 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Preliminary Study on SSCF-derived Polar Coordinate for ASR
Nov 30, 2022
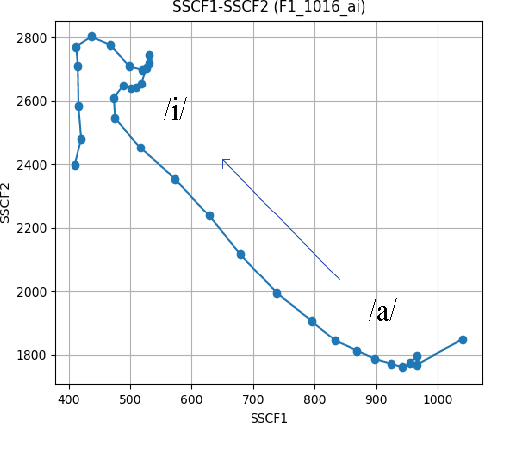

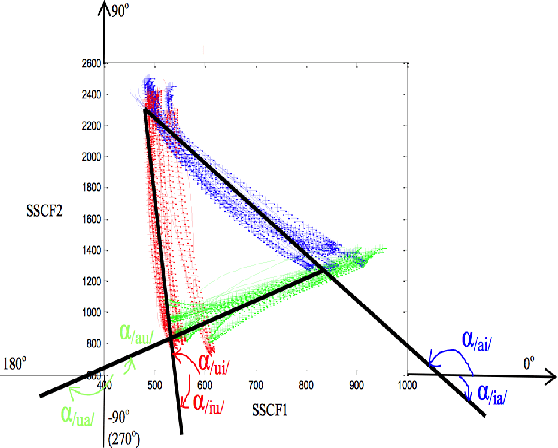

The transition angles are defined to describe the vowel-to-vowel transitions in the acoustic space of the Spectral Subband Centroids, and the findings show that they are similar among speakers and speaking rates. In this paper, we propose to investigate the usage of polar coordinates in favor of angles to describe a speech signal by characterizing its acoustic trajectory and using them in Automatic Speech Recognition. According to the experimental results evaluated on the BRAF100 dataset, the polar coordinates achieved significantly higher accuracy than the angles in the mixed and cross-gender speech recognitions, demonstrating that these representations are superior at defining the acoustic trajectory of the speech signal. Furthermore, the accuracy was significantly improved when they were utilized with their first and second-order derivatives ($\Delta$, $\Delta$$\Delta$), especially in cross-female recognition. However, the results showed they were not much more gender-independent than the conventional Mel-frequency Cepstral Coefficients (MFCCs).
BUT Opensat 2019 Speech Recognition System
Jan 30, 2020


The paper describes the BUT Automatic Speech Recognition (ASR) systems submitted for OpenSAT evaluations under two domain categories such as low resourced languages and public safety communications. The first was challenging due to lack of training data, therefore various architectures and multilingual approaches were employed. The combination led to superior performance. The second domain was challenging due to recording in extreme conditions such as specific channel, speaker under stress and high levels of noise. Data augmentation process was inevitable to get reasonably good performance.
