 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Exploring Wav2vec 2.0 fine-tuning for improved speech emotion recognition
Oct 12, 2021
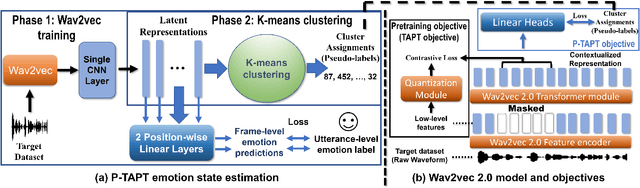
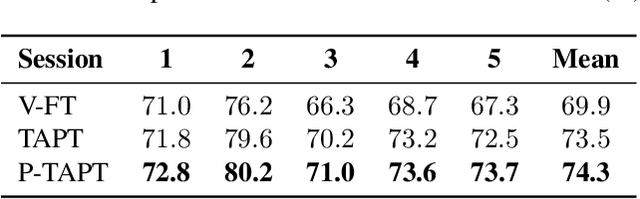
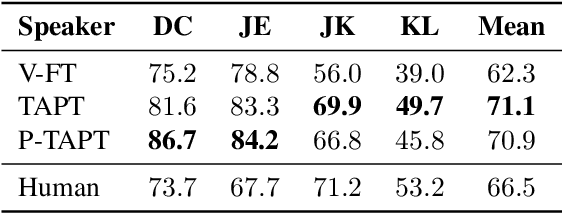

While wav2vec 2.0 has been proposed for speech recognition (ASR), it can also be used for speech emotion recognition (SER); its performance can be significantly improved using different fine-tuning strategies. Two baseline methods, vanilla fine-tuning (V-FT) and task adaptive pretraining (TAPT) are first presented. We show that V-FT is able to outperform state-of-the-art models on the IEMOCAP dataset. TAPT, an existing NLP fine-tuning strategy, further improves the performance on SER. We also introduce a novel fine-tuning method termed P-TAPT, which modifies the TAPT objective to learn contextualized emotion representations. Experiments show that P-TAPT performs better than TAPT especially under low-resource settings. Compared to prior works in this literature, our top-line system achieved a 7.4% absolute improvement on unweighted accuracy (UA) over the state-of-the-art performance on IEMOCAP. Our code is publicly available.
An Exploration of Self-Supervised Pretrained Representations for End-to-End Speech Recognition
Oct 09, 2021
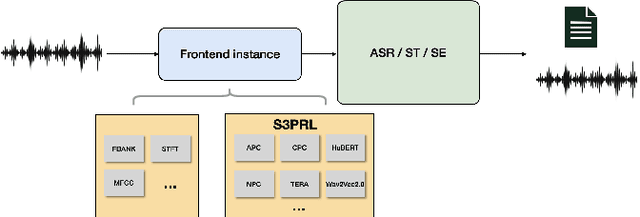
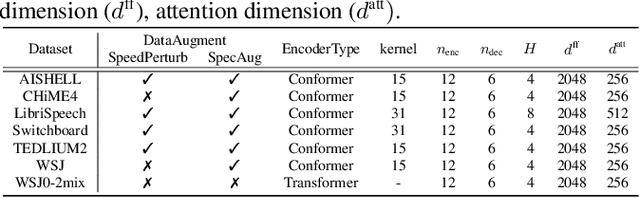
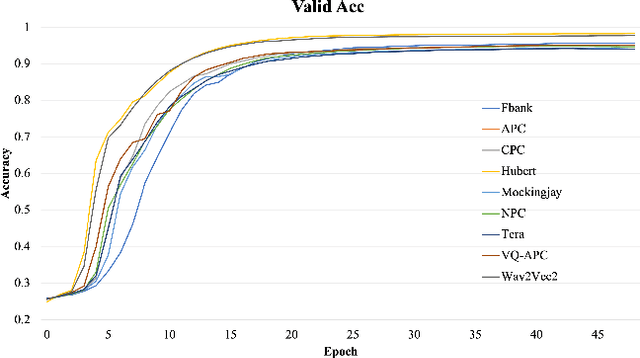
Self-supervised pretraining on speech data has achieved a lot of progress. High-fidelity representation of the speech signal is learned from a lot of untranscribed data and shows promising performance. Recently, there are several works focusing on evaluating the quality of self-supervised pretrained representations on various tasks without domain restriction, e.g. SUPERB. However, such evaluations do not provide a comprehensive comparison among many ASR benchmark corpora. In this paper, we focus on the general applications of pretrained speech representations, on advanced end-to-end automatic speech recognition (E2E-ASR) models. We select several pretrained speech representations and present the experimental results on various open-source and publicly available corpora for E2E-ASR. Without any modification of the back-end model architectures or training strategy, some of the experiments with pretrained representations, e.g., WSJ, WSJ0-2mix with HuBERT, reach or outperform current state-of-the-art (SOTA) recognition performance. Moreover, we further explore more scenarios for whether the pretraining representations are effective, such as the cross-language or overlapped speech. The scripts, configuratons and the trained models have been released in ESPnet to let the community reproduce our experiments and improve them.
