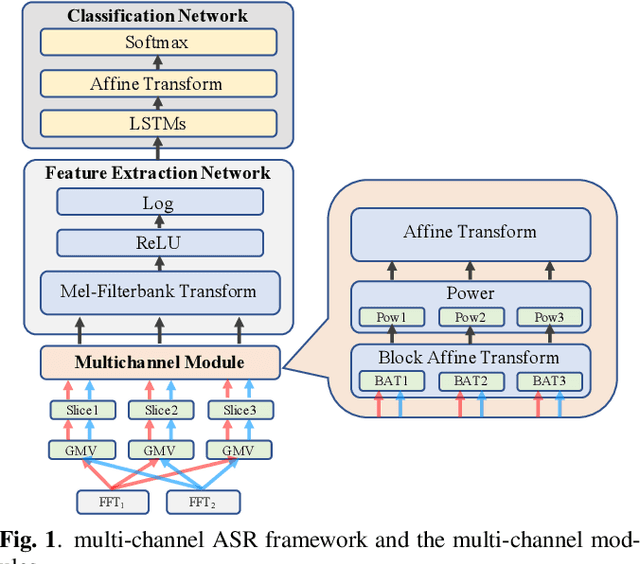
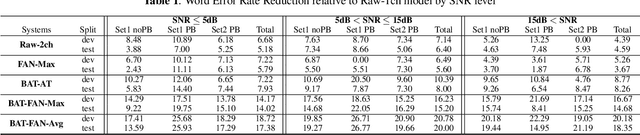
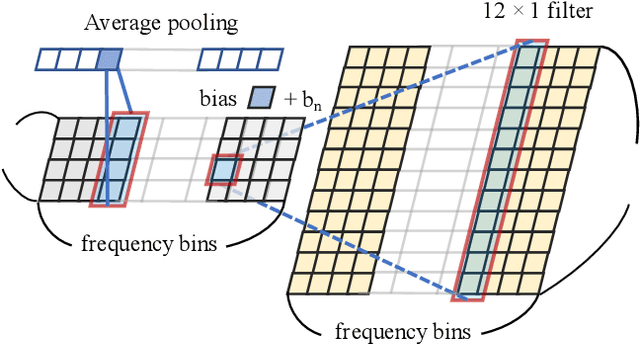
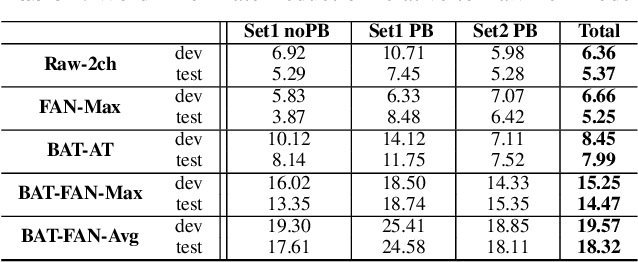
Conventional speech enhancement technique such as beamforming has known benefits for far-field speech recognition. Our own work in frequency-domain multi-channel acoustic modeling has shown additional improvements by training a spatial filtering layer jointly within an acoustic model. In this paper, we further develop this idea and use frequency aligned network for robust multi-channel automatic speech recognition (ASR). Unlike an affine layer in the frequency domain, the proposed frequency aligned component prevents one frequency bin influencing other frequency bins. We show that this modification not only reduces the number of parameters in the model but also significantly and improves the ASR performance. We investigate effects of frequency aligned network through ASR experiments on the real-world far-field data where users are interacting with an ASR system in uncontrolled acoustic environments. We show that our multi-channel acoustic model with a frequency aligned network shows up to 18% relative reduction in word error rate.