Wav2vec-Switch: Contrastive Learning from Original-noisy Speech Pairs for Robust Speech Recognition
Oct 11, 2021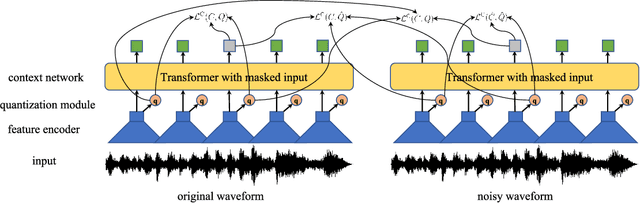
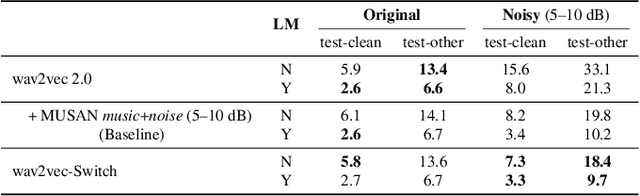
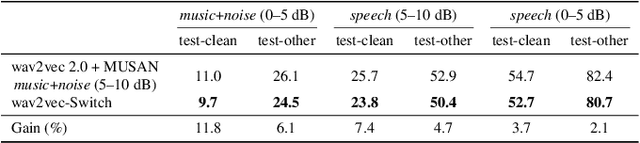

The goal of self-supervised learning (SSL) for automatic speech recognition (ASR) is to learn good speech representations from a large amount of unlabeled speech for the downstream ASR task. However, most SSL frameworks do not consider noise robustness which is crucial for real-world applications. In this paper we propose wav2vec-Switch, a method to encode noise robustness into contextualized representations of speech via contrastive learning. Specifically, we feed original-noisy speech pairs simultaneously into the wav2vec 2.0 network. In addition to the existing contrastive learning task, we switch the quantized representations of the original and noisy speech as additional prediction targets of each other. By doing this, it enforces the network to have consistent predictions for the original and noisy speech, thus allows to learn contextualized representation with noise robustness. Our experiments on synthesized and real noisy data show the effectiveness of our method: it achieves 2.9--4.9% relative word error rate (WER) reduction on the synthesized noisy LibriSpeech data without deterioration on the original data, and 5.7% on CHiME-4 real 1-channel noisy data compared to a data augmentation baseline even with a strong language model for decoding. Our results on CHiME-4 can match or even surpass those with well-designed speech enhancement components.
Improving Mandarin End-to-End Speech Recognition with Word N-gram Language Model
Jan 06, 2022
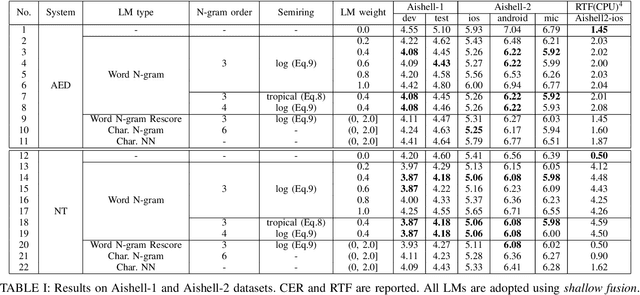
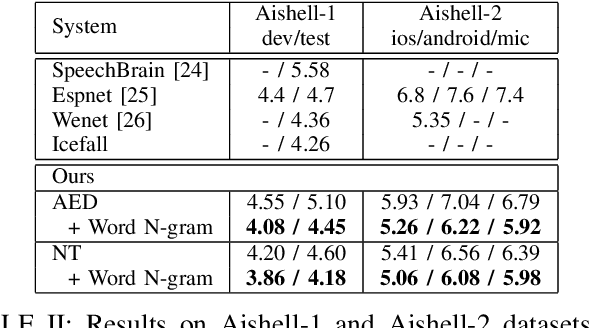
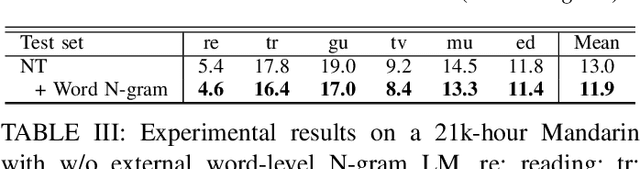
Despite the rapid progress of end-to-end (E2E) automatic speech recognition (ASR), it has been shown that incorporating external language models (LMs) into the decoding can further improve the recognition performance of E2E ASR systems. To align with the modeling units adopted in E2E ASR systems, subword-level (e.g., characters, BPE) LMs are usually used to cooperate with current E2E ASR systems. However, the use of subword-level LMs will ignore the word-level information, which may limit the strength of the external LMs in E2E ASR. Although several methods have been proposed to incorporate word-level external LMs in E2E ASR, these methods are mainly designed for languages with clear word boundaries such as English and cannot be directly applied to languages like Mandarin, in which each character sequence can have multiple corresponding word sequences. To this end, we propose a novel decoding algorithm where a word-level lattice is constructed on-the-fly to consider all possible word sequences for each partial hypothesis. Then, the LM score of the hypothesis is obtained by intersecting the generated lattice with an external word N-gram LM. The proposed method is examined on both Attention-based Encoder-Decoder (AED) and Neural Transducer (NT) frameworks. Experiments suggest that our method consistently outperforms subword-level LMs, including N-gram LM and neural network LM. We achieve state-of-the-art results on both Aishell-1 (CER 4.18%) and Aishell-2 (CER 5.06%) datasets and reduce CER by 14.8% relatively on a 21K-hour Mandarin dataset.