Lattice-Free Sequence Discriminative Training for Phoneme-Based Neural Transducers
Dec 07, 2022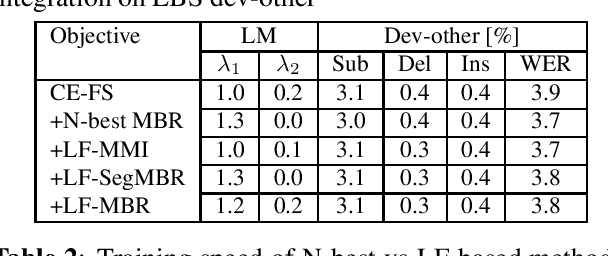
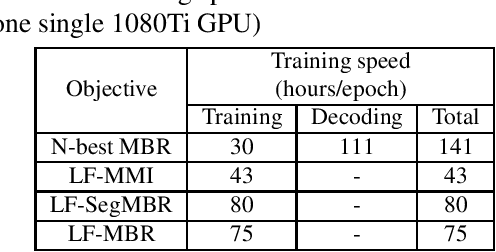
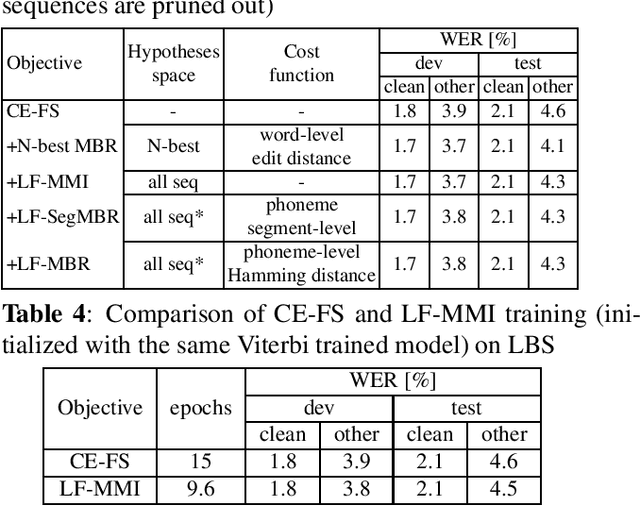
Recently, RNN-Transducers have achieved remarkable results on various automatic speech recognition tasks. However, lattice-free sequence discriminative training methods, which obtain superior performance in hybrid modes, are rarely investigated in RNN-Transducers. In this work, we propose three lattice-free training objectives, namely lattice-free maximum mutual information, lattice-free segment-level minimum Bayes risk, and lattice-free minimum Bayes risk, which are used for the final posterior output of the phoneme-based neural transducer with a limited context dependency. Compared to criteria using N-best lists, lattice-free methods eliminate the decoding step for hypotheses generation during training, which leads to more efficient training. Experimental results show that lattice-free methods gain up to 6.5% relative improvement in word error rate compared to a sequence-level cross-entropy trained model. Compared to the N-best-list based minimum Bayes risk objectives, lattice-free methods gain 40% - 70% relative training time speedup with a small degradation in performance.