Time-frequency Network for Robust Speaker Recognition
Mar 07, 2023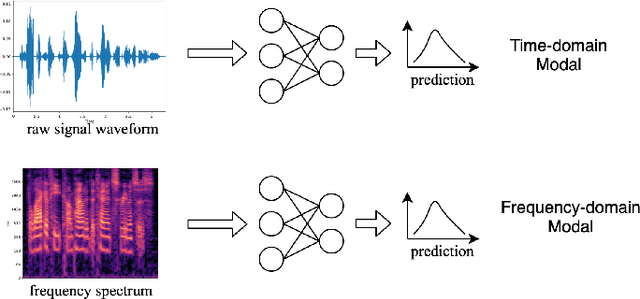
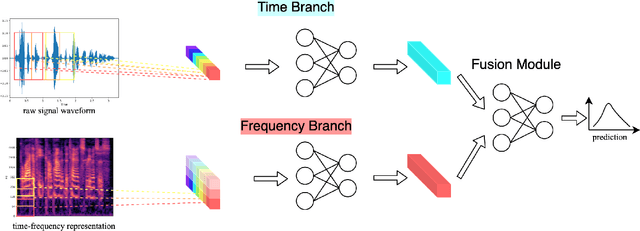
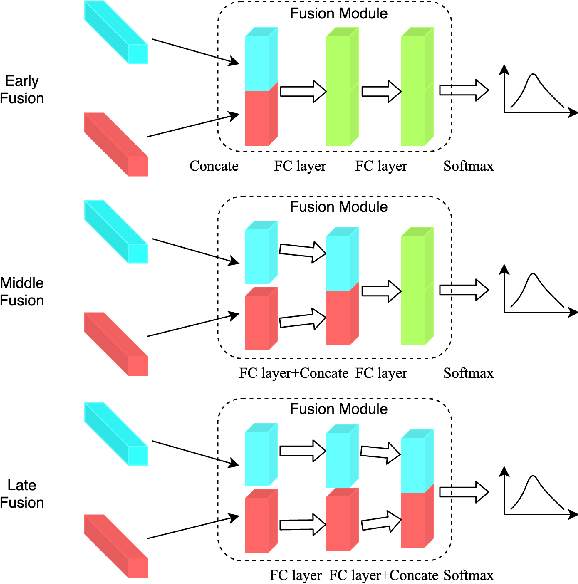
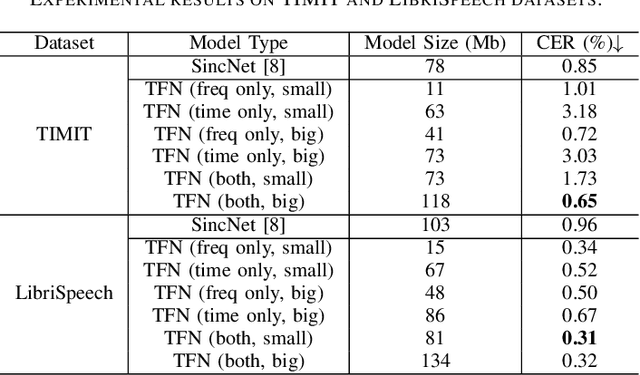
The wide deployment of speech-based biometric systems usually demands high-performance speaker recognition algorithms. However, most of the prior works for speaker recognition either process the speech in the frequency domain or time domain, which may produce suboptimal results because both time and frequency domains are important for speaker recognition. In this paper, we attempt to analyze the speech signal in both time and frequency domains and propose the time-frequency network~(TFN) for speaker recognition by extracting and fusing the features in the two domains. Based on the recent advance of deep neural networks, we propose a convolution neural network to encode the raw speech waveform and the frequency spectrum into domain-specific features, which are then fused and transformed into a classification feature space for speaker recognition. Experimental results on the publicly available datasets TIMIT and LibriSpeech show that our framework is effective to combine the information in the two domains and performs better than the state-of-the-art methods for speaker recognition.