Neural Transducer Training: Reduced Memory Consumption with Sample-wise Computation
Nov 29, 2022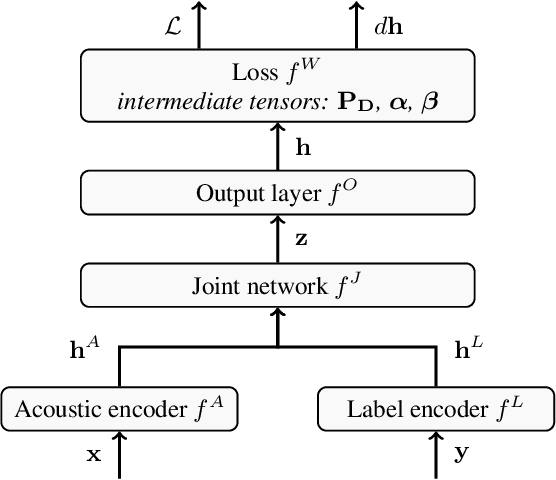

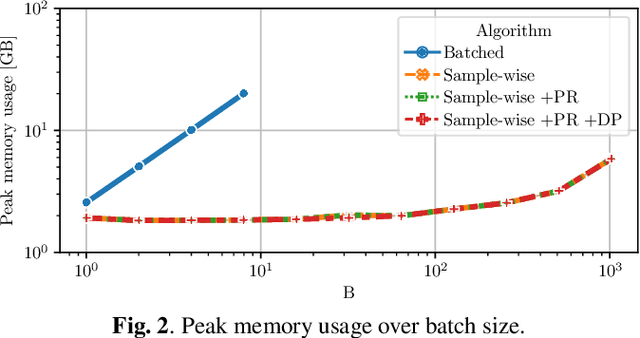
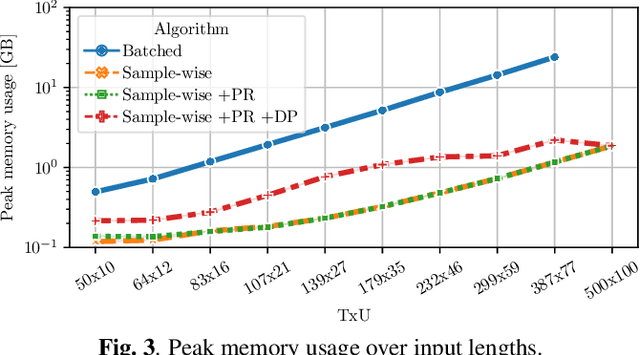
The neural transducer is an end-to-end model for automatic speech recognition (ASR). While the model is well-suited for streaming ASR, the training process remains challenging. During training, the memory requirements may quickly exceed the capacity of state-of-the-art GPUs, limiting batch size and sequence lengths. In this work, we analyze the time and space complexity of a typical transducer training setup. We propose a memory-efficient training method that computes the transducer loss and gradients sample by sample. We present optimizations to increase the efficiency and parallelism of the sample-wise method. In a set of thorough benchmarks, we show that our sample-wise method significantly reduces memory usage, and performs at competitive speed when compared to the default batched computation. As a highlight, we manage to compute the transducer loss and gradients for a batch size of 1024, and audio length of 40 seconds, using only 6 GB of memory.