Improving Transformer-based Speech Recognition Using Unsupervised Pre-training
Oct 30, 2019
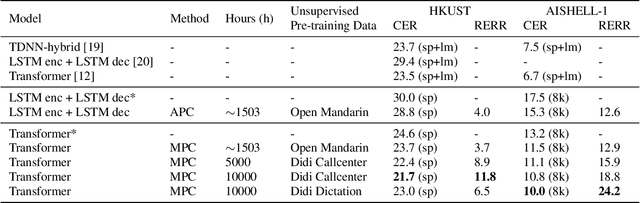
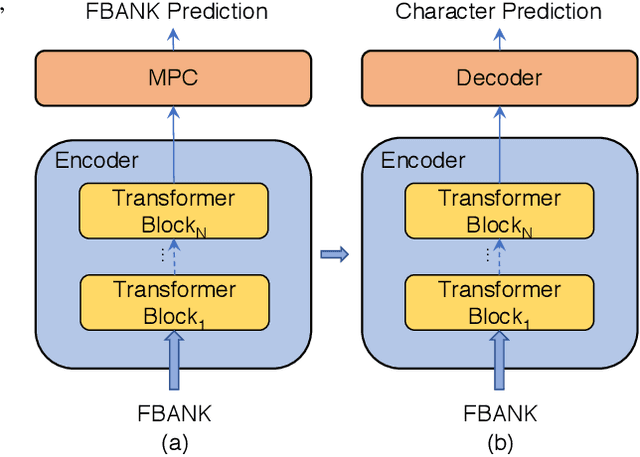
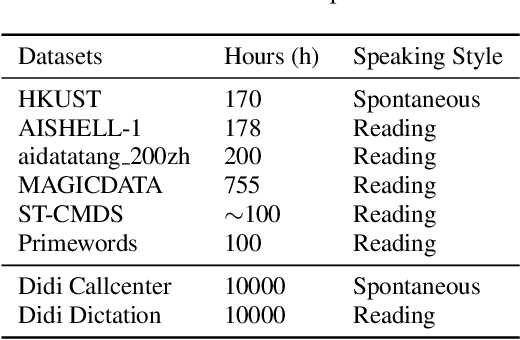
Speech recognition technologies are gaining enormous popularity in various industrial applications. However, building a good speech recognition system usually requires significant amounts of transcribed data, which is expensive to collect. To tackle this problem, an unsupervised pre-training method called Masked Predictive Coding is proposed, which can be applied for unsupervised pre-training with state-of-the-arts Transformer based model. Experiments on HKUST show that using the same training data and other open source Mandarin data, we can achieve a CER of 22.9, or a 3.8% relative improvements over a strong Transformer baseline. With more pre-training data, we can further reduce the CER to 21.0, or a 11.8% relative CER reduction over baseline.
A Transfer Learning Method for Speech Emotion Recognition from Automatic Speech Recognition
Aug 06, 2020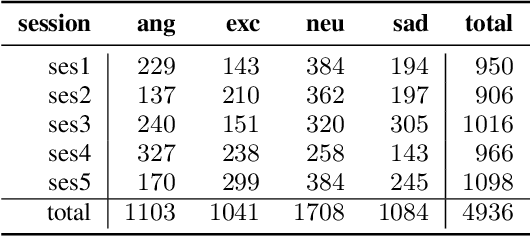
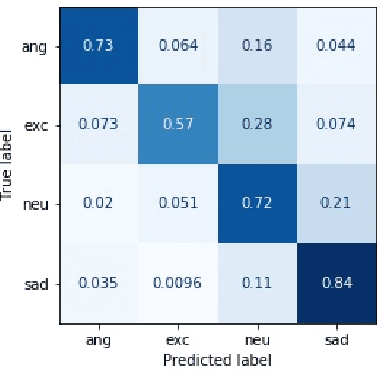

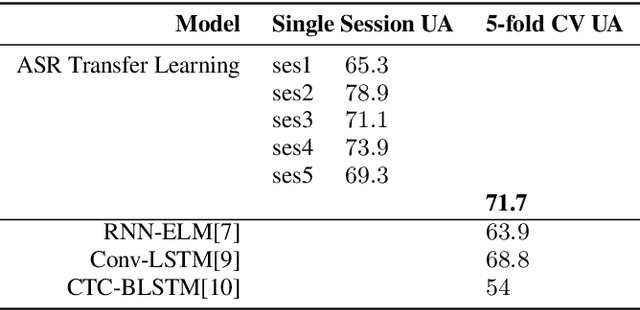
This paper presents a transfer learning method in speech emotion recognition based on a Time-Delay Neural Network (TDNN) architecture. A major challenge in the current speech-based emotion detection research is data scarcity. The proposed method resolves this problem by applying transfer learning techniques in order to leverage data from the automatic speech recognition (ASR) task for which ample data is available. Our experiments also show the advantage of speaker-class adaptation modeling techniques by adopting identity-vector (i-vector) based features in addition to standard Mel-Frequency Cepstral Coefficient (MFCC) features.