Efficient conformer: Progressive downsampling and grouped attention for automatic speech recognition
Sep 08, 2021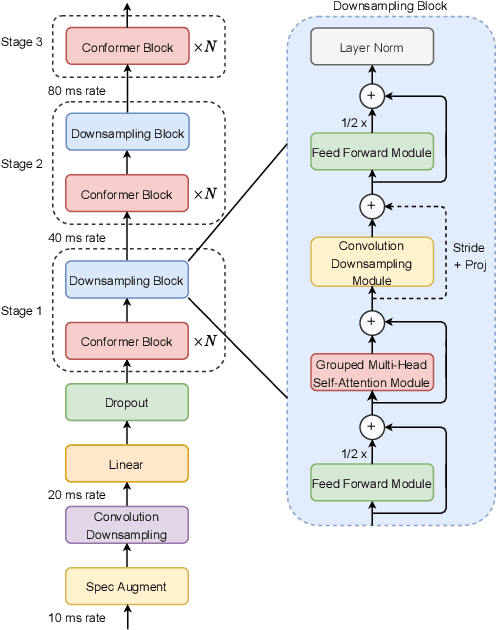
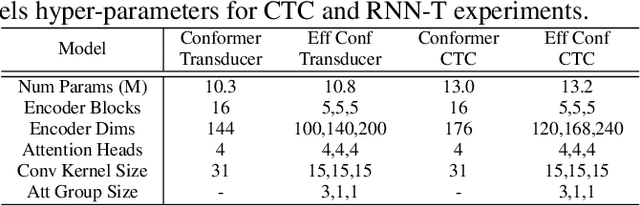

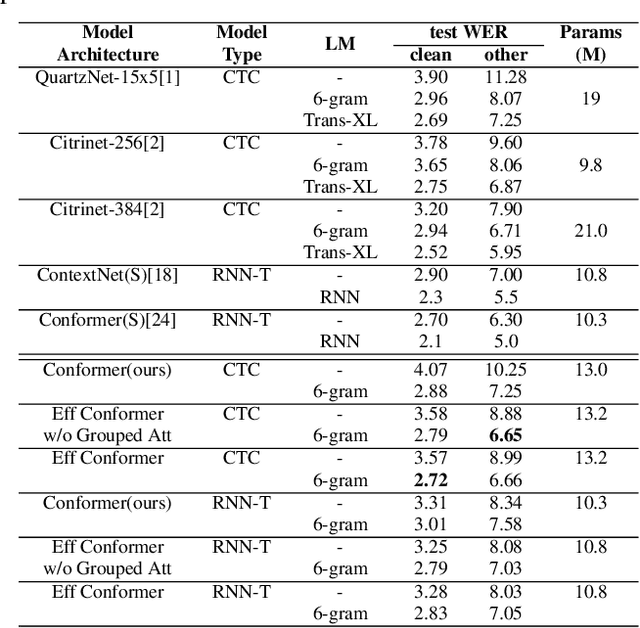
The recently proposed Conformer architecture has shown state-of-the-art performances in Automatic Speech Recognition by combining convolution with attention to model both local and global dependencies. In this paper, we study how to reduce the Conformer architecture complexity with a limited computing budget, leading to a more efficient architecture design that we call Efficient Conformer. We introduce progressive downsampling to the Conformer encoder and propose a novel attention mechanism named grouped attention, allowing us to reduce attention complexity from $O(n^{2}d)$ to $O(n^{2}d / g)$ for sequence length $n$, hidden dimension $d$ and group size parameter $g$. We also experiment the use of strided multi-head self-attention as a global downsampling operation. Our experiments are performed on the LibriSpeech dataset with CTC and RNN-Transducer losses. We show that within the same computing budget, the proposed architecture achieves better performances with faster training and decoding compared to the Conformer. Our 13M parameters CTC model achieves competitive WERs of 3.6%/9.0% without using a language model and 2.7%/6.7% with an external n-gram language model on the test-clean/test-other sets while being 29% faster than our CTC Conformer baseline at inference and 36% faster to train.
Speech recognition for air traffic control via feature learning and end-to-end training
Nov 04, 2021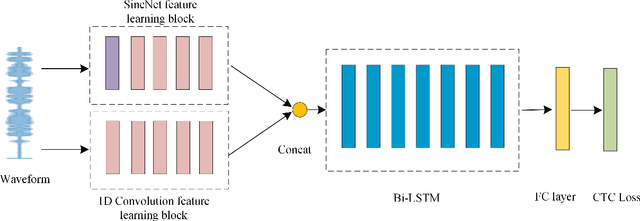
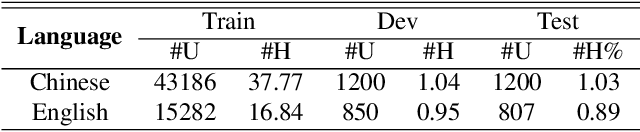
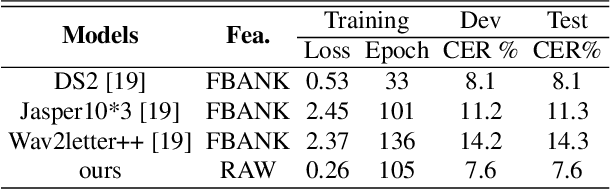
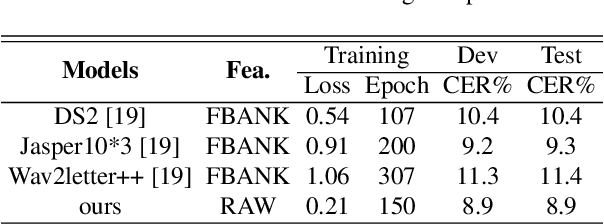
In this work, we propose a new automatic speech recognition (ASR) system based on feature learning and an end-to-end training procedure for air traffic control (ATC) systems. The proposed model integrates the feature learning block, recurrent neural network (RNN), and connectionist temporal classification loss to build an end-to-end ASR model. Facing the complex environments of ATC speech, instead of the handcrafted features, a learning block is designed to extract informative features from raw waveforms for acoustic modeling. Both the SincNet and 1D convolution blocks are applied to process the raw waveforms, whose outputs are concatenated to the RNN layers for the temporal modeling. Thanks to the ability to learn representations from raw waveforms, the proposed model can be optimized in a complete end-to-end manner, i.e., from waveform to text. Finally, the multilingual issue in the ATC domain is also considered to achieve the ASR task by constructing a combined vocabulary of Chinese characters and English letters. The proposed approach is validated on a multilingual real-world corpus (ATCSpeech), and the experimental results demonstrate that the proposed approach outperforms other baselines, achieving a 6.9\% character error rate.