Evaluating and reducing the distance between synthetic and real speech distributions
Nov 29, 2022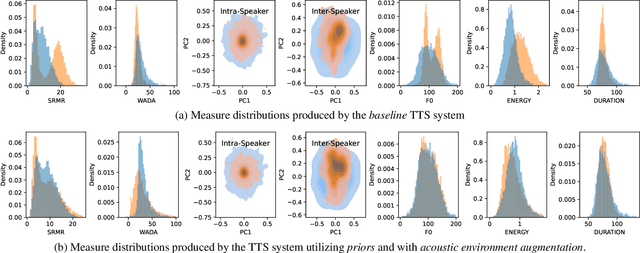
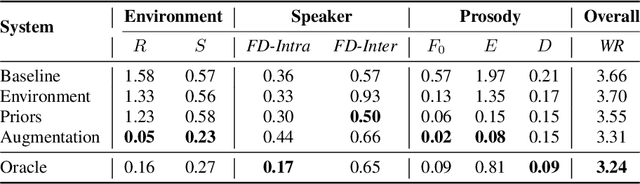
While modern Text-to-Speech (TTS) systems can produce speech rated highly in terms of subjective evaluation, the distance between real and synthetic speech distributions remains understudied, where we use the term \textit{distribution} to mean the sample space of all possible real speech recordings from a given set of speakers; or of the synthetic samples that could be generated for the same set of speakers. We evaluate the distance of real and synthetic speech distributions along the dimensions of the acoustic environment, speaker characteristics and prosody using a range of speech processing measures and the respective Wasserstein distances of their distributions. We reduce these distribution distances along said dimensions by providing utterance-level information derived from the measures to the model and show they can be generated at inference time. The improvements to the dimensions translate to overall distribution distance reduction approximated using Automatic Speech Recognition (ASR) by evaluating the fitness of the synthetic data as training data.
Streaming Attention-Based Models with Augmented Memory for End-to-End Speech Recognition
Nov 03, 2020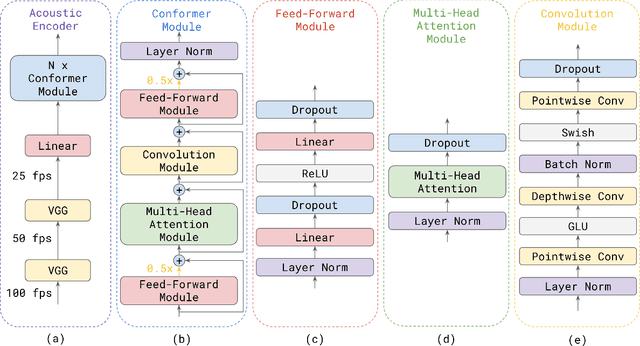
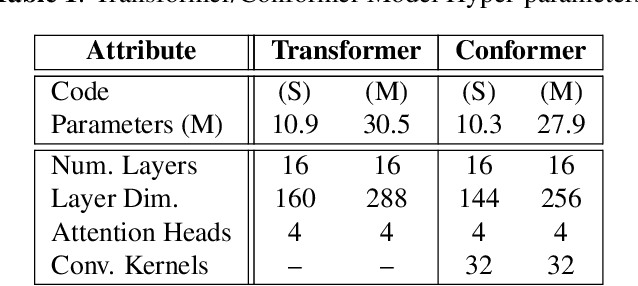
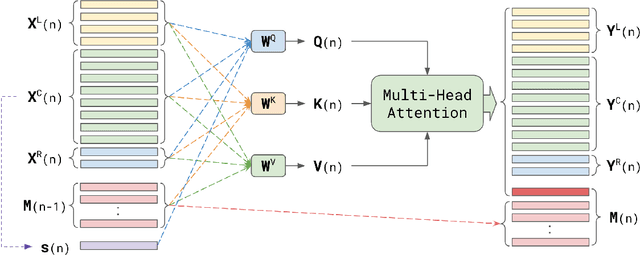
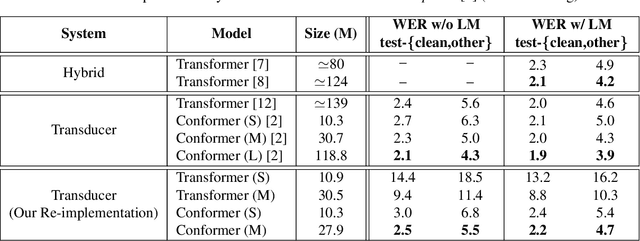
Attention-based models have been gaining popularity recently for their strong performance demonstrated in fields such as machine translation and automatic speech recognition. One major challenge of attention-based models is the need of access to the full sequence and the quadratically growing computational cost concerning the sequence length. These characteristics pose challenges, especially for low-latency scenarios, where the system is often required to be streaming. In this paper, we build a compact and streaming speech recognition system on top of the end-to-end neural transducer architecture with attention-based modules augmented with convolution. The proposed system equips the end-to-end models with the streaming capability and reduces the large footprint from the streaming attention-based model using augmented memory. On the LibriSpeech dataset, our proposed system achieves word error rates 2.7% on test-clean and 5.8% on test-other, to our best knowledge the lowest among streaming approaches reported so far.