[1] We show the transfer learning models significantly outperform the other methods without pretraining on ASR. The experiments performed on the publicly available IEMOCAP dataset which provides 12 hours of motional speech data. The transfer learning was initialized by using the Ted-Lium v.2 speech dataset providing 207 hours of audio with the corresponding transcripts. We achieve the highest significantly higher accuracy when compared to state-of-the-art, using five-fold cross validation. Using only speech, we obtain an accuracy 71.7% for anger, excitement, sadness, and neutrality emotion content.
Evaluating context-invariance in unsupervised speech representations
Oct 27, 2022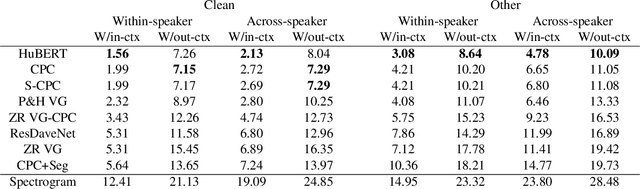
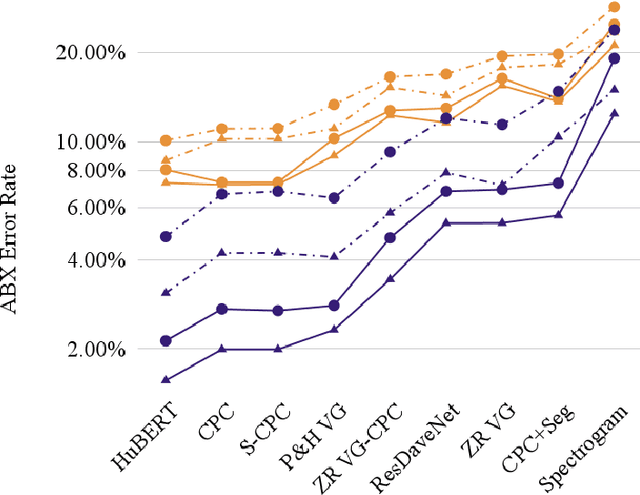
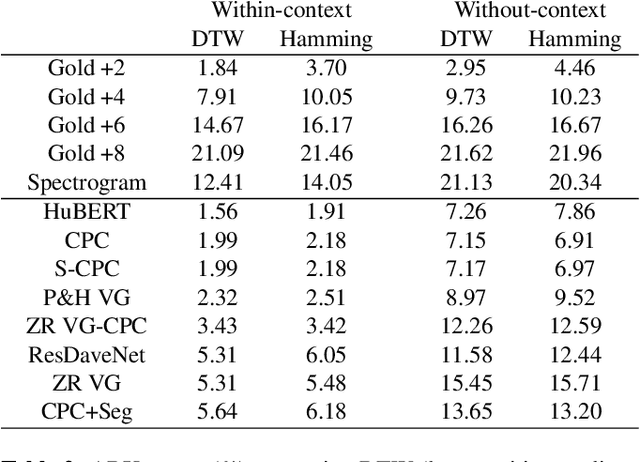
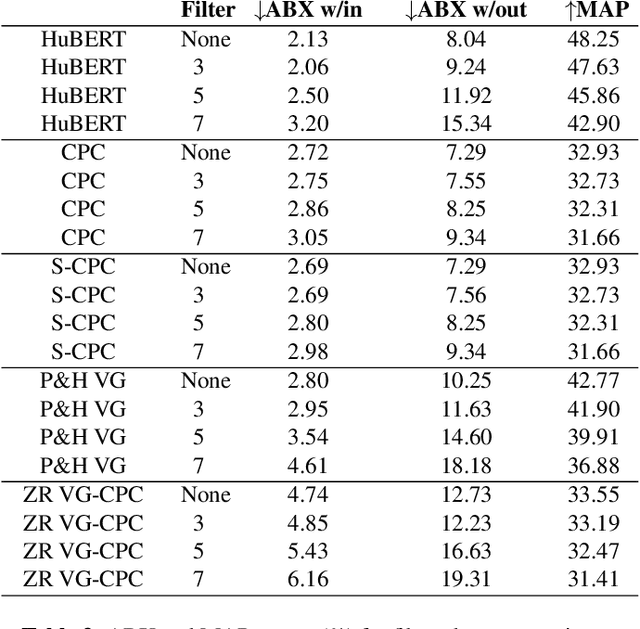
Unsupervised speech representations have taken off, with benchmarks (SUPERB, ZeroSpeech) demonstrating major progress on semi-supervised speech recognition, speech synthesis, and speech-only language modelling. Inspiration comes from the promise of ``discovering the phonemes'' of a language or a similar low-bitrate encoding. However, one of the critical properties of phoneme transcriptions is context-invariance: the phonetic context of a speech sound can have massive influence on the way it is pronounced, while the text remains stable. This is what allows tokens of the same word to have the same transcriptions -- key to language understanding. Current benchmarks do not measure context-invariance. We develop a new version of the ZeroSpeech ABX benchmark that measures