Simulating realistic speech overlaps improves multi-talker ASR
Nov 17, 2022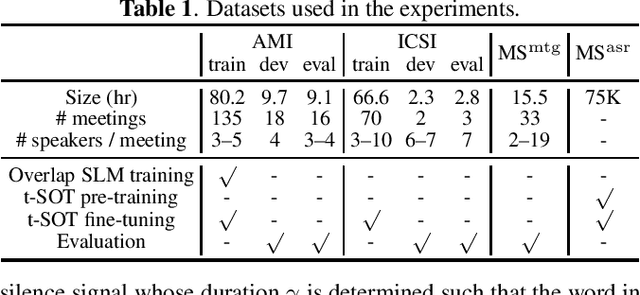
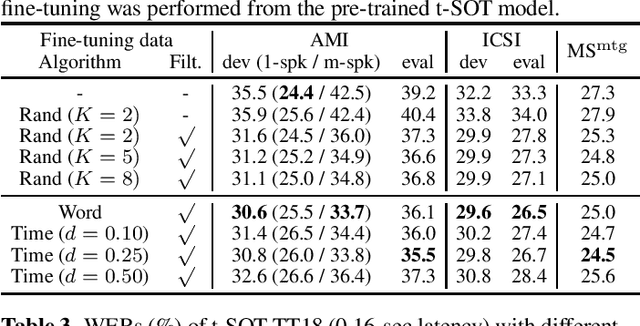

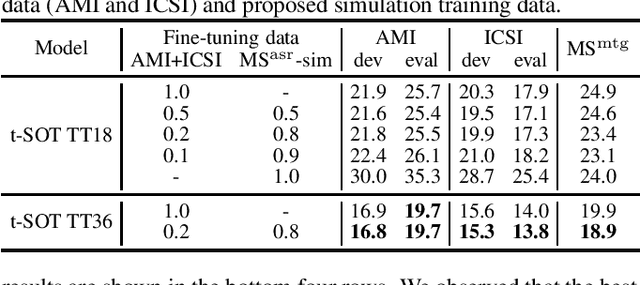
Multi-talker automatic speech recognition (ASR) has been studied to generate transcriptions of natural conversation including overlapping speech of multiple speakers. Due to the difficulty in acquiring real conversation data with high-quality human transcriptions, a na\"ive simulation of multi-talker speech by randomly mixing multiple utterances was conventionally used for model training. In this work, we propose an improved technique to simulate multi-talker overlapping speech with realistic speech overlaps, where an arbitrary pattern of speech overlaps is represented by a sequence of discrete tokens. With this representation, speech overlapping patterns can be learned from real conversations based on a statistical language model, such as N-gram, which can be then used to generate multi-talker speech for training. In our experiments, multi-talker ASR models trained with the proposed method show consistent improvement on the word error rates across multiple datasets.