Learning to Rank Microphones for Distant Speech Recognition
Apr 06, 2021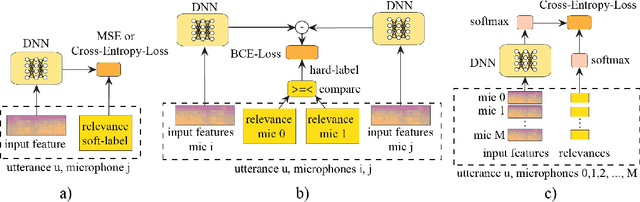
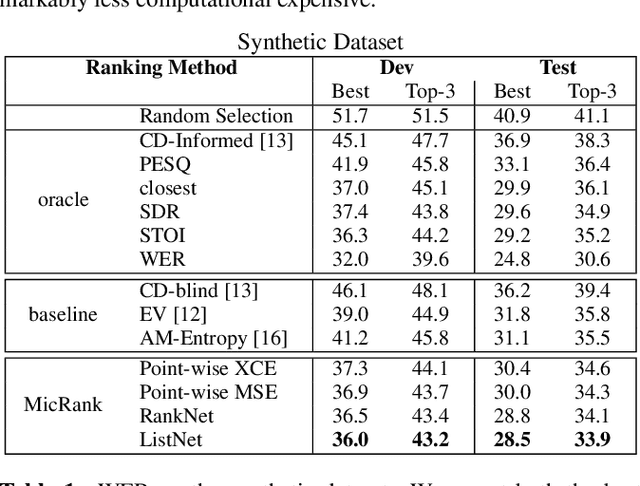
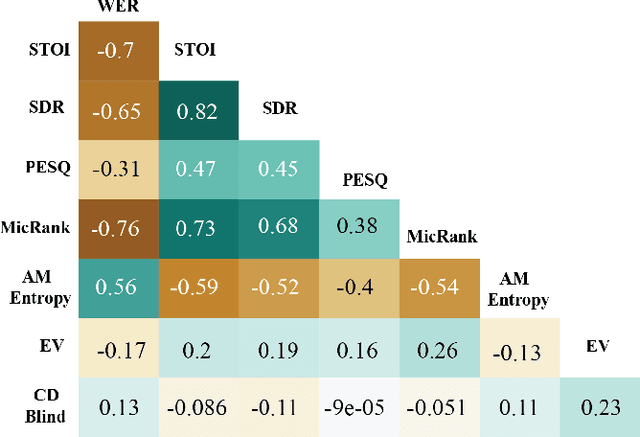
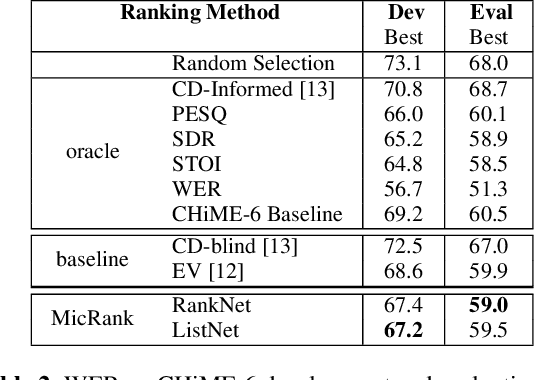
Fully exploiting ad-hoc microphone networks for distant speech recognition is still an open issue. Empirical evidence shows that being able to select the best microphone leads to significant improvements in recognition without any additional effort on front-end processing. Current channel selection techniques either rely on signal, decoder or posterior-based features. Signal-based features are inexpensive to compute but do not always correlate with recognition performance. Instead decoder and posterior-based features exhibit better correlation but require substantial computational resources. In this work, we tackle the channel selection problem by proposing MicRank, a learning to rank framework where a neural network is trained to rank the available channels using directly the recognition performance on the training set. The proposed approach is agnostic with respect to the array geometry and type of recognition back-end. We investigate different learning to rank strategies using a synthetic dataset developed on purpose and the CHiME-6 data. Results show that the proposed approach is able to considerably improve over previous selection techniques, reaching comparable and in some instances better performance than oracle signal-based measures.