context-invariance, and apply it to recent self-supervised representations. We demonstrate that the context-independence of representations is predictive of the stability of word-level representations. We suggest research concentrate on improving context-independence of self-supervised and unsupervised representations.
Momentum Pseudo-Labeling for Semi-Supervised Speech Recognition
Jun 16, 2021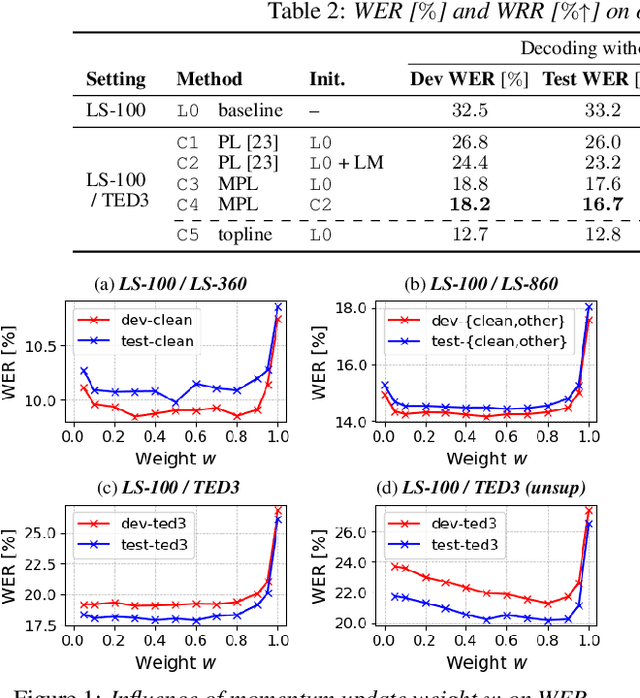
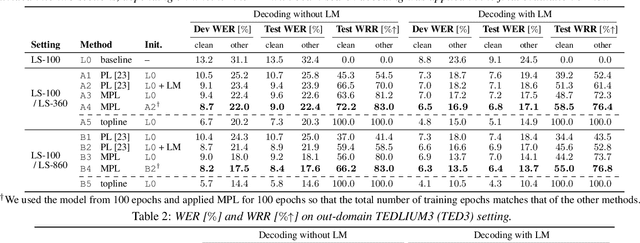
Pseudo-labeling (PL) has been shown to be effective in semi-supervised automatic speech recognition (ASR), where a base model is self-trained with pseudo-labels generated from unlabeled data. While PL can be further improved by iteratively updating pseudo-labels as the model evolves, most of the previous approaches involve inefficient retraining of the model or intricate control of the label update. We present momentum pseudo-labeling (MPL), a simple yet effective strategy for semi-supervised ASR. MPL consists of a pair of online and offline models that interact and learn from each other, inspired by the mean teacher method. The online model is trained to predict pseudo-labels generated on the fly by the offline model. The offline model maintains a momentum-based moving average of the online model. MPL is performed in a single training process and the interaction between the two models effectively helps them reinforce each other to improve the ASR performance. We apply MPL to an end-to-end ASR model based on the connectionist temporal classification. The experimental results demonstrate that MPL effectively improves over the base model and is scalable to different semi-supervised scenarios with varying amounts of data or domain mismatch.