SpeechFormer++: A Hierarchical Efficient Framework for Paralinguistic Speech Processing
Feb 27, 2023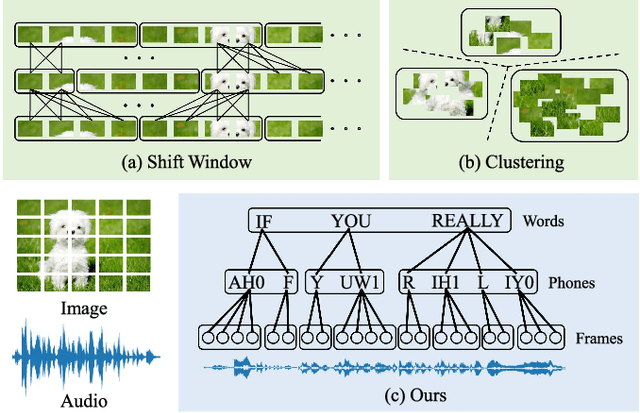
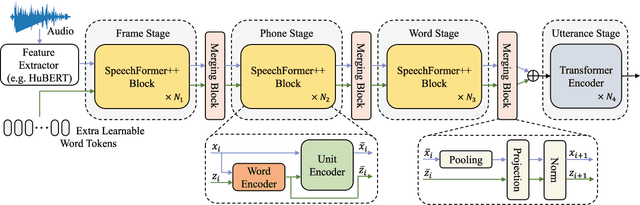
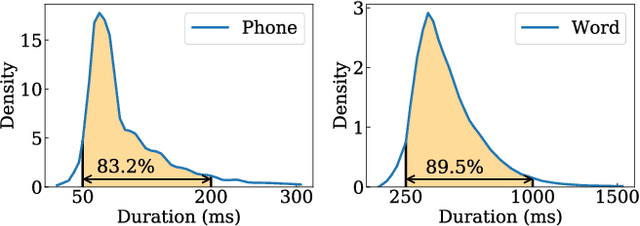
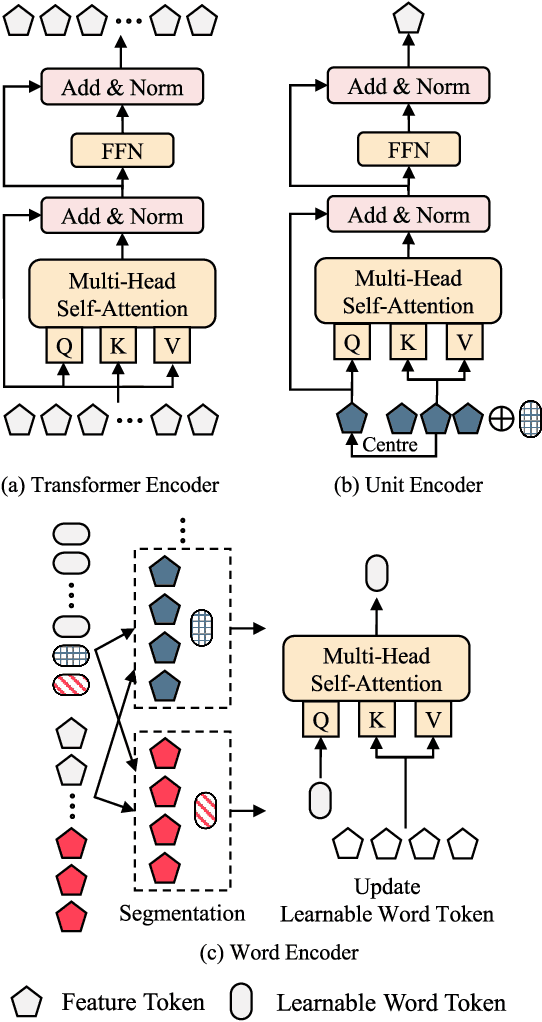
Paralinguistic speech processing is important in addressing many issues, such as sentiment and neurocognitive disorder analyses. Recently, Transformer has achieved remarkable success in the natural language processing field and has demonstrated its adaptation to speech. However, previous works on Transformer in the speech field have not incorporated the properties of speech, leaving the full potential of Transformer unexplored. In this paper, we consider the characteristics of speech and propose a general structure-based framework, called SpeechFormer++, for paralinguistic speech processing. More concretely, following the component relationship in the speech signal, we design a unit encoder to model the intra- and inter-unit information (i.e., frames, phones, and words) efficiently. According to the hierarchical relationship, we utilize merging blocks to generate features at different granularities, which is consistent with the structural pattern in the speech signal. Moreover, a word encoder is introduced to integrate word-grained features into each unit encoder, which effectively balances fine-grained and coarse-grained information. SpeechFormer++ is evaluated on the speech emotion recognition (IEMOCAP & MELD), depression classification (DAIC-WOZ) and Alzheimer's disease detection (Pitt) tasks. The results show that SpeechFormer++ outperforms the standard Transformer while greatly reducing the computational cost. Furthermore, it delivers superior results compared to the state-of-the-art approaches.