Privacy-Preserving Speech Representation Learning using Vector Quantization
Mar 15, 2022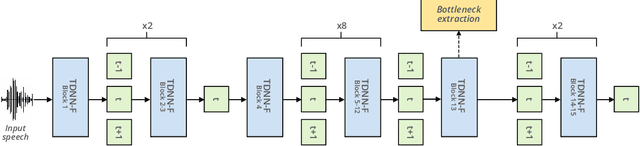

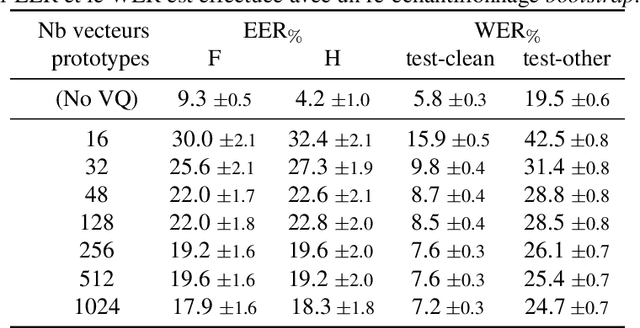
With the popularity of virtual assistants (e.g., Siri, Alexa), the use of speech recognition is now becoming more and more widespread.However, speech signals contain a lot of sensitive information, such as the speaker's identity, which raises privacy concerns.The presented experiments show that the representations extracted by the deep layers of speech recognition networks contain speaker information.This paper aims to produce an anonymous representation while preserving speech recognition performance.To this end, we propose to use vector quantization to constrain the representation space and induce the network to suppress the speaker identity.The choice of the quantization dictionary size allows to configure the trade-off between utility (speech recognition) and privacy (speaker identity concealment).
Adversarial Attacks and Defenses for Speech Recognition Systems
Mar 31, 2021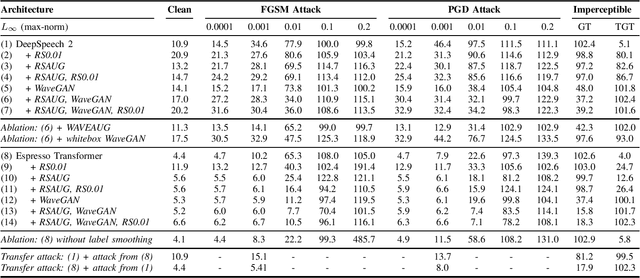
The ubiquitous presence of machine learning systems in our lives necessitates research into their vulnerabilities and appropriate countermeasures. In particular, we investigate the effectiveness of adversarial attacks and defenses against automatic speech recognition (ASR) systems. We select two ASR models - a thoroughly studied DeepSpeech model and a more recent Espresso framework Transformer encoder-decoder model. We investigate two threat models: a denial-of-service scenario where fast gradient-sign method (FGSM) or weak projected gradient descent (PGD) attacks are used to degrade the model's word error rate (WER); and a targeted scenario where a more potent imperceptible attack forces the system to recognize a specific phrase. We find that the attack transferability across the investigated ASR systems is limited. To defend the model, we use two preprocessing defenses: randomized smoothing and WaveGAN-based vocoder, and find that they significantly improve the model's adversarial robustness. We show that a WaveGAN vocoder can be a useful countermeasure to adversarial attacks on ASR systems - even when it is jointly attacked with the ASR, the target phrases' word error rate is high.