Toward Cross-Domain Speech Recognition with End-to-End Models
Mar 09, 2020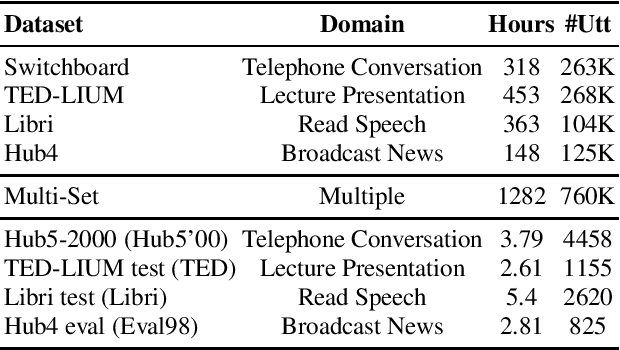
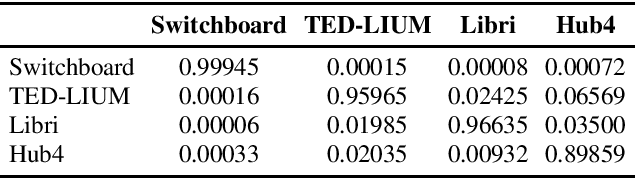
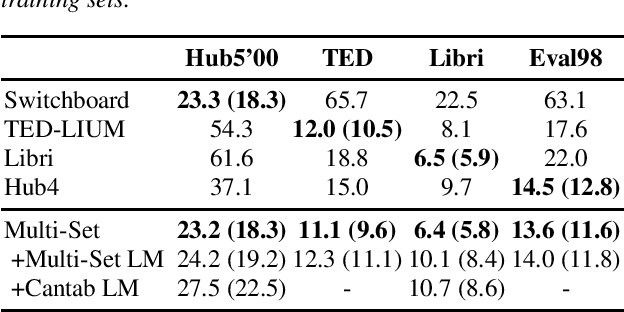
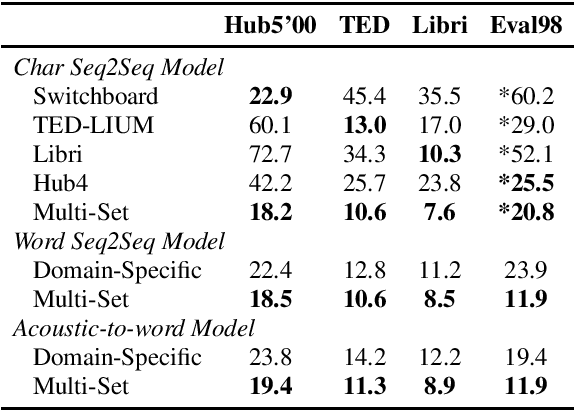
In the area of multi-domain speech recognition, research in the past focused on hybrid acoustic models to build cross-domain and domain-invariant speech recognition systems. In this paper, we empirically examine the difference in behavior between hybrid acoustic models and neural end-to-end systems when mixing acoustic training data from several domains. For these experiments we composed a multi-domain dataset from public sources, with the different domains in the corpus covering a wide variety of topics and acoustic conditions such as telephone conversations, lectures, read speech and broadcast news. We show that for the hybrid models, supplying additional training data from other domains with mismatched acoustic conditions does not increase the performance on specific domains. However, our end-to-end models optimized with sequence-based criterion generalize better than the hybrid models on diverse domains. In term of word-error-rate performance, our experimental acoustic-to-word and attention-based models trained on multi-domain dataset reach the performance of domain-specific long short-term memory (LSTM) hybrid models, thus resulting in multi-domain speech recognition systems that do not suffer in performance over domain specific ones. Moreover, the use of neural end-to-end models eliminates the need of domain-adapted language models during recognition, which is a great advantage when the input domain is unknown.
Domain Specific Wav2vec 2.0 Fine-tuning For The SE&R 2022 Challenge
Jul 29, 2022
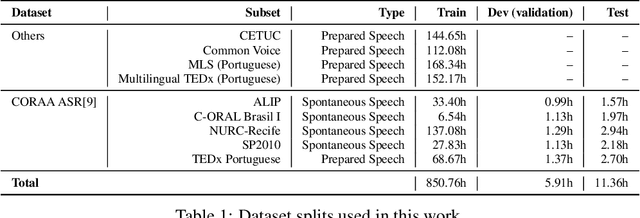
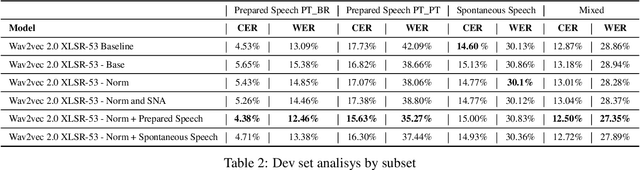
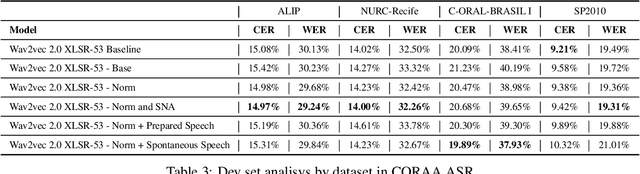
This paper presents our efforts to build a robust ASR model for the shared task Automatic Speech Recognition for spontaneous and prepared speech & Speech Emotion Recognition in Portuguese (SE&R 2022). The goal of the challenge is to advance the ASR research for the Portuguese language, considering prepared and spontaneous speech in different dialects. Our method consist on fine-tuning an ASR model in a domain-specific approach, applying gain normalization and selective noise insertion. The proposed method improved over the strong baseline provided on the test set in 3 of the 4 tracks available
Spectro-Temporal Deep Features for Disordered Speech Assessment and Recognition
Jan 14, 2022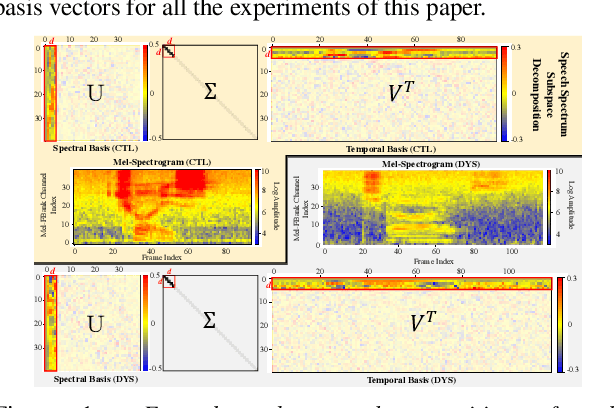
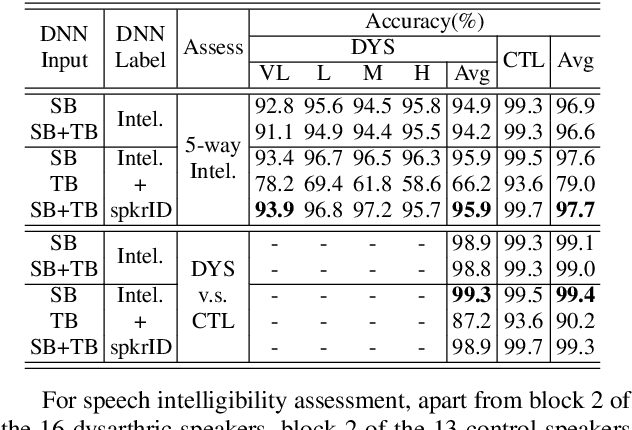
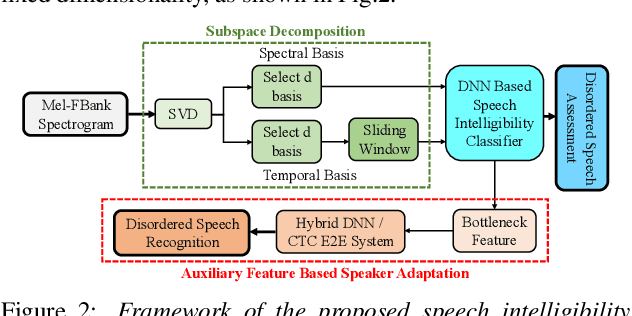
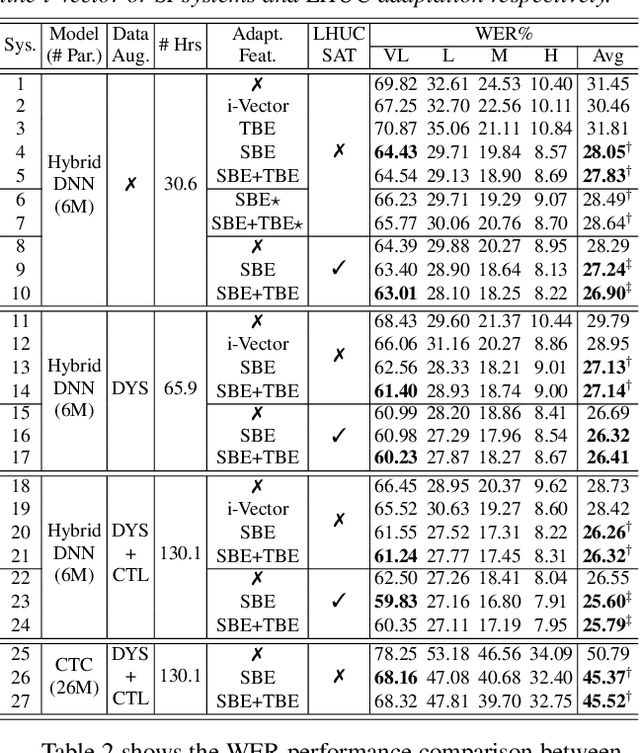
Automatic recognition of disordered speech remains a highly challenging task to date. Sources of variability commonly found in normal speech including accent, age or gender, when further compounded with the underlying causes of speech impairment and varying severity levels, create large diversity among speakers. To this end, speaker adaptation techniques play a vital role in current speech recognition systems. Motivated by the spectro-temporal level differences between disordered and normal speech that systematically manifest in articulatory imprecision, decreased volume and clarity, slower speaking rates and increased dysfluencies, novel spectro-temporal subspace basis embedding deep features derived by SVD decomposition of speech spectrum are proposed to facilitate both accurate speech intelligibility assessment and auxiliary feature based speaker adaptation of state-of-the-art hybrid DNN and end-to-end disordered speech recognition systems. Experiments conducted on the UASpeech corpus suggest the proposed spectro-temporal deep feature adapted systems consistently outperformed baseline i-Vector adaptation by up to 2.63% absolute (8.6% relative) reduction in word error rate (WER) with or without data augmentation. Learning hidden unit contribution (LHUC) based speaker adaptation was further applied. The final speaker adapted system using the proposed spectral basis embedding features gave an overall WER of 25.6% on the UASpeech test set of 16 dysarthric speakers